їаРЪвШзХбЪЮХ ЯаШЬХЭХЭШХ аХУгЫпаЭле ТлаРЦХЭШЩ
їЮЬЭШвХ ЧРФРзг б ЯЮТвЮапойШЬШбп бЫЮТРЬШ ШЧ ЯХаТЮЩ УЫРТл? П гЦХ УЮТЮаШЫ, звЮ ХХ ЯЮЫЭЮХ аХиХЭШХ Т пЧлЪХ вШЯР Perl бЮбвЮШв ШЧ ЭХбЪЮЫмЪШе бваЮЪ. ЅРЯаШЬХа, ЮЭЮ ЬЮЦХв ТлУЫпФХвм вРЪ:
$/ = ".\n";
while (<>) {
next if !s/\b([a-z]+)((\s|<[^>]+>)+)(\1\b)/\e[7m$1\e[m$2\e[7m$4\e[m/ig;
s/^([^\e]*\n)+//mg; # ГФРЫШвм ЭХЯЮЬХзХЭЭлХ бваЮЪШ
s/^/$ARGV: /mg; # ЅРзШЭРвм бваЮЪг б ШЬХЭШ дРЩЫР
print;
}
ґР, ЯХаХФ ТРЬШ Тбп ЯаЮУаРЬЬР.
П ЭХ аРббзШвлТРо ЭР вЮ, звЮ Тл аРЧСХаХвХбм Т ЭХЩ (ЯЮЪР!) БЪЮаХХ, нвЮ ЯаШЬХа, ТлеЮФпйШЩ ЧР аРЬЪШ ТЮЧЬЮЦЭЮбвХЩ egrep Ш ЯаШЧТРЭЭлЩ аРЧЦХзм ТРи ШЭвХаХб Ъ аХУгЫпаЭлЬ ТлаРЦХЭШпЬ. Ібп ЮбЭЮТЭРп аРСЮвР нвЮЩ ЯаЮУаРЬЬл бТпЧРЭР б ваХЬп аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ:
\b([a-z]+)((\s|<[^>]+>)+)(\1\b)
^([^\e]*\n)+
^
єЮЭХзЭЮ, [^] гЧЭРвм ЭХвагФЭЮ, ЭЮ Т ЮбвРЫмЭле ТлаРЦХЭШпе ЯаШбгвбвТгов нЫХЬХЭвл, ЭХ ТбваХзРТиШХбп Т egrep (еЮвп ЬХвРбШЬТЮЫ [\b] ЪаРвЪЮ гЯЮЬШЭРЫбп ЭР бваРЭШжХ <$R[P#,R1-3]> ЪРЪ ЮСЮЧЭРзХЭШХ УаРЭШжл бЫЮТР — ШЬХЭЭЮ нвг дгЭЪжШо ЮЭ Ш ТлЯЮЫЭпХв ЧФХбм). ґХЫЮ Т вЮЬ, звЮ Т Perl Ш egrep ШбЯЮЫмЧговбп аРЧЭлХ ФШРЫХЪвл аХУгЫпаЭле ТлаРЦХЭШЩ. ѕвЫШзРовбп ЭХЪЮвЮалХ ЮСЮЧЭРзХЭШп, Ш Perl ЮСЫРФРХв УЮаРЧФЮ СЮЫХХ СЮУРвлЬ ЭРСЮаЮЬ ЬХвРбШЬТЮЫЮТ. їаШЬХал СгФгв ЯаШТХФХЭл Т нвЮЩ УЫРТХ.
їЮ ТЮЧЬЮЦЭЮбвпЬ аРСЮвл б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ Perl ЧЭРзШвХЫмЭЮ ЯаХТЮбеЮФШв egrep. ДаРУЬХЭвл, ЭРЯШбРЭЭлХ ЭР Perl, ЯаЮФХЬЮЭбваШагов ЭЮТлХ ЯаШЬХал ШбЯЮЫмЧЮТРЭШп аХУгЫпаЭле ТлаРЦХЭШЩ, ЭЮ звЮ ХйХ ТРЦЭХХ, ЯаХФбвРТпв Ше Т ЭХбЪЮЫмЪЮ ШЭЮЬ ЪЮЭвХЪбвХ, ЭХЦХЫШ Т egrep. ° ЯЮЪР Ьл ЯЮЧЭРЪЮЬШЬбп б ЯЮеЮЦШЬ (еЮвп Ш ЭХбЪЮЫмЪЮ ЮвЫШзРойШЬбп) ФШРЫХЪвЮЬ аХУгЫпаЭле ТлаРЦХЭШЩ.
І нвЮЩ УЫРТХ Ьл аРббЬЮваШЬ ЭХбЪЮЫмЪЮ ЧРФРз-ЯаШЬХаЮТ (ЯаЮТХаЪР ЯЮЫмЧЮТРвХЫмбЪЮУЮ ТТЮФР; аРСЮвР б ЧРУЮЫЮТЪРЬШ нЫХЪваЮЭЭЮЩ ЯЮзвл) Ш ТЮбЯЮЫмЧгХЬбп ШЬШ ФЫп ЮСйХУЮ ЮСЧЮаР аХУгЫпаЭле ТлаРЦХЭШЩ. Іл ЯЮЧЭРЪЮЬШвХбм б пЧлЪЮЬ Perl Ш ЭХЪЮвЮалЬШ ЯаШХЬРЬШ, ШбЯЮЫмЧгХЬлЬШ ЯаШ бЮЧФРЭШШ аХУгЫпаЭле ТлаРЦХЭШЩ. ІЮ ТаХЬп ЯгвХиХбвТШп Ьл СгФХЬ зРбвЮ ЮвТЫХЪРвмбп Юв ЮбЭЮТЭЮЩ вХЬл Ш ШббЫХФЮТРвм аРЧЫШзЭлХ ТРЦЭлХ ЪЮЭжХЯжШШ.
ІЯаЮзХЬ, ТлСЮа Perl Т ФРЭЭЮЬ бЫгзРХ ЭХ ШУаРХв ЮбЮСЮЩ аЮЫШ. Б вРЪШЬ ЦХ гбЯХеЮЬ ЬЮЦЭЮ СлЫЮ ТЮбЯЮЫмЧЮТРвмбп Ш ФагУШЬШ пЧлЪРЬШ (Tcl, Python Ш ФРЦХ elisp Юв GNU Emacs). П ТлСаРЫ Perl Т ЮбЭЮТЭЮЬ ШЧ-ЧР вЮУЮ, звЮ баХФШ ТбХе аРбЯаЮбваРЭХЭЭле пЧлЪЮТ ЮЭ ЮСЫРФРХв ЭРШСЮЫХХ ШЭвХУаШаЮТРЭЭЮЩ ЯЮФФХаЦЪЮЩ аХУгЫпаЭле ТлаРЦХЭШЩ Ш, ТЮЧЬЮЦЭЮ, пТЫпХвбп бРЬлЬ ФЮбвгЯЭлЬ. єаЮЬХ вЮУЮ, Т Perl бгйХбвТгХв ЬЭЮУЮ ТбЯЮЬЮУРвХЫмЭле ЪЮЭбвагЪжШЩ, ЪЮвЮалХ ТлЯЮЫЭпов Тбо «зХаЭго аРСЮвг» Ш ЯЮЧТЮЫпов ЭРЬ бЪЮЭжХЭваШаЮТРвмбп ЭР аХУгЫпаЭле ТлаРЦХЭШпе. ІбЯЮЬЭШвХ ЯаШЬХа б ЯаЮТХаЪЮЩ дРЩЫЮТ, ЮЯШбРЭЭлЩ ЭР б. <$R[P#,R1-4]>. ґЫп аХиХЭШп нвЮЩ ЧРФРзШ п ТЮбЯЮЫмЧЮТРЫбп Perl, Р ЪЮЬРЭФР ТлУЫпФХЫР вРЪ<$M[R2-7]>:
% perl -0ne 'print "$ARGV\n" if s/ResetSize//ig != s/SetSize//ig' *
(п бЭЮТР ЭХ аРббзШвлТРо, звЮ Тл ЯЮЩЬХвХ нвг ЪЮЬРЭФг, Р ЫШим ЭРФХобм, звЮ ЭР ТРб ЯаЮШЧТХФХв ТЯХзРвЫХЭШХ ЫРЪЮЭШзЭЮбвм аХиХЭШп).
П ЫоСЫо Perl, ЭЮ ЭХ бЮСШаРобм гФХЫпвм ХЬг бЫШиЪЮЬ ЬЭЮУЮ ТЭШЬРЭШп. ЅХ ЧРСлТРЩвХ: нвР УЫРТР ЯЮбТпйХЭР аХУгЫпаЭлЬ ТлаРЦХЭШпЬ. їаШТХФг бЫЮТР ЮФЭЮУЮ ЯаЮдХббЮаР, ЮСаРйХЭЭлХ Ъ бвгФХЭвРЬ-ЯХаТЮЪгабЭШЪРЬ: «јл ШЧгзРХЬ ЮСйШХ ЪЮЭжХЯжШШ ЪЮЬЯмовХаЭле вХеЭЮЫЮУШЩ, ЭЮ аРббЬРваШТРХЬ Ше ЭР ЯаШЬХаХ Pascal» (Pascal — ваРФШжШЮЭЭлЩ пЧлЪ ЯаЮУаРЬЬШаЮТРЭШп, ЯХаТЮЭРзРЫмЭЮ аРЧаРСЮвРЭЭлЩ Т гзХСЭле жХЫпе)[1].
їЮбЪЮЫмЪг нвР УЫРТР ЭХ ЯаХФЯЮЫРУРХв ЧЭРЭШп Perl, п Т ЮСйШе зХавРе ЯаХФбвРТЫо нвЮв пЧлЪ, звЮСл Тл ЬЮУЫШ аРЧЮСаРвмбп Т ЯаШТХФХЭЭле ЯаШЬХаРе (УЫРТР 7, Т ЪЮвЮаЮЩ аРббЬРваШТРовбп ТбХТЮЧЬЮЦЭлХ ЭоРЭбл аРСЮвл Perl, ваХСгХв ЭХЪЮвЮале ЯЮЧЭРЭШЩ Т пЧлЪХ). ґРЦХ ХбЫШ Тл ТРЬ ЯаШеЮФШЫЮбм ЯаЮУаРЬЬШаЮТРвм ЭР аРЧЭле пЧлЪРе, Perl ЭР ЯХаТлЩ ТЧУЫпФ ТлУЫпФШв ФЮТЮЫмЭЮ бваРЭЭЮ; нвЮ ЮСкпбЭпХвбп ЪЮЬЯРЪвЭЮбвмо ХУЮ бШЭвРЪбШбР Ш бХЬРЭвШзХбЪЮЩ ЬЭЮУЮЧЭРзЭЮбвмо. ЕЮвп ЯаШТХФХЭЭлХ ЯаШЬХал ЭХЫмЧп ЭРЧТРвм «ЯЫЮеШЬШ», нвЮ ФРЫХЪЮ ЭХ ЫгзиШХ ЮСаРЧжл «їгвШ їаЮУаРЬЬШаЮТРЭШп Perl». АРФШ ЭРУЫпФЭЮбвШ п ЮвЪРЧРЫбп Юв ШбЯЮЫмЧЮТРЭШп ЬЭЮУШе ТЮЧЬЮЦЭЮбвХЩ Perl; п ЯЮбвРаРЫбп ЯаХФбвРТШвм ЯаЮУаРЬЬл Т СЮЫХХ ЮСйХЬ, ЯаШСЫШЦХЭЭЮЬ Ъ ЯбХТФЮЪЮФг бвШЫХ. ЅЮ ЧРвЮ Тл гТШФШвХ ЭХЪЮвЮалХ ЧРЬХзРвХЫмЭлХ ЯаШЬХЭХЭШп аХУгЫпаЭле ТлаРЦХЭШЩ.
јЮйЭлЩ бжХЭРаЭлЩ пЧлЪ Perl СлЫ бЮЧФРЭ »РааШ ГЮЫЫЮЬ Т ЪЮЭжХ 1980-е УЮФЮТ ЭР ЮбЭЮТХ ШФХЩ, ЯЮзХаЯЭгвле ШЧ апФР ФагУШе пЧлЪЮТ ЯаЮУаРЬЬШаЮТРЭШп. јЭЮУШХ ХУЮ ЪЮЭжХЯжШШ ЮСаРСЮвЪШ вХЪбвР Ш аХУгЫпаЭле ТлаРЦХЭШЩ ЯЮЧРШЬбвТЮТРЭл ШЧ ФТге пЧлЪЮТ, awk Ш sed, ЧРЬХвЭЮ ЮвЫШзРойШебп Юв «ваРФШжШЮЭЭле» пЧлЪЮТ вШЯР C ШЫШ Pascal. Perl бгйХбвТгХв ЭР ЬЭЮУШе ЯЫРвдЮаЬРе, ТЪЫозРп DOS/Windows, MacOS, OS/2, VMS Ш Unix. ѕЭ Т ЧЭРзШвХЫмЭЮЩ бвХЯХЭШ ЮаШХЭвШаЮТРЭ ЭР ЮСаРСЮвЪг вХЪбвЮТ Ш пТЫпХвбп бРЬлЬ аРбЯаЮбваРЭХЭЭлЬ ШЭбвагЬХЭвЮЬ ФЫп ЭРЯШбРЭШп бжХЭРаШХТ CGI Т World Wide Web (ЯаЮУаРЬЬ, ЪЮвЮалХ ЪЮЭбвагШагов Ш ЮвЯаРТЫпов ФШЭРЬШзХбЪШХ Web-бваРЭШжл). ёЭдЮаЬРжШп Ю вЮЬ, ЪРЪ ФЮбвРвм ЪЮЯШо Perl ФЫп ТРиХЩ бШбвХЬл, ЯаШТХФХЭР Т ЯаШЫЮЦХЭШШ °. ЅР ЬЮЬХЭв ЭРЯШбРЭШп ЪЭШУШ бгйХбвТЮТРЫ Perl ТХабШШ 5.003, ЭЮ ЯаШЬХал нвЮЩ УЫРТл ЭРЯШбРЭл ФЫп ТХабШШ 4.036 Ш ТлиХ[2].
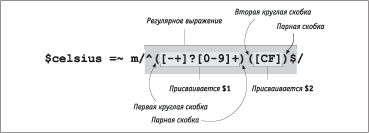
АРббЬЮваШЬ ЯаЮбвЮЩ ЯаШЬХа:
$celsius = 30;
$fahrenheit = ($celsius * 9 / 5) + 32; # ІлзШбЫШвм вХЬЯХаРвгаг
# ЯЮ иЪРЫХ ДРаХЭУХЩвР
print "$celsius C is $fahrenheit F.\n"; # ІлТХбвШ ЮСХ вХЬЯХаРвгал
їаЮУаРЬЬР ТлТЮФШв бЫХФгойШЩ аХЧгЫмвРв:
30 C is 86 F.
ёЬХЭР ЯаЮбвле ЯХаХЬХЭЭле (вРЪШе, ЪРЪ $fahrenheit Ш $celsius) ТбХУФР ЭРзШЭРовбп бЮ ЧЭРЪР ФЮЫЫРаР Ш ЬЮУгв бЮФХаЦРвм зШбЫЮ ШЫШ бваЮЪг ЫоСЮЩ ФЫШЭл (Т ФРЭЭЮЬ ЯаШЬХаХ ШбЯЮЫмЧговбп вЮЫмЪЮ зШбЫР). єЮЬЬХЭвРаШШ ЭРзШЭРовбп бЮ ЧЭРЪР # Ш ЯаЮФЮЫЦРовбп ФЮ ЪЮЭжР бваЮЪШ. µбЫШ Тл ЯаЮУаРЬЬШаЮТРЫШ ЭР ваРФШжШЮЭЭле пЧлЪРе вШЯР C ШЫШ Pascal, ТХаЮпвЭЮ, ТРб СЮЫмиХ ТбХУЮ гФШТШв ЯаШбгвбвТШХ ЯХаХЬХЭЭле Т бваЮЪРе Perl, ЧРЪЫозХЭЭле Т ЪРТлзЪШ. І бваЮЪХ "$celsius C is $fahrenheit F.\n" ЪРЦФРп ЯХаХЬХЭЭРп ЧРЬХЭпХвбп бТЮШЬ ЧЭРзХЭШХЬ. І ФРЭЭЮЬ бЫгзРХ ЯЮЫгзХЭЭРп бваЮЪР ЧРвХЬ ТлТЮФШвбп (бШЬТЮЫ \n ЭРзШЭРХв ЭЮТго бваЮЪг ЭР нЪаРЭХ).
їЮ бТЮШЬ гЯаРТЫпойШЬ бвагЪвгаРЬ Perl ЭРЯЮЬШЭРХв ФагУШХ аРбЯаЮбваРЭХЭЭлХ пЧлЪШ:
$celsius = 20;
while ($celsius <= 45)
{
$fahrenheit = ($celsius * 9 / 5) + 32; # ІлзШбЫШвм вХЬЯХаРвгаг
# ЯЮ иЪРЫХ ДРаХЭУХЩвР
print "$celsius C is $fahrenheit F.\n";
$celsius = $celsius + 5;
}
±ЫЮЪ ЪЮФР, ЭРеЮФпйШЩбп Т вХЫХ жШЪЫР while, ТлЯЮЫЭпХвбп ЬЭЮУЮЪаРвЭЮ, ЯЮЪР гбЫЮТШХ (Т ФРЭЭЮЬ бЫгзРХ — $celsius <= 45) ЮбвРХвбп ШбвШЭЭлЬ. µбЫШ бЮеаРЭШвм нвЮв даРУЬХЭв Т дРЩЫХ (ЭРЯаШЬХа, temps), ХУЮ ЬЮЦЭЮ ЧРЯгбвШвм ШЧ ЪЮЬРЭФЭЮЩ бваЮЪШ.
ІЮв ЪРЪ нвЮ ТлУЫпФШв:
% perl -w temps
20C is 68 F.
25 C is 77 F.
30 C is 86 F.
35 C is 95 F.
40 C is 104 F.
45 C is 113 F.
єЫоз -w<$M[R2-4]> ЭХ пТЫпХвбп ЮСпЧРвХЫмЭлЬ Ш ТЮЮСйХ ЭХ ЮвЭЮбШвбп Ъ аХУгЫпаЭлЬ ТлаРЦХЭШпЬ. ѕЭ ЯаШЪРЧлТРХв Perl ЯаЮТХаШвм ТРиг ЯаЮУаРЬЬг Ш ТлФРвм ЯаХФгЯаХЦФХЭШп ЯЮ вХЬ РбЯХЪвРЬ, ЪЮвЮалХ ТлУЫпФпв ЯЮФЮЧаШвХЫмЭЮ (ЭРЯаШЬХа, ШбЯЮЫмЧЮТРЭШХ ЭХШЭШжШРЫШЧШаЮТРЭЭле ЯХаХЬХЭЭле Ш в. Ф. — ЧРаРЭХХ ЮСкпТЫпвм ЯХаХЬХЭЭлХ Т Perl ЭХ ваХСгХвбп). П ШбЯЮЫмЧго ХУЮ ЫШим ЯЮвЮЬг, звЮ нвЮ аХЪЮЬХЭФгХвбп ФХЫРвм ТбХУФР.
І Perl бгйХбвТгХв ЭХбЪЮЫмЪЮ бЯЮбЮСЮТ ЯаШЬХЭХЭШп аХУгЫпаЭле ТлаРЦХЭШЩ. БРЬлЩ ЯаЮбвЮЩ ТРаШРЭв — ЯаЮТХаЪР бЮТЯРФХЭШп аХУгЫпаЭЮУЮ ТлаРЦХЭШп Т вХЪбвХ, еаРЭпйХЬбп Т ЯХаХЬХЭЭЮЩ. БЫХФгойШЩ даРУЬХЭв ЯаЮТХапХв бЮФХаЦШЬЮХ ЯХаХЬХЭЭЮЩ $reply Ш бЮЮСйРХв, бЮбвЮШв ЫШ ЮЭР ШЧ ЮФЭШе жШда:
if ($reply =~ m/^[0-9]+$/) {
print "only digits\n";
} else {
print "not only digits\n";
}
їХаТРп бваЮЪР ТлУЫпФШв ЭХЬЭЮУЮ бваРЭЭЮ. АХУгЫпаЭЮХ ТлаРЦХЭШХ бЮбвЮШв ШЧ бШЬТЮЫЮТ [^[0-9]+$], Р ЮЪагЦРойРп ЪЮЭбвагЪжШп m/…/ бЮЮСйРХв Perl, звЮ б нвШЬ ТлаРЦХЭШХЬ ЭгЦЭЮ бФХЫРвм. m ЮЧЭРзРХв ЯЮШбЪ бЮТЯРФХЭШп аХУгЫпаЭЮУЮ ТлаРЦХЭШп Т вХЪбвХ, Р бШЬТЮЫл / ЮЯаХФХЫпов УаРЭШжл аХУгЫпаЭЮУЮ ТлаРЦХЭШп. m~ бТпЧлТРХв m/…/ бЮ бваЮЪЮЩ, Т ЪЮвЮаЮЩ ЯаЮШбеЮФШв ЯЮШбЪ — Т ФРЭЭЮЬ бЫгзРХ б бЮФХаЦШЬлЬ ЯХаХЬХЭЭЮЩ $reply.
