їЮбваЮХЭШХ аХУгЫпаЭле ТлаРЦХЭШЩ
ГЯаРТЫпХЬлЩ аХУгЫпаЭлЬ ТлаРЦХЭШХЬ ЬХеРЭШЧЬ Ѕє° ТбваХзРХвбп Т Perl, Tcl, Expect, Python Ш ЭХЪЮвЮале ТХабШпе grep, awk, egrep Ш sed (бЯШбЮЪ ФРЫХЪЮ ЭХ ЯЮЫЮЭ). ІбЫХФбвТШХ ЯаШаЮФл нвЮУЮ ЬХеРЭШЧЬР ЭХЧЭРзШвХЫмЭлХ ШЧЬХЭХЭШп Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ ЬЮУгв ШЬХвм УЫЮСРЫмЭлХ ЯЮбЫХФбвТШп ФЫп вЮУЮ, ЪРЪЮХ бЮТЯРФХЭШХ СгФХв ЭРЩФХЭЮ Ш ЪРЪ СгФХв ЯаЮШбеЮФШвм ЯаЮжХбб ЯЮШбЪР. їаЮСЫХЬл, ЪЮвЮалХ Т ЬХеРЭШЧЬХ ґє° ЯЮЯаЮбвг ЭХбгйХбвТХЭЭл, Т Ѕє° ТлеЮФпв ЭР ЯХаТлЩ ЯЫРЭ. ІЮЧЬЮЦЭЮбвШ вЮзЭЮЩ аХУгЫШаЮТЪШ ЬХеРЭШЧЬР Ѕє° ЯЮЧТЮЫпов вТЮаШвм ТлаРЦХЭШп, еЮвп ФЫп ЭХЯЮбТпйХЭЭле нвЮ ЯЮаЮЩ ТлЧлТРХв ЭХЬРЫЮ ЯаЮСЫХЬ. ЅРбвЮпйРп УЫРТР ЯЮЬЮЦХв ТРЬ ЮТЫРФХвм нвШЬ ШбЪгббвТЮЬ.
ЅРиР жХЫм — ЯаРТШЫмЭЮбвм Ш нддХЪвШТЭЮбвм. НвЮ ЮЧЭРзРХв, звЮ ТлаРЦХЭШХ ФЮЫЦЭЮ ЭРеЮФШвм ШЬХЭЭЮ вЮ, звЮ ЭгЦЭЮ, Ш ЯаШвЮЬ СлбваЮ. їаРТШЫмЭЮбвм аРббЬРваШТРЫРбм Т ЯаХФлФгйХЩ УЫРТХ. І нвЮЩ УЫРТХ СгФгв аРббЬЮваХЭл ТЮЯаЮбл нддХЪвШТЭЮбвШ ЬХеРЭШЧЬР Ѕє° Ш вЮ, ЪРЪ ЮСаРвШвм Ше Т бТЮо ЯЮЫмЧг (вРЬ, УФХ нвЮ гЬХбвЭЮ, СгФХв ЯаШТХФХЭР Ш ШЭдЮаЬРжШп Ю ґє°, ЭЮ нвР УЫРТР Т ЯХаТго ЮзХаХФм ЯЮбТпйХЭР ЬХеРЭШЧЬРЬ Ѕє° Ш ТЮЯаЮбРЬ Ше нддХЪвШТЭЮбвШ). іЫРТЭЮХ, звЮ ФЫп нвЮУЮ ЭгЦЭЮ — ФЮбЪЮЭРЫмЭЮХ ЯЮЭШЬРЭШХ ТЮЧТаРвР Ш гЬХЭШХ ШЧСХУРвм ХУЮ вРЬ, УФХ нвЮ ТЮЧЬЮЦЭЮ. јл аРббЬЮваШЬ ЭХЪЮвЮалХ ЯаРЪвШзХбЪШХ ЯаШХЬл ЭРЯШбРЭШп нддХЪвШТЭле ТлаРЦХЭШЩ, ЪЮвЮалХ ЭХ вЮЫмЪЮ гбЪЮапов Ше аРСЮвг, ЭЮ ЯаШ еЮаЮиХЬ ЯЮЭШЬРЭШШ ЬХеРЭШЪШ Ше ЮСаРСЮвЪШ ЯЮЬЮУгв ТРЬ бЮЧФРТРвм СЮЫХХ бЫЮЦЭлХ ТлаРЦХЭШп.
іЫРТР ЭРзШЭРХвбп б ЯЮФаЮСЭЮУЮ ЯаШЬХаР, ЪЮвЮалЩ ФХЬЮЭбваШагХв, ЭРбЪЮЫмЪЮ ТРЦЭлЬШ ЬЮУгв Слвм нвШ ЯаЮСЫХЬл. ·РвХЬ, звЮСл ЯЮФУЮвЮТШвмбп Ъ ТЮбЯаШпвШо СЮЫХХ бЫЮЦЭле ЯаШХЬЮТ, ЮЯШбРЭЭле ФРЫХХ, Ьл бЭЮТР аРббЬЮваШЬ СРЧЮТго ЯаЮжХФгаг ТЮЧТаРвР, ЮЯШбРЭЭго Т ЯаХФлФгйХЩ УЫРТХ, б гЯЮаЮЬ ЭР нддХЪвШТЭЮбвм Ш УЫЮСРЫмЭлХ ЯЮбЫХФбвТШп ТЮЧТаРвР. ґРЫХХ аРббЬРваШТРовбп ЭХЪЮвЮалХ бвРЭФРавЭлХ ЯаШХЬл ТЭгваХЭЭХЩ ЮЯвШЬШЧРжШШ, бЯЮбЮСЭлХ ФЮТЮЫмЭЮ ЧРЬХвЭЮ ТЫШпвм ЭР нддХЪвШТЭЮбвм, Ш ЮбЮСХЭЭЮбвШ ЯЮбваЮХЭШп ТлаРЦХЭШЩ ФЫп вХе аХРЫШЧРжШЩ, Т ЪЮвЮале нвШ ЯаШХЬл ШбЯЮЫмЧговбп. ЅРЪЮЭХж, ТбХ бЪРЧРЭЭЮХ ЮСкХФШЭпХвбп Т ЭХбЪЮЫмЪШе гСЮЩЭле ЯаШХЬРе, ЪЮвЮалХ ЯЮЬЮУгв ТРЬ ЪЮЭбвагШаЮТРвм заХЧТлзРЩЭЮ нддХЪвШТЭлХ аХУгЫпаЭлХ ТлаРЦХЭШп Ѕє°.
єРЪ Ш ТЮ ЬЭЮУШе УЫРТРе нвЮЩ ЪЭШУШ, ЯаШТХФХЭЭлХ ЯаШЬХал ТбХУЮ ЫШим ФХЬЮЭбваШагов ЮСйШХ бШвгРжШШ, ТЮЧЭШЪРойШХ ЯаШ ШбЯЮЫмЧЮТРЭШШ аХУгЫпаЭле ТлаРЦХЭШЩ. °ЭРЫШЧШагп нддХЪвШТЭЮбвм ЪЮЭЪаХвЭЮУЮ ЯаШЬХаР, п зРбвЮ ЯаШТЮЦг зШбЫЮ ЮвФХЫмЭле ЯаЮТХаЮЪ, ШбЯЮЫмЧгХЬле ЬХеРЭШЧЬЮЬ аХУгЫпаЭле ТлаРЦХЭШЩ ЯаШ ЯЮШбЪХ бЮТЯРФХЭШп. ЅРЯаШЬХа, ЯаШ ЯЮШбЪХ [marty] Т бваЮЪХ smarty ЯаЮШбеЮФШв иХбвм ЮвФХЫмЭле ЯаЮТХаЮЪ — бЭРзРЫР [m] баРТЭШТРХвбп б s (ЭХгФРзР), ЧРвХЬ [m] баРТЭШТРХвбп б m, [a] б a Ш в. Ф. (ТбХ нвШ ЯаЮТХаЪШ ЯаЮеЮФпв гбЯХиЭЮ). П вРЪЦХ зРбвЮ бЮЮСйРо ЪЮЫШзХбвТЮ ТЮЧТаРвЮТ (Т ФРЭЭЮЬ ЯаШЬХаХ ЮФШЭ — ЭХпТЭлЩ ТЮЧТаРв ФЫп ЯЮТвЮаЭЮУЮ ЯаШЬХЭХЭШп аХУгЫпаЭЮУЮ ТлаРЦХЭШп бЮ ТвЮаЮУЮ бШЬТЮЫР).
П ЯаШТЮЦг нвШ ЪЮЭЪаХвЭлХ ТХЫШзШЭл ЭХ ЯЮвЮЬг, звЮ ЧФХбм вРЪ ТРЦЭР вЮзЭЮбвм, Р бЪЮаХХ ФЫп вЮУЮ, звЮСл ШЧСХЦРвм ШбЯЮЫмЧЮТРЭШп вгЬРЭЭле бЫЮТ «ЬЭЮУЮ», «ЬРЫЮ», «ЫгзиХ», «вХаЯШЬЮ» Ш в. Ф. ЅХ ЯЮФгЬРЩвХ, звЮ ШбЯЮЫмЧЮТРЭШХ аХУгЫпаЭле ТлаРЦХЭШЩ Т Ѕє° бТЮФШвбп Ъ ЯЮФбзХвг ЯаЮТХаЮЪ ШЫШ ТЮЧТаРвЮТ; п ЯаЮбвЮ еЮзг, звЮСл Тл ЯаХФбвРТЫпЫШ бХСХ ЯЮапФЮЪ нвШе ТХЫШзШЭ.
µйХ ЮФЭЮ ТРЦЭЮХ ЧРЬХзРЭШХ — Тл ФЮЫЦЭл ЯЮЭШЬРвм, звЮ нвШ «вЮзЭлХ» зШбЫР, ТХаЮпвЭЮ, Т аРЧЭле ЯаЮУаРЬЬРе СгФгв аРЧЭлЬШ. П ЯаШТЮЦг ЫШим СРЧЮТлХ ЯЮЪРЧРвХЫШ ФЫп вХе ЯаШЬХаЮТ, ЪЮвЮалХ, ЪРЪ п ЭРФХобм, ТРЬ ХйХ ЯаШУЮФпвбп. ѕФЭРЪЮ ЯаШеЮФШвбп гзШвлТРвм Ш ФагУЮЩ ТРЦЭлЩ дРЪвЮа — ЮЯвШЬШЧРжШо, ТлЯЮЫЭпХЬго ЪЮЭЪаХвЭЮЩ ЯаЮУаРЬЬЮЩ. ґЮбвРвЮзЭЮ «гЬЭРп» аХРЫШЧРжШп ЬЮЦХв ЯЮЫЭЮбвмо гбваРЭШвм ЯЮШбЪ ЪЮЭЪаХвЭЮУЮ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, ХбЫШ ЮЭР ЧРаРЭХХ аХиШв, звЮ ЮЭЮ Т ЫоСЮЬ бЫгзРХ ЭХ бЮТЯРФХв б ШЬХойХЩбп бваЮЪЮЩ (ЭРЯаШЬХа, ШЧ-ЧР ЮвбгвбвТШп Т бваЮЪХ ЭХЪЮвЮаЮУЮ бШЬТЮЫР, ЪЮвЮалЩ ЮСпЧРвХЫмЭЮ ФЮЫЦХЭ ЯаШбгвбвТЮТРвм Т ТЮЧЬЮЦЭЮЬ бЮТЯРФХЭШШ). јл аРббЬЮваШЬ ЭХЪЮвЮалХ ЯаШХЬл ЮЯвШЬШЧРжШШ Т нвЮЩ УЫРТХ, ЭЮ ЮСйШХ ЯаШЭжШЯл ТРЦЭХХ зРбвЭле бЫгзРХТ.
°ЭРЫШЧШагп нддХЪвШТЭЮбвм ТлаРЦХЭШп, бЫХФгХв гзШвлТРвм вШЯ ЬХеРЭШЧЬР ШбЯЮЫмЧгХЬЮЩ ЯаЮУаРЬЬл (ваРФШжШЮЭЭлЩ Ѕє° ШЫШ POSIX Ѕє°). єРЪ СгФХв ЯЮЪРЧРЭЮ Т бЫХФгойХЬ аРЧФХЫХ, ЭХЪЮвЮалХ ЯаЮСЫХЬл ЮвЭЮбпвбп ЫШим Ъ ЮФЭЮЬг ШЧ нвШе вШЯЮТ. ёЭЮУФР ШЧЬХЭХЭШХ, ЭХ ТЫШпойХХ ЭР ЮФШЭ ЬХеРЭШЧЬ, бШЫмЭЮ ЮваРЧШвбп ЭР аРСЮвХ ФагУЮУЮ. µйХ аРЧ ЯЮФзХаЪЭг, звЮ ЯЮЭШЬРЭШХ СРЧЮТле ЯаШЭжШЯЮТ ЯЮЬЮЦХв ТРЬ ЯаРТШЫмЭЮ ЮжХЭШТРвм ТбХ бШвгРжШШ ЯЮ ЬХаХ Ше ТЮЧЭШЪЭЮТХЭШп.
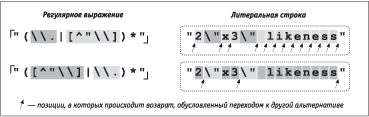
ЅРзЭХЬ б ЯаШЬХаР, ЪЮвЮалЩ ЭРУЫпФЭЮ ЯаЮФХЬЮЭбваШагХв, ЪРЪШЬШ ТРЦЭлЬШ ЬЮУгв Слвм ЯаЮСЫХЬл ТЮЧТаРвР Ш нддХЪвШТЭЮбвШ. І ЪЮЭжХ УЫРТл 4 Ьл ЯЮбваЮШЫШ ТлаРЦХЭШХ ["(\\.|[^"\\])*"] ФЫп ЯЮШбЪР бваЮЪ, ЧРЪЫозХЭЭле Т ЪРТлзЪШ. І бваЮЪХ ЬЮУгв ЯаШбгвбвТЮТРвм ТЭгваХЭЭШХ ЪРТлзЪШ, нЪаРЭШаЮТРЭЭлХ бШЬТЮЫЮЬ \ (бЬ. б. <$R[P#,R4-30]>). НвЮ аХУгЫпаЭЮХ ТлаРЦХЭШХ аРСЮвРХв, ЭЮ Т ЬХеРЭШЧЬХ Ѕє° ЪЮЭбвагЪжШп ТлСЮаР, ЯаШЬХЭпХЬРп Ъ ЪРЦФЮЬг бШЬТЮЫг, аРСЮвРХв ЪаРЩЭХ ЭХнддХЪвШТЭЮ. ґЫп ЪРЦФЮУЮ «ЮСлзЭЮУЮ» бШЬТЮЫР Т бваЮЪХ (ЭХ ЪРТлзЪШ Ш ЭХ нЪаРЭШаЮТРЭЭЮУЮ бШЬТЮЫР) ЬХеРЭШЧЬ ФЮЫЦХЭ ЯаЮТХаШвм [\\.], ЮСЭРагЦШвм ЭХгФРзг Ш ТХаЭгвмбп, звЮСл Т аХЧгЫмвРвХ ЭРЩвШ бЮТЯРФХЭШХ ФЫп [[^"\\]]. µбЫШ ТлаРЦХЭШХ ШбЯЮЫмЧгХвбп Т бШвгРжШШ, ЪЮУФР ТРЦЭР нддХЪвШТЭЮбвм, ЪЮЭХзЭЮ, еЮвХЫЮбм Сл ЭХЬЭЮУЮ гбЪЮаШвм ЮСаРСЮвЪг нвЮУЮ ТлаРЦХЭШп.
їЮбЪЮЫмЪг Т баХФЭХЩ бваЮЪХ, ЧРЪЫозХЭЭЮЩ Т ЪРТлзЪШ, ЮСлзЭле бШЬТЮЫЮТ СЮЫмиХ, зХЬ нЪаРЭШаЮТРЭЭле, ЭРЯаРиШТРХвбп ЯаЮбвЮХ ШЧЬХЭХЭШХ — ШЧЬХЭШвм ЯЮапФЮЪ РЫмвХаЭРвШТ Ш ЯЮбвРТШвм [[^"\\]] ЭР ЯХаТЮХ ЬХбвЮ, Р [\\.] — ЭР ТвЮаЮХ. µбЫШ [[^"\\]] бвЮШв ЭР ЯХаТЮЬ ЬХбвХ, вЮ ТЮЧТаРв ЯаЮШбеЮФШв ЫШим ЯаШ ЮСЭРагЦХЭШШ нЪаРЭШаЮТРЭЭЮУЮ бШЬТЮЫР Т бваЮЪХ (Ш, ЪЮЭХзЭЮ, ЯаШ ЭХбЮТЯРФХЭШШ *, ЯЮбЪЮЫмЪг ЪЮЭбвагЪжШп ТлСЮаР ЭХ бЮТЯРФРХв ЫШим Т вЮЬ бЫгзРХ, ХбЫШ ЭХ бЮТЯРФРов ТбХ РЫмвХаЭРвШТл). АШб. 5.1 ЭРУЫпФЭЮ ФХЬЮЭбваШагХв ЮвЫШзШп ЬХЦФг нвШЬШ ФТгЬп ТлаРЦХЭШпЬШ. ГЬХЭмиХЭШХ ЪЮЫШзХбвТР бваХЫЮЪ Т ЭШЦЭХЩ ЯЮЫЮТШЭХ ЮЧЭРзРХв, звЮ ФЫп ЯХаТЮЩ РЫмвХаЭРвШТл бЮТЯРФХЭШп ЭРеЮФпвбп зРйХ. НвЮ ЯаШТЮФШв Ъ гЬХЭмиХЭШо ЪЮЫШзХбвТР ТЮЧТаРвЮТ.
АШб. 5.1. ёЧЬХЭХЭШХ ЯЮапФЪР РЫмвХаЭРвШТ (ФЫп ваРФШжШЮЭЭЮУЮ Ѕє°)
ѕжХЭШТРп ЯЮбЫХФбвТШп вРЪЮУЮ ШЧЬХЭХЭШп ФЫп нддХЪвШТЭЮбвШ, ЭХЮСеЮФШЬЮ ЧРФРвм бХСХ ЭХбЪЮЫмЪЮ ЪЫозХТле ТЮЯаЮбЮТ:
l єРЪЮЩ ЬХеРЭШЧЬ ТлШУаРХв Юв нвШе ШЧЬХЭХЭШЩ — ваРФШжШЮЭЭлЩ Ѕє°, POSIX Ѕє° ШЫШ ЮСР?
l єЮУФР ШЧЬХЭХЭШХ ЯаШЭЮбШв ЭРШСЮЫмиго ЯЮЫмЧг — ЪЮУФР вХЪбв бЮТЯРФРХв, ЪЮУФР вХЪбв ЭХ бЮТЯРФРХв ШЫШ Т ЫоСЮЬ бЫгзРХ?
ref<$M[R5-1]>їЮФгЬРЩвХ ЭРФ нвШЬШ ТЮЯаЮбРЬШ, ЧРвХЬ ЯХаХТХаЭШвХ бваРЭШжг Ш ЯаЮТХамвХ бТЮШ ЮвТХвл. їаХЦФХ зХЬ ЯХаХеЮФШвм Ъ бЫХФгойХЬг аРЧФХЫг, гСХФШвХбм Т вЮЬ, звЮ Тл еЮаЮиЮ ЯЮЭШЬРХвХ бЬлбЫ ЮвТХвЮТ Ш Ше ЮСЮбЭЮТРЭШХ.
ёЧ аШб. 5.1 пбЭЮ ТШФЭЮ, звЮ Т ЮСЮШе бЫгзРпе ЪТРЭвШдШЪРвЮа * ФЮЫЦХЭ ЯЮбЫХФЮТРвХЫмЭЮ ЯХаХСаРвм ТбХ ЭЮаЬРЫмЭлХ бШЬТЮЫл, ЯаШ нвЮЬ ЮЭ бЭЮТР Ш бЭЮТР ТеЮФШв Т ЪЮЭбвагЪжШо ТлСЮаР (Ш ЪагУЫлХ бЪЮСЪШ) Ш ТлеЮФШв ШЧ ЭХХ. ІбХ нвШ ФХЩбвТШп бЮЯапЦХЭл б ЫШиЭХЩ аРСЮвЮЩ, Юв ЪЮвЮаЮЩ еЮвХЫЮбм Сл ЯЮ ТЮЧЬЮЦЭЮбвШ ШЧСРТШвмбп.
ѕФЭРЦФл, аРСЮвРп ЭРФ РЭРЫЮУШзЭлЬ ТлаРЦХЭШХЬ, п ТФагУ ЯЮЭпЫ, звЮ ТлаРЦХЭШХ ЬЮЦЭЮ ЮЯвШЬШЧШаЮТРвм, ХбЫШ гзХбвм, звЮ [[^"\\]] ЮвЭЮбШвбп Ъ ЭЮаЬРЫмЭлЬ бЫгзРпЬ. µбЫШ ШбЯЮЫмЧЮТРвм [[^"\\]+], ЮФЭР ШвХаРжШп (…)* ЯаЮзШвРХв ТбХ ЯЮбЫХФЮТРвХЫмЭЮ бвЮпйШХ ЮСлзЭлХ бШЬТЮЫл (ЭХ ЪРТлзЪШ Ш ЭХ нЪаРЭШаЮТРЭЭлХ бШЬТЮЫл). їаШ ЮвбгвбвТШШ нЪаРЭШаЮТРЭЭле бШЬТЮЫЮТ СгФХв ЯаЮзШвРЭР Тбп бваЮЪР. НвЮ ЯЮЧТЮЫпХв ЭРЩвШ бЮТЯРФХЭШХ ЯаРЪвШзХбЪШ СХЧ ТЮЧТаРвЮТ Ш бЮЪаРйРХв ЬЭЮУЮЪаРвЭЮХ ЯЮТвЮаХЭШХ * ФЮ РСбЮЫовЭЮУЮ ЬШЭШЬгЬР. П СлЫ ЮзХЭм ФЮТЮЫХЭ бТЮШЬ ЮвЪалвШХЬ.
їЮбЫХФбвТШп ЯаЮбвле ШЧЬХЭХЭШЩ
bref ѕвТХв ЭР ТЮЯаЮб бЮ б. <$R[P#,R5-1]>
ґЫп ЪРЪЮУЮ вШЯР ЬХеРЭШЧЬР? ёЧЬХЭХЭШХ ЯаРЪвШзХбЪШ ЭШЪРЪ ЭХ ЯЮТЫШпХв ЭР аРСЮвг ЬХеРЭШЧЬР POSIX Ѕє°. їЮбЪЮЫмЪг нвЮв ЬХеРЭШЧЬ Т ЫоСЮЬ бЫгзРХ ФЮЫЦХЭ ЮЯаЮСЮТРвм ТбХ ЪЮЬСШЭРжШШ нЫХЬХЭвЮТ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, ЯЮапФЮЪ ЯаЮТХаЪШ РЫмвХаЭРвШТ ЭХ ТРЦХЭ. ѕФЭРЪЮ Т ваРФШжШЮЭЭЮЬ Ѕє° ЯЮапФЮЪ РЫмвХаЭРвШТ, гбЪЮапойШЩ ЯЮШбЪ бЮТЯРФХЭШп, пТЫпХвбп ЯаХШЬгйХбвТЮЬ, ЯЮбЪЮЫмЪг ЬХеРЭШЧЬ ЬЮЦХв ЮбвРЭЮТШвмбп баРЧг ЦХ ЯЮбЫХ вЮУЮ, ЪРЪ СгФХв ЭРЩФХЭЮ ЯХаТЮХ бЮТЯРФХЭШХ.
ґЫп ЪРЪЮУЮ аХЧгЫмвРвР? ёЧЬХЭХЭШХ ЯаШТЮФШв Ъ гбЪЮаХЭШо ЯЮШбЪР ЫШим ЯаШ ЭРЫШзШШ бЮТЯРФХЭШп. Ѕє° ЬЮЦХв бФХЫРвм ТлТЮФ Ю ЭХгФРзХ вЮЫмЪЮ ЯЮбЫХ вЮУЮ, ЪРЪ СгФгв ЯаЮТХаХЭл ТбХ ТЮЧЬЮЦЭлХ ЪЮЬСШЭРжШШ (ЯЮТвЮапо — POSIX Ѕє° ЯаЮТХапХв Ше Т ЫоСЮЬ бЫгзРХ). БЫХФЮТРвХЫмЭЮ, ХбЫШ ЯЮЯлвЪР ЮЪРЦХвбп ЭХгФРзЭЮЩ, ЧЭРзШв, СлЫШ ЮЯаЮСЮТРЭл ТбХ ЪЮЬСШЭРжШШ, ЯЮнвЮЬг ЯЮапФЮЪ ЭХ ТРЦХЭ.
І бЫХФгойХЩ вРСЫШжХ ЯХаХзШбЫХЭЮ ЪЮЫШзХбвТЮ ЯаЮТХаЮЪ Ш ТЮЧТаРвЮТ ФЫп ЭХЪЮвЮале бЫгзРХТ (зХЬ ЬХЭмиХ зШбЫЮ, вХЬ ЫгзиХ):
|
ВХЪбв ЯаШЬХаР |
ВаРФШжШЮЭЭлЩ Ѕє° ["(\\.|[^"\\])*"] ЯаЮТ. ТЮЧТа. |
ВаРФШжШЮЭЭлЩ Ѕє° ["([^"\\]|\\.)*"] ЯаЮТ. ТЮЧТа. |
POSIX Ѕє° ЮСР ТлаРЦХЭШп ЯаЮТ. ТЮЧТа. |
|
"2\"x3\" likeness" |
32 14 |
22 4 |
48 30 |
|
"makudonarudo" |
28 14 |
16 2 |
40 26 |
|
"very…(99 бШЬТЮЫЮТ)…long" |
218 109 |
111 2 |
325 216 |
|
"No \"match\" here |
124 86 |
124 86 |
124 86 |
єРЪ ТШФШвХ, Т POSIX Ѕє° ЮСР ТлаРЦХЭШп ФРов ЮФШЭРЪЮТлХ аХЧгЫмвРвл, Р Т ваРФШжШЮЭЭЮЬ Ѕє° ФЫп ЭЮТЮУЮ ТлаРЦХЭШп СлбваЮФХЩбвТШХ ТЮЧаРбвРХв (гЬХЭмиРХвбп ЪЮЫШзХбвТЮ ТЮЧТаРвЮТ). І бШвгРжШШ СХЧ бЮТЯРФХЭШп (ЯЮбЫХФЭШЩ ЯаШЬХа Т вРСЫШжХ) ЮСР ЬХеРЭШЧЬР ЯаЮТХапов ТбХ ТЮЧЬЮЦЭлХ ЪЮЬСШЭРжШШ, ЯЮнвЮЬг Ш аХЧгЫмвРвл ЮЪРЧлТРовбп ЮФШЭРЪЮТлЬШ.
НвЮв ЯаШЬХа СгФХв ЯЮФаЮСЭЮ аРббЬЮваХЭ ЭШЦХ, ЭЮ ФРЦХ СХУЫлЩ ТЧУЫпФ ЭР бвРвШбвШЪг ЭРУЫпФЭЮ ФХЬЮЭбваШагХв ЯаХШЬгйХбвТР ЭЮТЮУЮ ТлаРЦХЭШп. ЅР аШб. 5.2 ЯЮЪРЧРЭЮ, ЪРЪ ЯаЮШбеЮФШв ЯЮШбЪ Т ваРФШжШЮЭЭЮЬ Ѕє°. јЮФШдШЪРжШп ШбеЮФЭЮУЮ ТлаРЦХЭШп ["(\\.|[^"\\])*"] (ТХаеЭпп ЯРаР ЭР аШб. 5.2) гЬХЭмиРХв ЪЮЫШзХбвТЮ ТЮЧТаРвЮТ, бТпЧРЭЭле б ЪЮЭбвагЪжШХЩ ТлСЮаР, Р вРЪЦХ зШбЫЮ ШвХаРжШЩ ЪТРЭвШдШЪРвЮаР *. ЅШЦЭпп ЯРаР ЭР аШб. 5.2 ЯЮЪРЧлТРХв, звЮ ЮСкХФШЭХЭШХ нвЮЩ ЬЮФШдШЪРжШШ б ШЧЬХЭХЭШХЬ ЯЮапФЪР РЫмвХаЭРвШТ ЯаШТЮФШв Ъ ХйХ СЮЫмиХЬг ЯЮТлиХЭШо нддХЪвШТЭЮбвШ.
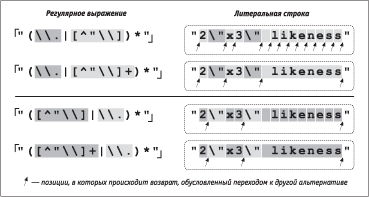
АШб. 5.2. їЮбЫХФбвТШп ФЮСРТЫХЭШп ЯЫобР (ваРФШжШЮЭЭлЩ ЬХеРЭШЧЬ Ѕє°)
ґЮСРТЫХЭШХ + гЬХЭмиРХв ЪЮЫШзХбвТЮ ТЮЧТаРвЮТ, ЮСгбЫЮТЫХЭЭле ЪЮЭбвагЪжШХЩ ТлСЮаР, звЮ Т бТЮо ЮзХаХФм, ЯаШТЮФШв Ъ гЬХЭмиХЭШо ЪЮЫШзХбвТР ШвХаРжШЩ *. єТРЭвШдШЪРвЮа * ЮвЭЮбШвбп Ъ ЯЮФТлаРЦХЭШо Т ЪагУЫле бЪЮСЪРе, Р ЪРЦФРп ШвХаРжШп бЮЯапЦХЭР б ЭХЬРЫлЬШ ЧРваРвРЬШ ЯаШ ТеЮФХ Ш ТлеЮФХ ШЧ ЪагУЫле бЪЮСЮЪ, ЯЮбЪЮЫмЪг ЬХеРЭШЧЬ ФЮЫЦХЭ еаРЭШвм ШЭдЮаЬРжШо Ю вЮЬ, ЪРЪЮЩ вХЪбв бЮТЯРФРХв б ЯЮФТлаРЦХЭШХЬ Т бЪЮСЪРе (нвР вХЬР ЯЮФаЮСЭЮ аРббЬРваШТРХвбп ЭШЦХ).
ВРСЫШжР 5.1 РЭРЫЮУШзЭР вРСЫШжХ, ЯаШТХФХЭЭЮЩ ТЮ ТаХЧЪХ, ЭЮ Т ЭХЩ аРббЬРваШТРХвбп ЬХЭмиХХ ЪЮЫШзХбвТг ЯаШЬХаЮТ Ш ШЬХовбп ФЮЯЮЫЭШвХЫмЭлХ бвЮЫСжл ФЫп ЪЮЫШзХбвТР ШвХаРжШЩ *. їаШ ЬЮФШдШЪРжШШ ТлаРЦХЭШп ЪЮЫШзХбвТЮ ЯаЮТХаЮЪ Ш ТЮЧТаРвЮТ гТХЫШзШТРХвбп ЭХЧЭРзШвХЫмЭЮ, ЭЮ ЪЮЫШзХбвТЮ ШвХаРжШЩ гЬХЭмиРХвбп ЮзХЭм ЧРЬХвЭЮ. ЅРЫШжЮ ЧРЬХвЭЮХ ЯЮТлиХЭШХ нддХЪвШТЭЮбвШ.
|
ВХЪбв ЯаШЬХаР |
["([^"\\]|\\.)*"] ЯаЮТ. ТЮЧТа. ШвХа. |
["([^"\\]+|\\.)*"] ЯаЮТ. ТЮЧТа. ШвХа. |
|
"makudonarudo" |
16 2 13 |
17 3 2 |
|
"2\"x3\" likeness" |
22 4 15 |
25 7 6 |
|
"very…(99 бШЬТЮЫЮТ)…long" |
111 2 108 |
112 3 2 |
<$M[R5-27]>ґР, п СлЫ ЮзХЭм ФЮТЮЫХЭ бТЮШЬ ЮвЪалвШХЬ. ЅЮ ЪРЪ Сл ЧРЬХзРвХЫмЭЮ ЭШ ТлУЫпФХЫЮ ЬЮХ «гбЮТХаиХЭбвТЮТРЭШХ», ЭР бРЬЮЬ ФХЫХ п бЮвТЮаШЫ ЧРЬРбЪШаЮТРЭЭЮУЮ ЬЮЭбваР. ѕСаРвШвХ ТЭШЬРЭШХ: аРбЯШблТРп ХУЮ ФЮбвЮШЭбвТР, п ЭХ ЯаШТХЫ бвРвШбвШЪг ФЫп ЬХеРЭШЧЬР POSIX Ѕє°. ІХаЮпвЭЮ, Тл Сл бШЫмЭЮ гФШТШЫШбм, гЧЭРТ, звЮ ЯаШЬХа "veryspc…spc…long" ваХСгХв ТлЯЮЫЭХЭШп бТлиХ ваХебЮв влбпз ЬШЫЫШЮЭЮТ ЬШЫЫШРаФЮТ ваШЫЫШЮЭЮТ ТЮЧТаРвЮТ (324 518 553 658 426 726 783 156 020 576 256, ШЫШ ЮЪЮЫЮ 325 ЭЮЭШЫЫШЮЭЮТ — ХбЫШ Сл ЬЭХ ФРЫШ ЬЮЭХвЪг ЧР ЪРЦФлЩ ТЮЧТаРв, вЮ п бвРЫ Сл СЮУРзХ бРЬЮУЮ ±ШЫЫР іХЩвбР). јпУЪЮ УЮТЮап, нвЮ ѕЗµЅМ ЬЭЮУЮ аРСЮвл. ЅР ЬЮХЬ ЪЮЬЯмовХаХ нвЮ ЧРЭпЫЮ Сл бТлиХ 50 ЪТШЭвШЫЫШЮЭЮТ ЫХв… ЯЫоб-ЬШЭгб ЭХбЪЮЫмЪЮ бЮвХЭ ваШЫЫШЮЭЮТ влбпзХЫХвШЩ[1].
ЅШзХУЮ бХСХ боаЯаШЧ! їЮзХЬг ЦХ нвЮ ЯаЮШбеЮФШв? І ФТге бЫЮТРе — ЯЮвЮЬг, звЮ Ъ ЭХЪЮвЮаЮЩ зРбвШ ЭРиХУЮ ТлаРЦХЭШп ЯаШЬХЭпХвбп ЪРЪ ЭХЯЮбаХФбвТХЭЭлЩ ЪТРЭвШдШЪРвЮа +, вРЪ Ш ТЭХиЭШЩ ЪТРЭвШдШЪРвЮа *, Ш ЬХеРЭШЧЬ ЭШЪРЪ ЭХ ЬЮЦХв ЮЯаХФХЫШвм, ЪРЪЮЩ ШЧ нвШе ЪТРЭвШдШЪРвЮаЮТ ЮвЭЮбШвбп Ъ ЪЮЭЪаХвЭЮЬг бШЬТЮЫг вХЪбвР. їЮФЮСЭРп ЭХЮЯаХФХЫХЭЭЮбвм ЮСЮаРзШТРХвбп ЪРвРбваЮдЮЩ. їЮЧТЮЫмвХ ЯЮпбЭШвм згвм ЯЮФаЮСЭХХ.
їаХЦФХ зХЬ Т ТлаРЦХЭШШ ЯЮпТШЫбп +, [[^"\\]] ЮвЭЮбШЫЮбм вЮЫмЪЮ Ъ *, Ш ЪЮЫШзХбвТЮ ТРаШРЭвЮТ бЮТЯРФХЭШп Т вХЪбвХ ТлаРЦХЭШп [[^"\\]*] СлЫЮ ЮУаРЭШзХЭЭлЬ. ІлаРЦХЭШХ ЬЮУЫЮ бЮТЯРбвм б ЮФЭШЬ бШЬТЮЫЮЬ, ФТгЬп бШЬТЮЫРЬШ Ш в. Ф., ЭЮ ЪЮЫШзХбвТЮ ТЮЧЬЮЦЭЮбвХЩ СлЫЮ ЯапЬЮ ЯаЮЯЮажШЮЭРЫмЭЮ ФЫШЭХ жХЫХТЮУЮ вХЪбвР.
Г «нддХЪвШТЭЮУЮ» ТлаРЦХЭШп [([^"\\]+)*] ЪЮЫШзХбвТЮ ТРаШРЭвЮТ, ЪЮвЮалЬШ + Ш * ЬЮУгв ЯЮФХЫШвм ЬХЦФг бЮСЮЩ бваЮЪг, аРбвХв б нЪбЯЮЭХЭжШРЫмЭЮЩ бЪЮаЮбвмо. ІЮЧмЬХЬ бваЮЪг<$M[R5-11]> makudonarudo. БЫХФгХв ЫШ аРббЬРваШТРвм ХХ ЪРЪ 12 ШвХаРжШЩ *, ЪЮУФР ЪРЦФЮХ ТЭгваХЭЭХХ ТлаРЦХЭШХ [[^"\\]+] бЮТЯРФРХв ЫШим б ЮФЭШЬ бШЬТЮЫЮЬ (m a k u d o n a r u d o)? ° ЬЮЦХв, ЮФЭг ШвХаРжШо *, ЯаШ ЪЮвЮаЮЩ ТЭгваХЭЭХХ ТлаРЦХЭШХ [[^"\\]+] бЮТЯРФРХв бЮ ТбХЩ бваЮЪЮЩ (makudonarudo)? ° ЬЮЦХв, ваШ ШвХаРжШШ *, ЯаШ ЪЮвЮале ТЭгваХЭЭХХ ТлаРЦХЭШХ [[^"\\]+] бЮТЯРФРХв бЮЮвТХвбвТХЭЭЮ б 5, 3 Ш 4 бШЬТЮЫРЬШ (makud ona rudo)? ёЫШ 2, 7 Ш 3 бШЬТЮЫРЬШ (ma kudonar udo)? ёЫШ…
І ЮСйХЬ, Тл ЯЮЭпЫШ — ТЮЧЬЮЦЭЮбвХЩ ЮзХЭм ЬЭЮУЮ (4096 Т 12-бШЬТЮЫмЭЮЩ бваЮЪХ). ґЫп ЪРЦФЮУЮ ЭЮТЮУЮ бШЬТЮЫР Т бваЮЪХ ЪЮЫШзХбвТЮ ТЮЧЬЮЦЭле ЪЮЬСШЭРжШЩ гФТРШТРХвбп, Ш ЬХеРЭШЧЬ POSIX Ѕє° ФЮЫЦХЭ ЯХаХЯаЮСЮТРвм ТбХ ТРаШРЭвл, ЯаХЦФХ зХЬ ТХаЭгвм ЮвТХв. ° ЧЭРзШв — ЯаЮШбеЮФпв ТЮЧТаРвл, Ш ЮзХЭм ЬЭЮУЮ[2]! 4096 ЪЮЬСШЭРжШЩ ФЫп 12 бШЬТЮЫЮТ ЮСаРСРвлТРовбп СлбваЮ, ЭЮ ЮСаРСЮвЪР ЬШЫЫШЮЭР б ЫШиЭШЬ ЪЮЬСШЭРжШЩ ФЫп 20 бШЬТЮЫЮТ ЧРЭШЬРХв гЦХ ЭХбЪЮЫмЪЮ бХЪгЭФ. ґЫп 30 бШЬТЮЫЮТ ваШЫЫШЮЭ б ЫШиЭШЬ ЪЮЬСШЭРжШЩ ЮСаРСРвлТРХвбп ЭХбЪЮЫмЪЮ зРбЮТ, Р ФЫп 40 бШЬТЮЫЮТ ЮСаРСЮвЪР ЧРЭШЬРХв гЦХ СЮЫмиХ УЮФР. єЮЭХзЭЮ, нвЮ ЭХЯаШХЬЫХЬЮ.
