АХУгЫпаЭлХ ТлаРЦХЭШп Т Perl
Perl зРбвЮ гЯЮЬШЭРХвбп ЭР бваРЭШжРе ЪЭШУШ, Ш ЭХ СХЧ ЮбЭЮТРЭШЩ. НвЮ ЯЮЯгЫпаЭлЩ пЧлЪ, ЮСЫРФРойШЩ ШбЪЫозШвХЫмЭЮ СЮУРвлЬШ ТЮЧЬЮЦЭЮбвпЬШ Т ЮСЫРбвШ аХУгЫпаЭле ТлаРЦХЭШЩ, СХбЯЫРвЭлЩ Ш ФЮбвгЯЭлЩ, ЯЮЭпвЭлЩ ФЫп ЭРзШЭРойШе Ш бгйХбвТгойШЩ ЭР ЬЭЮЦХбвТХ ЯЫРвдЮаЬ, Т вЮЬ зШбЫХ Amiga, DOS, MacOS, NT, OS/2, Windows, VMS Ш ЯаРЪвШзХбЪШ ТбХе аРЧЭЮТШФЭЮбвпе Unix.
ЅХЪЮвЮалХ ЯаЮУаРЬЬЭлХ ЪЮЭбвагЪжШШ Perl ЭРЯЮЬШЭРов C Ш ФагУШХ ваРФШжШЮЭЭлХ пЧлЪШ ЯаЮУаРЬЬШаЮТРЭШп, ЭЮ ЭР нвЮЬ ТбХ беЮФбвТЮ Ш ЪЮЭзРХвбп. їЮФеЮФ Ъ аХиХЭШо ЧРФРз ЭР Perl — їгвм Perl — бШЫмЭЮ ЮвЫШзРХвбп Юв ваРФШжШЮЭЭле пЧлЪЮТ. І Perl-ЯаЮУаРЬЬРе зРбвЮ ШбЯЮЫмЧговбп ваРФШжШЮЭЭлХ ЪЮЭжХЯжШШ бвагЪвгаЭЮУЮ Ш ЮСкХЪвЭЮ-ЮаШХЭвШаЮТРЭЭЮУЮ ЯаЮУаРЬЬШаЮТРЭШп, ЭЮ ЮСаРСЮвЪР ФРЭЭле ЮзХЭм бШЫмЭЮ ЧРТШбШв Юв аХУгЫпаЭле ТлаРЦХЭШЩ. І бгйЭЮбвШ, ЬЮЦЭЮ СХЧ ЯаХгТХЫШзХЭШп ЧРпТШвм, звЮ аХУгЫпаЭлХ ТлаРЦХЭШп ШУаРов ЪЫозХТго аЮЫм ЯаРЪвШзХбЪШ Т ЫоСЮЩ Perl-ЯаЮУаРЬЬХ. НвЮ гвТХаЦФХЭШХ бЯаРТХФЫШТЮ ЪРЪ ФЫп УШУРЭвбЪЮЩ бШбвХЬл ШЧ 100 000 бваЮЪ, вРЪ Ш ФЫп ЯаЮбвле ЮФЭЮбваЮзЭле ЯаЮУаРЬЬ вШЯР:
% perl -pi -e 's{([-+]?\d+(\.\d*)?)F\b}{sprintf "%.0fC",($1-32) * 5/9)eg' *.txt
НвР ЯаЮУаРЬЬР ЯаЮбЬРваШТРХв дРЩЫл *.txt Ш ЯаХЮСаРЧгХв вХЬЯХаРвгаг ШЧ иЪРЫл ДРаХЭУХЩвР Т иЪРЫг ЖХЫмбШп (ТбЯЮЬЭШвХ ЯХаТлЩ ЯаШЬХа ШЧ УЫРТл 2).
І нвЮЩ УЫРТХ аРббЬРваШТРовбп ЯаРЪвШзХбЪШ ТбХ РбЯХЪвл аХУгЫпаЭле ТлаРЦХЭШЩ Т пЧлЪХ Perl — Т ЭХЩ Тл ЭРЩФХвХ ШЭдЮаЬРжШо Ю ФШРЫХЪвХ Ш ЮЯХаРвЮаРе, ЯаХФЭРЧЭРзХЭЭле ФЫп аРСЮвл б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ. јРвХаШРЫ ШЧЫРУРХвбп б ЯаЮбвХЩиХУЮ гаЮТЭп, ЭЮ п ЯаХФЯЮЫРУРо, звЮ Тл ЯЮ ЪаРЩЭХЩ ЬХаХ Т ЮСйШе зХавРе ЧЭРЪЮЬл б Perl (ЯЮбЫХ звХЭШп УЫРТл 2, ТХаЮпвЭЮ, ТРиШе ЯЮЧЭРЭШЩ еТРвШв еЮвп Сл ЭР вЮ, звЮСл ЯаШбвгЯШвм Ъ звХЭШо нвЮЩ УЫРТл). П зРбвЮ ЬШЬЮеЮФЮЬ ШбЯЮЫмЧго ЪЮЭжХЯжШШ, ЪЮвЮалХ ХйХ ЯЮФаЮСЭЮ ЭХ аРббЬРваШТРЫШбм Т вХЪбвХ, Ш ЭХ СгФг ЯЮФЮЫУг ЧРФХаЦШТРвмбп ЭР РбЯХЪвРе пЧлЪР, ЭХ ШЬХойШе ЯапЬЮУЮ ЮвЭЮиХЭШп Ъ аХУгЫпаЭлЬ ТлаРЦХЭШпЬ. ІЮЧЬЮЦЭЮ, ТРЬ бвЮШв ФХаЦРвм ЯЮФ агЪЮЩ агЪЮТЮФбвТЮ ЯЮ Perl.
ѕФЭРЪЮ ЯЮЧЭРЭШп Т ЮСЫРбвШ Perl — ЭХ УЫРТЭЮХ. ІХаЮпвЭЮ, ХйХ ТРЦЭХХ ТРиХ бваХЬЫХЭШХ гЧЭРвм СЮЫмиХ. НвР УЫРТР ЭШ Т ЪЮХЬ бЫгзРХ ЭХ пТЫпХвбп «ЫХУЪШЬ звШТЮЬ». їЮбЪЮЫмЪг п ЭХ бЮСШаРобм гзШвм ТРб Perl б бРЬЮУЮ ЭРзРЫР, г ЬХЭп ЯЮпТЫпХвбп ТЮЧЬЮЦЭЮбвм, ЪЮвЮаЮХ ЭХв г РТвЮаЮТ ЮСйШе гзХСЭШЪЮТ Perl — ЬЭХ ЭХ ЯаШФХвбп ЮЯгбЪРвм ТРЦЭлХ ФХвРЫШ, звЮСл ФЮСШвмбп бТпЧЭЮУЮ ЯЮТХбвТЮТРЭШп, ЯЫРТЭЮ аРЧТЮаРзШТРойХУЮбп ЭР ЯаЮвпЦХЭШШ ТбХЩ УЫРТл. µбЫШ звЮ Ш ЮбвРХвбп ЯЮбвЮпЭЭлЬ, вРЪ нвЮ бваХЬЫХЭШХ Ъ ЯЮЭШЬРЭШо ЮСйХЩ ЪРавШЭл. ЅХЪЮвЮалХ ЯаЮСЫХЬл ФЮТЮЫмЭЮ бЫЮЦЭл Ш ЧРУаЮЬЮЦФХЭл ЮСШЫШХЬ ФХвРЫХЩ. ЅХ ЮУЮазРЩвХбм, ХбЫШ ТРЬ ЭХ гФРбвбп гбТЮШвм ТбХ баРЧг. П аХЪЮЬХЭФго ЮФШЭ аРЧ ЯаЮзШвРвм УЫРТг, звЮСл ЯЮЫгзШвм ЮСйХХ ЯаХФбвРТЫХЭШХ Ю вХЬХ, Р ЧРвХЬ ТЮЧТаРйРвмбп Ъ ЭХЩ Т СгФгйХЬ ЯЮ ЬХаХ ЭРФЮСЭЮбвШ.
єЮЭХзЭЮ, п Сл ЮзХЭм еЮвХЫ зХвЪЮ ЮвФХЫШвм ЮСбгЦФХЭШХ ФШРЫХЪвР аХУгЫпаЭле ТлаРЦХЭШЩ Юв ЮСбгЦФХЭШп Ше ЯаРЪвШзХбЪЮУЮ ЯаШЬХЭХЭШп, ЭЮ Т Perl нвШ ФТХ вХЬл ЭХаРЧалТЭЮ бТпЧРЭл. ЗвЮСл ЯЮЬЮзм ТРЬ аРЧЮСаРвмбп Т ЬРвХаШРЫХ, п ЯаШТХФг ЪаРвЪго бТЮФЪг ЯЮ бвагЪвгаХ нвЮЩ УЫРТл:
l І аРЧФХЫХ «їгвм Perl» ЯаШТХФХЭл ЮСйШХ бТХФХЭШп вЮУЮ, ЪРЪ Perl Ш аХУгЫпаЭлХ ТлаРЦХЭШп ТЧРШЬЮФХЩбвТгов ФагУ б ФагУЮЬ Ш б ЯаЮУаРЬЬШбвЮЬ. П ЯаШТХФг ЪЮаЮвЪШЩ ЯаШЬХа аХиХЭШп ЧРФРзШ Т бЮЮвТХвбвТШШ б їгвХЬ Perl Ш ЯаХФбвРТЫо ЭХЪЮвЮалХ ТРЦЭлХ ЪЮЭжХЯжШШ, ЪЮвЮалХ СгФгв бЭЮТР Ш бЭЮТР ТбваХзРвмбп Т нвЮЩ УЫРТХ — Р вРЪЦХ ЭР ЯаЮвпЦХЭШШ ТбХЩ ТРиХЩ аРСЮвл ЭР Perl.
l І аРЧФХЫХ «Perl’ШЧЬл ШЧ ЮСЫРбвШ аХУгЫпаЭле ТлаРЦХЭШЩ» (б. <$R[P#,R7-9]>) аРббЬРваШТРовбп ЭХЪЮвЮалХ РбЯХЪвл Perl, ШЬХойШХ ЮбЮСХЭЭЮ ТРЦЭЮХ ЧЭРзХЭШХ ФЫп аХУгЫпаЭле ТлаРЦХЭШЩ. ·ФХбм ЯЮФаЮСЭЮ РЭРЫШЧШаговбп вРЪШХ ЪЮЭжХЯжШШ, ЪРЪ ФШЭРЬШзХбЪРп ТШФШЬЮбвм, ЪЮЭвХЪбв ТлаРЦХЭШп Ш ШЭвХаЯЮЫпжШп, ЯаШ нвЮЬ ЮбЮСЮХ ТЭШЬРЭШХ гФХЫпХвбп Ше бТпЧШ б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ.
l І аРЧФХЫХ «ґШРЫХЪв аХУгЫпаЭле ТлаРЦХЭШЩ Perl» (б. <$R[P#,R7-10]>) ЮЯШбРЭл ЯаРЪвШзХбЪШХ бвЮаЮЭл аРСЮвл б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ, Т вЮЬ зШбЫХ ТбХ ШЭвХаХбЭлХ ЭЮТиХбвТР Perl ТХабШШ 5. ІЯаЮзХЬ, ТбХ нвШ ТЮЧЬЮЦЭЮбвШ еЮаЮиШ ЫШим Т бЮзХвРЭШШ бЮ баХФбвТРЬШ ФЫп Ше ЯаШЬХЭХЭШп. І аРЧФХЫРе «ѕЯХаРвЮа ЯЮШбЪР» (б. <$R[P#,R7-11]>), «ѕЯХаРвЮа ЯЮФбвРЭЮТЪШ» (б. <$R[P#,R7-12]>) Ш «ѕЯХаРвЮа аРЧСШХЭШп» (б. <$R[P#,R7-13]>) ЯЮФаЮСЭЮ ЮЯШбРЭл ТбХ ЮЯХаРвЮал аХУгЫпаЭле ТлаРЦХЭШЩ, ЪЮвЮалХ ЭХЯЮбТпйХЭЭлЬ зРбвЮ ЪРЦгвбп ЪРЪШЬ-вЮ ТЮЫиХСбвТЮЬ.
l АРЧФХЫ «їаЮСЫХЬл нддХЪвШТЭЮбвШ Т Perl» (б. <$R[P#,R7-6]>) ЧРваРУШТРХв вХЬг, СЫШЧЪго бХаФжг ЫоСЮУЮ ЯаЮУаРЬЬШбвР. І Perl ШбЯЮЫмЧгХвбп ваРФШжШЮЭЭлЩ ЬХеРЭШЧЬ Ѕє°, ЯЮнвЮЬг Тл ЬЮЦХвХ бЬХЫЮ ЭРзШЭРвм нЪбЯХаШЬХЭвл бЮ ТбХЬШ ЯаШХЬРЬШ, ЮЯШбРЭЭлЬШ Т УЫРТХ 5. єЮЭХзЭЮ, бгйХбвТгХв ЭХЬРЫЮ дРЪвЮаЮТ, бЯХжШдШзХбЪШе ФЫп Perl, бШЫмЭЮ ТЫШпойШе ЭР вЮ, ЪРЪ Ш ЭРбЪЮЫмЪЮ СлбваЮ ЯаШЬХЭповбп аХУгЫпаЭлХ ТлаРЦХЭШп Т Perl; нвШ дРЪвЮал СгФгв аРббЬЮваХЭл Т нвЮЬ аРЧФХЫХ.
l ЅРЪЮЭХж, аРЧФХЫ «ІбХ ТЬХбвХ» (б. <$R[P#,R7-14]>) ЧРТХаиРХв УЫРТг ЭХбЪЮЫмЪШЬШ ЯаШЬХаРЬШ, ЮСкХФШЭпойШЬШ ТбХ бЪРЧРЭЭЮХ Т ЮСйго ЪРавШЭг. єаЮЬХ вЮУЮ, Ьл ТХаЭХЬбп Ъ ЯаШЬХаг ШЧ аРЧФХЫР «їгвм Perl» Ш ЯХаХбЬЮваШЬ ХУЮ Т бТХвХ вЮУЮ, Ю зХЬ УЮТЮаШЫЮбм Т УЫРТХ. І ЯЮбЫХФЭХЬ ЯаШЬХаХ (ЯЮШбЪ РФаХбЮТ нЫХЪваЮЭЭЮЩ ЯЮзвл ёЭвХаЭХвР — б. <$R[P#,R7-15]>) СгФгв ЧРФХЩбвТЮТРЭл ЯаРЪвШзХбЪШ ТбХ ЯаШХЬл, ЪЮвЮалХ ЭРЬ ЧЭРЪЮЬл. ёвЮУЮТЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ бЮбвЮШв ЯЮзвШ ШЧ 5000 бШЬТЮЫЮТ, ЮФЭРЪЮ Тл аРЧСХаХвХбм Т ЭХЬ Ш ЯаШ ЭХЮСеЮФШЬЮбвШ бЬЮЦХвХ ЮваХФРЪвШаЮТРвм.
І вРСЫ. 7.1 ЯаШТХФХЭР ЪаРвЪРп бТЮФЪР ШбЪЫозШвХЫмЭЮ СЮУРвЮУЮ ФШРЫХЪвР аХУгЫпаЭле ТлаРЦХЭШЩ Perl. µбЫШ Тл вЮЫмЪЮ ЭРзШЭРХвХ аРСЮвРвм ЭР Perl, ЭЮ ШЬХХвХ ЮЯлв ШбЯЮЫмЧЮТРЭШп ФагУШе ЯаЮУаРЬЬ б ЯЮФФХаЦЪЮЩ аХУгЫпаЭле ТлаРЦХЭШЩ, ЬЭЮУШХ ЪЮЭбвагЪжШШ ЯЮЪРЦгвбп ЭХЧЭРЪЮЬлЬШ. ЅХЧЭРЪЮЬлЬШ, ФР — ЭЮ ЧРЬРЭзШТлЬШ! ІХаЮпвЭЮ, ФШРЫХЪв аХУгЫпаЭле ТлаРЦХЭШЩ Perl ЮСЫРФРХв ЭРШСЮЫмиШЬШ ТЮЧЬЮЦЭЮбвпЬШ ШЧ ТбХе бЮТаХЬХЭЭле ЯаЮУаРЬЬ. ЗвЮСл ТРиХ ЯЮЭШЬРЭШХ аХУгЫпаЭле ТлаРЦХЭШЩ Perl ЭХ СлЫЮ ЯЮТХаеЭЮбвЭлЬ, Тл ФЮЫЦЭл ЧЭРвм, звЮ Т Perl ШбЯЮЫмЧгХвбп ЬХеРЭШЧЬ Ѕє°. НвЮ ЮЧЭРзРХв, звЮ ТбХ бЪРЧРЭЭЮХ Ю Ѕє° Т ЯаХФлФгйШе УЫРТРе, Т аРТЭЮЩ бвХЯХЭШ ЮвЭЮбШвбп Ш Ъ Perl.
ЅЮ ЭХ ЮФЭШЬШ ЬХвРбШЬТЮЫРЬШ ЦШТ ЯаЮУаРЬЬШбв. АХУгЫпаЭлХ ТлаРЦХЭШп СХбЯЮЫХЧЭл, ХбЫШ Тл ЭХ аРбЯЮЫРУРХвХ баХФбвТРЬШ ФЫп Ше ЯаШЬХЭХЭШп. ІЯаЮзХЬ, Perl Ш ЧФХбм ТРб ЭХ ЯЮФТХФХв. І нвЮЩ ЮСЫРбвШ Perl, ЪРЪ ЮСлзЭЮ, бЫХФгХв бТЮХЬг ФХТШЧг: «Г ЪРЦФЮЩ ЧРФРзШ Хбвм ЭХбЪЮЫмЪЮ аХиХЭШЩ».