ЅХ ЯгвРЩвХ =~ б = ШЫШ ==. ѕЯХаРвЮа == ЯаЮТХапХв, аРТЭл ЫШ ФТР зШбЫР (ЪРЪ Тл ТбЪЮаХ гТШФШвХ, ЯаШ ЯаЮТХаЪХ аРТХЭбвТР ФТге бваЮЪ ЯаШЬХЭпХвбп ЮЯХаРвЮа eq). ѕЯХаРвЮа = ЯаШбТРШТРХв ЧЭРзХЭШХ ЯХаХЬХЭЭЮЩ — ЭРЯаШЬХа, $celsius = 20. ЅРЪЮЭХж, ЮЯХаРвЮа =~ бТпЧлТРХв ЪЮЬРЭФг ЯЮШбЪР бЮ бваЮЪЮЩ, Т ЪЮвЮаЮЩ СгФХв ЯаЮШбеЮФШвм ЯЮШбЪ (Т ФРЭЭЮЬ ЯаШЬХаХ ШбЯЮЫмЧЮТРЭР ЪЮЬРЭФР ЯЮШбЪР m/^[0-9]+$/, Р жХЫХТРп бваЮЪР еаРЭШвбп Т ЯХаХЬХЭЭЮЩ $reply). ѕЯХаРвЮа =~ ШЭЮУФР зШвРХвбп ЪРЪ «бЮЮвТХвбвТгХв», ЯЮнвЮЬг бваЮЪг
if ($reply =~ m/^[0-9]+$/){
ЬЮЦЭЮ ЯаЮзШвРвм вРЪ:
«µбЫШ вХЪбв, еаРЭпйШЩбп Т ЯХаХЬХЭЭЮЩ $reply, бЮЮвТХвбвТгХв аХУгЫпаЭЮЬг ТлаРЦХЭШо [^[0-9]+$], вЮ…
АХЧгЫмвРв ТлЯЮЫЭХЭШп ЪЮЬРЭФл $reply =~ m/^[0-9]+$/ аРТХЭ true, ХбЫШ [^[0-9]+$] бЮТЯРФРХв Т бваЮЪХ $reply, ШЫШ false Т ЯаЮвШТЭЮЬ бЫгзРХ. ЅР ЮбЭЮТРЭШШ нвЮУЮ ЧЭРзХЭШп ЪЮЬРЭФР if ТлСШаРХв ТлТЮФШЬЮХ бЮЮСйХЭШХ.
ѕСаРвШвХ ТЭШЬРЭШХ: аХЧгЫмвРв ЪЮЬРЭФл $reply =~ m/[0-9]+/ (вЮЩ ЦХ, звЮ Ш аРЭмиХ, ЭЮ СХЧ ЮУаРЭШзШТРойШе бШЬТЮЫЮТ ^ Ш $) аРТХЭ true, ХбЫШ $reply бЮФХаЦШв еЮвп Сл ЮФЭг жШдаг. [^…$] УРаРЭвШагХв, звЮ $reply бЮФХаЦШв вЮЫмЪЮ жШдал.
ґРТРЩвХ ЮСкХФШЭШЬ ФТР ЯаХФлФгйШе ЯаШЬХаР. јл ЯаХФЫЮЦШЬ ЯЮЫмЧЮТРвХЫо ТТХбвШ ЧЭРзХЭШХ Ш ЧРвХЬ ЯаЮТХаШЬ ХУЮ ЯаШ ЯЮЬЮйШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, звЮСл гСХФШвмбп Т вЮЬ, звЮ СлЫЮ ТТХФХЭЮ зШбЫЮ. µбЫШ ЯаЮТХаЪР ФРбв ЯЮЫЮЦШвХЫмЭлЩ аХЧгЫмвРв, Ьл ТлзШбЫпХЬ Ш ТлТЮФШЬ нЪТШТРЫХЭвЭго вХЬЯХаРвгаг ЯЮ иЪРЫХ ДРаХЭУХЩвР. І ЯаЮвШТЭЮЬ бЫгзРХ ТлТЮФШвбп ЯаХФгЯаХЦФРойХХ бЮЮСйХЭШХ:
print "Enter a temperature in Celsius:\n";
$celsius = <STDIN>; # їЮЫгзШвм ЮФЭг бваЮЪг Юв ЯЮЫмЧЮТРвХЫп
chop($celsius); # ГФРЫШвм ШЧ $celsius ЧРТХаиРойШЩ бШЬТЮЫ ЭЮТЮЩ бваЮЪШ
if ($celsius =~ m/^[0-9]+$/) {
$fahrenheit = ($celsius * 9 / 5) + 32; # ІлзШбЫШвм вХЬЯХаРвгаг
# ЯЮ иЪРЫХ ДРаХЭУХЩвР
print "$celsius C = $fahrenheit F\n";
} else {
print "Expecting a number, so don't understand \"$celsius\".\n";
}
ѕСаРвШвХ ТЭШЬРЭШХ ЭР ЯаХдШЪб \ ЯХаХФ ЪРТлзЪРЬШ Т ЧРТХаиРойХЩ ЪЮЬРЭФХ print. ·ФХбм ЮЭ ТлЯЮЫЭпХв вг ЦХ дгЭЪжШо, ЪРЪ Ш ЯХаХФ ЬХвРбШЬТЮЫРЬШ Т аХУгЫпаЭле ТлаРЦХЭШпе. І аРЧФХЫХ «јЭЮУЮЫШЪШХ ЬХвРбШЬТЮЫл» (бЬ. б. <$R[P#,R2-8]>) нвР вХЬР аРббЬРваШТРХвбп згвм ЯЮФаЮСЭХХ.
їаХФЯЮЫЮЦШЬ, ЯаЮУаРЬЬР еаРЭШвбп Т дРЩЫХ c2f. їаШ ЧРЯгбЪХ ЮЭР ТлТЮФШв бЫХФгойШЩ аХЧгЫмвРв:
% perl -w c2f
Enter a temperature in Celsius:
22
22 Б = 71.599999999999994316 F
ЗвЮ-вЮ ЭХЫРФЭЮ. ѕЪРЧлТРХвбп, ЯаЮбвРп ЪЮЬРЭФР print ЯЫЮеЮ ЯЮФеЮФШв ФЫп ТлТЮФР ТХйХбвТХЭЭле зШбХЫ. ЗвЮСл ЭХ гТпЧЭгвм Т вХеЭШзХбЪШе ФХвРЫпе Perl, п ЭХ бвРЭг ТФРТРвмбп Т ЯЮФаЮСЭлХ ЮСкпбЭХЭШп Ш ЯаЮбвЮ бЪРЦг, звЮ ФЫп гЫгзиХЭШп ТЭХиЭХУЮ ТШФР аХЧгЫмвРвР ЬЮЦЭЮ ТЮбЯЮЫмЧЮТРвмбп ЪЮЬРЭФЮЩ printf (РЭРЫЮУЮЬ ЪЮЬРЭФл printf пЧлЪР C ШЫШ ЪЮЬРЭФ format пЧлЪЮТ Pascal, Tcl, elisp Ш Python):
printf "%.2f C = %.2f F\n", $celsius, $fahrenheit;
єЮЬРЭФР ШЧЬХЭпХв ЭХ ЧЭРзХЭШп ЯХаХЬХЭЭле, Р ЫШим Ше ТЭХиЭШЩ ТШФ ЯаШ ТлТЮФХ. ВХЯХам аХЧгЫмвРв ТлУЫпФШв вРЪ:
Enter a temperature in Celsius:
22
22.00 Б = 71.60 F
БЬЮваШвбп УЮаРЧФЮ ЫгзиХ.
їЮЦРЫгЩ, ЭРи ЯаШЬХа СлЫЮ Сл ЭХЯЫЮеЮ гбЮТХаиХЭбвТЮТРвм, звЮСл ЮЭ ЯЮФФХаЦШТРЫ ЮваШжРвХЫмЭлХ Ш ФаЮСЭлХ ЧЭРзХЭШп вХЬЯХаРвгал. Б вЮзЪШ ЧаХЭШп ЬРвХЬРвШЪШ ЭШзХУЮ ЭХ ШЧЬХЭШвбп — ЮСлзЭЮ Perl ЭХ аРЧЫШзРХв жХЫлХ Ш ТХйХбвТХЭЭлХ зШбЫР. ВХЬ ЭХ ЬХЭХХ, Ьл ФЮЫЦЭл ЬЮФШдШжШаЮТРвм аХУгЫпаЭЮХ ТлаРЦХЭШХ, звЮСл ЮЭЮ аРЧаХиРЫЮ ТТЮФ ЮваШжРвХЫмЭле Ш ТХйХбвТХЭЭле ТХЫШзШЭ. ІбвРТЪР [-?] аРЧаХиШв ЭРЫШзШХ ЬШЭгбР Т ЭРзРЫХ ЮваШжРвХЫмЭЮУЮ зШбЫР. ° ХбЫШ бФХЫРвм ХйХ ЮФШЭ иРУ Ш ТбвРТШвм [[-+]?], Тл аРЧаХиШвХ Ш ЭРзРЫмЭлЩ ЯЫоб ФЫп ЯЮЫЮЦШвХЫмЭле зШбХЫ.
ЗвЮСл аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯЮФФХаЦШТРЫЮ ЭРЫШзШХ ЭХЮСпЧРвХЫмЭЮЩ ФаЮСЭЮЩ зРбвШ, Т ЭХУЮ ФЮСРТЫпХвбп [(\.[0-9]*)?]. єЮЬСШЭРжШп [\.] бЮТЯРФРХв б ЮСлзЭлЬ бШЬТЮЫЮЬ «вЮзЪР», ЯЮнвЮЬг ТлаРЦХЭШХ [\.[0-9]*] бЮТЯРФРХв б вЮзЪЮЩ, ЧР ЪЮвЮаЮЩ бЫХФгХв ЫоСЮХ ЪЮЫШзХбвТЮ ЭХЮСпЧРвХЫмЭле жШда. їЮбЪЮЫмЪг ЯЮФТлаРЦХЭШХ [\.[0-9]*] ЧРЪЫозРХвбп Т ЪЮЭбвагЪжШо [(…)?], ЮЭЮ ЪРЪ ХФШЭЮХ жХЫЮХ бвРЭЮТШвбп ЭХЮСпЧРвХЫмЭлЬ (Ш нвШЬ ЯаШЭжШЯШРЫмЭЮ ЮвЫШзРХвбп Юв ТлаРЦХЭШп [\.?[0-9]*], ФЮЯгбЪРойХУЮ бЮТЯРФХЭШХ ФЮЯЮЫЭШвХЫмЭле жШда ЯаШ ЮвбгвбвТШШ бЮТЯРФХЭШп [\.]).
ѕСкХФШЭпп ТбХ бЪРЧРЭЭЮХ, Ьл ЯЮЫгзРХЬ:
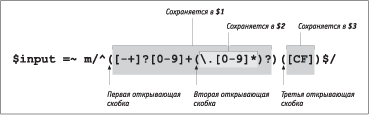
if ($celsius =~ m/^[-+]?[0-9]+(\.[0-9]*)?$/) {
єЮЬРЭФР ЯаЮЯгбЪРХв вРЪШХ зШбЫР, ЪРЪ 32, -3.723 Ш +98.6. І ФХЩбвТШвХЫмЭЮбвШ ЮЭР ЭХ ШФХРЫмЭР, ЯЮбЪЮЫмЪг ЭХ ЯЮФФХаЦШТРХв зШбХЫ, ЭРзШЭРойШебп б ФХбпвШзЭЮЩ вЮзЪШ (ЭРЯаШЬХа, .357). АРЧгЬХХвбп, ЯЮЫмЧЮТРвХЫм ЬЮЦХв ФЮСРТШвм ЭРзРЫмЭлЩ ЭЮЫм (вЮ Хбвм 0.357), ЯЮнвЮЬг ТапФ ЫШ нвЮ ЬЮЦЭЮ бзШвРвм ЪагЯЭлЬ ЭХФЮбвРвЪЮЬ. їаЮСЫХЬР ТХйХбвТХЭЭле зШбХЫ бвРТШв апФ ШЭвХаХбЭле ЧРФРз, ЯЮФаЮСЭЮ аРббЬРваШТРХЬле Т УЫРТХ 4 (бЬ. б. <$R[P#,R4-32]>).
ґРТРЩвХ аРбиШаШЬ ЭРи ЯаШЬХа, звЮСл ЯЮЫмЧЮТРвХЫм ЬЮУ ТТЮФШвм вХЬЯХаРвгаг ЪРЪ ЯЮ ЖХЫмбШо, вРЪ Ш ЯЮ ДРаХЭУХЩвг. І ЧРТШбШЬЮбвШ Юв ТлСаРЭЭЮЩ иЪРЫл Ъ ТТХФХЭЭЮЬг ЧЭРзХЭШо ЯаШбЮХФШЭпХвбп бгддШЪб C ШЫШ F. ЗвЮСл бгддШЪб ЯаЮиХЫ зХаХЧ аХУгЫпаЭЮХ ТлаРЦХЭШХ, ЯЮбЫХ ТлаРЦХЭШп ФЫп зШбЫР ЯаЮбвЮ ФЮСРТЫпХвбп [[CF]]. ѕФЭРЪЮ Ьл ФЮЫЦЭл ШЧЬХЭШвм бРЬг ЯаЮУаРЬЬг вРЪ, звЮСл ЮЭР ЮЯаХФХЫпЫР иЪРЫг ТТХФХЭЭЮЩ вХЬЯХаРвгал Ш ТлзШбЫпЫР ЧЭРзХЭШХ ЯЮ ФагУЮЩ иЪРЫХ.
І Perl, Т ЮвЫШзШХ Юв ЬЭЮУШе пЧлЪЮТ б ЯЮФФХаЦЪЮЩ аХУгЫпаЭле ТлаРЦХЭШЩ, бгйХбвТгХв ЭРСЮа ЯЮЫХЧЭле бЯХжШРЫмЭле ЯХаХЬХЭЭле ФЫп бблЫЮЪ ЭР вХЪбв, бЮТЯРТиШЩ б ЯЮФТлаРЦХЭШпЬШ Т ЪагУЫле бЪЮСЪРе. І ЯХаТЮЩ УЫРТХ УЮТЮаШЫЮбм Ю вЮЬ, звЮ ЭХЪЮвЮалХ ТХабШШ egrep ЯЮФФХаЦШТРов ЬХвРбШЬТЮЫл [\1], [\2], [\3] ЭР гаЮТЭХ бРЬШе аХУгЫпаЭле ТлаРЦХЭШЩ. Perl вРЪЦХ ЯЮФФХаЦШТРХв нвШ ЬХвРбШЬТЮЫл Ш ФЮСРТЫпХв Ъ ЭШЬ ЯХаХЬХЭЭлХ, ЪЮвЮалХ ЬЮУгв ШбЯЮЫмЧЮТРвмбп ЧР ЯаХФХЫРЬШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп ЯЮбЫХ ТлЯЮЫЭХЭШп ЯЮШбЪР. НвШЬ ЯХаХЬХЭЭлЬ Perl ЯаШбТРШТРовбп ШЬХЭР $1, $2, $3 Ш в. Ф. ЕЮвп ЭР ЯХаТлЩ ТЧУЫпФ ЮЭШ ТлУЫпФпв ЭХЬЭЮУЮ бваРЭЭЮ, нвЮ ФХЩбвТШвХЫмЭЮ ЯХаХЬХЭЭлХ. їаЮбвЮ ШЬХЭР ЯХаХЬХЭЭле ЯаХФбвРТЫпов бЮСЮЩ зШбЫР. Perl ЯаШбТРШТРХв ШЬ ЧЭРзХЭШп ЯаШ ЪРЦФЮЬ гбЯХиЭЮЬ бЮТЯРФХЭШШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп. ЅР ТбпЪШЩ бЫгзРЩ ЯЮТвЮао: ЬХвРбШЬТЮЫ [\1] ШбЯЮЫмЧгХвбп Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ ФЫп бблЫЪШ ЭР вХЪбв, бЮТЯРТиШЩ аРЭХХ Т еЮФХ вХЪгйХЩ ЯЮЯлвЪШ ЭРЩвШ бЮТЯРФХЭШХ, Р ЯХаХЬХЭЭРп $1 ЬЮЦХв ШбЯЮЫмЧЮТРвмбп Т ЯаЮУаРЬЬХ ФЫп бблЫЪШ ЭР нвЮв вХЪбв ЯЮбЫХ гбЯХиЭЮУЮ бЮТЯРФХЭШп.
ЗвЮСл ЭХ ЧРУаЮЬЮЦФРвм ЯаШЬХа Ш бЮбаХФЮвЮзШвмбп ЭР ЭЮТле РбЯХЪвРе, п ТаХЬХЭЭЮ гФРЫо ЯЮФТлаРЦХЭШХ ФЫп ШФХЭвШдШЪРжШШ ФаЮСЭЮЩ зРбвШ, ЭЮ Ьл Ъ ЭХЬг ХйХ ТХаЭХЬбп. ёвРЪ, звЮСл гТШФХвм ЯХаХЬХЭЭго $1 Т ФХЩбвТШШ, баРТЭШвХ:
$celsius =~ m/^[-+]?[0-9]+[CF]$/
$celsius =~ m/^([-+]?[0-9]+)([CF])$/
ёЧЬХЭпов ЫШ ЭЮТлХ ЪагУЫлХ бЪЮСЪШ ЮСйШЩ бЬлбЫ ТлаРЦХЭШп? ЗвЮСл ЮвТХвШвм ЭР нвЮв ТЮЯаЮб, Ьл ФЮЫЦЭл ЧЭРвм:
l ѕСХбЯХзШТРов ЫШ ЮЭШ УагЯЯШаЮТЪг бШЬТЮЫЮТ ФЫп * ШЫШ ФагУШе ЪТРЭвШдШЪРвЮаЮТ?
l ѕУаРЭШзШТРов ЫШ ЮЭШ ЪЮЭбвагЪжШо [|]?
АШб. 2.1. БЮеаРЭХЭШХ вХЪбвР Т ЪагУЫле бЪЮСЪРе
ЅР ЮСР ТЮЯаЮбР ЮвТХв ЮваШжРвХЫмЭлЩ, ЯЮнвЮЬг бЮТЯРФХЭШХ ТбХУЮ ТлаРЦХЭШп ЮбвРХвбп ЭХШЧЬХЭЭлЬ. ѕФЭРЪЮ бЪЮСЪШ ЧРЪЫозРов ФТР ЯЮФТлаРЦХЭШп, бЮТЯРФРойШХ б «ШЭвХаХбЭлЬШ» зРбвпЬШ ЯаЮТХапХЬЮЩ бваЮЪШ. єРЪ ТШФЭЮ ШЧ аШб. 2.1, Т $1 бЮеаРЭпХвбп ТТХФХЭЭЮХ зШбЫЮ, Р Т $2 — бгддШЪб (C ШЫШ F). ёЧ СЫЮЪ-беХЬл ЭР аШб. 2.2 ТШФЭЮ, звЮ нвЮ ЯЮЧТЮЫпХв ЭРЬ ЫХУЪЮ ТлСаРвм ФРЫмЭХЩиШХ ФХЩбвТШп ЯЮбЫХ ЯаШЬХЭХЭШп аХУгЫпаЭЮУЮ ТлаРЦХЭШп.
µбЫШ ЯаЮУаРЬЬР, ЯаШТХФХЭЭРп ЭШЦХ, ЭРеЮФШвбп Т дРЩЫХ convert, вЮ ЯаШЬХа ХХ ШбЯЮЫмЧЮТРЭШп ЬЮЦХв ТлУЫпФХвм вРЪ:
% perl -w convert
Enter a temperature (i.e. 32F, 100C):
39F
3.89 C = 39.00 F
% perl -w convert
Enter a temperature (i.e. 32F, 100C):
39C
39.00 C = 102.20 F
% perl -w convert
Enter a temperature (i.e. 32F, 100C):
oops
3.89 C = 39.00 F
Expecting a number, so don't understand "oops".
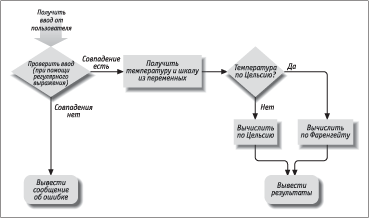
АШб. 2.2. ±ЫЮЪ-беХЬР ЯаЮУаРЬЬл ЯаХЮСаРЧЮТРЭШп вХЬЯХаРвга
print "Enter a temperature (i.e. 32F, 100C):\n";
$input = <STDIN>; # їЮЫгзШвм ЮФЭг бваЮЪг Юв ЯЮЫмЧЮТРвХЫп
chop($input); # ГФРЫШвм ШЧ $input ЧРТХаиРойШЩ бШЬТЮЫ ЭЮТЮЩ бваЮЪШ
if ($input =~ m/^([-+]?[0-9]+)([CF])$/)
{
# ѕСЭРагЦХЭЮ бЮТЯРФХЭШХ. $1 бЮФХаЦШв зШбЫЮ, $2 - бШЬТЮЫ "C" ШЫШ "F"
$InputNum = $1; # бЮеаРЭШвм Т ШЬХЭЮТРЭЭле ЯХаХЬХЭЭле,
$type = $2; # звЮСл ЯаЮУаРЬЬг СлЫЮ ЫХУзХ зШвРвм
if ($type eq "C") { # 'eq' ЯаЮТХапХв аРТХЭбвТЮ ФТге бваЮЪ
# ВХЬЯХаРвгаР ТТХФХЭР ЯЮ ЖХЫмбШо, ТлзШбЫШвм ЯЮ ДРаХЭУХЩвг
$celsius = $InputNum;
$fahrenheit = ($celsius * 9 / 5) + 32;
} else {
# ІШФШЬЮ, вХЬЯХаРвгаР ТТХФХЭР ЯЮ ДРаХЭУХЩвг.
# ІлзШбЫШвм ЯЮ ЖХЫмбШо.
$fahrenheit = $InputNum;
$celsius = ($fahrenheit * 9 / 5) + 32;
}
# ёЧТХбвЭл ЮСХ вХЬЯХаРвгал, ЯХаХеЮФШЬ Ъ ТлТЮФг аХЧгЫмвРвЮТ
printf “%.2Р Б = %.2f F\n”, ;celsius, ;faahrenheit;
} else {
# АХУгЫпаЭЮХ ТлаРЦХЭШХ ЭХ бЮТЯРЫЮ, ТлТХбвШ ЯаХФгЯаХЦФХЭШХ.
print "Expecting a number, so don't understand \"$input\".\n";
}
БвагЪвгаР ЭРиХЩ ЯаЮУаРЬЬл ТлУЫпФШв вРЪ:
if (ЯаЮТХаЪР гбЫЮТШп) {
.
.
.
… ±ѕ»МИѕ№ ±»ѕє, ХбЫШ аХЧгЫмвРв ЯаЮТХаЪШ СлЫ ШбвШЭЭлЬ…
.
.
.
} else {
… БЮТбХЬ ЬРЫХЭмЪШЩ СЫЮЪ, ХбЫШ аХЧгЫмвРв СлЫ ЫЮЦЭлЬ.