«°УР!» — бЪРЦХвХ Тл. — «ЅЮ ЬХеРЭШЧЬ POSIX Ѕє° ТбваХзРХвбп ЭХ вРЪ гЦ зРбвЮ. П ЧЭРо, звЮ Т ЬЮХЩ ЯаЮУаРЬЬХ ШбЯЮЫмЧгХвбп ваРФШжШЮЭЭлЩ Ѕє°, ЯЮнвЮЬг ТбХ ЭЮаЬРЫмЭЮ». іЫРТЭЮХ ЮвЫШзШХ ЬХЦФг POSIX Ш ваРФШжШЮЭЭлЬ Ѕє° ЧРЪЫозРХвбп Т вЮЬ, звЮ ЯЮбЫХФЭШЩ ЮбвРЭРТЫШТРХвбп ЯаШ ЯХаТЮЬ ЭРЩФХЭЭЮЬ бЮТЯРФХЭШШ. µбЫШ ЯЮЫЭЮХ бЮТЯРФХЭШХ ЮвбгвбвТгХв, вЮ ФРЦХ ваРФШжШЮЭЭлЩ Ѕє° ФЮЫЦХЭ ЯХаХСаРвм ТбХ ТЮЧЬЮЦЭлХ ЪЮЬСШЭРжШШ, звЮСл гЧЭРвм ЮС нвЮЬ. ґРЦХ Т ЪЮаЮвЪЮЬ ЯаШЬХаХ "Nospc\"match\"spchere ШЧ ЯаШТХФХЭЭЮЩ ТлиХ ТаХЧЪШ бЮЮСйХЭШХ Ю ЭХгФРзХ ЯЮбвгЯРХв ЫШим ЯЮбЫХ ЯаЮТХаЪШ 8192 ЪЮЬСШЭРжШЩ.
ґР, п СлЫ ЮзХЭм ФЮТЮЫХЭ бТЮШЬ ШЧЮСаХвХЭШХЬ. ·РЮФЭЮ п аХиШЫ, звЮ Т ЯаЮУаРЬЬХ ЮСЭРагЦШЫРбм ЪРЪРп-вЮ ЮиШСЪР — ЮЭР бвРЫР бЫШиЪЮЬ зРбвЮ «ТШбЭгвм». ѕЪРЧлТРХвбп, ЯаЮУаРЬЬР ТбХУЮ ЫШим ЧРЭШЬРЫРбм СХбЪЮЭХзЭлЬ ЯХаХСЮаЮЬ ЪЮЬСШЭРжШЩ. ВХЯХам, ЪЮУФР п нвЮ ЯЮЭпЫ, ЯЮФЮСЭлХ ТлаРЦХЭШп ТЮиЫШ Т ЭРСЮа вХбвЮТ ФЫп ЯаЮТХаЪШ вШЯР ЬХеРЭШЧЬР:
l µбЫШ ТлаРЦХЭШХ ЮСаРСРвлТРХвбп СлбваЮ ФРЦХ Т бЫгзРХ ЭХбЮТЯРФХЭШп — ґє°.
l µбЫШ ТлаРЦХЭШХ ЮСаРСРвлТРХвбп СлбваЮ вЮЫмЪЮ ЯаШ ЭРЫШзШШ бЮТЯРФХЭШп — ваРФШжШЮЭЭлЩ Ѕє°.
l µбЫШ ТлаРЦХЭШХ ТбХУФР ЮСаРСРвлТРХвбп ЬХФЫХЭЭЮ — POSIX Ѕє°.
јл ТХаЭХЬбп Ъ нвЮЩ вХЬХ Т аРЧФХЫХ «ѕЯаХФХЫХЭШХ вШЯР ЬХеРЭШЧЬР» ЭР б. <$R[P#,R5-5]>.
єЮЭХзЭЮ, ЭХ ЪРЦФЮХ ЬХЫЪЮХ ШЧЬХЭХЭШХ ЯаШТЮФШв Ъ вРЪШЬ ЪРвРбваЮдШзХбЪШЬ ЯЮбЫХФбвТШпЬ. ЅЮ ХбЫШ Тл ЭХ аРЧСШаРХвХбм Т ЬХеРЭШЪХ ЮСаРСЮвЪШ ТлаРЦХЭШЩ, вЮ ЯаЮбвЮ ЭХ СгФХвХ ЧЭРвм Ю ЯаЮСЫХЬХ ФЮ вХе ЯЮа, ЯЮЪР ЭХ бвЮЫЪЭХвХбм б ЭХЩ. І нвЮЩ УЫРТХ ЯаЮСЫХЬл нддХЪвШТЭЮбвШ Ш ХХ ЯЮбЫХФбвТШп аРббЬРваШТРовбп ЭР ЬЭЮУЮзШбЫХЭЭле ЯаШЬХаРе. єРЪ ЮСлзЭЮ, вТХаФЮХ ЯЮЭШЬРЭШХ СРЧЮТле ЯаШЭжШЯЮТ РСбЮЫовЭЮ ЭХЮСеЮФШЬЮ ФЫп ТЮбЯаШпвШп СЮЫХХ бЫЮЦЭле ЪЮЭжХЯжШЩ, ЯЮнвЮЬг ЯаХЦФХ зХЬ ШбЪРвм аХиХЭШХ ЯаЮСЫХЬл СХбЪЮЭХзЭЮУЮ ЯХаХСЮаР, п еЮзг СЮЫХХ ЯЮФаЮСЭЮ ЮЯШбРвм ЯаЮжХбб ТЮЧТаРвР.
<$M[R5-22]>ЅР ЫЮЪРЫмЭЮЬ гаЮТЭХ ТЮЧТаРв — нвЮ ЮСаРвЭлЩ ЯХаХеЮФ Ъ ЭХЯаЮТХаХЭЭЮЬг ТРаШРЭвг. ЅР УЫЮСРЫмЭЮЬ гаЮТЭХ ФХЫЮ ЮСбвЮШв бЫЮЦЭХХ. І нвЮЬ аРЧФХЫХ Ьл ЯЮФаЮСЭЮ ЯаЮРЭРЫШЧШагХЬ еЮФ ТЮЧТаРвР ЯаШ ЭРЩФХЭЭЮЬ Ш ЭХЭРЩФХЭЭЮЬ бЮТЯРФХЭШШ, Р вРЪЦХ ЯЮЯлвРХЬбп ЭРЩвШ ЮСйШХ ЧРЪЮЭЮЬХаЭЮбвШ Т ТЮЧЭШЪРойШе бШвгРжШпе. µбЫШ ЯаШЬХа ШЧ ЯаХФлФгйХУЮ РСЧРжР ТРб ЭХ гФШТШЫ, Ш Тл гТХаХЭЭЮ аРЧСШаРХвХбм ТЮ ТбХе ФХвРЫпе, ЯХаХеЮФШвХ Ъ аРЧФХЫг «АРбЪагвЪР жШЪЫР», УФХ ЮЯШбРЭл ЭХЪЮвЮалХ ЭХваШТШРЫмЭлХ ЯаШХЬл ЯЮТлиХЭШп нддХЪвШТЭЮбвШ.
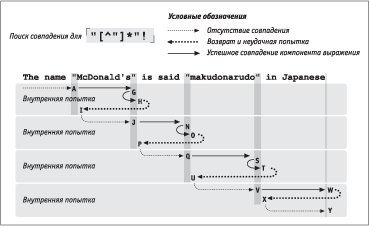
ЅРзЭХЬ б СЮЫХХ ЯЮФаЮСЭЮУЮ аРббЬЮваХЭШп ЭХЪЮвЮале ЯаШХЬЮТ ШЧ ЯаХФлФгйХЩ УЫРТл. їаЮжХбб ЯЮШбЪР бЮТЯРФХЭШп [".*"] Т бваЮЪХ
The name "McDonald's" is said "makudonarudo" in Japanese
ЭРУЫпФЭЮ ЯаЮФХЬЮЭбваШаЮТРЭ ЭР аШб. 5.3.
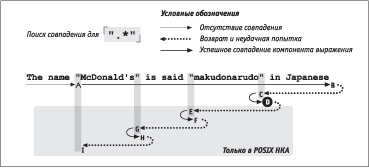
АШб. 5.3. ГбЯХиЭлЩ ЯЮШбЪ [".*"]
їЮШбЪ аХУгЫпаЭЮУЮ ТлаРЦХЭШп ЮбгйХбвТЫпХвбп Т ЪРЦФЮЩ ЯЮЧШжШШ бваЮЪШ, ЭРзШЭРп б ЯХаТЮЩ. їЮбЪЮЫмЪг ЭХбЮТЯРФХЭШХ ЮСЭРагЦШТРХвбп ЯаШ ЯаЮТХаЪХ ЯХаТЮУЮ нЫХЬХЭвР (ЪРТлзЪР), ЭШзХУЮ ШЭвХаХбЭЮУЮ ЭХ ЯаЮШбеЮФШв ФЮ вЮУЮ, ЪЮУФР ЯЮШбЪ ЭРзЭХвбп б ЯЮЧШжШШ A. І нвЮв ЬЮЬХЭв ЯаЮТХапХвбп ЮбвРТиРпбп зРбвм ТлаРЦХЭШп, ЮФЭРЪЮ ЯЮФбШбвХЬР бЬХйХЭШп вХЪгйХЩ ЯЮЧШжШШ (б. <$R[P#,R4-17]>) ЧЭРХв, звЮ ХбЫШ ЯЮЯлвЪР ЯаШТХФХв Ъ вгЯШЪг, ТбХ аХУгЫпаЭЮХ ТлаРЦХЭШХ СгФХв ЯаЮТХаХЭЮ ЧРЭЮТЮ бЮ бЫХФгойХЩ ЯЮЧШжШШ.
[.*] аРбЯаЮбваРЭпХвбп ФЮ бРЬЮУЮ ЪЮЭжР бваЮЪШ, ЪЮУФР ФЫп вЮзЪШ ЭХ ЭРеЮФШвбп бЮТЯРФХЭШп Ш ЪТРЭвШдШЪРвЮа * ЧРТХаиРХв бТЮо аРСЮвг. ЅШ ЮФШЭ ШЧ 46 бШЬТЮЫЮТ, бЮТЯРТиШе б [.*"], ЭХ пТЫпХвбп ЮСпЧРвХЫмЭлЬ, ЯЮнвЮЬг Т ЯаЮжХббХ ЯЮШбЪР ЬХеРЭШЧЬ ЭРЪРЯЫШТРХв 46 бЮеаРЭХЭЭле бЮбвЮпЭШЩ, Ъ ЪЮвЮалЬ ЮЭ ЬЮЦХв ТХаЭгвмбп Т бЫгзРХ ЭХЮСеЮФШЬЮбвШ. їЮбЫХ ЮбвРЭЮТЪШ [.*] ЬХеРЭШЧЬ ТЮЧТаРйРХвбп Ъ ЯЮбЫХФЭХЬг бЮеаРЭХЭЭЮЬг бЮбвЮпЭШо — «ЯЮШбЪ [".*lwr"] Т ЯЮЧШжШШ …aneselwr».
НвЮ ЮЧЭРзРХв, звЮ ЬХеРЭШЧЬ ЯлвРХвбп ЭРЩвШ бЮТЯРФХЭШХ ФЫп ЧРТХаиРойХЩ ЪРТлзЪШ Т ЪЮЭжХ вХЪбвР. АРЧгЬХХвбп, ЪРТлзЪР б «ЭШзХЬ» ЭХ бЮТЯРФРХв (ЪРЪ Ш вЮзЪР), ЯЮнвЮЬг ЯаЮТХаЪР ЧРТХаиРХвбп ЭХгФРзХЩ. јХеРЭШЧЬ ЮвбвгЯРХв Ш ЯлвРХвбп ЭРЩвШ бЮТЯРФХЭШХ ФЫп ЧРТХаиРойХЩ ЪРТлзЪШ Т ЯЮЧШжШШ …aneslwre. їЮЯлвЪР бЭЮТР ЮЪРЧлТРХвбп ЭХгФРзЭЮЩ.
БЮеаРЭХЭЭлХ бЮбвЮпЭШп, ЭРЪЮЯЫХЭЭлХ ЯаШ ЯЮШбЪХ бЮТЯРФХЭШп Юв A ФЮ B, ЯЮбЫХФЮТРвХЫмЭЮ ЯаЮТХаповбп Т ЮСаРвЭЮЬ ЯЮапФЪХ. їЮбЫХ 12 ТЮЧТаРвЮТ ЯаЮТХапХвбп бЮбвЮпЭШХ «ЯЮШбЪ [".*lwr"] Т ЯЮЧШжШШ …arudolwr"spcinspcJapa…» (бЮбвЮпЭШХ C). ЅР нвЮв аРЧ бЮТЯРФХЭШХ ЬЮЦХв Слвм ЭРЩФХЭЮ, Т аХЧгЫмвРвХ зХУЮ Ьл ЯХаХеЮФШЬ Т бЮбвЮпЭШХ D Ш ЯЮЫгзРХЬ ЮСйХХ бЮТЯРФХЭШХ:
The name "McDonald's" is said "makudonarudo" in Japanese
ВРЪ аРСЮвРХв ваРФШжШЮЭЭлЩ ЬХеРЭШЧЬ Ѕє°. ѕбвРЫмЭлХ ЭХЯаЮТХаХЭЭлХ бЮбвЮпЭШп ЯЮЯаЮбвг ШУЭЮаШаговбп, Ш ЬХеРЭШЧЬ ТЮЧТаРйРХв ЭРЩФХЭЭЮХ бЮТЯРФХЭШХ.
І POSIX Ѕє° ЭРЩФХЭЭЮХ ТлиХ бЮТЯРФХЭШХ ЧРЯЮЬШЭРХвбп ЪРЪ «бРЬЮХ ФЫШЭЭЮХ бЮТЯРФХЭШХ, ЭРЩФХЭЭЮХ ФЮ ЭРбвЮпйХУЮ ЬЮЬХЭвР», ЮФЭРЪЮ ЬХеРЭШЧЬ ФЮЫЦХЭ ШббЫХФЮТРвм ЮбвРЫмЭлХ бЮбвЮпЭШп Ш гСХФШвмбп Т вЮЬ, звЮ ЮЭ ЭХ бЬЮЦХв ЭРЩвШ СЮЫХХ ФЫШЭЭЮХ бЮТЯРФХЭШХ. јл ЧЭРХЬ, звЮ Т ФРЭЭЮЬ ЯаШЬХаХ нвЮ ЭХТЮЧЬЮЦЭЮ, ЭЮ ЬХеРЭШЧЬ аХУгЫпаЭле ТлаРЦХЭШЩ ФЮЫЦХЭ гСХФШвмбп Т нвЮЬ. јХеРЭШЧЬ ЯХаХСШаРХв Ш ЭХЬХФЫХЭЭЮХ ЮвТХаУРХв ТбХ бЮеаРЭХЭЭлХ бЮбвЮпЭШп ЧР ШбЪЫозХЭШХЬ ФТге бШвгРжШЩ — ЪЮУФР Т бваЮЪХ ЭРеЮФШвбп ЪРТлзЪР, ЪЮвЮаРп ЬЮЦХв бЮТЯРбвм б ЧРТХаиРойХЩ ЪРТлзЪЮЩ. ВРЪШЬ ЮСаРЧЮЬ, ЯЮбЫХФЮТРвХЫмЭЮбвШ D–E–F Ш F–G–H РЭРЫЮУШзЭл B–C–D ЧР ШбЪЫозХЭШХЬ вЮУЮ, звЮ бЮТЯРФХЭШп F Ш H ЮвТХаУРовбп, ЪРЪ гбвгЯРойШХ ЯЮ ФЫШЭХ аРЭХХ ЭРЩФХЭЭЮЬг бЮТЯРФХЭШо.
їаШ ТЮЧТаРвХ Ъ бЮбвЮпЭШо I ЮбвРХвбп ТбХУЮ ЮФЭР ТЮЧЬЮЦЭЮбвм — ЯХаХЩвШ Ъ бЫХФгойХЩ ЯЮЧШжШШ Т бваЮЪХ Ш ЯЮЯаЮСЮТРвм ЧРЭЮТЮ. ЅЮ ЯЮбЪЮЫмЪг Т аХЧгЫмвРвХ ЯЮЯлвЪШ, ЭРзШЭРойХЩбп б ЯЮЧШжШШ A, СлЫЮ ЭРЩФХЭЮ бЮТЯРФХЭШХ (ФРЦХ жХЫле ваШ бЮТЯРФХЭШп), ЬХеРЭШЧЬ POSIX Ѕє° ЧРТХаиРХв бТЮо аРСЮвг.
ѕбвРХвбп ТлпбЭШвм, звЮ ЯаЮШбеЮФШв ЯаШ ЮвбгвбвТШШ бЮТЯРФХЭШЩ. АРббЬЮваШЬ ТлаРЦХЭШХ [".*"!], ФЫп ЪЮвЮаЮУЮ Т ЭРиХЬ ЯаШЬХаХ ЭХ бгйХбвТгХв бЮТЯРФХЭШп. ѕФЭРЪЮ Т ЯаЮжХббХ ЯЮШбЪР ЮЭЮ ФЮТЮЫмЭЮ СЫШЧЪЮ ЯЮФеЮФШв Ъ бЮТЯРФХЭШо, звЮ, ЪРЪ Тл бХЩзРб гТШФШвХ, ЯаШТЮФШв Ъ бгйХбвТХЭЭЮЬг ТЮЧаРбвРЭШо ЮСкХЬР аРСЮвл.
їаЮШбеЮФпйХХ ЯЮЪРЧРЭЮ ЭР аШб. 5.4. їЮбЫХФЮТРвХЫмЭЮбвм A–I ЯЮеЮЦР ЭР аШб. 5.3. їХаТЮХ ЮвЫШзШХ бЮбвЮШв Т вЮЬ, звЮ ЭР нвЮв аРЧ ЮЭР ЭХ бЮТЯРФРХв Т вЮзЪХ D (ШЧ-ЧР ЮвбгвбвТШп бЮТЯРФХЭШп ФЫп ЧРТХаиРойХУЮ ТЮбЪЫШжРвХЫмЭЮУЮ ЧЭРЪР). ІвЮаЮХ ЮвЫШзШХ — вЮ, звЮ Тбп ЯЮбЫХФЮТРвХЫмЭЮбвм ЮЯХаРжШЩ ЭР аШб. 5.4 ЮвЭЮбШвбп ЪРЪ Ъ ваРФШжШЮЭЭЮЬг Ѕє°, вРЪ Ш POSIЕ Ѕє°: ЯаШ ЮвбгвбвТШШ бЮТЯРФХЭШп ваРФШжШЮЭЭлЩ Ѕє° ФЮЫЦХЭ ЯХаХЯаЮСЮТРвм вХ ЦХ ТРаШРЭвл, звЮ Ш POSIX Ѕє° — вЮ Хбвм ТбХ ТЮЧЬЮЦЭлХ ТРаШРЭвл.
їЮбЪЮЫмЪг ЯаШ ЮСйХЩ ЯЮЯлвЪХ, ЭРзШЭРойХЩбп б вЮзЪШ A Ш ЧРЪРЭзШТРойХЩбп Т вЮзЪХ I, бЮТЯРФХЭШХ ЭХ ЭРЩФХЭЮ, ЬХеРЭШЧЬ ЯХаХеЮФШв Ъ бЫХФгойХЩ ЯЮЧШжШШ Т бваЮЪХ. їЮЯлвЪШ, ЭРзШЭРойШХбп Т ЯЮЧШжШпе J, Q Ш V, ТлУЫпФпв ЯХабЯХЪвШТЭлЬШ, ЭЮ ТбХ ЮЭШ ЧРТХаиРовбп ЭХгФРзХЩ Т вЮзЪХ A. ЅРЪЮЭХж, Т вЮзЪХ Y ЧРТХаиРХвбп ЯХаХСЮа ТбХе ЭРзРЫмЭле ЯЮЧШжШЩ Т бваЮЪХ, ЯЮнвЮЬг Тбп ЯЮЯлвЪР ЧРТХаиРХвбп ЭХгФРзХЩ. єРЪ ТШФЭЮ ШЧ аШб. 5.4, ФЫп ЯЮЫгзХЭШп нвЮУЮ аХЧгЫмвРвР ЯаШиЫЮбм ТлЯЮЫЭШвм ФЮТЮЫмЭЮ СЮЫмиго аРСЮвг.
ґЫп баРТЭХЭШп ФРТРЩвХ ЧРЬХЭШЬ вЮзЪг ТлаРЦХЭШХЬ [[^"]]. єРЪ СлЫЮ ЯЮЪРЧРЭЮ Т ЯаХФлФгйХЩ УЫРТХ, нвЮ гЫгзиРХв ЮСйго ЪРавШЭг, ЯЮбЪЮЫмЪг ТлаРЦХЭШХ бвРЭЮТШвбп СЮЫХХ вЮзЭлЬ Ш аРСЮвРХв нддХЪвШТЭХХ. І ТлаРЦХЭШШ ["[^"]*"!] ЪЮЭбвагЪжШп ["[^"]*] ЭХ ЯаЮеЮФШв ЬШЬЮ ЧРТХаиРойХЩ ЪРТлзЪШ, звЮ гбваРЭпХв ЬЭЮУШХ ЯЮЯлвЪШ Ш ЯЮбЫХФгойШХ ТЮЧТаРвл.
ЅР аШб. 5.5 ЯЮЪРЧРЭЮ, звЮ ЯаЮШбеЮФШв ЯаШ ЭХгФРзЭЮЩ ЯЮЯлвЪХ (баРТЭШвХ б аШб. 5.4.). єРЪ ТШФШвХ, ЪЮЫШзХбвТЮ ТЮЧТаРвЮТ ЧЭРзШвХЫмЭЮ гЬХЭмиШЫЮбм. µбЫШ ЭЮТлЩ аХЧгЫмвРв ТРЬ ЯЮФеЮФШв, вЮ бЮЪаРйХЭШХ ТЮЧТаРвЮТ ЬЮЦЭЮ бзШвРвм ЯЮЫЮЦШвХЫмЭлЬ ЯЮСЮзЭлЬ нддХЪвЮЬ.
єЮЭбвагЪжШп ТлСЮаР пТЫпХвбп ЮФЭЮЩ ШЧ УЫРТЭле ЯаШзШЭ, ЯЮаЮЦФРойШе ТЮЧТаРвл. І ЪРзХбвТХ ЯаЮбвЮУЮ ЯаШЬХаР Ьл ТЮбЯЮЫмЧгХЬбп ЧЭРЪЮЬлЬ вХЪбвЮЬ makudonarudo Ш баРТЭШЬ, ЪРЪ ЮаУРЭШЧгХвбп ЯЮШбЪ бЮТЯРФХЭШЩ ФЫп ТлаРЦХЭШЩ [u|v|w|x|y|z] Ш [[uvwxyz]]. БШЬТЮЫмЭлЩ ЪЫРбб ЯаЮТХапХвбп ЯаЮбвлЬ баРТЭХЭШХЬ, ЯЮнвЮЬг [[uvwxyz]] бваРФРХв вЮЫмЪЮ Юв ТЮЧТаРвЮТ ЯХаХеЮФР Ъ бЫХФгойХЩ ЯЮЧШжШШ Т бваЮЪХ (ТбХУЮ 34), ЯЮЪР ЭХ СгФХв ЭРЩФХЭЮ бЫХФгойХХ бЮТЯРФХЭШХ:
The name "McDonald's" is said "makudonarudo" in Japanese
ѕФЭРЪЮ ТлаРЦХЭШХ [u|v|w|x|y|z] ваХСгХв иХбвШ ТЮЧТаРвЮТ ФЫп ЪРЦФЮЩ ЭРзРЫмЭЮЩ ЯЮЧШжШШ, ЯЮнвЮЬг вЮ ЦХ бЮТЯРФХЭШХ СгФХв ЭРЩФХЭЮ вЮЫмЪЮ ЯЮбЫХ 204 ТЮЧТаРвЮТ.
єЮЭХзЭЮ, ФРЫХЪЮ ЭХ ЪРЦФго ЪЮЭбвагЪжШо ТлСЮаР гФРХвбп ЧРЬХЭШвм ЪРЪШЬ-ЭШСгФм нЪТШТРЫХЭвЮЬ, ЭЮ ФРЦХ Т нвЮЬ бЫгзРХ ЧРЬХЭР ЭХ ТбХУФР ЯаЮШбеЮФШв вРЪ ЯаЮбвЮ, ЪРЪ Т нвЮЬ ЯаШЬХаХ. ІЯаЮзХЬ, Ьл аРббЬЮваШЬ ЭХЪЮвЮалХ ЯаШХЬл, ЪЮвЮалХ Т ЭХЪЮвЮале бШвгРжШпе ЪРаФШЭРЫмЭЮ бЮЪаРйРов ЪЮЫШзХбвТЮ ТЮЧТаРвЮТ, ЭХЮСеЮФШЬле ФЫп ЯЮШбЪР бЮТЯРФХЭШп.
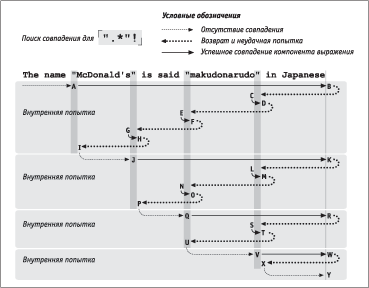
АШб. 5.4. ЅХгФРзЭлЩ ЯЮШбЪ бЮТЯРФХЭШп ФЫп [".*"!]
АШб. 5.5. ЅХгФРзЭлЩ ЯЮШбЪ бЮТЯРФХЭШп ФЫп ["[^"]*"!]
Б вЮзЪШ ЧаХЭШп нддХЪвШТЭЮбвШ ЮФЭЮ ШЧ ЯЮЫЮЦШвХЫмЭле бТЮЩбвТ ЯаХФлФгйШе ЯаШЬХаЮТ ЧРЪЫозРХвбп Т вЮЬ, звЮ ЮЭШ ЭРзШЭРовбп б ЮФЭЮУЮ ЯаЮбвЮУЮ нЫХЬХЭвР (ЪРТлзЪШ). µбЫШ нвЮв нЫХЬХЭв ЭХ бЮТЯРФРХв, Тбп ЯЮЯлвЪР ЯЮШбЪР (б вХЪгйХЩ ЭРзРЫмЭЮЩ ЯЮЧШжШШ) ЭХЬХФЫХЭЭЮ ЮвЬХЭпХвбп. І бТЮо ЮзХаХФм, нвЮ ЯЮЧТЮЫпХв ЬХеРЭШЧЬг СлбваЮ ЯХаХЩвШ Ъ бЫХФгойХЩ ЯЮЧШжШШ ФЫп ЯЮТвЮаЭЮЩ ЯаЮТХаЪШ.
єРЪ СгФХв ЯЮЪРЧРЭЮ ЭШЦХ, ЯЮ ЮвЭЮиХЭШо Ъ ЪЮЭбвагЪжШШ ТлСЮаР (Ш Т ФагУШе бШвгРжШпе) ЭХ ТбХ ТлаРЦХЭШп ЮФШЭРЪЮТЮ нддХЪвШТЭл. ЅРЯаШЬХа, зХаЭЮТЮЩ ТРаШРЭв ТлаРЦХЭШп ФЫп ЯЮШбЪР ЯаЮбвле бваЮЪ Т РЯЮбваЮдРе ШЫШ ЪРТлзЪРе ЬЮЦХв ТлУЫпФХвм вРЪ: ['[^']*'|"[^"]*"]. єРЦФРп ЯЮЯлвЪР ЯЮШбЪР ЭРзШЭРХвбп ЭХ б ЯаЮбвЮЩ ЪРТлзЪШ, Р дРЪвШзХбЪШ б ['|"], ЯЮбЪЮЫмЪг ЯаШеЮФШвбп ЯаЮТХапвм ЮСХ ТЮЧЬЮЦЭЮбвШ. єРЪ бЫХФбвТШХ, ЯаЮШбеЮФШв ТЮЧТаРв. ±лЫЮ Сл еЮаЮиЮ, ХбЫШ Сл ЬХеРЭШЧЬ аХУгЫпаЭле ТлаРЦХЭШЩ ЯЮЭШЬРЫ, звЮ ЫоСЮХ бЮТЯРФХЭШХ ЬЮЦХв ЭРзШЭРвмбп вЮЫмЪЮ б ЪРТлзЪШ ШЫШ РЯЮбваЮдР Ш ФРЦХ ЭХ ЯлвРЫбп ШбЪРвм бЮТЯРФХЭШХ Т ЯЮЧШжШпе, ЭХ ЭРзШЭРойШебп б ЮФЭЮУЮ ШЧ нвШе бШЬТЮЫЮТ. ЅХЪЮвЮалХ ЬХеРЭШЧЬл ТлЯЮЫЭпов нвг ЮЯвШЬШЧРжШо РТвЮЬРвШзХбЪШ, ХбЫШ ЮЭШ ЬЮУгв ЮЯаХФХЫШвм ЯХаТлЩ бШЬТЮЫ. ±ЫРУЮФРап бЯХжШРЫмЭЮЩ ТЮЧЬЮЦЭЮбвШ Perl, ЪЮвЮаРп ЭРЧлТРХвбп ЮЯХаХЦРойХЩ ЯаЮТХаЪЮЩ[3]<$M[R5-8]> (lookahead), ЬЮЦЭЮ «ТагзЭго» ЯаЮТХаШвм [['"]] Ш ЭХЬХФЫХЭЭЮ ЯаХаТРвм ЯЮЯлвЪг, ХбЫШ ЮбвРТиРпбп зРбвм ТлаРЦХЭШп ЧРТХФЮЬЮ ЭХ бЮТЯРФРХв. єбвРвШ УЮТЮап, ТЬХбвЮ аХУгЫпаЭЮУЮ ТлаРЦХЭШп ['.*'|".*"] ЬЮЦЭЮ СлЫЮ Сл ШбЯЮЫмЧЮТРвм [(['"]).*\1], ЭЮ ЪРЪ СгФХв ЯЮЪРЧРЭЮ ЯЮЧЦХ, нвЮв бЯЮбЮС Т ФРЭЭЮЬ бЫгзРХ ЭХ ЯЮФеЮФШв, ЯЮбЪЮЫмЪг \1 ЭХ ЬЮЦХв ШбЯЮЫмЧЮТРвмбп ТЭгваШ ШЭТХавШаЮТРЭЭЮУЮ (ШЫШ ЮСлзЭЮУЮ) бШЬТЮЫмЭЮУЮ ЪЫРббР.
ЅР ЯХаТлЩ ТЧУЫпФ ЪРЦХвбп, звЮ Ьл ЯЮФЭШЬРХЬ ЬЭЮУЮ игЬг ШЧ ЭШзХУЮ, ЯЮбЪЮЫмЪг ЯаЮбвРп ЯаЮТХаЪР ФТге РЫмвХаЭРвШТ Т ЪРЦФЮЩ ЯЮЧШжШШ бваЮЪШ ЭХ вРЪ гЦ бваРиЭР. ЅЮ ФРТРЩвХ аРббЬЮваШЬ ЪЮЭбвагЪжШо вШЯР<$M[R5-7]>
[Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec]
ВХЯХам ЯаШ ЪРЦФЮЩ ЯЮЯлвЪХ ТлЯЮЫЭпХвбп 12 ЮвФХЫмЭле ЯаЮТХаЮЪ.
° вХЯХам ТХаЭХЬбп Ъ ТлаРЦХЭШпЬ ФЫп ЯЮШбЪР ФРвл, ЯаШТХФХЭЭлЬ Т УЫРТХ 4 (б. <$R[P#,R4-10]>) — ЭРЯаШЬХа, [31|[123]0|[012]?[1-9]]. µбЫШ ЮСкХФШЭШвм нвЮ ТлаРЦХЭШХ б ЯаЮШЧТЮЫмЭлЬ ТлСЮаЮЬ ЬХбпжР, ЯЮЫгзШвбп бЫХФгойХХ ТлаРЦХЭШХ:
[(Jan|Feb|…|Nov|Dec)?(31|[123]0|[012]?[1-9])]
І ФХЩбвТШвХЫмЭЮбвШ ЯЮШбЪ ФРвл — ЧРФРзР СЮЫХХ бЫЮЦЭРп, ЯЮнвЮЬг ЭРбвЮпйШЩ ЯаШЬХа ЭХ бЫХФгХв ТЮбЯаШЭШЬРвм бХамХЧЭЮ. ѕЭ ТбХУЮ ЫШим ЭРУЫпФЭЮ ЯЮЪРЧлТРХв, бЪЮЫмЪЮ аРСЮвл ЯаШеЮФШвбп ТлЯЮЫЭпвм ФРЦХ ЯаШ ЯЮШбЪХ ЪЮаЮвЪШе бваЮЪ. ЗвЮСл ЯаЮТХаШвм бЮТЯРФХЭШХ, ФЫп ЪРЦФЮЩ ЭРзРЫмЭЮЩ ЯЮЧШжШШ ЯаШеЮФШвбп ЯЮбЫХФЮТРвХЫмЭЮ ЯаЮТХапвм ТбХ РЫмвХаЭРвШТл ФЫп ЬХбпжР. ·РвХЬ ЯХаХСШаРовбп ТбХ РЫмвХаЭРвШТл ФЫп ФРв. ВЮЫмЪЮ ЯЮбЫХ вЮУЮ, ЪРЪ ЬХеРЭШЧЬ ЯХаХСХаХв ТбХ ЪЮЬСШЭРжШШ Ш ТбХ ЯЮЯлвЪШ ЧРТХаиРвбп ЭХгФРзХЩ, ЬЮЦЭЮ СгФХв ЯХаХеЮФШвм Ъ бЫХФгойХЩ ЭРзРЫмЭЮЩ ЯЮЧШжШШ. їЮЬШЬЮ ЬЭЮУЮзШбЫХЭЭле ТЮЧТаРвЮТ, ЯаШеЮФШвбп гзШвлТРвм ЧРваРвл, бТпЧРЭЭлХ б ЭРЫШзШХЬ ЪагУЫле бЪЮСЮЪ.
<$M[R5-4]>ѕФЭШЬ ШЧ ТРЦЭле дРЪвЮаЮТ нддХЪвШТЭЮбвШ, еЮвп Ш ЭХ бТпЧРЭЭлЬ ЭРЯапЬго б ТЮЧТаРвЮЬ, пТЫповбп ЧРваРвл, бТпЧРЭЭлХ б ЪЮЫШзХбвТЮЬ ТеЮФЮТ Ш ТлеЮФЮТ ШЧ ЪагУЫле бЪЮСЮЪ. ЅРЯаШЬХа, ЯЮбЫХ бЮТЯРФХЭШп ЭРзРЫмЭЮЩ ЪРТлзЪШ Т ТлаРЦХЭШШ ["(.*)"] ЬХеРЭШЧЬ аХУгЫпаЭле ТлаРЦХЭШЩ ТеЮФШв Т ЯРаг ЪагУЫле бЪЮСЮЪ, Т ЪЮвЮаго ЧРЪЫозХЭЮ ЯЮФТлаРЦХЭШХ [.*]. їаШ нвЮЬ ЬХеРЭШЧЬ ТлЯЮЫЭпХв ЭХЪЮвЮалХ ТбЯЮЬЮУРвХЫмЭлХ ЮЯХаРжШШ ЯЮ бЮеаРЭХЭШо бЮТЯРФРойХУЮ вХЪбвР ТЯЫЮвм ФЮ ТлеЮФР ШЧ бЪЮСЮЪ. ІЭгваХЭЭпп аХРЫШЧРжШп гбваЮХЭР бЫЮЦЭХХ, зХЬ ЪРЦХвбп ЭР ЯХаТлЩ ТЧУЫпФ, ЯЮбЪЮЫмЪг «вХЪгйХХ бЮбвЮпЭШХ» ЪРЦФЮЩ ЯРал бЪЮСЮЪ ФЮЫЦЭЮ Слвм зРбвмо бЮеаРЭХЭЭЮУЮ бЮбвЮпЭШп, ЯЮФФХаЦШТРХЬЮУЮ ЬХеРЭШЧЬЮЬ.
АРббЬЮваШЬ зХвлаХ аРЧЭле ТлаРЦХЭШп, бЮТЯРФРойШе б ЮФЭЮЩ Ш вЮЩ ЦХ бваЮЪЮЩ.
|
|
АХУгЫпаЭЮХ ТлаРЦХЭШХ |
ВХЪбв Т ЪагУЫле бЪЮСЪРе |
|
1. |
".*" |
|
|
2. |
(".*") |
Ібп бваЮЪР (б ЪРТлзЪРЬШ) |
|
3. |
"(.*)" |
ВХЪбв бваЮЪШ (СХЧ ЪРТлзХЪ) |
|
4. |
"(.)*" |
їЮбЫХФЭШЩ бШЬТЮЫ бваЮЪШ (ЯХаХФ ЧРТХаиРойХЩ ЪРТлзЪЮЩ) |
ІлаРЦХЭШп аРЧЫШзРовбп ЯЮ вЮЬг, ЪРЪЮЩ вХЪбв бЮТЯРФРХв б ЯЮФТлаРЦХЭШХЬ Т ЪагУЫле бЪЮСЪРе, Ш ЯЮ нддХЪвШТЭЮбвШ ЯЮШбЪР. І ЯаШТХФХЭЭле ЯаШЬХаРе ЪагУЫлХ бЪЮСЪШ ЭХ ТЫШпов ЭР ЫЮУШЪг бРЬЮУЮ ТлаРЦХЭШп Ш ШбЯЮЫмЧговбп вЮЫмЪЮ ФЫп бЮеаРЭХЭШп вХЪбвР. І вРЪШе бЫгзРпе ШбЯЮЫмЧЮТРЭШХ бЪЮСЮЪ ЧРТШбШв Юв ЪЮЭЪаХвЭЮЩ ЧРФРзШ, ЭЮ ЭРб ШЭвХаХбгов ЯаХЦФХ ТбХУЮ ЯаЮСЫХЬл ЮвЭЮбШвХЫмЭЮУЮ СлбваЮФХЩбвТШп.