ВРСЫШжР 7.1. ПЧлЪ аХУгЫпаЭле ТлаРЦХЭШЩ Т Perl
|
. (вЮзЪР) |
ЫоСЮЩ СРЩв, ЪаЮЬХ бШЬТЮЫР ЭЮТЮЩ бваЮЪШ (б. <$R[P#,R7-16]>) ШЫШ РСбЮЫовЭЮ ЫоСЮЩ СРЩв б ЬЮФШдШЪРвЮаЮЬ /s[1] б. <$R[P#,R7-17]>) |
|
| |
ЪЮЭбвагЪжШп ТлСЮаР |
|
ЬРЪбШЬРЫмЭлХ ЪТРЭвШдШЪРвЮал |
|
|
* + ? {n} {ЬШЭ,} {ЬШЭ, ЬРЪб} |
БЬ. б. <$R[P#,R7-18]> |
|
ЬШЭШЬРЫмЭлХ ЪТРЭвШдШЪРвЮал[2] |
|
|
*? +? ?? {n}? {ЬШЭ,}? {ЬШЭ, ЬРЪб}? |
БЬ. б. <$R[P#,R7-19]> |
|
(…) |
ЮСлзЭлХ ЪагУЫлХ бЪЮСЪШ (УагЯЯШаЮТЪР Ш бЮеаРЭХЭШХ) |
|
(?:…) |
вЮЫмЪЮ УагЯЯШаЮТЪР (б. <$R[P#,R7-20]>) |
|
(?=…) |
ЯЮЧШвШТЭРп ЮЯХаХЦРойРп ЯаЮТХаЪР (б. <$R[P#,R7-1]>) |
|
(?!…) |
ЭХУРвШТЭРп ЮЯХаХЦРойРп ЯаЮТХаЪР (б. <$R[P#,R7-8]>) |
|
(?#…) |
ЪЮЬЬХЭвРаШЩ[3] (б. <$R[P#,R7-21]>) |
|
#… |
(б ЬЮФШдШЪРвЮаЮЬ /x, б. <$R[P#,R7-22]>) ЪЮЬЬХЭвРаШЩ[4] ФЮ ЪЮЭжР бваЮЪШ ШЫШ ТлаРЦХЭШп |
|
ТбваЮХЭЭлХ ЬЮФШдШЪРвЮал [5] (б. <$R[P#,R7-23]>) |
|
|
(?ЬЮФШдШЪРвЮал) |
ЬЮФШдШЪРвЮал i, x, m Ш s |
|
пЪЮаЭлХ ЬХвРбШЬТЮЫл |
|
|
\b[6] \B |
УаРЭШжР бЫЮТР/ЭХ УаРЭШжР бЫЮТР (б. <$R[P#,R7-24]>) |
|
^ $ |
ЭРзРЫЮ/ЪЮЭХж бваЮЪШ (ШЫШ ЭРзРЫЮ Ш ЪЮЭХж ЫЮУШзХбЪЮЩ бваЮЪШ) (б. <$R[P#,R7-25]>) |
|
\A \Z |
ЭРзРЫЮ/ЪЮЭХж бваЮЪШ[7] (б. <$R[P#,R7-26]>) |
|
\G |
ЪЮЭХж ЯаХФлФгйХУЮ бЮТЯРФХЭШп[8] (б. <$R[P#,R7-27]>) |
|
\1, \2 Ш в. Ф. |
вХЪбв, бЮТЯРТиШЩ б ЧРФРЭЭЮЩ ЯРаЮЩ ЪагУЫле бЪЮСЮЪ (б. <$M[R7-28]>) |
|
[…] [^…] |
бШЬТЮЫмЭлХ ЪЫРббл (ЭЮаЬРЫмЭлЩ Ш ШЭТХавШаЮТРЭЭлЩ). БЬ. б. <$R[P#,R7-29]>. |
|
(БЫХФгойШХ ЬХвРбШЬТЮЫл вРЪЦХ ФХЩбвТШвХЫмЭл ТЭгваШ бШЬТЮЫмЭле ЪЫРббЮТ) |
|
|
БЮЪаРйХЭЭлХ ЮСЮЧЭРзХЭШп бШЬТЮЫЮТ |
|
|
\b[9] \t \n \r \f \a \e \зШбЫЮ \xзШбЫЮ \ббШЬТЮЫ |
БЬ. б. <$R[P#,R7-30]> |
|
БЮЪаРйХЭЭлХ ЮСЮЧЭРзХЭШп ЪЫРббЮТ |
|
|
\w \W \s \S \d \D |
БЬ. б. <$R[P#,R7-30]> |
|
|
|
|
\l \u \L \U \Q[10] \E |
ѕЯХаРвШТЭЮХ ШЧЬХЭХЭШХ аХУШбваР бШЬТЮЫЮТ (б. <$R[P#,R7-31]>) |
ѕФЭЮЩ ШЧ ЯаШТЫХЪРвХЫмЭле зХав Perl пТЫпХвбп вЮ, звЮ ЯЮФФХаЦЪР аХУгЫпаЭле ТлаРЦХЭШЩ пТЫпХвбп ЭХЮвкХЬЫХЬЮЩ зРбвмо пЧлЪР. ІЬХбвЮ РТвЮЭЮЬЭле дгЭЪжШЩ ФЫп ЯаШЬХЭХЭШп аХУгЫпаЭле ТлаРЦХЭШЩ Perl ЯаХФЮбвРТЫпХв Т ТРиХ аРбЯЮапЦХЭШХ ЮЯХаРвЮал, ЧРЭШЬРойШХ ФЮЫЦЭЮХ ЬХбвЮ Т ЭРСЮаХ ФагУШе ЮЯХаРвЮаЮТ Ш бШЭвРЪбШзХбЪШе ЪЮЭбвагЪжШЩ, ЮСаРЧгойШе пЧлЪ Perl. І вРСЫ. 7.2 ЪаРвЪЮ ЯХаХзШбЫХЭл ЪЮЬЯЮЭХЭвл пЧлЪР, ШЬХойШХ ЭХЯЮбаХФбвТХЭЭЮХ ЮвЭЮиХЭШХ Ъ аХУгЫпаЭлЬ ТлаРЦХЭШпЬ.
ІЮЧЬЮЦЭЮ, Тл ЭШЪЮУФР ЭХ аРббЬРваШТРЫШ …=~ m/…/ ЪРЪ ЮЯХаРвЮа. ЅЮ ЯЮФЮСЭЮ вЮЬг, ЪРЪ ЮЯХаРвЮа бЫЮЦХЭШп + ЯЮЫгзРХв ФТР ЮЯХаРЭФР Ш ТЮЧТаРйРХв бгЬЬг, ЮЯХаРвЮа ЯЮШбЪР вРЪЦХ ЯЮЫгзРХв ФТР ЮЯХаРЭФР (аХУгЫпаЭЮХ ТлаРЦХЭШХ Ш жХЫХТго бваЮЪг) Ш ТЮЧТаРйРХв ЧЭРзХЭШХ. єРЪ гЯЮЬШЭРЫЮбм Т аРЧФХЫХ «ДгЭЪжШШ, ШЭвХУаШаЮТРЭЭлХ баХФбвТР Ш ЮСкХЪвл» УЫРТл 5 (б. <$R[P#,R5-20]>), УЫРТЭЮХ ЮвЫШзШХ ЬХЦФг дгЭЪжШХЩ Ш ЮЯХаРвЮаЮЬ ЧРЪЫозРХвбп Т вЮЬ, звЮ ЮЯХаРвЮа ЬЮЦХв ЮСаРСРвлТРвм бТЮШ ЮЯХаРЭФл ЮбЮСлЬ ЮСаРЧЮЬ, ЮСлзЭЮ ЭХФЮбвгЯЭлЬ ФЫп дгЭЪжШЩ[11]. єЮЭХзЭЮ, ЮЯХаРвЮал аХУгЫпаЭле ТлаРЦХЭШЩ Т Perl ТлУЫпФпв вРШЭбвТХЭЭЮ. ЅЮ ТбЯЮЬЭШвХ, звЮ п УЮТЮаШЫ Т УЫРТХ 1: Т дЮЪгбРе ЭХв ЭШзХУЮ ТЮЫиХСЭЮУЮ, ХбЫШ Тл ЯЮЭШЬРХвХ, звЮ ЯаШ нвЮЬ ЯаЮШбеЮФШв. НвР УЫРТР ЯЮЬЮЦХв ТРЬ аРЧЮСаРвмбп Т ЯаЮШбеЮФпйХЬ.
јХЦФг ЯЮЭпвШпЬШ аХУгЫпаЭЮХ ТлаРЦХЭШХ Ш аХУгЫпаЭЮХ ТлаРЦХЭШХ-ЮЯХаРЭФ бгйХбвТгов ЮЯаХФХЫХЭЭлХ ЮвЫШзШп. І бжХЭРаШШ ЧРФРовбп «блалХ» аХУгЫпаЭлХ ТлаРЦХЭШп-ЮЯХаРЭФл. Perl ЯЮФТХаУРХв Ше ЭХСЮЫмиЮЩ «ЯаХФТРаШвХЫмЭЮЩ ЮСаРСЮвЪХ» Ш ЯХаХФРХв аХЧгЫмвРв ЬХеРЭШЧЬг ЯЮШбЪР аХУгЫпаЭле ТлаРЦХЭШЩ. ІлЯЮЫЭпХЬлХ ЭР бвРФШШ ЯаХФТРаШвХЫмЭЮЩ ЮСаРСЮвЪШ ЮЯХаРжШШ РЭРЫЮУШзЭл (ЭЮ ЭХ ШФХЭвШзЭл!) вХЬ, ЪЮвЮалХ ТлЯЮЫЭпХвбп ФЫп бваЮЪ Т ЪРТлзЪРе. ґЫп ЯЮТХаеЭЮбвЭЮУЮ ЯЮЭШЬРЭШп нвШ аРЧЫШзШп ЭХбгйХбвТХЭЭл — ТЮв ЯЮзХЬг п СгФг ЮСкпбЭпвм Ш ЯЮФзХаЪШТРвм Ше ЯаШ ЪРЦФЮЩ ТЮЧЬЮЦЭЮбвШ!
їгбвм ЪаРвЪЮбвм бХЪжШШ «ѕЯХаРвЮал аХУгЫпаЭле ТлаРЦХЭШЩ» Т вРСЫ. 7.2 ТРб ЭХ бЬгйРХв. ±ЫРУЮФРап аРЧЭЮЮСаРЧЭлЬ ЯРаРЬХваРЬ Ш ЮбЮСлЬ бЫгзРпЬ ЯаШЬХЭХЭШп ЪРЦФлЩ ШЧ ваХе ЮЯХаРвЮаЮТ аХиРХв ЬЭЮУЮ ЧРФРз.
АРЧЭЮЮСаРЧШХ ТЮЧЬЮЦЭЮбвХЩ Ш ТлаРЧШвХЫмЭле баХФбвТ Т ЮЯХаРвЮаРе Ш дгЭЪжШпе, ТХаЮпвЭЮ, пТЫпХвбп бРЬЮЩ бШЫмЭЮЩ бвЮаЮЭЮЩ Perl. їЮТХФХЭШХ ЮЯХаРвЮаЮТ Ш дгЭЪжШЩ ШЧЬХЭпХвбп Т ЧРТШбШЬЮбвШ Юв ЪЮЭвХЪбвР, Т ЪЮвЮаЮЬ ЮЭШ ШбЯЮЫмЧговбп, Ш ФЮТЮЫмЭЮ зРбвЮ Т ЪРЦФЮЩ бЯХжШдШзХбЪЮЩ бШвгРжШШ ФХЫРХвбп ШЬХЭЭЮ вЮ, звЮ Ш ЯаХФЯЮЫРУРЫ ЯаЮУаРЬЬШбв. ЅРЯаШЬХа, ЮЯХаРвЮа ЯЮШбЪР m/ТлаРЦХЭШХ/ ЮСЫРФРХв ЬЭЮЦХбвТЮЬ аРЧЭле дгЭЪжШЮЭРЫмЭле ТЮЧЬЮЦЭЮбвХЩ Т ЧРТШбШЬЮбвШ Юв вЮУЮ, УФХ, ЪРЪ Ш б ЪРЪШЬШ ЬЮФШдШЪРвЮаРЬШ ЮЭ ШбЯЮЫмЧгХвбп. µУЮ УШСЪЮбвм ЯаЮбвЮ ЯЮаРЦРХв.
ВРСЫШжР 7.2. ѕСЧЮа бШЭвРЪбШбР Perl, ЮвЭЮбпйХУЮбп Ъ аРСЮвХ б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ
|
ѕЯХаРвЮал ФЫп аРСЮвл б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ |
|
|
m/ТлаРЦХЭШХ/ЬЮФШдШЪРвЮал[12] |
БЬ. б. <$R[P#,R7-11]> |
|
s/ТлаРЦХЭШХ/ЧРЬХЭР/ЬЮФШдШЪРвЮал[13] |
БЬ. б. <$R[P#,R7-12]> |
|
split(…) |
БЬ. б. <$R[P#,R7-13]> |
|
ІбЯЮЬЮУРвХЫмЭлХ ЯХаХЬХЭЭлХ |
|
|
$_ |
ЖХЫХТЮЩ вХЪбв ЯЮ гЬЮЫзРЭШо |
|
$* |
ГбвРаХТиШЩ ЬЭЮУЮбваЮзЭлЩ аХЦШЬ (б. <$R[P#,R7-32]>) |
|
ЬЮФШдШЪРвЮа (б. <$R[P#,R7-33]>) |
ІЫШпЭШХ |
|
/x[14] /o |
ёЭвХаЯаХвРжШп аХУгЫпаЭЮУЮ ТлаРЦХЭШп |
|
ёЭвХаЯаХвРжШп жХЫХТЮУЮ вХЪбвР |
|
|
/g /e |
їаЮзХХ |
|
їХаХЬХЭЭлХ б ШЭдЮаЬРжШХЩ Ю бЮТЯРФХЭШШ (б. <$R[P#,R7-34]>) |
|
|
$1, $2 Ш в. Ф. |
БЮеаРЭХЭЭлЩ вХЪбв. |
|
$+ |
БвРаиХХ ШЧ ЯаШбТЮХЭЭле ЧЭРзХЭШЩ $1, $2… |
|
$` $& &' |
їаХФиХбвТгойШЩ вХЪбв, вХЪбв бЮТЯРФХЭШп Ш вХЪбв ЯЮбЫХ бЮТЯРФХЭШп (ШбЯЮЫмЧЮТРвм ЭХ аХЪЮЬХЭФгХвбп — бЬ. «їаЮСЫХЬл нддХЪвШТЭЮбвШ Т Perl», б. <$R[P#,R7-6]>) |
|
БТпЧРЭЭлХ дгЭЪжШШ |
|
|
pos |
БЬ. б. <$R[P#,R7-36]> |
|
study |
БЬ. б. <$R[P#,R7-5]> |
|
quotemeta |
|
|
lc, lcfirst, uc, ucfirst |
БЬ. б. <$R[P#,R7-35]> |
ѕУаЮЬЭРп ЪЮЭжХЭваРжШп аРЧЭЮЮСаРЧЭле ТЮЧЬЮЦЭЮбвХЩ Т ТлаРЧШвХЫмЭле баХФбвТРе Perl вРЪЦХ пТЫпХвбп ЮФЭЮЩ ШЧ ЮввРЫЪШТРойШе бвЮаЮЭ пЧлЪР. БгйХбвТгов СХбзШбЫХЭЭлХ ЮбЮСлХ бЫгзРШ, гбЫЮТШп Ш ЪЮЭвХЪбвл, ЪЮвЮалХ ЭХЮЦШФРЭЭЮ ТЮЧЭШЪРов ЯаШ ТЭХбХЭШШ ЭХСЮЫмиЮУЮ ШбЯаРТЫХЭШп Т ЯаЮУаРЬЬг — ЯаЮбвЮ Тл бвРЫЪШТРХвХбм б ЮзХаХФЭлЬ ЮбЮСлЬ бЫгзРХЬ, Ю бгйХбвТЮТРЭШШ ЪЮвЮаЮУЮ Тл Ш ЭХ ЯЮФЮЧаХТРЫШ. єЮЭХзЭЮ, Т ЯаЮУаРЬЬШаЮТРЭШШ ЭРбвЮпйШЬ ЯаЮШЧТХФХЭШХЬ ШбЪгббвТР ЭХаХФЪЮ бзШвРХвбп бЪгзЭлЩ, ЯЮбЫХФЮТРвХЫмЭлЩ, ЯаХФбЪРЧгХЬлЩ ШЭвХадХЩб. І агЪРе ЮЯлвЭЮУЮ ЯЮЫмЧЮТРвХЫп Perl ЯаХТаРйРХвбп Т ЮагЦШХ ЮУаЮЬЭЮЩ аРЧагиШвХЫмЭЮЩ бШЫл, ЭЮ Т ЯаЮжХббХ ЯаШЮСаХвХЭШп ЮЯлвР Тл ЭХЮФЭЮЪаРвЭЮ аРЧапФШвХ нвЮ ЮагЦШХ Т бХСп.
І ТХбХЭЭХЬ ТлЯгбЪХ «The Perl Journal» ЧР 1996 У.[17] »РааШ ГЮЫЫ ЯШбРЫ:
«ѕФЭР ШЧ ШФХЩ, ЪЮвЮалХ п ТбХ ТаХЬп ЯЮФзХаЪШТРо ЯаШ ЯаЮХЪвШаЮТРЭШШ Perl — вЮ, звЮ А°·ЅЛµ ТХйШ ФЮЫЦЭл їѕ-А°·ЅѕјГ ТлУЫпФХвм».
ё нвЮ ЯаРТШЫмЭЮ, ЭЮ. Ъ бЮЦРЫХЭШо, ФЫп ЮЯХаРвЮаЮТ аХУгЫпаЭле ТлаРЦХЭШЩ нвШ аРЧЫШзШп ЭХ ТбХУФР ЮзХТШФЭл. ґРЦХ ЮЯлвЭлХ ЯаЮУаРЬЬШбвл ЯгвРовбп Т СХбзШбЫХЭЭле ЪЫозРе Ш ЮбЮСле бЫгзРпе. µбЫШ Тл бзШвРХвХ бХСп ЧЭРвЮЪЮЬ, ЭХ ЯлвРЩвХбм гСХФШвм ЬХЭп, звЮ Тл ЭШЪЮУФР ЭХ ваРвШЫШ ТаХЬп Т ЯЮЯлвЪРе ЯЮЭпвм, ЯЮзХЬг ЭХ аРСЮвРХв ЪЮЭбвагЪжШп
if (m/…/g) {
…
ЅХ ЯлвРЩвХбм, п ТбХ аРТЭЮ ЭХ ЯЮТХао. ЗХаХЧ нвЮ ЯаЮеЮФпв ТбХ. ° ХбЫШ Тл ЭХ бзШвРХвХ бХСп ЧЭРвЮЪЮЬ Ш ЭХ ЯЮЭШЬРХвХ, Т зХЬ ЯаЮСЫХЬР — ЭХ ЮУЮазРЩвХбм: ФЫп вЮУЮ Ш ЭРЯШбРЭР нвР ЪЭШУР.
І вЮЩ ЦХ бРЬЮЩ бвРвмХ »РааШ ЭРЯШбРЫ:
«БваХЬпбм бФХЫРвм ЯаЮУаРЬЬШаЮТРЭШХ ЯаХФбЪРЧгХЬлЬ, вХЮаХвШЪШ бФХЫРЫШ ХУЮ бЪгзЭлЬ».
ё нвЮ вЮЦХ ЯаРТФР, ЭЮ ЧРСРТЭЮ ФагУЮХ: ТбХУЮ ЧР ЭХФХЫо ФЮ звХЭШп бвРвмШ »РааШ п бРЬ ЭРЯШбРЫ, звЮ «Т ЯаЮУаРЬЬШаЮТРЭШШ ЭРбвЮпйШЬ ЯаЮШЧТХФХЭШХЬ ШбЪгббвТР ЭХаХФЪЮ бзШвРХвбп бЪгзЭлЩ, ЯЮбЫХФЮТРвХЫмЭлЩ, ЯаХФбЪРЧгХЬлЩ ШЭвХадХЩб»! І ЬЮХЬ ЯаХФбвРТЫХЭШШ «ЯаЮШЧТХФХЭШп ШбЪгббвТР» бЮЧФРов ШЭЦХЭХал, Р ЭХ егФЮЦЭШЪШ, ЭЮ ЪвЮ п вРЪЮЩ, звЮСл бгФШвм ЮС нвЮЬ? І ЫоСЮЬ бЫгзРХ, п ЭРбвЮпвХЫмЭЮ аХЪЮЬХЭФго ЯаЮзШвРвм гТЫХЪРвХЫмЭго, ЭРТЮФпйго ЭР аРЧЬлиЫХЭШп бвРвмо »РааШ. Іл ЭРЩФХвХ Т ЭХЩ ШбЪЫозШвХЫмЭЮ УЫгСЮЪШХ ЪЮЬЬХЭвРаШШ Ю Perl, пЧлЪРе, Ш… ШбЪгббвТХ.