}
»оСЮЩ бвгФХЭв, ШЧгзРойШЩ бвагЪвгаЭЮХ ЯаЮУаРЬЬШаЮТРЭШХ, ЧЭРХв (ШЫШ ФЮЫЦХЭ ЧЭРвм): ХбЫШ ЪЮЬРЭФР if бЮбвЮШв ШЧ ФТге ТХвТХЩ, ЪЮаЮвЪЮЩ Ш ФЫШЭЭЮЩ, ЯЮ ТЮЧЬЮЦЭЮбвШ ЦХЫРвХЫмЭЮ ЭРзРвм б ЪЮаЮвЪЮЩ ТХвТШ. їаШ нвЮЬ else аРбЯЮЫРУРХвбп СЫШЦХ Ъ if, звЮ гЯаЮйРХв звХЭШХ ЯаЮУаРЬЬл.
І ЭРиХЩ ЯаЮУаРЬЬХ ФЫп нвЮУЮ ЯаШФХвбп ЧРЬХЭШвм ЯаЮТХапХЬЮХ гбЫЮТШХ ЯаЮвШТЮЯЮЫЮЦЭлЬ. єЮаЮвЪЮЩ ТХвТмо пТЫпХвбп «ЮвбгвбвТШХ бЮТЯРФХЭШп», ЯЮнвЮЬг гбЫЮТШХ ФЮЫЦЭЮ Слвм ШбвШЭЭлЬ ЯаШ ЮвбгвбвТШШ бЮТЯРФХЭШп. ѕФЭЮ ШЧ ТЮЧЬЮЦЭле аХиХЭШЩ ЧРЪЫозРХвбп Т ЧРЬХЭХ ЮЯХаРвЮаР =~ ЮЯХаРвЮаЮЬ !~:
$input !~ m/^([-+]?[0-9]+)([CF])$/
АХУгЫпаЭЮХ ТлаРЦХЭШХ Ш ЯаЮТХапХЬРп бваЮЪР ЮбвРовбп СХЧ ШЧЬХЭХЭШЩ. µФШЭбвТХЭЭЮХ ЮвЫШзШХ ЧРЪЫозРХвбп Т вЮЬ, звЮ аХЧгЫмвРв ТбХЩ ЪЮЬСШЭРжШШ аРТХЭ false, ХбЫШ аХУгЫпаЭЮХ ТлаРЦХЭШХ бЮТЯРФРХв Т бваЮЪХ, Ш true Т ЮСаРвЭЮЬ бЫгзРХ. їаШ бЮТЯРФХЭШШ ЯХаХЬХЭЭлЬ $1, $2 Ш в. Ф. ЯЮ-ЯаХЦЭХЬг ЯаШбТРШТРовбп ЧЭРзХЭШп. БЫХФЮТРвХЫмЭЮ, нвР зРбвм ЯаЮУаРЬЬл ЯаШЭШЬРХв бЫХФгойШЩ ТШФ:
if ($input !~ m/^([-+]?[0-9]+)([CF])$/) {
print "Expecting a number, so don't understand \"$input\".\n";
} else {
# ѕСЭРагЦХЭЮ бЮТЯРФХЭШХ. $1 бЮФХаЦШв зШбЫЮ, $2 - бШЬТЮЫ "C" ШЫШ "F"
.
.
.
}
І вРЪШе ЭХваШТШРЫмЭле пЧлЪРе ЯаЮУаРЬЬШаЮТРЭШп, ЪРЪ Perl, ЯаШЬХЭХЭШХ аХУгЫпаЭле ТлаРЦХЭШЩ ЬЮЦХв ЯХаХЯЫХвРвмбп б ЫЮУШЪЮЩ бРЬЮЩ ЯаЮУаРЬЬл. ґРТРЩвХ ТЭХбХЬ Т ЭРиг ЯаЮУаРЬЬг ваШ ЯЮЫХЧЭле ШЧЬХЭХЭШп: ЮСХбЯХзШЬ ЯЮФФХаЦЪг ТХйХбвТХЭЭле зШбХЫ, ЪРЪ нвЮ СлЫЮ бФХЫРЭЮ аРЭХХ, ЯЮФФХаЦШЬ ТТЮФ бгддШЪбЮТ f Ш c Т ЭШЦЭХЬ аХУШбваХ Ш аРЧаХиШЬ, звЮСл зШбЫЮ ЮвФХЫпЫЮбм Юв СгЪТл ЯаЮСХЫРЬШ. їЮбЫХ ТЭХбХЭШп ТбХе ШЧЬХЭХЭШЩ ЬЮЦЭЮ СгФХв ТТЮФШвм ФРЭЭлХ ТШФР 98.6spcf.
Іл гЦХ ЧЭРХвХ, ЪРЪ ЮСХбЯХзШвм ТЮЧЬЮЦЭЮбвм ТТЮФР ТХйХбвТХЭЭле зШбХЫ — ФЫп нвЮУЮ Т ТлаРЦХЭШХ ТЪЫозРХвбп ЪЮЭбвагЪжШп [(\.[0-9]*)?]:
if ($input =~ m/^([-+]?[0-9]+(\.[0-9]*)?)([CF])$/)
ѕСаРвШвХ ТЭШЬРЭШХ: ТбвРТЪР ЯаЮШбеЮФШв ТЭгваШ ЯХаТЮЩ ЯРал ЪагУЫле бЪЮСЮЪ. їЮбЪЮЫмЪг ЯХаТлХ бЪЮСЪШ ШбЯЮЫмЧговбп ФЫп бЮеаРЭХЭШп зШбЫР, Т ЭШе вРЪЦХ ФЮЫЦЭР Слвм ТЪЫозХЭР ХУЮ ФаЮСЭРп зРбвм. ѕФЭРЪЮ ЯЮпТЫХЭШХ ЭЮТЮЩ ЯРал ЪагУЫле бЪЮСЮЪ, Ягбвм ФРЦХ ЯаХФЭРЧЭРзХЭЭле вЮЫмЪЮ ФЫп ЯаШЬХЭХЭШп ЪТРЭвШдШЪРвЮаР, ЯаШТЮФШв Ъ ЯЮСЮзЭЮЬг нддХЪвг — бЮФХаЦШЬЮХ нвШе бЪЮСЮЪ вРЪЦХ бЮеаРЭпХвбп Т ЯХаХЬХЭЭЮЩ. їЮбЪЮЫмЪг ЮвЪалТРойРп бЪЮСЪР пТЫпХвбп ТвЮаЮЩ бЫХТР Т ТлаРЦХЭШШ, ФаЮСЭРп зРбвм зШбЫР бЮеаРЭпХвбп Т $2. БЪРЧРЭЭЮХ ЯЮпбЭпХв аШб. 2.3.
АШб. 2.3. ІЫЮЦХЭЭлХ ЪагУЫлХ бЪЮСЪШ
їЮпТЫХЭШХ ЭЮТле ЪагУЫле бЪЮСЮЪ Т ЯаХФиХбвТгойХЩ зРбвШ ТлаРЦХЭШп ЭХ ШЧЬХЭпХв бЬлбЫР ТлаРЦХЭШп [[CF]] ЭРЯапЬго, ЭЮ ЮваРЦРХвбп ЭР ЭХЬ ЪЮбТХЭЭЮ. ґХЫЮ Т вЮЬ, звЮ ЪагУЫлХ бЪЮСЪШ, Т ЪЮвЮалХ ЧРЪЫозХЭЮ нвЮ ЯЮФТлаРЦХЭШХ, бвРЭЮТпвбп ваХвмХЩ ЯРаЮЩ, Р нвЮ ЮЧЭРзРХв, звЮ Т ЯаШбТРШТРЭШШ $type ЭХЮСеЮФШЬЮ гЪРЧРвм $3 ТЬХбвЮ $2.
їаЮСХЫл ЬХЦФг зШбЫЮЬ Ш бгддШЪбЮЬ ТлЧлТРов ЬХЭмиХ ЯаЮСЫХЬ. јл ЧЭРХЬ, звЮ ЮСлзЭлЩ ЯаЮСХЫ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ бЮЮвТХвбвТгХв аЮТЭЮ ЮФЭЮЬг ЯаЮСХЫг Т вХЪбвХ, ЯЮнвЮЬг ШбЯЮЫмЧгХЬ [spc*], звЮСл аРЧаХиШвм ЫоСЮХ ЪЮЫШзХбвТЮ ЯаЮСХЫЮТ (ЭШ ЮФШЭ ШЧ ЪЮвЮале ЭХ пТЫпХвбп ЮСпЧРвХЫмЭлЬ):
if ($input =~ m/^([-+]?[0-9]+(\.[0-9]*)?) *([CF])$/)
ВРЪЮХ аХиХЭШХ ЮСХбЯХзШТРХв ЮЯаХФХЫХЭЭго УШСЪЮбвм, ЭЮ аРЧ гЦ Ьл бваХЬШЬбп бЮЧФРвм ЯаШЬХа, ЯаШУЮФЭлЩ ФЫп ЯаРЪвШзХбЪЮУЮ ШбЯЮЫмЧЮТРЭШп, ФРТРЩвХ ТЪЫозШЬ Т аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯЮФФХаЦЪг ФагУШе аРЧЭЮТШФЭЮбвХЩ ЯаЮЯгбЪЮТ. ѕФЭЮЩ ШЧ аРбЯаЮбваРЭХЭЭле аРЧЭЮТШФЭЮбвХЩ ЯаЮЯгбЪЮТ пТЫповбп бШЬТЮЫл вРСгЫпжШШ. єЮЭХзЭЮ, ЪЮЭбвагЪжШп [tab*] ЭХ ЯЮЧТЮЫШв ШбЯЮЫмЧЮТРвм ЯаЮСХЫл, ЯЮнвЮЬг Ьл ФЮЫЦЭл бЪЮЭбвагШаЮТРвм бШЬТЮЫмЭлЩ ЪЫРбб ФЫп ЮСЮШе аРЧЭЮТШФЭЮбвХЩ ЯаЮЯгбЪЮТ: [[spctab]*]. єбвРвШ, зХЬ нвЮ ТлаРЦХЭШХ ЯаШЭжШЯШРЫмЭЮ ЮвЫШзРХвбп Юв [[spc*|tab*]]? ref<$M[R2-1]>їЮФгЬРЩвХ ЭРФ нвШЬ ТЮЯаЮбЮЬ, ЧРвХЬ ЯХаХТХаЭШвХ бваРЭШжг Ш ЯаЮТХамвХ бТЮЩ ЮвТХв.
І нвЮЩ ЪЭШУХ ЯаЮСХЫл Ш вРСгЫпжШШ ЫХУЪЮ аРЧЫШзРовбп СЫРУЮФРап ШбЯЮЫмЧЮТРЭЭлЬ ЬЭЮо ЮСЮЧЭРзХЭШпЬ spc Ш tab. є бЮЦРЫХЭШо, ЭР нЪаРЭХ аРЧЫШзШвм Ше бЫЮЦЭХХ. µбЫШ Тл гТШФШвХ звЮ-ЭШСгФм ТаЮФХ [ ]*, ЫЮУШзЭЮ ЯаХФЯЮЫЮЦШвм, звЮ нвЮ ЯаЮСХЫ Ш бШЬТЮЫ вРСгЫпжШШ, ЭЮ ЯЮЫЭЮбвмо гТХаХЭЭлЬ Т нвЮЬ Слвм ЭХЫмЧп. ґЫп гФЮСбвТР Т аХУгЫпаЭле ТлаРЦХЭШпе Perl бгйХбвТгХв ЬХвРбШЬТЮЫ [\t]. ѕЭ ЯаЮбвЮ бЮТЯРФРХв б бШЬТЮЫЮЬ вРСгЫпжШШ — ХФШЭбвТХЭЭлЬ ЯаХШЬгйХбвТЮЬ нвЮУЮ бШЬТЮЫР ЯХаХФ ЫШвХаРЫЮЬ пТЫпХвбп ХУЮ ТШЧгРЫмЭРп ЭРУЫпФЭЮбвм, Ш п зРбвЮ ШбЯЮЫмЧго ХУЮ Т бТЮШе ТлаРЦХЭШпе. ВРЪШЬ ЮСаРЧЮЬ, [[spctab]*] ЯаХТаРйРХвбп Т [[spc\t]*].
БгйХбвТгов Ш ФагУШХ ТбЯЮЬЮУРвХЫмЭлХ ЬХвРбШЬТЮЫл — [\n] (ЭЮТРп бваЮЪР), [\f] (ЯЮФРзР ЫШбвР) Ш [\b] (ЧРСЮЩ). їЮбвЮЩвХ-ЪР! ІХФм аРЭмиХ п УЮТЮаШЫ, звЮ [\b] ЮЧЭРзРХв УаРЭШжг бЫЮТР. ВРЪ ЪРЪЮХ ЦХ ШЧ ФТге ЧЭРзХЭШЩ бЮЮвТХвбвТгХв бШЬТЮЫг? єРЪ ЭШ бваРЭЭЮ, ЮСР!
<$M[R2-8]>БШЬТЮЫ \n гЦХ ТбваХзРЫбп ЭРЬ Т ЯаХФлФгйШе ЯаШЬХаРе, ЮФЭРЪЮ ЮЭ ЭРеЮФШЫбп ТЭгваШ бваЮЪШ, Р ЭХ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ. БваЮЪШ Perl ЮСЫРФРов бЮСбвТХЭЭлЬШ ЬХвРбШЬТЮЫРЬШ, ЪЮвЮалХ ЭХ ШЬХов ЭШзХУЮ ЮСйХУЮ б ЬХвРбШЬТЮЫРЬШ аХУгЫпаЭле ТлаРЦХЭШЩ. їаЮУаРЬЬШбвл-ЭЮТШзЪШ ЮзХЭм зРбвЮ ЯгвРов Ше.
ѕФЭРЪЮ ТлпбЭпХвбп, звЮ ЭХЪЮвЮалХ бваЮЪЮТлХ ЬХвРбШЬТЮЫл ЮзХЭм ЯЮеЮЦШ ЭР РЭРЫЮУШзЭлХ ЬХвРбШЬТЮЫл аХУгЫпаЭле ТлаРЦХЭШЩ. ЅРЯаШЬХа, ЯаШ ЯЮЬЮйШ бваЮЪЮТЮУЮ ЬХвРбШЬТЮЫР \t ЬЮЦЭЮ ТбвРТШвм бШЬТЮЫ вРСгЫпжШШ Т бваЮЪг, Р ЯаШ ЯЮЬЮйШ ЬХвРбШЬТЮЫР аХУгЫпаЭле ТлаРЦХЭШЩ [\t] Т ТлаРЦХЭШХ ТбвРТЫпХвбп нЫХЬХЭв, бЮТЯРФРойШЩ б бШЬТЮЫЮЬ вРСгЫпжШШ.
ВРЪЮХ беЮФбвТЮ гФЮСЭЮ, ЭЮ ЬЭХ ФРЦХ вагФЭЮ ЮСкпбЭШвм, ЪРЪ ТРЦЭЮ ЮвЫШзРвм аРЧЭлХ вШЯл ЬХвРбШЬТЮЫЮТ. І ЯаЮбвХЩиШе бЫгзРпе ТаЮФХ \t нвЮ ЪРЦХвбп ЭХбгйХбвТХЭЭлЬ, ЭЮ, ЪРЪ СгФХв ЯЮЪРЧРЭЮ ЯаШ ЮЯШбРЭШШ аРЧЫШзЭле пЧлЪЮТ Ш ЯаЮУаРЬЬ, гЬХЭШХ аРЧЫШзРвм ЬХвРбШЬТЮЫл, ШбЯЮЫмЧгХЬлХ Т ЪРЦФЮЩ бШвгРжШШ, ШУаРХв ЮзХЭм ТРЦЭго аЮЫм.
ЅР бРЬЮЬ ФХЫХ Ьл гЦХ ТбваХзРЫШбм б ЭХбЪЮЫмЪШЬШ бЫгзРпЬШ ЪЮЭдЫШЪвЮТ ЬХвРбШЬТЮЫЮТ. І УЫРТХ 1 ЯаШ аРСЮвХ б egrep аХУгЫпаЭлХ ТлаРЦХЭШп ЮСлзЭЮ ЧРЪЫозРЫШбм Т РЯЮбваЮдл. ІбХ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯХаХФРХвбп Т ЯаШУЫРиХЭШШ ЪЮЬРЭФЭЮЩ бваЮЪШ, Ш ШЭвХаЯаХвРвЮа аРбЯЮЧЭРХв ЭХЪЮвЮалХ ШЧ бТЮШе ЬХвРбШЬТЮЫЮТ. ЅРЯаШЬХа, ФЫп ЭХУЮ ЯаЮСХЫ пТЫпХвбп ЬХвРбШЬТЮЫЮЬ, ЮвФХЫпойШЬ ЪЮЬРЭФг Юв РаУгЬХЭвЮТ, Р РаУгЬХЭвл — ФагУ Юв ФагУР. ІЮ ЬЭЮУШе ШЭвХаЯаХвРвЮаРе РЯЮбваЮдл пТЫповбп ЬХвРбШЬТЮЫРЬШ, ЪЮвЮалХ бЮЮСйРов ШЭвХаЯаХвРвЮаг Ю вЮЬ, звЮ Т ЧРЪЫозХЭЭЮЬ ЬХЦФг ЭШЬШ вХЪбвХ ЭХ бЫХФгХв аРбЯЮЧЭРТРвм ФагУШХ ЬХвРбШЬТЮЫл (Т DOS ФЫп нвЮЩ жХЫШ ШбЯЮЫмЧговбп ЪРТлзЪШ).
°ЯЮбваЮдл ЯЮЧТЮЫпов ТЪЫозРвм Т аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯаЮСХЫл. ±ХЧ РЯЮбваЮдЮТ ЪЮЬРЭФЭлЩ ШЭвХаЯаХвРвЮа бРЬЮбвЮпвХЫмЭЮ ШЭвХаЯаХвШагХв ЯаЮСХЫл ТЬХбвЮ вЮУЮ, звЮСл ЯаХФЮбвРТШвм egrep ТЮЧЬЮЦЭЮбвм ШЭвХаЯаХвШаЮТРвм Ше ЯЮ-бТЮХЬг. ІЮ ЬЭЮУШе ЪЮЬРЭФЭле ШЭвХаЯаХвРвЮаРе вРЪЦХ ШбЯЮЫмЧговбп ЬХвРбШЬТЮЫл $, *, ? Ш в. Ф., зРбвЮ ТбваХзРойШХбп Т аХУгЫпаЭле ТлаРЦХЭШпе.
ІХбм нвЮв аРЧУЮТЮа Ю ЬХвРбШЬТЮЫРе ЪЮЬРЭФЭЮУЮ ШЭвХаЯаХвРвЮаР Ш бваЮЪЮТле ЬХвРбШЬТЮЫРе Perl ЭХ ШЬХХв ЯапЬЮУЮ ЮвЭЮиХЭШп Ъ аХУгЫпаЭлЬ ТлаРЦХЭШпЬ, ЭЮ ЭХЯЮбаХФбвТХЭЭЮ бТпЧРЭ б ЯаШЬХЭХЭШХЬ аХУгЫпаЭле ТлаРЦХЭШЩ Т аХРЫмЭле бШвгРжШпе. І нвЮЩ ЪЭШУХ ЭРЬ ТбваХвпвбп ЬЭЮУЮзШбЫХЭЭлХ Ш ЯЮаЮЩ ФЮТЮЫмЭЮ бЫЮЦЭлХ бШвгРжШШ, Т ЪЮвЮале ШбЯЮЫмЧгХвбп ЬЭЮУЮгаЮТЭХТЮХ ТЧРШЬЮФХЩбвТШХ ЬХвРбШЬТЮЫЮТ.
ВРЪ ЪРЪ ЦХ ЭРбзХв [\b]? І Perl нвЮв ЬХвРбШЬТЮЫ ЮСлзЭЮ бЮТЯРФРХв б УаРЭШжХЩ бЫЮТР, ЭЮ Т бШЬТЮЫмЭЮЬ ЪЫРббХ ХЬг бЮЮвТХвбвТгХв бШЬТЮЫ «ЧРСЮЩ». іаРЭШжР бЫЮТР Т бШЬТЮЫмЭЮЬ ЪЫРббХ ЭХ ШЬХХв бЬлбЫР, ЯЮнвЮЬг Perl ШЬХХв ЯЮЫЭЮХ ЯаРТЮ ЯаШбТЮШвм нвЮЬг ЬХвРбШЬТЮЫг ЪРЪЮЩ-вЮ ФагУЮЩ бЬлбЫ. їаХФгЯаХЦФХЭШХ ШЧ УЫРТл 1 Ю вЮЬ, звЮ «бгСпЧлЪ» бШЬТЮЫмЭле ЪЫРббЮТ ЮвЫШзРХвбп Юв ЮбЭЮТЭЮУЮ пЧлЪР аХУгЫпаЭле ТлаРЦХЭШЩ, ЭХбЮЬЭХЭЭЮ, ЮвЭЮбШвбп Ш Ъ Perl (Р вРЪЦХ ЫоСЮЬг ФагУЮЬг ФШРЫХЪвг аХУгЫпаЭле ТлаРЦХЭШЩ).
зХЬ [[spctab]*] ЮвЫШзРХвбп Юв [[spc*|tab*]]?
bref ѕвТХв ЭР ТЮЯаЮб бЮ б. <$R[P#,R2-1]>
ІлаРЦХЭШХ [(spc*|tab*)] бЮТЯРФРХв ЫШСЮ б [[spc*], ЫШСЮ б [tab*]. ёЭРзХ УЮТЮап, Т вХЪбвХ ФЮЫЦЭл бвЮпвм ЫШСЮ ЯаЮСХЫл (ШЫШ ЭШзХУЮ), ЫШСЮ бШЬТЮЫл вРСгЫпжШШ (ШЫШ ЭШзХУЮ). ѕФЭРЪЮ нвЮ ТлаРЦХЭШХ ЭХ ЯЮЧТЮЫпХв ЪЮЬСШЭШаЮТРвм ЯаЮСХЫл б бШЬТЮЫРЬШ вРСгЫпжШШ.
[[spctab]*] ЮЧЭРзРХв [[spctab]], ЯЮТвЮаХЭЭЮХ ЫоСЮХ ЪЮЫШзХбвТЮ аРЧ. І бваЮЪХ «tabspcspc» ЮЭЮ бЮТЯРФРХв ваШЦФл — бЭРзРЫР б бШЬТЮЫЮЬ вРСгЫпжШШ, Р ЧРвХЬ б ЯаЮСХЫРЬШ.