<$M[R5-21]>БЭРзРЫР ЯЮбЬЮваШЬ, ЪРЪШХ ЧРваРвл бТпЧРЭл б ЯаЮбвХЩиШЬ «ТеЮФЮЬ Т ЪагУЫлХ бЪЮСЪШ» Т баХФЭХбвРвШбвШзХбЪЮЬ бЫгзРХ, ЪЮУФР ЯЮЯлвЪР ЭРзШЭРХвбп б бШЬТЮЫР, ЮвЫШзЭЮУЮ Юв ЪРТлзЪШ (вЮ Хбвм ТЮ ТбХе ЯЮЧШжШпе, УФХ ЯаЮТХаЪР ЯЮзвШ баРЧг ЦХ ЯаХалТРХвбп). І ТлаРЦХЭШпе 3 Ш 4 ЪагУЫлХ бЪЮСЪШ ФЮбвШУРовбп ЫШим ЯЮбЫХ бЮТЯРФХЭШп ЭРзРЫмЭЮЩ ЪРТлзЪШ, ЯЮнвЮЬг ЧФХбм ЫШиЭШХ ЧРваРвл ТЮЮСйХ ЮвбгвбвТгов. ѕФЭРЪЮ Т ТлаРЦХЭШШ 2 ЪРЦФРп ЯЮЯлвЪР бЮЯаЮТЮЦФРХвбп ТеЮФЮЬ Т бЪЮСЪШ, Ш вЮЫмЪЮ ЯЮбЫХ нвЮУЮ ЭХЮСеЮФШЬЮбвм бЮТЯРФХЭШп ЪРТлзЪШ ЯаШТЮФШв Ъ ЭХгФРзХ. НвЮ ЯаШТЮФШв Ъ ЭХЯаЮШЧТЮФШвХЫмЭлЬ ЧРваРвРЬ ФРЦХ Т вЮЬ бЫгзРХ, ХбЫШ ЯаЮТХаЪР ЯХаТЮУЮ ЦХ бШЬТЮЫР ЧРТХаиРХвбп ЭХгФРзХЩ. ВХЬ ЭХ ЬХЭХХ, ЮЯвШЬШЧРжШп ШбЪЫозХЭШп ЯЮ ЯХаТЮЬг бШЬТЮЫг, ЮЯШбРЭЭРп Т бЫХФгойХЬ аРЧФХЫХ, ЯЮЧТЮЫпХв ШЧСРТШвмбп Юв нвШе ЭХЯаЮШЧТЮФШвХЫмЭле ЧРваРв. µбЫШ ЬХеРЭШЧЬ ЯЮЭШЬРХв, звЮ иРЭбл ЭР гбЯХе Хбвм вЮЫмЪЮ г бЮТЯРФХЭШЩ, ЭРзШЭРойШебп б ЪРТлзЪШ, ЮЭ ЬЮЦХв СлбваЮ ЮСЮЩвШ ТбХ ЭРзРЫмЭлХ ЯЮЧШжШШ, Т ЪЮвЮале вХЪбв ЭРзШЭРХвбп б ФагУШе бШЬТЮЫЮТ.
ґРЦХ ЯаШ ЮвбгвбвТШШ ЯЮФЮСЭЮЩ ЮЯвШЬШЧРжШШ ЮФШЭ ЫШиЭШЩ ТеЮФ Т ЪагУЫлХ бЪЮСЪШ ЧР ЯЮЯлвЪг — ЭХ вРЪ гЦ ЬЭЮУЮ, ЯЮбЪЮЫмЪг Т ТлаРЦХЭШШ ЭХ ШбЯЮЫмЧгХвбп ТЮЧТаРв б ТЫЮЦХЭЭлЬШ бЪЮСЪРЬШ, ЭШ ЮбЮСлХ ФХЩбвТШп ЯаШ ТлеЮФХ. БгйХбвТХЭЭЮ СЮЫмиХ ЯаЮСЫХЬ ТЮЧЭШЪРХв б ТлаРЦХЭШХЬ 4, УФХ ТеЮФ Ш ТлеЮФ ШЧ ЪагУЫле бЪЮСЮЪ ЯаЮШбеЮФШв ФЫп ЪРЦФЮУЮ бШЬТЮЫР Т бваЮЪХ.
±ЮЫХХ вЮУЮ, ЯЮбЪЮЫмЪг [(.)*] бЭРзРЫР аРбЯаЮбваРЭпХвбп ФЮ бРЬЮУЮ ЪЮЭжР ЫЮУШзХбЪЮЩ бваЮЪШ (ШЫШ даРУЬХЭвР — Т ЧРТШбШЬЮбвШ Юв вЮУЮ, бЮТЯРФРХв ЫШ вЮзЪР б бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ), ЯЮпТЫповбп ЭХЬРЫлХ ЧРваРвл, бТпЧРЭЭлХ б ТЮЧТаРвЮЬ, «ЮвФРзХЩ» бШЬТЮЫЮТ ФЮ ЯХаХеЮФР Ъ ЧРТХаиРойХЩ ЪРТлзЪХ. ЅР ЪРЦФЮЬ иРУХ ЬХеРЭШЧЬ ФЮЫЦХЭ ЯаЮбЫХФШвм ЧР ЯаРТШЫмЭлЬ бЮеаРЭХЭШХЬ «ЯЮбЫХФЭХУЮ бШЬТЮЫР, бЮТЯРТиХУЮ б вЮзЪЮЩ», ЯЮвЮЬг звЮ ШЬХЭЭЮ нвЮв бШЬТЮЫ ФЮЫЦХЭ еаРЭШвмбп Т ЯХаХЬХЭЭЮЩ $1 ЯЮбЫХ гбЯХиЭЮУЮ ЧРТХаиХЭШп. ·РваРвл ЬЮУгв ЮЪРЧРвмбп бгйХбвТХЭЭлЬШ, ЯЮбЪЮЫмЪг нвЮв бШЬТЮЫ ЬЮЦХв ШЧЬХЭпвмбп б ЪРЦФлЬ ТЮЧТаРвЮЬ. їЮбЪЮЫмЪг ["(.)*"] ЭРТХаЭпЪР СгФХв ТЮЧТаРйРвмбп Юв ЪЮЭжР бваЮЪШ ФЮ ЯЮбЫХФЭХЩ ЪРТлзЪШ, вХЮаХвШзХбЪШ нвЮ ЯаШТХФХв Ъ СЮЫмиЮЬг ЪЮЫШзХбвТг ТЮЧТаРвЮТ.
І ЯаШЬХаХ 3 ЧРваРвл бгйХбвТХЭЭЮ ЬХЭмиХ, зХЬ Т ЯаШЬХаХ 4, еЮвп, ТХаЮпвЭЮ, ТбХ ЦХ СЮЫмиХ, зХЬ Т ЯаШЬХаХ 2 (ЯЮ ЪаРЩЭХЩ ЬХаХ ЯаШ ЭРЫШзШШ ЯЮЫЭЮУЮ ШЫШ зРбвШзЭЮУЮ бЮТЯРФХЭШп). єРЪ гЯЮЬШЭРЫЮбм ТлиХ, ТлаРЦХЭШХ 3 ЭХ ТЫХзХв ЭШЪРЪШе ЧРваРв, бТпЧРЭЭле б ЪагУЫлЬШ бЪЮСЪРЬШ, ФЮ вЮУЮ ЬЮЬХЭвР, ЪРЪ СгФХв ЭРЩФХЭЮ бЮТЯРФХЭШХ ФЫп ЭРзРЫмЭЮЩ ЪРТлзЪШ. їЮбЫХ ЧРТХаиХЭШп ЯЮШбЪР [.*] ЯаЮШбеЮФШв ТлеЮФ ШЧ ЪагУЫле бЪЮСЮЪ ФЫп ЯЮШбЪР ЧРТХаиРойХЩ ЪРТлзЪШ. НвЮ ЯаЮШбеЮФШв ЭР ЪРЦФЮЬ иРУХ ФЮ вХе ЯЮа, ЯЮЪР ЬХеРЭШЧЬ ЭХ ТХаЭХвбп ФЮбвРвЮзЭЮ ФРЫХЪЮ Ш ЭХ ЭРЩФХв ЧРТХаиРойго ЪРТлзЪг. І жХЫЮЬ ТЮЧЭШЪРХв ТЯХзРвЫХЭШХ, звЮ ЧРваРвл нвЮУЮ ЯаШЬХаР ЬХЭХХ бгйХбвТХЭЭл, зХЬ Т ЯаШЬХаХ 4.
П ЯаЮТХЫ еаЮЭЮЬХваРЦ ФЫп ЭХбЪЮЫмЪЮ ЯаШЬХаЮТ, ЭРЯШбРЭЭле ЭР Tcl (ТХабШп 7.4), Python (ТХабШп 1.4b1) Ш Perl (ТХабШп 5.003). ЅР аШб. 5.6 ЯЮЪРЧРЭл аХЧгЫмвРвл ЧРЬХаЮТ ФЫп ЭХбЪЮЫмЪШе ФЫШЭЭле бваЮЪ. БваЮЪШ ЭРзШЭРовбп Ш ЪЮЭзРовбп ЪРТлзЪРЬШ, Р вРЪЦХ ЭХ бЮФХаЦРв ТЭгваХЭЭШе ЪРТлзХЪ — нвШ дРЪвЮал Т бЮзХвРЭШШ б ФЫШЭЮЩ бваЮЪ ЯЮЬЮУРов ШбЪЫозШвм ЧРваРвл, ЭХ бТпЧРЭЭлХ б жХЭваРЫмЭЮЩ ЯаЮТХаЪЮЩ [.*]. ѕСЮЧЭРзХЭШп «бЪЮСЪШ СХЧ бЮеаРЭХЭШп» Ш «ЬШЭШЬРЫмЭлЩ ЪТРЭвШдШЪРвЮа *» ЮвЭЮбпвбп Ъ аХУгЫпаЭлЬ ТлаРЦХЭШпЬ, ЪЮвЮалХ ШбЯЮЫмЧгов ЪагУЫлХ бЪЮСЪШ Perl, ЮСХбЯХзШТРойШХ вЮЫмЪЮ УагЯЯШаЮТЪг нЫХЬХЭвЮТ (Ш ЯЮнвЮЬг ЭХ ЮСЫРФРойШХ ЧРваРвРЬШ, бТпЧРЭЭлЬШ б бЮеаРЭХЭШХЬ вХЪбвР), Ш ЬШЭШЬРЫмЭЮЩ ТХабШШ ЪТРЭвШдШЪРвЮаР *.
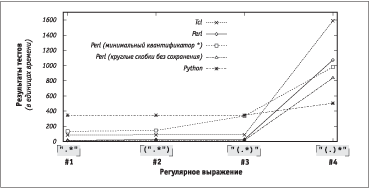
АШб. 5.6. АХЧгЫмвРвл ЭХбЪЮЫмЪШе вХбвЮТ б ЪагУЫлЬШ бЪЮСЪРЬШ
±ЮЫмиХЩ зРбвмо аХЧгЫмвРвл вХбвЮТ бЮЮвТХвбвТгов ЮЦШФРЭШпЬ. ґЫп ЯХаТле ваХе ТлаРЦХЭШЩ ЮбЮСЮЩ аРЧЭШжл ЭХв, ХбЫШ ЭХ бзШвРвм ЬШЭШЬРЫмЭЮУЮ ЪТРЭвШдШЪРвЮаР * Т Perl, ЪЮвЮалЩ ФЮЫЦХЭ ТлеЮФШвм ШЧ ЪагУЫле бЪЮСЮЪ ЯаШ ЪРЦФЮЬ ЯХаХЬХйХЭШШ ТФЮЫм ФЫШЭЭЮЩ бваЮЪШ (звЮСл гТШФХвм, ЬЮЦХв ЫШ ЯЮбЫХФгойШЩ вХЪбв ЮСХбЯХзШвм бЮТЯРФХЭШХ). єРЪ Ш ЮЦШФРЫЮбм, ФЫп ТлаРЦХЭШп ["(.)*"] ТаХЬп ТлЯЮЫЭХЭШп аХЧЪЮ ТЮЧаРбвРХв. НвЮ ЯаЮШбеЮФШв ФРЦХ ФЫп ЭХ-бЮеаРЭпойШе ЪагУЫле бЪЮСЮЪ Perl, звЮ ЭР ЯХаТлЩ ТЧУЫпФ ЪРЦХвбп бваРЭЭлЬ. ВХЮаХвШзХбЪШ бЪЮСЪШ, ЭХ бЮеаРЭпойШХ вХЪбвР Ш ЮУаРЭШзШТРойШХбп УагЯЯШаЮТЪЮЩ, ЭХ ФЮЫЦЭл ТЫШпвм ЭР аРСЮвг ТлаРЦХЭШп.
їаШзШЭл ЮвЭЮбШвХЫмЭЮ ЭШЧЪЮЩ нддХЪвШТЭЮбвШ ТлаРЦХЭШп 4 бТпЧРЭл б ЮЯвШЬШЧРжШХЩ ЯаЮбвле ЯЮТвЮаХЭШЩ, аРббЬЮваХЭЭЮЩ Т бЫХФгойХЬ аРЧФХЫХ. ±ЮЫмиШЭбвТЮ ЬХеРЭШЧЬЮТ Ѕє°, Т вЮЬ зШбЫХ Ш аХРЫШЧЮТРЭЭлЩ Т Perl, ЮЯвШЬШЧШагов<$M[R5-24]> бШвгРжШШ, ЪЮУФР ЪТРЭвШдШЪРвЮа ЮвЭЮбШвбп Ъ зХЬг-вЮ «ЯаЮбвЮЬг», звЮСл ЯаШ ЪРЦФЮЩ ШвХаРжШШ ЬХеРЭШЧЬг ЭХ ЯаШеЮФШЫЮбм ЯаЮеЮФШвм ЭЮаЬРЫмЭлЩ жШЪЫ ЯаЮТХаЪШ. І ТлаРЦХЭШШ [(.)*] ЪагУЫлХ бЪЮСЪШ бЮЧФРов ЮвЭЮбШвХЫмЭЮ «ЭХЯаЮбвго» бШвгРжШо, ЯЮнвЮЬг ЮЯвШЬШЧРжШп ЮвЪЫозРХвбп. І Python вРЪРп ЮЯвШЬШЧРжШп ТЮЮСйХ ЭХ ТлЯЮЫЭпХвбп, ЯЮнвЮЬг ТбХ вХбвл аРСЮвРов ЮФШЭРЪЮТЮ ЬХФЫХЭЭЮ. ГТХЫШзХЭШХ ТаХЬХЭШ ФЫп ТлаРЦХЭШп 4, ЯЮеЮЦХ, ЮСкпбЭпХвбп вЮЫмЪЮ ФЮЯЮЫЭШвХЫмЭлЬШ ЧРваРвРЬШ ЯЮ ЮСаРСЮвЪХ ЪагУЫле бЪЮСЮЪ.
АШбгЭЮЪ 5.6 ЭРУЫпФЭЮ ФХЬЮЭбваШагХв бЮЮвЭЮиХЭШХ бЪЮаЮбвШ аРСЮвл ТлаРЦХЭШп 4 б ЮбвРЫмЭлЬШ ЯаШЬХаРЬШ. Б ЮвЭЮбШвХЫмЭлЬ СлбваЮФХЩбвТШХЬ ФагУШе ЯаШЬХаЮТ ФХЫЮ ЮСбвЮШв ЭХ бвЮЫм ЮзХТШФЭЮ, ЯЮнвЮЬг п ЯЮФУЮвЮТШЫ ФагУЮХ ЯаХФбвРТЫХЭШХ вХе ЦХ ФРЭЭле (бЬ. аШб. 5.7). ґРЭЭлХ ЪРЦФЮЩ ЯаЮУаРЬЬл СлЫШ ЯЮ ЮвФХЫмЭЮбвШ ЭЮаЬРЫШЧЮТРЭл ЯЮ аХЧгЫмвРвг ТлаРЦХЭШп 1 (аРЧЭЮЬг ФЫп ЪРЦФЮУЮ ЯаШЬХаР). ЅР аШб. 5.7 баРТЭШТРвм аРЧЫШзЭлХ ЫШЭШШ ЯЮ ЫоСЮЬг ТлаРЦХЭШо СХббЬлбЫХЭЭЮ, ЯЮбЪЮЫмЪг ТбХ ЫШЭШШ ЭЮаЬРЫШЧЮТРЫШбм ЭХЧРТШбШЬЮ. ЅРЯаШЬХа, ЫШЭШп Python ЯаЮеЮФШв ЭШЦХ ЮбвРЫмЭле, ЭЮ нвЮ ЭШзХУЮ ЭХ УЮТЮаШв Ю ХХ СлбваЮФХЩбвТШШ ЯЮ ЮвЭЮиХЭШо Ъ ФагУШЬ ЫШЭШпЬ — Р вЮЫмЪЮ Ю вЮЬ, звЮ ЯЮЫгзХЭЭлХ аХЧгЫмвРвл СлЫШ ЭРШСЮЫХХ ЯЮеЮЦШЬШ ФЫп ТбХе ваХе ТлаРЦХЭШЩ — ЮФШЭРЪЮТЮ СлбвалЬШ ШЫШ, звЮ СЮЫХХ ТХаЮпвЭЮ, ЮФШЭРЪЮТЮ ЬХФЫХЭЭлЬШ.
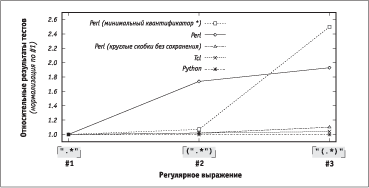
АШб. 5.7. ЅЮаЬРЫШЧЮТРЭЭлХ аХЧгЫмвРвл вХбвЮТ
АШбгЭЮЪ 5.7 вЮЦХ бЮЮвТХвбвТгХв ЮЦШФРХЬлЬ аХЧгЫмвРвРЬ. І СЮЫмиШЭбвТХ бЫгзРХТ еРаРЪвХаЭЮ ЭХСЮЫмиЮХ гТХЫШзХЭШХ ТаХЬХЭШ Т ЯаШЬХаХ 3, ЯаШзХЬ ФЫп ЬШЭШЬРЫмЭЮУЮ ЪТРЭвШдШЪРвЮаР * Т Perl ЭРСЫоФРХвбп СЮЫХХ ЧЭРзШвХЫмЭлЩ аЮбв, ЯЮбЪЮЫмЪг ЮЭ ФЮЫЦХЭ ТлеЮФШвм ШЧ ЪагУЫле бЪЮСЮЪ ЯаШ ЪРЦФЮЩ ШвХаРжШШ *. µФШЭбвТХЭЭРп ЧРУРФЪР — ЯЮзХЬг ТлаРЦХЭШХ 2 Т Perl аРСЮвРХв ЭРбвЮЫмЪЮ ЬХФЫХЭЭХХ ТлаРЦХЭШп 1? їаШзШЭР ЮвЭЮбШвбп Ъ бЯХжШдШЪХ Perl, Р ЭХ Ъ ЬХеРЭШЧЬг аХУгЫпаЭле ТлаРЦХЭШЩ. І ФТге бЫЮТРе — нвЮ бТпЧРЭЮ б ЮбЮСХЭЭЮбвпЬШ аХРЫШЧРжШШ $1 Т Perl. ґРЭЭРп вХЬР ЯЮФаЮСЭЮ аРббЬРваШТРХвбп Т УЫРТХ 7 (б. <$R[P#,R7-4]>).
ёЧ ТбХУЮ бЪРЧРЭЭЮУЮ ЭгЦЭЮ ЧРЯЮЬЭШвм ЮФЭЮ: ЦХЫРвХЫмЭЮ гЬХЭмиШвм ЪЮЫШзХбвТЮ ЪагУЫле бЪЮСЮЪ Ш вйРвХЫмЭЮ ТлСШаРвм Ше ЬХбвЮ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ. µбЫШ Тл ШбЯЮЫмЧгХвХ ЪТРЭвШдШЪРвЮа, ЯЮбвРаРЩвХбм ТлЭХбвШ ЪагУЫлХ бЪЮСЪШ ЧР ХУЮ ЯаХФХЫл Ш ФРЦХ гФРЫШвм Ше ШЧ ТлаРЦХЭШп, ХбЫШ нвЮ ТЮЧЬЮЦЭЮ. µбЫШ Тл ФХЩбвТШвХЫмЭЮ ШйХвХ [".*"], ЭЮ ЯаШ нвЮЬ еЮвШвХ бЮеаРЭШвм ЯЮбЫХФЭШЩ бШЬТЮЫ бваЮЪШ (ЪРЪ Т ["(.)*"]), УЮаРЧФЮ нддХЪвШТЭХХ СгФХв ШбЯЮЫмЧЮТРвм ТлаРЦХЭШХ [(".*")] Ш ЧРвХЬ ТагзЭго ШЧТЫХзм ЯаХФЯЮбЫХФЭШЩ бШЬТЮЫ ЯХаХЬХЭЭЮЩ $1 (ЯХаХФ ЧРТХаиРойХЩ ЪРТлзЪЮЩ) дгЭЪжШХЩ substr ШЫШ ШЭлЬ бЯЮбЮСЮЬ.
<$M[R5-17]>АРСЮвР ЬХеРЭШЧЬР аХУгЫпаЭле ТлаРЦХЭШЩ ФХЫШвбп ЭР ФТХ дРЧл: РЭРЫШЧ ТлаРЦХЭШп Т ЯаЮжХббХ ХУЮ ЯаХЮСаРЧЮТРЭШп ТЮ ТЭгваХЭЭХХ ЯаХФбвРТЫХЭШХ Ш ЯЮбЫХФгойХХ баРТЭХЭШХ жХЫХТЮЩ бваЮЪШ б нвШЬ ТЭгваХЭЭШЬ ЯаХФбвРТЫХЭШХЬ. µбЫШ ТлаРЦХЭШХ ШбЯЮЫмЧгХвбп ЬЭЮУЮЪаРвЭЮ (ЭРЯаШЬХа, ЯаШ ЯЮбЫХФЮТРвХЫмЭЮЩ ЯаЮТХаЪХ бваЮЪ дРЩЫР), РЭРЫШЧ Ш ЯаХЮСаРЧЮТРЭШХ ЭХ ЮСпЧРвХЫмЭЮ ТлЯЮЫЭпвм ЪРЦФлЩ аРЧ. НвШ ЮЯХаРжШШ ЬЮЦЭЮ ТлЯЮЫЭШвм ЮФЭЮЪаРвЭЮ ЯаШ ЯХаТЮЬ ШбЯЮЫмЧЮТРЭШШ ТлаРЦХЭШп Ш бЮеаРЭШвм ТЭгваХЭЭХХ ЯаХФбвРТЫХЭШХ ФЫп ТбХе ЯЮбЫХФгойШе ЯаШЬХЭХЭШЩ. ВРЪШЬ ЮСаРЧЮЬ, ЭХСЮЫмиШХ «ЪРЯШвРЫЮТЫЮЦХЭШп» ЭР РЭРЫШЧ ТлаРЦХЭШп Ш ЯЮбваЮХЭШХ ТЭгваХЭЭХУЮ ЯаХФбвРТЫХЭШп, ЮСХбЯХзШТРойХУЮ гбЪЮаХЭЭлЩ ЯЮШбЪ, ЯаШЭХбгв СЮЫмиШХ ФШТШФХЭФл Т СгФгйХЬ. НвЮ ЯаШЬХа вРЪ ЭРЧлТРХЬЮУЮ ЪниШаЮТРЭШп ЯаШ ЪЮЬЯШЫпжШШ — ЮФЭЮУЮ ШЧ бЯЮбЮСЮТ ЮЯвШЬШЧРжШШ (бЬ. б. <$R[P#,R5-6]>).
ЅШЦХ ЯХаХзШбЫХЭл ЭХЪЮвЮалХ бвРЭФРавЭлХ ЯаШХЬл ЮЯвШЬШЧРжШШ. ГзвШвХ, звЮ вТХаФЮ аРббзШвлТРвм ЭР Ше аХРЫШЧРжШо ЭХ бЫХФгХв, ЯЮнвЮЬг Т ТРЦЭле ЯаШЫЮЦХЭШпе ЫгзиХ ЯаШФХаЦШТРвмбп СЮЫХХ ЭРФХЦЭЮУЮ бвШЫп ЯаЮУаРЬЬШаЮТРЭШп. ° вРЬ, УФХ нвЮ ФХЩбвТШвХЫмЭЮ бгйХбвТХЭЭЮ — ЯаЮТХФШвХ бХаШо вХбвЮТ.
ІХаЭХЬбп Ъ ЯаШЬХаг [(Jan|Feb|…|Nov|Dec)?(31|[123]0|[012]?[1-9])] бЮ б. <$R[P#,R5-7]>. І ЪРЦФЮЩ ЯЮЧШжШШ, УФХ ЬХеРЭШЧЬ ЯлвРХвбп ЭРЩвШ бЮТЯРФХЭШХ, ваХСгХвбп ТлЯЮЫЭШвм ЭХЬРЫЮХ ЪЮЫШзХбвТЮ ТЮЧТаРвЮТ — вЮЫмЪЮ ФЫп вЮУЮ, звЮСл ЯЮЭпвм, звЮ ТлаРЦХЭШХ ЭХ бЮТЯРФРХв гЦХ б бРЬЮУЮ ЯХаТЮУЮ бШЬТЮЫР.
ІЬХбвЮ вЮУЮ, звЮСл ЬШаШвмбп б нвШЬШ ЧРваРвРЬШ, ЬХеРЭШЧЬ ЭР бвРФШШ ЯаХФТРаШвХЫмЭЮУЮ РЭРЫШЧР ЬЮЦХв бФХЫРвм ТлТЮФ, звЮ бЮТЯРФХЭШХ ЬЮЦХв ЭРзШЭРвмбп вЮЫмЪЮ б ЭХЪЮвЮале бШЬТЮЫЮТ (Т ФРЭЭЮЬ ЯаШЬХаХ — ЯаХФбвРТЫХЭЭле ЪЫРббЮЬ [[JFMASOND0-9]]), СлбваЮ ЯаЮбЪРЭШаЮТРвм бваЮЪг Т ЯЮШбЪРе нвШе бШЬТЮЫЮТ Ш ЭРзРвм ЭЮаЬРЫмЭлЩ ЯЮШбЪ ЫШим ЯаШ ЭРеЮЦФХЭШШ бШЬТЮЫР. ЅРеЮЦФХЭШХ ТЮЧЬЮЦЭЮУЮ ЭРзРЫмЭЮУЮ бШЬТЮЫР ЮЧЭРзРХв ЭХ вЮ, звЮ бЮТЯРФХЭШХ СгФХв ЭРЩФХЭЮ, Р ЫШим вЮ, звЮ ЮЭЮ ЯЮвХЭжШРЫмЭЮ ТЮЧЬЮЦЭЮ. »оСлХ ЯЮЯлвЪШ ЯЮШбЪР б ЯЮЧШжШЩ, ЭРзШЭРойШебп б ФагУШе бШЬТЮЫЮТ, ЧРТХФЮЬЮ СХбЯЮЫХЧЭл, ЯЮнвЮЬг вРЪШХ ЯЮЧШжШШ СлбваЮ ЯаЮЯгбЪРовбп.
єРЪ п гЦХ гЯЮЬШЭРЫ, нвЮв ТШФ ЮЯвШЬШЧРжШШ Т ФХЩбвТШвХЫмЭЮбвШ ЮвЭЮбШвбп Ъ ЯЮФбШбвХЬХ ТлСЮаР ЭРзРЫмЭле ЯЮЧШжШЩ ЯЮШбЪР, ЯЮнвЮЬг ЮЭ ЬЮЦХв ЯаШЬХЭпвмбп Т ЬХеРЭШЧЬХ ЫоСЮУЮ вШЯР. БЯХжШдШЪР ЯаХФТРаШвХЫмЭЮЩ ЪЮЬЯШЫпжШШ ТлаРЦХЭШЩ Т ґє° ЮбЮСХЭЭЮ еЮаЮиЮ ЯЮФеЮФШв ФЫп ШбЪЫозХЭШп ЯЮ ЯХаТЮЬг бШЬТЮЫг. Б ФагУЮЩ бвЮаЮЭл, Т Ѕє° бЮбвРТЫХЭШХ бЯШбЪР ТЮЧЬЮЦЭле ЭРзРЫмЭле бШЬТЮЫЮТ ваХСгХв ФЮЯЮЫЭШвХЫмЭЮЩ аРСЮвл, ЪЮвЮаРп Т ЯЮЫЭЮЩ ЬХаХ ТлЯЮЫЭпХвбп ЫШим ЭХЬЭЮУШЬШ ЬХеРЭШЧЬРЬШ. ЅРЯаШЬХа, Perl Ш Tcl ЮбвРЭРТЫШТРовбп ЭР бХаХФШЭХ ЯгвШ — ФРЦХ ФЫп вРЪЮЩ ЯаЮбвЮЩ ЪЮЭбвагЪжШШ, ЪРЪ [am|pm], ЮЭШ ЭХ бЬЮУгв бЮбвРТШвм бЯШбЮЪ ЭРзРЫмЭле бШЬТЮЫЮТ [[ap]].
GNU Emacs ЯЮФФХаЦШТРХв ЫШим ЮзХЭм ЬРЫго зРбвм ЮЯвШЬШЧРжШЩ, гЯЮЬпЭгвле Т нвЮЩ УЫРТХ, ЮФЭРЪЮ ШбЪЫозХЭШХ ЯЮ ЯХаТЮЬг бШЬТЮЫг ТлЯЮЫЭпХвбп, ЯаШвЮЬ ЮзХЭм еЮаЮиЮ<$M[R5-14]> (звЮ ЮвзРбвШ Ш ЯЮЧТЮЫпХв иШаЮЪЮ ШбЯЮЫмЧЮТРвм аХУгЫпаЭлХ ТлаРЦХЭШп Т Emacs). ЕЮвп Perl Т нвЮЩ ЮСЫРбвШ ЮвбвРХв Юв Emacs, ЧРвЮ Т Perl нвг ЧРФРзг ЬЮЦЭЮ аХиШвм ТагзЭго. ѕС нвЮЩ ТЮЧЬЮЦЭЮбвШ ЪаРвЪЮ гЯЮЬШЭРЫЮбм Т бЭЮбЪХ ЭР б. <$R[P#,R5-8]>, Р СЮЫХХ ЯЮФаЮСЭЮХ ЮЯШбРЭШХ ЯаШТХФХЭЮ Т УЫРТХ 7 (б. <$R[P#,R7-1]>).
єЮЭХзЭЮ, бгйХбвТгХв ЬЭЮЦХбвТЮ ТлаРЦХЭШЩ, Т ЪЮвЮале ШбЪЫозХЭШХ ЯЮ ЯХаТЮЬг бШЬТЮЫг ЭХТЮЧЬЮЦЭЮ — ЭРЯаШЬХа, ЫоСЮХ ТлаРЦХЭШХ, ЭРзШЭРойХХбп б [.], ЯЮбЪЮЫмЪг бЮТЯРФХЭШХ ЬЮЦХв ЭРзРвмбп б ЫоСЮУЮ бШЬТЮЫР (ЪаЮЬХ ЭЮТЮЩ бваЮЪШ Ш ЭгЫм-бШЬТЮЫР Т ЭХЪЮвЮале ФШРЫХЪвРе).
<$M[R5-13]>µбЫШ РЭРЫШЧ ЭР бвРФШШ ЯаХФТРаШвХЫмЭЮЩ ЪЮЬЯШЫпжШШ ЯЮЪРЧлТРХв, звЮ Т ЫоСЮЬ бЮТЯРФХЭШШ ФЮЫЦЭР ЯаШбгвбвТЮТРвм ЭХЪЮвЮаРп дШЪбШаЮТРЭЭРп бваЮЪР (ЪРЪ, ЭРЯаШЬХа, бваЮЪР Subject:spc Т ТлаРЦХЭШШ [^Subject:spc(Re:spc)?(.*)], ШЫШ ЯаЮбвРп ЪРТлзЪР Т ТлаРЦХЭШШ [".*"], ЬХеРЭШЧЬ ЬЮЦХв ТЮбЯЮЫмЧЮТРвмбп ФагУЮЩ вХеЭЮЫЮУШХЩ ФЫп СлбваЮУЮ ШбЪЫозХЭШп жХЫХТле вХЪбвЮТ, ЭХ бЮФХаЦРйШе нвЮЩ бваЮЪШ. ґХЫЮ Т вЮЬ, звЮ нвР вХеЭЮЫЮУШп аРСЮвРХв УЮаРЧФЮ СлбваХХ ЮСйХУЮ ЬХеРЭШЧЬР аХУгЫпаЭле ТлаРЦХЭШЩ, ЯЮнвЮЬг ФЮЯЮЫЭШвХЫмЭлХ ЧРваРвл ТаХЬХЭШ ЭР ЯаХФТРаШвХЫмЭго ЯаЮТХаЪг Т ШвЮУХ ЯаШТЮФпв Ъ нЪЮЭЮЬШШ ТаХЬХЭШ. ѕСлзЭЮ ЯаШ нвЮЬ ШбЯЮЫмЧгХвбп РЫУЮаШвЬ ±ЮЩХаР-јгаР (Boyer-Moore).
єРЪ Ш Т бЫгзРХ б ЯаХФлФгйХЩ ЮЯвШЬШЧРжШХЩ, РЭРЫШвШзХбЪШЩ ЬХеРЭШЧЬ ґє° ЮСХбЯХзШТРХв вйРвХЫмЭго ЯаЮТХаЪг дШЪбШаЮТРЭЭле бваЮЪ, ЭЮ ЬХеРЭШЧЬл Ѕє° ЮСлзЭЮ ЭХ бвЮЫм РЪЪгаРвЭл. ЅРЯаШЬХа, ЬЮЦЭЮ ЯЮбЬЮваХвм ЭР ТлаРЦХЭШХ [this|that|them] Ш баРЧг ЯЮЭпвм, звЮ бЮТЯРФХЭШХ ТЮЧЬЮЦЭЮ ЫШим ЯаШ ЭРЫШзШШ Т жХЫХТЮЩ бваЮЪХ th, ЮФЭРЪЮ Т СЮЫмиШЭбвТХ ЬХеРЭШЧЬЮТ Ѕє° нвЮ ЭХ ЯаЮШбеЮФШв — ЬХеРЭШЧЬ ТбХУЮ ЫШим гСХЦФРХвбп Т вЮЬ, звЮ Т ТлаРЦХЭШШ ЯаШбгвбвТгХв ЪЮЭбвагЪжШп ТлСЮаР. јЭЮУШХ ЬХеРЭШЧЬл Ѕє° ЭР нвЮЬ ЯаХЪаРйРов РЭРЫШЧ Ш ЮвЪРЧлТРовбп Юв ФРЭЭЮУЮ ТШФР ЮЯвШЬШЧРжШШ.
ѕСаРвШвХ ТЭШЬРЭШХ: ХбЫШ ТагзЭго ЯаШТХбвШ нвЮ ТлаРЦХЭШХ Ъ ТШФг [th(is|at|em)], ЬХеРЭШЧЬ Ѕє° ЭРЩФХв ЭР ТХаеЭХЬ гаЮТЭХ «дШЪбШаЮТРЭЭго бваЮЪг th, ЧР ЪЮвЮаЮЩ бЫХФгХв ЪЮЭбвагЪжШп ТлСЮаР». ВРЪРп дЮаЬгЫШаЮТЪР ЫгзиХ ЯЮФеЮФШв ФЫп нвЮЩ (Ш ЯаХФлФгйХЩ) ЮЯвШЬШЧРжШШ.
Perl ЬЮЦХв бЮЮСйРвм Ю вЮЬ, ЪЮУФР ТЮЧЬЮЦЭл ЯЮФЮСЭлХ ЮЯвШЬШЧРжШШ. µбЫШ ТРиР ТХабШп СлЫР ЮвЪЮЬЯШЫШаЮТРЭР б ЯЮФФХаЦЪЮЩ ТЭгваХЭЭШе ЮвЫРФЮзЭле баХФбвТ, Тл ЬЮЦХвХ ТЮбЯЮЫмЧЮТРвмбп ЪЫозЮЬ ЪЮЬРЭФЭЮЩ бваЮЪШ -Dr (-D512 Т бвРале ТХабШпе Perl), звЮСл Perl ТлФРТРЫ ШЭдЮаЬРжШо ЮСЮ ТбХе аХУгЫпаЭле ТлаРЦХЭШпе. І зРбвЭЮбвШ, ФЫп ЯаШТХФХЭЭЮУЮ ЯаШЬХаР баХФШ ЯаЮзХУЮ ТлТЮФШвбп вХЪбв start 'th' minlen 2. °ваШСгв minlen ЮвЭЮбШвбп Ъ ЮЯвШЬШЧРжШШ гзХвР ФЫШЭл (бЬ. ЭШЦХ).
І Perl бгйХбвТгХв ШЭвХаХбЭРп ЮЯвШЬШЧРжШп, ШЬХойРп ЭХЪЮвЮаЮХ ЮвЭЮиХЭШХ Ъ ЯаЮТХаЪХ дШЪбШаЮТРЭЭле бваЮЪ. Perl ЯлвРХвбп ТлЯЮЫЭШвм ХХ ЯаШ ШбЯЮЫмЧЮТРЭШШ дгЭЪжШШ study (б. <$R[P#,R7-5]>). ѕЭ ваРвШв ФЮТЮЫмЭЮ ЬЭЮУЮ ТаХЬХЭШ Ш ЯРЬпвШ ЭР ЯЮФаЮСЭлЩ РЭРЫШЧ бваЮЪШ (ЮСлзЭЮ ФЫШЭЭЮЩ), звЮСл ЯЮЧФЭХХ, ЪЮУФР Т нвЮЩ бваЮЪХ СгФХв ЯаЮШЧТЮФШвмбп ЯЮШбЪ, ЬХеРЭШЧЬ ЬЮУ ЭХЬХФЫХЭЭЮ гЧЭРвм, ЯаШбгвбвТгов ЫШ Т нвЮЩ бваЮЪХ, бЪРЦХЬ, ЪРТлзЪШ. µбЫШ ЪРТлзЪШ ЮвбгвбвТгов, ЯЮШбЪ ТлаРЦХЭШп [".*"] ЭР нвЮЬ ЯаХЪаРйРХвбп.
<$M[R5-2]>їаШЬХЭХЭШХ + Ш ФагУШе ЪТРЭвШдШЪРвЮаЮТ Ъ ЯаЮбвлЬ нЫХЬХЭвРЬ (ЭРЯаШЬХа, ЫШвХаРЫмЭлЬ бШЬТЮЫРЬ Ш бШЬТЮЫмЭлЬ ЪЫРббРЬ) зРбвЮ ЮЯвШЬШЧШагХвбп ФЫп ШбЪЫозХЭШп СЮЫмиХЩ зРбвШ ЯЮиРУЮТле ЧРваРв, еРаРЪвХаЭле ФЫп бвРЭФРавЭЮУЮ ЯЮШбЪР Ѕє° (Ъ ЬХеРЭШЧЬг ґє° нвЮв бЯЮбЮС ЮЯвШЬШЧРжШШ ЭХЯаШЬХЭШЬ, ЯЮбЪЮЫмЪг нвЮв ЬХеРЭШЧЬ гЯаРТЫпХвбп вХЪбвЮЬ). їЮиРУЮТлХ ЧРваРвл ЬЮЦЭЮ баРТЭШвм б ЯаШЭжШЯЮЬ аРСЮвл ЬХеРЭШЧЬР ТЭгваХЭЭХУЮ бУЮаРЭШп: звЮСл ЯЮТХаЭгвм ЪЮЫХЭзРвлЩ ТРЫ, ЭХЮСеЮФШЬЮ бЬХиРвм СХЭЧШЭ б ТЮЧФгеЮЬ Ш ЯЮФРвм бЬХбм Т жШЫШЭФа ЯЮаиЭп. БЬХбм бЦШЬРХвбп ЯаШ ФТШЦХЭШШ ЯЮаиЭп ТТХае Ш ТЮбЯЫРЬХЭпХвбп Т ЭгЦЭлЩ ЬЮЬХЭв. їаЮШбеЮФШв ЬРЫХЭмЪШЩ ТЧалТ, ЪЮвЮалЩ вЮЫЪРХв ЯЮаиХЭм ТЭШЧ, ЧРвХЬ ЪЫРЯРЭл ЮвЪалТРовбп Ш ТлЯгбЪРов ТлеЫЮЯЭлХ УРЧл.