І аХУгЫпаЭле ТлаРЦХЭШпе Perl бЯЫХвХЭЮ бвЮЫмЪЮ ТЧРШЬЮбТпЧРЭЭле ЪЮЭжХЯжШЩ, звЮ ЯаШ ЫоСле ЯЮЯлвЪРе ЭРТХбвШ еЮвм ЪРЪЮЩ-вЮ ЯЮапФЮЪ ТЮЧЭШЪРХв ЪЫРббШзХбЪРп ЯаЮСЫХЬР «ЪгаШжл Ш пЩжР». їЮбЪЮЫмЪг ТЮ ТТХФХЭШШ Ъ УЫРТХ 2 СлЫ ЯаХФбвРТЫХЭ гЯаЮйХЭЭлЩ ЯЮФеЮФ Ъ аХУгЫпаЭлЬ ТлаРЦХЭШпЬ Perl, п еЮзг ЯаШТХбвШ ЯЮЫЭЮжХЭЭлЩ ЯаШЬХа, звЮСл Тл бЫХУЪР аРЧЬпЫШбм ЯХаХФ аХиШвХЫмЭлЬ ЭРбвгЯЫХЭШХЬ ЭР ЮЯХаРвЮал Ш ЬХвРбШЬТЮЫл. ЅРФХобм, нвЮв ЯаШЬХа ЮЪРЦХвбп ЯЮЫХЧЭлЬ, ЯЮбЪЮЫмЪг Т ЭХЬ ЮСбгЦФРовбп ЬЭЮУШХ ЪЮЭжХЯжШШ, аРббЬРваШТРХЬлХ Т нвЮЩ УЫРТХ. НвЮв ЯаШЬХа ЯЮЪРЧлТРХв, ЪРЪ бЫХФЮТРвм «їгвШ Perl» ЯаШ аХиХЭШШ ЧРФРз Ш ШЧСХЦРвм ЭХЪЮвЮале ЫЮТгиХЪ, б ЪЮвЮалЬШ Тл ЬЮЦХвХ бвЮЫЪЭгвмбп Т СгФгйХЬ.
їаХФЯЮЫЮЦШЬ<$M[R7-54]>, ЯХаХЬХЭЭРп $text бЮФХаЦШв ЭХЪЮвЮалХ ФРЭЭлХ, аРЧФХЫХЭЭлХ ЧРЯпвлЬШ. ґРЭЭлХ Т нвЮЬ дЮаЬРвХ ЬЮУгв Слвм ЯаЮзШвРЭл ШЧ дРЩЫЮТ, бЮЧФРЭЭле Т dBASE, Excel ШЫШ ФагУЮЩ ЯаЮУаРЬЬХ. ДРЩЫ бЮбвЮШв ШЧ бваЮЪ ТШФР:
"earth",1,,"moon",9.374
І нвЮЩ бваЮЪХ ЮЯаХФХЫповбп Япвм ЯЮЫХЩ. ЅРЬ еЮвХЫЮбм Сл ЮдЮаЬШвм нвг ШЭдЮаЬРжШо Т ТШФХ ЬРббШТР (ФЮЯгбвШЬ, @field), звЮСл нЫХЬХЭв $field[0] бЮФХаЦРЫ бваЮЪг earth, нЫХЬХЭв $field[1] — зШбЫЮ 1, нЫХЬХЭв $field[2] ШЬХЫ ЭХЮЯаХФХЫХЭЭЮХ ЧЭРзХЭШХ, Ш в. Ф. ґЫп нвЮУЮ ЯаШФХвбп ЭХ вЮЫмЪЮ аРЧФХЫШвм ФРЭЭлХ ЭР ЯЮЫп, ЭЮ Ш гФРЫШвм ЪРТлзЪШ ШЧ бваЮЪЮТле ЯЮЫХЩ. їХаТЮХ, звЮ ЯаШеЮФШв Т УЮЫЮТг — ТЮбЯЮЫмЧЮТРвмбп аРЧСШХЭШХЬ бваЮЪШ ЯаШ ЯЮЬЮйШ split:
@fields = split(/,/, $text);
єЮЬРЭФР ЭРеЮФШв Т $text ТбХ ЬХбвР, УФХ бЮТЯРФРХв [,], Ш ЧРЯЮЫЭпХв @fields даРУЬХЭвРЬШ бваЮЪШ, ЪЮвЮалХ ЭРеЮФпвбп ЬХЦФг ЭРЩФХЭЭлЬШ бЮТЯРФХЭШпЬШ (ТЬХбвЮ бРЬШе бЮТЯРФХЭШЩ!).
є бЮЦРЫХЭШо, еЮвп ЮЯХаРвЮа split ЯаШЭЮбШв ЭХЬРЫго ЯЮЫмЧг, Т ФРЭЭЮЬ бЫгзРХ ЮЭ ЭХ ЯЮФеЮФШв. ґХЫЮ Т вЮЬ, звЮ ЯаШ аРЧСШХЭШШ ЯЮ ЧРЯпвлЬ ЮбвРовбп ЪРТлзЪШ, ЪЮвЮалХ Ьл вРЪЦХ еЮвХЫШ гФРЫШвм. їаЮСЫХЬг ЬЮЦЭЮ аХиШвм ТлаРЦХЭШХЬ ["?,"?], ЭЮ ЮбвРовбп Ш ФагУШХ ЯаЮСЫХЬл. ЅРЯаШЬХа, бваЮЪЮТлХ ЯЮЫп Т ЪРТлзЪРе ЭРТХаЭпЪР ЬЮУгв бЮФХаЦРвм ТЭгваХЭЭШХ ЪРТлзЪШ, ЪЮвЮалХ ЭХ ФЮЫЦЭл ШЭвХаЯаХвШаЮТРвмбп ЪРЪ ЮУаРЭШзШвХЫШ ЯЮЫХЩ, ЮФЭРЪЮ Тл ЭХ бЬЮЦХвХ ЯаШЪРЧРвм split ЭХ ЮСаРйРвм ЭР ЭШе ТЭШЬРЭШп.
ёЭбвагЬХЭвРаШЩ Perl ЯаХФЫРУРХв ЬЭЮУЮ ТЮЧЬЮЦЭле аХиХЭШЩ; ЯаШТХФг вЮ, звЮ ЯЮЫгзШЫЮбм г ЬХЭп<$M[R7-125]>:
@fields = (); # ёЭШжШРЫШЧШаЮТРвм ЯгбвЮЩ бЯШбЮЪ @fields
while ($text =~ m/"([^"\\]*(\\.[^"\\]*)*)",?|([^,]+),?|,/g) {
push(@fields, defined($1) ? $1 : $3); # ґЮСРТШвм бЮТЯРТиХХ ЯЮЫХ
}
push(@fields, undef) if $text =~ m/,$/; # ГзХбвм ЯЮбЫХФЭХХ ЯгбвЮХ ЯЮЫХ
# ВХЯХам ЬЮЦЭЮ аРСЮвРвм б ФРЭЭлЬШ зХаХЧ @fields
ІХаЮпвЭЮ, ФРЦХ ЮЯлвЭлЩ ЯаЮУаРЬЬШбв Perl ЭХ баРЧг аРЧСХаХвбп Т нвЮЬ даРУЬХЭвХ, ЯЮнвЮЬг ФРТРЩвХ аРЧСХаХЬ ХУЮ иРУ ЧР иРУЮЬ.
АХУгЫпаЭЮХ ТлаРЦХЭШХ ТлУЫпФШв ТЭгиШвХЫмЭЮ:
["([^"\\]*(\\.[^"\\]*)*)",?|([^,]+),?|,]
ЗвЮСл Т ЯЮЫЭЮЩ ЬХаХ ЯЮЭпвм бЬлбЫ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, ЭХЮСеЮФШЬЮ аРЧЮСаРвмбп Т вЮЬ, ЪРЪ ЮЭЮ ШбЯЮЫмЧгХвбп. І ФРЭЭЮЬ бЫгзРХ ЮЭЮ ЯаШЬХЭпХвбп ЮЯХаРвЮаЮЬ ЯЮШбЪР, б ЯаШЬХЭХЭШХЬ ЬЮФШдШЪРвЮаР /g, Т гбЫЮТШШ жШЪЫР while. НвР вХЬР ЯЮФаЮСЭЮ аРббЬРваШТРХвбп Т ЮбЭЮТЭЮЬ вХЪбвХ УЫРТл, ЭЮ УЫРТЭЮХ ЧРЪЫозРХвбп Т вЮЬ, звЮ ЮЯХаРвЮа ЯЮШбЪР ЯЮ-аРЧЭЮЬг ТХФХв бХСп Т ЧРТШбШЬЮбвШ Юв вЮУЮ, УФХ Ш ЪРЪ ЮЭ ШбЯЮЫмЧгХвбп. І ФРЭЭЮЬ бЫгзРХ вХЫЮ жШЪЫР while ТлЯЮЫЭпХвбп ЪРЦФлЩ аРЧ, ЪЮУФР аХУгЫпаЭЮХ ТлаРЦХЭШХ бЮТЯРФРХв Т ЯХаХЬХЭЭЮЩ $text. І вХЫХ жШЪЫР ФЮбвгЯЭл ЧЭРзХЭШп ЯХаХЬХЭЭле $&, $1, $2 Ш в. Ф., гбвРЭРТЫШТРХЬлХ ФЫп ЪРЦФЮУЮ бЮТЯРФХЭШп.
І ФХЩбвТШвХЫмЭЮбвШ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЭХ вРЪ гЦ бваРиЭЮ, ЪРЪ ЪРЦХвбп ЭР ЯХаТлЩ ТЧУЫпФ. ЅР ТХаеЭХЬ гаЮТЭХ ЮЭЮ ЯаХФбвРТЫпХв бЮСЮЩ ЪЮЭбвагЪжШо ТлСЮаР б ваХЬп РЫмвХаЭРвШТРЬШ. їЮбЬЮваШЬ, звЮ ЮЧЭРзРов нвШ ТлаРЦХЭШп б ЫЮЪРЫмЭЮЩ вЮзЪШ ЧаХЭШп.
l [" [^"\\]*(\\.[^"\\]*)*)",?]: ЭРи бвРалЩ ЧЭРЪЮЬлЩ ШЧ УЫРТл 5 — ТлаРЦХЭШХ ФЫп ЯЮШбЪР бваЮЪ Т ЪРТлзЪРе б ЯаШбЮХФШЭХЭЭлЬ бгддШЪбЮЬ [,?]. їЮЬХзХЭЭлХ бЪЮСЪШ ЭХ ТЫШпов ЭР бЬлбЫ аХУгЫпаЭЮУЮ ТлаРЦХЭШп — ЪЮЭХзЭЮ, ЮЭШ ШбЯЮЫмЧговбп ЫШим ФЫп бЮеаРЭХЭШп вХЪбвР Т ЯХаХЬХЭЭЮЩ $1. НвР РЫмвХаЭРвШТР ЯаХФЭРЧЭРзХЭР ФЫп ЮСаРСЮвЪШ ЯЮЫХЩ, ЧРЪЫозХЭЭле Т ЪРТлзЪШ.
l [([^,]+),?]: ЭХЯгбвРп ЯЮбЫХФЮТРвХЫмЭЮбвм бШЬТЮЫЮТ, ЭХ пТЫпойШебп ЧРЯпвлЬШ, ЧР ЪЮвЮаЮЩ ЬЮЦХв бЫХФЮТРвм ЧРЯпвРп. єРЪ Ш Т ЯХаТЮЩ РЫмвХаЭРвШТХ, ЪагУЫлХ бЪЮСЪШ ШбЯЮЫмЧговбп вЮЫмЪЮ ФЫп бЮеаРЭХЭШп бЮТЯРТиХУЮ вХЪбвР — ЭР нвЮв аРЧ ТбХе бШЬТЮЫЮТ ФЮ ЧРЯпвЮЩ (ШЫШ ФЮ ЪЮЭжР вХЪбвР). НвР РЫмвХаЭРвШТР ЮСаРСРвлТРХв ЯаЮбвлХ ЯЮЫп ФРЭЭле, ЭХ ЧРЪЫозХЭЭлХ Т ЪРТлзЪШ.
l [,]: ЭХ Ю зХЬ УЮТЮаШвм — ЯаЮбвЮ ЧРЯпвРп.
їЮЭпвм бЬлбЫ ЮвФХЫмЭле ЪЮЬЯЮЭХЭвЮТ ТлаРЦХЭШп ЭХвагФЭЮ — ТЮЧЬЮЦЭЮ, ЪаЮЬХ бЬлбЫР [,?], Ъ ЪЮвЮаЮЬг Ьл ХйХ ТХаЭХЬбп. ѕФЭРЪЮ ЯЮ ЮвФХЫмЭЮбвШ нвШ ТлаРЦХЭШп ЬРЫЮ Ю зХЬ УЮТЮапв — Ьл ФЮЫЦЭл ЯЮбЬЮваХвм, ЪРЪ ЮЭШ ЮСкХФШЭповбп Ш ЪРЪ ЮЭШ аРСЮвРов Т бЮзХвРЭШШ б ФагУШЬШ ЪЮЬРЭФРЬШ ЯаЮУаРЬЬл.
јЭЮУЮЪаРвЭЮ ЯаШЬХЭпп ТлаРЦХЭШХ ЯаШ ЯЮЬЮйШ ЪЮЬСШЭРжШШ while Ш m/…/g, Ьл еЮвШЬ, звЮСл ТлаРЦХЭШХ ЮФШЭ аРЧ бЮТЯРЫЮ б ЪРЦФлЬ ЯЮЫХЬ Т бваЮЪХ, аРЧФХЫХЭЭЮЩ ЧРЯпвлЬШ. БЭРзРЫР аРЧСХаХЬбп, ЪРЪ нвЮ ТлаРЦХЭШХ бЮТЯРФРХв Т ЯХаТлЩ аРЧ Т ЫоСЮЩ бваЮЪХ, СгФвЮ ЬЮФШдШЪРвЮа /g ЭХ ШбЯЮЫмЧгХвбп.
ВаШ РЫмвХаЭРвШТл бЮЮвТХвбвТгов ваХЬ вШЯРЬ ЯЮЫХЩ: Т ЪРТлзЪРе, СХЧ ЪРТлзХЪ Ш ЯгбвлЬ ЯЮЫпЬ. ѕСаРвШвХ ТЭШЬРЭШХ: ТЮ ТвЮаЮЩ РЫмвХаЭРвШТХ ЭХв ЭШзХУЮ, звЮ ЯЮЬХиРЫЮ Сл ХЩ бЮТЯРбвм ХЩ б ЯЮЫХЬ Т ЪРТлзЪРе. ѕФЭРЪЮ ЭХв ЭХЮСеЮФШЬЮбвШ пТЭЮ ШбЪЫозРвм бЫгзРШ, ЮвЭЮбпйШХбп Ъ ЯХаТЮЩ РЫмвХаЭРвШТХ, ЯЮбЪЮЫмЪг ЬШЭШЬРЫмЭЮбвм ЪЮЭбвагЪжШШ ТлСЮаР Т ваРФШжШЮЭЭЮЬ ЬХеРЭШЧЬХ Ѕє° Perl УРаРЭвШагХв, звЮ ЯХаТРп РЫмвХаЭРвШТР бЮТЯРФХв ТХЧФХ, УФХ нвЮ ТЮЧЬЮЦЭЮ. І аХЧгЫмвРвХ ЯЮЫХ Т ЪРТлзЪРе ЭХ ЯаЮЩФХв ЬШЬЮ ЯХаТЮЩ РЫмвХаЭРвШТл Ш ЭХ бЮТЯРФХв бЮ ТвЮаЮЩ РЫмвХаЭРвШТЮЩ ЯаЮвШТ ЭРиХУЮ ЦХЫРЭШп.
ѕСаРвШвХ ТЭШЬРЭШХ ЭР ТРЦЭЮХ ЮСбвЮпвХЫмбвТЮ — б ЪРЪЮЩ Сл РЫмвХаЭРвШТЮЩ ЭХ бЮТЯРЫЮ ЯХаТЮХ ЯЮЫХ, ТлаРЦХЭШХ ТбХУФР аРбЯаЮбваРЭпХвбп ФЮ ЧРЯпвЮЩ, аРЧФХЫпойХЩ ЯЮЫп. їаШ нвЮЬ вХЪгйРп ЯЮЧШжШп ЬЮФШдШЪРвЮаР /g СгФХв ЭРеЮФШвмбп Т ЭРзРЫХ бЫХФгойХУЮ ЯЮЫп. ВРЪШЬ ЮСаРЧЮЬ, ЯаШ жШЪЫШзХбЪЮЬ ТлЯЮЫЭХЭШШ ЪЮЬСШЭРжШШ while Ш m/…/g Ш ЬЭЮУЮЪаРвЭЮЬ ЯаШЬХЭХЭШШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп ЯЮШбЪ ЧРТХФЮЬЮ СгФХв ЭРзШЭРвмбп б ЭРзРЫР ЯЮЫп. їЮФЮСЭРп<$M[R7-65]> «бШЭеаЮЭШЧРжШп» ШУаРХв ТРЦЭго аЮЫм ТЮ ЬЭЮУШе бШвгРжШпе, УФХ ШбЯЮЫмЧгХвбп ЬЮФШдШЪРвЮа /g. ёЬХЭЭЮ ШЧ-ЧР ЭХХ ЯХаТлХ ФТХ РЫмвХаЭРвШТл ЧРТХаиРовбп ЯЮФТлаРЦХЭШХЬ [,?] (ТЮЯаЮбШвХЫмЭлЩ ЧЭРЪ ЭХЮСеЮФШЬ ШЧ-ЧР вЮУЮ, звЮ ЯЮбЫХФЭХХ ЯЮЫХ Т бваЮЪХ ЭХ ЧРТХаиРХвбп ЧРЯпвЮЩ). јл ХйХ ТбваХвШЬбп б ЯаЮпТЫХЭШХЬ нвЮЩ «бШЭеаЮЭШЧРжШШ».
ёвРЪ, Ьл ЬЮЦХЬ ШФХЭвШдШжШаЮТРвм ЪРЦФЮХ ЯЮЫХ. ЅЮ ЪРЪ ЧРЯЮЫЭШвм ФРЭЭлЬШ ЮзХаХФЭЮЩ нЫХЬХЭв @fields ЯЮбЫХ ЪРЦФЮУЮ бЮТЯРФХЭШп? µбЫШ ЯЮЫХ ЧРЪЫозХЭЮ Т ЪРТлзЪШ, вЮ ЯХаТРп РЫмвХаЭРвШТР бЮТЯРФРХв, Р вХЪбв Т ЪРТлзЪРе ЯаШбТРШТРХвбп ЯХаХЬХЭЭЮЩ $1. ЅЮ ХбЫШ ЯЮЫХ ЭХ ЧРЪЫозХЭЮ Т ЪРТлзЪШ, ЯЮШбЪ ЯХаТЮЩ РЫмвХаЭРвШТл ЧРТХаиРХвбп ЭХгФРзХЩ, Р ТвЮаРп РЫмвХаЭРвШТР бЮТЯРФРХв. І аХЧгЫмвРвХ ЯХаХЬХЭЭРп $1 ШЬХХв ЭХЮЯаХФХЫХЭЭЮХ ЧЭРзХЭШХ, Р вХЪбв ЯЮЫп ЯаШбТРШТРХвбп ЯХаХЬХЭЭЮЩ $3. ЅРЪЮЭХж, ФЫп ЯгбвЮУЮ ЯЮЫп бЮТЯРФРХв ваХвмп РЫмвХаЭРвШТР, Р ЯХаХЬХЭЭлЬ $1 Ш $3 ЯаШбТРШТРовбп ЭХЮЯаХФХЫХЭЭлХ ЧЭРзХЭШп. ІбХ бЪРЧРЭЭЮХ аХРЫШЧгХвбп бЫХФгойХЩ ЪЮЬРЭФЮЩ:
push(@fields, defined($1) ? $1 :$3);
їЮФзХаЪЭгвРп зРбвм ЮЧЭРзРХв: «ёбЯЮЫмЧЮТРвм ЯХаХЬХЭЭго $1, ХбЫШ ЮЭР ШЬХХв ЮЯаХФХЫХЭЭЮХ ЧЭРзХЭШХ, ШЫШ ЯХаХЬХЭЭго $3 Т ЯаЮвШТЭЮЬ бЫгзРХ». µбЫШ ЮСХ ЯХаХЬХЭЭлХ ШЬХов ЭХЮЯаХФХЫХЭЭлХ ЧЭРзХЭШп, вЮ ЯХаХЬХЭЭРп $3 ЧРТХФЮЬЮ ЭХ ЮЯаХФХЫХЭР, Р ШЬХЭЭЮ нвЮ ЭРЬ Ш ЭгЦЭЮ Юв ЯгбвЮУЮ ЯЮЫп. ВРЪШЬ ЮСаРЧЮЬ, Т ЫоСЮЬ бЫгзРХ Т @fields ЧРЭЮбШвбп ШЬХЭЭЮ вЮ ЧЭРзХЭШХ, ЪЮвЮаЮХ ЭРЬ ЭгЦЭЮ, Р бЮзХвРЭШХ жШЪЫР while, ЬЮФШдШЪРвЮаР /g Ш ЯаШЭжШЯР бШЭеаЮЭШЧРжШШ ЯЮЧТЮЫпХв ЮСаРСЮвРвм ТбХ ЯЮЫп.