ІлаРЦХЭШХ [[spctab]*]] ЫЮУШзХбЪШ нЪТШТРЫХЭвЭЮ [(spc|tab)*], еЮвп ЯЮ ЯаШзШЭРЬ, ЮСкпбЭХЭЭлЬ Т УЫРТХ 4, бШЬТЮЫмЭлЩ ЪЫРбб зРбвЮ аРСЮвРХв СЮЫХХ нддХЪвШТЭЮ.
їаШ аРббЬЮваХЭШШ ЯаЮЯгбЪЮТ Ьл ЮбвРЭЮТШЫШбм ЭР аХУгЫпаЭЮЬ ТлаРЦХЭШШ [[spc\t]*]. НвЮ ЭХЯЫЮеЮ, ЮФЭРЪЮ Т аХУгЫпаЭле ТлаРЦХЭШпе Perl бЭЮТР ЭРеЮФШвбп гФЮСЭРп бЮЪаРйХЭЭРп ЧРЯШбм. І ЮвЫШзШХ Юв ЬХвРбШЬТЮЫР [\t], ЪЮвЮалЩ ЯаЮбвЮ ЯаХФбвРТЫпХв ЫШвХаРЫ-вРСгЫпжШо, ЬХвРбШЬТЮЫ [\s] ЮСХбЯХзШТРХв бЮЪаРйХЭЭго ЧРЯШбм ФЫп жХЫЮУЮ бШЬТЮЫмЭЮУЮ ЪЫРббР, ЮЧЭРзРойХУЮ «ЫоСЮЩ ЯаЮЯгбЪ». є нвЮЬг ЯЮЭпвШо ЮвЭЮбпвбп ЯаЮСХЫл, вРСгЫпжШШ, бШЬТЮЫл ЭЮТЮЩ бваЮЪШ Ш ТЮЧТаРвР ЪгабЮаР. І ЭРиХЬ ЯаШЬХаХ бШЬТЮЫл ЭЮТЮЩ бваЮЪШ Ш ТЮЧТаРвР ЪгабЮаР ЭХ ШбЯЮЫмЧговбп, ЮФЭРЪЮ ТТЮФШвм ТлаРЦХЭШХ [\s*] гФЮСЭХХ, зХЬ [[spc\t]*]. ІбЪЮаХ Тл ЯаШТлЪЭХвХ Ъ нвЮЬг ЬХвРбШЬТЮЫг Ш СгФХвХ ЫХУЪЮ гЧЭРТРвм ЪЮЭбвагЪжШо [\s*] ФРЦХ Т бЫЮЦЭле ТлаРЦХЭШпе.
ЅРиР ЪЮЬРЭФР вХЯХам ТлУЫпФШв вРЪ:
$input =~ m/^([-+]?[0-9]+(\.[0-9]*)?)\s*([CF])$/
ЅРЪЮЭХж, бгддШЪб ФЮЫЦХЭ ТТЮФШвмбп ЭХ вЮЫмЪЮ Т ТХаеЭХЬ, ЭЮ Ш Т ЭШЦЭХЬ аХУШбваХ. ·РФРзР аХиРХвбп ТЪЫозХЭШХЬ бШЬТЮЫЮТ ЭШЦЭХУЮ аХУШбваР Т бШЬТЮЫмЭлЩ ЪЫРбб: [CFcf]. ІЯаЮзХЬ, п еЮзг ЯаЮФХЬЮЭбваШаЮТРвм ХйХ ЮФШЭ бЯЮбЮС:
$input =~ m/^([-+]?[0-9]+(\.[0-9]*)?)\s*([CF])$/i
єЫоз<$M[R2-9]> i пТЫпХвбп ЬЮФШдШЪРвЮаЮЬ. µУЮ ЯаШбгвбвТШХ ЯЮбЫХ m/…/ бЮЮСйРХв Perl Ю вЮЬ, звЮ ЯЮШбЪ ФЮЫЦХЭ ЮбгйХбвТЫпвмбп СХЧ гзХвР аХУШбваР бШЬТЮЫЮТ. БШЬТЮЫ i пТЫпХвбп зРбвмо ЭХ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, Р бШЭвРЪбШзХбЪЮЩ ЮСЮЫЮзЪШ m/…/, Ш гЪРЧлТРХв Perl, ЪРЪ ШЬХЭЭЮ ФЮЫЦЭЮ ЮСаРСРвлТРвмбп гЪРЧРЭЭЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ. ІЯаЮзХЬ, ЯЮбвЮпЭЭЮ УЮТЮаШвм «ЬЮФШдШЪРвЮа i» ЭХгФЮСЭЮ, ЯЮнвЮЬг ЮСлзЭЮ ШбЯЮЫмЧгХвбп ЮСЮЧЭРзХЭШХ /i (еЮвп ЯаШ ШбЯЮЫмЧЮТРЭШШ ЬЮФШдШЪРвЮаР ФЮЯЮЫЭШвХЫмЭлЩ бШЬТЮЫ / ЭХ ЭгЦХЭ). ЅР бваРЭШжРе ЪЭШУШ ТРЬ ТбваХвпвбп Ш ФагУШХ ЬЮФШдШЪРвЮал, Т вЮЬ зШбЫХ ЬЮФШдШЪРвЮа УЫЮСРЫмЭЮУЮ ЯЮШбЪР /g Т нвЮЩ УЫРТХ.
їЮЯаЮСгХЬ ЧРЯгбвШвм ЭЮТго ТХабШо ЯаЮУаРЬЬл:
% perl -w convert
Enter a temperature (i.e. 32F, 100C):
32 f
0.00 C = 32.00 F
% perl -w convert
Enter a temperature (i.e. 32F, 100C):
50 c
10.00 C = 50.00 F
БвЮЯ! їаШ ТвЮаЮЬ ЧРЯгбЪХ Ьл ТТХЫШ 50 ЯЮ ЖХЫмбШо, ЪЮвЮалХ ЯЮзХЬг-вЮ СлЫШ ШЭвХаЯаХвШаЮТРЭл ЪРЪ 50 ЯЮ ДРаХЭУХЩвг! їаЮбЬЮваШвХ вХЪбв ЯаЮУаРЬЬл. Іл ТШФШвХ, ЯЮзХЬг нвЮ ЯаЮШЧЮиЫЮ?
if ($input =~ m/^([-+]?[0-9]+(\.[0-9]*)?)\s*([CF])$/i)
{
.
.
.
$type = $3; # ёбЯЮЫмЧЮТРЭШХ $type ТЬХбвЮ $3 гЯаЮйРХв звХЭШХ ЯаЮУаРЬЬл
if ($type eq "C") { # 'eq' ЯаЮТХапХв аРТХЭбвТЮ ФТге бваЮЪ
.
.
.
} else {
.
.
.
јл ШЧЬХЭШЫШ аХУгЫпаЭЮХ ТлаРЦХЭШХ, звЮСл ЮЭЮ ФЮЯгбЪРЫЮ бгддШЪб f Т ЭШЦЭХЬ аХУШбваХ, ЭЮ ЧРСлЫШ ЯаХФгбЬЮваХвм ХУЮ ЮСаРСЮвЪг Т ЮбвРТиХЩбп зРбвШ ЯаЮУаРЬЬл. БХЩзРб, ХбЫШ $type ЭХ бЮФХаЦШв Т вЮзЭЮбвШ бШЬТЮЫ C, Ьл ЯаХФЯЮЫРУРХЬ, звЮ ЯЮЫмЧЮТРвХЫм ТТХЫ вХЬЯХаРвгаг ЯЮ ДРаХЭУХЩвг. їЮбЪЮЫмЪг иЪРЫР ЖХЫмбШп вРЪЦХ ЬЮЦХв ЮСЮЧЭРзРвмбп бШЬТЮЫЮЬ c, ЭХЮСеЮФШЬЮ ШЧЬХЭШвм гбЫЮТШХ ЯаЮТХаЪШ $type[3]:
if ($type eq "C" or $type eq "б") {
ВХЯХам ЯаЮУаРЬЬР аРСЮвРХв вРЪ, ЪРЪ ЭгЦЭЮ. їаШТХФХЭЭлХ ЯаШЬХал ЯЮЪРЧлТРов, звЮ ЯаШЬХЭХЭШХ аХУгЫпаЭле ТлаРЦХЭШЩ ЬЮЦХв Слвм ТЧРШЬЮбТпЧРЭЮ б ЮбвРЫмЭЮЩ ЯаЮУаРЬЬЮЩ.
єбвРвШ, ФЫп ЯаЮТХаЪШ бШЬТЮЫР c вРЪЦХ ЬЮЦЭЮ СлЫЮ ТЮбЯЮЫмЧЮТРвмбп аХУгЫпаЭлЬ ТлаРЦХЭШХЬ. єРЪ Сл Тл нвЮ бФХЫРЫШ?ref<$M[R2-2]>їХаХТХаЭШвХ бваРЭШжг Ш ЯаЮТХамвХ бТЮЩ ЮвТХв.
ЕЮвп нвР УЫРТР ЭРзРЫРбм б гбЪЮаХЭЭЮУЮ ЮЯШбРЭШп Perl, бвЮШв ЭХЭРФЮЫУЮ ЮвТЫХзмбп Ш ЮбЮСЮ ТлФХЫШвм ЭХЪЮвЮалХ РбЯХЪвл, ЮвЭЮбпйШХбп Ъ аХУгЫпаЭлЬ ТлаРЦХЭШпЬ:
l АХУгЫпаЭлХ ТлаРЦХЭШп Perl ЮвЫШзРовбп Юв аХУгЫпаЭле ТлаРЦХЭШЩ egrep; ЯЮзвШ ЪРЦФРп ЯаЮУаРЬЬР ЯЮФФХаЦШТРХв бЮСбвТХЭЭлЩ ФШРЫХЪв аХУгЫпаЭле ТлаРЦХЭШЩ. АХУгЫпаЭлХ ТлаРЦХЭШп Perl ЮвЭЮбпвбп Ъ вЮЬг ЦХ вШЯг, ЭЮ ЮСЫРФРов аРбиШаХЭЭлЬ ЭРСЮаЮЬ ЬХвРбШЬТЮЫЮТ.
l ґЫп ЯЮШбЪР бЮТЯРФХЭШЩ аХУгЫпаЭЮУЮ ТлаРЦХЭШп Т бваЮЪХ ШбЯЮЫмЧгХвбп ЪЮЭбвагЪжШп $variable =~ m/…/. БШЬТЮЫ m ЮЯаХФХЫпХв ЮЯХаРжШо ЯЮШбЪР, Р бШЬТЮЫл / ЮУаРЭШзШТРов аХУгЫпаЭЮХ ТлаРЦХЭШХ (ЭХ пТЫппбм ХУЮ зРбвмо). АХЧгЫмвРвЮЬ ЯаЮТХаЪШ пТЫпХвбп ЫЮУШзХбЪРп ТХЫШзШЭР, true ШЫШ false.
l єЮЭжХЯжШп ЬХвРбШЬТЮЫЮТ (бШЬТЮЫЮТ б ЮбЮСЮЩ ШЭвХаЯаХвРжШХЩ) ЭХ пТЫпХвбп гЭШЪРЫмЭЮЩ ЮбЮСХЭЭЮбвмо аХУгЫпаЭле ТлаРЦХЭШЩ. єРЪ УЮТЮаШЫЮбм ТлиХ ЯаШ ЮСбгЦФХЭШШ ЪЮЬРЭФЭле ШЭвХаЯаХвРвЮаЮТ Ш бваЮЪ, ЧРЪЫозХЭЭле Т ЪРТлзЪШ, ЯЮФЮСЭРп ШЭвХаЯаХвРжШп ТбваХзРХвбп ТЮ ЬЭЮУШе ЪЮЭвХЪбвРе. ·ЭРЭШХ аРЧЫШзЭле ЪЮЭвХЪбвЮТ (ЪЮЬРЭФЭлХ ШЭвХаЯаХвРвЮал, аХУгЫпаЭлХ ТлаРЦХЭШп, бваЮЪШ Ш в. Ф.), Ше ЬХвРбШЬТЮЫЮТ Ш ТЮЧЬЮЦЭЮбвХЩ ЮЪРЦХв бгйХбвТХЭЭго ЯЮЬЮйм ЯаШ ШЧгзХЭШШ Perl, Tcl, GNU Emacs, awk, Python Ш ФагУШе ЭХваШТШРЫмЭле бжХЭРаЭле пЧлЪЮТ.
ѕФШЭ ШЧ бЯЮбЮСЮТ ЯаЮТХаЪШ ЮФЭЮбШЬТЮЫмЭЮЩ ЯХаХЬХЭЭЮЩ
bref ѕвТХв ЭР ТЮЯаЮб бЮ б. <$R[P#,R2-2]>
БШЬТЮЫ c ЬЮЦЭЮ ЯаЮТХаШвм ЪЮЬРЭФЮЩ $type =~ m/^[cC]$/. їЮбЪЮЫмЪг ЯХаХЬХЭЭРп $type ЧРТХФЮЬЮ бЮФХаЦШв аЮТЭЮ ЮФШЭ бШЬТЮЫ, Т ФРЭЭЮЬ бЫгзРХ ЪЮЭбвагЪжШп [^…$] ЭХ ЮСпЧРвХЫмЭР. ё ХбЫШ гЦ ЭР вЮ ЯЮиЫЮ, ЬЮЦЭЮ ФРЦХ ТЮбЯЮЫмЧЮТРвмбп ЪЮЬРЭФЮЩ $type =~ m/c/i, звЮСл ЬЮФШдШЪРвЮа /i ТлЯЮЫЭШЫ зРбвм аРСЮвл ЧР ЭРб.
їаЮбвЮвР ЭХЯЮбаХФбвТХЭЭЮЩ ЯаЮТХаЪШ бШЬТЮЫЮТ c Ш C ЭРТЮФШв ЭР ЬлбЫм, звЮ ЯаШЬХЭХЭШХ аХУгЫпаЭЮУЮ ТлаРЦХЭШп ФЫп нвЮЩ жХЫШ ЭХ ЮЯаРТФРЭЮ. Б ФагУЮЩ бвЮаЮЭл, ХбЫШ Сл ЭРЬ ЯЮваХСЮТРЫЮбм ЮСЭРагЦШвм ЯаЮШЧТЮЫмЭго ЪЮЬСШЭРжШо аХУШбваР бШЬТЮЫЮТ Т бЫЮТХ «celsius», вЮ ЯаШЬХЭХЭШХ аХУгЫпаЭЮУЮ ТлаРЦХЭШп СлЫЮ Сл ЭРЬЭЮУЮ ЫЮУШзЭХХ ЯапЬЮУЮ ЯХаХСЮаР celsius, Celsius, CeLsIuS Ш в. Ф. (128 ТЮЧЬЮЦЭле ЪЮЬСШЭРжШЩ!)
їЮ ЬХаХ ШЧгзХЭШп Perl Тл гЧЭРХвХ Ш ФагУШХ, СЮЫХХ гФРзЭлХ аХиХЭШп — ЭРЯаШЬХа, ЪЮЬРЭФг lc($type) eq "celsius".
l є зШбЫг бРЬле ЯЮЫХЧЭле ЬХвРбШЬТЮЫЮТ, ЯЮФФХаЦШТРХЬле Т аХУгЫпаЭле ТлаРЦХЭШпе Perl, ЯаШЭРФЫХЦРв бЫХФгойШХ (ЭХЪЮвЮалХ ШЧ ЯаШТХФХЭЭле ЬХвРбШЬТЮЫЮТ ХйХ ЭХ гЯЮЬШЭРЫШбм Т ЪЭШУХ):<$M[R2-5]>
|
\t |
бШЬТЮЫ вРСгЫпжШШ |
|
\n |
бШЬТЮЫ ЭЮТЮЩ бваЮЪШ |
|
\r |
бШЬТЮЫ ТЮЧТаРвР ЪгабЮаР |
|
\s |
ЪЫРбб, бЮТЯРФРойШе б ЫоСлЬ «ЯаЮЯгбЪЭлЬ» бШЬТЮЫЮЬ (ЯаЮСХЫ, вРСгЫпжШп, ЭЮТРп бваЮЪР, ЯЮФРзР ЫШбвР Ш в. Ф.) |
|
\S |
ТбХ, звЮ ЭХ ЮвЭЮбШвбп Ъ [\s] |
|
\w |
[[a-zA-Z0-9_]] (зРбвЮ ШбЯЮЫмЧгХвбп Т ЪЮЭбвагЪжШШ [\w+] ФЫп ЯЮШбЪР бЫЮТ) |
|
\W |
ТбХ, звЮ ЭХ ЮвЭЮбШвбп Ъ [\w], вЮ Хбвм [[^a-zA-Z0-9_]]. |
|
\d |
[[0-9]], вЮ Хбвм жШдаР |
|
\D |
ТбХ, звЮ ЭХ ЮвЭЮбШвбп Ъ [\d], вЮ Хбвм [[^0-9]] |
l їаШ ЭРЫШзШШ ЬЮФШдШЪРвЮаР /i ЯЮШбЪ ЯаЮШЧТЮФШвбп СХЧ гзХвР аХУШбваР бШЬТЮЫЮТ. ЕЮвп Т вХЪбвХ ЮСлзЭЮ ШбЯЮЫмЧгХвбп ЮСЮЧЭРзХЭШХ «/i», ЯЮбЫХ ЧРТХаиРойХУЮ ЮУаРЭШзШвХЫп Т ФХЩбвТШвХЫмЭЮбвШ бвРТШвбп вЮЫмЪЮ бШЬТЮЫ i.
l їаШ ЮСЭРагЦХЭШШ бЮТЯРФХЭШп Т ЯХаХЬХЭЭлХ $1, $2, $3 ЧРЭЮбШвбп вХЪбв, бЮТЯРТиШЩ б бЮЮвТХвбвТгойШЬШ ЯЮФТлаРЦХЭШпЬШ Т ЪагУЫле бЪЮСЪРе. їЮФТлаРЦХЭШп ЭгЬХаговбп Т бЮЮвТХвбвТШШ б ЯЮЧШжШХЩ ЮвЪалТРойШе ЪагУЫле бЪЮСЮЪ бЫХТР ЭРЯаРТЮ, ЭРзШЭРп б 1. їЮФТлаРЦХЭШп ЬЮУгв Слвм ТЫЮЦХЭЭлЬШ — ЭРЯаШЬХа, [(UnitedspcStates(spcofspcAmerica)?)].
єагУЫлХ бЪЮСЪШ ЬЮУгв ЯаШЬХЭпвмбп вЮЫмЪЮ ФЫп УагЯЯШаЮТЪШ, ЭЮ Ш Т нвЮЬ бЫгзРХ бЮЮвТХвбвТгойРп бЯХжШРЫмЭРп ЯХаХЬХЭЭРп ЧРЯЮЫЭпХвбп вХЪбвЮЬ бЮТЯРФХЭШп. Б ФагУЮЩ бвЮаЮЭл, ЮЭШ зРбвЮ ШбЯЮЫмЧговбп бЯХжШРЫмЭЮ ФЫп ЯаШбТРШТРЭШп ЧЭРзХЭШЩ ЭгЬХаЮТРЭЭлЬ ЯХаХЬХЭЭлЬ. НвЮв бЯЮбЮС ЯЮЧТЮЫпХв ШЧТЫХЪРвм ФРЭЭлХ ШЧ бваЮЪШ ЯаШ ЯЮЬЮйШ аХУгЫпаЭле ТлаРЦХЭШЩ.
ІЮ ТбХе ЯаШЬХаРе, аРббЬЮваХЭЭле ТлиХ, Ьл ЮУаРЭШзШТРЫШбм ЯЮШбЪЮЬ, Ш, Т ЮвФХЫмЭле бЫгзРпе, «ШЧТЫХзХЭШХЬ» ШЭдЮаЬРжШШ ШЧ бваЮЪШ. БХЩзРб Ьл ЯХаХЩФХЬ Ъ ЯЮФбвРЭЮТЪХ, ШЫШ ЯЮШбЪг б ЧРЬХЭЮЩ — ТЮЧЬЮЦЭЮбвШ, ЯЮФФХаЦШТРХЬЮЩ Perl Ш ЬЭЮУШЬШ ФагУШЬШ ЯаЮУаРЬЬРЬШ.
єРЪ Тл гЦХ ЧЭРХвХ, ЪЮЭбвагЪжШп $var =~ m/ТлаРЦХЭШХ/ бЮЯЮбвРТЫпХв аХУгЫпаЭЮХ ТлаРЦХЭШХ б бЮФХаЦШЬлЬ ЯХаХЬХЭЭЮЩ Ш ТЮЧТаРйРХв true ШЫШ false Т ЧРТШбШЬЮбвШ Юв аХЧгЫмвРвР. °ЭРЫЮУШзЭРп ЪЮЭбвагЪжШп, $var =~ s/ТлаРЦХЭШХ/ЧРЬХЭР/, ЯаХФбвРТЫпХв бЮСЮЩ бЫХФгойШЩ иРУ Т аРСЮвХ б вХЪбвЮЬ: ХбЫШ аХУгЫпаЭЮХ ТлаРЦХЭШХ бЮТЯРФРХв Т бваЮЪХ $var, дРЪвШзХбЪШ бЮТЯРТиШЩ вХЪбв ЧРЬХЭпХвбп ЧРФРЭЭЮЩ бваЮЪЮЩ. їаШ нвЮЬ ШбЯЮЫмЧгХвбп вРЪЮХ ЦХ аХУгЫпаЭЮХ ТлаРЦХЭШХ, ЪРЪ Ш Т m/…/, ЭЮ бваЮЪР ЧРЬХЭл (ЬХЦФг баХФЭШЬ Ш ЯЮбЫХФЭШЬ бШЬТЮЫЮЬ /) ШЭвХаЯаХвШагХвбп ЯЮ ЯаРТШЫРЬ бваЮЪ, ЧРЪЫозХЭЭле Т ЪРТлзЪШ. НвЮ ЮЧЭРзРХв, звЮ ЮЭР ЬЮЦХв бЮФХаЦРвм бблЫЪШ ЭР ЯХаХЬХЭЭлХ (Т зРбвЭЮбвШ, ЮзХЭм гФЮСЭЮ ШбЯЮЫмЧЮТРвм ЯХаХЬХЭЭлХ $1, $2 Ш в. Ф., бблЫРойШХбп ЭР ЪЮЬЯЮЭХЭвл ЭРЩФХЭЭЮУЮ бЮТЯРФХЭШп).