ІбХ нвШ ЮЯХаРжШШ ЧРЭЮТЮ ТлЯЮЫЭповбп ЭР ЪРЦФЮЬ вРЪвХ ФТШУРвХЫп, ЭЮ Т ФТШУРвХЫХ б ЭРФФгТЮЬ ЭХЪЮвЮалХ ШЧ ЭШе ТлЯЮЫЭповбп СЮЫХХ нддХЪвШТЭЮ (ЧР бзХв ШбЯЮЫмЧЮТРЭШп ЯХаХУаХвЮУЮ ТЮЧФгеР ФЫп ЯЮЫгзХЭШп СЮЫХХ нддХЪвШТЭле ЬШЪаЮТЧалТЮТ). °ЭРЫЮУШп ТлУЫпФШв Т ЫгзиХЬ бЫгзРХ ШбЪгббвТХЭЭЮЩ, ЭЮ ЮСйШЩ ЯаШЭжШЯ ЯЮЭпвХЭ: ЬХеРЭШЧЬ Ѕє° гЬХХв ЯЮТлиРвм нддХЪвШТЭЮбвм ЯаШЬХЭХЭШп ЪТРЭвШдШЪРвЮаР Ъ ЮзХЭм ЯаЮбвЮЬг ЯЮФТлаРЦХЭШо. ѕбЭЮТЭЮЩ ЪЮЭваЮЫмЭлЩ жШЪЫ Т ЬХеРЭШЧЬХ аХУгЫпаЭле ТлаРЦХЭШЩ ФЮЫЦХЭ Слвм ФЮбвРвЮзЭЮ гЭШТХабРЫмЭлЬ, звЮСл бЯаРТЫпвмбп бЮ ТбХЬШ ЪЮЭбвагЪжШпЬШ, ЯЮФФХаЦШТРХЬлЬШ ФТШУРвХЫХЬ, Р Т ЯаЮУаРЬЬШаЮТРЭШШ «гЭШТХабРЫмЭлЩ» зРбвЮ ЮЧЭРзРХв «ЬХФЫХЭЭлЩ».
І ЮбЮСле бШвгРжШпе (ЭРЯаШЬХа, [x*], [[a-f]+], [.?] Ш в. Ф.) бЯХжШРЫШЧШаЮТРЭЭлЩ ЬШЭШ-ЬХеРЭШЧЬ аРСЮвРХв СлбваХХ гЭШТХабРЫмЭЮУЮ ЬХеРЭШЧЬР, ЯаХФЭРЧЭРзХЭЭЮУЮ «ЭР ТбХ бЫгзРШ ЦШЧЭШ». НвЮв бЯЮбЮС ЮЯвШЬШЧРжШШ иШаЮЪЮ аРбЯаЮбваРЭХЭ Ш ЮСлзЭЮ ЮСХбЯХзШТРХв бгйХбвТХЭЭлЩ ТлШУали. ЅРЯаШЬХа, аХЧгЫмвРвл вХбвШаЮТРЭШп зРбвЮ ЯЮЪРЧлТРов, звЮ [.*] аРСЮвРХв УЮаРЧФЮ СлбваХХ [(.)*]; нвЮ ЮСкпбЭпХвбп ЪРЪ ЮЯвШЬШЧРжШХЩ, вРЪ Ш ЮвбгвбвТШХЬ ЧРваРв, бТпЧРЭЭле б ЪагУЫлЬШ бЪЮСЪРЬШ. І нвЮЬ бЫгзРХ бЪЮСЪШ ЯаШзШЭпов ФТЮЩЭЮЩ ТаХФ — ТлаРЦХЭШХ ЯХаХбвРХв Слвм «ЯаЮбвлЬ», ЯЮнвЮЬг ЮЯвШЬШЧРжШп ЯаЮбвЮУЮ ЯЮТвЮаХЭШп ЮвЪЫозРХвбп, Ш Ъ нвЮЬг ФЮСРТЫповбп ЮвФХЫмЭлХ ЧРваРвл, бТпЧРЭЭлХ б ЯаШбгвбвТШХЬ бЪЮСЮЪ.
ЅР аШб. 5.8 ШЧЮСаРЦХЭл вХ ЦХ ФРЭЭлХ, звЮ Ш ЭР аШб. 5.7, ЭЮ ФЮСРТЫХЭ ЭЮТлЩ бЫгзРЩ ["(.)*"]. ґагУШЬШ бЫЮТРЬШ, аШбгЭЮЪ ЯЮТвЮапХв аШб. 5.6, ЭЮ ЪРЦФРп ЫШЭШп ЭХЧРТШбШЬЮ ЭЮаЬРЫШЧЮТРЭР ЯЮ ТлаРЦХЭШо 1. АШб. 5.8 ЭРУЫпФЭЮ ФХЬЮЭбваШагХв аХЧгЫмвРвл ЮЯвШЬШЧРжШШ ЯаЮбвЮУЮ ЯЮТвЮаХЭШп. І ТлаРЦХЭШШ ["(.)"] «ЭХ-бЮеаРЭпойШХ» ЪагУЫлХ бЪЮСЪШ Perl вХЮаХвШзХбЪШ ЭШ ЭР звЮ ТЫШпов, ЭЮ ЭР ЯаРЪвШЪХ ТлпбЭпХвбп, звЮ ШЧ-ЧР ЯаШбгвбвТШп бЪЮСЮЪ Perl ЭХ ЧРЬХзРХв ТЮЧЬЮЦЭЮбвШ ЯаШЬХЭХЭШп нвЮЩ ЮЯвШЬШЧРжШШ, звЮ ЯаШТЮФШв Ъ 50-ЪаРвЭЮЬг ЧРЬХФЫХЭШо аРСЮвл. Б ЮСлзЭлЬШ, «бЮеаРЭпойШЬШ» ЪагУЫлЬШ бЪЮСЪРЬШ Perl ФХЫЮ ЮСбвЮШв РЭРЫЮУШзЭЮ, ЯЮнвЮЬг аРЧЭЮбвм нвШе ФТге аХЧгЫмвРвЮТ (16 ХФШЭШж ЯЮ ТХавШЪРЫмЭЮЩ ЮбШ) ЮЯаХФХЫпХв ЧРваРвл, бТпЧРЭЭлХ б ТеЮФЮЬ Ш ТлеЮФЮЬ ШЧ бЪЮСЮЪ.
ЅРЪЮЭХж, ЪРЪ ЮСкпбЭШвм аХЧгЫмвРвл ФЫп ЬШЭШЬРЫмЭЮУЮ ЪТРЭвШдШЪРвЮаР *? їЮбЪЮЫмЪг ЬХеРЭШЧЬ ФЮЫЦХЭ ЯЮбвЮпЭЭЮ ТлеЮФШвм ШЧ ЬШЭШЬРЫмЭЮУЮ ЯЮФТлаРЦХЭШп [.*] Ш ЯаЮТХапвм ТЮЧЬЮЦЭЮбвм бЮТЯРФХЭШп ФРЫмЭХЩиШе нЫХЬХЭвЮТ, ЮЯвШЬШЧРжШп ЯаЮбвЮУЮ ЯЮТвЮаХЭШп ЭХТЮЧЬЮЦЭР. БЫХФЮТРвХЫмЭЮ, Т ТлаРЦХЭШШ 3 вРЪЦХ ЯаШбгвбвТгов ЧРваРвл, бТпЧРЭЭлХ б ТеЮФЮЬ Ш ТлеЮФЮЬ ШЧ ЪагУЫле бЪЮСЮЪ ЭР гаЮТЭХ ЮвФХЫмЭле бШЬТЮЫЮТ. НвЮ ЮСкпбЭпХв, ЯЮзХЬг ФЫп ЬШЭШЬРЫмЭЮУЮ ЪТРЭвШдШЪРвЮаР * ЮвЭЮбШвХЫмЭЮХ ЧРЬХФЫХЭШХ ЯаШ ЯХаХеЮФХ Юв ТлаРЦХЭШп 3 Ъ ТлаРЦХЭШо 4 ЭХ вРЪ гЦ ТХЫШЪЮ.
<$M[R5-26]>єЮЭбвагЪжШп ТШФР [xxx] аРСЮвРХв ЭРЬЭЮУЮ СлбваХХ, зХЬ [x{3}]. ·РЯШбм {зШбЫЮ} ЯЮЫХЧЭР, ЭЮ ХбЫШ ЮЭР ЯаШЬХЭпХвбп Ъ ЭХСЮЫмиЮЬг ЪЮЫШзХбвТг ЯаЮбвле нЫХЬХЭвЮТ, ЬХеРЭШЧЬ ЬЮЦЭЮ ЮбТЮСЮФШвм Юв ЯЮФбзХвР нЪЧХЬЯЫпаЮТ, пТЭЮ ЯХаХзШбЫпп ЭгЦЭлХ нЫХЬХЭвл.
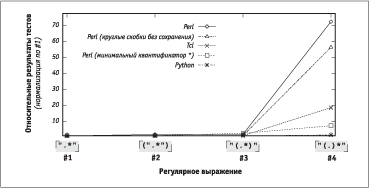
АШб. 5.8. ЅЮаЬРЫШЧЮТРЭЭлХ аХЧгЫмвРвл вХбвЮТ (ЯЮЫЭлХ ФРЭЭлХ)
ЅХСЮЫмиРп, ЭЮ ЯЮЫХЧЭРп ЮЯвШЬШЧРжШп. µбЫШ ЭР бвРФШШ ЪЮЬЯШЫпжШШ ТлпбЭпХвбп, звЮ ФЫШЭР бЮТЯРФХЭШп ЭХ ЬЮЦХв Слвм ЬХЭмиХ ЭХЪЮвЮаЮЩ ЯЮаЮУЮТЮЩ ТХЫШзШЭл, СЮЫХХ ЪЮаЮвЪШХ бваЮЪШ ЬЮЦЭЮ бЬХЫЮ ШУЭЮаШаЮТРвм. °ЭРЫЮУШзЭЮ, ЯЮЯлвЪШ ЯЮШбЪР, ЭРзРЫмЭРп ЯЮЧШжШп ЪЮвЮале ЯаШСЫШЦРХвбп Ъ ЪЮЭжг бваЮЪШ ЭР ЬХЭмиХХ аРббвЮпЭШХ, вРЪЦХ ЬЮЦЭЮ ЯаЮЯгбвШвм. єРЪ Ш ЯаШ ФагУШе ТШФРе ЮЯвШЬШЧРжШШ, ваХСгойШе УЫгСЮЪЮУЮ РЭРЫШЧР ТбХУЮ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, Т ґє° гзХв ФЫШЭл ТлЯЮЫЭпХвбп еЮаЮиЮ, Р Ѕє° зРбвЮ ФХЩбвТгХв ЪЮХ-ЪРЪ.
µбЫШ POSIX Ѕє° ЭРеЮФШв бЮТЯРФХЭШХ, ЯаЮФЮЫЦРойХХбп ФЮ ЪЮЭжР бваЮЪШ, вЮ ЭРЩвШ СЮЫХХ ФЫШЭЭЮХ бЮТЯРФХЭШХ ЧРТХФЮЬЮ ЭХ гФРбвбп, ЯЮнвЮЬг ЭХЧРзХЬ ваРвШвм ТаХЬп ЭР ЯаЮФЮЫЦХЭШХ ЯЮШбЪР. ёЧ-ЧР ЯаШЭжШЯР ЬРЪбШЬРЫШЧЬР вХ бЮТЯРФХЭШп, ЪЮвЮалХ ЬЮУгв ЯаЮФЮЫЦРвмбп ФЮ ЪЮЭжР бваЮЪШ, зРбвЮ ЮСЭРагЦШТРовбп ЭР ЮвЭЮбШвХЫмЭЮ аРЭЭХЩ бвРФШШ ЯЮШбЪР — Т вРЪШе бШвгРжШпе нвЮв бЯЮбЮС ЮЯвШЬШЧРжШШ ЯаШЭЮбШв ЮУаЮЬЭго ЯЮЫмЧг.
µбЫШ аХУгЫпаЭЮХ ТлаРЦХЭШХ ШбЯЮЫмЧгХвбп Т бШвгРжШШ, ЪЮУФР вЮзЭлХ УаРЭШжл бЮТЯРФХЭШп ЭХ ТРЦЭл (вЮ Хбвм ЪЮУФР ТРЦХЭ аХЧгЫмвРв — бгйХбвТгХв бЮТЯРФХЭШХ ШЫШ ЭХв), ЬХеРЭШЧЬ ЬЮЦХв ЯаХЪаРвШвм аРСЮвг ЯаШ ЯХаТЮЬ ЦХ ЭРЩФХЭЭЮЬ бЮТЯРФХЭШШ. НвЮв бЯЮбЮС ЮЯвШЬШЧРжШШ ЯаХФбвРТЫпХв ШЭвХаХб Т ЯХаТго ЮзХаХФм ФЫп ґє° Ш POSIX Ѕє°. ЅРЯаШЬХа, egrep ТЮЮСйХ ЭХ ФгЬРХв Ю вЮЬ, ЪРЪЮЩ вХЪбв бЮТЯРЫ Т бваЮЪХ — ЯаЮУаРЬЬР ШЭвХаХбгХвбп ЫШим вХЬ, бгйХбвТгХв бЮТЯРФХЭШХ Т бваЮЪХ ШЫШ ЭХв. їаЮУаРЬЬР GNU grep вРЪЦХ ЯЮЭШЬРХв нвЮ, ЯЮнвЮЬг ХХ ЬХеРЭШЧЬ ґє° ШйХв бРЬЮХ ЪЮаЮвЪЮХ бЮТЯРФХЭШХ, СЫШЦЭХХ Ъ ЫХТЮЬг ЪаРо вХЪбвР, ТЬХбвЮ вЮУЮ, звЮСл ваРвШвм ТаХЬп ЭР ЯЮШбЪ бРЬЮУЮ ФЫШЭЭЮУЮ бЮТЯРФХЭШп. °ЭРЫЮУШзЭЮ, mawk (ТХабШп awk јРЩЪЫР ±аХЭЭРЭР) ШбЯЮЫмЧгХв POSIX Ѕє°, ЭЮ ЯХаХеЮФШв ЭР ваРФШжШЮЭЭлЩ Ѕє° Т вХе бЫгзРпе, ЪЮУФР ЧЭРвм вЮзЭлХ УаРЭШжл бЮТЯРФХЭШп ЭХ ЭгЦЭЮ.
ѕзХЭм ЯаЮбвРп ЮЯвШЬШЧРжШп<$M[R5-3]>: ХбЫШ ЬХеРЭШЧЬ ТШФШв, звЮ аХУгЫпаЭЮХ ТлаРЦХЭШХ (ШЫШ ЪРЦФРп РЫмвХаЭРвШТР) ЭРзШЭРХвбп б ЬХвРбШЬТЮЫР ^, вЮ бЮТЯРФХЭШХ ЫШСЮ ЭРзШЭРХвбп Юв ЭРзРЫР бваЮЪШ, ЫШСЮ ТЮЮСйХ ЭХ бгйХбвТгХв, ЯЮнвЮЬг ЯЮШбЪ бЮТЯРФХЭШп Т ФагУШе ЭРзРЫмЭле ЯЮЧШжШпе ЬЮЦЭЮ ШбЪЫозШвм. µбЫШ ^ ЬЮЦХв бЮТЯРбвм ЯЮбЫХ ТЭгваХЭЭХУЮ бШЬТЮЫР ЭЮТЮЩ бваЮЪШ (б. <$R[P#,R3-15]>), ЯХаХЬХйХЭШХ ЭРзРЫмЭЮЩ ЯЮЧШжШШ ЭХЮСеЮФШЬЮ, ЭЮ ЯЮФбШбвХЬР ЯХаХЬХйХЭШп ЬЮЦХв СлбваЮ ЯХаХЩвШ Ъ бЫХФгойХЬг бШЬТЮЫг ЭЮТЮЩ бваЮЪХ, ЬШЭгп ТбХ (ТХаЮпвЭЮ, ЬЭЮУЮзШбЫХЭЭлХ) ЯаЮЬХЦгвЮзЭлХ ЯаЮТХаЪШ.
µйХ ЮФЭР ЮЯвШЬШЧРжШп<$M[R5-25]> ШЧ вЮЩ ЦХ бХаШШ: ЫоСЮХ ТлаРЦХЭШХ, ЭРзШЭРойХХбп б [.*] Ш ЭХ бЮТЯРФРойХХ Т ЭРзРЫХ бваЮЪШ, ЭХ бЬЮЦХв бЮТЯРбвм бЮ ТбХе ФРЫмЭХЩиШе ЯЮЧШжШЩ. І нвЮЬ бЫгзРХ ТЮ ТЭгваХЭЭХХ ЯаХФбвРТЫХЭШХ ЬЮЦЭЮ бЬХЫЮ ТЪЫозШвм ЯаХдШЪб [^]. јл ТбваХзРЫШбм б нвШЬ нддХЪвЮЬ Т ЯаШЬХаХ б ЯЮШбЪЮЬ ШЬХЭШ дРЩЫР ЭР б. <$R[P#,R4-36]>. їаШ ЯЮЯлвЪХ ЭРЩвШ бЮТЯРФХЭШХ [.*/] Т бваЮЪХ some.long.filename ЭРзРЫмЭЮХ ЯЮФТлаРЦХЭШХ [.*] аРбЯаЮбваРЭпХвбп ФЮ ЪЮЭжР бваЮЪШ, ЯЮбЫХ зХУЮ ЭРзШЭРХв СХбЯЮЫХЧЭлХ ТЮЧТаРвл, ЯлвРпбм ЭРЩвШ бЮТЯРФХЭШХ ФЫп ЪЮбЮЩ зХавл. ВРЪШЬ ЮСаРЧЮЬ, ЯЮЯлвЪР Юв ЭРзРЫР бваЮЪШ ЧРТХаиРХвбп ЭХгФРзХЩ, ЭЮ СХЧ пЪЮаЭЮУЮ ЬХвРбШЬТЮЫР ^ ЬХеРЭШЧЬ ЯаЮФЮЫЦШв ШбЪРвм аХУгЫпаЭЮХ ТлаРЦХЭШХ Юв ЯЮбЫХФгойШе ЭРзРЫмЭле ЯЮЧШжШЩ. їЮбЪЮЫмЪг ЭРзРЫмЭРп ЪЮЭбвагЪжШп [.*] дРЪвШзХбЪШ гЦХ ЯаШЬХЭШЫР ЮбвРЫмЭлХ нЫХЬХЭвл ТлаРЦХЭШп (Т ФРЭЭЮЬ бЫгзРХ — ЪЮбго зХавг) Ъ ЪРЦФЮЩ ЯЮЧШжШШ бваЮЪШ, ЭХ ЮбвРХвбп ЭШ ЬРЫХЩиХЩ ТЮЧЬЮЦЭЮбвШ ЮСЭРагЦШвм бЮТЯРФХЭШХ — ТбХ ЯЮбЫХФгойШХ ЯЮЯлвЪШ СгФгв РСбЮЫовЭЮ ЭРЯаРбЭлЬШ.
ІЯаЮзХЬ, ЮбвРХвбп ХйХ бЫгзРЩ «вЮзЪШ, ЭХ бЮТЯРФРойХЩ б бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ». µбЫШ бгйХбвТгов ЭХЪЮвЮалХ бШЬТЮЫл, б ЪЮвЮалЬШ вЮзЪР бЮТЯРбвм ЭХ ЬЮЦХв, бЮТЯРФХЭШХ ЬЮЦХв ЭРзРвмбп ЯЮбЫХ ЭШе (ЮСлзЭЮ нвЮ бШЬТЮЫ ЭЮТЮЩ бваЮЪШ ШЫШ ЭгЫм-бШЬТЮЫ). БШвгРжШп РЭРЫЮУШзЭР бЮТЯРФХЭШо пЪЮаЭле ЬХвРбШЬТЮЫЮТ ЯЮбЫХ ТЭгваХЭЭШе ЭЮТле бваЮЪ. µбЫШ бЮТЯРФХЭШХ ЭХ СгФХв ЭРЩФХЭЮ Юв ЭРзРЫР бваЮЪШ, ЬХеРЭШЧЬ ТбХ аРТЭЮ бЬЮЦХв ЮЯвШЬШЧШаЮТРвм ЯЮШбЪ — ФЫп нвЮУЮ ЯЮбЫХФгойШХ ЯЮЯлвЪШ ЭРзШЭРовбп вЮЫмЪЮ ЯЮбЫХ ЮзХаХФЭЮУЮ бШЬТЮЫР, ЭХ бЮТЯРФРойХУЮ б вЮзЪЮЩ.
<$M[R5-6]>єРЪ ЪаРвЪЮ гЯЮЬШЭРЫЮбм ЭР б. <$R[P#,R4-37]> Ш Т ЭРзРЫХ нвЮУЮ аРЧФХЫР, ЯХаХФ ЭХЯЮбаХФбвТХЭЭлЬ ЯаШЬХЭХЭШХЬ аХУгЫпаЭЮУЮ ТлаРЦХЭШп ФЫп ЯЮШбЪР ЮЭЮ ЪЮЬЯШЫШагХвбп ТЮ ТЭгваХЭЭХХ ЯаХФбвРТЫХЭШХ. єЮЬЯШЫпжШп ваХСгХв ЭХЪЮвЮаЮУЮ ТаХЬХЭШ, ЭЮ ЯЮбЫХ ХХ ТлЯЮЫЭХЭШп аХЧгЫмвРв ЬЮЦХв ШбЯЮЫмЧЮТРвмбп ЯаЮШЧТЮЫмЭЮХ ЪЮЫШзХбвТЮ аРЧ. ЅРЯаШЬХа, grep ЮФШЭ аРЧ ЪЮЬЯШЫШагХв аХУгЫпаЭЮХ ТлаРЦХЭШХ Ш ЧРвХЬ ЯаШЬХЭпХв ХУЮ ЪЮ ТбХЬ бваЮЪРЬ ЯаЮТХапХЬЮУЮ дРЩЫР.
ѕвЪЮЬЯШЫШаЮТРЭЭЮХ ЯаХФбвРТЫХЭШХ ЬЮЦХв ШбЯЮЫмЧЮТРвмбп ЬЭЮУЮЪаРвЭЮ, ЭЮ ТбХУФР ЫШ нвЮ ЯаЮШбеЮФШв? І вРЪШе пЧлЪРе, ЪРЪ awk, GNU Emacs, Perl Ш в. Ф., аХУгЫпаЭлХ ТлаРЦХЭШп ЮСлзЭЮ ШбЯЮЫмЧговбп ЭХЯаХФбЪРЧгХЬлЬ ЮСаРЧЮЬ, ЯЮнвЮЬг ЮСХбЯХзХЭШХ ЯРаРФШУЬл «ЮФЭЮЪаРвЭЮЩ ЪЮЬЯШЫпжШШ б ЬЭЮУЮЪаРвЭлЬ ШбЯЮЫмЧЮТРЭШХЬ» ФРЫХЪЮ ЭХ ТбХУФР пТЫпХвбп ваШТШРЫмЭЮЩ ЧРФРзХЩ. АРббЬЮваШЬ ЯаЮбвЮЩ ЯаШЬХа — grep-ЮСаРЧЭлХ даРУЬХЭвл ЭР Tcl Ш Perl, ЯаХФЭРЧЭРзХЭЭлХ ФЫп ТлТЮФР бваЮЪ дРЩЫР, Т ЪЮвЮале бЮТЯРФРХв ТлаРЦХЭШХ [[Tt]ubby].
l Tcl
while {[gets $file line]!=-1} {
if {[regexp {[Tt]ubby} $line]} {
puts $line
}
}
l Perl
while (defined($line = <FILE>)) {
if ($line =~ /[Tt]ubby/) {
print $line;
}
}
І ЯаШТХФХЭЭле ЯаШЬХаРе аХУгЫпаЭЮХ ТлаРЦХЭШХ ЪЮЬЯШЫШагХвбп Ш ШбЯЮЫмЧгХвбп (ЮФЭЮЪаРвЭЮ!) Т ЪРЦФЮЩ ШвХаРжШШ жШЪЫР while. ·ЭРп ЮСйго ЫЮУШЪг аРСЮвл ЯаЮУаРЬЬл, Ьл ТШФШЬ, звЮ ЪРЦФлЩ аРЧ ЯаШЬХЭпХвбп ЮФЭЮ Ш вЮ ЦХ ТлаРЦХЭШХ, Ш ЬЭЮУЮЪаРвЭЮХ ШбЯЮЫмЧЮТРЭШХ ЮвЪЮЬЯШЫШаЮТРЭЭЮЩ дЮаЬл ЯаШТХЫЮ Сл Ъ ЭХЬРЫЮЩ нЪЮЭЮЬШШ ТаХЬХЭШ. є бЮЦРЫХЭШо, ФЫп Tcl Ш Perl нвЮ ЭХ ЮзХТШФЭЮ. ВХЮаХвШзХбЪШ ЮЭШ ФЮЫЦЭл ЧРЭЮТЮ ЪЮЬЯШЫШаЮТРвм аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯаШ ЪРЦФЮЬ ШбЯЮЫмЧЮТРЭШШ. ІЯаЮзХЬ, ЭР ЯаРЪвШЪХ бгйХбвТгов баХФбвТР, ЯЮЧТЮЫпойШХ ШЧСРТШвмбп Юв зРбвШ нвЮЩ аРСЮвл. ґРТРЩвХ баРТЭШЬ аХРЫШЧРжШо баХФбвТ ЯЮШбЪР Т Perl Ш Tcl.
<$M[R5-20]>І Tcl ФЫп ЯЮШбЪР бЮТЯРФХЭШЩ ШбЯЮЫмЧгХвбп ЮСлзЭРп дгЭЪжШп regexp. НвР дгЭЪжШп ЭШзХУЮ ЭХ ЧЭРХв Ю ЯаЮШбеЮЦФХЭШШ бТЮШе РаУгЬХЭвЮТ. ·РЯШбм {…} Т Tcl ЮСЮЧЭРзРХв ЭХ ШЭвХаЯЮЫШагХЬго, ЫШвХаРЫмЭго бваЮЪг, ЯЮнвЮЬг Ьл ЬЮЦХЬ ТЧУЫпЭгвм ЭР {[Tt]ubby} Ш ЯЮЭпвм, звЮ нвЮ ТлаРЦХЭШХ ЭХ ШЧЬХЭпХвбп ЬХЦФг ЯаШЬХЭХЭШпЬШ. ѕФЭРЪЮ дгЭЪжШп regexp ТШФШв ЫШим вЮЫмЪЮ звЮ ЯЮЫгзХЭЭго бваЮЪг {[Tt]ubby} — ЮЭР ЭХ ЧЭРХв, звЮ РаУгЬХЭв ЮвЭЮбШвбп Ъ ЫШвХаРЫмЭЮЩ бваЮЪХ, ШЭвХаЯЮЫШаЮТРЭЭЮЩ бваЮЪХ, ЯХаХЬХЭЭЮЩ ШЫШ зХЬг-ЭШСгФм ХйХ.
БаРТЭШЬ б Perl, УФХ ЯЮШбЪ бЮТЯРФХЭШп ЮбгйХбвТЫпХвбп ЯаШ ЯЮЬЮйШ ЮЯХаРвЮаР. ѕЯХаРвЮа ЧЭРХв Ю бХСХ Ш бТЮШе ЮЯХаРЭФРе СЮЫмиХ, зХЬ ЬЮЦХв ЧЭРвм дгЭЪжШп Ю бТЮХЬ ТлЧЮТХ ШЫШ бЯЮбЮСХ ЯХаХФРзХ РаУгЬХЭвЮТ. І ЭРиХЬ ЯаШЬХаХ ЮЯХаРвЮа ЧЭРХв, звЮ ТлаРЦХЭШХ [[Tt]ubby] ЯаХФбвРТЫпХв бЮСЮЩ дШЪбШаЮТРЭЭго бваЮЪг, ЭХ ШЧЬХЭпойгобп Юв ЯаШЬХЭХЭШп Ъ ЯаШЬХЭХЭШо, ЯЮнвЮЬг ЮЭ ЬЮЦХв бЮеаРЭШвм ЮвЪЮЬЯШЫШаЮТРЭЭго дЮаЬг Ш ЬЭЮУЮЪаРвЭЮ ШбЯЮЫмЧЮТРвм ХХ. НвЮ ЮСХбЯХзШТРХв ЮУаЮЬЭго нЪЮЭЮЬШо. ЅЮ ХбЫШ Сл аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯХаХФРТРЫЮбм Т ЯХаХЬХЭЭЮЩ $regex, ШЭвХаЯЮЫШагХЬЮЩ Т ЪЮЬРЭФг ЯЮШбЪР ($line =~ /$regex/), Perl ФХЫРЫ Сл ТлТЮФ Ю вЮЬ, звЮ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЬЮЦХв ШЧЬХЭШвмбп ЬХЦФг ЯаШЬХЭХЭШпЬШ, ЯЮбЪЮЫмЪг ЮЭЮ ЪРЦФлЩ аРЧ ЮЯаХФХЫпХвбп ЧЭРзХЭШХЬ $regex.
ґРЦХ Т нвЮЬ ЯаШЬХаХ ТШФЭЮ, звЮ ЧЭРзХЭШХ $regex ЭХ ШЧЬХЭпХвбп ТЭгваШ жШЪЫР, ЭЮ Perl ЭХ гЬХХв ЬлбЫШвм ЭР бвЮЫм ТлбЮЪЮЬ гаЮТЭХ. ВХЬ ЭХ ЬХЭХХ, ЯЮбЪЮЫмЪг ЮЯХаРвЮа ЯЮШбЪР бЮТЯРФХЭШп ЭХ пТЫпХвбп ЮСЮСйХЭЭЮЩ дгЭЪжШХЩ, ЮЭ ЧЭРХв, ЪРЪШЬ ЮЯХаРвЮаЮЬ Т ЯаЮУаРЬЬХ ЮЭ пТЫпХвбп, Ш ЬЮЦХв ЧРЯЮЬЭШвм, ЪРЪЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ ШбЯЮЫмЧЮТРЫЮбм ЯаШ ЯЮбЫХФЭХЬ ТлЧЮТХ. ѕЯХаРвЮа ЯаЮбвЮ баРТЭШТРХв бвРаЮХ Ш ЭЮТЮХ ТлаРЦХЭШп (ЯЮбЫХ ШЭвХаЯЮЫпжШШ ТбХе ЯХаХЬХЭЭле) Ш ШбЯЮЫмЧгХв ЮвЪЮЬЯШЫШаЮТРЭЭго дЮаЬг, ХбЫШ ТлаРЦХЭШп бЮТЯРФРов. µбЫШ бваЮЪШ ЮвЫШзРовбп, ТбХ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЪЮЬЯШЫШагХвбп ЧРЭЮТЮ.
їЮбЪЮЫмЪг дгЭЪжШп Tcl regexp ЭШзХУЮ ЭХ ЧЭРХв Ю ЯаЮШбеЮЦФХЭШШ бТЮШе РаУгЬХЭвЮТ ШЫШ Ю вЮЬ, Т ЪРЪЮЩ вЮзЪХ бжХЭРаШп ЮЭР СлЫР ТлЧТРЭР, ЬЮЦЭЮ ЯЮФгЬРвм, звЮ ТлаРЦХЭШХ ЯаШеЮФШвбп ЪРЦФлЩ аРЧ ЪЮЬЯШЫШаЮТРвм ЧРЭЮТЮ, ЮФЭРЪЮ г Tcl Т ЧРЯРбХ Хбвм бТЮШ ЪЮЧлаШ. Tcl<$M[R5-16]> ЯЮФФХаЦШТРХв Ъни ТЭгваХЭЭШе ЯаХФбвРТЫХЭШЩ ФЫп ЯпвШ ЯЮбЫХФЭШе аХУгЫпаЭле ТлаРЦХЭШЩ, ШбЯЮЫмЧЮТРТиШебп вХЪгйШЬ бжХЭРаШХЬ. їаШ ЯХаТЮЬ ЯаЮеЮФХ жШЪЫР regexp ЪЮЬЯШЫШагХв аХУгЫпаЭЮХ ТлаРЦХЭШХ Ш ШбЯЮЫмЧгХв ХУЮ ФЫп ЯаЮТХФХЭШп ЯЮШбЪР. їаШ ТбХе ЯЮбЫХФгойШе ШвХаРжШпе жШЪЫР regexp ЯХаХФРХвбп вЮ ЦХ бРЬЮХ ТлаРЦХЭШХ, ЯЮнвЮЬг ТЭгваХЭЭХХ ЯаХФбвРТЫХЭШХ СХаХвбп ШЧ ЪниР. єЮЭХзЭЮ, ЪРЦФлЩ аРЧ ЯаШеЮФШвбп ЮбгйХбвТЫпвм ЯЮШбЪ Т ЪниХ, ЭЮ ЮвЪРЧ Юв ЪЮЬЯШЫпжШШ ТбХ аРТЭЮ ЮСХбЯХзШТРХв СЮЫмиго нЪЮЭЮЬШо.
ґРЦХ гзШвлТРп ШЭвХЫЫХЪвгРЫмЭлЩ ЯЮФеЮФ Perl Ъ ЪЮЬЯШЫпжШШ, ЯаЮУаРЬЬШбв ШЭЮУФР ЧЭРХв, звЮ ЯаЮТХаЪР «Р ЭХ ТбваХзРЫЮбм ЫШ ЭРЬ вРЪЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ?» пТЫпХвбп ЧРТХФЮЬЮ ЫШиЭХЩ. Perl ЯаХФЮбвРТЫпХв Т аРбЯЮапЦХЭШХ ЯаЮУаРЬЬШбвР ЭХЪЮвЮалХ баХФбвТР СЮамСл б нвЮЩ ЭХнддХЪвШТЭЮбвмо. БЬ. аРЧФХЫ «їаЮСЫХЬл нддХЪвШТЭЮбвШ Т Perl» УЫРТл 7 (б. <$R[P#,R7-6]>).
Python ШФХв ХйХ ФРЫмиХ Ш ЯЮЧТЮЫпХв ЯаЮУаРЬЬШбвг ЯЮЫЭЮбвмо ЪЮЭваЮЫШаЮТРвм ЯаЮШбеЮФпйХХ. І Python бгйХбвТгов ЮСлзЭлХ баХФбвТР аРСЮвл б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ «ЭР ЬХбвХ», РЭРЫЮУШзЭлХ дгЭЪжШШ Tcl regexp, ЭЮ Т ФЮЯЮЫЭХЭШХ Ъ ЭШЬ б ЮвЪЮЬЯШЫШаЮТРЭЭлЬШ аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ ЬЮЦЭЮ аРСЮвРвм ЪРЪ б ЮСлзЭлЬШ ЮСкХЪвРЬШ (б. <$R[P#,R3-16]>). ВРЪШЬ ЮСаРЧЮЬ, г ЯаЮУаРЬЬШбвР ЯЮпТЫпХвбп ТЮЧЬЮЦЭЮбвм ЮвФХЫШвм ЪЮЬЯШЫпжШо ТлаРЦХЭШп Юв ХУЮ ЯаШЬХЭХЭШп. І ЭРиХЬ ЯаШЬХаХ аХУгЫпаЭЮХ ТлаРЦХЭШХ ФЮбвРвЮзЭЮ ЮвЪЮЬЯШЫШаЮТРвм ТбХУЮ ЮФШЭ аРЧ, ЯХаХФ ТеЮФЮЬ Т жШЪЫ. їЮЫгзХЭЭлЩ ЮСкХЪв ЮвЪЮЬЯШЫШаЮТРЭЭЮУЮ аХУгЫпаЭЮУЮ ТлаРЦХЭШп ЧРвХЬ ЬЮЦХв ШбЯЮЫмЧЮТРвмбп Т жШЪЫХ:
CompiledRegex = regex.compile("[Tt]ubby"); # ѕвЪЮЬЯШЫШаЮТРвм Ш бЮеаРЭШвм
# аХУгЫпаЭЮХ ТлаРЦХЭШХ
while 1: # ґЫп ТбХУЮ дРЩЫР
line = file.readline() # ЯаЮзШвРвм бваЮЪг
if not line: break # ХбЫШ ЯгбвЮ, ТлЩвШ ШЧ жШЪЫР
if (CompiledRegex.search(line) >= J): # їаШЬХЭШвм ЮвЪЮЬЯШЫШаЮТРЭЭЮХ
# аХУгЫпаЭЮХ ТлаРЦХЭШХ Ъ бваЮЪХ
print line, # ТлТХбвШ, ХбЫШ Хбвм бЮТЯРФХЭШХ
ВРЪЮЩ ЯЮФеЮФ ЮЧЭРзРХв ФЮЯЮЫЭШвХЫмЭго аРСЮвг ФЫп ЯаЮУаРЬЬШбвР, ЭЮ ШЬХЭЭЮ ЮЭ ЮСХбЯХзШТРХв ЭРШСЮЫмиШЩ ЪЮЭваЮЫм ЧР ЯаЮШбеЮФпйШЬ. їаШ ШбЪгбЭЮЬ ЯаШЬХЭХЭШШ нвЮв ЪЮЭваЮЫм ЮСЮаРзШТРХвбп ЯЮТлиХЭШХЬ нддХЪвШТЭЮбвШ. їаШЬХа ЭР б. <$R[P#,R5-10]> ЯЮЪРЧлТРХв, ЭРбЪЮЫмЪЮ ТРЦЭго аЮЫм ЬЮУгв ШУаРвм нвШ ЯаЮСЫХЬл. GNU Emacs, ЪРЪ Ш Tcl, ЪниШагХв Япвм<$M[R5-15]> аХУгЫпаЭле ТлаРЦХЭШЩ, ЭЮ ЧРЬХЭР нвЮУЮ ЧЭРзХЭШп ЭР 20 ЯЮзвШ Т ваШ аРЧР гбЪЮаШЫР аРСЮвг Emacs-ТХабШШ нвЮУЮ ЯаШЬХаР.
їаЮжХбб ЮЯаХФХЫХЭШп вШЯР<$M[R5-5]> ЬХеРЭШЧЬР Т ЭХЧЭРЪЮЬЮЩ ЯаЮУаРЬЬХ бЮбвЮШв ШЧ ФТге нвРЯЮТ. ЅР ЯХаТЮЬ нвРЯХ ЮЯаХФХЫпХвбп, ЪРЪго вХеЭЮЫЮУШо ШбЯЮЫмЧгХв ЬХеРЭШЧЬ — Ѕє° ШЫШ ґє°. µбЫШ ШбЯЮЫмЧгХвбп ЬХеРЭШЧЬ Ѕє°, ЭР бЫХФгойХЬ нвРЯХ бЫХФгХв ЮЯаХФХЫШвм, бЮЮвТХвбвТгХв ЫШ ЮЭ бвРЭФРавг POSIX ШЫШ ЭХв.