ІХаЭХХ, ЯЮзвШ ТбХ ЯЮЫп. µбЫШ ЯЮбЫХФЭХХ ЯЮЫХ ЯгбвЮ (ХбЫШ бваЮЪР ЧРТХаиРХвбп ЧРЯпвЮЩ), ЭРиР ЯаЮУаРЬЬР гзШвлТРХв нвЮ ЯЮЫХ ЭХ Т УЫРТЭЮЬ аХУгЫпаЭЮЬ ТлаРЦХЭШШ, Р Т ЮвФХЫмЭЮЩ бваЮЪХ, ТЪЫозРойХЩ Т бЯШбЮЪ undef. І вРЪШе бШвгРжШпе ТЮЧЭШЪРХв ЦХЫРЭШХ ШЧЬХЭШвм УЫРТЭЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ вРЪ, звЮСл ЮЭЮ бЮТЯРФРЫЮ б «ЭШзХЬ» Т ЪЮЭжХ бваЮЪШ. ВРЪЮХ аХиХЭШХ ЯЮФЮЩФХв ФЫп бваЮЪ, ЧРЪРЭзШТРойШебп ЯгбвлЬШ ЯЮЫпЬШ, ЭЮ Т ЮбвРЫмЭле бваЮЪРе СгФХв бЮЧФРТРвм дРЭвЮЬЭЮХ ЯгбвЮХ ЯЮЫХ, ЯЮбЪЮЫмЪг «ЭШзвЮ» ЯаШбгвбвТгХв Т ЪЮЭжХ ЫоСЮЩ бваЮЪШ.
ЕЮвп Ьл ЭХЬЭЮУЮ ЮвТЫХЪЫШбм ЭР РЭРЫШЧ ШбЯЮЫмЧЮТРЭЭЮУЮ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, ЯЮЫРУРо, нвЮв ЯаШЬХа ЯЮЬЮЦХв ТРЬ ЮбТЮШвмбп б ЯаШЬХЭХЭШХЬ аХУгЫпаЭле ТлаРЦХЭШЩ ЭР їгвШ Perl:
l БгФп ЯЮ ЮСкХЬг ЯХаХЯШбЪШ Т нЫХЪваЮЭЭле ЪЮЭдХаХЭжШпе Perl Ш Т ЬЮХЩ ЫШзЭЮЩ ЯЮзвХ, РЭРЫШЧ ФРЭЭле, аРЧФХЫХЭЭле ЧРЯпвлЬШ, пТЫпХвбп ТХбмЬР аРбЯаЮбваРЭХЭЭЮЩ ЧРФРзХЩ. І пЧлЪРе вШЯР C Ш Pascal нвР ЧРФРзР ЮСлзЭЮ аХиРХвбп «УагСЮЩ бШЫЮЩ», вЮ Хбвм ЯХаХСЮаЮЬ бШЬТЮЫЮТ, ЮФЭРЪЮ Т Perl Ъ ЭХЩ ЫгзиХ ЯЮФЮЩвШ б ФагУЮЩ бвЮаЮЭл.
l АРббЬЮваХЭЭРп ЧРФРзР ЭХ аХиРХвбп ЯаЮбвлЬ ЮФЭЮЪаРвЭлЬ ЯаШЬХЭХЭШХЬ аХУгЫпаЭЮУЮ ТлаРЦХЭШп. І ЭХЩ СлЫШ ЧРФХЩбвТЮТРЭл аРЧЭЮЮСаРЧЭлХ, вХбЭЮ ЯХаХЯЫХвХЭЭлХ ФагУ б ФагУЮЬ ТЮЧЬЮЦЭЮбвШ пЧлЪР. ЅР ЯХаТлЩ ТЧУЫпФ ЪРЧРЫЮбм, звЮ ЧРФРзР ваХСгХв ЯаШЬХЭХЭШп split, ЭЮ ЯаШ СЮЫХХ ТЭШЬРвХЫмЭЮЬ аРббЬЮваХЭШШ ТлпбЭпХвбп, звЮ нвЮв Ягвм ТХФХв Т вгЯШЪ.
l <$M[R7-55]>·РФРзР ФХЬЮЭбваШагХв ЭХЪЮвЮалХ ЯЮвХЭжШРЫмЭлХ ЮЯРбЭЮбвШ, ТбваХзРойШХбп Т бШвгРжШпе, ЪЮУФР бвагЪвгаР аХУгЫпаЭЮУЮ ТлаРЦХЭШп вХбЭЮ бТпЧРЭР б ЫЮУШЪЮЩ аРСЮвл ЯаЮУаРЬЬл. ЅРЯаШЬХа, ЭРЬ еЮвХЫЮбм Сл аРббЬРваШТРвм ваШ РЫмвХаЭРвШТл ЪРЪ ЯаРЪвШзХбЪШ ЭХЧРТШбШЬлХ ЪЮЭбвагЪжШШ, ЮФЭРЪЮ ЯаШеЮФШвбп гзШвлТРвм ЭРЫШзШХ Т ЯХаТЮЩ РЫмвХаЭРвШТХ ФТге ЯРа ЪагУЫле бЪЮСЮЪ Ш ЮСаРйРвмбп Ъ бЪЮСЪРЬ ТвЮаЮЩ РЫмвХаЭРвШТл зХаХЧ ЯХаХЬХЭЭго $3. ґЮСРТЫХЭШХ ШЫШ гФРЫХЭШХ бЪЮСЮЪ Т ЯХаТЮЩ РЫмвХаЭРвШТХ ЯаШТХФХв Ъ вЮЬг, звЮ ЭРЬ ЯаШФХвбп ШЧЬХЭпвм ТбХ бблЫЪШ ЭР $3, ЪЮвЮалХ ЬЮУгв ЭРеЮФШвмбп Т ФагУЮЬ ЬХбвХ ЯаЮУаРЬЬл ЭР ЭХЪЮвЮаЮЬ аРббвЮпЭШШ Юв аХУгЫпаЭЮУЮ ТлаРЦХЭШп.
l І аРббЬЮваХЭЭЮЬ ЯаШЬХаХ Ьл «ШЧЮСаХвРХЬ ТХЫЮбШЯХФ». І бвРЭФРавЭлЩ СШСЫШЮвХзЭлЩ ЬЮФгЫм Perl (ТХабШШ 5) Text::ParseWords ТеЮФШв дгЭЪжШп quotewords[18], ЯЮнвЮЬг ЭР бРЬЮЬ ФХЫХ ЧРФРзР аХиРХвбп бЮТбХЬ ЯаЮбвЮ:
use Text::ParseWords;
…
@fields = quotewords(',', 0, $text);
єЮЭХзЭЮ, гЬХЭШХ бРЬЮбвЮпвХЫмЭЮ аХиРвм ЧРФРзШ — ЯЮЫХЧЭлЩ ЭРТлЪ. ЅЮ ХбЫШ нддХЪвШТЭЮбвм ЭХ пТЫпХвбп РСбЮЫовЭлЬ ЯаШЮаШвХвЮЬ, ЭРУЫпФЭЮбвм Ш ЯаЮбвЮвР бЮЯаЮТЮЦФХЭШп, ЯаШбгйШХ аХиХЭШпЬ б ШбЯЮЫмЧЮТРЭШХЬ дгЭЪжШЩ бвРЭФРавЭле СШСЫШЮвХЪ, ТлУЫпФпв ТХбмЬР ЧРЬРЭзШТЮ. БвРЭФРавЭРп СШСЫШЮвХЪР Perl ТХЫШЪР, ЯЮнвЮЬг ЯЮбЫХ ХХ ШЧгзХЭШп Т ТРиХЬ аРбЯЮапЦХЭШШ ЮЪРЦХвбп ЬЭЮЦХбвТЮ аРЧЭЮЮСаРЧЭле дгЭЪжШЩ ЪРЪ ТлбЮЪЮУЮ, вРЪ Ш ЭШЧЪЮУЮ гаЮТЭп.
»РааШ ГЮЫЫ ТлЯгбвШЫ ЯХаТго ТХабШо Perl Т ФХЪРСаХ 1987 УЮФР, Ш б вХе ЯЮа пЧлЪ ЯЮбвЮпЭЭЮ ЮСЭЮТЫпХвбп. І ТХабШШ 1 ШбЯЮЫмЧЮТРЫбп ЬХеРЭШЧЬ аХУгЫпаЭле ТлаРЦХЭШЩ, ЯЮбваЮХЭЭлЩ ЭР ЮбЭЮТХ ЭР rn — ЯаЮУаРЬЬХ ЯаЮбЬЮваР нЫХЪваЮЭЭле ЭЮТЮбвХЩ, ЭРЯШбРЭЭЮЩ бРЬШЬ »РааШ. І бТЮо ЮзХаХФм, rn бЮЧФРТРЫбп ЭР ЮбЭЮТХ ЬХеРЭШЧЬР аХУгЫпаЭле ТлаРЦХЭШЩ Юв Emacs ґЦХЩЬбР іЮбЫШЭУР (ЯХаТРп ТХабШп Emacs ФЫп Unix). ІЮЧЬЮЦЭЮбвШ нвЮУЮ ЬХеРЭШЧЬР ЮбвРТЫпЫШ ЦХЫРвм ЫгзиХУЮ, Ш Т ТХабШШ 2 ЮЭ СлЫ ЧРЬХЭХЭ гЫгзиХЭЭЮЩ ТХабШХЩ аРбЯаЮбваРЭХЭЭЮУЮ ЯРЪХвР ФЫп аРСЮвл б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ, ЭРЯШбРЭЭЮУЮ іХЭаШ БЯХЭбХаЮЬ. Б ЯЮпТЫХЭШХЬ ЭЮТЮУЮ, ЬЮйЭЮУЮ ФШРЫХЪвР баХФбвТР ФЫп аРСЮвл б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ ТбЪЮаХ бвРЫШ ЭХЮвкХЬЫХЬЮЩ зРбвмо пЧлЪР Perl.
ІХабШп 5 (бЮЪаРйХЭЭЮ — Perl5) СлЫР ЮдШжШРЫмЭЮ ТлЯгйХЭР Т ЮЪвпСаХ 1994 УЮФР. ПЧлЪ ЯЮФТХаУбп ЧЭРзШвХЫмЭЮЩ ЯХаХаРСЮвЪХ, Т ЭХЬ ЯЮпТШЫШбм ШЫШ СлЫШ ЬЮФШдШжШаЮТРЭл ЬЭЮУШХ баХФбвТР ФЫп аРСЮвл б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ. ѕФЭР ШЧ ЯаЮСЫХЬ, б ЪЮвЮалЬШ бвЮЫЪЭгЫбп »РааШ ГЮЫЫ ЯаШ бЮЧФРЭШШ ЭЮТле ТЮЧЬЮЦЭЮбвХЩ — ЯаЮСЫХЬР бЮТЬХбвШЬЮбвШ. ПЧлЪ аХУгЫпаЭле ТлаРЦХЭШЩ Perl ЯЮзвШ ЭХ ЮбвРТЫпЫ ТЮЧЬЮЦЭЮбвХЩ ФЫп аРбиШаХЭШп, ЯЮнвЮЬг ХЬг ЯаШиЫЮбм ТТХбвШ апФ ЭЮТле ЮСЮЧЭРзХЭШЩ. АХЧгЫмвРвл ЭХ ТбХУФР аРФгов УЫРЧ; ЬЭЮУШХ ЭЮТлХ ЪЮЭбвагЪжШШ ЪРЦгвбп ЭХнбвХвШзЭлЬШ Ш ЭЮТШзЪРЬ, Ш нЪбЯХавРЬ. ЅЮ ЭХбЬЮвап ЭР гаЮФбвТЮ, ЮЭШ ЮЪРЧлТРовбп заХЧТлзРЩЭЮ ЬЮйЭлЬШ.
ёЧ-ЧР ЬЭЮУЮзШбЫХЭЭле ШЧЬХЭХЭШЩ Т ТХабШШ 5.000 ЬЭЮУШХ ЯЮЫмЧЮТРвХЫШ ЯаЮФЮЫЦРЫШ аРСЮвРвм б ЭРФХЦЭЮЩ ТХабШХЩ 4.036 (бЮЪаРйХЭЭЮ — Perl4). ЕЮвп Perl5 ТлФХаЦРЫ ШбЯлвРЭШХ ТаХЬХЭХЬ, ЭР ЬЮЬХЭв ЭРЯШбРЭШп нвЮЩ ЪЭШУШ Perl4 ЯаЮФЮЫЦРХв ШбЯЮЫмЧЮТРвмбп. Г ТбХе РТвЮаЮТ, ЯШигйШе Ю Perl (Т ФРЭЭЮЬ бЫгзРХ — г ЬХЭп) ТЮЧЭШЪРов ЯаЮСЫХЬл. јЮЦЭЮ ЮУаРЭШзШвмбп ЯаЮУаРЬЬРЬШ, ЪЮвЮалХ СгФгв аРСЮвРвм Т ЮСЮШе ТХабШпе, ЭЮ Т нвЮЬ бЫгзРХ Тл ЫШиРХвХбм ЬЭЮУШе ЧРЬХзРвХЫмЭле ТЮЧЬЮЦЭЮбвХЩ Perl5. ЅРЯаШЬХа, Т бЮТаХЬХЭЭЮЩ ТХабШШ Perl ЮбЭЮТЭго зРбвм ЯаШТХФХЭЭЮУЮ ЯаШЬХаР ЬЮЦЭЮ ЧРЯШбРвм Т бЫХФгойХЬ ТШФХ:
push(@fields, $+) while $text =~ m{ # БвРЭФРавЭРп бваЮЪР Т ЪРТлзЪРе (
"([^"\\]*(\\.[^"\\]*)*)",? # ё»ё бШЬТЮЫл ФЮ бЫХФгойХЩ ЧРЯпвЮЩ
|([^,]+),? # ё»ё ЯаЮбвЮ ЧРЯпвРп.
| ,
}gx;
НвШ ЪЮЬЬХЭвРаШШ пТЫповбп зРбвмо аХУгЫпаЭЮУЮ ТлаРЦХЭШп… УЮаРЧФЮ ЭРУЫпФЭХХ, ЭХ ЯаРТФР ЫШ? єРЪ СгФХв ЯЮЪРЧРЭЮ ЭШЦХ, ФагУШХ ТЮЧЬЮЦЭЮбвШ Perl5 ЯЮЧТЮЫпов гбЮТХаиХЭбвТЮТРвм Ш нвЮ аХиХЭШХ — Ьл ТХаЭХЬбп Ъ нвЮЬг ЯаШЬХаг Т аРЧФХЫХ «ІбХ ТЬХбвХ» (б. <$R[P#,R7-14]>), ЪЮУФР ЮСкХЬ ЯаЮЩФХЭЭЮУЮ ЬРвХаШРЫР ЯЮЧТЮЫШв ТРЬ аРЧЮСаРвмбп Т нвШе ТЮЧЬЮЦЭЮбвпе.
јЭХ еЮвХЫЮбм Сл бЪЮЭжХЭваШаЮТРвмбп ЭР Perl5, ЮФЭРЪЮ ШУЭЮаШаЮТРвм Perl4 ЧЭРзШЫЮ Сл ШУЭЮаШаЮТРвм впЦХЫго аХРЫмЭЮбвм. П СгФг гЯЮЬШЭРвм Ю ТРЦЭХЩиШе ЮвЫШзШпе Perl4 Т ЮСЫРбвШ аХУгЫпаЭле ТлаРЦХЭШЩ ЯаШ ЯЮЬЮйШ ЯЮЬХвЮЪ ТШФР<$M[R7-38]> [1 б.<$R[P#,R7-37]>]. НвР ЯЮЬХвЪР ЮвЭЮбШвбп Ъ ЯХаТЮЬг ЯаШЬХзРЭШо Ъ Perl4, ЯаШТХФХЭЭЮЬг ЭР б. <$R[P#,R7-37]>. Perl4 бгйХбвТгХв ФРТЭЮ, Ш п ЭХ ТШЦг ЭХЮСеЮФШЬЮбвШ ЯХаХбЪРЧлТРвм бваРЭШжл агЪЮТЮФбвТР Perl4. ѕСлзЭЮ Т ЯаШЬХзРЭШпе ЯаШТЮФШвбп ЪаРвЪРп, ЪЮЭЪаХвЭРп ШЭдЮаЬРжШп ФЫп вХе ЭХбзРбвЭле, ЪЮвЮалЬ ЯаШеЮФШвбп бЮЯаЮТЮЦФРвм ЯаЮУаРЬЬЭлЩ ЪЮФ ФЫп ЮСХШе ТХабШЩ. µбЫШ ТРиХ ЧЭРЪЮЬбвТЮ б Perl вЮЫмЪЮ ЭРзШЭРХвбп, ТРЬ ЮЯаХФХЫХЭЭЮ ЭХ бвЮШв СХбЯЮЪЮШвмбп Ю бвРале ТХабШпе ТаЮФХ Perl4.
БШвгРжШп ЮбЫЮЦЭпХвбп вХЬ, звЮ Т УЮапзго ЯЮаг ЯЮбЫХ ТлеЮФР аРЭЭШе ТХабШЩ Perl5 ФШбЪгббШШ Т ЪЮЭдХаХЭжШШ USENET comp.lang.perl.misc ТлЧТРЫШ апФ бХамХЧЭле ШЧЬХЭХЭШЩ Т пЧлЪХ Ш Т ХУЮ аХУгЫпаЭле ТлаРЦХЭШпе. ЅРЯаШЬХа, ЮФЭРЦФл ЬЭХ ЯаШиЫЮбм ЮвТХзРвм ЭР бЮЮСйХЭШХ б ЮзХЭм ФЫШЭЭлЬ аХУгЫпаЭлЬ ТлаРЦХЭШХЬ. ЗвЮСл ТлаРЦХЭШХ ЫгзиХ бЬЮваХЫЮбм, п аРЧСШЫ ХУЮ ЭР бваЮЪШ Ш ФЮСРТШЫ ЯаЮСХЫл ФЫп ЯгйХЩ ЭРУЫпФЭЮбвШ. »РааШ ГЮЫЫ гТШФХЫ бЮЮСйХЭШХ, ЯЮФгЬРЫ, звЮ ЯЮФЮСЭЮХ ЮдЮаЬЫХЭШХ аХУгЫпаЭле ТлаРЦХЭШЩ ЬЮЦХв ЯаШУЮФШвмбп, Ш ТЪЫозШЫ Т Perl5 ЬЮФШдШЪРвЮа /x, ЯаШ ЭРЫШзШШ ЪЮвЮаЮУЮ СЮЫмиШЭбвТЮ ЯаЮЯгбЪЮТ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ ШУЭЮаШагХвбп.