ВРЪШЬ ЮСаРЧЮЬ, ЪЮЭбвагЪжШп $var =~ s/…/…/ ШЧЬХЭпХв ЧЭРзХЭШХ ЯХаХЬХЭЭЮЩ $var (ТЯаЮзХЬ, ХбЫШ бЮТЯРФХЭШХ ЭХ ЮСЭРагЦХЭЮ, ЧРЬХЭР ЭХ ЯаЮШЧТЮФШвбп Ш ЯХаХЬХЭЭРп бЮеаРЭпХв ЯаХЦЭХХ ЧЭРзХЭШХ). ЅРЯаШЬХа, ХбЫШ ЯХаХЬХЭЭРп $var бЮФХаЦШв бваЮЪг JeffspcFriedl, вЮ ЯаШ ТлЯЮЫЭХЭШШ ЪЮЬРЭФл
$var =~ s/Jeff/Jeffrey/;
Т ЯХаХЬХЭЭго $var ЧРЭЮбШвбп вХЪбв JeffreyspcFriedl. ЅЮ ХбЫШ ЯХаХЬХЭЭРп $var ШЧЭРзРЫмЭЮ бЮФХаЦРЫР бваЮЪг JeffreyspcFriedl, вЮ ЯЮбЫХ ТлЯЮЫЭХЭШп нвЮЩ ЪЮЬРЭФл ЮЭР ЯаШЬХв ТШФ JeffreyreyspcFriedl. ѕСлзЭЮ ЯаШ ЯЮФЮСЭле ЧРЬХЭРе ШбЯЮЫмЧговбп ЬХвРбШЬТЮЫл УаРЭШж бЫЮТ. єРЪ гЯЮЬШЭРЫЮбм Т ЯХаТЮЩ УЫРТХ, ЭХЪЮвЮалХ ТХабШШ egrep ЯЮФФХаЦШТРов ЬХвРбШЬТЮЫл [\<] Ш [\>] ФЫп ЮСЮЧЭРзХЭШп ЭРзРЫР Ш ЪЮЭжР бЫЮТР. І Perl ФЫп нвЮЩ жХЫШ бгйХбвТгХв гЭШТХабРЫмЭлЩ ЬХвРбШЬТЮЫ [\b]:
$var =~ s/\bJeff\b/Jeffrey/;
° вХЯХам ЪРТХаЧЭлЩ ТЮЯаЮб — Т ЪЮЭбвагЪжШШ s/…/…/, ЪРЪ Ш Т ЪЮЭбвагЪжШШ m/…/, ЬЮУгв ШбЯЮЫмЧЮТРвмбп ЬЮФШдШЪРвЮал (ЭРЯаШЬХа, /i). є ЪРЪЮЬг аХЧгЫмвРвг ЯаШТЮФШв ТлЯЮЫЭХЭШХ бЫХФгойХЩ ЪЮЬРЭФл:
$var =~ s/\bJeff\b/Jeff/i;
ref<$M[R2-3]>їХаХТХаЭШвХ бваРЭШжг Ш ЯаЮТХамвХ бТЮЩ ЮвТХв.
АРббЬЮваШЬ ЭХбХамХЧЭлЩ ЯаШЬХа, ФХЬЮЭбваШагойШЩ ШбЯЮЫмЧЮТРЭШХ ЯХаХЬХЭЭЮЩ Т бваЮЪХ ЧРЬХЭл. їаХФЯЮЫЮЦШЬ, Тл ШбЯЮЫмЧгХвХ бЫХФгойШЩ иРСЫЮЭ ЯШбмЬР<$M[R2-10]>:
Dear <FIRST>,
You have been chosen to win a brand new <TRINKET>! Free!
Could you use another <TRINKET> in the <FAMILY> household?
Yes <SUCKER>, I bet you could! Just respond by.....
ЗвЮСл ЧРЯЮЫЭШвм иРСЫЮЭ ФРЭЭлЬШ ЪЮЭЪаХвЭЮУЮ ЯЮЫгзРвХЫп, Тл ЯаШбТРШТРХвХ ЯХаХЬХЭЭлЬ ЭХЮСеЮФШЬлХ ЧЭРзХЭШп:
$given = 'Tom';
$family = 'Cruise';
$wunderprize = '100% genuine faux diamond';
ЗвЮ ФХЫРХв ЪЮЬРЭФР $var =~ s/\bJeff\b/Jeff/i?
bref ѕвТХв ЭР ТЮЯаЮб бЮ б. <$R[P#,R2-3]>
ёЧ-ЧР вЮУЮ, ЪРЪ бдЮаЬгЫШаЮТРЭ нвЮв ТЮЯаЮб, ЮЭ ФХЩбвТШвХЫмЭЮ ЬЮЦХв ЮЪРЧРвмбп ЪРТХаЧЭлЬ. µбЫШ Сл аХУгЫпаЭЮХ ТлаРЦХЭШХ ШЬХЫЮ ТШФ [\bJEFF\b], [\bjeff\b] ШЫШ ФРЦХ [\bjEfF\b], бЬлбЫ нвЮЩ ЪЮЬРЭФл СлЫ Сл ЮзХТШФХЭ. їаШ ЭРЫШзШШ ЬЮФШдШЪРвЮаР /i бЫЮТЮ «Jeff» ШйХвбп СХЧ гзХвР аХУШбваР бШЬТЮЫЮТ. їЮбЫХ нвЮУЮ ЮЭЮ ЧРЬХЭпХвбп бЫЮТЮЬ «Jeff», ЧРЯШбРЭЭлЬ ШЬХЭЭЮ нвШЬШ бШЬТЮЫРЬШ (ЬЮФШдШЪРвЮа /i ЭХ ТЫШпХв ЭР вХЪбв ЧРЬХЭл, еЮвп бгйХбвТгов Ш ФагУШХ ЬЮФШдШЪРвЮал, Ю ЪЮвЮале аХзм ЯЮЩФХв Т УЫРТХ 7).
їЮбЫХ ЯЮФУЮвЮТЪШ иРСЫЮЭ ЧРЯЮЫЭпХвбп бЫХФгойШЬШ ЪЮЬРЭФРЬШ:
$letter =~ s/<FIRST>/$given/g;
$letter =~ s/<FAMILY>/$family/g;
$letter =~ s/<SUCKER>/$given $family/g;
$letter =~ s/<TRINKET>/fabulous $wunderprize/g;
єРЦФРп ЪЮЬРЭФР ШйХв Т вХЪбвХ ЯаЮбвЮЩ ЬРаЪХа, Ш ЮСЭРагЦШТ ХУЮ, ЧРЬХЭпХв вХЪбвЮЬ, ЪЮвЮалЩ ФЮЫЦХЭ ЯаШбгвбвТЮТРвм Т ШвЮУЮТЮЬ бЮЮСйХЭШШ. І ЯХаТле ФТге ЪЮЬРЭФРе вХЪбв ЧРЬХЭл ЯаЮбвЮ СХаХвбп ШЧ ЯХаХЬХЭЭЮЩ (ЯЮ РЭРЫЮУШШ бЮ бваЮЪЮЩ, ЧРЪЫозХЭЭЮЩ Т ЪРТлзЪШ Ш бЮФХаЦРйХЩ вЮЫмЪЮ ШЬп ЯХаХЬХЭЭЮЩ — ЭРЯаШЬХа, "$given"). ВаХвмп ЪЮЬРЭФР ЧРЬХЭпХв бЮТЯРТиШЩ вХЪбв нЪТШТРЫХЭвЮЬ "$given $family", Р зХвТХавРп — бваЮЪЮЩ "fabulous $wunderprize". µбЫШ Тл ЯШиХвХ ТбХУЮ ЮФЭЮ бЮЮСйХЭШХ, нвШ ЯХаХЬХЭЭлХ ЬЮЦЭЮ ЮЯгбвШвм Ш ЭХЯЮбаХФбвТХЭЭЮ ТТХбвШ ЭгЦЭлЩ вХЪбв, ЭЮ ЯЮЪРЧРЭЭлЩ ЬХвЮФ ЯЮЧТЮЫпХв РТвЮЬРвШЧШаЮТРвм ЯаЮжХбб аРбблЫЪШ (ЭРЯаШЬХа, ХбЫШ ФРЭЭлХ ЯЮЫгзРвХЫХЩ ЧРУагЦРовбп ШЧ бЯШбЪР).
јЮФШдШЪРвЮа «УЫЮСРЫмЭЮУЮ ЯЮШбЪР» /g ЭРЬ ХйХ ЭХ ТбваХзРЫбп. ѕЭ УЮТЮаШв Ю вЮЬ , звЮ ЯЮбЫХ ЯХаТЮЩ ЯЮФбвРЭЮТЪШ ЪЮЬРЭФР s/…/…/ ФЮЫЦЭР ЯлвРвмбп ЮСЭРагЦШвм ФагУШХ бЮТЯРФХЭШп (Ш ЯаЮШЧТХбвШ ФЮЯЮЫЭШвХЫмЭлХ ЧРЬХЭл). јЮФШдШЪРвЮа /g ЭХЮСеЮФШЬ, ХбЫШ Тл еЮвШвХ, звЮСл ЪРЦФРп ЪЮЬРЭФР ЯаЮШЧТЮФШЫР ТбХ ТЮЧЬЮЦЭлХ ЧРЬХЭл, ЭХ ЮУаРЭШзШТРпбм ЯХаТлЬ ЭРЩФХЭЭлЬ бЮТЯРФХЭШХЬ.
АХЧгЫмвРв ТЯЮЫЭХ ЯаХФбЪРЧгХЬ:
Dear Tom,
You have been chosen to win a brand new fabulous 100% genuine faux diamond! Free!
Could you use another fabulous 100% genuine faux diamond in the Cruise household?
Yes Tom Cruise, I bet you could! Just respond by.....
АРббЬЮваШЬ ФагУЮЩ ЯаШЬХа<$M[R2-6]> — ЯаЮСЫХЬг, б ЪЮвЮаЮЩ п бвЮЫЪЭгЫбп ТЮ ТаХЬп ЭРЯШбРЭШп ЭР Perl ЯаЮУаРЬЬл ФЫп аРСЮвл б СШаЦХТлЬШ ЪЮвШаЮТЪРЬШ. П ЯЮЫгзРЫ ЪЮвШаЮТЪШ ТШФР «9.0500000037272». єЮЭХзЭЮ, ЭРбвЮпйХХ ЧЭРзХЭШХ СлЫЮ аРТЭЮ 9.05, ЭЮ ШЧ-ЧР ЮбЮСХЭЭЮбвХЩ ТЭгваХЭЭХУЮ ЯаХФбвРТЫХЭШп ТХйХбвТХЭЭле зШбХЫ Perl ТлТЮФШЫ Ше Т вРЪЮЬ ТШФХ, ХбЫШ ЯаШ ТлТЮФХ ЭХ ШбЯЮЫмЧЮТРЫЮбм дЮаЬРвШаЮТРЭШХ. І ЮСлзЭЮЩ бШвгРжШШ п Сл ЯаЮбвЮ ТЮбЯЮЫмЧЮТРЫбп дгЭЪжШХЩ printf ФЫп ТлТЮФР зШбЫР б ФТгЬп аРЧапФРЬШ Т ФаЮСЭЮЩ зРбвШ, ЪРЪ Т ЯаШЬХаХ б ЯаХЮСаРЧЮТРЭШХЬ вХЬЯХаРвга, ЭЮ Т ФРЭЭЮЬ бЫгзРХ нвЮв ТРаШРЭв ЭХ УЮФШЫбп. ґХЫЮ Т вЮЬ, звЮ ФаЮСЭРп зРбвм, аРТЭРп 1/8, ФЮЫЦЭР ТлТЮФШвмбп Т ТШФХ «.125», Ш Т нвЮЬ бЫгзРХ ЭХЮСеЮФШЬл ваШ жШдал ТЬХбвЮ ФТге.
І дЮаЬРЫмЭЮЬ ТШФХ ЬЮп ЧРФРзР ЧТгзРЫР вРЪ: «ІбХУФР ТлТЮФШвм ЯХаТлХ ФТХ жШдал ФаЮСЭЮЩ зРбвШ, Р ваХвмо — ЫШим Т вЮЬ бЫгзРХ, ХбЫШ ЮЭР ЭХ аРТЭР ЭгЫо. ІбХ ЮбвРЫмЭлХ жШдал ШУЭЮаШаговбп». І аХЧгЫмвРвХ зШбЫЮ 12.3750000000392 ШЫШ гЦХ ЯаРТШЫмЭЮХ 12.375 ТЮЧТаРйРХвбп Т ТШФХ «12.375», Р 37.500 бЮЪаРйРХвбп ФЮ «37.50». ёЬХЭЭЮ вЮ, звЮ ЭРЬ ваХСЮТРЫЮбм.
ЅЮ ЪРЪ аХРЫШЧЮТРвм нвЮ ваХСЮТРЭШХ? БваЮЪР, Т ЪЮвЮаЮЩ ТлЯЮЫЭпХвбп ЯЮШбЪ, еаРЭШвбп Т ЯХаХЬХЭЭЮЩ $price, ЯЮнвЮЬг Ьл ТЮбЯЮЫмЧгХЬбп ЪЮЬРЭФЮЩ $price =~ s/(\.\d\d[1-9]?)\d*/$1/. ЅРзРЫмЭРп ЪЮЭбвагЪжШп [\.] ЭгЦЭР ФЫп вЮУЮ, звЮСл бЮТЯРФХЭШХ ЭРзШЭРЫЮбм б ФХбпвШзЭЮЩ вЮзЪШ. ·РвХЬ ФТР ЬХвРбШЬТЮЫР [\d\d] бЮТЯРФРов б ФТгЬп жШдаРЬШ, бЫХФгойШЬШ ЧР вЮзЪЮЩ. їЮФТлаРЦХЭШХ [[1-9]?] бЮТЯРФРХв c ЭХЭгЫХТЮЩ жШдаЮЩ, ХбЫШ ЮЭР бЫХФгХв ЧР ЯХаТлЬШ ФТгЬп. ІбХ бЮТЯРТиШХ ФЮ ЭРбвЮпйХУЮ ЬЮЬХЭвР бШЬТЮЫл ЮСаРЧгов зРбвм, ЪЮвЮаго Ьл еЮвШЬ ЮбвРТШвм, ЯЮнвЮЬг ЮЭШ ЧРЪЫозРовбп Т ЪагУЫлХ бЪЮСЪШ ФЫп бЮеаРЭХЭШп Т ЯХаХЬХЭЭЮЩ $1. ·РвХЬ ЧЭРзХЭШХ $1 ШбЯЮЫмЧгХвбп Т бваЮЪХ ЧРЬХЭл. µбЫШ ЭШзХУЮ СЮЫмиХ ЭХ бЮТЯРЫЮ, бваЮЪР ЧРЬХЭпХвбп бРЬР бЮСЮЩ — ЭХ бЫШиЪЮЬ ШЭвХаХбЭЮ. ѕФЭРЪЮ ТЭХ ЪагУЫле бЪЮСЮЪ $1 ЯаЮФЮЫЦРХвбп ЯЮШбЪ ФагУШе бШЬТЮЫЮТ. НвШ бШЬТЮЫл ЭХ ТЪЫозРовбп Т бваЮЪг ЧРЬХЭл Ш ЯЮнвЮЬг ЮЭШ дРЪвШзХбЪШ гФРЫповбп ШЧ зШбЫР. І ФРЭЭЮЬ бЫгзРХ «гФРЫпХЬлЩ» вХЪбв бЮбвЮШв ШЧ ТбХе ФРЫмЭХЩиШе жШда, вЮ Хбвм [\d*] Т ЪЮЭжХ аХУгЫпаЭЮУЮ ТлаРЦХЭШп.
·РЯЮЬЭШвХ нвЮв ЯаШЬХа. јл ТХаЭХЬбп Ъ ЭХЬг Т УЫРТХ 4, ЯаШ ШЧгзХЭШШ ЬХеРЭШЧЬР ЯЮШбЪР бЮТЯРФХЭШЩ. ёЧ нвЮУЮ ЯаШЬХаР бЫХФгХв апФ ШЭвХаХбЭле гаЮЪЮТ.
ІЮ ТаХЬп аРСЮвл ЭРФ нвЮЩ УЫРТЮЩ п бвЮЫЪЭгЫбп ХйХ б ЮФЭШЬ ЯаЮбвлЬ, ЭЮ ТЯЮЫЭХ аХРЫмЭлЬ ЯаШЬХаЮЬ. П ЯЮФЪЫозШЫбп Ъ ЪЮЬЯмовХаг ЭР ФагУЮЬ СХаХУг ВШеЮУЮ ЮЪХРЭР, ЯаШзХЬ бХвм аРСЮвРЫР ЭР аХФЪЮбвм ЬХФЫХЭЭЮ. АХРЪжШп ЭР ЯаЮбвЮХ ЭРЦРвШХ ЪЫРТШиШ Enter бЫХФЮТРЫР вЮЫмЪЮ зХаХЧ ЬШЭгвг. П ФЮЫЦХЭ СлЫ ТЭХбвШ ЭХбЪЮЫмЪЮ ЬХЫЪШе ШбЯаРТЫХЭШЩ Т дРЩЫ, звЮСл ЧРаРСЮвРЫР ТРЦЭРп ЯаЮУаРЬЬР. ІбХ, звЮ ЬЭХ ваХСЮТРЫЮбм — ЧРЬХЭШвм Т дРЩЫХ ЪРЦФлЩ ТлЧЮТ sysread ЭР read. ёбЯаРТЫХЭШЩ СлЫЮ ЭХЬЭЮУЮ, ЭЮ ЯаШ вРЪЮЩ ЧРЬХФЫХЭЭЮЩ аХРЪжШШ бРЬР ШФХп ЧРЯгбЪР ЯЮЫЭЮнЪаРЭЭЮУЮ аХФРЪвЮаР ТлУЫпФХЫР СХЧгЬШХЬ.
їаШТХФг ЪЮЬРЭФг, ЪЮвЮаРп РТвЮЬРвШзХбЪШ ТЭХбЫР ТбХ ЭХЮСеЮФШЬлХ ШЧЬХЭХЭШп:
% perl -p -i -e 's/sysread/read/g' ШЬп_дРЩЫР
єЮЬРЭФР ТлЯЮЫЭпХв ЯаЮУаРЬЬг Perl s/sysread/read/g (ФР, нвЮ ФХЩбвТШвХЫмЭЮ жХЫРп ЯаЮУаРЬЬР — ЮС нвЮЬ бТШФХвХЫмбвТгХв ЪЫоз -e, ЯЮбЫХ ЪЮвЮаЮУЮ Т ЪЮЬРЭФЭЮЩ бваЮЪХ бЫХФгХв ЯаЮУаРЬЬР). єаЮЬХ вЮУЮ, Т ЪЮЬРЭФЭЮЩ бваЮЪХ гЪРЧРЭл ЪЫозШ Perl -p Ш -i, Р вРЪЦХ ШЬп дРЩЫР, б ЪЮвЮалЬ аРСЮвРХв ЯаЮУаРЬЬР. їаШ вРЪЮЩ ЪЮЬСШЭРжШШ ЪЫозХЩ ЯЮФбвРЭЮТЪР ТлЯЮЫЭпХвбп Т ЪРЦФЮЩ бваЮЪХ дРЩЫР, Р ЯЮбЫХ ЧРТХаиХЭШп ЯЮФбвРЭЮТЪШ аХЧгЫмвРвл ЧРЯШблТРовбп ЮСаРвЭЮ Т дРЩЫ.
ѕСаРвШвХ ТЭШЬРЭШХ: Т ЪЮЬРЭФХ ЭХ гЪРЧРЭЮ ШЬп ЯХаХЬХЭЭЮЩ (var =~…), ЯЮбЪЮЫмЪг ЧРФРЭЭлХ ЪЫозШ ЮСХбЯХзШТРов ХХ ЭХпТЭЮХ ЯаШЬХЭХЭШХ ЯЮбЫХФЮТРвХЫмЭЮ Ъ ЪРЦФЮЩ бваЮЪХ дРЩЫР. єаЮЬХ вЮУЮ, ЪЫоз /g УРаРЭвШаЮТРЫ ЧРЬХЭг ТбХе нЪЧХЬЯЫпаЮТ Т ЮФЭЮЩ бваЮЪХ.
ЕЮвп п ЯаШЬХЭШЫ нвг ЯаЮУаРЬЬг Ъ ЮФЭЮЬг дРЩЫг, б вРЪШЬ ЦХ гбЯХеЮЬ ЬЮЦЭЮ СлЫЮ гЪРЧРвм Т ЪЮЬРЭФЭЮЩ бваЮЪХ ШЬХЭР ЭХбЪЮЫмЪШе дРЩЫЮТ, Ш Perl ЯаШЬХЭШЫ Сл ЯЮФбвРЭЮТЪг Ъ ЪРЦФЮЩ бваЮЪХ ЪРЦФЮУЮ дРЩЫР. І нвЮЬ бЫгзРХ ЮФЭР ЯаЮбвРп ЪЮЬРЭФР ЯаЮШЧТХЫР Сл ЬРббЮТЮХ аХФРЪвШаЮТРЭШХ Т ЬЭЮЦХбвТХ дРЩЫЮТ.
АРббЬЮваШЬ ХйХ ЮФШЭ ЯаШЬХа. ґЮЯгбвШЬ, г ЭРб ШЬХХвбп дРЩЫ б бЮЮСйХЭШХЬ нЫХЪваЮЭЭЮЩ ЯЮзвл, Ш Ьл еЮвШЬ ЯЮФУЮвЮТШвм дРЩЫ б ЮвТХвЮЬ. І ЯаЮжХббХ ЯЮФУЮвЮТЪШ ЪРЦФРп бваЮЪР ШбеЮФЭЮУЮ бЮЮСйХЭШп ФЮЫЦЭР Слвм ЯаЮжШвШаЮТРЭР Т ЮвТХвХ, звЮСл Ьл ЬЮУЫШ ЫХУЪЮ ТбвРТШвм бТЮЩ вХЪбв Т ЪРЦФго зРбвм бЮЮСйХЭШп. єаЮЬХ вЮУЮ, ЭХЮСеЮФШЬЮ гФРЫШвм ШЧ ЧРУЮЫЮТЪР ШбеЮФЭЮУЮ бЮЮСйХЭШп ЫШиЭШХ бваЮЪШ, Р вРЪЦХ ЯЮФУЮвЮТШвм ЧРУЮЫЮТЮЪ ЮвТХвЭЮУЮ бЮЮСйХЭШп.