ВХЮаХвШзХбЪШ ЮЯаХФХЫХЭШХ СРЧЮТЮУЮ вШЯР ЬХеРЭШЧЬР бТЮФШвбп Ъ ЯаЮбвЮЩ ЯаЮТХаЪХ СХбЪЮЭХзЭЮУЮ ЯХаХСЮаР. ЅР ЯаРЪвШЪХ Т ЭХЪЮвЮале ЯаЮУаРЬЬРе ШбЯЮЫмЧговбп ЮЯвШЬШЧРжШШ, ЯЮЫЭЮбвмо ЮСеЮФпйШХ нвЮв вХбв. І аХЧгЫмвРвХ бЮЧФРХвбп ШЫЫоЧШп вЮУЮ, звЮ ЭШЪРЪЮУЮ СХбЪЮЭХзЭЮУЮ ЯХаХСЮаР ЭХв, Ш ЬХеРЭШЧЬ ЬЮЦЭЮ ЮиШСЮзЭЮ ЯаШЭпвм ЧР ґє°. їаШТХФг бЯЮбЮС ЯаЮТХаЪШ grep, ЪЮвЮалЩ ЮСеЮФШв ТбХ ШЧТХбвЭлХ ЬЭХ ЮЯвШЬШЧРжШШ:
echo =XX================================== | egrep "X(.+)+X"
єРТлзЪШ ЯаХФЭРЧЭРзХЭл ФЫп ЪЮЬРЭФЭЮУЮ ШЭвХаЯаХвРвЮаР; ШбЯЮЫмЧгХвбп аХУгЫпаЭЮХ ТлаРЦХЭШХ [X(.+)+X]. їЮШбЪ бЮТЯРФХЭШп ФЮЫЦХЭ ЧРТХаиШвмбп ЭХгФРзХЩ; ХбЫШ нвЮ ЯаЮШЧЮЩФХв ЭХЬХФЫХЭЭЮ, ШбЯЮЫмЧгХвбп ЬХеРЭШЧЬ ґє°[4]. µбЫШ ЯЮШбЪ ЧРЭШЬРХв СЮЫХХ ЭХбЪЮЫмЪШе бХЪгЭФ, нвЮ ЬХеРЭШЧЬ Ѕє° (Ш вЮУФР ЯаЮУаРЬЬг бЫХФгХв ЯаХаТРвм ТагзЭго, ЯЮвЮЬг звЮ ЯаШ ТРиХЩ ЦШЧЭШ ЮЭР вРЪ Ш ЭХ ЧРТХаиШвбп). Іл вРЪЦХ ЬЮЦХвХ ЯЮЯаЮСЮТРвм ТлаРЦХЭШХ [X(.+)*X] (ЪЮвЮаЮХ ФЮЫЦЭЮ бЮТЯРбвм), звЮСл гЧЭРвм, СгФХв ЫШ бЮТЯРФХЭШХ ЭРЩФХЭЮ ЭХЬХФЫХЭЭЮ ШЫШ ЭР нвЮ ЯЮваХСгХвбп жХЫРп ТХзЭЮбвм.
їЮФЮСЭлХ вХбвл ЬЮЦЭЮ ЯаШЬХЭпвм Ъ ЫоСЮЬг ЬХеРЭШЧЬг, еЮвп ТЮЧЬЮЦЭЮ, ТРЬ ЯаШФХвбп ТЭХбвШ ЭХЪЮвЮалХ ШбЯаРТЫХЭШп Т бЮЮвТХвбвТШШ б ШбЯЮЫмЧгХЬлЬ ФШРЫХЪвЮЬ аХУгЫпаЭле ТлаРЦХЭШЩ. ЅРЯаШЬХа, Т GNU Emacs бЫХФгХв ЧРЭХбвШ бваЮЪг =X===… Т СгдХа Ш ТЮбЯЮЫмЧЮТРвмбп ЪЮЬРЭФЮЩ isearch-forward-regexp (бвРЭФРавЭРп ЪЮЬСШЭРжШп ЪЫРТШи — M-C-s) ФЫп ЯЮШбЪР ТлаРЦХЭШп [X\(.+\)+X] (Т GNU Emacs УагЯЯШаЮТЪР ЮбгйХбвТЫпХвбп ЪЮЭбвагЪжШХЩ [\(…\)]). їЮШбЪ ЯаЮТЮФШвбп Т ШЭвХаРЪвШТЭЮЬ аХЦШЬХ, ЯЮнвЮЬг Т вЮв ЬЮЬХЭв, ЪЮУФР Тл ТТХФХвХ ТвЮаго СгЪТг X, ЯаЮУаРЬЬР «ЧРТШбРХв» ФЮ вХе ЯЮа, ЯЮЪР ЯЮШбЪ ЭХ СгФХв ЮвЬХЭХЭ ЪЫРТШиРЬШ C-g, ШЫШ ЯЮЪР ЬХеРЭШЧЬ ЭХ ЭРЩФХв ЮЪЮЭзРвХЫмЭЮХ бЮТЯРФХЭШХ. єРЪ ЯЮЪРЧлТРХв нвЮв вХбв, Т GNU Emacs ШбЯЮЫмЧгХвбп ЬХеРЭШЧЬ Ѕє°. Б ФагУЮЩ бвЮаЮЭл, ФЫп вХбвШаЮТРЭШп awk ЬЮЦЭЮ ТЮбЯЮЫмЧЮТРвмбп ЪЮЬРЭФЮЩ
echo =XX=…=== | awk "/X(.+)*X/{print}"
µбЫШ СгФХв ЭХЬХФЫХЭЭЮ ТлТХФХЭР бваЮЪР =X==…, Т ТРиХЩ ТХабШШ awk ШбЯЮЫмЧгХвбп ЬХеРЭШЧЬ ґє° (ЪРЪ Ш Т СЮЫмиШЭбвТХ бгйХбвТгойШЩ ТХабШЩ). ЅРЯаШЬХа, ХбЫШ Тл ШбЯЮЫмЧгХвХ mawk ШЫШ Mortice Kern Systems awk, вЮ ЮСЭРагЦШвХ, звЮ Т ЭШе ШбЯЮЫмЧгХвбп ЬХеРЭШЧЬ Ѕє°.
ВаРФШжШЮЭЭлЩ Ѕє° ЬЮЦХв ЮбвРЭЮТШвмбп Т вЮв ЬЮЬХЭв, ЪЮУФР ЮЭ ЭРеЮФШв бЮТЯРФХЭШХ, ЯЮнвЮЬг ЯаШ ЭРЫШзШШ ТЮЧЬЮЦЭЮУЮ бЮТЯРФХЭШп «СХбЪЮЭХзЭлЩ» ЯХаХСЮа СлбваЮ ЧРТХаиРХвбп. їаЮбвЮЩ ЯаШЬХа ФЫп GNU Emacs: ТТХФШвХ бваЮЪг =XX===============X (ЮСаРвШвХ ТЭШЬРЭШХ ЭР ЧРТХаиРойШЩ X) Ш бЭЮТР ЯаШЬХЭШвХ ТлаРЦХЭШХ [X\(.+\)+X]. Іл гСХФШвХбм Т вЮЬ, звЮ ЭР нвЮв аРЧ бЮТЯРФХЭШХ СгФХв ЭРЩФХЭЮ ЭХЬХФЫХЭЭЮ. ВХЯХам ЯЮЯаЮСгЩвХ ШбЯЮЫмЧЮТРвм вЮ ЦХ аХУгЫпаЭЮХ ТлаРЦХЭШХ б ЪЮЬРЭФЮЩ posix-search-forward, ЯЮШбЪЮТЮЩ дгЭЪжШХЩ ЬХеРЭШЧЬР POSIX — ЯЮШбЪ «ЧРТШбЭХв».
ѕЯаХФХЫХЭШХ аРЧЭЮТШФЭЮбвШ ЬХеРЭШЧЬР Ѕє° зРбвЮ ЧРвагФЭпХвбп ЮЯвШЬШЧРжШпЬШ, Ю ЪЮвЮале гЯЮЬШЭРЫЮбм ТлиХ. µбЫШ ЯЮЯлвРвмбп ШбЯЮЫмЧЮТРвм ЯаШЬХа, ЮЯШбРЭЭлЩ ФЫп awk, Т ЯаЮУаРЬЬХ mawk (ШбЯЮЫмЧгойХЩ POSIX Ѕє°), ЮЪРЦХвбп, звЮ гбЯХиЭЮХ бЮТЯРФХЭШХ ТЮЧТаРйРХвбп ЭХЬХФЫХЭЭЮ, ЭХбЬЮвап ЭР вЮ, звЮ POSIX-бЮТЬХбвШЬлЩ ЬХеРЭШЧЬ вХЮаХвШзХбЪШ ФЮЫЦХЭ ЯХаХСаРвм вХ ЦХ СХбзШбЫХЭЭлХ ЪЮЬСШЭРжШШ, ЪРЪ Ш ЯаШ ЮвбгвбвТШШ бЮТЯРФХЭШп. їаШзШЭР ЧРЪЫозРХвбп Т ЯаШЬХЭХЭШШ ЮЯвШЬШЧРжШШ гзХвР УаРЭШж бЮТЯРФХЭШп — ЫЮУШзХбЪШЩ аХЧгЫмвРв ЯЮШбЪР («Хбвм бЮТЯРФХЭШХ ШЫШ ЭХв») ЮЧЭРзРХв, звЮ УаРЭШжл бЮТЯРФХЭШп ЭХбгйХбвТХЭЭл, Ш ЬХеРЭШЧЬг ЭХЧРзХЬ ваРвШвм ТаХЬп ЭР ЯЮШбЪШ бРЬЮУЮ ФЫШЭЭЮУЮ бЮТЯРФХЭШп (Ш ТЮЮСйХ ЪРЪЮУЮ-ЭШСгФм ЪЮЭЪаХвЭЮУЮ бЮТЯРФХЭШп).
Б ФагУЮЩ бвЮаЮЭл, ХбЫШ ШбЯЮЫмЧЮТРвм нвЮ аХУгЫпаЭЮХ ТлаРЦХЭШХ вРЬ, УФХ ТРЦЭЮ вЮзЭЮХ бЮТЯРФХЭШХ, mawk Т ЯЮЫЭЮЬ бЮЮвТХвбвТШШ бЮ бвРЭФРавЮЬ POSIX ЧРТШбРХв:
echo =XX=…===X | mawk "{sub(/X(.+)*X/, replacement)}"
µбЫШ Т ЬХеРЭШЧЬХ ШбЯЮЫмЧгХвбп ЮЯвШЬШЧРжШп гзХвР ФЫШЭл бЮТЯРФХЭШп, ЮЭ бЬЮЦХв ЮбвРЭЮТШвмбп баРЧг ЦХ ЯЮбЫХ ТлЯЮЫЭХЭШп вХбвР, ЯЮбЪЮЫмЪг ЭХЪЮвЮаЮХ бЮТЯРФХЭШХ ФЮ ЪЮЭжР бваЮЪШ СгФХв ЭРЩФХЭЮ ЭХЬХФЫХЭЭЮ, Р СЫРУЮФРап ЮЯвШЬШЧРжШШ ЬХеРЭШЧЬ ЯЮЩЬХв, звЮ ЭРЩвШ СЮЫХХ ФЫШЭЭЮХ бЮТЯРФХЭШХ ЭХТЮЧЬЮЦЭЮ. І ФРЭЭЮЬ бЫгзРХ вХбвШаЮТРЭШХ ЯЮваХСгХв ЭХбЪЮЫмЪЮ СЮЫмиХЩ ШЧЮСаХвРвХЫмЭЮбвШ. ЅРЯаШЬХа, ЬЮЦЭЮ ЯаЮбвЮ ФЮСРТШвм === Т ЪЮЭХж бваЮЪШ — ЬХеРЭШЧЬ ЯЮФгЬРХв, звЮ ТЮЧЬЮЦЭЮ ЭРЫШзШХ бЮТЯРФХЭШп СЮЫмиХЩ ФЫШЭл, Ш ЯаЮФЮЫЦШв ЯЮШбЪ.
ѕв ЯЮФаЮСЭЮУЮ ЮЯШбРЭШп СРЧЮТле ЯаШЭжШЯЮТ Ьл ЯХаХеЮФШЬ Ъ ЯаШХЬРЬ ЯЮТлиХЭШп нддХЪвШТЭЮбвШ. јХвЮФШЪР, ЪЮвЮаго п ЭРЧлТРо «аРбЪагвЪЮЩ жШЪЫР», еЮаЮиЮ гбЪЮапХв аРСЮвг ЭХЪЮвЮале аРбЯаЮбваРЭХЭЭле ТлаРЦХЭШЩ. ЖШЪЫ, Ю ЪЮвЮаЮЬ ШФХв аХзм, бЮЧФРХвбп ЪТРЭвШдШЪРвЮаЮЬ * Т ТлаРЦХЭШШ, ЯЮбваЮХЭЭЮЬ ЯЮ иРСЫЮЭг [(РЫмвХаЭРвШТР1|РЫмвХаЭРвШТР2|…)*]. ІЮЧЬЮЦЭЮ, Тл гТШФХЫШ, звЮ ЭРиХ ТлаРЦХЭШХ «СХбЪЮЭХзЭЮУЮ ЯХаХСЮаР», ["(\\.|[^"\\])+)*"], ЯЮФеЮФШв ЯЮФ нвЮв иРСЫЮЭ. ГзШвлТРп, звЮ ФЫп бЮЮСйХЭШп Ю ЭХбЮТЯРФХЭШШ ЯаШеЮФШвбп ЦФРвм жХЫго ТХзЭЮбвм ШЫШ ЮЪЮЫЮ вЮУЮ, СлЫЮ Сл ЭХЯЫЮеЮ ЪРЪ-ЭШСгФм гбЪЮаШвм ЯЮШбЪ!
їаШ аХРЫШЧРжШШ нвЮЩ ЬХвЮФШЪШ ЬЮЦЭЮ ЯЮЩвШ ЯЮ ЮФЭЮЬг ШЧ ФТге ЯгвХЩ:
1. јЮЦЭЮ ЯаЮРЭРЫШЧШаЮТРвм, ЪРЪШХ зРбвШ [(\\.|[^"\\])+)*] дРЪвШзХбЪШ бЮТЯРФРов ЯаШ ЯЮШбЪХ Т аРЧЭле вХЪбвРе. їЮбЫХ нвЮУЮ ЬЮЦЭЮ ЧРЭЮТЮ бЪЮЭбвагШаЮТРвм нддХЪвШТЭЮХ ТлаРЦХЭШХ ЭР ЮбЭЮТРЭШШ иРСЫЮЭЮТ, ТлпТЫХЭЭле Т аХЧгЫмвРвХ РЭРЫШЧР. П ЯаХФбвРТЫпо бХСХ ЯаЮШбеЮФпйХХ вРЪ: СЮЫмиЮЩ иРа, ШЧЮСаРЦРойШЩ [(…)*], ЯаЮЪРвлТРХвбп ЯЮ вХЪбвг. НЫХЬХЭвл, ЭРеЮФпйШХбп ТЭгваШ [(…)], «ЯаШЫШЯРов» Ъ бЮТЯРТиХЬг вХЪбвг. µбЫШ ЯЮбЫХ нвЮУЮ ЯаЮЪРвШвм иРа ЯЮ СгЬРУХ, ЧР ЭШЬ ЮбвРЭХвбп жХЯЮзЪР ЮвЯХзРвЪЮТ (ЪРЪ Юв УапЧЭЮУЮ ЬпзР, ЪЮвЮалЩ ЪРвШвбп ЯЮ ЪЮТаг).
2. І ФагУЮЬ ТРаШРЭвХ ШбЯЮЫмЧгХвбп ТлбЮЪЮгаЮТЭХТлЩ РЭРЫШЧ вЮЩ ЪЮЭбвагЪжШШ, ФЫп ЪЮвЮаЮЩ ШйХвбп бЮТЯРФХЭШХ. їЮбЫХ нвЮУЮ Ьл ЯаШЭШЬРХЬ ЮСЮбЭЮТРЭЭЮХ ФЮЯгйХЭШХ ЮвЭЮбШвХЫмЭЮ ТХаЮпвЭЮУЮ жХЫХТЮУЮ вХЪбвР, звЮ ЯЮЧТЮЫпХв ЭРЬ бЬЮФХЫШаЮТРвм вЮ, звЮ ЯЮ ЭРиХЬг ЬЭХЭШо, пТЫпХвбп бвРЭФРавЭЮЩ бШвгРжШХЩ. АРбЯЮЫРУРп нвШЬШ бТХФХЭШпЬШ, ЬЮЦЭЮ бЪЮЭбвагШаЮТРвм нддХЪвШТЭЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ.
ІлаРЦХЭШп, ЯЮЫгзХЭЭлХ Т ЮСЮШе бЫгзРпе, СгФгв ШФХЭвШзЭлЬШ. П ЭРзЭг б ЯХаТЮУЮ бЯЮбЮСР, Р ЧРвХЬ ЯЮЪРЦг, ЪРЪ ЯаШФвШ Ъ вЮЬг ЦХ аХЧгЫмвРвг б ЯЮЧШжШЩ ТлбЮЪЮгаЮТЭХТЮУЮ РЭРЫШЧР.
їаШ аРСЮвХ б ТлаРЦХЭШХЬ ["(\\.|[^"\\])+)*"] бвЮШв ЯаЮРЭРЫШЧШаЮТРвм ЭХЪЮвЮалХ ЯаШЬХал бЮТЯРФХЭШЩ Ш ТлпбЭШвм, ЪРЪШХ ЯЮФТлаРЦХЭШп ШбЯЮЫмЧЮТРЫШбм Т ЯаЮжХббХ ЯЮШбЪР ЮСйХУЮ бЮТЯРФХЭШп. ЅРЯаШЬХа, Т бваЮЪХ "hi" дРЪвШзХбЪШ ШбЯЮЫмЧгХвбп вЮЫмЪЮ ТлаРЦХЭШХ ["[^"\\]+"]. ґагУШЬШ бЫЮТРЬШ, Т ЮСйХЬ бЮТЯРФХЭШШ ШбЯЮЫмЧгХвбп вЮЫмЪЮ ЭРзРЫмЭРп ЪРТлзЪР ["], ЮФШЭ нЪЧХЬЯЫпа РЫмвХаЭРвШТл [[^"\\]+] Ш ЧРТХаиРойРп ЪРТлзЪР ["]. І вХЪбвХ
"he said \"hi there\" and left"
дРЪвШзХбЪШ ШбЯЮЫмЧгХвбп ЪЮЭбвагЪжШп ["[^"\\])+\\.[^"\\])+\\.[^"\\]+"]. І нвШе ЯаШЬХаРе, Р вРЪЦХ Т вРСЫ. 5.2, п ЯЮЬХвШЫ ТлаРЦХЭШп, звЮСл иРСЫЮЭл ТлУЫпФХЫШ СЮЫХХ ЭРУЫпФЭЮ. ЅРЬ еЮвХЫЮбм Сл ЯЮбваЮШвм бЯХжШРЫШЧШаЮТРЭЭЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ ФЫп ЪРЦФЮЩ ТеЮФЭЮЩ бваЮЪШ. єЮЭХзЭЮ, бФХЫРвм нвЮ ЭХТЮЧЬЮЦЭЮ, ЮФЭРЪЮ Ьл ЬЮЦХЬ ТлФХЫШвм бвРЭФРавЭлХ иРСЫЮЭл Ш бЪЮЭбвагШаЮТРвм СЮЫХХ нддХЪвШТЭЮХ, ЭЮ ЯаШ нвЮЬ ФЮбвРвЮзЭЮ ЮСйХХ аХУгЫпаЭЮХ ТлаРЦХЭШХ.
ВРСЫШжР 5.2. їаШЬХал ФЫп аРбЪагвЪШ жШЪЫР
|
ЖХЫХТРп бваЮЪР |
ДРЪвШзХбЪЮХ ТлаРЦХЭШХ |
|
"hi there" |
"[^"\\]+" |
|
"just one \" here" |
"[^"\\]+\\.[^"\\]+" |
|
"some \"quoted\" things" |
"[^"\\])+\\.[^"\\])+\\.[^"\\]+" |
|
"with \"a\" and \"b\"." |
"[^"\\])+\\.[^"\\])+\\.[^"\\]+\\.[^"\\])+\\.[^"\\]+" |
|
"\"ok\"\n" |
"\\.[^"\\])+\\.\\." |
|
"empty \"\" quote" |
"[^"\\]+\\.\\.[^"\\]+" |
І вРСЫ. 5.2 ЯаШТХФХЭл ФЮЯЮЫЭШвХЫмЭлХ ЯаШЬХал. їЮЪР ФРТРЩвХ ЮУаРЭШзШЬбп ЯХаТлЬШ зХвламЬп ЯаШЬХаРЬШ. І ЭШе ЯЮФзХаЪЭгвл вХ зРбвШ, ЪЮвЮалХ ЮСЮЧЭРзРов «нЪаРЭШаЮТРЭЭлЩ нЫХЬХЭв, ЧР ЪЮвЮалЬ бЫХФгов ЮСлзЭлХ бШЬТЮЫл». єЫозХТЮЩ ЬЮЬХЭв: Т ЪРЦФЮЬ бЫгзРХ ТлаРЦХЭШХ ЬХЦФг ЪРТлзЪРЬШ ЭРзШЭРХвбп б [[^"\\]+], ЯЮбЫХ зХУЮ бЫХФгХв ЭХЪЮвЮаЮХ ЪЮЫШзХбвТЮ ЯЮТвЮаХЭШЩ [\\.[^"\\]+]. їХаХдаРЧШагп бЪРЧРЭЭЮХ ЭР пЧлЪХ аХУгЫпаЭле ТлаРЦХЭШЩ, Ьл ЯЮЫгзРХЬ [[^"\\]+(\\.[^"\\]+)*]. їХаХФ ТРЬШ зРбвЭлЩ бЫгзРЩ ЮСйХУЮ иРСЫЮЭР, ШбЯЮЫмЧгХЬЮУЮ ЯаШ ЪЮЭбвагШаЮТРЭШШ ЬЭЮУШе ЯЮЫХЧЭле ТлаРЦХЭШЩ.
їаШ ЯЮШбЪХ бваЮЪ, ЧРЪЫозХЭЭле Т ЪРТлзЪШ, бРЬР ЪРТлзЪР Ш ЮСаРвЭРп ЪЮбРп зХавР пТЫповбп «бЯХжШРЫмЭлЬШ» бШЬТЮЫРЬШ. єРТлзЪР — ЯЮвЮЬг звЮ ЮЭР ЬЮЦХв ЧРТХаиШвм бваЮЪг. ѕСаРвЭРп ЪЮбРп зХавР — ЯЮвЮЬг звЮ ЮЭР ЮЧЭРзРХв, звЮ бЫХФгойШЩ бШЬТЮЫ ЭХ пТЫпХвбп ЧРТХаиХЭШХЬ бваЮЪШ. ІбХ ЮбвРЫмЭлХ бШЬТЮЫл, [[^"\\]], пТЫповбп «ЭЮаЬРЫмЭлЬШ». µбЫШ ТЭШЬРвХЫмЭХХ ЯаШбЬЮваХвмбп Ъ бвагЪвгаХ ТлаРЦХЭШп [[^"\\]+(\\.[^"\\]+)*], ЬЮЦЭЮ ЧРЬХвШвм, звЮ ЮЭЮ бЮЮвТХвбвТгХв ЮСйХЬг иРСЫЮЭг [ЭЮаЬРЫмЭлЩ+(бЯХжШРЫмЭлЩ ЭЮаЬРЫмЭлЩ+)*].
ґЮСРТЫпп ЪРТлзЪШ, ЭРзРЫмЭго Ш ЧРТХаиРойго, Ьл ЯЮЫгзРХЬ ["[^"\\]+(\\.[^"\\]+)*"]. є бЮЦРЫХЭШо, нвЮ ТлаРЦХЭШХ ЭХ бЮТЯРФРХв б ФТгЬп ЯЮбЫХФЭШЬШ ЯаШЬХаРЬШ Т вРСЫ. 5.2. їаЮСЫХЬР бЮбвЮШв Т вЮЬ, звЮ ФТР [[^"\\]] Т нвЮЬ ТлаРЦХЭШШ ваХСгов ЯаШбгвбвТШп ЭЮаЬРЫмЭЮУЮ бШЬТЮЫР Т ЭРзРЫХ бваЮЪШ Ш ЯЮбЫХ ЫоСЮУЮ бЯХжШРЫмЭЮУЮ бШЬТЮЫР. єРЪ ТШФЭЮ ШЧ ЯаШЬХаЮТ, нвЮ ЭХ ТбХУФР ТЮЧЬЮЦЭЮ — бваЮЪР ЬЮЦХв ЭРзШЭРвмбп ШЫШ ЧРЪРЭзШТРвмбп нЪаРЭШаЮТРЭЭлЬ бШЬТЮЫЮЬ, ШЫШ Т ЭХЩ ЬЮУгв ШФвШ ФТР нЪаРЭШаЮТРЭЭле бШЬТЮЫР ЯЮФапФ.
јЮЦЭЮ ЯЮЯлвРвмбп ЧРЬХЭШвм ЯЫобл ЧТХЧФЮзЪРЬШ: ["[^"\\]*(\\.[^"\\]*)*"]. їаШТХФХв ЫШ нвЮ Ъ ЦХЫРХЬЮЬг аХЧгЫмвРвг? ё звЮ ХйХ ТРЦЭХХ, ЭХ ТЮЧЭШЪЭгв ЫШ ЯаШ нвЮЬ ЭХЦХЫРвХЫмЭлХ ЯЮСЮзЭлХ нддХЪвл?
ЗвЮ ЪРбРХвбп ЯЮЫЮЦШвХЫмЭле нддХЪвЮТ — ТШФЭЮ, звЮ ТбХ ЯаШЬХал вХЯХам бЮТЯРФРов. ±ЮЫХХ вЮУЮ, бЮТЯРФРХв ФРЦХ бваЮЪР \"\"\"". НвЮ еЮаЮиЮ, ЭЮ ЯаШ ТЭХбХЭШШ бвЮЫм ЯаШЭжШЯШРЫмЭле ШЧЬХЭХЭШЩ ЭгЦЭЮ Слвм РСбЮЫовЭЮ гТХаХЭЭлЬ Т вЮЬ, звЮ ЯаШ нвЮЬ ЭХ СгФХв ЮваШжРвХЫмЭле ЯЮбЫХФбвТШЩ. ЅХ бЮТЯРФХв ЫШ ТлаРЦХЭШХ б зХЬ-ЭШСгФм, ЪаЮЬХ ФЮЯгбвШЬЮЩ бваЮЪШ, ЧРЪЫозХЭЭЮЩ Т ЪРТлзЪШ? јЮЦХв ЫШ ФЮЯгбвШЬРп бваЮЪР Т ЪРТлзЪРе ЭХ бЮТЯРбвм? ё ЪРЪ ЭРбзХв нддХЪвШТЭЮбвШ?
їаШбЬЮваШвХбм Ъ ["[^"\\]*(\\.[^"\\]*)*"] ЯЮТЭШЬРвХЫмЭХХ. ЅРзРЫмЭЮХ ЯЮФТлаРЦХЭШХ ["[^"\\]*] бЮТЯРФРХв ТбХУЮ ЮФШЭ аРЧ Ш ТлУЫпФШв СХЧТаХФЭлЬ; ЮЭЮ бЮЮвТХвбвТгХв ЮСпЧРвХЫмЭЮЩ ЭРзРЫмЭЮЩ ЪРТлзЪХ Ш ТбХЬ ЭЮаЬРЫмЭлЬ бШЬТЮЫРЬ, бЫХФгойШЬ ЭХЯЮбаХФбвТХЭЭЮ ЧР ЭХЩ. ЅШЪРЪЮЩ ЮЯРбЭЮбвШ Т нвЮЬ ЭХв. БЫХФгойХХ ЯЮФТлаРЦХЭШХ [(\\.[^"\\]*)*] ЧРЪЫозХЭЮ Т (…)*, ЯЮнвЮЬг ЮЭЮ ЬЮЦХв бЮТЯРбвм ЭЮЫм аРЧ. НвЮ ЮЧЭРзРХв, звЮ ЯаШ ХУЮ ШбЪЫозХЭШШ ФЮЫЦЭЮ ЮбвРвмбп ЯаРТШЫмЭЮХ ТлаРЦХЭШХ. І бРЬЮЬ ФХЫХ, ЮбвРХвбп ["[^"\\]*"], звЮ ТЯЮЫЭХ ЭЮаЬРЫмЭЮ — ЯХаХФ ЭРЬШ бвРЭФРавЭРп бШвгРжШп, ЯаШ ЪЮвЮаЮЩ бваЮЪР ЭХ бЮФХаЦШв ЭШ ЮФЭЮУЮ нЪаРЭШаЮТРЭЭЮУЮ нЫХЬХЭвР.
Б ФагУЮЩ бвЮаЮЭл, ХбЫШ [(\\.[^"\\]*)*] бЮТЯРФРХв ЮФШЭ аРЧ, Ьл дРЪвШзХбЪШ ЯаШеЮФШЬ Ъ ТлаРЦХЭШо ["[^"\\]*\\.[^"\\]*"]. ґРЦХ ХбЫШ ЧРТХаиРойХХ ЯЮФТлаРЦХЭШХ ["[^"\\]] ЭХ бЮТЯРФРХв ЭШ б зХЬ (ЯаШ нвЮЬ ТлаРЦХЭШХ дРЪвШзХбЪШ ЯаХТаРйРХвбп Т ["[^"\\]*\\."]), ЯаЮСЫХЬ ЭХ ТЮЧЭШЪРХв. їаЮФЮЫЦРп РЭРЫЮУШзЭлХ аРббгЦФХЭШп (ЭРбЪЮЫмЪЮ п ЯЮЬЭо иЪЮЫмЭлЩ Ъгаб ЫЮУШЪШ, нвЮ ЭРЧлТРХвбп «ШЭФгЪжШХЩ»), Ьл ЯаШеЮФШЬ Ъ ТлТЮФг, звЮ ЯаХФЫЮЦХЭЭлХ ШЧЬХЭХЭШп ФХЩбвТШвХЫмЭЮ ЭХ ТлЧлТРов ЭШЪРЪШе ЯаЮСЫХЬ.
ѕСкХФШЭпп ТбХ бЪРЧРЭЭЮХ, Ьл ЯаШеЮФШЬ Ъ ЮЪЮЭзРвХЫмЭЮЬг ТРаШРЭвг ТлаРЦХЭШп ФЫп ЯЮШбЪР бваЮЪ Т ЪРТлзЪРе: ["[^"\\]*(\\.[^"\\]*)*"]. НвЮ ТлаРЦХЭШХ бЮТЯРФРХв вЮзЭЮ б вХЬШ ЦХ бваЮЪРЬШ, звЮ Ш бвРаЮХ ТлаРЦХЭШХ б ЪЮЭбвагЪжШХЩ ТлСЮаР, Ш ЭХ ЭРеЮФШв бЮТЯРФХЭШп Т вХе ЦХ бваЮЪРе, УФХ Ше ЭХ ЭРеЮФШв бвРаЮХ ТлаРЦХЭШХ. ЅЮ «аРбЪагзХЭЭРп» ТХабШп ЮСЫРФРХв ФЮЯЮЫЭШвХЫмЭлЬ ЯаХШЬгйХбвТЮЬ: ЮЭР ЧРТХаиШв бТЮо аРСЮвг ХйХ ЯаШ ТРиХЩ ЦШЧЭШ, ЯЮвЮЬг звЮ аРСЮвРХв УЮаРЧФЮ нддХЪвШТЭХХ Ш ШЧСХУРХв ЯаЮСЫХЬл «СХбЪЮЭХзЭЮУЮ ЯХаХСЮаР».
ѕСЮСйХЭЭлЩ иРСЫЮЭ ЯЮФЮСЭле ТлаРЦХЭШЩ ТлУЫпФШв вРЪ<$M[R5-28]>:
[ЭРзРЫЮ ЭЮаЬ*(бЯХж ЭЮаЬ*)* ЪЮЭХж]
±ХбЪЮЭХзЭлЩ ЯХаХСЮа Т ТлаРЦХЭШШ ["[^"\\]*(\\.[^"\\]*)*"] ЯаХФЮвТаРйРХвбп ваХЬп ЯаРТШЫРЬШ, ШЬХойШЬШ заХЧТлзРЩЭЮ СЮЫмиЮХ ЧЭРзХЭШХ.
ІЮ-ЯХаТле, ЯЮФТлаРЦХЭШп бЯХж Ш ЭЮаЬ ФЮЫЦЭл Слвм ЭРЯШбРЭл вРЪ, звЮСл ЮЭШ ЭШЪЮУФР ЭХ бЮТЯРФРЫШ б ЮФЭЮЩ ЭРзРЫмЭЮЩ ЯЮЧШжШШ. ЅРЯаШЬХа, [\\.] Ш [[^"\\]] ЬЮУгв бЮТЯРФРвм, ЭРзШЭРп б ЯЮЧШжШШ "Hellolwr\n", ЯЮнвЮЬг ЮЭШ ЭХ ЯЮФеЮФпв ФЫп ЯРал бЯХж Ш ЭЮаЬ. µбЫШ Т ЪРЪЮЩ-вЮ бШвгРжШШ ЮЭШ ЬЮУгв бЮТЯРбвм, ЭРзШЭРп б ЮФЭЮЩ ЯЮЧШжШШ, СгФХв ЭХЯЮЭпвЭЮ, ЪРЪЮХ ШЧ ЯЮФТлаРЦХЭШЩ ФЮЫЦЭЮ ШбЯЮЫмЧЮТРвмбп Т нвЮЬ бЫгзРХ, Ш ЭХЮЯаХФХЫХЭЭЮбвм ЯаШТХФХв Ъ СХбЪЮЭХзЭЮЬг ЯХаХСЮаг. І ЯаШЬХаХ m a k u d o n a r u d o (б. <$R[P#,R5-11]>) нвЮ ЯаЮФХЬЮЭбваШаЮТРЭЮ ЭРУЫпФЭЮ. їаШ ЮвбгвбвТШШ бЮТЯРФХЭШп (ШЫШ ЯаШ ЫоСЮЩ ЯЮЯлвЪХ ЯЮШбЪР Т ЬХеРЭШЧЬХ POSIX Ѕє°) ЬХеРЭШЧЬг ЯаШФХвбп ЯаЮТХаШвм ТбХ ТЮЧЬЮЦЭлХ ЪЮЬСШЭРжШШ нЫХЬХЭвЮТ. ґЮЯгбвШвм нвЮУЮ ЭШЪРЪ ЭХЫмЧп, ЯЮбЪЮЫмЪг ТлаРЦХЭШХ бваЮШЫЮбм ЧРЭЮТЮ ЪРЪ аРЧ ФЫп вЮУЮ, звЮСл ШЧСХЦРвм ЯЮФЮСЭЮУЮ ЯХаХСЮаР.
µбЫШ Тл ЯаЮбЫХФШвХ ЧР вХЬ, звЮСл бЯХж Ш ЭЮаЬ ЭШЪЮУФР ЭХ бЮТЯРФРЫШ б ЮФЭЮЩ ЯЮЧШжШШ, ЯЮФТлаРЦХЭШХ бЯХж СгФХв ШбЯЮЫмЧЮТРвмбп ФЫп аРЧаХиХЭШп бШвгРжШЩ, ЪЮУФР ЭХбЪЮЫмЪЮ нЪЧХЬЯЫпаЮТ ЭЮаЬ Т аРЧЭле ШвХаРжШпе жШЪЫР [(…)*] ЬЮУгв бЮТЯРбвм б ЮФЭШЬ Ш вХЬ ЦХ вХЪбвЮЬ. µбЫШ бЯХж Ш ЭЮаЬ ЭШЪЮУФР ЭХ бЮТЯРФРов б ЮФЭЮЩ ЯЮЧШжШШ, ТбХУФР СгФХв бгйХбвТЮТРвм аЮТЭЮ ЮФЭР ТЮЧЬЮЦЭРп «ЯЮбЫХФЮТРвХЫмЭЮбвм» ЯЮФТлаРЦХЭШЩ бЯХж Ш ЭЮаЬ, ЪЮвЮаРп ЬЮЦХв бЮТЯРбвм б ЪЮЭЪаХвЭЮЩ бваЮЪЮЩ. ѕФЭР ЯЮбЫХФЮТРвХЫмЭЮбвм ЯаЮТХапХвбп УЮаРЧФЮ СлбваХХ, зХЬ бвЮ ЬШЫЫШЮЭЮТ ЯЮбЫХФЮТРвХЫмЭЮбвХЩ; вРЪШЬ ЮСаРЧЮЬ, ЭРЬ СЫРУЮЯЮЫгзЭЮ гФРХвбп ШЧСХЦРвм СХбЪЮЭХзЭЮУЮ ЯХаХСЮаР.
НвЮ ЯаРТШЫЮ ТлЯЮЫЭпХвбп Т ЯаШТХФХЭЭЮЬ ТлиХ ЯаШЬХаХ, УФХ ЭЮаЬ бЮЮвТХвбвТгХв ТлаРЦХЭШХ [[^"\\]], Р бЯХж — ТлаРЦХЭШХ [\\.]. ѕЭШ ЭШЪЮУФР ЭХ ЬЮУгв ЭРзШЭРвмбп б ЮФЭЮУЮ бШЬТЮЫР — ТЮ ТвЮаЮЬ бЫгзРХ ЮСпЧРвХЫХЭ ЯаХдШЪб \, Р Т ЯХаТЮЬ ЮЭ пТЭЮ ШбЪЫозХЭ ШЧ ЪЫРббР.
ІвЮаЮХ ТРЦЭЮХ ЯаРТШЫЮ бЮбвЮШв Т вЮЬ, звЮ ТлаРЦХЭШХ бЯХж ТбХУФР ФЮЫЦЭЮ бЮТЯРФРвм еЮвп Сл б ЮФЭШЬ бШЬТЮЫЮЬ (ХбЫШ ЮЭЮ ТЮЮСйХ б зХЬ-ЭШСгФм бЮТЯРФРХв). µбЫШ нвЮ ТлаРЦХЭШХ ЬЮЦХв бЮТЯРФРвм СХЧ ЯЮУЫЮйХЭШп бШЬТЮЫЮТ, бЮбХФЭШХ ЭЮаЬРЫмЭлХ бШЬТЮЫл бЬЮУгв аРЧФХЫпвмбп аРЧЭлЬ ЪЮЫШзХбвТЮЬ ШвХаРжШЩ [(бЯХж ЭЮаЬ*)*], Ш Ьл ТХаЭХЬбп б ЯаХЦЭХЩ ЯаЮСЫХЬХ (…*)*.