їаШЬХаЭЮ Т вЮ ЦХ ТаХЬп »РааШ ФЮСРТШЫ ЪЮЭбвагЪжШо [(?#…)], ЯЮЧТЮЫпойго ШбЯЮЫмЧЮТРвм ТбваЮХЭЭлХ ЪЮЬЬХЭвРаШШ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ. ЅЮ зХаХЧ ЭХбЪЮЫмЪЮ ЬХбпжХТ, ЯЮбЫХ ЮСбгЦФХЭШп Т ЪЮЭдХаХЭжШШ, СлЫЮ ТЭХбХЭЮ ЮзХаХФЭЮХ ШЧЬХЭХЭШХ — ЯаШ ЭРЫШзШШ ЬЮФШдШЪРвЮаР /x бШЬТЮЫ # бвРЫ ЮСЮЧЭРзРвм ЭРзРЫЮ ЪЮЬЬХЭвРаШп. НвЮ ЭЮТиХбвТЮ ЯЮпТШЫЮбм Т ТХабШШ 5.002[19]. ІбваХзРовбп Ш ФагУШХ ЬЮФШдШЪРжШШ Ш ШбЯаРТЫХЭШп — аРЭЭШХ ТХабШШ ЬЮУгв ЮЪРЧРвмбп ЭХбЮТЬХбвШЬлЬШ б ЯаШТХФХЭЭлЬШ ЯаШЬХаРЬШ. П аХЪЮЬХЭФго ШбЯЮЫмЧЮТРвм ТХабШо 5.002 Ш ТлиХ.
ЅР ЬЮЬХЭв ТлЯгбЪР ТвЮаЮУЮ ШЧФРЭШп нвЮЩ ЪЭШУШ[20] ТХабШп 5.004 ТлиЫР ЭР бвРФШо СХвР-вХбвШаЮТРЭШп, Р ТлеЮФ ЮЪЮЭзРвХЫмЭЮЩ ТХабШШ СлЫ ЭРЬХзХЭ ЭР ТХбЭг 1997 УЮФР. БаХФШ ЯаХФЯЮЫРУРХЬле ШЧЬХЭХЭШЩ Т ЮСЫРбвШ аХУгЫпаЭле ТлаРЦХЭШЩ — гбЮТХаиХЭбвТЮТРЭЭРп ЯЮФФХаЦЪР ЫЮЪРЫмЭле ЪЮЭвХЪбвЮТ, ЬЮФШдШЪРжШп ЯЮФФХаЦЪШ pos, Р вРЪЦХ аРЧЫШзЭлХ гЫгзиХЭШп Ш ЮЯвШЬШЧРжШШ (ЭРЯаШЬХа, вРСЫ. 7.10 ФЮЫЦЭР бвРвм ЯЮзвШ ЯгбвЮЩ).
<$M[R7-9]>БгйХбвТгов ЬЭЮЦХбвТЮ ЪЮЭжХЯжШЩ, ЪЮвЮалХ пТЫповбп зРбвмо «Perl ТЮЮСйХ», ЭЮ ЯаХФбвРТЫпов ШЭвХаХб ФЫп ЭРиХУЮ ШЧгзХЭШп аХУгЫпаЭле ТлаРЦХЭШЩ. І ЭХбЪЮЫмЪШе СЫШЦРЩиШе аРЧФХЫРе аРббЬРваШТРовбп бЫХФгойШХ вХЬл:
l єЮЭвХЪбв. јЭЮУШХ дгЭЪжШШ Ш ЮЯХаРвЮал Perl гзШвлТРов ЪЮЭвХЪбв, Т ЪЮвЮаЮЬ ЮЭШ ШбЯЮЫмЧговбп. ЅРЯаШЬХа, Perl ЮЦШФРХв, звЮ Т гбЫЮТШШ жШЪЫР while ЧРФРХвбп бЪРЫпаЭРп ТХЫШзШЭР — УЫРТЭлЩ ЮЯХаРвЮа ЯЮШбЪР ШЧ ЯаХФлФгйХУЮ ЯаШЬХаР ЯЮТХЫ Сл бХСп ШЭРзХ Т бШвгРжШШ, ЪЮУФР Perl ЮЦШФРХв бЯШбЮЪ.
l ґШЭРЬШзХбЪРп ТШФШЬЮбвм. ІЮ ЬЭЮУШе пЧлЪРе ЯаЮУаРЬЬШаЮТРЭШп бгйХбвТгов ЪЮЭжХЯжШШ ЫЮЪРЫмЭле Ш УЫЮСРЫмЭле ЯХаХЬХЭЭле. І Perl ЪРавШЭР ФЮЯЮЫЭпХвбп вРЪ ЭРЧлТРХЬЮЩ ФШЭРЬШзХбЪЮЩ ТШФШЬЮбвмо. ґШЭРЬШзХбЪРп ЮСЫРбвм ТШФШЬЮбвШ ТаХЬХЭЭЮ «ЧРйШйРХв» УЫЮСРЫмЭго ЯХаХЬХЭЭго; ФЫп нвЮУЮ бЮеаРЭпХвбп ЪЮЯШп ЯХаХЬХЭЭЮЩ, ЪЮвЮаРп ЯЮЧФЭХХ РТвЮЬРвШзХбЪШ ТЮббвРЭРТЫШТРХвбп. НвР ЫоСЮЯлвЭРп ЪЮЭжХЯжШп ТРЦЭР ФЫп ЭРб, ЯЮбЪЮЫмЪг ЮЭР ТЫШпХв ЭР $1 Ш ШЬХХв ФагУШХ ЯЮСЮзЭлХ нддХЪвл Т ЮСЫРбвШ аХУгЫпаЭле ТлаРЦХЭШЩ.
l ѕСаРСЮвЪР бваЮЪ. ІЮЧЬЮЦЭЮ, ЯаЮУаРЬЬШбвР б ЮЯлвЮЬ аРСЮвл ЭР ваРФШжШЮЭЭле пЧлЪРе вШЯР C ШЫШ Pascal гФШТШв вЮ, звЮ бваЮЪЮТлХ «ЪЮЭбвРЭвл» Т Perl Т ФХЩбвТШвХЫмЭЮбвШ ЯаХФбвРТЫпов бЮСЮЩ ФШЭРЬШзХбЪШХ ЮЯХаРвЮал, ЭРФХЫХЭЭлХ иШаЮЪШЬШ ТЮЧЬЮЦЭЮбвпЬШ. ёЧ бваЮЪШ ФРЦХ ЬЮЦЭЮ ТлЧТРвм дгЭЪжШо! АХУгЫпаЭлХ ТлаРЦХЭШп Perl ЮСлзЭЮ ЮСаРСРвлТРовбп ЮзХЭм ЯЮеЮЦШЬ ЮСаРЧЮЬ; ЯаШ нвЮЬ ТЮЧЭШЪРов ЭХЪЮвЮалХ ШЭвХаХбЭлХ нддХЪвл, ЪЮвЮалХ СгФгв аРббЬЮваХЭл ЭШЦХ.
їЮЭпвШХ ЪЮЭвХЪбвР ШУаРХв ТРЦЭго аЮЫм Т пЧлЪХ Perl, Ш Т зРбвЭЮбвШ, ЯаШ ШбЯЮЫмЧЮТРЭШШ ЮЯХаРвЮаР ЯЮШбЪР. єРЦФЮХ ТлаРЦХЭШХ ЬЮЦХв ЮвЭЮбШвмбп Ъ ЮФЭЮЬг ШЧ ФТге ЪЮЭвХЪбвЮТ. І бЯШбЪЮТЮЬ ЪЮЭвХЪбвХ[21] ЮЦШФРХвбп бЯШбЮЪ ТХЫШзШЭ, Р Т бЪРЫпаЭЮЬ ЪЮЭвХЪбвХ ЮЦШФРХвбп ЮФЭР ТХЫШзШЭР.
АРббЬЮваШЬ ФТХ ЪЮЬРЭФл ЯаШбТРШТРЭШп:
$s = ТлаРЦХЭШХ_1;
@a = ТлаРЦХЭШХ_2;
їЮбЪЮЫмЪг $s пТЫпХвбп ЯаЮбвЮЩ бЪРЫпаЭЮЩ ЯХаХЬХЭЭЮЩ (вЮ Хбвм бЮФХаЦШв ЮФЭг ТХЫШзШЭг, Р ЭХ бЯШбЮЪ), ТлаРЦХЭШХ_1, ЪРЪШЬ Сл ЮЭЮ ЭШ СлЫЮ, ЯаШЭРФЫХЦШв Ъ бЪРЫпаЭЮЬг ЪЮЭвХЪбвг. °ЭРЫЮУШзЭЮ, ЯЮбЪЮЫмЪг ЯХаХЬХЭЭРп @a ЯаХФбвРТЫпХв бЮСЮЩ ЬРббШТ Ш бЮФХаЦШв бЯШбЮЪ ЧЭРзХЭШЩ, ТлаРЦХЭШХ_2 ЯаШЭРФЫХЦШв Ъ бЯШбЪЮТЮЬг ЪЮЭвХЪбвг. ЕЮвп ТлаРЦХЭШп ЬЮУгв Слвм ЮФШЭРЪЮТлЬШ, Т ЧРТШбШЬЮбвШ Юв ЪЮЭвХЪбвР ЮЭШ ЬЮУгв ТЮЧТаРйРвм РСбЮЫовЭЮ аРЧЭлХ ЧЭРзХЭШп Ш ШЬХвм аРЧЭлХ ЯЮСЮзЭлХ нддХЪвл.
ёЭЮУФР вШЯ ТлаРЦХЭШп ЭХ бЮЮвТХвбвТгХв вШЯг ЧЭРзХЭШп, ЪЮвЮаЮХ СгФХв ЯЮЫгзХЭЮ Т аХЧгЫмвРвХ ХУЮ ТлзШбЫХЭШп. І вРЪШе бЫгзРпе Perl ТлСШаРХв ЮФЭЮ ШЧ ФТге аХиХЭШЩ: 1) ТлаРЦХЭШХ ЮСаРСРвлТРХвбп Т бЮЮвТХвбвТШШ б ЪЮЭвХЪбвЮЬ Ш ТЮЧТаРйРХв ЮЦШФРХЬлЩ вШЯ; 2) аХЧгЫмвРв ЯаХЮСаРЧгХвбп Ъ ЭгЦЭЮЬг вШЯг.
їаЮбвХЩиШЬ ЯаШЬХаЮЬ пТЫпХвбп ЮЯХаРвЮа дРЩЫЮТЮУЮ ТТЮФР/ТлТЮФР (ЭРЯаШЬХа, <MYDATA>). І бЯШбЪЮТЮЬ ЪЮЭвХЪбвХ ЮЭ ТЮЧТаРйРХв бЯШбЮЪ ТбХе (ЮбвРТиШебп) бваЮЪ дРЩЫР. І бЪРЫпаЭЮЬ ЪЮЭвХЪбвХ ТЮЧТаРйРХвбп бЫХФгойРп бваЮЪР.
јЭЮУШХ ЪЮЭбвагЪжШШ Perl ЮСаРСРвлТРовбп Т бЮЮвТХвбвТШШ б ЪЮЭвХЪбвЮЬ, Ш ЮЯХаРвЮал аХУгЫпаЭле ТлаРЦХЭШЩ ЭХ пТЫповбп ШбЪЫозХЭШХЬ. ЅРЯаШЬХа, ЮЯХаРвЮа m/…/ Т ЮФЭШе бШвгРжШпе ТЮЧТаРйРХв ЯаЮбвго ЫЮУШзХбЪго ТХЫШзШЭг «ШбвШЭР/ЫЮЦм», Р Т ФагУШе — бЯШбЮЪ бЮТЯРФХЭШЩ. їЮФаЮСЭЮбвШ СгФгв ЯаШТХФХЭл ЭШЦХ.
µбЫШ ЮСаРСЮвЪР ТлаРЦХЭШп Т бЯШбЪЮТЮЬ ЪЮЭвХЪбвХ ФРХв бЪРЫпаЭлЩ аХЧгЫмвРв, РТвЮЬРвШзХбЪШ бЮЧФРХвбп бЯШбЮЪ, бЮбвЮпйШЩ ШЧ ЮФЭЮУЮ нЫХЬХЭвР. ВРЪШЬ ЮСаРЧЮЬ, ЪЮЬРЭФР @a=42 нЪТШТРЫХЭвЭР @a=(42). Б ФагУЮЩ бвЮаЮЭл, ЮСйШе ЯаРТШЫ ЯаХЮСаРЧЮТРЭШп бЯШбЪР Т бЪРЫпа ЭХ бгйХбвТгХв. ЅРЯаШЬХа, ФЫп ЫШвХаРЫмЭЮУЮ бЯШбЪР:
$ver = (this, &is, 0xA, 'list');
ЯХаХЬХЭЭЮЩ $var ЯаШбТРШТРХвбп ЯЮбЫХФЭШЩ нЫХЬХЭв, 'list'. І ЪЮЬРЭФХ ТШФР $var=@array ЯХаХЬХЭЭЮЩ $var ЯаШбТРШТРХвбп ФЫШЭР ЬРббШТР.
І Perl бгйХбвТгХв ФТР вШЯР ЯХаХЬХЭЭле: УЫЮСРЫмЭлХ Ш ЧРЪалвлХ[22] (private). ·РЪалвлХ ЯХаХЬХЭЭлХ, ЯЮпТШТиШХбп вЮЫмЪЮ Т Perl5, ЮСкпТЫповбп ФШаХЪвШТЮЩ my(…). іЫЮСРЫмЭлХ ЯХаХЬХЭЭлХ ТЮЮСйХ ЭХ ЮСкпТЫповбп, Р ЯаЮбвЮ бгйХбвТгов, ЭРзШЭРп б ЬЮЬХЭвР ШбЯЮЫмЧЮТРЭШп. іЫЮСРЫмЭлХ ЯХаХЬХЭЭлХ ФЮбвгЯЭл Т ЫоСЮЩ вЮзЪХ ЯаЮУаРЬЬл, Р ЧРЪалвлХ ЯХаХЬХЭЭлХ б вЮзЪШ ЧаХЭШп ЫХЪбШЪШ ЮбвРовбп ФЮбвгЯЭлЬШ ФЮ ЪЮЭжР ТЭХиЭХУЮ СЫЮЪР. ґагУШЬШ бЫЮТРЬШ, б ЧРЪалвлЬШ ЯХаХЬХЭЭлЬШ ЬЮЦХв аРСЮвРвм вЮЫмЪЮ ЪЮФ Perl, аРбЯЮЫЮЦХЭЭлЩ ЬХЦФг бЮЮвТХвбвТгойШЬ ЮСкпТЫХЭШХЬ my Ш ЪЮЭжЮЬ ЯаЮУаРЬЬЭЮУЮ СЫЮЪР, ТЭгваШ ЪЮвЮаЮУЮ аРбЯЮЫЮЦХЭЮ ЮСкпТЫХЭШХ my.
ґШЭРЬШзХбЪРп ТШФШЬЮбвм — ШЭвХаХбЭРп ЪЮЭжХЯжШп, ЮвбгвбвТгойРп ТЮ ЬЭЮУШе пЧлЪРе ЯаЮУаРЬЬШаЮТРЭШп. ѕ вЮЬ, ЪРЪЮХ ЮвЭЮиХЭШХ ЮЭР ШЬХХв Ъ аХУгЫпаЭлЬ ТлаРЦХЭШпЬ, СгФХв аРббЪРЧРЭЮ ЭШЦХ. АХзм ШФХв Ю вЮЬ, звЮ Perl ЬЮЦХв бЮеаРЭШвм УЫЮСРЫмЭго ЯХаХЬХЭЭго, ЪЮвЮаРп ФЮЫЦЭР ШЧЬХЭШвмбп, Ш РТвЮЬРвШзХбЪШ ТЮббвРЭЮТШвм ШбеЮФЭЮХ ЧЭРзХЭШХ ЪЮЯШо Т ЬЮЬХЭв ЧРТХаиХЭШп ТЭХиЭХУЮ СЫЮЪР. БЮеаРЭХЭШХ ЪЮЯШШ ЭРЧлТРХвбп бЮЧФРЭШХЬ ЭЮТЮЩ ФШЭРЬШзХбЪЮЩ ЮСЫРбвШ ТШФШЬЮбвШ. НвР ТЮЧЬЮЦЭЮбвм ШбЯЮЫмЧгХвбп ЯЮ ЭХбЪЮЫмЪШЬ ЯаШзШЭРЬ, Т вЮЬ зШбЫХ:
l І ЯХаТЮЭРзРЫмЭЮЬ ТРаШРЭвХ Perl ЭХ бгйХбвТЮТРЫЮ ЫЮЪРЫмЭле ЯХаХЬХЭЭле, СлЫШ вЮЫмЪЮ УЫЮСРЫмЭлХ. µбЫШ ТРЬ ЯЮЭРФЮСШЫРбм ТаХЬХЭЭРп ЯХаХЬХЭЭРп, ЯаШеЮФШЫЮбм ШбЯЮЫмЧЮТРвм УЫЮСРЫмЭго ЯХаХЬХЭЭго Ш аШбЪЮТРвм ЪЮЭдЫШЪвРЬШ ШЬХЭ Т вЮЬ бЫгзРХ, ХбЫШ ТРЬ ЭХ ЯЮТХЧХв Ш ТлСаРЭЭЮХ ШЬп СгФХв ШбЯЮЫмЧЮТРвмбп ЪХЬ-вЮ ХйХ. ±ЫРУЮФРап бЮеаРЭХЭШо Ш ТЮббвРЭЮТЫХЭШо ШЧЬХЭХЭШХ УЫЮСРЫмЭЮЩ ЯХаХЬХЭЭЮЩ ЮУаРЭШзШТРЫЮбм ХХ ТаХЬХЭЭлЬ ШбЯЮЫмЧЮТРЭШХЬ.
l µбЫШ УЫЮСРЫмЭРп ЯХаХЬХЭЭРп ЯаХФбвРТЫпХв «вХЪгйХХ бЮбвЮпЭШХ» (ЭРЯаШЬХа, ШЬп дРЩЫР, ЮСаРСРвлТРХЬЮУЮ Т ФРЭЭлЩ ЬЮЬХЭв), ШЭЮУФР ТЮЧЭШЪРХв ЭХЮСеЮФШЬЮбвм ТЮ ТаХЬХЭЭЮЩ ЬЮФШдШЪРжШШ нвЮУЮ бЮбвЮпЭШп. ЅРЯаШЬХа, ТЮ ТаХЬп ЮСаРСЮвЪШ ФШаХЪвШТл ТЪЫозХЭШп дРЩЫР «вХЪгйХХ ШЬп» ФЮЫЦЭЮ бЮЮвТХвбвТЮТРвм ШЬХЭШ ТЪЫозРХЬЮУЮ дРЩЫР, Р ЯЮбЫХ ХХ ЧРТХаиХЭШп ЮЭЮ ФЮЫЦЭЮ ТХаЭгвмбп Ъ ШбеЮФЭЮЬг бЮбвЮпЭШо. їаШ ШбЯЮЫмЧЮТРЭШШ ФШЭРЬШзХбЪЮЩ ТШФШЬЮбвШ бЮеаРЭХЭШХ Ш ТЮббвРЭЮТЫХЭШХ ЯаЮШбеЮФШв РТвЮЬРвШзХбЪШ.
їХаТРп ЯаШзШЭР Т ЭРиШ ФЭШ ЯХаХбвРЫР Слвм РЪвгРЫмЭЮЩ, ЯЮбЪЮЫмЪг Т Perl ЯЮпТШЫШбм ЭЮаЬРЫмЭлХ ЫЮЪРЫмЭлХ ЯХаХЬХЭЭлХ, ЮСкпТЫпХЬлХ ФШаХЪвШТЮЩ my. ґШаХЪвШТР my бЮЧФРХв ЭЮТго ЯХаХЬХЭЭго, ЪЮвЮаРп ЭШЪРЪ ЭХ бТпЧРЭР ЭШ б ЮФЭЮЩ ЯХаХЬХЭЭЮЩ, бгйХбвТгойХЩ Т ЯаЮУаРЬЬХ. їапЬЮЩ ФЮбвгЯ Ъ нвЮЩ ЯХаХЬХЭЭЮЩ ТЮЧЬЮЦХЭ вЮЫмЪЮ Т ЯаЮУаРЬЬЭЮЬ ЪЮФХ, аРбЯЮЫЮЦХЭЭЮЬ ЬХЦФг ФШаХЪвШТЮЩ my Ш ЪЮЭжЮЬ ТЭХиЭХУЮ СЫЮЪР.