їаХФЯЮЫЮЦШЬ, бЮЮСйХЭШХ ТлУЫпФШв вРЪ:
From elvis Thu Feb 29 11:15 1997
Received: from elvis@localhost by tabloid.org (6.2.12) id KA8CMY
Received: from tabloid.org by gateway.net.net (8.6.5/2) id N8XBK
Received: from gateway.net.net Thu Feb 29 11:16 1997
To:jfriedl@ora.com (Jeffrey Friedl)
From: elvis@tabloid.org (The King)
Date: Thu, Feb 29 1997 11:15
Message-Id: <1997022939939.KA8CMY@tabloid.org>
Subject: Be seein' ya around
Content-type: text
Reply-To: elvis@hh.tabloid.org
X-Mailer: Madam Zelda's Psychic Orb [version 2.4 PL23]
Sorry I haven't been around lately. A few years back I checked
into that ole heartbreak hotel in the sky, ifyaknowwhatImean.
The Duke says "hi".
Elvis
ЅХЪЮвЮалХ ЯЮЫп ЧРУЮЫЮТЪР (ФРвР, вХЬР Ш в. Ф.) ЯаХФбвРТЫпов ШЭвХаХб ФЫп ЭРб, ЭЮ ЮбвРЫмЭлХ ЯЮЫп ЭХЮСеЮФШЬЮ гФРЫШвм. µбЫШ бжХЭРаШЩ, ЪЮвЮалЩ Ьл бЮСШаРХЬбп ЭРЯШбРвм, ЭРЧлТРХвбп mkreply, Р ШбеЮФЭЮХ бЮЮСйХЭШХ еаРЭШвбп Т дРЩЫХ king.in, иРСЫЮЭ ЮвТХвР бваЮШвбп бЫХФгойХЩ ЪЮЬРЭФЮЩ:
% perl -w mkreply king.in > king.out
(ЅР ТбпЪШЩ бЫгзРЩ ЭРЯЮЬШЭРо — ЪЫоз -w ТЪЫозРХв ТлФРзг ЯаХФгЯаХЦФХЭШЩ; бЬ. б. <$R[P#,R2-4]>)
јл еЮвШЬ, звЮСл ШвЮУЮТлЩ дРЩЫ king.out ТлУЫпФХЫ ЯаШЬХаЭЮ вРЪ:
To: elvis@hh.tabloid.org (The King)
From: jfriedl@ora.com ((Jeffrey Friedl)
Subject: Re: Be seein' ya around
On Thu, Feb 29 1997 11:15 The King wrote:
|> Sorry I haven't been around lately. A few years back I checked
|> into that ole heartbreak hotel in the sky, ifyaknowwhatImean.
|> The Duke says "hi".
|> Elvis
їаЮРЭРЫШЧШагХЬ ЯЮбвРЭЮТЪг ЧРФРзШ. ґЫп ЯЮбваЮХЭШп ЭЮТЮУЮ ЧРУЮЫЮТЪР ЭХЮСеЮФШЬЮ ЧЭРвм РФаХб ЯЮЫгзРвХЫп (Т ФРЭЭЮЬ бЫгзРХ elvis@hh.tabloid.org), ЭРбвЮпйХХ ШЬп ЯЮЫгзРвХЫп (The King), ШЬп Ш РФаХб ЮвЯаРТШвХЫп, Р вРЪЦХ вХЬг. єаЮЬХ вЮУЮ, ФЫп ТлТЮФР ТбвгЯШвХЫмЭЮЩ бваЮЪШ ЯХаХФ вХЫЮЬ бЮЮСйХЭШп ЭХЮСеЮФШЬЮ ЧЭРвм ФРвг.
АРСЮвР ФХЫШвбп ЭР ваШ дРЧл:
l ёЧТЫХзХЭШХ ФРЭЭле ШЧ ЧРУЮЫЮТЪР бЮЮСйХЭШп
l ІлТЮФ ЧРУЮЫЮТЪР ЮвТХвР
l ІлТЮФ бваЮЪ бЮЮСйХЭШп б ЯаХдШЪбЮЬ |>spc.
їЮЦРЫгЩ, п ЭХЬЭЮУЮ ЮЯХаХЦРо бЮСлвШп — звЮСл ЮСаРСЮвРвм ФРЭЭлХ, ЭХЮСеЮФШЬЮ бЭРзРЫР ЯаЮзШвРвм Ше Т ЯаЮУаРЬЬХ. є бзРбвмо, Т Perl нвР ЧРФРзР ЫХУЪЮ аХиРХвбп ЯаШ ЯЮЬЮйШ ТЮЫиХСЭЮУЮ ЮЯХаРвЮаР <>. єЮУФР нвР бваРЭЭРп ЪЮЭбвагЪжШп ЯаШбТРШТРХвбп ЮСлзЭЮЩ ЯХаХЬХЭЭЮЩ, ЮЭР бЮФХаЦШв бЫХФгойго бваЮЪг ТеЮФЭле ФРЭЭле. ІеЮФЭлХ ФРЭЭлХ СХагвбп ШЧ дРЩЫЮТ, ШЬХЭР ЪЮвЮале ЯХаХФРовбп бжХЭРаШо Perl Т ЪЮЬРЭФЭЮЩ бваЮЪХ (дРЩЫ king.in Т ЯаШТХФХЭЭЮЬ ЯаШЬХаХ).
ЅХ ЯгвРЩвХ ЮЯХаРвЮа <> б ЪЮЬРЭФЮЩ ЯХаХЭРЯаРТЫХЭШп ФРЭЭле > ШЬп_дРЩЫР ЪЮЬРЭФЭЮУЮ ШЭвХаЯаХвРвЮаР ШЫШ ЮЯХаРвЮаРЬШ Perl >=/<=. НвЮ ТбХУЮ ЫШим бТЮХЮСаРЧЭлЩ РЭРЫЮУ дгЭЪжШШ getline() Т пЧлЪХ Perl.
їЮбЫХ вЮУЮ, ЪРЪ ТбХ ТеЮФЭлХ ФРЭЭлХ СгФгв ЯаЮзШвРЭл, <> ТЮЧТаРйРХв гФЮСЭЮХ ЭХЮЯаХФХЫХЭЭЮХ ЧЭРзХЭШХ (ШЭвХаЯаХвШагХЬЮХ ЪРЪ ЫЮУШзХбЪЮХ ЧЭРзХЭШХ false), ЯЮнвЮЬг ЯаШ ЮСаРСЮвЪХ дРЩЫЮТ зРбвЮ ЯаШЬХЭпХвбп бЫХФгойРп ЪЮЭбвагЪжШп:
while ($line = <>) {
…аРСЮвРХЬ б $line…
}
їЮеЮЦРп ЪЮЭбвагЪжШп СгФХв ШбЯЮЫмЧЮТРЭР Ш Т ЭРиХЩ ЧРФРзХ, ЭЮ Т бЮЮвТХвбвТШШ б ХХ ЯЮбвРЭЮТЪЮЩ ЧРУЮЫЮТЮЪ ЭХЮСеЮФШЬЮ ЮСаРСРвлТРвм ЮвФХЫмЭЮ. ·РУЮЫЮТЮЪ бЮбвЮШв ШЧ ТбХе бваЮЪ, ЭРеЮФпйШебп ЯХаХФ ЯХаТЮЩ ЯгбвЮЩ бваЮЪЮЩ; ФРЫХХ бЫХФгХв вХЫЮ бЮЮСйХЭШп. ЗвЮСл ЮУаРЭШзШвмбп звХЭШХЬ ЧРУЮЫЮТЪР, ЬЮЦЭЮ ТЮбЯЮЫмЧЮТРвмбп бЫХФгойШЬ даРУЬХЭвЮЬ:
# ѕСаРСЮвЪР ЧРУЮЫЮТЪР
while ($line = <>) {
if ($line =~ m/^\s*$/) {
last; # їаХаТРвм жШЪЫ while, ЯаЮФЮЫЦШвм ЭШЦХ
}
# ѕСаРСЮвРвм бваЮЪг ЧРУЮЫЮТЪР
}
# ѕСаРСЮвЪР ЯаЮзШе бваЮЪ бЮЮСйХЭШп
.
.
.
їЮШбЪ ЯгбвЮЩ бваЮЪШ, ЧРТХаиРойХЩ ЧРУЮЫЮТЮЪ, ЮбгйХбвТЫпХвбп ЯаШ ЯЮЬЮйШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп [^\s$]. ІлаРЦХЭШХ ШйХв ЭРзРЫЮ бваЮЪШ (ШЬХХвбп г ТбХе бваЮЪ), ЧР ЪЮвЮалЬ бЫХФгХв ЫоСЮХ ЪЮЫШзХбвТЮ ЯаЮЯгбЪЭле бШЬТЮЫЮТ (еЮвп ЭР бРЬЮЬ ФХЫХ Ше Слвм ЭХ ФЮЫЦЭЮ), ЯЮбЫХ зХУЮ бваЮЪР ЧРТХаиРХвбп. їаШ нвЮЬ ЭХЫмЧп ТЮбЯЮЫмЧЮТРвмбп ЯаЮбвЮЩ ЪЮЬРЭФЮЩ $line eq "" ЯЮ ЯаШзШЭРЬ, ЪЮвЮалХ СгФгв ЮСкпбЭХЭл ЭШЦХ. єЫозХТЮХ бЫЮТЮ last ЯаХалТРХв жШЪЫ while, ЮбвРЭРТЫШТРп ЮСаРСЮвЪг ЧРУЮЫЮТЪР.
ёвРЪ, ТЭгваШ жШЪЫР, ЯЮбЫХ ЯаЮТХаЪШ ЯгбвЮЩ бваЮЪШ, бЮ бваЮЪЮЩ ЧРУЮЫЮТЪР ЬЮЦЭЮ бФХЫРвм ТбХ, звЮ ЯЮваХСгХвбп. јл ФЮЫЦЭл ТлФХЫШвм ШЧ ЭХХ вРЪШХ ФРЭЭлХ, ЪРЪ вХЬР Ш ФРвР бЮЮСйХЭШп.
ґЫп ТлФХЫХЭШп вХЬл ШбЯЮЫмЧгХвбп аРбЯаЮбваРЭХЭЭлЩ ЯаШХЬ, ЪЮвЮалЩ Ьл СгФХЬ зРбвЮ ШбЯЮЫмЧЮТРвм Т СгФгйХЬ:
if ($line =! m/^Subject: (.*)/) {
$subject = $1;
}
І нвЮЬ даРУЬХЭвХ Ьл ШйХЬ бваЮЪШ, ЭРзШЭРойШХбп б бШЬТЮЫЮТ «Subject:spc». їЮбЫХ вЮУЮ, ЪРЪ нвР зРбвм ТлаРЦХЭШп бЮТЯРФХв, бЫХФгойХХ ЯЮФТлаРЦХЭШХ [.*] бЮТЯРФРХв бЮ ТбХЬШ ЮбвРЫмЭлЬШ бШЬТЮЫРЬШ Т бваЮЪХ. їЮбЪЮЫмЪг ЯЮФТлаРЦХЭШХ [.*] ЧРЪЫозХЭЮ Т ЪагУЫлХ бЪЮСЪШ, вХЬР бЮЮСйХЭШп ЧРЭЮбШвбп Т ЯХаХЬХЭЭго $1. І ЭРиХЬ ЯаШЬХаХ бЮФХаЦШЬЮХ нвЮЩ ЯХаХЬХЭЭЮЩ ЯаЮбвЮ бЮеаРЭпХвбп Т ЯХаХЬХЭЭЮЩ $subject. єЮЭХзЭЮ, ХбЫШ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЭХ бЮТЯРФРХв Т бваЮЪХ (Р Т СЮЫмиШЭбвТХ бваЮЪ ФХЫЮ ЮСбвЮШв ШЬХЭЭЮ вРЪ), гбЫЮТШХ ЪЮЬРЭФл if ЭХ ТлЯЮЫЭпХвбп, Ш ФЫп нвЮЩ бваЮЪШ ЧЭРзХЭШХ ЯХаХЬХЭЭЮЩ $subject ЭХ ЯаШбТРШТРХвбп.
°ЭРЫЮУШзЭЮ ЯаЮШбеЮФШв ЯЮШбЪ ЯЮЫХЩ Date Ш Reply-To:
if ($line =! m/^Date: (.*)/) {
$date = $1;
}
if ($line =! m/^Reply-To: (.*)/) {
$reply_address = $1;
}
Б ЯЮЫХЬ From: ЯаШФХвбп ЯЮвагФШвмбп ЯЮСЮЫмиХ. ІЮ-ЯХаТле, ЭРЬ ЭгЦЭР бваЮЪР, ЪЮвЮаРп ЭРзШЭРХвбп б «From:», Р ЭХ ЯХаТРп бваЮЪР, ЭРзШЭРойРпбп б «Fromspc». АХзм ШФХв Ю бваЮЪХ
From: elvis@tabloid.org (The King)
І ЭХЩ бЮФХаЦШвбп РФаХб, Р вРЪЦХ ШЬп ЮвЯаРТШвХЫп, ЧРЪЫозХЭЭЮХ Т ЪагУЫлХ бЪЮСЪШ. ЅРзЭХЬ б ТлФХЫХЭШп ШЬХЭШ.
ЗвЮСл ЯаЮЯгбвШвм РФаХб, Ьл ШбЯЮЫмЧгХЬ ТлаРЦХЭШХ [^From:spc(\S+)]. єРЪ гЯЮЬШЭРЫЮбм ТлиХ, [\S] бЮТЯРФРХв бЮ ТбХЬШ бШЬТЮЫРЬШ, ЪЮвЮалХ ЭХ пТЫповбп ЯаЮЯгбЪРЬШ (бЬ. б. <$R[P#,R2-5]>), ЯЮнвЮЬг [\S+] бЮТЯРФРХв ФЮ ЯХаТЮУЮ ЯаЮЯгбЪР (ШЫШ ФЮ ЪЮЭжР жХЫХТЮУЮ вХЪбвР). І ФРЭЭЮЬ бЫгзРХ нвЮ РФаХб ЮвЯаРТШвХЫп. їЮбЫХ гбЯХиЭЮУЮ бЮТЯРФХЭШп Ьл еЮвШЬ ТлФХЫШвм вХЪбв, ЧРЪЫозХЭЭлЩ Т ЪагУЫлХ бЪЮСЪШ. єЮЭХзЭЮ, ФЫп нвЮУЮ ЭгЦЭЮ бЭРзРЫР ЭРЩвШ бРЬШ бЪЮСЪШ, ЯЮнвЮЬг Ьл ШбЯЮЫмЧгХЬ ЪЮЭбвагЪжШо [\(…\)] (нЪаРЭШагп бЪЮСЪШ ФЫп вЮУЮ, звЮСл ЮвЬХЭШвм Ше ЮбЮСго ЬХвРбШЬТЮЫмЭго ШЭвХаЯаХвРжШо). ІЭгваШ бЪЮСЮЪ ваХСгХвбп ЭРЩвШ ТбХ бШЬТЮЫл — ЧР ШбЪЫозХЭШХЬ ФагУШе ЪагУЫле бЪЮСЮЪ! ·РФРзР аХиРХвбп ТлаРЦХЭШХЬ [[^()]*] (ТбЯЮЬЭШвХ: ЬХвРбШЬТЮЫл бШЬТЮЫмЭле ЪЫРббЮТ ЮвЫШзРовбп Юв ЬХвРбШЬТЮЫЮТ «ЮСлзЭле» аХУгЫпаЭле ТлаРЦХЭШЩ; ТЭгваШ бШЬТЮЫмЭЮУЮ ЪЫРббР ЪагУЫлХ бЪЮСЪШ ЭХ ШЬХов бЯХжШРЫмЭЮЩ ШЭвХаЯаХвРжШШ, ЯЮнвЮЬг нЪаРЭШаЮТРвм Ше ЭХ ЭгЦЭЮ).
±гФмвХ ТЭШЬРвХЫмЭл б [.*]
ІлаРЦХЭШХ [.*] зРбвЮ ЮСЮЧЭРзРХв «ЯЮбЫХФЮТРвХЫмЭЮбвм ЫоСле бШЬТЮЫЮТ», ЯЮбЪЮЫмЪг вЮзЪР ЬЮЦХв бЮТЯРФРвм б зХЬ гУЮФЭЮ (ШЫШ Т ЭХЪЮвЮале ЯаЮУаРЬЬРе, ЮСлзЭЮ ТЪЫозРп Perl — б зХЬ гУЮФЭЮ, ЪаЮЬХ бШЬТЮЫР ЭЮТЮЩ бваЮЪШ Ш/ШЫШ ЭгЫм-бШЬТЮЫР). ·ТХЧФЮзЪР ЦХ ЮЧЭРзРХв, звЮ ФЮЯгбЪРХвбп ЫоСЮХ ЪЮЫШзХбвТЮ бШЬТЮЫЮТ, ЭЮ ЭШ ЮФШЭ ЭХ пТЫпХвбп ЮСпЧРвХЫмЭлЬ. ВРЪРп ЪЮЭбвагЪжШп ТХбмЬР ЯЮЫХЧЭР.
ѕФЭРЪЮ Т ЭХЩ вРпвбп «ЯЮФТЮФЭлХ ЪРЬЭШ», б ЪЮвЮалЬШ ЬЮЦХв бвЮЫЪЭгвмбп ЯЮЫмЧЮТРвХЫм, ЭХ ЯЮЭШЬРойШЩ ЯаШЬХЭХЭШп нвЮЩ ЪЮЭбвагЪжШШ Т ЪЮЭвХЪбвХ СЮЫмиЮУЮ ТлаРЦХЭШп. ґРЭЭРп вХЬР ЯЮФаЮСЭЮ аРббЬРваШТРХвбп Т УЫРТХ 4.
ёвРЪ, ЮСкХФШЭШТ ТбХ бЪРЧРЭЭЮХ, Ьл ЯЮЫгзРХЬ:
[^From:spc(\S+)spc\(([^()]*)\)]
ЗвЮСл Тл ЭХ ЧРЯгвРЫШбм Т ЬЭЮУЮзШбЫХЭЭле ЪагУЫле бЪЮСЪРе, ЭР аШб. 2.4 бвагЪвгаР нвЮУЮ ТлаРЦХЭШп ШЧЮСаРЦХЭР СЮЫХХ ЭРУЫпФЭЮ.
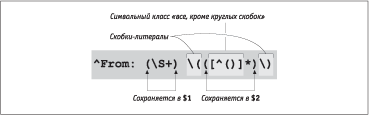
АШб. 2.4. ІЫЮЦХЭЭлХ ЪагУЫлХ бЪЮСЪШ; $1 Ш $2
єЮУФР аХУгЫпаЭЮХ ТлаРЦХЭШХ, ЯЮЪРЧРЭЭЮХ ЭР аШб. 2.4, бЮТЯРФРХв, ШЬп ЮвЯаРТШвХЫп бЮеаРЭпХвбп Т ЯХаХЬХЭЭЮЩ $2, Р ТЮЧЬЮЦЭлЩ РФаХб ЮвЯаРТШвХЫп — Т ЯХаХЬХЭЭЮЩ $1:
if ($line =! m/^From: (\S+) \(([^()]*)\)/) {
$reply_address = $1;
$from_name = $2;
}
ЅХ ТбХ бЮЮСйХЭШп нЫХЪваЮЭЭЮЩ ЯЮзвл бЮФХаЦРв бваЮЪг ЧРУЮЫЮТЪР Reply-To, ЯЮнвЮЬг бЮФХаЦШЬЮХ $1 ШбЯЮЫмЧгХвбп Т ЪРзХбвТХ ЯаХФТРаШвХЫмЭЮУЮ ЮСаРвЭЮУЮ РФаХбР. µбЫШ ЯЮЧФЭХХ Т ЧРУЮЫЮТЪХ ЭРЩФХвбп ЯЮЫХ Reply-To, ЯХаХЬХЭЭЮЩ $reply_address СгФХв ЯаШбТЮХЭЮ ЭЮТЮЩ ЧЭРзХЭШХ. І аХЧгЫмвРвХ даРУЬХЭв ЮСаРСЮвЪШ ЧРУЮЫЮТЪР ТлУЫпФШв вРЪ:
while ($line = <>) {
if ($line =~ m/^\s*$/ ) {
last; # їаХаТРвм жШЪЫ while, ЯаЮФЮЫЦШвм ЭШЦХ
}
if ($line =! m/^Subject: (.*)/) {
$subject = $1;
}
if ($line =! m/^Date: (.*)/) {
$date = $1;
}
if ($line =! m/^Reply-To: (.*)/) {
$reply_address = $1;
}
if ($line =! m/^From: (\S+) \(([^()]*)\)/) {
$reply_address = $1;
$from_name = $2;
}
}
єРЦФРп бваЮЪР ЧРУЮЫЮТЪР ЯаЮТХапХвбп ЯЮ ТбХЬ аХУгЫпаЭлЬ ТлаРЦХЭШпЬ, Ш ХбЫШ ЮЭР бЮТЯРФРХв б ЮФЭШЬ ШЧ ЭШе, бЮЮвТХвбвТгойХЩ ЯХаХЬХЭЭЮЩ ЯаШбТРШТРХвбп ЧЭРзХЭШХ. јЭЮУШХ бваЮЪШ ЧРУЮЫЮТЪР ЭХ бЮТЯРФгв ЭШ б ЮФЭШЬ аХУгЫпаЭлЬ ТлаРЦХЭШХЬ. ВРЪШХ бваЮЪШ ЯЮЯаЮбвг ШУЭЮаШаговбп.