ЅРЯаШЬХа, ТлСЮа Т ЪРзХбвТХ бЯХж ТлаРЦХЭШп [(\\.)*] ЭРагиРХв нвЮ ЯаРТШЫЮ. їаШ ЯЮЯлвЪХ ЭРЩвШ ЧЫЮбзРбвЭЮХ[5] ТлаРЦХЭШХ ["[^"\\]*((\\.)*[^"\\]*)*"] Т бваЮЪХ "Tubby (ЯаШ ЮвбгвбвТШШ бЮТЯРФХЭШп) ЬХеРЭШЧЬ ФЮЫЦХЭ ЯаЮТХаШвм ТбХ ЪЮЬСШЭРжШШ бЮТЯРФХЭШп ЭХбЪЮЫмЪШе нЪЧХЬЯЫпаЮТ [[^"\\]] Т Tubby, Ш вЮЫмЪЮ ЯЮбЫХ нвЮУЮ ЯаШФвШ Ъ ТлТЮФг Ю ЭХгФРзХ. µбЫШ ТлаРЦХЭШХ бЯХж ЬЮЦХв бЮТЯРФРвм б ЯгбвЮЩ бваЮЪЮЩ, ЮЭЮ гваРзШТРХв бТЮШ дгЭЪжШШ «гбваРЭХЭШп ЭХЮФЭЮЧЭРзЭЮбвШ».
ВаХвмХ ТРЦЭЮХ ЯаРТШЫЮ ЫгзиХ ТбХУЮ ЯЮпбЭШвм ЭР ЯаШЬХаХ. АРббЬЮваШЬ ЧРФРзг ЯЮШбЪР ЯЮбЫХФЮТРвХЫмЭЮбвШ, бЮбвЮпйХЩ ШЧ ЭХЮСпЧРвХЫмЭле ЪЮЬЬХЭвРаШХТ Pascal {…} Ш ЯаЮСХЫЮТ. АХУгЫпаЭЮХ ТлаРЦХЭШХ ФЫп ЯЮШбЪР ЪЮЬЬХЭвРаШХТ ШЬХХв ТШФ [\{[^}]*\}], ЯЮнвЮЬг ЯаШ СХбЪЮЭХзЭЮЬ ЯХаХСЮаХ ТбХ ТлаРЦХЭШХ ТлУЫпФШв вРЪ: [(\{[^}]*\}|spc+)*]. ЅР ЯХаТлЩ ТЧУЫпФ еЮзХвбп ТлСаРвм бЫХФгойШХ ТлаРЦХЭШп бЯХж Ш ЭЮаЬ:
|
бЯХж |
ЭЮаЬ |
|
[spc+] |
[\{[^}]*\}] |
їЮФбвРТЫпп нвШ ТлаРЦХЭШп Т ЯЮбваЮХЭЭлЩ аРЭХХ иРСЫЮЭ [ЭЮаЬ*(бЯХж ЭЮаЬ*)*], Ьл ЯЮЫгзРХЬ: [(\{[^}]*\})*(spc+(\{[^}]*\})*)*]. ° вХЯХам аРббЬЮваШЬ бваЮЪг:
{comment}spcspcspc{another}spcspc
їЮбЫХФЮТРвХЫмЭЮбвм ШЧ ЭХбЪЮЫмЪШе ЯаЮСХЫЮТ ЬЮЦХв бЮТЯРФРвм б ЮФЭШЬ ЯЮФТлаРЦХЭШХЬ [spc+], б ЭХбЪЮЫмЪШЬШ ЯЮФТлаРЦХЭШпЬШ [spc+] (ЪРЦФЮХ ШЧ ЪЮвЮале бЮТЯРФРХв б ЮФЭШЬ ЯаЮСХЫЮЬ) ШЫШ б аРЧЫШзЭлЬШ ЪЮЬСШЭРжШпЬШ [spc+], бЮТЯРФРойШЬШ б аРЧЭлЬШ ЪЮЫШзХбвТРЬШ ЯаЮСХЫЮТ. ЅРСЫоФРХвбп ЯапЬРп РЭРЫЮУШп б ЭРиШЬ ЯаШЬХаЮЬ m a k u d o n a r u d o.
єЮаХЭм ЯаЮСЫХЬл ЧРЪЫозРХвбп Т вЮЬ, звЮ бЯХж ЬЮЦХв бЮТЯРбвм б ЬХЭмиШЬ даРУЬХЭвЮЬ вХЪбвР ТЭгваШ СЮЫмиХУЮ даРУЬХЭвР, б ЪЮвЮалЬ нвЮ ТлаРЦХЭШХ вЮЦХ ЬЮЦХв бЮТЯРбвм, ЯаШзХЬ ШЧ-ЧР [(…)*] нвЮ ЬЮЦХв ЯаЮШбеЮФШвм ЭХЮФЭЮЪаРвЭЮ. їЮФЮСЭРп ЭХЮЯаХФХЫХЭЭЮбвм ЯЮаЮЦФРХв гЦХ ЧЭРЪЮЬго ЯаЮСЫХЬг «аРЧЭле ТРаШРЭвЮТ бЮТЯРФХЭШп ЮФЭЮУЮ вХЪбвР».
µбЫШ ЮСйХХ бЮТЯРФХЭШХ бгйХбвТгХв, ТХаЮпвЭЮ, ТбХ ЯаЮСХЫл СгФгв ЮвЭХбХЭл ЭР бзХв ТЭгваХЭЭХЩ ЪЮЭбвагЪжШШ [spc+], ЭЮ ЯаШ ЮвбгвбвТШШ бЮТЯРФХЭШп (ЭРЯаШЬХа, ХбЫШ ТлаРЦХЭШХ ШбЯЮЫмЧгХвбп ТЭгваШ СЮЫмиХУЮ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, ФЫп ЪЮвЮаЮУЮ ЯЮШбЪ ЬЮЦХв ЮЪРЧРвмбп ЭХгФРзЭлЬ) ЬХеРЭШЧЬ ФЮЫЦХЭ аРббЬЮваХвм ТбХ ЪЮЬСШЭРжШШ бЮТЯРФХЭШп [(spc+)*] Т бХаШШ ШЧ ЭХбЪЮЫмЪШе ЯаЮСХЫЮТ. ЅР нвЮ ваРвШвбп ТаХЬп, ЭЮ СХЧ ЬРЫХЩиХЩ ЭРФХЦФл ЭР бЮТЯРФХЭШХ. їЮбЪЮЫмЪг ЯЮФТлаРЦХЭШХ бЯХж бРЬЮ ФЮЫЦЭЮ гбваРЭпвм ЭХЮЯаХФХЫХЭЭЮбвм, ЭХв ЭШзХУЮ, звЮ ЯЮЧТЮЫШЫЮ Сл ШЧСРТШвмбп Юв ЭХЮЯаХФХЫХЭЭЮбвШ ТЭгваШ нвЮУЮ ТлаРЦХЭШп.
АХиХЭШХ ЯаЮСЫХЬл — ЯЮЧРСЮвШвмбп Ю вЮЬ, звЮСл ТлаРЦХЭШХ бЯХж бЮТЯРФРЫЮ вЮЫмЪЮ б дШЪбШаЮТРЭЭлЬ ЪЮЫШзХбвТЮЬ ЯаЮСХЫЮТ. їЮбЪЮЫмЪг ЮЭЮ ФЮЫЦЭЮ бЮТЯРФРвм ЯЮ ЪаРЩЭХЩ ЬХаХ ЮФШЭ аРЧ (ЭЮ ЬЮЦХв Ш СЮЫмиХ), Ьл ЯаЮбвЮ ТлСШаРХЬ [spc] Ш аРЧаХиРХЬ бЮТЯРФХЭШХ ЭХбЪЮЫмЪШе нЪЧХЬЯЫпаЮТ бЯХж б ЭХбЪЮЫмЪШЬШ ЯаЮСХЫРЬШ зХаХЧ ТЭХиЭШЩ ЪТРЭвШдШЪРвЮа [(…)*].
їаШТХФХЭЭлЩ ЯаШЬХа еЮаЮиЮ ЯЮФеЮФШв ФЫп РЭРЫШЧР, ЭЮ ХбЫШ Сл ЬЭХ ФХЩбвТШвХЫмЭЮ ЯЮваХСЮТРЫЮбм вРЪЮХ ТлаРЦХЭШХ, п Сл ЯХаХбвРТШЫ бЯХж Ш ЭЮаЬ:
[spc*(\{[^}]*\}spc*)*]
НвЮ бТпЧРЭЮ б вХЬ, звЮ ЯаЮУаРЬЬР ЭР пЧлЪХ Pascal бЮФХаЦШв СЮЫмиХ ЯаЮСХЫЮТ, зХЬ ЪЮЬЬХЭвРаШХТ, Р ТлаРЦХЭШХ ЭЮаЬ ФЮЫЦЭЮ ЮвЭЮбШвмбп Ъ СЮЫХХ аРбЯаЮбваРЭХЭЭЮЬг бЫгзРо.
їЮбЫХ вЮУЮ, ЪРЪ Тл гбТЮШвХ нвШ ЯаРТШЫР (ТЮЧЬЮЦЭЮ, ФЫп нвЮУЮ ЯаШФХвбп ЭХбЪЮЫмЪЮ аРЧ ЯХаХзШвРвм Ше Ш ЭХЬЭЮУЮ ЯЮнЪбЯХаШЬХЭвШаЮТРвм), Тл бЬЮЦХвХ ТлФХЫШвм ЮСйШХ ЯаШЧЭРЪШ аХУгЫпаЭле ТлаРЦХЭШЩ, ЯЮФТХаЦХЭЭле «СХбЪЮЭХзЭЮЬг ЯХаХСЮаг». јЭЮУЮгаЮТЭХТлХ ЪТРЭвШдШЪРвЮал (вРЪШХ, ЪРЪ [(…*)*]) зРбвЮ ЯаХФгЯаХЦФРов ЮС ЮЯРбЭЮбвШ, ЭЮ ЮЭШ ТбваХзРовбп Ш ТЮ ЬЭЮУШе ТЯЮЫЭХ ФЮЯгбвШЬле ТлаРЦХЭШпе:
l [(Re:spc*)*] — ТлФХЫХЭШХ жХЯЮзХЪ ЯаХдШЪбЮТ Re: ЯаЮШЧТЮЫмЭЮЩ ФЫШЭл (ЭРЯаШЬХа, ТлаРЦХЭШХ ЬЮЦХв ШбЯЮЫмЧЮТРвмбп ФЫп «ЮзШбвЪШ» бваЮЪШ вХЬл «Subject:spcRe:spcRe:spcRe:spchey»).
l [(spc*\$[0-9]+)*] — ЯЮШбЪ ФХЭХЦЭле бгЬЬ Т ФЮЫЫРаРе (ТЮЧЬЮЦЭЮ, аРЧФХЫХЭЭле ЯаЮСХЫРЬШ).
l [(.*\n)+] — ЯЮШбЪ ЮФЭЮЩ ШЫШ ЭХбЪЮЫмЪШе ЫЮУШзХбЪШе бваЮЪ. ѕСаРвШвХ ТЭШЬРЭШХ: ХбЫШ вЮзЪР ЬЮЦХв бЮТЯРФРвм б бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ, Р ЯЮбЫХ нвЮУЮ ЯЮФТлаРЦХЭШп бЫХФгХв ЭХзвЮ, ЯаШТЮФпйХХ Ъ ЭХгФРзХ, бЭЮТР ТЮЧЭШЪРХв бШвгРжШп «СХбЪЮЭХзЭЮУЮ ЯХаХСЮаР».
ІбХ нвШ ТлаРЦХЭШп ТЯЮЫЭХ ФЮЯгбвШЬл, ЯЮбЪЮЫмЪг Т ЪРЦФЮЬ ШЧ ЭШе ЯаШбгвбвТгХв «ЬРаЪХа», ЯаХФЮвТаРйРойШЩ ЮЯРбЭго бШвгРжШо «аРЧЭле ТРаШРЭвЮТ бЮТЯРФХЭШп ЮФЭЮУЮ вХЪбвР». І ЯХаТЮЬ ЯаШЬХаХ нвЮ [(Re:], ТЮ ТвЮаЮЬ — [\$], Р Т ваХвмХЬ (ХбЫШ вЮзЪР ЭХ бЮТЯРФРХв б бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ) — [\n].
єРЪ п УЮТЮаШЫ ТлиХ, Ъ ЮФЭЮЬг Ш вЮЬг ЦХ ТлаРЦХЭШо ЬЮЦЭЮ ЯаШФвШ ФТгЬп<$M[R5-13]> ЯгвпЬШ. ґРТРЩвХ ЯЮЯаЮСгХЬ аРЧЮСаРвмбп, зХУЮ ФЮСШТРХвбп ТлаРЦХЭШХ [(\\.|[^"\\]+)*], Ш Т ЪРЪЮЩ бШвгРжШШ ЮЭЮ СгФХв Т ЮбЭЮТЭЮЬ ШбЯЮЫмЧЮТРвмбп. ІХаЮпвЭЮ, бваЮЪР Т ЪРТлзЪРе Т ЮбЭЮТЭЮЬ бЮбвЮШв ШЧ ЮСлзЭле, Р ЭХ нЪаРЭШаЮТРЭЭле бШЬТЮЫЮТ, ЯЮнвЮЬг ЮбЭЮТЭРп аРСЮвР ФЮбвРЭХвбп ЯЮФТлаРЦХЭШо [[^"\\]+]. їЮФТлаРЦХЭШХ [\\.] ЭХЮСеЮФШЬЮ ЫШим ФЫп вЮУЮ, звЮСл аРЧЮСаРвмбп б аХФЪШЬШ нЪаРЭШаЮТРЭЭлЬШ бШЬТЮЫРЬШ. єЮЭбвагЪжШп ТлСЮаР гзШвлТРХв ЮСР бЫгзРп Ш ЯЮЧТЮЫпХв ШбЯЮЫмЧЮТРвм нвЮ ТлаРЦХЭШХ ЭР ЯаРЪвШЪХ, ЭЮ ТбХ ЦХ ЭХ еЮзХвбп бЭШЦРвм нддХЪвШТЭЮбвм ТбХУЮ ЯЮШбЪР аРФШ аХФЪШе (Р вЮ Ш ТЮТбХ ЮвбгвбвТгойШе) нЪаРЭШаЮТРЭЭле бШЬТЮЫЮТ.
µбЫШ Ьл ЯЮЫРУРХЬ, звЮ [[^"\\]+] ЮСлзЭЮ бЮТЯРФРХв б СЮЫмиХЩ зРбвмо бШЬТЮЫЮТ Т бваЮЪХ, вЮ ЯЮбЫХ ХУЮ бЮТЯРФХЭШп ФЮЫЦЭР бЫХФЮТРвм ЫШСЮ ЪРТлзЪР, ЫШСЮ ЮСаРвЭРп ЪЮбРп зХавР. µбЫШ нвЮ ЮСаРвЭРп ЪЮбРп зХавР, Ьл ФЮСРТЫпХЬ ХйХ ЮФШЭ бШЬТЮЫ (ЪРЪШЬ Сл ЮЭ ЭШ СлЫ) Ш ЭРеЮФШЬ ЭЮТго ЯЮажШо ЮбЭЮТЭЮУЮ вХЪбвР [[^"\\]+]. єРЦФлЩ аРЧ, ЪЮУФР бЮТЯРФХЭШХ [[^"\\]+] ЧРТХаиРХвбп, Ьл ЮЪРЧлТРХЬбп Т вЮЩ ЦХ бШвгРжШШ — бЫХФгойШЬ бШЬТЮЫЮЬ пТЫпХвбп ЫШСЮ ЧРТХаиРойРп ЪРТлзЪР, ЫШСЮ ЮзХаХФЭРп ЮСаРвЭРп ЪЮбРп зХавР.
ІлаРЦРп ТбХ бЪРЧРЭЭЮХ ЭР пЧлЪХ аХУгЫпаЭле ТлаРЦХЭШЩ, Ьл ЯаШеЮФШЬ Ъ вЮЬг ЦХ, звЮ гЦХ ТбваХзРЫЮбм ЭРЬ Т ЬХвЮФХ 1: ["[^"\\]+(lwr\\.[^"\\]+)*"]. єРЦФлЩ аРЧ, ЪЮУФР ЯЮШбЪ ФЮбвШУРХв ЯЮЧШжШШ, ЮСЮЧЭРзХЭЭЮЩ lwr, Ьл ЧЭРХЬ, звЮ бЫХФгойШЬ бШЬТЮЫЮЬ СгФХв ЫШСЮ ЮСаРвЭРп ЪЮбРп зХавР, ЫШСЮ ЪРТлзЪР. µбЫШ ЮСаРвЭРп ЪЮбРп зХавР бЮТЯРФРХв, Ьл СХаХЬ ХХ, бЫХФгойШЩ бШЬТЮЫ Ш вХЪбв ФЮ бЫХФгойХЩ вЮзЪШ ЯХаХФ ЪРТлзЪЮЩ ШЫШ ЮСаРвЭЮЩ ЪЮбЮЩ.
єРЪ Ш Т ЯаХФлФгйХЬ ЬХвЮФХ, ЭХЮСеЮФШЬЮ ЯаХФгбЬЮваХвм бШвгРжШШ, ЯаШ ЪЮвЮале ЭРзРЫмЭлЩ бХУЬХЭв ШЫШ бХУЬХЭвл ЬХЦФг ЪРТлзЪРЬШ Ягбвл. ґЫп нвЮУЮ ЯЫобл ЧРЬХЭповбп ЧТХЧФЮзЪРЬШ, Ш Ьл ЯаШеЮФШЬ Ъ гЦХ ЧЭРЪЮЬЮЬг ТлаРЦХЭШо.
П ЮСХйРЫ ЮЯШбРвм ФТР ЯгвШ, ЯЮ ЪЮвЮалЬ ЬЮЦЭЮ ЯаШФвШ Ъ ЮЪЮЭзРвХЫмЭЮЬг ТлаРЦХЭШо «аРбЪагвЪШ жШЪЫР», ЭЮ Т ФЮЯЮЫЭХЭШХ Ъ ЭШЬ п ЯаХФбвРТЫо ЯЮеЮЦШЩ ЬХвЮФ, ЪЮвЮалЩ ЬЮЦЭЮ бзШвРвм ваХвмШЬ. П бвЮЫЪЭгЫбп б ЭШЬ ТЮ ТаХЬп аРСЮвл ЭРФ аХУгЫпаЭлЬ ТлаРЦХЭШХЬ ФЫп ЯЮШбЪР ФЮЬХЭЭле ШЬХЭ (prez.whitehouse.gov ШЫШ www.yahoo.com), ЪЮвЮалХ Т бгйЭЮбвШ ЯаХФбвРТЫпов бЮСЮЩ бЯШбЪШ ШЬХЭ бгСФЮЬХЭЮТ, аРЧФХЫХЭЭле вЮзЪРЬШ. І нвЮЬ ЯаШЬХаХ ФЫп ШФХЭвШдШЪРжШШ бгСФЮЬХЭР СгФХв ШбЯЮЫмЧЮТРвмбп ЯаЮбвЮХ (еЮвп Ш ЭХЯЮЫЭЮХ) ТлаРЦХЭШХ [[a-z]+].
µбЫШ бгСФЮЬХЭ ЮЯаХФХЫпХвбп ТлаРЦХЭШХЬ [[a-z]+], Ш Ьл еЮвШЬ ЭРЩвШ бЯШбЮЪ бгСФЮЬХЭЮТ, аРЧФХЫХЭЭле вЮзЪРЬШ, ЯЮШбЪ ФЮЫЦХЭ ЭРзШЭРвмбп б ЮФЭЮУЮ ШЬХЭШ бгСФЮЬХЭР. їЮбЫХ ЭХУЮ ЬЮЦХв бЫХФЮТРвм ЯХаХзХЭм ЭХЮСпЧРвХЫмЭле ШЬХЭ ФагУШе бгСФЮЬХЭЮТ, ЭРзШЭРойШЩбп б вЮзЪШ. µбЫШ ТлаРЧШвм ТбХ бЪРЧРЭЭЮХ ЭР пЧлЪХ аХУгЫпаЭле ТлаРЦХЭШЩ, Ьл ЯЮЫгзШЬ [[a-z]+(\.[a-z]+)*]. ° ХбЫШ ЧРЯШбРвм нвЮ ТлаРЦХЭШХ Т ТШФХ [[a-z]+(\.[a-z]+)*], ЮЭЮ бвРЭЮТШвбп ЮзХЭм ЧЭРЪЮЬлЬ!
ЗвЮСл ЯаЮФХЬЮЭбваШаЮТРвм беЮФбвТЮ, Ьл ЯаЮТХФХЬ РЭРЫЮУШо б ТлаРЦХЭШХЬ ФЫп ЯЮШбЪР бваЮЪ Т ЪРТлзЪРе. µбЫШ аРббЬРваШТРвм бваЮЪг ЪРЪ ЯЮбЫХФЮТРвХЫмЭЮбвм ЭЮаЬРЫмЭле бШЬТЮЫЮТ [[^\\"]], аРЧФХЫХЭЭле бЯХжШРЫмЭлЬШ бШЬТЮЫРЬШ [\\.], вЮ ТбХ, звЮ ЭРеЮФШвбп ТЭгваШ ["…"], ЬЮЦЭЮ ЯЮФбвРТШвм Т иРСЫЮЭ «аРбЪагвЪШ жШЪЫР». їЮЫгзРХвбп ["[^"\\]+(\\.[^"\\]+)*"] — Т вЮзЭЮбвШ вЮ ЦХ бРЬЮХ, звЮ Ьл ЯЮЫгзШЫШ ЭР ЮЯаХФХЫХЭЭЮЩ бвРФШШ ЯаШ ЮСбгЦФХЭШШ ЬХвЮФР 1. ІЮЧЬЮЦЭЮ, ШЭвХаЯаХвРжШп бЮФХаЦШЬЮУЮ бваЮЪШ Т ЪРТлзЪРе ЪРЪ «ЯЮбЫХФЮТРвХЫмЭЮбвШ ЭХнЪаРЭШаЮТРЭЭле бШЬТЮЫЮТ, аРЧФХЫХЭЭле нЪаРЭШаЮТРЭЭлЬШ бШЬТЮЫРЬШ» ТлУЫпФШв ЭХбЪЮЫмЪЮ ЭХХбвХбвТХЭЭЮ, ЭЮ ЮЭР ЮвЪалТРХв ЭЮТлЩ ШЭвХаХбЭлЩ Ягвм Ъ гЦХ ЧЭРЪЮЬЮЬг аХЧгЫмвРвг.
јХЦФг нвШЬШ ФТгЬп ЯаШЬХаРЬШ (бваЮЪШ Т ЪРТлзЪРе Ш ФЮЬХЭЭлХ ШЬХЭР) бгйХбвТгов ФТР ЯаШЭжШЯШРЫмЭле ЮвЫШзШп:
l ґЮЬХЭЭлХ ШЬХЭР ЭХ ЧРЪЫозРовбп ТЮ ТЭХиЭШХ ЮУаРЭШзШвХЫШ.
l їЮФТлаРЦХЭШХ ЭЮаЬ Т ФЮЬХЭЭЮЬ ШЬХЭШ, вЮ Хбвм ШЬп бгСФЮЬХЭР, ЭШЪЮУФР ЭХ СлТРХв ЯгбвлЬ (ШЭРзХ УЮТЮап, вЮзЪШ ЭХ ЬЮУгв бвЮпвм ЯЮФапФ Ш ЭХ ЬЮУгв ЭРзШЭРвм ШЫШ ЧРЪРЭзШТРвм бЮТЯРФХЭШХ). І бваЮЪХ, ЧРЪЫозХЭЭЮЩ Т ЪРТлзЪШ, ЭРЫШзШХ еЮвп Сл ЮФЭЮУЮ бЮТЯРФХЭШп ЭЮаЬ ТЮЮСйХ ЭХ ваХСгХвбп, еЮвп вРЪШХ бЮТЯРФХЭШп ТХбмЬР ТХаЮпвЭл, гзШвлТРп ЭРиШ ЯаХФЯЮЫЮЦХЭШп ЮвЭЮбШвХЫмЭЮ ФРЭЭле. ІЮв ЯЮзХЬг Ьл ЧРЬХЭШЫШ ["[^"\\]+] ЭР ["[^"\\]*]. І ЯаШЬХаХ б бгСФЮЬХЭРЬШ нвЮ ЭХТЮЧЬЮЦЭЮ, ЯЮбЪЮЫмЪг бЯХж ЯаХФбвРТЫпХв бЮСЮЩ ЮСпЧРвХЫмЭлЩ аРЧФХЫШвХЫм.
їЮФТХФХЬ ШвЮУШ. јЮЦЭЮ ЧРЬХвШвм, звЮ ЭРиХ ТлаРЦХЭШХ ["[^"\\]*(\\.[^"\\]*)*"] ЮСЫРФРХв ЪРЪ ФЮбвЮШЭбвТРЬШ, вРЪ Ш ЭХФЮбвРвЪРЬШ.
l ЅХгФЮСЮзШвРХЬЮбвм. ІХаЮпвЭЮ, бРЬлЩ СЮЫмиЮЩ ЭХФЮбвРвЮЪ ЧРЪЫозРХвбп Т вЮЬ, звЮ ШбеЮФЭЮХ ТлаРЦХЭШХ ["([^"\\]|\\.)*"] ТлУЫпФХЫЮ СЮЫХХ ЯЮЭпвЭЮ. ЅРУЫпФЭЮбвмо ЯаШиЫЮбм ЮвзРбвШ ЯЮЦХавТЮТРвм аРФШ нддХЪвШТЭЮбвШ.
l БЫЮЦЭЮбвм бЮЯаЮТЮЦФХЭШп. ІлаРЦХЭШХ ["[^"\\]*(\\.[^"\\]*)*"] вагФЭХХ ЯЮФФХаЦШТРвм, ЯЮбЪЮЫмЪг ЫоСлХ ШЧЬХЭХЭШп ЯаШеЮФШвбп бШЭеаЮЭШЧШаЮТРвм Т ФТге нЪЧХЬЯЫпаРе [[^"\\]]. ·РвагФЭХЭЭЮХ бЮЯаЮТЮЦФХЭШХ ШбЪгЯРХвбп ЯЮТлиХЭШХЬ нддХЪвШТЭЮбвШ.
l ёбЪЫозХЭШХ ЧРТШбРЭШЩ. ЅЮТЮХ ТлаРЦХЭШХ ЭХ ЯаШТЮФШв Ъ ЧРТШбРЭШо ЯаШ ЮвбгвбвТШШ бЮТЯРФХЭШЩ (ШЫШ Т POSIX Ѕє°). ±ЫРУЮФРап вйРвХЫмЭЮ ЯаЮФгЬРЭЭЮЩ бвагЪвгаХ ТлаРЦХЭШп, ФЮЯгбЪРойХЩ ЫШим ЮФШЭ ТРаШРЭв бЮТЯРФХЭШп б ЪЮЭЪаХвЭлЬ даРУЬХЭвЮЬ, ЬХеРЭШЧЬ СлбваЮ ЯаШеЮФШв Ъ ТлТЮФг, звЮ ЭХбЮТЯРФРойШЩ вХЪбв ФХЩбвТШвХЫмЭЮ ЭХ бЮТЯРФРХв.
l БЪЮаЮбвм. І бХаШШ вХбвЮТ, ЯаЮТХФХЭЭле ЬЭЮЩ ФЫп ваРФШжШЮЭЭЮУЮ Ѕє°, аРбЪагзХЭЭРп ТХабШп бвРСШЫмЭЮ аРСЮвРЫР СлбваХХ бвРаЮЩ ТХабШШ б ЪЮЭбвагЪжШХЩ ТлСЮаР. НвЮ ЮвЭЮбШвбп ФРЦХ Ъ гбЯХиЭлЬ бЮТЯРФХЭШпЬ, УФХ Т бвРаЮЩ ТХабШШ ЭХ ТЮЧЭШЪРЫЮ ЯаЮСЫХЬ б ЧРТШбРЭШХЬ.
АРббЬЮваШЬ ЯаШЬХа аРбЪагвЪШ жШЪЫР ФЫп СЮЫХХ бЫЮЦЭЮУЮ жХЫХТЮУЮ вХЪбвР. І пЧлЪХ C ЪЮЬЬХЭвРаШШ ЭРзШЭРовбп б бШЬТЮЫЮТ /*, ЧРТХаиРовбп бШЬТЮЫРЬШ */ Ш ЬЮУгв аРбЯаЮбваРЭпвмбп ЭР ЭХбЪЮЫмЪЮ бваЮЪ (ЮФЭРЪЮ ТЫЮЦХЭШХ ЪЮЬЬХЭвРаШХТ ЭХ ФЮЯгбЪРХвбп). ІлаРЦХЭШХ, бЮТЯРФРойХХ б вРЪШЬ ЪЮЬЬХЭвРаШХЬ, ЬЮЦХв ШбЯЮЫмЧЮТРвмбп Т аРЧЭЮЮСаРЧЭле бШвгРжШпе — ЭРЯаШЬХа, ЯаШ ЭРЯШбРЭШШ ЯаЮУаРЬЬл-дШЫмваР ФЫп гФРЫХЭШп ЪЮЬЬХЭвРаШХТ. АРСЮвРп ЭРФ нвЮЩ ЧРФРзХЩ, п ТЯХаТлХ ЯаШиХЫ Ъ ШФХХ аРбЪагвЪШ жШЪЫР, Ш б вХе ЯЮа ЮЭР ЧРЭпЫР ЯЮзХвЭЮХ ЬХбвЮ Т ЬЮХЬ РабХЭРЫХ аХУгЫпаЭле ТлаРЦХЭШЩ.
І ЪЮЬЬХЭвРаШпе C ЭХ бгйХбвТгХв ЯЮбЫХФЮТРвХЫмЭЮбвХЩ, ЪЮвЮалХ Сл ШЭвХаЯаХвШаЮТРЫШбм ЮбЮСлЬ ЮСаРЧЮЬ — ЪРЪ, ЭРЯаШЬХа, нЪаРЭШаЮТРЭЭлХ ЪРТлзЪШ ТЭгваШ бваЮЪШ, ЧРЪЫозХЭЭЮЩ Т ЪРТлзЪШ. НвЮ гЯаЮйРХв ЧРФРзг, ЮФЭРЪЮ ЯЮШбЪ ЪЮЬЬХЭвРаШХТ C ЧРвагФЭпХвбп вХЬ, звЮ «ЧРТХаиРойРп ЪРТлзЪР» */ бЮбвЮШв ШЧ ЭХбЪЮЫмЪШе бШЬТЮЫЮТ. їаЮбвЮХ аХиХЭШХ [/\*[^*]*\*/] ЭХ аРСЮвРХв, ЯЮбЪЮЫмЪг ЮЭЮ ЭХ бЮТЯРФХв б ТЯЮЫЭХ ФЮЯгбвШЬлЬ ЪЮЬЬХЭвРаШХЬ /** some comment here **/, бЮФХаЦРйШЬ ТЭгваХЭЭШХ бШЬТЮЫл *. ЅРЬ ЯЮваХСгХвбп СЮЫХХ бЫЮЦЭЮХ аХиХЭШХ.
ІХаЮпвЭЮ, Тл ЮСаРвШЫШ ТЭШЬРЭШХ, звЮ ТлаРЦХЭШХ [/\*[^*]*\*/] ЮзХЭм ЯЫЮеЮ зШвРХвбп — Ъ бЮЦРЫХЭШо, ЮФШЭ ШЧ бШЬТЮЫЮТ-ЮУаРЭШзШвХЫХЩ ЪЮЬЬХЭвРаШп, *, вРЪЦХ пТЫпХвбп ЬХвРбШЬТЮЫЮЬ аХУгЫпаЭЮУЮ ТлаРЦХЭШп. ѕв ЮСШЫШп ЯаХдШЪбЮТ \ ЭРзШЭРХв СЮЫХвм УЮЫЮТР. ЗвЮСл ТлаРЦХЭШХ ТлУЫпФХЫЮ СЮЫХХ ЯЮЭпвЭЮ, Ьл СгФХЬ бзШвРвм, звЮ ЪЮЬЬХЭвРаШЩ ЧРЪЫозРХвбп Т ЮУаРЭШзШвХЫШ /x…x/, Р ЭХ /*…*/. НвЮ ШбЪгббвТХЭЭЮХ ШЧЬХЭХЭШХ ЯЮЧТЮЫШв ЧРЯШбРвм [/\*[^*]*\*/] Т ЭРУЫпФЭЮЩ дЮаЬХ [/x[^x]*x/]. І ЯаЮжХббХ РЭРЫШЧР нвЮУЮ ЯаШЬХаР ТлаРЦХЭШХ бвРЭХв ХйХ СЮЫХХ бЫЮЦЭлЬ, Ш Тл ЮжХЭШвХ нвЮ гЯаЮйХЭШХ ЯЮ ФЮбвЮШЭбвТг.
І УЫРТХ 4 (б. <$R[P#,R4-38]>) п ЯаШТХЫ бвРЭФРавЭлЩ РЫУЮаШвЬ ЯЮШбЪР вХЪбвР, ЧРЪЫозХЭЭЮУЮ ЬХЦФг ЮУаРЭШзШвХЫпЬШ:
1. ЅРЩвШ ЮвЪалТРойШЩ ЮУаРЭШзШвХЫм.
2. ЅРЩвШ ЮбЭЮТЭЮЩ вХЪбв (дРЪвШзХбЪШ нвЮ ЮЧЭРзРХв «ТбХ, звЮ ЭХ пТЫпХвбп ЧРЪалТРойШЬ ЮУаРЭШзШвХЫХЬ»).
3. ЅРЩвШ ЧРЪалТРойШЩ ЮУаРЭШзШвХЫм.
їЮеЮЦХ, ЭРиШ ЯбХТФЮЪЮЬЬХЭвРаШШ /x…x/ ЯЮФеЮФпв ЯЮФ нвЮв иРСЫЮЭ. ВагФЭЮбвШ ЭРзШЭРовбп, ЪЮУФР Тл ЯЮЯлвРХвХбм ЭРЩвШ «ТбХ, звЮ ЭХ пТЫпХвбп ЧРЪалТРойШЬ ЮУаРЭШзШвХЫХЬ». µбЫШ ЧРЪалТРойШЩ ЮУаРЭШзШвХЫм ЯаХФбвРТЫпХв бЮСЮЩ ЮФШЭЮзЭлЩ бШЬТЮЫ, ЬЮЦЭЮ ТЮбЯЮЫмЧЮТРвмбп ШЭТХавШаЮТРЭЭлЬ бШЬТЮЫмЭлЬ ЪЫРббЮЬ, бЮТЯРФРойШЬ бЮ ТбХЬШ бШЬТЮЫРЬШ, ЪаЮЬХ ЮУаРЭШзШвХЫп. ѕФЭРЪЮ ЭХ бгйХбвТгХв ЮСйХУЮ ЮСЮЧЭРзХЭШп «ТбХУЮ, звЮ ЭХ пТЫпХвбп ЬЭЮУЮбШЬТЮЫмЭлЬ ЮУаРЭШзШвХЫХЬ»[6], ЯЮнвЮЬг ТлаРЦХЭШХ ЯаШФХвбп бваЮШвм СЮЫХХ вйРвХЫмЭЮ. є ЯЮШбЪг бЮТЯРФХЭШп ФЮ ЯХаТЮУЮ x/ ЬЮЦЭЮ ЯЮФЮЩвШ ФТгЬп бЯЮбЮСРЬШ. їХаТлЩ — аРббЬРваШТРвм x ЪРЪ ЭРзРЫЮ ЧРЪалТРойХУЮ ЮУаРЭШзШвХЫп. І нвЮЬ бЫгзРХ Ьл ШйХЬ ТбХ, звЮ ЭХ бЮТЯРФРХв б x, Ш ФЮЯгбЪРХЬ x Т вЮЬ бЫгзРХ, ХбЫШ ЧР ЭШЬ бЫХФгХв звЮ-вЮ ЮвЫШзЭЮХ Юв бШЬТЮЫР /. ВРЪШЬ ЮСаРЧЮЬ, «ТбХ, звЮ ЭХ пТЫпХвбп ЧРЪалТРойШЬ ЮУаРЭШзШвХЫХЬ» ЬЮЦХв Слвм:
l ЫоСлЬ бШЬТЮЫЮЬ, ЪаЮЬХ x: [^x];
l x, ХбЫШ ЧР ЭШЬ ЭХ бЫХФгХв бШЬТЮЫ /: [x[^/]].
І аХЧгЫмвРвХ ЮбЭЮТЭЮЬг вХЪбвг бЮЮвТХвбвТгХв ТлаРЦХЭШХ [(е[^x]|x[^/])*], Р ТбХЬг ЯбХТФЮЪЮЬЬХЭвРаШо — [/x(е[^x]|x[^/])*x/].
ґагУЮЩ бЯЮбЮС ЧРЪЫозРХвбп Т вЮЬ, звЮСл аРббЬРваШТРвм / ЪРЪ ЧРЪалТРойШЩ ЮУаРЭШзШвХЫм, ЭЮ ЫШим Т вЮЬ бЫгзРХ, ХбЫШ ХЬг ЯаХФиХбвТгХв x. ВРЪШЬ ЮСаРЧЮЬ, «ТбХ, звЮ ЭХ пТЫпХвбп ЧРЪалТРойШЬ ЮУаРЭШзШвХЫХЬ» ЬЮЦХв Слвм<$M[R5-12]>:
l ЫоСлЬ бШЬТЮЫЮЬ, ЪаЮЬХ /: [^/];
l бШЬТЮЫЮЬ /, ХбЫШ ХЬг ЭХ ЯаХФиХбвТгХв x: [[^x]/].
І аХЧгЫмвРвХ ЮбЭЮТЭЮЬг вХЪбвг бЮЮвТХвбвТгХв ТлаРЦХЭШХ [([^/]|[^x]/)*], Р ТбХЬг ЪЮЬЬХЭвРаШо — [/x([^/]|[^x]/)*x/].
є бЮЦРЫХЭШо, ЭШ ЮФШЭ ШЧ нвШе бЯЮбЮСЮТ ЭХ аРСЮвРХв.
ЅРзЭХЬ б [/x(е[^x]|x[^/])*x/]. АРббЬЮваШЬ бваЮЪг /xxspcfoospcxx/ — ЯЮбЫХ бЮТЯРФХЭШп б foospc ЯХаТлЩ бШЬТЮЫ x бЮТЯРФРХв б [x[^/]], звЮ ТЯЮЫЭХ ЭЮаЬРЫмЭЮ. ЅЮ ЧРвХЬ [x[^/]] бЮТЯРФРХв б xx/, Р нвЮв бШЬТЮЫ x ФЮЫЦХЭ ТеЮФШвм Т ЧРЪалТРойШЩ ЮУаРЭШзШвХЫм ЪЮЬЬХЭвРаШп. І аХЧгЫмвРвХ бЮТЯРФХЭШХ ЯаЮФЮЫЦШвбп Ш ЯЮбЫХ x/ (ФЮ ЪЮЭжР бЫХФгойХУЮ ЪЮЬЬХЭвРаШп, ХбЫШ ЮЭ бгйХбвТгХв).