ёЬп дгЭЪжШШ local СлЫЮ ТлСаРЭЮ ЭР аХФЪЮбвм ЭХгФРзЭЮ. НвР дгЭЪжШп бЮЧФРХв ЭЮТго ФШЭРЬШзХбЪго ЮСЫРбвм ТШФШЬЮбвШ. П ФЮЫЦХЭ баРЧг ЧРпТШвм, звЮ ТлЧЮТ local ЭХ бЮЧФРХв ЭЮТЮЩ ЯХаХЬХЭЭЮЩ. µбЫШ г ТРб ШЬХХвбп УЫЮСРЫмЭРп ЯХаХЬХЭЭРп, local ТлЯЮЫЭпХв ваШ ЮЯХаРжШШ:
1. БЮеаРЭХЭШХ ТЭгваХЭЭХЩ ЪЮЯШШ ЧЭРзХЭШп ЯХаХЬХЭЭЮЩ.
2. єЮЯШаЮТРЭШХ ЭЮТЮУЮ ЧЭРзХЭШп Т ЯХаХЬХЭЭго (undef ШЫШ ЧЭРзХЭШп, гЪРЧРЭЭЮУЮ ЯаШ ТлЧЮТХ local).
3. ІЮббвРЭЮТЫХЭШХ ШбеЮФЭЮУЮ ЧЭРзХЭШп ЯХаХЬХЭЭЮЩ ЯаШ ТлеЮФХ ЧР ЯаХФХЫл СЫЮЪР, Т ЪЮвЮаЮЬ ЭРеЮФШвбп ТлЧЮТ local.
ВРЪШЬ ЮСаРЧЮЬ, «ЫЮЪРЫмЭЮбвм» Т ФРЭЭЮЬ бЫгзРХ ЮвЭЮбШвбп ЫШим Ъ ТаХЬХЭШ, Т вХзХЭШХ ЪЮвЮаЮУЮ СгФгв бгйХбвТЮТРвм ШЧЬХЭХЭШп, ТЭХбХЭЭлХ Т ЯХаХЬХЭЭго. іЫЮСРЫмЭРп ЯХаХЬХЭЭРп, ЧЭРзХЭШХ ЪЮвЮаЮЩ СлЫЮ бЪЮЯШаЮТРЭЮ, ЯЮ-ЯаХЦЭХЬг ТШФЭР ШЧ ЫоСЮЩ вЮзЪШ ЯаЮУаРЬЬл — ХбЫШ ЯЮбЫХ бЮЧФРЭШп ЭЮТЮЩ ФШЭРЬШзХбЪЮЩ ЮСЫРбвШ ТШФШЬЮбвШ ТлЧТРвм дгЭЪжШо, ТЭХбХЭЭлХ ШЧЬХЭХЭШп СгФгв ТШФЭл Т нвЮЩ дгЭЪжШШ. І нвЮЬ ЮвЭЮиХЭШШ ЯХаХЬХЭЭРп ЭШзХЬ ЭХ ЮвЫШзРХвбп Юв ЮСлзЭле УЫЮСРЫмЭле ЯХаХЬХЭЭле. ѕвЫШзШХ ЧРЪЫозРХвбп Т вЮЬ, звЮ ЯЮбЫХ ЧРТХаиХЭШп ТЭХиЭХУЮ СЫЮЪР РТвЮЬРвШзХбЪШ ТЮббвРЭРТЫШТРХвбп ЯаХФлФгйХХ ЧЭРзХЭШХ.
°ТвЮЬРвШзХбЪЮХ бЮеаРЭХЭШХ Ш ТЮббвРЭЮТЫХЭШп ЧЭРзХЭШп ЯХаХЬХЭЭЮЩ — ТЮв, Т бгйЭЮбвШ, Ш ТбХ, звЮ ЯаЮШбеЮФШв ЯаШ ТлЧЮТХ local. ЕЮвп ЯаШ ШбЯЮЫмЧЮТРЭШШ local зРбвЮ ТЮЧЭШЪРов ЭХФЮаРЧгЬХЭШп, ЭР бРЬЮЬ ФХЫХ нвР дгЭЪжШп нЪТШТРЫХЭвЭР даРУЬХЭвг, ЯаШТХФХЭЭЮЬг Т ЯаРТЮЬ бвЮЫСжХ вРСЫ. 7.3.
ВРСЫШжР 7.3. БЬлбЫ дгЭЪжШШ local
|
ѕСлзЭлЩ ЪЮФ Perl |
НЪТШТРЫХЭвЭлЩ даРУЬХЭв |
|
{ local($SomeVar); # БЮеаРЭШвм ЪЮЯШо $SomeVar = 'My Value'; … } # °ТвЮЬРвШзХбЪЮХ # ТЮббвРЭЮТЫХЭШХ $SomeVar |
{ my $TempCopy = $SomeVar; $SomeVar = undef; $SomeVar = 'My Value'; … $SomeVar = $TempCopy; } |
ґЫп гФЮСбвТР ЪЮЭбвагЪжШШ local($SomeVar) ЬЮЦЭЮ ЯаШбТЮШвм ЭЮТЮХ ЧЭРзХЭШХ; нвЮ Т вЮзЭЮбвШ нЪТШТРЫХЭвЭЮ ЯаШбТРШТРЭШо ЧЭРзХЭШп $SomeVar ТЬХбвЮ ЯаШбТРШТРЭШп undef Т вРСЫ. 7.3. єаЮЬХ вЮУЮ, Тл ЬЮЦХвХ ЮЯгбвШвм ЪагУЫлХ бЪЮСЪШ, звЮСл дЮабШаЮТРвм бЪРЫпаЭлЩ ЪЮЭвХЪбв.
БблЫЪШ ЭР $SomeVar Т УаРЭШжРе СЫЮЪР, Р вРЪЦХ Т дгЭЪжШпе, ТлЧТРЭЭле ШЧ СЫЮЪР, ШЫШ ШЭШжШШаЮТРЭЭле ШЧ ЭХУЮ ЮСаРСЮвзШЪРе бШУЭРЫЮТ — ЪЮаЮзХ, ЫоСлХ бблЫЪШ Юв ЬЮЬХЭвР ТлЧЮТР local ФЮ ЬЮЬХЭвР ТлеЮФР ШЧ СЫЮЪР — СгФгв ЮвЭЮбШвмбп Ъ ТХЫШзШЭХ 'MyspcValue'. µбЫШ ЪЮФ ТЭгваШ СЫЮЪР (ШЫШ УФХ-вЮ ХйХ) ЬЮФШдШжШагХв $SomeVar, нвЮ ШЧЬХЭХЭШХ ЮваРЧШвбп ТХЧФХ (Т вЮЬ зШбЫХ Ш Т ЯаЮУаРЬЬЭЮЬ ЪЮФХ СЫЮЪР), ЭЮ ЯаШ ТлеЮФХ ШЧ СЫЮЪР ЮЭЮ СгФХв гваРзХЭЮ б ТЮббвРЭЮТЫХЭШХЬ ШбеЮФЭЮЩ ЪЮЯШШ.
їаХФЯЮЫЮЦШЬ, ТРЬ ЯаШеЮФШвбп ТлЧлТРвм дгЭЪжШо ШЧ ЭХСаХЦЭЮ ЭРЯШбРЭЭЮЩ СШСЫШЮвХЪШ. ДгЭЪжШп УХЭХаШагХв ЬЭЮЦХбвТЮ ЯаХФгЯаХЦФХЭШЩ Use of uninitialized warnings. Іл, ЪРЪ Ш ТбХ ЯЮапФЮзЭлХ ЯаЮУаРЬЬШбвл Perl, ШбЯЮЫмЧгХвХ ЪЫоз -w, ЭЮ РТвЮа СШСЫШЮвХЪШ нвЮУЮ, ТШФШЬЮ, ЭХ бФХЫРЫ. їаХФгЯаХЦФХЭШп ТлЧлТРов г ТРб ЭРаРбвРойХХ аРЧФаРЦХЭШХ, ЭЮ звЮ ФХЫРвм, ХбЫШ ШЧЬХЭШвм СШСЫШЮвХЪг ЭХТЮЧЬЮЦЭЮ — ЯЮЫЭЮбвмо ЮвЪРЧРвмбп Юв ШбЯЮЫмЧЮТРЭШп -w? јЮЦЭЮ ТЮбЯЮЫмЧЮТРвмбп ЯаЮУаРЬЬЭлЬ дЫРУЮЬ ТлФРзШ ЯаХФгЯаХЦФХЭШЩ $^W<$M[R7-63]> (ШЬп ЯХаХЬХЭЭЮЩ ^W ЬЮЦХв бЮбвЮпвм ШЧ ФТге бШЬТЮЫЮТ, «ЪалиЪР» Ш W, ШЫШ ШЧ ЮФЭЮУЮ бШЬТЮЫР Control+W):
{
local $^W = 0; # ѕвЪЫозШвм ТлФРзг ЯаХФгЯаХЦФХЭШЩ
&unruly_function(…);
}
# їаШ ТлеЮФХ ШЧ СЫЮЪР ТЮббвРЭРТЫШТРХвбп ШбеЮФЭЮХ ЧЭРзХЭШХ $^W
ІлЧЮТ local бЮеаРЭпХв ТЭгваХЭЭоо ЪЮЯШо ЯаХФлФгйХУЮ ЧЭРзХЭШп УЫЮСРЫмЭЮЩ ЯХаХЬХЭЭЮЩ $^W, ЪРЪШЬ Сл ЮЭЮ ЭШ СлЫЮ. ·РвХЬ вЮЩ ЦХ ЯХаХЬХЭЭЮЩ $^W ЯаШбТРШТРХвбп ЭЮТЮХ ЭгЫХТЮХ ЧЭРзХЭШХ. їаШ ТлЯЮЫЭХЭШШ unruly_function Perl ЯаЮТХапХв ЯХаХЬХЭЭго $^W, ЭРеЮФШв ЯаШбТЮХЭЭлЩ ХЩ ЭЮЫм Ш ЭХ ТлФРХв ЯаХФгЯаХЦФХЭШЩ. їаШ ТЮЧТаРйХЭШШ ШЧ дгЭЪжШШ ЯХаХЬХЭЭРп ЯЮ-ЯаХЦЭХЬг аРТЭР ЭгЫо.
їЮЪР ТбХ ШФХв вРЪ, бЫЮТЭЮ ЭШЪРЪЮУЮ ТлЧЮТР local ЭХ СлЫЮ. ЅЮ ЯаШ ТлеЮФХ ШЧ СЫЮЪР ЯЮбЫХ ТЮЧТаРйХЭШп ШЧ дгЭЪжШШ unruly_function ТЮббвРЭРТЫШТРХвбп бЮеаРЭХЭЭЮХ ЧЭРзХЭШХ $^W. ЅРиХ ШЧЬХЭХЭШХ СлЫЮ ТаХЬХЭЭлЬ Ш ФХЩбвТЮТРЫЮ ЫШим ЭР ТаХЬп ТлЯЮЫЭХЭШп СЫЮЪР. Іл ЬЮЦХвХ ТагзЭго ФЮСШвмбп вЮУЮ ЦХ нддХЪвР, бЮеаРЭпп Ш ТЮббвРЭРТЫШТРп ЧЭРзХЭШХ нвЮЩ ЯХаХЬХЭЭЮЩ (бЬ. вРСЫ. 7.3), ЭЮ дгЭЪжШп local ФХЫРХв нвЮ ЧР ТРб.
ґЫп ЯЮЫЭЮвл ЪРавШЭл ФРТРЩвХ ЯЮбЬЮваШЬ, звЮ ЯаЮШЧЮЩФХв, ХбЫШ ТЬХбвЮ local ШбЯЮЫмЧгХвбп my[23]. ґШаХЪвШТР my бЮЧФРХв ЭЮТго ЯХаХЬХЭЭго, ЪЮвЮаРп ЯХаТЮЭРзРЫмЭЮ ШЬХХв ЭХЮЯаХФХЫХЭЭЮХ ЧЭРзХЭШХ. НвР ЯХаХЬХЭЭРп ТШФЭР вЮЫмЪЮ Т вЮЬ ЫХЪбШзХбЪЮЬ СЫЮЪХ, Т ЪЮвЮаЮЬ ЮЭР СлЫР ЮСкпТЫХЭР (вЮ Хбвм Т ЯаЮУаРЬЬЭЮЬ ЪЮФХ ЬХЦФг my Ш ЪЮЭжЮЬ ТЭХиЭХУЮ СЫЮЪР). ѕФЭРЪЮ ЯЮпТЫХЭШХ ЭЮТЮЩ ЯХаХЬХЭЭЮЩ ЭШЪРЪ ЭХ бЪРЧлТРХвбп ЭР ФагУШе ЯХаХЬХЭЭле, Т вЮЬ зШбЫХ Ш ЭР бгйХбвТгойШе УЫЮСРЫмЭле ЯХаХЬХЭЭле б вХЬ ЦХ ШЬХЭХЬ. ІЭЮТм бЮЧФРЭЭРп ЯХаХЬХЭЭРп ЮбвРЭХвбп ЭХТШФШЬЮЩ ФЫп ЯаЮУаРЬЬл, Т вЮЬ зШбЫХ Ш Т unruly_function. І ЯаШТХФХЭЭЮЬ даРУЬХЭвХ ЭЮТЮЩ ЯХаХЬХЭЭЮЩ $^W ЭХЬХФЫХЭЭЮ ЯаШбТРШТРХвбп ЭЮЫм, ЭЮ нвР ЯХаХЬХЭЭРп ЭШУФХ ЭХ ШбЯЮЫмЧгХвбп, ЯЮнвЮЬг ТбХ гбШЫШп ЮЪРЧлТРовбп ЭРЯаРбЭлЬШ (ТЮ ТаХЬп ТлЯЮЫЭХЭШп unruly_function Ш ЯаШЭпвШп аХиХЭШп Ю ТлФРзХ ЯаХФгЯаХЦФХЭШЩ Perl ЮСаРйРХвбп Ъ УЫЮСРЫмЭЮЩ ЯХаХЬХЭЭЮЩ $^W, ЪЮвЮаРп ЭШЪРЪ ЭХ бТпЧРЭР б ЯХаХЬХЭЭЮЩ, бЮЧФРЭЭЮЩ ЭРЬШ).
ґЫп local бгйХбвТгХв ЮФЭР ЯЮЫХЧЭРп РЭРЫЮУШп: Тл ЪРЪ Сл ЧРЪалТРХвХ ЯХаХЬХЭЭго ЯЫХЭЪЮЩ, ЭР ЪЮвЮаЮЩ ЬЮЦЭЮ ТаХЬХЭЭЮ ЧРЯШбРвм ШЧЬХЭХЭШп. ІбХ, ЪвЮ аРСЮвРХв б ЯХаХЬХЭЭЮЩ — ЭРЯаШЬХа, дгЭЪжШп ШЫШ ЮСаРСЮвзШЪ бШУЭРЫР — ТШФШв ХХ ЭЮТЮХ ЧЭРзХЭШХ. БвРаЮХ ЧЭРзХЭШХ ЧРЪалТРХвбп ФЮ ТлеЮФР ШЧ СЫЮЪР. І нвЮв ЬЮЬХЭв ЯЫХЭЪР РТвЮЬРвШзХбЪШ гСШаРХвбп, Ш ТЬХбвХ б ЭХЩ ШбзХЧРов ТбХ ШЧЬХЭХЭШп, ТЭХбХЭЭлХ ЯЮбЫХ ТлЧЮТР local.
ВРЪРп РЭРЫЮУШп УЮаРЧФЮ СЫШЦХ Ъ аХРЫмЭЮбвШ, зХЬ ШбеЮФЭЮХ ЮЯШбРЭШХ б «бЮЧФРЭШХЬ ТЭгваХЭЭХЩ ЪЮЯШШ». їаШ ТлЧЮТХ local Perl ЭХ бЮЧФРХв ЪЮЯШШ, Р ЫШим бвРТШв ЭЮТго ТХЫШзШЭг ЭР СЮЫХХ аРЭЭоо ЯЮЧШжШо Т бЯШбЪХ ЧЭРзХЭШЩ, ЯаЮТХапХЬле ЯаШ ЮСаРйХЭШШ Ъ ЯХаХЬХЭЭЮЩ (вЮ Хбвм «ЧРЪалТРХв» ЮаШУШЭРЫ). їаШ ТлеЮФХ ШЧ СЫЮЪР гФРЫповбп ТбХ «ЧРЪалТРойШХ» ЧЭРзХЭШп, ЧРЭХбХЭЭлХ Т бЯШбЮЪ ЯЮбЫХ ТеЮФР Т СЫЮЪ. їаШ ТлЧЮТХ local ЭЮТРп ФШЭРЬШзХбЪРп ЮСЫРбвм ТШФШЬЮбвШ бЮЧФРХвбп ЯаЮУаРЬЬШбвЮЬ, ЭЮ ФЫп ЭХЪЮвЮале ЯХаХЬХЭЭле нвЮ ЯаЮШбеЮФШв РТвЮЬРвШзХбЪШ. їаХЦФХ зХЬ ЯХаХеЮФШвм Ъ ЮваРЦХЭШо нвЮУЮ ТРЦЭЮУЮ РбЯХЪвР Т ЮСЫРбвШ аХУгЫпаЭле ТлаРЦХЭШЩ, п еЮзг ЯаХФбвРТШвм аРбиШаХЭЭлЩ ЯаШЬХа агзЭЮУЮ бЮЧФРЭШп ФШЭРЬШзХбЪЮЩ ЮСЫРбвШ ТШФШЬЮбвШ.
±ЮЫХХ аХРЫмЭлЩ Ш ЮвТХзРойШЩ «їгвШ Perl» ЯаШЬХа ЯаШТХФХЭ Т бЫХФгойХЬ ЫШбвШЭУХ. іЫРТЭРп дгЭЪжШп, ProcessFile, ЯЮЫгзРХв ШЬп дРЩЫР, ЮвЪалТРХв дРЩЫ Ш ЯЮбваЮзЭЮ ЮСаРСРвлТРХв еаРЭпйШХбп Т ЭХЬ ЪЮЬРЭФл. І нвЮЬ ЯаЮбвЮЬ ЯаШЬХаХ бгйХбвТгХв ТбХУЮ ваШ вШЯР ЪЮЬРЭФ, ЪЮвЮалХ ЮСаРСРвлТРовбп бЮЮвТХвбвТХЭЭЮ Т вЮзЪРе (6), (7) Ш (8). І ФРЭЭЮЬ бЫгзРХ ЭРб ШЭвХаХбгов УЫЮСРЫмЭлХ ЯХаХЬХЭЭлХ $filename, $command, $. Ш %HaveRead, Р вРЪЦХ УЫЮСРЫмЭлЩ дРЩЫЮТлЩ ЬРЭШЯгЫпвЮа FILE. їаШ ТлЧЮТХ ProcessFile ФЫп ТбХе ЯХаХЬХЭЭле, ЪаЮЬХ %HaveRead, бЮЧФРовбп ФШЭРЬШзХбЪШХ ЮСЫРбвШ ТШФШЬЮбвШ ТлЧЮТЮЬ local Т вЮзЪХ (3).