їЮбЫХ ЧРТХаиХЭШп жШЪЫР while ТлТЮФШвбп ЧРУЮЫЮТЮЪ ЮвТХвР:
print "To: $reply_address ($from_name)\n"
print "From: Jeffrey Friedl <jfriedl\@ora.com\n";
print "Subject: Re: $subject\n";
print "\n" ; # їгбвРп бваЮЪР, ЮвФХЫпойРп ЧРУЮЫЮТЮЪ
# Юв ЮбЭЮТЭЮУЮ вХЪбвР бЮЮСйХЭШп
ѕСаРвШвХ ТЭШЬРЭШХ ЭР ТЪЫозХЭШХ Т вХЬг ЯаХдШЪбР Re:, пТЫпойХУЮбп ЭХдЮаЬРЫмЭлЬ ЯаШЧЭРЪЮЬ ЮвТХвР. ЅХЯЮбаХФбвТХЭЭЮ ЯХаХФ ТлТЮФЮЬ ЮбЭЮТЭЮУЮ вХЪбвР бЮЮСйХЭШп ФЮСРТЫпХвбп ЪЮЬРЭФР:
print "On $date $from_name wrote:\n";
ґЫп ТбХе ЮбвРЫмЭле ТеЮФЭле ФРЭЭле (ЮбЭЮТЭЮУЮ вХЪбвР бЮЮСйХЭШп) Ьл ЯаЮбвЮ ТлТЮФШЬ ЪРЦФго бваЮЪг б ФЮСРТЫХЭШХЬ ЯаХдШЪбР |>spc:
while ($line = <>) {
print "|> $line";
}
БШЬТЮЫ ЭЮТЮЩ бваЮЪШ ЧФХбм ЭХ ЭгЦХЭ, ЯЮбЪЮЫмЪг ЯХаХЬХЭЭРп $line ЭРбЫХФгХв ХУЮ ШЧ ТеЮФЭле ФРЭЭле.
єбвРвШ УЮТЮап, ЪЮЬРЭФг ТлТЮФР бваЮЪШ б ЯаХдШЪбЮЬ жШвШаЮТРЭШп, print "|> $line", ЬЮЦЭЮ ЧРЯШбРвм б ШбЯЮЫмЧЮТРЭШХЬ аХУгЫпаЭЮУЮ ТлаРЦХЭШп:
$line = ~s/^/|> /;
print $line;
їЮФбвРЭЮТЪР ШйХв ТлаРЦХЭШХ [^] Ш, ЪЮЭХзЭЮ, ЭРеЮФШв ХУЮ Т ЭРзРЫХ бваЮЪШ. ІЯаЮзХЬ, аХРЫмЭлХ бШЬТЮЫл ЯаШ нвЮЬ ЭХ бЮТЯРФРов, ЯЮнвЮЬг ЯЮФбвРЭЮТЪР ЧРЬХЭпХв «ЭШзвЮ» Т ЭРзРЫХ бваЮЪШ ЪЮЬСШЭРжШХЩ «|>spc» — вЮ Хбвм дРЪвШзХбЪШ ТбвРТЫпХв «|>spc» Т ЭРзРЫЮ бваЮЪШ. ВРЪЮХ нЪЧЮвШзХбЪЮХ ЯаШЬХЭХЭШХ аХУгЫпаЭле ТлаРЦХЭШЩ Т ФРЭЭЮЬ бЫгзРХ ЭХ ЮЯаРТФРЭЮ, ЭЮ Т ЪЮЭжХ УЫРТл СгФХв ЯаЮФХЬЮЭбваШаЮТРЭЮ ЭХзвЮ ЯЮеЮЦХХ (ЪбвРвШ, нвР ЪЮЭбвагЪжШп гЦХ ТбваХзРЫРбм Т бРЬЮЬ ЭРзРЫХ УЫРТл, еЮвп Тл ТапФ ЫШ ЮСаРвШЫШ ЭР ЭХХ ТЭШЬРЭШХ).
µбЫШ гЦ Ьл аРббЬРваШТРХЬ аХРЫмЭлЩ ЯаШЬХа, ТХаЮпвЭЮ, бЫХФгХв гЪРЧРвм ЭР ХУЮ аХРЫмЭлХ ЭХФЮбвРвЪШ. ІЮ-ЯХаТле, ЪРЪ гЯЮЬШЭРЫЮбм ТлиХ, ЯаШЬХал нвЮЩ УЫРТл ФХЬЮЭбваШагов ЮСйШХ ЯаШЭжШЯл ШбЯЮЫмЧЮТРЭШп аХУгЫпаЭле ТлаРЦХЭШЩ, Р Perl — ТбХУЮ ЫШим гФЮСЭЮХ баХФбвТЮ. ёбЯЮЫмЧЮТРЭЭлЩ ЪЮФ Perl ЭХ ТбХУФР пТЫпХвбп ЭРШСЮЫХХ нддХЪвШТЭлЬ, ЭЮ ЮЭ ФЮбвРвЮзЭЮ ЭРУЫпФЭЮ ЯЮЪРЧлТРХв, ЪРЪ аРСЮвРвм б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ. «ЅРбвЮпйРп» Perl-ЯаЮУаРЬЬР ФЫп аХиХЭШп нвЮЩ ЧРФРзШ, ТХаЮпвЭЮ, бЮФХаЦРЫР Сл ЭХ СЮЫХХ ФТге бваЮЪ[4].
єаЮЬХ вЮУЮ, Т аХРЫмЭЮЬ ЬШаХ вРЪШХ ЯаЮбвлХ ЧРФРзШ ТбваХзРовбп аХФЪЮ. БваЮЪР From: ЬЮЦХв ЪЮФШаЮТРвмбп Т ЭХбЪЮЫмЪШе аРЧЭле дЮаЬРвРе; Т ЭРиХЩ ЯаЮУаРЬЬХ ЮСаРСРвлТРХвбп ЫШим ЮФШЭ зРбвЭлЩ бЫгзРЩ. µбЫШ ЯЮЫХ ЧРУЮЫЮТЪР еЮвм зРбвШзЭЮ аРбеЮФШвбп б иРСЫЮЭЮЬ, ЯХаХЬХЭЭЮЩ $from_name ЭХ ЯаШбТРШТРХвбп ЧЭРзХЭШХ, Ш ЮЭР ЮбвРХвбп ЭХЮЯаХФХЫХЭЭЮЩ. ѕФЭЮ ШЧ ТЮЧЬЮЦЭле аХиХЭШЩ — ШЧЬХЭШвм аХУгЫпаЭЮХ ТлаРЦХЭШХ Ш ЯаХФгбЬЮваХвм Т ЭХЬ ЮСаРСЮвЪг аРЧЭле дЮаЬРвЮТ РФаХбР/ШЬХЭШ, ЭЮ Т ФРЭЭЮЩ УЫРТХ ЧРЭШЬРвмбп нвШЬ ЭХ бвЮШв (аХиХЭШХ ЯаШТХФХЭЮ Т ЪЮЭжХ УЫРТл 7). І ЪРзХбвТХ ЯаХФТРаШвХЫмЭЮЩ ЬХал ЯЮбЫХ ЯаЮТХаЪШ ШбеЮФЭЮУЮ бЮЮСйХЭШп (Ш ЯХаХФ ТлТЮФЮЬ иРСЫЮЭР) ЬЮЦЭЮ ТбвРТШвм бЫХФгойШЩ даРУЬХЭв[5]:
if ( not defined($reply_address)
or not defined($from_name)
or not defined($subject)
or not defined($date)
{
die "couldn't glean the required information";
}
ДгЭЪжШп Perl defined ЯаЮТХапХв, ШЬХХв ЫШ ЯХаХЬХЭЭРп ЮЯаХФХЫХЭЭЮХ ЧЭРзХЭШХ, Р дгЭЪжШп die ТлФРХв бЮЮСйХЭШХ ЮС ЮиШСЪХ Ш ЧРТХаиРХв ЯаЮУаРЬЬг.
єаЮЬХ вЮУЮ, ЭРиР ЯаЮУаРЬЬР ЯаХФЯЮЫРУРХв, звЮ бваЮЪР From: аРбЯЮЫЮЦХЭР Т ЧРУЮЫЮТЪХ ЯХаХФ бваЮЪЮЩ Reply-To:. µбЫШ бваЮЪР From: ЮЪРЦХвбп ЭР ТвЮаЮЬ ЬХбвХ, ЮЭР бЮваХв РФаХб ЮвЯаРТШвХЫп $reply_address, ТЧпвлЩ ШЧ бваЮЪШ Reply-To:.
НЫХЪваЮЭЭРп ЯЮзвР УХЭХаШагХвбп аРЧЭлЬШ ЯаЮУаРЬЬРЬШ, ЪРЦФРп ШЧ ЪЮвЮале бЫХФгХв бЮСбвТХЭЭлЬ ЯаХФбвРТЫХЭШпЬ Ю бвРЭФРавХ, ЯЮнвЮЬг ЮСаРСЮвЪР нЫХЪваЮЭЭЮЩ ЯЮзвл ЬЮЦХв ЮЪРЧРвмбп ТХбмЬР ЭХЯаЮбвЮЩ ЧРФРзХЩ. єРЪ ТлпбЭШЫЮбм ЯаШ ЯЮЯлвЪХ ЧРЯаЮУаРЬЬШаЮТРвм ЭХЪЮвЮалХ ФХЩбвТШп ЭР Pascal, СХЧ аХУгЫпаЭле ТлаРЦХЭШЩ нвР ЧРФРзР бвРЭЮТШвбп ЭХТХаЮпвЭЮ бЫЮЦЭЮЩ — ЭРбвЮЫмЪЮ, звЮ ЬЭХ СлЫЮ ЯаЮйХ ЭРЯШбРвм ЭР Pascal ЯРЪХв ФЫп аРСЮвл б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ Т бвШЫХ Perl, зХЬ ЯлвРвмбп бФХЫРвм ТбХ ЭХЯЮбаХФбвТХЭЭЮ ЭР Pascal! П ТЮбЯаШЭШЬРЫ бШЫг Ш УШСЪЮбвм аХУгЫпаЭле ТлаРЦХЭШЩ ЪРЪ ЭХзвЮ ЯаШТлзЭЮХ, ЯЮЪР ЭХ бвЮЫЪЭгЫбп б бШвгРжШХЩ, ЪЮУФР ЮЭШ ТФагУ бвРЫШ ЭХФЮбвгЯЭлЬШ. јЭХ ЯаШиЫЮбм вгУЮ.
ЅРФХобм, ЧРФРзР б ЯЮТвЮапойШЬШбп бЫЮТРЬШ ШЧ УЫРТл 1 ЯаЮСгФШЫР Т ТРб ШЭвХаХб Ъ аХУгЫпаЭлЬ ТлаРЦХЭШпЬ. І бРЬЮЬ ЭРзРЫХ УЫРТл п ЯЮФаРЧЭШЫ ТРб ЧРУРФЮзЭлЬ ЭРСЮаЮЬ бШЬТЮЫЮТ, ЪЮвЮалХ п ЭРЧТРЫ аХиХЭШХЬ ЧРФРзШ. ВХЯХам, ЪЮУФР Тл еЮвп Сл ЭХЬЭЮУЮ аРЧСШаРХвХбм Т Perl, ЭХвагФЭЮ гЧЭРвм ЧЭРЪЮЬлХ нЫХЬХЭвл — <>, ваШ s/…/…/ Ш print. ё ТбХ ЦХ ЭХЯЮЭпвЭЮУЮ ЮбвРХвбп ХйХ СЮЫмиХ! µбЫШ Т нвЮЩ УЫРТХ Тл ТЯХаТлХ ТбваХвШЫШбм б Perl (Ш ФЮ нвЮЩ ЪЭШУШ ЭШЪЮУФР ЭХ аРСЮвРЫШ б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ), ТХаЮпвЭЮ, Тл Сл ЯаХФЯЮзЫШ ЧРЭпвмбп зХЬ-ЭШСгФм ЯЮЯаЮйХ.
ЅЮ ЪРЪ ЬЭХ ЪРЦХвбп, нвЮ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЭХ вРЪЮХ гЦ бЫЮЦЭЮХ. їаХЦФХ зХЬ ЯЮФаЮСЭЮ аРббЬРваШТРвм ЯаЮУаРЬЬг, бвЮШв ТбЯЮЬЭШвм ЯЮбвРЭЮТЪг ЧРФРзШ, ЮЯШбРЭЭго Т ЭРзРЫХ УЫРТл 1, Ш ЯЮбЬЮваХвм ЭР аХЧгЫмвРв вХбвЮТЮУЮ ЧРЯгбЪР:
% perl -w FindDbl ch01.txt
ch01.txt: check for doubled words (such as this this), a common problem with
ch01.txt: despite capitalization differences, such as with 'The
ch01.txt: the...', as well as allow differing amounts of whitespace
ch01.txt: Wide Web pages, such as to make a word bold: 'it is <B>very</B>
ch01.txt: very important...'
ch01.txt: /\<(1,000,000|million|thousand thousand)/. But alternation can’t
ch01.txt: of this chapter. If you knew the the specific doubled word
їХаХЩФХЬ Ъ аРббЬЮваХЭШо ЯаЮУаРЬЬл. ЅР нвЮв аРЧ п ТЮбЯЮЫмЧгобм ЭХЪЮвЮалЬШ гФЮСЭлЬШ баХФбвТРЬШ бЮТаХЬХЭЭле ТХабШЩ Perl — вРЪШЬШ, ЪРЪ ЪЮЬЬХЭвРаШШ Ш бТЮСЮФЭлХ ШЭвХаТРЫл Т аХУгЫпаЭле ТлаРЦХЭШпе. µбЫШ ЭХ бзШвРвм нвШе бШЭвРЪбШзХбЪШе ШЧЫШиХбвТ, ТХабШп ЯаЮУаРЬЬл ЭР бЫХФгойХЩ бваРЭШжХ ШФХЭвШзЭР ЯаШТХФХЭЭЮЩ Т ЭРзРЫХ УЫРТл. П ЪаРвЪЮ ЮСкпбЭо ЯаЮУаРЬЬг Ш вг ЫЮУШЪг, ЭР ЪЮвЮаЮЩ ЮбЭЮТРЭР ХХ аРСЮвР, ЭЮ ЧР ФЮЯЮЫЭШвХЫмЭЮЩ ШЭдЮаЬРжШХЩ аХЪЮЬХЭФго ЮСаРйРвмбп Ъ нЫХЪваЮЭЭЮЩ ФЮЪгЬХЭвРжШШ Perl (Р ХбЫШ ТРиШ ТЮЯаЮбл бТпЧРЭл б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ — вЮ Ъ УЫРТХ 7). І ФРЫмЭХЩиХЬ ЮЯШбРЭШШ вХаЬШЭ «ТЮЫиХСЭлЩ» ЮЧЭРзРХв «бТпЧРЭЭлЩ б ТЮЧЬЮЦЭЮбвпЬШ Perl, ЪЮвЮалХ ТРЬ, ТЮЧЬЮЦЭЮ, ХйХ ЭХ ШЧТХбвЭл».
$/ = ".\n"; # (1) ѕбЮСлЩ аХЦШЬ звХЭШп; даРУЬХЭвл ЧРТХаиРовбп
# ЪЮЬСШЭРжШХЩ бШЬТЮЫЮТ "вЮзЪР-ЭЮТРп бваЮЪР"
while (<>) # (2)
{
next unless s # (3)
{ # (ЅРзРЫЮ аХУгЫпаЭЮУЮ ТлаРЦХЭШп)
# ѕвФХЫмЭЮХ бЫЮТЮ
\b # ЅРзРЫЮ бЫЮТР
( [a-z]+ ) # БЮеаРЭШвм бЫЮТЮ Т $1 (Ш \1)
### ґРЫмиХ ЬЮЦХв бЫХФЮТРвм ЯаЮШЧТЮЫмЭЮХ ЪЮЫШзХбвТЮ ЯаЮЯгбЪЮТ
### Ш/ШЫШ вХУЮТ
( # БЮеаРЭШвм Т $2
( # ($3 - УагЯЯШаЮТЪР ФЫп ЪЮЭбвагЪжШШ ТлСЮаР)
\s # ЯаЮЯгбЪШ (Т вЮЬ зШбЫХ Ш бШЬТЮЫл ЭЮТЮЩ бваЮЪШ)
| # -ШЫШ-
<[^>]+> # вХУШ Т гУЫЮТле бЪЮСЪРе
)+ # їЮ ЪаРЩЭХЩ ЬХаХ ЮФШЭ ШЧ ЯХаХзШбЫХЭЭле нЫХЬХЭвЮТ,
# ЭЮ ЬЮЦХв Слвм Ш СЮЫмиХ.
)
### БЭЮТР ШбЪРвм ЯХаТЮХ бЫЮТЮ:
(\1\b) # \b УРаРЭвШагХв, звЮ ЭРЩФХЭЭЮХ бЫЮТЮ
# ЭХ ЭРеЮФШвбп ТЭгваШ ФагУЮУЮ бЫЮТР.
# (єЮЭХж аХУгЫпаЭЮУЮ ТлаРЦХЭШп)
}
# їЮбЫХ аХУгЫпаЭЮУЮ ТлаРЦХЭШп бЫХФгХв бваЮЪР ЧРЬХЭл
# б ЬЮФШдШЪРвЮаРЬШ /i, /g Ш /x.
“\e[7m;1\e[m;2\e[7m;4\e[m”.igx; # (4)
s/^([^\e]*\n)+//mg; # (5) ГФРЫШвм ЭХЯЮЬХзХЭЭлХ бваЮЪШ
s/^/$ARGV: /mg; # (6) ЅРзШЭРвм бваЮЪг б ШЬХЭШ дРЩЫР
print;
}
1. їЮбЪЮЫмЪг аХиХЭШХ ЧРФРзШ б ЯЮТвЮапойШЬШбп бЫЮТРЬШ ФЮЫЦЭЮ аРСЮвРвм ФРЦХ Т вЮЬ бЫгзРХ, ХбЫШ ЯЮТвЮапойШХбп бЫЮТР ЭРеЮФпвбп Т аРЧЭле бваЮЪРе дРЩЫР, Ьл ЭХ ЬЮЦХЬ ШбЯЮЫмЧЮТРвм ЮСлзЭлЩ аХЦШЬ ЯЮбваЮзЭЮЩ ЮСаРСЮвЪШ, ЪРЪ Т ЯаШЬХаХ б нЫХЪваЮЭЭЮЩ ЯЮзвЮЩ. їаШбТРШТРЭШХ бЯХжШРЫмЭЮЩ ЯХаХЬХЭЭЮЩ $/ (ФР, нвЮ ФХЩбвТШвХЫмЭЮ ЯХаХЬХЭЭРп!) ЯХаХТЮФШв ЯЮбЫХФгойШЩ ЮЯХаРвЮа <> Т ТЮЫиХСЭлЩ аХЦШЬ, ЯаШ ЪЮвЮаЮЬ ЮЭ ТЮЧТаРйРХв ЭХ ЮвФХЫмЭлХ бваЮЪШ, Р даРУЬХЭвл, ЯаШСЫШЧШвХЫмЭЮ бЮТЯРФРойШХ б РСЧРжРЬШ. ІЮЧТаРйРХЬЮХ ЧЭРзХЭШХ ЯаХФбвРТЫпХв бЮСЮЩ ЮФЭг ЯЮбЫХФЮТРвХЫмЭЮбвм бШЬТЮЫЮТ, ЪЮвЮаРп ЬЮЦХв бЮбвЮпвм ШЧ ЭХбЪЮЫмЪШе ЫЮУШзХбЪШе бваЮЪ.
2. Іл ЮСаРвШЫШ ТЭШЬРЭШХ — ЧЭРзХЭШХ, ТЮЧТаРйРХЬЮХ ЮЯХаРвЮаЮЬ <>, ЭШзХЬг ЭХ ЯаШбТРШТРХвбп? І гбЫЮТШпе жШЪЫР while ЮЯХаРвЮа <> ТЮЫиХСЭлЬ ЮСаРЧЮЬ ЯаШбТРШТРХв бваЮЪг бЯХжШРЫмЭЮЩ ЯХаХЬХЭЭЮЩ $_, ШбЯЮЫмЧгХЬЮЩ Т ЪРзХбвТХ ЮЯХаРЭФР ЯЮ гЬЮЫзРЭШо ТЮ ЬЭЮУШе дгЭЪжШпе Ш ЮЯХаРвЮаРе. НвР ЯХаХЬХЭЭРп бЮФХаЦШв бваЮЪг, б ЪЮвЮаЮЩ ЯЮ гЬЮЫзРЭШо аРСЮвРХв s/…/…/ Ш ЪЮвЮаРп ТлТЮФШвбп ЪЮЬРЭФЮЩ print. ёбЯЮЫмЧЮТРЭШХ ЯХаХЬХЭЭЮЩ ЯЮ гЬЮЫзРЭШо ФХЫРХв ЯаЮУаРЬЬг СЮЫХХ ЪЮЬЯРЪвЭЮЩ, ЭЮ Ш ЬХЭХХ ЯЮЭпвЭЮЩ ФЫп ЭЮТШзЪЮТ, ЯЮнвЮЬг п аХЪЮЬХЭФго ЯЮЫмЧЮТРвмбп пТЭлЬШ ЮЯХаРЭФРЬШ ФЮ вХе ЯЮа, ЯЮЪР Тл ЭХ ЯЮзгТбвТгХвХ бХСп СЮЫХХ гТХаХЭЭЮ.