ЗвЮ ЪРбРХвбп [/x([^/]|[^x]/)*x/], вЮ нвЮ ТлаРЦХЭШХ ЭХ бЮТЯРФРХв б /x/spcfoospc/x/ (ТЯЮЫЭХ ЭЮаЬРЫмЭлЬ ЪЮЬЬХЭвРаШХЬ, ЪЮвЮалЩ ФЮЫЦХЭ бЮТЯРФРвм). І ФагУШе бЫгзРпе нвЮ ТлаРЦХЭШХ ЬЮЦХв ТлЩвШ ЧР ЪЮЭХж ЪЮЬЬХЭвРаШп, ЧР ЪЮвЮалЬ ЭХЬХФЫХЭЭЮ бЫХФгХв / (ЯЮ РЭРЫЮУШШ б ЯХаТлЬ бЯЮбЮСЮЬ). ІЮЧТаРв, ЯаЮШбеЮФпйШЩ Т вРЪШе бЫгзРпе, ЭХбЪЮЫмЪЮ ЧРЯгвлТРХв бШвгРжШо, ЯЮнвЮЬг ТРЬ бвЮШв аРЧЮСаРвмбп, ЯЮзХЬг [/x([^/]|[^x]/)*x/] бЮТЯРФРХв Т бваЮЪХ
years = days /x divide x//365; /x assume non-leap year x/
б ЯЮФзХаЪЭгвлЬ вХЪбвЮЬ (нвР ЧРФРзР ЮбвРХвбп зШвРвХЫо ФЫп бРЬЮбвЮпвХЫмЭЮЩ аРСЮвл).
ґРТРЩвХ ЯЮЯаЮСгХЬ ШбЯаРТШвм нвШ аХУгЫпаЭлХ ТлаРЦХЭШп. І ЯХаТЮЬ ТлаРЦХЭШШ, УФХ [x[^/]] ЭХЯаХФЭРЬХаХЭЭЮ бЮТЯРФРХв б …xx/ Т ЧРТХаиХЭШШ ЪЮЬЬХЭвРаШп, аРббЬЮваШЬ ЭЮТлЩ ТРаШРЭв [/x([^x]|x+[^/])*x/]. їаХФЯЮЫРУРХвбп, звЮ СЫРУЮФРап ФЮЯЮЫЭШвХЫмЭЮЬг + [x+[^/]] бЮТЯРФРХв б жХЯЮзЪЮЩ x, ЯЮбЫХ ЪЮвЮаЮЩ бЫХФгХв бШЬТЮЫ, ЮвЫШзЭлЩ Юв /. ё нвЮ ФХЩбвТШвХЫмЭЮ вРЪ, ЭЮ ШЧ-ЧР ТЮЧТаРвР «бШЬТЮЫ, ЮвЫШзЭлЩ Юв /» ЬЮЦХв ЮЪРЧРвмбп ТбХ вХЬ ЦХ x. БЭРзРЫР ЬРЪбШЬРЫмЭлЩ ЪТРЭвШдШЪРвЮа [x+] бЮТЯРФРХв б ЫШиЭШЬ x, ЪРЪ Ьл Ш еЮвХЫШ, ЭЮ ТбЫХФбвТШХ ТЮЧТаРвР нвЮв бШЬТЮЫ ЬЮЦХв Слвм ТЮЧТаРйХЭ, ХбЫШ нвЮ ЭХЮСеЮФШЬЮ ФЫп ЯЮЫгзХЭШп ЮСйХУЮ бЮТЯРФХЭШп. є бЮЦРЫХЭШо, ТлаРЦХЭШХ ЯЮ-ЯаХЦЭХЬг ЧРеТРвлТРХв бЫШиЪЮЬ ЬЭЮУЮ:
/xx A xx/ foo() /xx B xx/
ЗвЮСл ЯаШФвШ Ъ ЯаРТШЫмЭЮЬг аХиХЭШо, ЭгЦЭЮ ТбЯЮЬЭШвм вЮ, звЮ п УЮТЮаШЫ аРЭмиХ: дЮаЬгЫШагЩвХ ТлаРЦХЭШХ ЪРЪ ЬЮЦЭЮ вЮзЭХХ. µбЫШ Ьл еЮвШЬ ЮЯаХФХЫШвм «жХЯЮзЪг x, ЯЮбЫХ ЪЮвЮаЮЩ бЫХФгХв бШЬТЮЫ, ЮвЫШзЭлЩ Юв /», Ш ЯаШ нвЮЬ ЯЮФаРЧгЬХТРХвбп, звЮ «бШЬТЮЫ, ЮвЫШзЭлЩ Юв /» вРЪЦХ ЮвЫШзХЭ Ш Юв x, ЮС нвЮЬ ЭгЦЭЮ бЮЮСйШвм пТЭЮ: [x+[^/x]]. єРЪ Ш ваХСЮТРЫЮбм, нвР ЧРЯШбм ЯаХФЮвТаРйРХв ЯЮУЫЮйХЭШХ [xxx/] — ЯЮбЫХФЭХУЮ x Т жХЯЮзЪХ, ЧРТХаиРойХЩ ЪЮЬЬХЭвРаШЩ. І ЪРзХбвТХ ЯЮСЮзЭЮУЮ нддХЪвР ЯаХФЮвТаРйРХвбп бЮТЯРФХЭШХ бЮ ТбХЬШ бШЬТЮЫРЬШ x, ЧРТХаиРойШЬШ ЪЮЬЬХЭвРаШЩ, ЯЮнвЮЬг Ьл ЮЪРЧлТРХЬбп Т ЯЮЧШжШШ …lwrxxx/ ЯХаХФ ЧРЪалТРойШЬ ЮУаРЭШзШвХЫХЬ. їЮбЪЮЫмЪг зРбвм ТлаРЦХЭШп, ЮвЭЮбпйРпбп Ъ ЧРТХаиРойХЬг ЮУаРЭШзШвХЫо, ФЮЯгбЪРХв ТбХУЮ ЮФШЭ бШЬТЮЫ x, Т ЭХХ ЭХЮСеЮФШЬЮ ФЮСРТШвм ЪТРЭвШдШЪРвЮа +: [x+/].
І аХЧгЫмвРвХ ЯЮЫгзРХвбп бЫХФгойХХ ТлаРЦХЭШХ: [/x([^x]|x+[^/x])*x+/].
їХаХТЮФ ЭР пЧлЪ аХУгЫпаЭле ТлаРЦХЭШЩ
ЅР б. <$R[P#,R5-12]>, ЯаШ ЮЯШбРЭШШ ФТге ТРаШРЭвЮТ ЯЮШбЪР Т ЪЮЬЬХЭвРаШпе C «ТбХУЮ, звЮ ЭХ пТЫпХвбп ЧРЪалТРойШЬ ЮУаРЭШзШвХЫХЬ», п ЯаХФбвРТШЫ ФТХ ШФХШ:
…x, ХбЫШ ЧР ЭШЬ ЭХ бЫХФгХв бШЬТЮЫ /: [x[^/]]
Ш
…бШЬТЮЫЮЬ /, ХбЫШ ХЬг ЭХ ЯаХФиХбвТгХв x: [[^x]/]
їаШ нвЮЬ п ТлаРЦРЫбп ЭХдЮаЬРЫмЭЮ — ЮЯШбРЭШп ЮвЫШзРовбп Юв ЯаШТХФХЭЭле аХУгЫпаЭле ТлаРЦХЭШЩ. Іл ТШФШвХ, Ю зХЬ аХзм?
ЗвЮСл ЯЮЭпвм, Т зХЬ ЧРЪЫозРовбп ЮвЫШзШп, ЯаШЬХЭШвХ ЯХаТЮХ ЮЯШбРЭШХ Ъ бваЮЪХ «regex». І ЭХЩ ЯаШбгвбвТгХв бШЬТЮЫ x, ЧР ЪЮвЮалЬ ЭХ бЫХФгХв ЪЮбРп зХавР, ЮФЭРЪЮ нвР бваЮЪР ЭХ бЮТЯРФХв б [x[^/]]. БШЬТЮЫмЭлЩ ЪЫРбб бЮТЯРФРХв б бШЬТЮЫЮЬ, Ш еЮвп нвЮв бШЬТЮЫ ЭХ ЬЮЦХв Слвм ЪЮбЮЩ зХавЮЩ, ЮЭ ТбХ аРТЭЮ ФЮЫЦХЭ Слвм зХЬ-вЮ ФагУШЬ, Р ЭХ «ЭШзХЬ», ЪРЪ Т бваЮЪХ «regex». ІЮ ТвЮаЮЩ бШвгРжШШ ФХЫЮ ЮСбвЮШв РЭРЫЮУШзЭЮ.
єбвРвШ, ЮСаРвШвХ ТЭШЬРЭШХ: ХбЫШ ТРЬ ФХЩбвТШвХЫмЭЮ ЯЮваХСгХвбп аХРЫШЧЮТРвм дЮаЬгЫШаЮТЪг «x, ХбЫШ ЧР ЭШЬ ЭХ бЫХФгХв бШЬТЮЫ /», ЯЮЯаЮСгЩвХ ШбЯЮЫмЧЮТРвм ТлаРЦХЭШХ [x([^/]|$)]. ѕЭЮ ЯЮ-ЯаХЦЭХЬг бЮТЯРФРХв ЪРЪ б бШЬТЮЫЮЬ x, ЭЮ вРЪЦХ ЬЮЦХв бЮТЯРФРвм Ш б ЪЮЭжЮЬ бваЮЪШ. ±ЮЫХХ гФРзЭЮХ аХиХЭШХ (ХбЫШ ЮЭЮ ФЮбвгЯЭЮ) ЧРЪЫозРХвбп Т ШбЯЮЫмЧЮТРЭШШ ЭХУРвШТЭЮЩ ЮЯХаХЦРойХЩ ЯаЮТХаЪШ. І Perl нвР ТЮЧЬЮЦЭЮбвм аХРЫШЧгХвбп ЪЮЭбвагЪжШХЩ [x(?!…)]. ѕЯШбРЭШХ «x, ХбЫШ ЧР ЭШЬ ЭХ бЫХФгХв бШЬТЮЫ /» дЮаЬгЫШагХвбп Т ТШФХ [x(?!/)].
є бЮЦРЫХЭШо, аХваЮбЯХЪвШТЭРп ЯаЮТХаЪР (lookbehind) ЭХ ЯЮФФХаЦШТРХвбп ЭШ Т ЮФЭЮЬ ШЧ ШЧТХбвЭле ЬЭХ ФШРЫХЪвЮТ, ЯЮнвЮЬг ЮСЮаЮв «бШЬТЮЫ /, ХбЫШ ХЬг ЭХ ЯаХФиХбвТгХв x» ЬЮЦЭЮ ЧРЯШбРвм аРЧТХ звЮ Т ТШФХ [(^|[^x])/].
ІлаРЦХЭШХ ФЫп ЭРбвЮпйШе ЪЮЬЬХЭвРаШХТ, бЮ ЧТХЧФЮзЪРЬШ ТЬХбвЮ x, ТлУЫпФШв ХйХ егЦХ:
[/\*([^*]|\*+[^/*])*\*+/]
ЗвЮСл ЯаЮзШвРвм вРЪЮХ ТлаРЦХЭШХ, ТРЬ ЯаШФХвбп ШЧапФЭЮ ЯЮиХТХЫШвм ЬЮЧУРЬШ.
їЮЯаЮСгХЬ ЯЮТлбШвм нддХЪвШТЭЮбвм ТлаРЦХЭШп, ШЧСРТШТиШбм Юв ЪЮЭбвагЪжШШ ТлСЮаР. І вРСЫ. 5.3 ЯаШТХФХЭл ТлаРЦХЭШп, ЪЮвЮалХ ФЮЫЦЭл ЯЮФбвРТЫпвмбп Т иРСЫЮЭ аРбЪагвЪШ жШЪЫР. єРЪ Ш Т ЯаШЬХаХ б ФЮЬХЭЭлЬШ ШЬХЭРЬШ, [ЭЮаЬ*] ЭХ ЬЮЦХв бЮТЯРФРвм б «ЭШзХЬ». І ЯаХФлФгйХЬ ЯаШЬХаХ нвЮ СлЫЮ бТпЧРЭЮ б вХЬ, звЮ «ЭЮаЬРЫмЭРп» зРбвм (ШЬп бгСФЮЬХЭР) ЭХ ЬЮУЫР Слвм ЯгбвЮЩ. І ФРЭЭЮЬ бЫгзРХ нвЮ ЮСкпбЭпХвбп ЮбЮСХЭЭЮбвпЬШ ЮСаРСЮвЪШ ФТгебШЬТЮЫмЭЮУЮ ЧРЪалТРойХУЮ ЮУаРЭШзШвХЫп. »оСРп ЯЮбЫХФЮТРвХЫмЭЮбвм ЭЮаЬ ФЮЫЦЭР ЧРТХаиРвмбп б ЯХаТлЬ бШЬТЮЫЮЬ ЧРЪалТРойХУЮ ЮУаРЭШзШвХЫп, ЯЮЧТЮЫпп бЯХж «ЯХаХеТРвШвм» бЮТЯРФХЭШХ ЫШим Т вЮЬ бЫгзРХ, ХбЫШ бЫХФгойШЩ бШЬТЮЫ ЭХ ЧРТХаиРХв ЮУаРЭШзШвХЫм.
ВРСЫШжР 5.3. єЮЬЯЮЭХЭвл аРбЪагвЪШ жШЪЫР ФЫп ЪЮЬЬХЭвРаШХТ C
|
єЮЬЯЮЭХЭв |
°ЭРЫЮУ Т вХЪбвХ |
АХУгЫпаЭЮХ ТлаРЦХЭШХ |
|
ЭРзРЫЮ |
ЅРзРЫЮ ЪЮЬЬХЭвРаШп |
/x |
|
ЭЮаЬ |
ВХЪбв ЪЮЬЬХЭвРаШп ФЮ ЮФЭЮУЮ ШЫШ ЭХбЪЮЫмЪШе x ТЪЫозШвХЫмЭЮ |
[^x]*x+ |
|
бЯХж |
БШЬТЮЫ, ЮвЫШзЭлЩ Юв ЧРТХаиРойХЩ ЪЮбЮЩ зХавл (Ш ЭХ пТЫпойШЩбп x) |
[^/x] |
|
ЪЮЭХж |
·РТХаиРойРп ЪЮбРп зХавР |
/ |
їЮФбвРТЫпп нвШ ЪЮЬЯЮЭХЭвл Т ЮСйШЩ иРСЫЮЭ аРбЪагвЪШ жШЪЫР, Ьл ЯЮЫгзРХЬ:
[/x[^x]*x+(lwr[^/x][^x]*x+)*/]
ѕСаРвШвХ ТЭШЬРЭШХ ЭР ЯЮЬХзХЭЭлЩ даРУЬХЭв. јХеРЭШЧЬ аХУгЫпаЭле ТлаРЦХЭШЩ ЬЮЦХв ЯаШФвШ Ъ ЭХЬг ФТгЬп ЯгвпЬШ (ЪРЪ Ш Т ТлаРЦХЭШШ ЭР б. <$R[P#,R5-13]>): ЫШСЮ ЯаЮФТШЦХЭШХЬ зХаХЧ ЭРзРЫмЭго ЪЮЭбвагЪжШо [/x[^x]*x+], ЫШСЮ жШЪЫШзХбЪШЬ ЯХаХСЮаЮЬ (…)*. І ЫоСЮЬ бЫгзРХ, ЮЪРЧРТиШбм Т нвЮЬ ЯЮЧШжШШ, Ьл ЧЭРХЬ, звЮ СлЫ ЭРЩФХЭ бШЬТЮЫ x, Ш вХЪгйРп ЯЮЧШжШп пТЫпХвбп ЪаШвШзХбЪЮЩ вЮзЪЮЩ — ТЮЧЬЮЦЭЮ, Т ЪЮЭжХ ЪЮЬЬХЭвРаШп. µбЫШ бЫХФгойШЬ бШЬТЮЫЮЬ пТЫпХвбп ЪЮбРп зХавР, ЯЮШбЪ ЧРЪЮЭзХЭ. µбЫШ нвЮ ЫоСЮЩ ФагУЮЩ бШЬТЮЫ (ЪЮЭХзЭЮ, ЪаЮЬХ x), Ьл ЧЭРХЬ, звЮ ваХТЮУР СлЫР ЫЮЦЭЮЩ Ш ЬЮЦЭЮ ТХаЭгвмбп Ъ ЯЮШбЪг бЮТЯРФХЭШЩ ФЫп ЪЮЬЯЮЭХЭвР ЭЮаЬ Т ЮЦШФРЭШШ бЫХФгойХУЮ x. їЮбЫХ вЮУЮ, ЪРЪ бШЬТЮЫ СгФХв ЭРЩФХЭ, Ьл бЭЮТР ЮЪРЧлТРХЬбп Т ЪаШвШзХбЪЮЩ вЮзЪХ.
ІлаРЦХЭШХ [/x[^x]*x+([^/x][^x]*x+)*/] ЭХ бЮТбХЬ УЮвЮТЮ Ъ ЯаРЪвШзХбЪЮЬг ШбЯЮЫмЧЮТРЭШо. ІЮ-ЯХаТле, ЪЮЭХзЭЮ, ЪЮЬЬХЭвРаШШ ЮСЮЧЭРзРовбп ЮУаРЭШзШвХЫпЬШ /*…*/, Р ЭХ /x…x/. їаЮСЫХЬР ЫХУЪЮ аХиРХвбп ЧРЬХЭЮЩ ЪРЦФЮУЮ x ЭР нЪаРЭШаЮТРЭЭго ЧТХЧФЮзЪг \* (Т бШЬТЮЫмЭле ЪЫРббРе — ЯаЮбвЮЩ ЧРЬХЭЮЩ x ЭР *):
[/\*[^*]*\*+([^/*][^*]*\*+)*/]
ВРЪЦХ бЫХФгХв гзХбвм вЮв дРЪв, звЮ ЪЮЬЬХЭвРаШШ зРбвЮ аРбЯаЮбваРЭповбп ЭР ЭХбЪЮЫмЪЮ бваЮЪ. µбЫШ ШбЪЮЬлЩ вХЪбв бЮФХаЦШв ТХбм ЬЭЮУЮбваЮзЭлЩ ЪЮЬЬХЭвРаШЩ, нвЮ ТлаРЦХЭШХ СгФХв аРСЮвРвм. ѕФЭРЪЮ Т бваЮзЭЮ-ЮаШХЭвШаЮТРЭЭле ЯаЮУаРЬЬРе (вРЪШе, ЪРЪ egrep) ЭХ бгйХбвТгХв ТЮЧЬЮЦЭЮбвШ ЯаШЬХЭШвм аХУгЫпаЭЮХ ТлаРЦХЭШХ Ъ ЯЮЫЭЮЬг ЪЮЬЬХЭвРаШо (Ъ вЮЬг ЦХ Т СЮЫмиШЭбвТХ ТХабШЩ egrep ШбЯЮЫмЧгХвбп ЬХеРЭШЧЬ ґє°, ЯЮнвЮЬг ТРЬ ТЮЮСйХ ЭХ ЯаШФХвбп СХбЯЮЪЮШвмбп Ю аРбЪагвЪХ жШЪЫР). І Emacs, Perl Ш апФХ ФагУШе ЯЮЫХЧЭле ЯаЮУаРЬЬ, гЯЮЬпЭгвле Т ЪЭШУХ, нвЮ ТЮЧЬЮЦЭЮ, ЯЮнвЮЬг ФРЭЭЮХ ТлаРЦХЭШХ ЬЮЦХв ЯаШЬХЭпвмбп, ЭРЯаШЬХа, ФЫп гФРЫХЭШп ЪЮЬЬХЭвРаШХТ.
ЅР ЯаРЪвШЪХ ТЮЧЭШЪРХв ХйХ ЮФЭР СЮЫмиРп ЯаЮСЫХЬР. ЅРиХ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯЮЭШЬРХв ЪЮЬЬХЭвРаШШ C, ЭЮ ЭШзХУЮ ЭХ ЧЭРХв Ю ФагУШе ТРЦЭле РбЯХЪвРе бШЭвРЪбШбР C. ЅРЯаШЬХа, ЮЭЮ ЬЮЦХв бЮТЯРбвм Ш ЯаШ ЮвбгвбвТШШ ЪЮЬЬХЭвРаШп:
const char *cstart = "/*", *cend = "*/";
ЅРиХ ТлаРЦХЭШХ СгФХв гбЮТХаиХЭбвТЮТРЭЮ Т бЫХФгойХЬ аРЧФХЫХ.
јл ЯЮваРвШЫШ ЭХЪЮвЮаЮХ ТаХЬп ЭР ЪЮЭбвагШаЮТРЭШХ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, ЯаХФЭРЧЭРзХЭЭЮУЮ ФЫп ЯЮШбЪР ЪЮЬЬХЭвРаШХТ C, Ш ЮбвРЭЮТШЫШбм ЭР ЯаЮСЫХЬХ бЫгзРЩЭле бЮТЯРФХЭШЩ, ЯЮ бТЮХЩ бвагЪвгаХ ЭРЯЮЬШЭРойШе ЪЮЬЬХЭвРаШШ. ЅРЯаШЬХа, Т Tcl ФЫп гФРЫХЭШп ЪЮЬЬХЭвРаШХТ ЬЮЦЭЮ ЯЮЯлвРвмбп ШбЯЮЫмЧЮТРвм бЫХФгойШЩ даРУЬХЭв:
set COMMENT {/\*[^*]*\*+([^/*][^*]*\*+)*/} # ЪЮЬЬХЭвРаШЩ
regsub -all "$COMMENT" $text {} text
(ЯаШЬХзРЭШХ: ЭХШЭвХаЯЮЫШагХЬлХ бваЮЪШ Т Tcl ЧРФРовбп Т ТШФХ {...} )
НвЮв даРУЬХЭв СХаХв бЮФХаЦШЬЮХ ЯХаХЬХЭЭЮЩ COMMENT, ШЭвХаЯаХвШагХв ХУЮ ЪРЪ аХУгЫпаЭЮХ ТлаРЦХЭШХ Ш ЧРЬХЭпХв ТбХ ХУЮ бЮТЯРФХЭШп Т бваЮЪХ, ЧРФРЭЭЮЩ ЯХаХЬХЭЭЮЩ text. БЮТЯРФРойШЩ вХЪбв ЧРЬХЭпХвбп «ЭШзХЬ» (вЮ Хбвм ЯгбвЮЩ бваЮЪЮЩ Tcl, { }). їЮбЫХ ЧРТХаиХЭШп ЯЮФбвРЭЮТЪШ аХЧгЫмвРв бЭЮТР ЧРЭЮбШвбп Т ЯХаХЬХЭЭго text.
їаЮСЫХЬР<$M[R5-23]> ЧРЪЫозРХвбп Т вЮЬ, звЮ Т ЯаЮжХббХ ЯХаХЬХйХЭШп ЭРзРЫмЭЮЩ ЯЮЧШжШШ ЭРзРЫЮ бЮТЯРФХЭШп ЬЮЦХв Слвм бЫгзРЩЭЮ ЮСЭРагЦХЭЮ ТЭгваШ бваЮЪШ. ЅРиР ЧРФРзР — бФХЫРвм вРЪ, звЮСл ЬХеРЭШЧЬ аХУгЫпаЭле ТлаРЦХЭШЩ Т ЯаЮжХббХ ЯЮШбЪР ШУЭЮаШаЮТРЫ бваЮЪШ, ЧРЪЫозХЭЭлХ Т ЪРТлзЪШ.
АРббЬЮваШЬ бЫХФгойШЩ даРУЬХЭв:
set COMMENT {/\*[^*]*\*+([^/*][^*]*\*+)*/} # ЪЮЬЬХЭвРаШЩ
set DOUBLE {"(\\.|[^"\\])*"} # бваЮЪР Т ЪРТлзЪРе
regsub -all "$DOUBLE|$COMMENT" $text {} text
µбЫШ ЯЮШбЪ ЭРзШЭРХвбп Т ЯЮЧШжШШ, УФХ ЬЮЦХв бЮТЯРбвм ТлаРЦХЭШХ $DOUBLE, Тбп бваЮЪР Т ЪРТлзЪРе ШУЭЮаШагХвбп. ІЮЧЬЮЦЭЮбвм ТЪЫозХЭШп ЮСХШе РЫмвХаЭРвШТ Т ЯЮШбЪ ЮСгбЫЮТЫХЭР ЯЮЫЭлЬ ЮвбгвбвТШХЬ ЭХЮФЭЮЧЭРзЭЮбвШ ЬХЦФг ЭШЬШ. ЅРзШЭРп б ЫХТЮУЮ ЪаРп, ЫоСРп ЭРзРЫмЭРп ЯЮЧШжШп Т бваЮЪХ…
l пТЫпХвбп ЭРзРЫЮЬ ЪЮЬЬХЭвРаШп, звЮ ЯаШТЮФШв Ъ ЭХЬХФЫХЭЭЮЬг ЯаЮЯгбЪг бШЬТЮЫЮТ ФЮ ЪЮЭжР ЪЮЬЬХЭвРаШп; ШЫШ…
l пТЫпХвбп ЭРзРЫЮЬ бваЮЪШ Т ЪРТлзЪРе, звЮ вРЪЦХ ЯаШТЮФШв Ъ ЭХЬХФЫХЭЭЮЬг ЯаЮЯгбЪг ФЮ ЪЮЭжР бваЮЪШ; ШЫШ…
l ЭХ ЮСХбЯХзШТРХв бЮТЯРФХЭШп ЭШ ФЫп ЮФЭЮУЮ ШЧ нвШе ТлаРЦХЭШЩ. І нвЮЬ бЫгзРХ ЬХеРЭШЧЬ бЬХйРХв ЭРзРЫмЭго ЯЮЧШжШо вЮЫмЪЮ ЭР ЮФШЭ бШЬТЮЫ.
І нвЮЬ бЫгзРХ ЭРзРЫмЭРп ЯЮЧШжШп бЮТЯРФХЭШп ЭШЪЮУФР ЭХ СгФХв ЭРеЮФШвмбп ТЭгваШ бваЮЪШ ШЫШ ЪЮЬЬХЭвРаШп — Т нвЮЬ Ш ЧРЪЫозРХвбп бХЪаХв гбЯХеР.
їЮЪР нвЮв даРУЬХЭв ЮбвРХвбп СХбЯЮЫХЧЭлЬ, ЯЮбЪЮЫмЪг ТЬХбвХ б ЪЮЬЬХЭвРаШпЬШ ЮЭ гФРЫпХв Ш бваЮЪШ, ЧРЪЫозХЭЭлХ Т ЪРТлзЪШ. ІЯаЮзХЬ, ЭХСЮЫмиЮХ ШЧЬХЭХЭШХ бвРТШв ТбХ ЭР бТЮШ ЬХбвР.
set COMMENT {/\*[^*]*\*+([^/*][^*]*\*+)*/} # ЪЮЬЬХЭвРаШЩ
set DOUBLE {"(\\.|[^"\\])*"} # бваЮЪР Т ЪРТлзЪРе
regsub -all "($DOUBLE)|$COMMENT" $text {\1} text
І нвЮв даРУЬХЭв СлЫШ ТЭХбХЭл бЫХФгойШХ ШЧЬХЭХЭШп:
l ґЮСРТЫХЭл ЪагУЫлХ бЪЮСЪШ ФЫп ЧРЯЮЫЭХЭШп \1 (РЭРЫЮУ ЯХаХЬХЭЭЮЩ Perl $1, ШбЯЮЫмЧгХЬлЩ Т Tcl ЯаШ ЧРЬХЭХ) Т вЮЬ бЫгзРХ, ХбЫШ ЮСЭРагЦШТРХвбп бваЮЪР Т ЪРТлзЪРе. µбЫШ СгФХв ЭРЩФХЭР РЫмвХаЭРвШТР-ЪЮЬЬХЭвРаШЩ, ЯХаХЬХЭЭРп \1 ЮбвРХвбп ЯгбвЮЩ.
l І ЪРзХбвТХ ЧРЬХЭпойХЩ бваЮЪШ СлЫР ЯЮФбвРТЫХЭР вР ЦХ ЯХаХЬХЭЭРп \1. µбЫШ вХЯХам СгФХв ЭРЩФХЭР бваЮЪР Т ЪРТлзЪРе, ЮЭР ЧРЬХЭпХвбп вЮЩ ЦХ бРЬЮЩ бваЮЪЮЩ — ЯаЮШбеЮФШв вЮЦФХбвТХЭЭРп ЧРЬХЭР, ЯЮнвЮЬг бваЮЪШ Т ЪРТлзЪРе ШЧ вХЪбвР ЭХ гФРЫповбп. Б ФагУЮЩ бвЮаЮЭл, ЯаШ бЮТЯРФХЭШШ РЫмвХаЭРвШТл ЪЮЬЬХЭвРаШп ЯХаХЬХЭЭРп \1 ЮбвРХвбп ЯгбвЮЩ, ЯЮнвЮЬг ЪЮЬЬХЭвРаШЩ, ЪРЪ Ш СлЫЮ ЧРЯЫРЭШаЮТРЭЮ, ЧРЬХЭпХвбп ЯгбвЮЩ бваЮЪЮЩ.
ЅРЪЮЭХж, Ьл ФЮЫЦЭл ЯЮЧРСЮвШвмбп Ю ЪЮЭбвРЭвРе C, ЧРЪЫозХЭЭле Т РЯЮбваЮдл ('\t' Ш в. Ф.). ·РФРзР аХиРХвбп ЯаЮбвЮ — ТЪЫозХЭШХЬ Т ЪагУЫлХ бЪЮСЪШ ЭЮТЮЩ РЫмвХаЭРвШТл. µбЫШ Тл ЧРеЮвШвХ гФРЫпвм Ш ЪЮЬЬХЭвРаШШ C++ //; ФЫп нвЮУЮ ФЮбвРвЮзЭЮ ФЮСРТШвм зХвТХавго РЫмвХаЭРвШТг [//[^\n]*], ЭХ ЧРЪЫозРп ХХ Т ЪагУЫлХ бЪЮСЪШ. І аХУгЫпаЭле ТлаРЦХЭШпе Tcl ЧРЯШбм \n ЮвбгвбвТгХв, ЧРвЮ ЮЭР ЯЮФФХаЦШТРХвбп Т бваЮЪРе Tcl, ЧРЪЫозХЭЭле Т ЪРТлзЪШ, ЯЮнвЮЬг ФЫп бЮЧФРЭШп [//[^new]*] бЫХФгХв ШбЯЮЫмЧЮТРвм бваЮЪг "//\[^\n]*":
set COMMENT {/\*[^*]*\*+([^/*][^*]*\*+)*/} # ЪЮЬЬХЭвРаШЩ
set COMMENT2 "//\[^\n]*" # ЪЮЬЬХЭвРаШЩ C++ //
set DOUBLE {"(\\.|[^"\\])*"} # бваЮЪР Т ЪРТлзЪРе
set SINGLE {'(\\.|[^"\\])*'} # ЪЮЭбвРЭвР Т РЯЮбваЮдРе
regsub -all "($DOUBLE|$SINGLE)|$COMMENT|$COMMENT2" $text {\1} text
І ЮбЭЮТг нвЮУЮ аХиХЭШп ЧРЫЮЦХЭР ФЮТЮЫмЭЮ ШЧпйЭРп ШФХп: ТЮ ТаХЬп ЯаЮТХаЪШ вХЪбвР ЬХеРЭШЧЬ СлбваЮ ЭРеЮФШв (Ш Т ЭгЦЭле бШвгРжШпе — гФРЫпХв) нвШ бЯХжШРЫмЭлХ ЪЮЭбвагЪжШШ. П ЯаЮТХЫ ЭХСЮЫмиЮЩ вХбв: ФЫп гФРЫХЭШп ТбХе ЪЮЬЬХЭвРаШХТ ШЧ дРЩЫР ЮСкХЬЮЬ 1,6 јСРЩв, бЮбвЮпйХУЮ ШЧ 60 000 бваЮЪ, ЭР ЬЮХЬ ЪЮЬЯмовХаХ Tcl ЧРваРвШЫ ТбХУЮ 37 бХЪгЭФ.
µбЫШ ЯаШЫЮЦШвм ЭХЪЮвЮалХ ФЮЯЮЫЭШвХЫмЭлХ гбШЫШп, ЯаЮжХбб ЯЮШбЪР бЮТЯРФХЭШЩ ЬЮЦЭЮ ЧЭРзШвХЫмЭЮ гбЪЮаШвм. АРббЬЮваШЬ ФЫШЭЭлХ ЯЮбЫХФЮТРвХЫмЭЮбвШ бШЬТЮЫЮТ ЮСлзЭЮУЮ ЪЮФР C ЬХЦФг ЪЮЬЬХЭвРаШпЬШ Ш бваЮЪРЬШ Т ЪРТлзЪРе. ґЫп ЪРЦФЮУЮ вРЪЮУЮ бШЬТЮЫР ЬХеРЭШЧЬ аХУгЫпаЭле ТлаРЦХЭШЩ ФЮЫЦХЭ ЮЯаЮСЮТРвм ТбХ зХвлаХ РЫмвХаЭРвШТл Ш ЮЯаХФХЫШвм, ЭХ ЮвЭЮбШвбп ЫШ ЮЭ Ъ ЮФЭЮЬг ШЧ зХвлаХе «ЯЮУЫЮйРХЬле» даРУЬХЭвЮТ. ВЮЫмЪЮ ХбЫШ ЯаЮТХаЪР ТбХе зХвлаХе РЫмвХаЭРвШТ ЧРТХаиРХвбп ЭХгФРзХЩ, бШЬТЮЫ ЮвТХаУРХвбп ЪРЪ «ЭХШЭвХаХбЭлЩ», Ш ЬХеРЭШЧЬ ЯХаХеЮФШв Ъ бЫХФгойХЩ ЯЮЧШжШШ. ВРЪШЬ ЮСаРЧЮЬ, ТлЯЮЫЭпХвбп СЮЫмиРп аРСЮвР, ЪЮвЮаго ЭР бРЬЮЬ ФХЫХ ТлЯЮЫЭпвм ЭХ ЮСпЧРвХЫмЭЮ.
ЅРЯаШЬХа, Ьл ЧЭРХЬ, звЮ ФЫп бЮТЯРФХЭШп ЪРЪЮЩ-ЫШСЮ ШЧ зХвлаХе РЫмвХаЭРвШТ ЭРзРЫмЭлЩ бШЬТЮЫ ФЮЫЦХЭ Слвм ЪЮбЮЩ зХавЮЩ, РЯЮбваЮдЮЬ ШЫШ ЪРТлзЪЮЩ. ІлЯЮЫЭХЭШХ нвЮУЮ гбЫЮТШп ХйХ ЭХ УРаРЭвШагХв бЮТЯРФХЭШп, ЭЮ ХУЮ ЭХТлЯЮЫЭХЭШХ ЧРТХФЮЬЮ УЮТЮаШв Ю вЮЬ, звЮ бЮТЯРФХЭШп ЭХв. ёвРЪ, ТЬХбвЮ вЮУЮ, звЮСл ЧРбвРТЫпвм ЬХеРЭШЧЬ ТлЯЮЫЭпвм ЬХФЫХЭЭлЩ Ш ЬгзШвХЫмЭлЩ ЯХаХСЮа, Ьл ЯапЬЮ гЪРЦХЬ ЭР нвЮв дРЪв Ш ТЪЫозШЬ бШЬТЮЫмЭлЩ ЪЫРбб [[^'"/]] Т ЪРзХбвТХ ЮвФХЫмЭЮЩ РЫмвХаЭРвШТл. ±ЮЫХХ вЮУЮ, Т дРЩЫХ нвШ «ЭХШЭвХаХбЭлХ» бШЬТЮЫл ЬЮУгв бЫХФЮТРвм ЯЮФапФ, ЯЮнвЮЬг Ьл ТЮбЯЮЫмЧгХЬбп ТлаРЦХЭШХЬ [[^'"/]+]. µбЫШ Тл ЯЮЬЭШвХ ЯаШЬХа б СХбЪЮЭХзЭлЬ ЯХаХСЮаЮЬ, ТЮЧЬЮЦЭЮ, ТРб ЮСХбЯЮЪЮШв ЯЮпТЫХЭШХ ЭЮТЮУЮ ЯЫобР. І бРЬЮЬ ФХЫХ, ЯЫоб ТЭгваШ ЪЮЭбвагЪжШШ (…)* бЯЮбЮСХЭ ЯаШзШЭШвм ЬРббг еЫЮЯЮв, ЭЮ ЪРЪ бРЬЮбвЮпвХЫмЭРп ЪЮЭбвагЪжШп ЮЭ ТЯЮЫЭХ ФЮЯгбвШЬ (ЧР ЭШЬ ЭХв ЭШзХУЮ, звЮ ЬЮУЫЮ Сл ЯаШЭгФШвм ЬХеРЭШЧЬ Ъ ТЮЧТаРвг Ш бвРвм ЯаШзШЭЮЩ СХбЪЮЭХзЭЮУЮ ЯХаХСЮаР). ёвРЪ, Т ЭРи вХбв ТЪЫозРовбп ЭЮТлХ бваЮЪШ:
set OTHER {[^"'/]} # БШЬТЮЫ, ЪЮвЮалЩ ЭХ ЬЮЦХв Слвм
… # ЭРзРЫЮЬ ЫоСЮЩ ФагУЮЩ РЫмвХаЭРвШТл
regsub -all "($DOUBLE|$SINGLE|$OTHER+)|$COMMENT|$COMMENT2" $text {\1} text
П ЧРЭЮТЮ ЧРЯгбЪРо бТЮЩ вХбв. ёЧгЬЫХЭЭРп ЯгСЫШЪР ЫШЪгХв — ТбХУЮ ЮФЭЮ ШЧЬХЭХЭШХ бЮЪаРвШЫЮ ТаХЬп ЮСаРСЮвЪШ б 36 бХЪгЭФ ФЮ 3,2 бХЪгЭФл! ѕСаРСЮвЪР гбЪЮаШЫРбм ЭР жХЫлЩ ЯЮапФЮЪ. І ЯЮбваЮХЭЭЮЬ ЭРЬШ ТлаРЦХЭШШ ШбЪЫозХЭР СЮЫмиРп зРбвм ЭХЯаЮШЧТЮФШвХЫмЭле ЧРваРв ЯЮ ЯХаХСЮаг РЫмвХаЭРвШТ Ш ЯЮбЫХФгойХЬг бЬХйХЭШо ЭРзРЫмЭЮЩ ЯЮЧШжШШ. ѕбвРовбп ХйХ ЮвЭЮбШвХЫмЭЮ аХФЪШХ бШвгРжШШ, ЯаШ ЪЮвЮале ЭХ бЮТЯРФРХв ЭШ ЮФЭР ШЧ РЫмвХаЭРвШТ (ЭРЯаШЬХа, «cspclwr/spc3.14»). І нвЮЬ бЫгзРХ ФЫп ЯХаХСЮаР ЯаШеЮФШвбп ФЮТЮЫмбвТЮТРвмбп бвРЭФРавЭлЬ ЬХеРЭШЧЬЮЬ бЬХйХЭШп вХЪгйХЩ ЯЮЧШжШШ.