# ѕСаРСЮвЪР ЪЮЬРЭФл "this"
sub DoThis # (1)
{
print "$filename line $.: processing $command";
…
}
# ѕСаРСЮвЪР ЪЮЬРЭФл "that"
sub DoThat # (2)
{
print "$filename line $.: processing $command";
…
}
# ѕвЪалвм дРЩЫ ЯЮ ШЬХЭШ Ш ЮСаРСЮвРвм ЪЮЬРЭФл
sub ProcessFile
{
local($filename) = @_; # (3)
local(*FILE, $command, $.);
open(FILE, $filename) || die qq/can't open "$filename": $!\n/;
$HaveRead($filename) = 1; # (4)
while ($command = <FILE>)
{
if ($command =~ m/^#include "(.*)"$/) { # (5)
if (defined $HaveRead{$1}) {
warn qq/$filename $.: ignoring repeat include of "$1"\n/;
} else {
ProcessFile($1); # (6)
}
} elsif ($command =~ m/^do-this/) {
DoThis; # (7)
} elsif ($command =~ m/^do-that/) {
DoThat; # (8)
} else {
warn "$filename $.: unknown command: $command";
}
}
close(FILE);
} # (9)
їаШ ЮСЭРагЦХЭШШ ЪЮЬРЭФл do-this (7) ТлЧлТРХвбп дгЭЪжШп DoThis, ЪЮвЮаРп ЮСаРСРвлТРХв нвг ЪЮЬРЭФг. НвР дгЭЪжШп (1) бблЫРХвбп ЭР УЫЮСРЫмЭлХ ЯХаХЬХЭЭлХ $filename, $. Ш $command. ·ЭРзХЭШп ЯХаХЬХЭЭле, ТШФШЬлХ Т DoThis, СлЫШ ЯаШбТЮХЭл Т дгЭЪжШШ ProcessFile — ТЯаЮзХЬ, дгЭЪжШп DoThis ЮС нвЮЬ ЭХ ЧЭРХв, ФР нвЮ ФЫп ЭХХ Ш ЭХТРЦЭЮ.
ѕСаРСЮвЪР ЪЮЬРЭФл #include ЭРзШЭРХвбп б ТлФХЫХЭШп ШЬХЭШ дРЩЫР ШЧ бваЮЪШ (5). ГСХФШТиШбм, звЮ дРЩЫ ЭХ ЮСаРСРвлТРЫбп аРЭХХ, Ьл ЯаЮШЧТЮФШЬ аХЪгабШТЭлЩ ТлЧЮТ ProcessFile (6). їаШ ЭЮТЮЬ ТлЧЮТХ УЫЮСРЫмЭлХ ЯХаХЬХЭЭлХ $filename, $command Ш $., Р вРЪЦХ дРЩЫЮТлЩ ЬРЭШЯгЫпвЮа FILE, бЭЮТР «ЭРЪалТРовбп ЯЫХЭЪЮЩ», ЭР ЪЮвЮаЮЩ ТбЪЮаХ ЯЮпТЫповбп ШЧЬХЭХЭШп, ЮваРЦРойШХ бЮбвЮпЭШХ Ш ЪЮЬРЭФл ТвЮаЮУЮ дРЩЫР. І ЯаЮжХббХ ЮСаРСЮвЪШ ЪЮЬРЭФ ЭЮТЮУЮ дРЩЫР Т ProcessFile Ш ФТге ФагУШе дгЭЪжШпе $filename Ш ЮбвРЫмЭлХ ЯХаХЬХЭЭлХ ТШФЭл Т ЯаЮУаРЬЬХ, ЪРЪ Ш ЯаХЦФХ.
ЅР нвЮЩ бвРФШШ ТбХ ТлУЫпФШв вРЪ, бЫЮТЭЮ ЮЭШ пТЫповбп бРЬлЬШ ЮСлзЭлЬШ УЫЮСРЫмЭлЬШ ЯХаХЬХЭЭлЬШ.
їаХШЬгйХбвТР ФШЭРЬШзХбЪЮЩ ТШФШЬЮбвШ ЭРУЫпФЭЮ ЯаЮпТЫповбп Т вЮв ЬЮЬХЭв, ЪЮУФР ЮСаРСЮвЪР ТвЮаЮУЮ дРЩЫР ЧРТХаиРХвбп, Ш ЯаЮШбеЮФШв ТлеЮФ ШЧ бЮЮвТХвбвТгойХУЮ ТлЧЮТР ProcessFile. їаШ ТлеЮФХ ШЧ СЫЮЪР (9) «ЯЫХЭЪШ», ЭРЫЮЦХЭЭлХ Т вЮзЪХ 3, бЭШЬРовбп, ТЮббвРЭРТЫШТРп ЧЭРзХЭШп $filename Ш ФагУШе ЯХаХЬХЭЭле ФЫп ШбеЮФЭЮУЮ дРЩЫР. І зРбвЭЮбвШ, дРЩЫЮТлЩ ЬРЭШЯгЫпвЮа FILE вХЯХам бЭЮТР бблЫРХвбп ЭР ЯХаТлЩ дРЩЫ, Р ЭХ ЭР ТвЮаЮЩ.
ЅРЪЮЭХж, аРббЬЮваШЬ ЯХаХЬХЭЭго %HaveRead, ЯаХФЭРЧЭРзХЭЭго ФЫп ЮвбЫХЦШТРЭШп ЮСаРСЮвРЭЭле дРЩЫЮТ (4 Ш 5). ґЫп ЭХХ ФШЭРЬШзХбЪРп ЮСЫРбвм ТШФШЬЮбвШ ЭРЬХаХЭЭЮ ЭХ бЮЧФРХвбп, ЯЮбЪЮЫмЪг нвР ЯХаХЬХЭЭРп ФЮЫЦЭР Слвм УЫЮСРЫмЭЮЩ ЭР ТбХ ТаХЬп ТлЯЮЫЭХЭШп бжХЭРаШп. І ЯаЮвШТЭЮЬ бЫгзРХ ТЪЫозХЭЭлХ дРЩЫл СгФгв ЧРСлТРвмбп ЯаШ ТлеЮФХ ШЧ ProcessFile.
ЅЮ ЪРЪЮХ ЮвЭЮиХЭШХ ТбХ нвШ аРЧУЮТЮал Ю ФШЭРЬШзХбЪЮЩ ТШФШЬЮбвШ ШЬХов Ъ аХУгЫпаЭлЬ ТлаРЦХЭШпЬ? БРЬЮХ ЯапЬЮХ. І аХЧгЫмвРвХ гбЯХиЭЮУЮ бЮТЯРФХЭШп ЭХЪЮвЮалЬ ЯХаХЬХЭЭлЬ РТвЮЬРвШзХбЪШ ЯаШбТРШТРовбп ЧЭРзХЭШп — бТЮХУЮ аЮФР ЯЮСЮзЭлЩ нддХЪв. є зШбЫг нвШе ЯХаХЬХЭЭле, ЯЮФаЮСЭЮ ЮЯШбРЭЭле Т бЫХФгойХЬ аРЧФХЫХ, ЯаШЭРФЫХЦРв, ЭРЯаШЬХа, $& (вХЪбв бЮТЯРФХЭШп) Ш $1 (вХЪбв, бЮТЯРТиШЩ б ЯХаТлЬ ЯЮФТлаРЦХЭШХЬ Т ЪагУЫле бЪЮСЪРе). ґЫп нвШе ЯХаХЬХЭЭле ФШЭРЬШзХбЪРп ЮСЫРбвм ФХЩбвТШп бЮЧФРХвбп РТвЮЬРвШзХбЪШ ЯаШ ТеЮФХ Т ЪРЦФлЩ СЫЮЪ.
ЗвЮСл ЯЮЭпвм, ФЫп зХУЮ нвЮ ЭгЦЭЮ, бЫХФгХв гзШвлТРвм, звЮ ЪРЦФлЩ ТлЧЮТ дгЭЪжШШ ЮЯаХФХЫпХв ЭЮТлЩ СЫЮЪ. БЫХФЮТРвХЫмЭЮ, ФЫп вРЪШе ЯХаХЬХЭЭле ЯаШ нвЮЬ бЮЧФРХвбп ЭЮТРп ФШЭРЬШзХбЪРп ЮСЫРбвм ТШФШЬЮбвШ. їЮбЪЮЫмЪг ЧЭРзХЭШп, бгйХбвТЮТРТиШХ ЯХаХФ ТеЮФЮЬ Т СЫЮЪ, ТЮббвРЭРТЫШТРовбп ЯаШ ТлеЮФХ ШЧ ЭХУЮ (вЮ Хбвм ЯаШ ТЮЧТаРвХ ШЧ дгЭЪжШШ), дгЭЪжШп ЭХ бЬЮЦХв ШЧЬХЭШвм ЧЭРзХЭШп, ТШФШЬлХ ТлЧлТРойХЩ бвЮаЮЭХ.
І ЪРзХбвТХ ЯаШЬХаР аРббЬЮваШЬ бЫХФгойШЩ даРУЬХЭв:
if (m/(…)/)
{
&do_some_other_stuff();
print "the matched text was $1.\n";
}
їЮбЪЮЫмЪг ФЫп ЯХаХЬХЭЭЮЩ $1 ЭЮТРп ФШЭРЬШзХбЪРп ЮСЫРбвм ФХЩбвТШп бЮЧФРХвбп РТвЮЬРвШзХбЪШ ЯаШ ЪРЦФЮЬ ТеЮФХ Т СЫЮЪ, нвЮв даРУЬХЭв ЭХ ЧЭРХв (ФР Ш ЭХ еЮзХв ЧЭРвм), ШЧЬХЭпХв ЫШ дгЭЪжШп do_some_other_stuff ЧЭРзХЭШХ $1 ШЫШ ЭХв. ІбХ ШЧЬХЭХЭШп, ТЭЮбШЬлХ Т $1 нвЮЩ дгЭЪжШХЩ, ЮУаРЭШзШТРовбп СЫЮЪЮЬ, ЮЯаХФХЫпХЬлЬ нвЮЩ дгЭЪжШХЩ, ШЫШ, ТЮЧЬЮЦЭЮ, ЭХЪЮвЮалЬ ХУЮ ТЫЮЦХЭЭлЬ СЫЮЪЮЬ. ВРЪШЬ ЮСаРЧЮЬ, ЮЭШ ЭХ ЬЮУгв ЯЮТЫШпвм ЭР ЧЭРзХЭШХ, ТШФШЬЮХ Т ЪЮЬРЭФХ print ЯЮбЫХ ТЮЧТаРйХЭШп ШЧ дгЭЪжШШ.
°ТвЮЬРвШзХбЪЮХ бЮЧФРЭШХ ФШЭРЬШзХбЪЮЩ ЮСЫРбвШ ТШФШЬЮбвШ ЯаШЭЮбШв ЯЮЫмЧг Ш Т ЬХЭХХ ЮзХТШФЭле бШвгРжШпе:
if ($result =~ m/ERROR=(.*)/) {
warn "Hey, tell $Config{perladmin} about $1!\n";
}
(І бвРЭФРавЭЮЬ СШСЫШЮвХзЭЮЬ ЬЮФгЫХ Config ЮЯаХФХЫпХвбп РббЮжШРвШТЭлЩ ЬРббШТ %Config, нЫХЬХЭв ЪЮвЮаЮУЮ $Config{perladmin} бЮФХаЦШв РФаХб нЫХЪваЮЭЭЮЩ ЯЮзвл ЫЮЪРЫмЭЮУЮ Perl-ЬРбвХаР). µбЫШ Сл ЧЭРзХЭШХ ЯХаХЬХЭЭЮЩ $1 ЭХ бЮеаРЭпЫЮбм, нвЮв ЪЮФ ЯаХЯЮФЭХб Сл ТРЬ боаЯаШЧ. ґХЫЮ Т вЮЬ, звЮ %Config Т ФХЩбвТШвХЫмЭЮбвШ пТЫпХвбп бТпЧРЭЭЮЩ ЯХаХЬХЭЭЮЩ; нвЮ ЮЧЭРзРХв, звЮ ЯаШ ЫоСЮЩ бблЫЪХ ЭР нвг ЯХаХЬХЭЭго ЯаЮШбеЮФШв РТвЮЬРвШзХбЪШЩ ТлЧЮТ дгЭЪжШШ. І ФРЭЭЮЬ бЫгзРХ дгЭЪжШп, ЮбгйХбвТЫпойРп ТлСЮаЪг ЭгЦЭЮУЮ ЧЭРзХЭШп ФЫп $Config{…}, ШбЯЮЫмЧгХв аХУгЫпаЭЮХ ТлаРЦХЭШХ. їЮбЪЮЫмЪг нвР ЮЯХаРжШп ЯЮШбЪР ТлЯЮЫЭпХвбп ЬХЦФг ТРиХЩ ЮЯХаРжШХЩ ЯЮШбЪР Ш ТлТЮФЮЬ $1, ЯаШ ЮвбгвбвТШШ ФШЭРЬШзХбЪЮЩ ЮСЫРбвШ ТШФШЬЮбвШ ЮЭР ШбЯЮавШЫР Сл ЧЭРзХЭШХ $1, ЪЮвЮаЮХ Тл бЮСШаРЫШбм ШбЯЮЫмЧЮТРвм. є бзРбвмо, ЫоСлХ ШЧЬХЭХЭШп, ТЭХбХЭЭлХ Т дгЭЪжШШ $Config{…}, ЭРФХЦЭЮ ШЧЮЫШаговбп СЫРУЮФРап ФШЭРЬШзХбЪЮЩ ТШФШЬЮбвШ.
їаШ ЯаЮФгЬРЭЭЮЬ ШбЯЮЫмЧЮТРЭШШ ФШЭРЬШзХбЪРп ТШФШЬЮбвм ЯаШЭЮбШв ЭХЬРЫго ЯЮЫмЧг, ЭЮ ЫХУЪЮЬлбЫХЭЭЮХ ЯаШЬХЭХЭШХ local ЬЮЦХв ЯаХТаРвШвм бЮЯаЮТЮЦФХЭШХ ЪЮФР Т бгйШЩ ЪЮиЬРа. єРЪ гЯЮЬШЭРЫЮбм ТлиХ, ЮСкпТЫХЭШХ my(…) бЮЧФРХв ЧРЪалвго ЯХаХЬХЭЭго б ЫХЪбШзХбЪЮЩ ТШФШЬЮбвмо. »ХЪбШзХбЪРп ТШФШЬЮбвм ЧРЪалвЮЩ ЯХаХЬХЭЭЮЩ пТЫпХвбп ЯаЮвШТЮЯЮЫЮЦЭЮбвмо УЫЮСРЫмЭЮЩ ТШФШЬЮбвШ УЫЮСРЫмЭле ЯХаХЬХЭЭле, ЮФЭРЪЮ ЮЭР ЭХ ШЬХХв ЮвЭЮиХЭШп Ъ ФШЭРЬШзХбЪЮЩ ТШФШЬЮбвШ (ХбЫШ ЭХ бзШвРвм вЮУЮ, звЮ Ъ ЯХаХЬХЭЭлЬ my ЭХЫмЧп ЯаШЬХЭпвм local). їЮЬЭШвХ: local — нвЮ ФХЩбвТШХ, Р my — нвЮ ФХЩбвТШХ Ш ЮСкпТЫХЭШХ.
<$R[P#,R7-34]>їаШ гбЯХиЭЮЬ ТлЯЮЫЭХЭШШ ЯЮШбЪР ШЫШ ЧРЬХЭл РТвЮЬРвШзХбЪШ ЯаШбТРШТРовбп ЧЭРзХЭШп ЭХЪЮвЮале УЫЮСРЫмЭле, ФЮбвгЯЭле вЮЫмЪЮ ФЫп звХЭШп ЯХаХЬХЭЭле, ФЫп ЪЮвЮале РТвЮЬРвШзХбЪШ бЮЧФРХвбп ЭЮТРп ФШЭРЬШзХбЪРп ЮСЫРбвм ТШФШЬЮбвШ [1 б. <$R[P#,R7-37]>][24]. ·ЭРзХЭШп нвШе ЯХаХЬХЭЭле ЭШЪЮУФР ЭХ ШЧЬХЭповбп Т вЮЬ бЫгзРХ, ХбЫШ бЮТЯРФХЭШХ ЭХ ЭРЩФХЭЮ, Ш ТбХУФР ШЧЬХЭповбп Т бЫгзРХ, ХбЫШ бЮТЯРФХЭШХ ЭРеЮФШвбп. І ЭХЪЮвЮале бЫгзРпе ЯХаХЬХЭЭлЬ ЬЮЦХв Слвм ЯаШбТЮХЭР ЯгбвРп бваЮЪР (вЮ Хбвм бваЮЪР, ЭХ бЮФХаЦРйРп ЭШ ЮФЭЮУЮ бШЬТЮЫР) ШЫШ ЭХЮЯаХФХЫХЭЭЮХ<$M[R7-131]> ЧЭРзХЭШХ (ЯЮеЮЦХХ ЭР Ягбвго бваЮЪг, ЭЮ ЯаШЭжШЯШРЫмЭЮ ЮвЫШзРойХХбп Юв ЭХХ).
l $& єЮЯШп вХЪбвР, гбЯХиЭЮ бЮТЯРТиХУЮ б аХУгЫпаЭлЬ ТлаРЦХЭШХЬ. ёбЯЮЫмЧЮТРвм нвг ЯХаХЬХЭЭго (ТЬХбвХ б ФагУШЬШ ЯХаХЬХЭЭлЬШ $` Ш $') ЭХ аХЪЮЬХЭФгХвбп (бЬ. аРЧФХЫ «ЅХЦХЫРвХЫмЭРп ЯХаХЬХЭЭРп $& Ш ХХ ФагЧмп» ЭР б. <$R[P#,R7-3]>). І бЫгзРХ гбЯХиЭЮУЮ бЮТЯРФХЭШп ЯХаХЬХЭЭЮЩ $& ЭШЪЮУФР ЭХ ЯаШбТРШТРХвбп ЭХЮЯаХФХЫХЭЭЮХ ЧЭРзХЭШХ.
l $` єЮЯШп жХЫХТЮУЮ вХЪбвР, ЯаХФиХбвТгойХУЮ ЭРзРЫг бЮТЯРФХЭШп (вЮ Хбвм аРбЯЮЫЮЦХЭЭЮУЮ бЫХТР Юв ЭХУЮ). І бЮзХвРЭШШ б ЬЮФШдШЪРвЮаЮЬ /g ШЭЮУФР СлТРХв ЭгЦЭЮ, звЮСл Т ЯХаХЬХЭЭЮЩ $` еаРЭШЫбп вХЪбв Юв ЭРзРЫмЭЮЩ ЯЮЧШжШШ ЯЮШбЪР, Р ЭХ Юв ЭРзРЫР бваЮЪШ. є бЮЦРЫХЭШо, ЯХаХЬХЭЭРп аРСЮвРХв ЭХ вРЪ<$M[R7-40]> [2 б. <$R[P#,R7-39]>]. µбЫШ Тл еЮвШвХ ТЮбЯаЮШЧТХбвШ вРЪЮХ ЯЮТХФХЭШХ, ЯЮЯаЮСгЩвХ ЯЮбвРТШвм ЯХаХФ аХУгЫпаЭлЬ ТлаРЦХЭШХЬ [\G([\x00-\xff]*?)] Ш ЧРвХЬ бЮбЫРвмбп ЭР $1. І бЫгзРХ гбЯХиЭЮУЮ бЮТЯРФХЭШп ЯХаХЬХЭЭЮЩ $` ЭШЪЮУФР ЭХ ЯаШбТРШТРХвбп ЭХЮЯаХФХЫХЭЭЮХ ЧЭРзХЭШХ.
l $' єЮЯШп жХЫХТЮУЮ вХЪбвР, бЫХФгойХУЮ ЯЮбЫХ бЮТЯРФХЭШп (вЮ Хбвм аРбЯЮЫЮЦХЭЭЮУЮ бЯаРТР Юв ЭХУЮ). їЮбЫХ гбЯХиЭЮУЮ бЮТЯРФХЭШп бваЮЪР "$`$&$'" ТбХУФР ЯаХФбвРТЫпХв бЮСЮЩ ЪЮЯШо ШбеЮФЭЮУЮ жХЫХТЮУЮ вХЪбвР[25]. І бЫгзРХ гбЯХиЭЮУЮ бЮТЯРФХЭШп ЯХаХЬХЭЭЮЩ $' ЭШЪЮУФР ЭХ ЯаШбТРШТРХвбп ЭХЮЯаХФХЫХЭЭЮХ ЧЭРзХЭШХ.
l $1, $2, $3 Ш в. Ф. ВХЪбв, бЮТЯРТиШЩ б ЯХаТЮЩ, ТвЮаЮЩ, ваХвмХЩ Ш в. Ф. ЯРаЮЩ бЮеаРЭпойШе ЪагУЫле бЪЮСЮЪ (ЮСаРвШвХ ТЭШЬРЭШХ: ЯХаХЬХЭЭРп $0 Т бЯШбЮЪ ЭХ ТеЮФШв — Т ЭХЩ еаРЭШвбп ЪЮЯШп ШЬХЭШ бжХЭРаШп, Ш нвР ЯХаХЬХЭЭРп ЭХ ШЬХХв ЮвЭЮиХЭШп Ъ аХУгЫпаЭлЬ ТлаРЦХЭШпЬ). µбЫШ ЯХаХЬХЭЭРп ЮвЭЮбШвбп Ъ ЯРаХ бЪЮСЮЪ, ЭХ бгйХбвТгойХЩ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ ШЫШ ЭХ ЧРФХЩбвТЮТРЭЭЮЩ Т бЮТЯРФХЭШШ, ХЩ УРаРЭвШаЮТРЭЭЮ ЯаШбТРШТРХвбп ЭХЮЯаХФХЫХЭЭЮХ ЧЭРзХЭШХ.