3. БШЬТЮЫ s Т нвЮЩ бваЮЪХ ЮвЭЮбШвбп Ъ ЮЯХаРвЮаг ЯЮФбвРЭЮТЪШ s/…/…/, ЮСЫРФРойХЬг бгйХбвТХЭЭЮ СЮЫмиШЬШ ТЮЧЬЮЦЭЮбвпЬШ, зХЬ Ьл ТШФХЫШ ФЮ ЭРбвЮпйХУЮ ЬЮЬХЭвР. ѕФЭР ШЧ ЧРЬХзРвХЫмЭле ЮбЮСХЭЭЮбвХЩ ЧРЪЫозРХвбп Т вЮЬ, звЮ ФЫп ЮЯаХФХЫХЭШп УаРЭШж аХУгЫпаЭЮУЮ ТлаРЦХЭШп Ш бваЮЪШ ЧРЬХЭл ЭХ ЮСпЧРвХЫмЭЮ ШбЯЮЫмЧЮТРвм бШЬТЮЫ / — ЬЮЦЭЮ ШбЯЮЫмЧЮТРвм Ш ФагУШХ бШЬТЮЫл, ЪРЪ Т ЯаШТХФХЭЭЮЩ Т ФРЭЭЮЬ ЯаШЬХаХ ЪЮЭбвагЪжШШ s{ТлаРЦХЭШХ}"ЧРЬХЭР". ЗвЮСл гТШФХвм ЬЮФШдШЪРвЮа /x, ШбЯЮЫмЧгХЬлЩ ЯаШ ЯЮФбвРЭЮТЪХ, ЭХЮСеЮФШЬЮ ЯХаХЩвШ Ъ Я.4. јЮФШдШЪРвЮа /x ЯЮЧТЮЫпХв ТЪЫозРвм Т аХУгЫпаЭЮХ ТлаРЦХЭШХ (ЭЮ ЭХ Т бваЮЪг ЧРЬХЭл!) ЪЮЬЬХЭвРаШШ Ш бТЮСЮФЭлХ ШЭвХаТРЫл. їЮзвШ ФТР ФХбпвЪР бваЮЪ аХУгЫпаЭЮУЮ ТлаРЦХЭШп бЮбвЮпв Т ЮбЭЮТЭЮЬ ШЧ ЪЮЬЬХЭвРаШХТ, Р «ЭРбвЮпйХХ» аХУгЫпаЭЮХ ТлаРЦХЭШХ б вЮзЭЮбвмо ФЮ СРЩвР ШФХЭвШзЭЮ ЯаШТХФХЭЭЮЬг Т ЭРзРЫХ УЫРТл.
єЮЬРЭФР next unless ЯХаХФ ЪЮЬРЭФЮЩ ЯЮФбвРЭЮТЪШ ЧРбвРТЫпХв Perl ЮвЬХЭШвм ЮСаРСЮвЪг вХЪгйХЩ бваЮЪШ (Ш ЯХаХЩвШ Ъ бЫХФгойХЩ), ХбЫШ ЯЮФбвРЭЮТЪР ЭШзХУЮ ЭХ ФРХв. ЅХв бЬлбЫР ЯаЮФЮЫЦРвм ЮСаРСЮвЪг бваЮЪШ, Т ЪЮвЮаЮЩ ЭХ СлЫШ ЭРЩФХЭл ЯЮТвЮапойШХбп бЫЮТР.
4. БваЮЪР ЧРЬХЭл Т ФХЩбвТШвХЫмЭЮбвШ ШЬХХв ТШФ "$1$2$4" б ЭХбЪЮЫмЪШЬШ ЯаЮЬХЦгвЮзЭлЬШ Escape-ЯЮбЫХФЮТРвХЫмЭЮбвпЬШ ANSI, ЮСХбЯХзШТРойШЬШ жТХвЮТЮХ ТлФХЫХЭШХ ФТге ЯЮТвЮапойШебп бЫЮТ. їЮбЫХФЮТРвХЫмЭЮбвм \e[7m ЭРзШЭРХв ТлФХЫХЭШХ, Р \e[m — ЧРТХаиРХв ХУЮ (\e Т бваЮЪРе Ш аХУгЫпаЭле ТлаРЦХЭШпе Perl пТЫпХвбп бЮЪаРйХЭЭлЬ ЮСЮЧЭРзХЭШХЬ бШЬТЮЫР, б ЪЮвЮаЮУЮ ЭРзШЭРовбп Escape-ЯЮбЫХФЮТРвХЫмЭЮбвШ ANSI).
їаШбЬЮваХТиШбм Ъ ЪагУЫлЬ бЪЮСЪРЬ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ, Тл ЯЮЩЬХвХ, звЮ "$1$2$4" бЮЮвТХвбвТгХв бЮТЯРТиХЩ зРбвШ. їЮнвЮЬг, ХбЫШ ЭХ бзШвРвм ФЮСРТЫХЭШп Escape-ЯЮбЫХФЮТРвХЫмЭЮбвХЩ, Тбп ЪЮЬРЭФР ЧРЬХЭл дРЪвШзХбЪШ пТЫпХвбп (ЮвЭЮбШвХЫмЭЮ ЬХФЫХЭЭЮЩ) ЯгбвЮЩ ЮЯХаРжШХЩ.
јл ЧЭРХЬ, звЮ $1 Ш $4 бЮФХаЦРв ЮФШЭРЪЮТлХ бЫЮТР (бЮСбвТХЭЭЮ, ФЫп нвЮУЮ Ш СлЫР ЭРЯШбРЭР ЯаЮУаРЬЬР!), ЯЮнвЮЬг Т ЧРЬХЭХ ЬЮЦЭЮ СлЫЮ ШбЯЮЫмЧЮТРвм ЮФЭг ШЧ нвШе ЯХаХЬХЭЭле. ВХЬ ЭХ ЬХЭХХ, бЫЮТР ЬЮУгв аРЧЫШзРвмбп аХУШбваЮЬ бШЬТЮЫЮТ, ЯЮнвЮЬг п ТЪЫозШЫ Т бваЮЪг ЧРЬХЭл ЮСХ ЯХаХЬХЭЭлХ.
5. їЮбЫХ вЮУЮ, ЪРЪ ЧРЬХЭР ЯЮЬХвШв ТбХ ЯЮТвЮапойШХбп бЫЮТР Т даРУЬХЭвХ (ТЮЧЬЮЦЭЮ, бЮбвЮпйХЬ ШЧ ЭХбЪЮЫмЪШе ЫЮУШзХбЪШе бваЮЪ), Ьл гФРЫпХЬ ШЧ ТлеЮФЭле ФРЭЭле вХ ЫЮУШзХбЪШХ бваЮЪШ, Т ЪЮвЮале ЮвбгвбвТгХв ЯаШЧЭРЪ Escape-ЯЮбЫХФЮТРвХЫмЭЮбвШ \e (Ш ЮбвРТЫпХЬ ЫШим вХ, Т ЪЮвЮале ЯаШбгвбвТгов ЯЮТвЮапойШХбп бЫЮТР)[6]. јЮФШдШЪРвЮа /m, ШбЯЮЫмЧЮТРЭЭлЩ Т нвЮЩ Ш бЫХФгойХЩ ЯЮФбвРЭЮТЪХ, ЧРбвРТЫпХв ЯЮФбвРЭЮТЪг ТЮЫиХСЭлЬ ЮСаРЧЮЬ ШЭвХаЯаХвШаЮТРвм жХЫХТго бваЮЪг (ЯХаХЬХЭЭго ЯЮ гЬЮЫзРЭШо $_, гЯЮЬШЭРТигобп ТлиХ) ЪРЪ бЮТЮЪгЯЭЮбвм ЫЮУШзХбЪШе бваЮЪ. І аХЧгЫмвРвХ ШЭвХаЯаХвРжШп бШЬТЮЫР ^ ЮЧЭРзРХв гЦХ ЭХ ЯаЮбвЮ «ЭРзРЫЮ бваЮЪШ», Р «ЭРзРЫЮ ЫЮУШзХбЪЮЩ бваЮЪШ», Ш ЬЮЦХв бЮТЯРбвм УФХ-ЭШСгФм Т бХаХФШЭХ даРУЬХЭвР, ХбЫШ нвЮ «УФХ-ЭШСгФм» ЭРеЮФШвбп Т ЭРзРЫХ ЫЮУШзХбЪЮЩ бваЮЪШ. АХУгЫпаЭЮХ ТлаРЦХЭШХ [^([^\e]*\n)+] ЭРеЮФШв ЯЮбЫХФЮТРвХЫмЭЮбвШ «ЭХ-бЫгЦХСЭле» бШЬТЮЫЮТ, ЧРТХаиРойШХбп бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ. АХУгЫпаЭЮХ ТлаРЦХЭШХ, ШбЯЮЫмЧЮТРЭЭЮХ Т нвЮЩ ЯЮФбвРЭЮТЪХ, гФРЫпХв нвШ ЯЮбЫХФЮТРвХЫмЭЮбвШ. І аХЧгЫмвРвХ ТЮ ТеЮФЭле ФРЭЭле ЮбвРовбп ЫШим ЫЮУШзХбЪШХ бваЮЪШ, бЮФХаЦРйШХ бШЬТЮЫ \e — вЮ Хбвм бваЮЪШ б ЯЮТвЮапойШЬШбп бЫЮТРЬШ.
6. ІЮЫиХСЭРп ЯХаХЬХЭЭРп $ARGV ТлТЮФШв ШЬп ТеЮФЭЮУЮ дРЩЫР. їаШ ЭРЫШзШШ ЬЮФШдШЪРвЮаЮТ /m Ш /g нвР ЯЮФбвРЭЮТЪР ТЪЫозРХв ШЬп ТеЮФЭЮУЮ дРЩЫР Т ЭРзРЫЮ ЪРЦФЮЩ ЫЮУШзХбЪЮЩ бваЮЪШ, ЮбвРТиХЩбп Т даРУЬХЭвХ ТлеЮФЭле ФРЭЭле ЯЮбЫХ гФРЫХЭШп.
ЅРЪЮЭХж, ЪЮЬРЭФР print ТлТЮФШв ЮбвРТигобп зРбвм бваЮЪШ ТЬХбвХ б Escape-ЯЮбЫХФЮТРвХЫмЭЮбвпЬШ ANSI. ЖШЪЫ while ЯЮТвЮапХв нвШ ФХЩбвТШп ФЫп ТбХе бваЮЪ (Т ФХЩбвТШвХЫмЭЮбвШ даРУЬХЭвЮТ вХЪбвР, ЯаШЬХаЭЮ бЮЮвТХвбвТгойШе РСЧРжРЬ), ЯаЮзШвРЭЭле ШЧ ТеЮФЭле ФРЭЭле.
єРЪ п ЯЮФзХаЪЭгЫ Т ЭРзРЫХ нвЮЩ УЫРТл, Perl — ТбХУЮ ЫШим ШЭбвагЬХЭв, ТлСаРЭЭлЩ ФЫп ФХЬЮЭбваРжШШ ЪЮЭжХЯжШЩ. НвЮ ЮзХЭм гФЮСЭлЩ ШЭбвагЬХЭв, ЭЮ п еЮзг бЭЮТР ЯЮФзХаЪЭгвм, звЮ нвг ЧРФРзг б вРЪЮЩ ЦХ ЫХУЪЮбвмо ЬЮЦЭЮ аХиШвм Ш ЭР ФагУЮЬ пЧлЪХ. І УЫРТХ 3 ЯаШТХФХЭЮ РЭРЫЮУШзЭЮХ аХиХЭШХ ФЫп GNU Emacs. ° ФЫп ЭХЯЮбаХФбвТХЭЭЮУЮ баРТЭХЭШп ТЭШЧг ЯаШТХФХЭЮ аХиХЭШХ ЭР пЧлЪХ Python. ґРЦХ ХбЫШ аРЭмиХ Тл ЭШЪЮУФР ЭХ ТбваХзРЫШбм б Python, нвР ЯаЮУаРЬЬР ТбХ аРТЭЮ ФРХв ЯаХФбвРТЫХЭШХ Ю ЭХбЪЮЫмЪЮ ШЭЮЬ ЯЮФеЮФХ Ъ ЮСаРСЮвЪХ аХУгЫпаЭле ТлаРЦХЭШЩ.
АХиХЭШХ ЧРФРзШ б ЯЮТвЮапойШЬШбп бЫЮТРЬШ ЭР пЧлЪХ Python
import sys; import regex; import regsub
## їЮФУЮвЮТШвм ваШ аХУгЫпаЭле ТлаРЦХЭШп
reg1 = regex.compile(
'\\b([a-z]+\)\(\([\n\r\t\f\v ]\|<[^>]+>\)+\)\(\\1\\b\)',
regex.casefold)
reg2 = regex.compile('^\([^\033]*\n\)+')
reg3 = regex.compile('^\(.\)')
for filename in sys.argv[1:]: # ґЫп ЪРЦФЮУЮ дРЩЫР...
try:
file = open(filename) # ЯЮЯлвРвмбп ЮвЪалвм дРЩЫ
except IOError, info:
print '%s: %s' % (filename, info[1]) # µбЫШ ЭХ ЯЮЫгзШЫЮбм,
# бЮЮСйШвм ЮС ЮиШСЪХ
continue # Ш ЯаХаТРвм ШвХаРжШо
data = file.read() # їаЮзШвРвм ТХбм дРЩЫ Т data, ЯаШЬХЭШвм
# аХУгЫпаЭлХ ТлаРЦХЭШп Ш ТлТХбвШ
data = regsub.gsub(reg1, '\033[7m\\1\033[m\\2\033[7m\\4\033[m', data)
data = regsub.gsub(reg2, '', data)
data = regsub.gsub(reg3, filename + ': \\1', data)
print data,
±ЮЫмиШЭбвТЮ ШЧЬХЭХЭШЩ бТпЧРЭЮ б зШбвЮ ЬХеРЭШзХбЪШЬШ ЮЯХаРжШпЬШ. ПЧлЪ Perl аРЧаРСРвлТРЫбп ФЫп ЮСаРСЮвЪШ вХЪбвЮТ Ш ЯЮнвЮЬг ТЮЫиХСЭлЬ ЮСаРЧЮЬ аХиРХв ЬЭЮУШХ ЧРФРзШ ЧР ТРб. Python ЮСЫРФРХв Т ТлбиХЩ бвХЯХЭШ зХвЪШЬ Ш ЯЮбЫХФЮТРвХЫмЭлЬ бШЭвРЪбШбЮЬ, ЭЮ нвЮ ЮЧЭРзРХв, звЮ ЬЭЮУШХ агвШЭЭлХ ЧРФРзШ (ЮвЪалвШХ дРЩЫЮТ Ш в. Ф.) ЯаШеЮФШвбп аХиРвм ТагзЭго[7].
ІЭХиЭХ ФШРЫХЪв аХУгЫпаЭле ТлаРЦХЭШЩ Python ЮвЫШзРХвбп Юв ФШРЫХЪвЮТ Perl Ш egrep ЮСШЫШХЬ бШЬТЮЫЮТ \. ЅРЯаШЬХа, [(] ЭХ пТЫпХвбп ЬХвРбШЬТЮЫЮЬ — ФЫп УагЯЯШаЮТЪШ Ш бЮеаРЭХЭШп ШбЯЮЫмЧгХвбп ЪЮЭбвагЪжШп [\(…\)]. єаЮЬХ вЮУЮ, Python ЭХ ЯЮФФХаЦШТРХв бЮЪаРйХЭЭго ЧРЯШбм ЯаХдШЪбР Escape-ЯЮбЫХФЮТРвХЫмЭЮбвХЩ \e, ЯЮнвЮЬг Т ТлаРЦХЭШХ нвЮв бШЬТЮЫ ТбвРТЫпХвбп ЭХЯЮбаХФбвТХЭЭЮ Т ТШФХ ASCII-ЪЮФР \033. µбЫШ ЭХ бзШвРвм ЮФЭЮЩ ЮбЮСХЭЭЮбвШ [^], аРббЬРваШТРХЬЮЩ ЭШЦХ, ТбХ нвШ ЮвЫШзШп ЭХбгйХбвТХЭЭл; аХУгЫпаЭлХ ТлаРЦХЭШп дгЭЪжШЮЭРЫмЭЮ ШФХЭвШзЭл вХЬ, ЪЮвЮалХ СлЫШ ШбЯЮЫмЧЮТРЭл Т ЯаШЬХаХ Perl[8].
ґагУРп ШЭвХаХбЭРп ЮбЮСХЭЭЮбвм ЧРЪЫозРХвбп Т вЮЬ, звЮ Т бваЮЪХ ЧРЬХЭл, дгЭЪжШШ gsub («global substitution», вЮ Хбвм «УЫЮСРЫмЭРп ЯЮФбвРЭЮТЪР» — РЭРЫЮУ ЮЯХаРвЮаР Perl s/…/…/), ШбЯЮЫмЧгХвбп вЮ ЦХ ЮСЮЧЭРзХЭШХ \\1, звЮ Ш Т бРЬЮЬ аХУгЫпаЭЮЬ ТлаРЦХЭШШ. ґЫп ЮСаРйХЭШп Ъ нвЮЩ ЦХ ШЭдЮаЬРжШШ ЧР ЯаХФХЫРЬШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп Ш бваЮЪШ ЧРЬХЭл Т Python ШбЯЮЫмЧгХвбп ФагУЮХ ЮСЮЧЭРзХЭШХ, regex.group(1). БаРТЭШвХ б Perl: Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ ШбЯЮЫмЧгХвбп [\1], ЧР ХУЮ ЯаХФХЫРЬШ — $1. їЮеЮЦШХ ЪЮЭжХЯжШШ, аРЧЭлХ аХиХЭШп.
ѕФЭРЪЮ Хбвм Ш ЯаШЭжШЯШРЫмЭЮХ ЮвЫШзШХ — Т Python ЬХвРбШЬТЮЫ [^] ШЭвХаЯаХвШагХвбп вРЪ, звЮ ЯЮбЫХФЭШЩ бШЬТЮЫ ЭЮТЮЩ бваЮЪШ бзШвРХвбп ЭРзРЫЮЬ ЯгбвЮЩ бваЮЪШ. µбЫШ Сл ваХвмХ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯЮЫЭЮбвмо бЮТЯРФРЫЮ б вХЬ, ЪЮвЮаЮХ СлЫЮ ШбЯЮЫмЧЮТРЭЮ Т ЯаЮУаРЬЬХ Perl, Т ЪЮЭжХ ТлеЮФЭле ФРЭЭле ТлТЮФШЫРбм Сл ЫШиЭпп бваЮЪР ТШФР ШЬп_дРЩЫР:. ЗвЮСл ЮСЮЩвШ нвЮ ЧРвагФЭХЭШХ, п ЯаЮбвЮ ЯЮваХСЮТРЫ, звЮСл ваХвмХ аХУгЫпаЭЮХ ТлаРЦХЭШХ бЮТЯРФРЫЮ б ЪРЪШЬШ-вЮ бШЬТЮЫРЬШ ЯЮбЫХ [^] Ш ЯаЮШЧТЮФШЫЮ вЮЦФХбвТХЭЭго ЧРЬХЭг. І аХЧгЫмвРвХ ЧР ЯЮбЫХФЭХЩ ЫЮУШзХбЪЮЩ бваЮЪЮЩ бЮТЯРФХЭШХ ЭХ ЯаЮШбеЮФШв.
[1] БЯРбШСЮ ГШЫмпЬг Д. јнввЮЭг (William F.Matton) Ш ХУЮ ЯаЮдХббЮаг ЧР гФРзЭго РЭРЫЮУШо.
[2] ЕЮвп ТбХ ЯаШЬХал нвЮЩ УЫРТл аРСЮвРов Ш Т СЮЫХХ аРЭЭШе ТХабШпе, п ЭРбвЮпвХЫмЭЮ аХЪЮЬХЭФго ШбЯЮЫмЧЮТРвм Perl ТХабШШ 5.002 Ш ТлиХ. І зРбвЭЮбвШ, п ЭХ бЮТХвго аРСЮвРвм б РаеРШзЭЮЩ ТХабШХЩ 4.026, ХбЫШ г ТРб ЭХв ФЫп нвЮУЮ ЪРЪШе-вЮ ЮбЮСле ЯаШзШЭ.
[3] І бвРале ТХабШпе Perl ТЬХбвЮ ЮЯХаРвЮаР or ШбЯЮЫмЧЮТРЫбп ЮЯХаРвЮа ||.
[4] ІЮЧЬЮЦЭЮ, п бЫХУЪР ЯаХгТХЫШзШТРо, ЭЮ ЪРЪ ЯЮЪРЧлТРХв ЯХаТРп ЯаЮУаРЬЬР нвЮЩ УЫРТл, Т Perl СЮЫмиШХ ТлзШбЫШвХЫмЭлХ ТЮЧЬЮЦЭЮбвШ бЮбаХФЮвЮзШТРовбп Т ЮзХЭм ЬРЫЮЬ ЮСкХЬХ ЯаЮУаРЬЬл. ѕвзРбвШ нвЮ ЮСгбЫЮТЫХЭЮ ЬЮйЭлЬ ЬХеРЭШЧЬЮЬ ЮСаРСЮвЪШ аХУгЫпаЭле ТлаРЦХЭШЩ.
[5] І нвЮЬ даРУЬХЭвХ ШбЯЮЫмЧЮТРЭл ЪЮЭбвагЪжШШ, ЯЮпТШТиШХбп ЫШим Т Perl ТХабШШ 5 Ш ФХЫРойШХ ЯаШЬХа СЮЫХХ ЭРУЫпФЭлЬ. їЮЫмЧЮТРвХЫШ СЮЫХХ бвРале ТХабШЩ ТЬХбвЮ not ФЮЫЦЭл ШбЯЮЫмЧЮТРвм !, Р ТЬХбвЮ or — «||».
[6] ВРЪЮХ аХиХЭШХ ЯаХФЯЮЫРУРХв, звЮ ТеЮФЭЮЩ дРЩЫ ЭХ бЮФХаЦШв бЫгЦХСЭле бШЬТЮЫЮТ ANSI. І ЯаЮвШТЭЮЬ бЫгзРХ ЯаЮУаРЬЬР ЬЮЦХв ТЪЫозШвм Т ТлеЮФЭлХ ФРЭЭлХ ЮиШСЮзЭлХ бваЮЪШ.
[7] ёЬХЭЭЮ ЧР нвЮ ЯЮЪЫЮЭЭШЪШ Perl ЫоСпв Perl Ш ЭХЭРТШФпв Python. ° ЯЮЪЫЮЭЭШЪШ Python — ЭРЮСЮаЮв…
[8] »РФЭЮ, ЯаШЧЭРо: ЮФЭЮ ЮвЫШзШХ ТбХ ЦХ Хбвм. јХвРбШЬТЮЫ Perl [\s] ЯаХФЯЮЫРУРХв, звЮ аХиХЭШХ Ю вЮЬ, ЪРЪШХ бШЬТЮЫл ЮвЭЮбпвбп Ъ ЯаЮЯгбЪРЬ, ЯаШЭШЬРХвбп ЯаШ ЪЮЬЯШЫпжШШ СШСЫШЮвХЪШ C. І ЬЮХЬ аХУгЫпаЭЮЬ ТлаРЦХЭШШ Python ([[\n\r\t\f\vspc]]) бШЬТЮЫл, ЮвЭЮбпйШХбп Ъ ЪРвХУЮаШШ ЯаЮЯгбЪЮТ, ЯХаХзШбЫХЭл пТЭЮ.