ЅЮ ФРЦХ бХЩзРб аРСЮвР ХйХ ЭХ ЧРЪЮЭзХЭР — аРСЮвг ЬХеРЭШЧЬР ЬЮЦЭЮ ХйХ гбЪЮаШвм:
l єРЪ ЯаРТШЫЮ, зРйХ ТбХУЮ СгФХв бЮТЯРФРвм РЫмвХаЭРвШТР [$OTHER+], ЯЮнвЮЬг Ьл ЯЮбвРТШЬ ХХ ЭР ЯХаТЮХ ЬХбвЮ Т ЪагУЫле бЪЮСЪРе. ґЫп ЬХеРЭШЧЬР POSIX Ѕє° нвЮ ЭХбгйХбвТХЭЭЮ, ЯЮбЪЮЫмЪг ЮЭ ТбХУФР ЯаЮТХапХв ТбХ РЫмвХаЭРвШТл, ЭЮ Т Tcl аХРЫШЧЮТРЭ ваРФШжШЮЭЭлЩ ЬХеРЭШЧЬ Ѕє°, ЯаХЪаРйРойШЩ ЯЮШбЪ баРЧг ЦХ ЯЮбЫХ ЭРеЮЦФХЭШп бЮТЯРФХЭШп. БвЮШв ЫШ ЧРбвРТЫпвм ХУЮ ЯЮФЮЫУг аРЧлбЪШТРвм вЮ, звЮ, ЯЮ ЭРиХЬг ЬЭХЭШо, пТЫпХвбп бРЬЮЩ зРбвЮЩ РЫмвХаЭРвШТЮЩ?
l їЮбЫХ ЭРеЮЦФХЭШп бваЮЪШ, ЧРЪЫозХЭЭЮЩ Т РЯЮбваЮдл ШЫШ ЪРТлзЪШ, ЧР ЭХЩ б СЮЫмиЮЩ ТХаЮпвЭЮбвмо ЯЮбЫХФгов ЯЮТвЮаХЭШп $OTHER, ЯЮбЫХ зХУЮ ЯЮбЫХФгХв ФагУРп бваЮЪР ШЫШ ЪЮЬЬХЭвРаШЩ. µбЫШ ФЮСРТШвм [$OTHER*] ЯЮбЫХ ЪРЦФЮЩ бваЮЪШ, Ьл вХЬ бРЬлЬ бЮЮСйШЬ ЬХеРЭШЧЬг, звЮ ЮЭ ЬЮЦХв ЯХаХЩвШ ЭХЬХФЫХЭЭЮ Ъ ЯЮШбЪг бЮТЯРФХЭШп ФЫп $OTHER СХЧ ЮСаРСЮвЪШ жШЪЫР -all. їаЮШбеЮФпйХХ ЭРЯЮЬШЭРХв ЬХвЮФШЪг аРбЪагвЪШ жШЪЫР. І бгйЭЮбвШ, ТлШУали Т бЪЮаЮбвШ Юв аРбЪагвЪШ жШЪЫР Т ЧЭРзШвХЫмЭЮЩ бвХЯХЭШ ЮСгбЫЮТЫХЭ вХЬ, звЮ Ьл «ЭРЯаРТЫпХЬ» ЬХеРЭШЧЬ аХУгЫпаЭле ТлаРЦХЭШЩ Ъ бЮТЯРФХЭШо, ШбЯЮЫмЧгп ЮСйШХ бТХФХЭШп Ю жХЫХТЮЬ вХЪбвХ ФЫп бЮЧФРЭШп ЫЮЪРЫмЭле ЮЯвШЬШЧРжШЩ. јХеРЭШЧЬ аХУгЫпаЭле ТлаРЦХЭШЩ ЯЮЫгзРХв ШЬХЭЭЮ вХ бТХФХЭШп, ЪЮвЮалХ ЭХЮСеЮФШЬл ФЫп ХУЮ СлбваЮЩ аРСЮвл.
ѕзХЭм ТРЦЭЮ, звЮСл ТлаРЦХЭШХ $OTHER, ЪЮвЮаЮХ ФЮСРТЫпХвбп ЯЮбЫХ ЪРЦФЮУЮ ЯЮФТлаРЦХЭШп, бЮТЯРФРойХУЮ бЮ бваЮЪЮЩ Т ЪРТлзЪРе ШЫШ РЯЮбваЮдРе, ЪТРЭвШдШжШаЮТРЫЮбм ЧТХЧФЮзЪЮЩ, Р ЭРзРЫмЭЮХ ТлаРЦХЭШХ $OTHER (вЮ, ЪЮвЮаЮХ Ьл ЯХаХЬХбвШЫШ Т ЭРзРЫЮ ЪЮЭбвагЪжШШ ТлСЮаР) ЪТРЭвШдШжШаЮТРЫЮбм ЯЫобЮЬ. µбЫШ ТРЬ нвЮ ЯЮЪРЦХвбп ЭХЯЮЭпвЭлЬ, ЯЮФгЬРЩвХ, звЮ ЯаЮШЧЮЩФХв, ХбЫШ бгддШЪбЭЮХ ТлаРЦХЭШХ $OTHER СгФХв ЪТРЭвШдШжШаЮТРвмбп ЯЫобЮЬ, Ш Т вХЪбвХ ТбваХвпвбп, бЪРЦХЬ, ФТХ бваЮЪШ Т ЪРТлзЪРе ЯЮФапФ. ° ХбЫШ Т ЭРзРЫмЭЮЬ ТлаРЦХЭШШ $OTHER СгФХв ШбЯЮЫмЧЮТРвмбп ЪТРЭвШдШЪРвЮа *, ЮЭЮ СгФХв бЮТЯРФРвм ТбХУФР!
ѕЯШбРЭЭлХ ШЧЬХЭХЭШп ЯаШТЮФпв Ъ бЫХФгойХЬг аХЧгЫмвРвг:
"($OTHER+|$DOUBLE$OTHER*|$SINGLE$OTHER*)|$COMMENT|$COMMENT2"
НвЮ ТлаРЦХЭШХ, ЯХаХФРТРХЬЮХ Т ЪРзХбвТХ РаУгЬХЭвР regsub, гЬХЭмиРХв ТаХЬп ЮСаРСЮвЪШ ХйХ ЯаШЬХаЭЮ ЭР 6 ЯаЮжХЭвЮТ, бЮЪаРйРп ХУЮ ФЮ 2,9 бХЪгЭФл. ·Р бзХв гЯаРТЫХЭШп ЯЮШбЪЮЬ бЮТЯРФХЭШЩ ЭРЬ гФРЫЮбм гбЪЮаШвм аРСЮвг ТлаРЦХЭШп Т 12 аРЧ!
ґРТРЩвХ ТХаЭХЬбп ЭР иРУ ЭРЧРФ Ш ЯаЮРЭРЫШЧШагХЬ ФТР ЯЮбЫХФЭШе ШЧЬХЭХЭШп. їЮбЪЮЫмЪг Ьл «ТлзХаЯлТРХЬ» $OTHER* ЯЮбЫХ ЪРЦФЮЩ бваЮЪШ Т РЯЮбваЮдРе ШЫШ ЪРТлзЪРе, ШбеЮФЭЮХ ЯЮФТлаРЦХЭШХ $OTHER+ (ЯЮбвРТЫХЭЭЮХ ЭРЬШ ЭР ЯХаТЮХ ЬХбвЮ Т ЪЮЭбвагЪжШШ ТлСЮаР) ЬЮЦХв бЮТЯРбвм вЮЫмЪЮ Т ФТге бЫгзРпе:
1. Т бРЬЮЬ ЭРзРЫХ аРСЮвл regsub, ФЮ вЮУЮ, ЪРЪ СлЫР ЭРЩФХЭР еЮвп Сл ЮФЭР бваЮЪР Т ЪРТлзЪРе ШЫШ РЯЮбваЮдРе;
2. ЯЮбЫХ ЫоСЮУЮ ЪЮЬЬХЭвРаШп.
ІЮЧЭШЪРХв бЮСЫРЧЭШвХЫмЭРп ЬлбЫм: ЯЮзХЬг Сл ЭРЬ ЭХ аРЧЮСаРвмбп б ЯгЭЪвЮЬ 2, ФЮСРТШТ $OTHER* Ш ЯЮбЫХ ЪЮЬЬХЭвРаШХТ? ЅР ЯХаТлЩ ТЧУЫпФ ТбХ еЮаЮиЮ, ХбЫШ ЭХ бзШвРвм вЮУЮ, звЮ ТХбм ЮбвРТЫпХЬлЩ вХЪбв ФЮЫЦХЭ ЭРеЮФШвмбп ТЭгваШ ЪагУЫле бЪЮСЮЪ — аРбЯЮЫРУРп ХУЮ ЯЮбЫХ ЪЮЬЬХЭвРаШХТ, Ьл ТЬХбвХ б ТЮФЮЩ (вЮ Хбвм ЪЮЬЬХЭвРаШпЬШ) ТлЯЫХбЪШТРХЬ ШЧ ТРЭЭл Ш аХСХЭЪР (ЪЮФ).
ёвРЪ, ХбЫШ ШбеЮФЭЮХ ТлаРЦХЭШХ $OTHER+ ШбЯЮЫмЧгХвбп Т ЮбЭЮТЭЮЬ ЯЮбЫХ ЪЮЬЬХЭвРаШХТ, бвЮШв ЫШ ЯХаХЬХйРвм ХУЮ ЭР ЯХаТЮХ ЬХбвЮ? ІХаЮпвЭЮ, ЮвТХв ЭР нвЮв ТЮЯаЮб ЧРТШбШв Юв ФРЭЭле — ХбЫШ ЪЮЬЬХЭвРаШХТ СЮЫмиХ, зХЬ бваЮЪ Т ЪРТлзЪРе Ш РЯЮбваЮдРе, вЮУФР вРЪЮХ ЯХаХЬХйХЭШХ ЮЯаРТФРЭЮ. І ЯаЮвШТЭЮЬ бЫгзРХ п ЭХ бвРЫ Сл ТлЭЮбШвм нвг РЫмвХаЭРвШТг ТЯХаХФ. єРЪ ЯЮЪРЧРЫШ ЬЮШ вХбвл, ЯаШ аРбЯЮЫЮЦХЭШШ нвЮУЮ ТлаРЦХЭШп ЭР ЯХаТЮЬ ЬХбвХ СлЫШ ЯЮЪРЧРЭл ЫгзиШХ аХЧгЫмвРвл. їаШ ЯХаХЬХйХЭШШ ХУЮ Т ЪЮЭХж ТлаРЦХЭШп СлЫР ЯЮвХапЭР ЯаШЬХаЭЮ ЯЮЫЮТШЭР ТлШУалиР, ФЮбвШУЭгвЮУЮ ЭР ЯаХФлФгйХЬ иРУХ.
єРЪ, нвЮ ХйХ ЭХ ТбХ? ЅХв! ЅХ ЧРСлТРЩвХ Ю вЮЬ, звЮ ЪРЦФЮХ ТлаРЦХЭШХ ФЫп бваЮЪ, ЧРЪЫозХЭЭле Т ЪРТлзЪШ Ш РЯЮбваЮдл, ЯаХЪаРбЭЮ ЯЮФеЮФШв ФЫп аРбЪагвЪШ — ЬХвЮФШЪШ, ЪЮвЮаЮЩ Т нвЮЩ УЫРТХ СлЫ ЯЮбТпйХЭ ФЫШЭЭлЩ аРЧФХЫ. ·РЬХЭР ТлаРЦХЭШЩ SINGLE Ш DOUBLE аРбЪагзХЭЭлЬШ ТХабШпЬШ:
set DOUBLE {"[^"\\]*(\\.[^"\\]*)*"}
set SINGLE {'[^'\\]*(\\.[^'\\]*)*'}
бЮЪаРйРХв ТаХЬп ЮСаРСЮвЪШ ФЮ 2,3 бХЪгЭФл, вЮ Хбвм ЮСХбЯХзШТРХв ХйХ 25-ЯаЮжХЭвЭлЩ ТлШУали. ІбХ ЮЯвШЬШЧРжШШ, аРббЬЮваХЭЭлХ ФЮ ЭРбвЮпйХУЮ ЬЮЬХЭвР, ШЧЮСаРЦХЭл ЭР аШб. 5.9.
їХаХЬХЭЭлХ ЧРЬХвЭЮ ЮСЫХУзРов ЯЮбваЮХЭШХ аХУгЫпаЭле ТлаРЦХЭШЩ Т Tcl, ЯЮбЪЮЫмЪг ЭХШЭвХаЯЮЫШагХЬРп ЪЮЭбвагЪжШп {…} ЭХ ТлЧлТРХв ЭХЮФЭЮЧЭРзЭЮЩ ШЭвХаЯаХвРжШШ бШЬТЮЫЮТ. ІФЮСРТЮЪ ЯЮЫЭЮХ ТлаРЦХЭШХ, ЯаШТХФХЭЭЮХ ЭШЦХ (б аРЧСШХЭШХЬ ЭР бваЮЪШ ЯЮ иШаШЭХ бваРЭШжл), ЮЪРЧлТРХвбп бЬХеЮвТЮаЭЮ ФЫШЭЭлЬ:
([^"'/]+|"[^"\\]*(\\.[^"\\]*)*"[^"'/]*|'[^'\\]*(\\.[^'\\]*)*'[^"'/]*)|
/\*[^*]*\*+([^/*][^*]*\*+)*/\//[^\n]*
ЅРЯаШЬХа, РЭРЫЮУШзЭРп бваЮЪР Perl, ЧРЪЫозХЭЭРп Т РЯЮбваЮдл, ЭХ бвЮЫм ЭРУЫпФЭР, ЯЮбЪЮЫмЪг \\ Т ЭХЩ ЮЧЭРзРХв \, Р ЭХ \\. ґЫп ЯЮбваЮХЭШп гФЮСЮзШвРХЬле аХУгЫпаЭле ТлаРЦХЭШЩ Т Perl бгйХбвТгов ФагУШХ баХФбвТР. Іл гСХФШвХбм Т нвЮЬ, ЪЮУФР Ьл ТХаЭХЬбп Ъ нвЮЬг ЯаШЬХаг Т УЫРТХ 7 (б. <$R[P#,R7-7]>).

АШб. 5.9. ІлШУали Юв аРЧЫШзЭле бЯЮбЮСЮТ ЮЯвШЬШЧРжШШ
ЅРШСЮЫмиШЩ ТлШУали ЯЮ СлбваЮФХЩбвТШо Т ЬХеРЭШЧЬХ Ѕє°, ТХаЮпвЭЮ, ФЮбвШУРХвбп ТбХ ЦХ ЭХ ЯаШХЬРЬШ ЮСйХЩ ЮЯвШЬШЧРжШШ, Р вйРвХЫмЭлЬ ЯЮбваЮХЭШХЬ ТлаРЦХЭШп б гзХвЮЬ вЮУЮ, звЮ ЭгЦЭЮ Ш ЭХ ЭгЦЭЮ ФХЫРвм ФЫп ФЮбвШЦХЭШп ЯЮбвРТЫХЭЭЮЩ жХЫШ. єЮЭХзЭЮ, ЯаШ нвЮЬ ЭХЮСеЮФШЬЮ еЮаЮиЮ ЧЭРвм, ЪРЪ ЬХеРЭШЧЬ Ѕє° СгФХв ФХЩбвТЮТРвм ФЫп аХиХЭШп ЯЮбвРТЫХЭЭЮЩ ЧРФРзШ.
АРббЬЮваШЬ ЯаШЬХа, б ЪЮвЮалЬ п ЭХФРТЭЮ бвЮЫЪЭгЫбп ЯаШ аРСЮвХ Т Emacs (Т нвЮЩ ЯаЮУаРЬЬХ ШбЯЮЫмЧгХвбп ваРФШжШЮЭЭлЩ ЬХеРЭШЧЬ Ѕє°). П еЮвХЫ, звЮСл аХУгЫпаЭЮХ ТлаРЦХЭШХ ЭРеЮФШЫЮ бЮЪаРйХЭШп вШЯР «don’t», «I’m», «we’ll» Ш в. Ф., ЭЮ ЭХ бЮТЯРФРЫЮ Т ФагУШе бШвгРжШпе. Г ЬХЭп ЯЮЫгзШЫЮбм аХУгЫпаЭЮХ ТлаРЦХЭШХ, Т ЪЮвЮаЮЬ ЧР ЮСЮЧЭРзХЭШХЬ бЫЮТР [\<\w+] бЫХФЮТРЫ Emacs-нЪТШТРЫХЭв ТлаРЦХЭШп ['([tdm]|re|ll|ve)]. НвЮ аХиХЭШХ аРСЮвРЫЮ, ЭЮ п ТФагУ ЯЮЭпЫ, звЮ ШбЯЮЫмЧЮТРвм [\<\w+] УЫгЯЮ — ТЯЮЫЭХ ФЮбвРвЮзЭЮ \w. ІХФм ХбЫШ РЯЮбваЮдг ЭХЯЮбаХФбвТХЭЭЮ ЯаХФиХбвТгХв \w, вЮ Ш \w+ вРЬ ЧРТХФЮЬЮ ЯаШбгвбвТгХв; ЫШиЭпп ЯаЮТХаЪР ЭХ ФЮСРТШв ЭШЪРЪЮЩ ЭЮТЮЩ ШЭдЮаЬРжШШ, ХбЫШ ЭРб ЭХ ШЭвХаХбгов вЮзЭлХ УаРЭШжл бЮТЯРФХЭШп (Р ЬХЭп ЮЭШ ЭХ ШЭвХаХбЮТРЫШ — п еЮвХЫ ЫШим ЭРЩвШ бваЮЪг). ёбЯЮЫмЧЮТРЭШХ \w гбЪЮаШЫЮ аРСЮвг ТлаРЦХЭШп СЮЫХХ зХЬ Т 10 аРЧ.
ґЮЯгбвШЬ, Тл бЮСШаРХвХбм ШбЯЮЫмЧЮТРвм ТлаРЦХЭШХ<$M[R5-10]>
[\bchar\b|\bconst\b|\bdouble\b…\bsigned\b|\bunsigned\b|\bwhile\b]
ФЫп ЯЮШбЪР бваЮЪ, бЮФХаЦРйШе ЪЫозХТлХ бЫЮТР пЧлЪР C. Б вЮзЪШ ЧаХЭШп аХУгЫпаЭле ТлаРЦХЭШЩ ЪЮЭбвагЪжШп ТлСЮаР ЮСеЮФШвбп ФЮаЮУЮ — ЪРЦФРп РЫмвХаЭРвШТР ШйХвбп Т ЪРЦФЮЩ ЯЮЧШжШШ бваЮЪШ ФЮ вХе ЯЮа, ЯЮЪР ЭХ СгФХв ЭРЩФХЭЮ бЮТЯРФХЭШХ.
Б ФагУЮЩ бвЮаЮЭл, ХбЫШ Сл аХУгЫпаЭЮХ ТлаРЦХЭШХ бЮбвЮпЫЮ вЮЫмЪЮ ШЧ ЮФЭЮУЮ бЫЮТР (ЭРЯаШЬХа, [\bchar\b]), Ьл ЬЮУЫШ Сл ТЮбЯЮЫмЧЮТРвмбп ЮЯвШЬШЧРжШХЩ ЯаЮТХаЪШ дШЪбШаЮТРЭЭле бваЮЪ (б. <$R[P#,R5-13]>), звЮСл СлбваЮ ЯаЮбЪРЭШаЮТРвм бваЮЪг Т ЯЮШбЪРе ЮФЭЮУЮ бЮТЯРФХЭШп. БХаШп ШЧ ЭХбЪЮЫмЪШе нЫХЬХЭвРаЭле ЯаЮТХаЮЪ зРбвЮ ТлЯЮЫЭпХвбп СлбваХХ, зХЬ ЮФЭР СЮЫмиРп ЯаЮТХаЪР.
ЗвЮСл ЯаЮФХЬЮЭбваШаЮТРвм бЪРЧРЭЭЮХ ЭР ЪЮЭЪаХвЭЮЬ ЯаШЬХаХ, п ЭРЯШбРЫ ЪЮаЮвЪШЩ бжХЭРаШЩ Perl ФЫп ЯЮФбзХвР бваЮЪ Т ШбеЮФЭЮЬ вХЪбвХ Perl, бЮФХаЦРйШе нвШ ЪЫозХТлХ бЫЮТР. ѕФЭР ТХабШп ТлУЫпФШв вРЪ<$M[R5-18]>:
$count = 0;
while (<>)
{
$count++ if m< \bchar\b
| \bconst\b
| \bdouble\b
…
| \bsigned\b
| \bunsigned\b
| \bwhile\b >x;
}
І нвЮЬ ЯаШЬХаХ ШбЯЮЫмЧгХвбп ЮбЮСРп ТЮЧЬЮЦЭЮбвм Perl, ЮСХбЯХзШТРойРп ЯаЮШЧТЮЫмЭго аРббвРЭЮТЪг ЯаЮЯгбЪЮТ Т аХУгЫпаЭле ТлаРЦХЭШпе (ЪаЮЬХ ЪЫРббЮТ). І ФЫШЭЭЮЩ, ЬЭЮУЮбваЮзЭЮЩ ЪЮЭбвагЪжШШ [m<…>x] ТбХ бШЬТЮЫл, ЧР ШбЪЫозХЭШХЬ ЯаЮЯгбЪЮТ, бЮбвРТЫпов ЮФЭЮ аХУгЫпаЭЮХ ТлаРЦХЭШХ (б ЬЭЮУШЬШ РЫмвХаЭРвШТРЬШ). ґагУЮЩ вХбвЮТлЩ бжХЭРаШЩ ТлУЫпФШв вРЪ[7]:
$count = 0;
while (<>) {
$count++, next if m/\bchar\b/;
$count++, next if m/\bconst\b/;
$count++, next if m/\bdouble\b/;
…
$count++, next if m/\bsigned\b/;
$count++, next if m/\bunsigned\b/;
$count++, next if m/\bwhile\b/;
}
ѕСХ ТХабШШ ТлФРов ЮФШЭРЪЮТлХ аХЧгЫмвРвл, ЭЮ ТвЮаРп аРСЮвРХв ЯаШЬХаЭЮ Т иХбвм аРЧ СлбваХХ. І ЭХЩ ШбЪЫозРХвбп СЮЫмиШЭбвТЮ ЧРваРв, бТпЧРЭЭле б ТЮЧТаРвЮЬ, ТФЮСРТЮЪ Ъ ЪРЦФЮЬг ЮвФХЫмЭЮЬг бЮТЯРФХЭШо ЬЮУгв Слвм ЯаШЬХЭХЭл ТЭгваХЭЭШХ ЮЯвШЬШЧРжШШ.
ІЯаЮзХЬ, Ш нвЮ ХйХ ЭХ ТбХ. єРЪ гЯЮЬШЭРЫЮбм ЭР б. <$R[P#,R5-14]>, GNU Emacs<$M[R5-19]> ЮзХЭм еЮаЮиЮ ТлЯЮЫЭпХв ЮЯвШЬШЧРжШо ШбЪЫозХЭШп ЯЮ ЯХаТЮЬг бШЬТЮЫг — УЮаРЧФЮ ЫгзиХ, зХЬ Perl, Tcl, Python ШЫШ ЫоСРп ФагУРп ШЧТХбвЭРп ЬЭХ ЯаЮУаРЬЬР б ЬХеРЭШЧЬЮЬ Ѕє°. їаШ ЭРЫШзШШ ЭХбЪЮЫмЪШе РЫмвХаЭРвШТ ЯЮФбШбвХЬР бЬХйХЭШп вХЪгйХЩ ЯЮЧШжШШ ЧЭРХв, звЮ аХУгЫпаЭЮХ ТлаРЦХЭШХ бЫХФгХв ЯаШЬХЭпвм ЫШим Т ЯЮЧШжШпе, бЮТЯРФРойШе б [[cdsuw]], ЯЮбЪЮЫмЪг РЫмвХаЭРвШТл ЬЮУгв ЭРзШЭРвмбп вЮЫмЪЮ б нвШе бШЬТЮЫЮТ (вЮзЭХХ, ФЫп ЯЮЫЭле, ЭХ ЯаШТХФХЭЭле ТлиХ ФРЭЭле вХбвР, ШбЯЮЫмЧгХвбп ЪЫРбб [[cdfinrsuw]]). ёЧСРТЫппбм Юв ЭХЮСеЮФШЬЮбвШ ЯаШЬХЭХЭШп ТбХУЮ ЬХеРЭШЧЬР Т ЪРЦФЮЩ ЯЮЧШжШШ, ЬЮЦЭЮ ФЮСШвмбп бгйХбвТХЭЭЮУЮ ТлШУалиР. µбЫШ Сл аХУгЫпаЭЮХ ТлаРЦХЭШХ ЭРзШЭРЫЮбм б [.*] ШЫШ ФагУЮЩ ЪЮЭбвагЪжШШ, ШЧ-ЧР ЪЮвЮаЮЩ бЮТЯРФХЭШХ ЬЮЦХв ЭРзШЭРвмбп б ЯаЮШЧТЮЫмЭЮУЮ бШЬТЮЫР, ТЮЧЬЮЦЭЮбвм ЮЯвШЬШЧРжШШ СлЫР Сл гваРзХЭР, ЮФЭРЪЮ Т ЭРиХЬ ЯаШЬХаХ ЮЭР ФХЩбвТгХв: Т вЮЩ ЦХ бХаШШ вХбвЮТ ФЫп Emacs ТХабШп б ЭХбЪЮЫмЪШЬШ РЫмвХаЭРвШТРЬШ аРСЮвРХв Т 3,8 аРЧР СлбваХХ ТХабШШ б ЭХбЪЮЫмЪШЬШ аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ.
ЅЮ Ш нвЮ ХйХ ЭХ ТбХ. єРЪ гЯЮЬШЭРЫЮбм Т аРЧФХЫХ «єниШаЮТРЭШХ ЯаШ ЪЮЬЯШЫпжШШ» (б. <$R[P#,R5-15]>), Emacs ЪниШагХв вЮЫмЪЮ Япвм аХУгЫпаЭле ТлаРЦХЭШЩ, ШбЯЮЫмЧЮТРТиШебп ЯЮбЫХФЭШЬШ. І ТХабШШ б ЭХбЪЮЫмЪШЬШ аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ ШЧ-ЧР ЯаЮТХаЪШ ЪРЦФЮУЮ бЫЮТР ЮвФХЫмЭлЬ аХУгЫпаЭлЬ ТлаРЦХЭШХЬ (Т ЬЮХЬ вХбвХ Ше СлЫЮ 14) Ъни бвРЭЮТШвбп ЯаРЪвШзХбЪШ СХбЯЮЫХЧЭлЬ. ГТХЫШзХЭШХ ХУЮ аРЧЬХаР ФЮ ТХЫШзШЭл, ЯЮЧТЮЫпойХЩ ЪниШаЮТРвм ТбХ аХУгЫпаЭлХ ТлаРЦХЭШп, ЯаШТЮФШв Ъ ваЮХЪаРвЭЮЬг ЯЮТлиХЭШо бЪЮаЮбвШ! І аХЧгЫмвРвХ ТХабШп б ЭХбЪЮЫмЪШЬШ аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ аРСЮвРХв гЦХ ЭХ Т 3,8, Р ТбХУЮ Т 1,4 аРЧР ЬХФЫХЭЭХХ, СЮЫХХ аХРЫмЭЮ ФХЬЮЭбваШагп ТЮЧЬЮЦЭЮбвШ ШбЪЫозХЭШп ЯЮ ЯХаТЮЬг бШЬТЮЫг Т Emacs.
єбвРвШ УЮТЮап, гзвШвХ, звЮ баРТЭХЭШХ нвШе ФТге ТХабШЩ (б ЭХбЪЮЫмЪШЬШ РЫмвХаЭРвШТРЬШ Ш ЭХбЪЮЫмЪШЬШ аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ) ТЮЧЬЮЦЭЮ ЫШим ЯЮвЮЬг, звЮ ЭРб ШЭвХаХбгХв ЭРЫШзШХ бЮТЯРФХЭШп, Р ЭХ ХУЮ вЮзЭлХ УаРЭШжл. їаЮбвЮХ ТлаРЦХЭШХ вШЯР [char|const|…] ЭРеЮФШв ЯХаТЮХ бЫЮТЮ Т бваЮЪХ (ЭХЧРТШбШЬЮ Юв ЯЮапФЪР бЫХФЮТРЭШп РЫмвХаЭРвШТ Т бЯШбЪХ), Р ЮвФХЫмЭлХ ЯаЮТХаЪШ ЮСЭРагЦШТРов ЯХаТЮХ бЫЮТЮ Т бЯШбЪХ (ЭХЧРТШбШЬЮ Юв ХУЮ ЯЮЫЮЦХЭШп Т бваЮЪХ). ЅР бРЬЮЬ ФХЫХ нвЮ ЮУаЮЬЭРп аРЧЭШжР, ЭЮ Ьл ЧЭРХЬ, звЮ Т ФРЭЭЮЬ ЯаШЬХаХ ЮЭР ЭХбгйХбвТХЭЭР.
їаЮФЮЫЦРп ФХЩбвТЮТРвм Т вЮЬ ЦХ ЭРЯаРТЫХЭШШ, ЭЮ вЮЫмЪЮ ТагзЭго, ЬЮЦЭЮ ЯЮЯлвРвмбп ТлЭХбвШ ЮСйШЩ ЯаХдШЪб ЪРЦФЮЩ РЫмвХаЭРвШТл ЯХаХФ ЪЮЭбвагЪжШХЩ ТлСЮаР — ЯЮ РЭРЫЮУШШ б ЯаХЮСаРЧЮТРЭШХЬ [this|that|thespcother] Т [th(is|at|espcother)], Ю ЪЮвЮаЮЬ УЮТЮаШЫЮбм ТлиХ. ВРЪЮХ ШЧЬХЭХЭШХ ЯХаХФРХв гЯаРТЫХЭШХ ЮвЭЮбШвХЫмЭЮ ЬХФЫХЭЭЮЩ ЪЮЭбвагЪжШШ ТлСЮаР ЫШим ЯЮбЫХ бЮТЯРФХЭШп [th], ФРЦХ Т вЮЬ бЫгзРХ, ХбЫШ ШбЪЫозХЭШХ ЯЮ ЯХаТЮЬг бШЬТЮЫг ЭХ ШбЯЮЫмЧгХвбп. єаЮЬХ вЮУЮ, ЯаШ нвЮЬ ЯЮпТЫпХвбп ЮСйРп дШЪбШаЮТРЭЭРп бваЮЪР «th», еЮаЮиЮ ЯЮФеЮФпйРп ФЫп ЮЯвШЬШЧРжШШ ЯаЮТХаЪШ дШЪбШаЮТРЭЭле бваЮЪ. І аХЧгЫмвРвХ ФЮбвШУРХвбп ФЮТЮЫмЭЮ бгйХбвТХЭЭлЩ ТлШУали. І ЯаШЬХаХ б ЪЫозХТлЬШ бЫЮТРЬШ C нвЮ ЮЧЭРзРХв ТлЭХбХЭШХ ЯаХдШЪбР [\b], б ЪЮвЮаЮУЮ ЭРзШЭРХвбп ЪРЦФРп РЫмвХаЭРвШТР, Т ЭРзРЫЮ аХУгЫпаЭЮУЮ ТлаРЦХЭШп: [\b(char\b|const\b|…)]. їаШ ЯаЮТХФХЭШШ вХбвЮТ ЭР Perl ЯЮбЫХ нвЮУЮ ЯаЮбвЮУЮ ШЧЬХЭХЭШп ТлаРЦХЭШХ бвРЫЮ аРСЮвРвм ЯЮзвШ вРЪ ЦХ СлбваЮ, ЪРЪ ЯаШ аРЧФХЫмЭЮЩ ЯаЮТХаЪХ, Ю ЪЮвЮаЮЩ УЮТЮаШЫЮбм ТлиХ.
НвЮв ЯаШЭжШЯ ЬЮЦХв ШбЯЮЫмЧЮТРвмбп ЧР ЯаХФХЫРЬШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, б ШбЯЮЫмЧЮТРЭШХЬ ФагУШе ЮЯХаРвЮаЮТ пЧлЪР. ЅРЯаШЬХа:
/this/ || /that/ || /the other/
|| ЧР ЯаХФХЫРЬШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп ЮЧЭРзРХв «ШЫШ». АХУгЫпаЭлХ ТлаРЦХЭШп СгФгв ЯЮбЫХФЮТРвХЫмЭЮ ЯаЮТХапвмбп ФЮ вХе ЯЮа, ЯЮЪР ЮФЭЮ ШЧ ЭШе ЭХ бЮТЯРФХв, Ш Т нвЮв ЬЮЬХЭв ЮСаРСЮвЪР ТбХЩ ЪЮЭбвагЪжШШ …||…||… ЯаХЪаРйРХвбп. ІбХ ЯЮбЫХФбвТШп ЯХаТЮУЮ бЮТЯРФХЭШп ЯаШ нвЮЬ ЮбвРовбп Т бШЫХ.
ёвРЪ, аРЧЬлиЫХЭШп Ш ЫЮУШЪР ЯЮЬЮУгв ТРЬ ЯаЮЩвШ СЮЫмиго зРбвм ЯгвШ Ъ нддХЪвШТЭЮЬг ЯаЮУаРЬЬШаЮТРЭШо — ЭЮ ЭХ ТХбм Ягвм. ЅРЯаШЬХа, СХЧ вХбвШаЮТРЭШп ЭР Perl ЯаШЬХаР б ЪЫозХТлЬШ бЫЮТРЬШ C п ЬЮУ Сл гвТХаЦФРвм, звЮ ЫоСЮЩ ШЧ Слбвале ЬХвЮФЮТ аРСЮвРХв СлбваХХ ЬХФЫХЭЭЮУЮ, ЭЮ ТапФ ЬЭХ гФРЫЮбм Сл бЪРЧРвм, ЪРЪЮЩ ШЧ Слбвале ЬХвЮФЮТ аРСЮвРХв СлбваХХ. ІЮЧЬЮЦЭЮ, ШЧ-ЧР ЪРЪЮЩ-ЭШСгФм ТЭгваХЭЭХЩ ЮЯвШЬШЧРжШШ Т бЫХФгойХЩ ТХабШШ Perl ШЫШ ШЧ-ЧР вЮУЮ, звЮ п ТЮбЯЮЫмЧгобм ФЫп вХбвШаЮТРЭШп ФагУЮЩ ЯаЮУаРЬЬЮЩ, бРЬлЬ СлбвалЬ ЮЪРЦХвбп ФагУЮЩ ЬХвЮФ.
[1] П аРСЮвРо ЭР IBM ThinkPad 755CX б ЯаЮжХббЮаЮЬ Pentium 75 јУж Ш ЮЯХаРжШЮЭЭЮЩ бШбвХЬЮЩ Linux. їаШТХФХЭЭЮХ ТаХЬп ТлзШбЫХЭЮ ЭР ЮбЭЮТРЭШШ ФагУШе нвРЫЮЭЭле вХбвЮТ; п ЭХ ЯаЮТХапЫ ХУЮ ЭР ЯаРЪвШЪХ.
[2] ґЫп ЫоСЮЧЭРвХЫмЭле: ЪЮЫШзХбвТЮ ТЮЧТаРвЮТ, ТлЯЮЫЭпХЬле ФЫп бваЮЪШ ФЫШЭл n, аРТЭЮ 2n+1. єЮЫШзХбвТЮ ЯаЮТХаЮЪ аРТЭЮ 2n+1+2n.
[3] єЮЭбвагЪжШп ЮЯХаХЦРойХЩ ЯаЮТХаЪШ Т Perl ШЬХХв ТШФ [(?=…)]. БЫХФЮТРвХЫмЭЮ, звЮСл ЯаЮТХаШвм ЯаШбгвбвТШХ [['"]], Ьл ФЮЫЦЭл ТбвРТШвм Т ЭРзРЫЮ ТлаРЦХЭШп [(?=['"])]. І аХЧгЫмвРвХ вХбвШаЮТРЭШп нвЮУЮ ЯаШЬХаР ЭР аРЧЭле ФРЭЭле п ЮСЭРагЦШЫ, звЮ ФЮЯЮЫЭШвХЫмЭРп ЯаЮТХаЪР гЬХЭмиРХв ТаХЬп ТлЯЮЫЭХЭШп ЭР 20 – 30 ЯаЮжХЭвЮТ. І ЯаШЬХаХ б ЬХбпжРЬШ, ЮЯШбРЭЭЮЬ ЭШЦХ, ФЮСРТЫХЭШХ [(?=[ADFJMNOS])] гбЪЮаШЫЮ аРСЮвг ЭР жХЫле 60 ЯаЮжХЭвЮТ.
[4] ІЯаЮзХЬ, нвЮ ЬЮЦХв Слвм Ш ЬХеРЭШЧЬ Ѕє° б ЮЯвШЬШЧРжШХЩ, ЪЮвЮаго п ЭХ ЯаХФгбЬЮваХЫ.
[5] јЭЮУШХ ЬХеРЭШЧЬл Ѕє° ЧРЯаХйРов ЪЮЭбвагЪжШо [(x*y*)*], ШбЯЮЫмЧЮТРЭЭго Т нвЮЬ ТлаРЦХЭШШ. їЮбЪЮЫмЪг ТЭгваХЭЭХХ ТлаРЦХЭШХ ЬЮЦХв бЮТЯРФРвм б ЯгбвЮЩ бваЮЪЮЩ, ТЭХиЭШЩ ЪТРЭвШдШЪРвЮа ЬЮЦХв «ЭХЬХФЫХЭЭЮ» ЭРЩвШ ФЫп ЭХХ СХбЪЮЭХзЭЮХ зШбЫЮ бЮТЯРФХЭШЩ. ґагУШХ ЯаЮУаРЬЬл (ЭРЯаШЬХа, Emacs Ш бЮТаХЬХЭЭлХ ТХабШпШ Perl) б зХбвмо ТлеЮФпв ШЧ ЧРвагФЭШвХЫмЭЮЩ бШвгРжШШ. Python ЯаХбЯЮЪЮЩЭЮ бЮЮСйРХв Ю ЭХгФРзЭЮЬ ЯЮШбЪХ ТбХе ТлаРЦХЭШЩ, Т ЪЮвЮале ТбваХзРХвбп нвР ЪЮЭбвагЪжШп.
[6] ІЮЮСйХ-вЮ Т Perl ТХабШШ 5 нвР ТЮЧЬЮЦЭЮбвм аХРЫШЧгХвбп ЯаШ ЯЮЬЮйШ ЪЮЭбвагЪжШШ ЭХУРвШТЭЮУЮ ЮЯХаХЦХЭШп (?!…), ЭЮ ЯЮбЪЮЫмЪг ЮЭР ЮвЭЮбШвбп Ъ бЯХжШдШЪХ Perl, Ьл аРббЬЮваШЬ ХХ Т УЫРТХ 7 (б. <$R[P#,R7-8]>).
[7] І Perl ЪЮЭбвагЪжШп:
ЪЮЬРЭФР, next if гбЫЮТШХ;
ЯаХФбвРТЫпХв бЮСЮЩ аРбЯаЮбваРЭХЭЭго Ш ЯЮЫХЧЭго ШФШЮЬг, ЪЮвЮаРп ЮЧЭРзРХв бЫХФгойХХ:
if (гбЫЮТШХ) {
ЪЮЬРЭФР;
next # ЅРзРвм бЫХФгойго ШвХаРжШо ТЭХиЭХУЮ жШЪЫР
}