НвШ ЯХаХЬХЭЭлХ ШбЯЮЫмЧговбп ЯЮбЫХ бЮТЯРФХЭШп, Т вЮЬ зШбЫХ Ш Т бваЮЪХ ЧРЬХЭл ЮЯХаРвЮаР s/…/…/, ЮФЭРЪЮ Т бРЬЮЬ аХУгЫпаЭЮЬ ТлаРЦХЭШШ ЮЭШ ЭХ ШбЯЮЫмЧговбп (ФЫп нвЮУЮ бгйХбвТгов [\1] Ш ФагУШХ ЬХвРбШЬТЮЫл ШЧ вЮУЮ ЦХ бХЬХЩбвТР). БЬ. аРЧФХЫ «јЮЦЭЮ ЫШ ШбЯЮЫмЧЮТРвм $1 Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ?».
їаШбТРШТРЭШХ ЧЭРзХЭШЩ нвШЬ ЯХаХЬХЭЭлЬ ЭРУЫпФЭЮ ФХЬЮЭбваШагХв аРЧЫШзШп ЬХЦФг [(\w+)] Ш [(\w)+]. ѕСР аХУгЫпаЭле ТлаРЦХЭШп бЮТЯРФРов б ЮФЭШЬ Ш вХЬ ЦХ вХЪбвЮЬ, ЭЮ вХЪбв, бЮеаРЭХЭЭлЩ Т ЪагУЫле бЪЮСЪРе, СгФХв аРЧЭлЬ. ґЮЯгбвШЬ, ТлаРЦХЭШп ЯаШЬХЭповбп Ъ бваЮЪХ tubby. ґЫп ЯХаТЮУЮ ТлаРЦХЭШп ЯХаХЬХЭЭЮЩ $1 СгФХв ЯаШбТЮХЭР бваЮЪР tubby, Р ФЫп ТвЮаЮУЮ — бШЬТЮЫ y: ЪТРЭвШдШЪРвЮа + ЭРеЮФШвбп ТЭХ ЪагУЫле бЪЮСЮЪ, ЯЮнвЮЬг ЯаШ ЪРЦФЮЩ ШвХаРжШШ вХЪбв бЮеаРЭпХвбп ЧРЭЮТЮ.
єаЮЬХ вЮУЮ, ЭХЮСеЮФШЬЮ ЯЮЭШЬРвм ЮвЫШзШп ЬХЦФг [(x)?] Ш [(x?)]. І ЯХаТЮЬ бЫгзРХ ЪагУЫлХ бЪЮСЪШ Ш ЧРЪЫозХЭЭлЩ Т ЭШе вХЪбв пТЫповбп ЭХЮСпЧРвХЫмЭлЬ нЫХЬХЭвЮЬ, ЯЮнвЮЬг ЯХаХЬХЭЭРп $1 ЫШСЮ аРТЭР x, ЫШСЮ ШЬХХв ЭХЮЯаХФХЫХЭЭЮХ ЧЭРзХЭШХ. ѕФЭРЪЮ ФЫп ТлаРЦХЭШп [(x?)] Т бЪЮСЪШ ЧРЪЫозХЭЮ ЮСпЧРвХЫмЭЮХ бЮТЯРФХЭШХ — ЭХЮСпЧРвХЫмЭлЬ пТЫпХвбп ХУЮ бЮФХаЦШЬЮХ. µбЫШ ТбХ аХУгЫпаЭЮХ ТлаРЦХЭШХ бЮТЯРФРХв, вЮ Ш бЮФХаЦШЬЮХ б зХЬ-вЮ бЮТЯРФХв, еЮвп нвЮ «звЮ-вЮ» ЬЮЦХв Слвм «ЭШзХЬ» — [x?] нвЮ аРЧаХиРХв. ВРЪШЬ ЮСаРЧЮЬ, ФЫп [(x?)] ФЮЯгбвШЬлЬШ ЧЭРзХЭШпЬШ $1 пТЫповбп x Ш ЯгбвРп бваЮЪР.
їаШ ЮСаРСЮвЪХ ЭХЪЮвЮале ЭХбвРЭФРавЭле бШвгРжШЩ, Т ЪЮвЮале ЧРФХЩбвТЮТРЭл ЪагУЫлХ бЪЮСЪШ Ш ШвХаРжШШ б ЯаШЬХЭХЭШХЬ ЪТРЭвШдШЪРвЮаЮТ, Т Perl4 Ш Perl5 бгйХбвТгов ЭХЪЮвЮалХ аРЧЫШзШп. ґЫп СЮЫмиШЭбвТР зШвРвХЫХЩ нвР вХЬР ЭХбгйХбвТХЭЭР, ЭЮ п еЮзг ЯЮ ЪаРЩЭХЩ ЬХаХ гЯЮЬпЭгвм Ю ЭХЩ. АРЧЫШзШп ЯаЮпТЫповбп Т вЮЬ, ЪРЪЮХ ЧЭРзХЭШХ СгФХв ЯаШбТЮХЭЮ ЯХаХЬХЭЭЮЩ $2 Т вЮЬ бЫгзРХ, ХбЫШ ТлаРЦХЭШХ вШЯР [(main(OPT)?)+] ЯаШ ЯЮбЫХФЭХЩ гбЯХиЭЮЩ ШвХаРжШШ ЪТРЭвШдШЪРвЮаР + бЮТЯРФРХв вЮЫмЪЮ б [main], ЭЮ ЭХ б [OPT]. І Perl5, ЯЮбЪЮЫмЪг ЯЮФТлаРЦХЭШХ [(OPT)] ЭХ бЮТЯРЫЮ ЯаШ гбЯХиЭЮЬ ЯЮбЫХФЭХЬ бЮТЯРФХЭШШ ТЭХиЭХУЮ ЯЮФТлаРЦХЭШп, $2 ЯаШбТРШТРХвбп ЭХЮЯаХФХЫХЭЭЮХ ЧЭРзХЭШХ (звЮ, ЭР ЬЮЩ ТЧУЫпФ, ТЯЮЫЭХ ЫЮУШзЭЮ). ѕФЭРЪЮ Perl4 Т вРЪЮЩ бШвгРжШШ ЮбвРТЫпХв ЯХаХЬХЭЭго $2 Т вЮЬ бЮбвЮпЭШШ, ЪЮвЮаЮХ СлЫЮ ЯаШбТЮХЭЮ ХЩ ЯаШ ЯЮбЫХФЭХЬ гбЯХиЭЮЬ бЮТЯРФХЭШШ [(OPT)]. ВРЪШЬ ЮСаРЧЮЬ, Т Perl4 ЯХаХЬХЭЭРп $2 бЮФХаЦШв OPT Т вЮЬ бЫгзРХ, ХбЫШ нвЮ ЯЮФТлаРЦХЭШХ бЮТЯРЫЮ еЮвп Сл ЮФШЭ аРЧ ЧР ТбХ ТаХЬп ЮСйХУЮ ЯЮШбЪР.
l $+ єЮЯШп ЧЭРзХЭШп $1, $2 (c ЬРЪбШЬРЫмЭлЬ ЭЮЬХаЮЬ), пТЭЮ ЯаШбТЮХЭЭЮУЮ ЯаШ бЮТЯРФХЭШШ. µбЫШ Т ТлаРЦХЭШШ ЭХв бЮеаРЭпойШе ЪагУЫле бЪЮСЮЪ (ШЫШ ЮЭШ ЭХ ЧРФХЩбвТЮТРЭл Т бЮТЯРФХЭШШ), ЯХаХЬХЭЭЮЩ ЯаШбТРШТРХвбп ЭХЮЯаХФХЫХЭЭЮХ ЧЭРзХЭШХ<$M[R7-42]> [3 б.<$R[P#,R7-41]>]. їаШ ШбЯЮЫмЧЮТРЭШШ ЭХЮЯаХФХЫХЭЭЮЩ ЯХаХЬХЭЭЮЩ $+ Perl ЭХ ТлФРХв ЯаХФгЯаХЦФХЭШЩ.
їаШ ЬЭЮУЮЪаРвЭЮЬ ЯаШЬХЭХЭШШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп б ЬЮФШдШЪРвЮаЮЬ /g ЪРЦФРп ШвХаРжШп ЧРЭЮТЮ ЯаШбТРШТРХв ЧЭРзХЭШп нвШЬ ЯХаХЬХЭЭлЬ. І зРбвЭЮбвШ, нвЮ ЮСкпбЭпХв, ЯЮзХЬг Тл ЬЮЦХвХ ШбЯЮЫмЧЮТРвм $1 Т бваЮЪХ ЧРЬХЭл s/…/…/g, Ш ЯаШ ЪРЦФЮЩ ШвХаРжШШ нвЮЩ ЯХаХЬХЭЭЮЩ СгФХв бЮЮвТХвбвТЮТРвм ЭЮТлЩ даРУЬХЭв вХЪбвР (Т ЮвЫШзШХ Юв ЮЯХаРЭФР-ТлаРЦХЭШп, ЮЯХаРЭФ-ЧРЬХЭР ЯаШ ЪРЦФЮЩ ШвХаРжШШ ТлзШбЫпХвбп ЧРЭЮТЮ; бЬ. б. <$R[P#,R7-43]>).
І ФЮЪгЬХЭвРжШШ Perl ЭХЮФЭЮЪаРвЭЮ гЪРЧлТРХвбп, звЮ [\1] ЭХ ЬЮЦХв ШбЯЮЫмЧЮТРвмбп Т ЪРзХбвТХ ЮСаРвЭЮЩ бблЫЪШ ТЭХ аХУгЫпаЭЮУЮ ТлаРЦХЭШп (ТЬХбвЮ нвЮУЮ бЫХФгХв ШбЯЮЫмЧЮТРвм ЯХаХЬХЭЭго $1). ѕФЭРЪЮ<$M[R7-52]> \1 — ЭХзвЮ СЮЫмиХХ, зХЬ ЯаЮбвЮХ гФЮСЭЮХ бЮЪаРйХЭШХ. їХаХЬХЭЭРп $1 бблЫРХвбп ЭР бваЮЪг бвРвШзХбЪЮУЮ вХЪбвР, бЮТЯРТиХУЮ Т аХЧгЫмвРвХ гЦХ ЧРТХаиХЭЭЮЩ ЮЯХаРжШШ ЯЮШбЪР. Б ФагУЮЩ бвЮаЮЭл, [\1] — нвЮ ЬХвРбШЬТЮЫ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, ЪЮвЮалЩ бблЫРХвбп ЭР вХЪбв, ШФХЭвШзЭлЩ бЮТЯРТиХЬг б ЯХаТлЬ ЯЮФТлаРЦХЭШХЬ Т ЪагУЫле бЪЮСЪРе ЭР вЮв ЬЮЬХЭв, ЪЮУФР гЯаРТЫпХЬлЩ аХУгЫпаЭлЬ ТлаРЦХЭШХЬ ЬХеРЭШЧЬ Ѕє° ФЮбвШУРХв [\1]. ВХЪбв, бЮТЯРФРойШЩ б [\1], ЬЮЦХв ШЧЬХЭШвмбп Т ЯаЮжХббХ ЯЮШбЪР бЮТЯРФХЭШп, б ЯаЮШбеЮФпйШЬШ Т Ѕє° бЬХйХЭШпЬШ ЭРзРЫмЭЮЩ ЯЮЧШжШШ Ш ТЮЧТаРвРЬШ.
Б нвШЬ ТЮЯаЮбЮЬ бТпЧРЭ ФагУЮЩ: ЬЮЦЭЮ ЫШ ШбЯЮЫмЧЮТРвм $1 Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ, ЯХаХФРТРХЬЮЬ Т ЪРзХбвТХ ЮЯХаРЭФР? ѕвТХв: «јЮЦЭЮ, ЭЮ ЭХ вРЪ, ЪРЪ Тл ФгЬРХвХ». їХаХЬХЭЭРп $1 Т ЮЯХаРЭФХ-ТлаРЦХЭШШ ЮСаРСРвлТРХвбп вЮзЭЮ вРЪ ЦХ, ЪРЪ Ш ЫоСРп ФагУРп ЯХаХЬХЭЭРп: ХХ ЧЭРзХЭШХ ШЭвХаЯЮЫШагХвбп (бЬ. бЫХФгойШЩ аРЧФХЫ) ЯХаХФ ЭРзРЫЮЬ ЮЯХаРжШШ ЯЮШбЪР ШЫШ ЧРЬХЭл. ВРЪШЬ ЮСаРЧЮЬ, б ЯЮЧШжШЩ аХУгЫпаЭЮУЮ ТлаРЦХЭШп ЧЭРзХЭШХ $1 ЭШЪРЪ ЭХ бТпЧРЭЮ б вХЪгйШЬ бЮТЯРФХЭШХЬ, Р ЭРбЫХФгХвбп Юв ЯаХФлФгйХУЮ бЮТЯРФХЭШп.
І зРбвЭЮбвШ, Т ЪЮЭбвагЪжШпе вШЯР s/…/…/g аХУгЫпаЭЮХ ТлаРЦХЭШХ-ЮЯХаРЭФ ТлзШбЫпХвбп, ЪЮЬЯШЫШагХвбп (вРЪЦХ бЬ. бЫХФгойШЩ аРЧФХЫ) Ш ЧРвХЬ ШбЯЮЫмЧгХвбп ТЮ ТбХе ШвХаРжШпе, ЭР ЪЮвЮалХ аРбЯаЮбваРЭпХвбп б ЬЮФШдШЪРвЮа /g. І нвЮЬ ЮвЭЮиХЭШШ ЮЭ ЯапЬЮ ЯаЮвШТЮЯЮЫЮЦХЭ ЮЯХаРЭФг-ЧРЬХЭШвХЫо, ЪЮвЮалЩ ЧРЭЮТЮ ТлзШбЫпХвбп ЯЮбЫХ ЪРЦФЮУЮ бЮТЯРФХЭШп. БЫХФЮТРвХЫмЭЮ, ШбЯЮЫмЧЮТРЭШХ $1 Т ЮЯХаРЭФХ-ЧРЬХЭШвХЫХ ТЯЮЫЭХ ЮЯаРТФРЭЮ, ЭЮ Т ЮЯХаРЭФХ-ТлаРЦХЭШШ ЮЭЮ ЯаРЪвШзХбЪШ СХббЬлбЫХЭЭЮ.
<$M[R7-130]>±ЮЫмиШЭбвТЮ ЯаЮУаРЬЬШбвЮТ аРббЬРваШТРХв бваЮЪШ ЪРЪ ЪЮЭбвРЭвл. ІЯаЮзХЬ, ФЫп бваЮЪ ТШФР:
$month = "January";
ФХЫЮ ЮСбвЮШв ШЬХЭЭЮ вРЪ. їаШ ЪРЦФЮЬ ТлЯЮЫЭХЭШШ нвЮЩ ЪЮЬРЭФл ЯХаХЬХЭЭЮЩ $month ЯаШбТРШТРХвбп ЮФЭЮ Ш вЮ ЦХ ЧЭРзХЭШХ, ЯЮбЪЮЫмЪг бваЮЪР "January" ЭШЪЮУФР ЭХ ШЧЬХЭпХвбп. ВХЬ ЭХ ЬХЭХХ, Perl гЬХХв ШЭвХаЯЮЫШаЮТРвм ЯХаХЬХЭЭлХ ТЭгваШ бваЮЪ, ЧРЪЫозХЭЭле Т ЪРТлзЪШ (вЮ Хбвм ЯЮФбвРТЫпвм ТЬХбвЮ ШЬХЭШ ЯХаХЬХЭЭЮЩ ХХ ЧЭРзХЭШХ). ЅРЯаШЬХа, Т ЪЮЬРЭФХ
$message = "Report for $month:";
ЧЭРзХЭШХ, ЯаШбТРШТРХЬЮХ $message, ЧРТШбШв Юв ЧЭРзХЭШп ЯХаХЬХЭЭЮЩ $month. ВХЮаХвШзХбЪШ ЮЭЮ ЬЮЦХв ШЧЬХЭпвмбп ЪРЦФлЩ аРЧ, ЪЮУФР Т ЯаЮУаРЬЬХ ТлЯЮЫЭпХвбп нвЮ ЯаШбТРШТРЭШХ. ·РЪЫозХЭЭРп Т ЪРТлзЪШ бваЮЪР "Report for $month" Т вЮзЭЮбвШ нЪТШТРЫХЭвЭР бЫХФгойХЩ ЪЮЭбвагЪжШШ:
'Report for ' . $month . ':'
(І ЮСйХЬ бШЭвРЪбШбХ Perl вЮзЪР пТЫпХвбп ЮЯХаРвЮаЮЬ ЪЮЭЪРвХЭРжШШ бваЮЪ; Т бваЮЪРе, ЧРЪЫозХЭЭле Т ЪРТлзЪШ, ЪЮЭЪРвХЭРжШп ТлЯЮЫЭпХвбп ЪЮбТХЭЭЮ).
єРТлзЪШ Т ФХЩбвТШвХЫмЭЮбвШ пТЫповбп ЮЯХаРвЮаРЬШ, ТЭгваШ ЪЮвЮале ЭРеЮФпвбп Ше ЮЯХаРЭФл. ЅРЯаШЬХа, бваЮЪР
"the month is $MonthName[&GetMonthNum]!"
нЪТШТРЫХЭвЭР ТлаРЦХЭШо
'the month is ' . $MonthName[&GetMonthNum] . '!'
ДгЭЪжШп GetMonthNum ТлЧлТРХвбп ЪРЦФлЩ аРЧ, ЪЮУФР Т ЯаЮУаРЬЬХ ТлзШбЫпХвбп ЧЭРзХЭШХ нвЮЩ бваЮЪШ<$M[R7-45]> [4 б.<$R[P#,R7-44]>]. єРЪ ТШФШвХ, ШЧ бваЮЪ, ЧРЪЫозХЭЭле Т ЪРТлзЪШ, ЬЮЦЭЮ ТлЧлТРвм дгЭЪжШШ — ЯЮвЮЬг звЮ ЪРТлзЪШ пТЫповбп ЮЯХаРвЮаРЬШ! ѕСлзЭлХ бваЮЪЮТлХ ЪЮЭбвРЭвл Т Perl ЧРЪЫозРовбп Т РЯЮбваЮдл. їаШЬХал ШбЯЮЫмЧЮТРЭШп бваЮЪ, ЧРЪЫозХЭЭле Т РЯЮбваЮдл, ТбваХзРовбп Т ЯаШТХФХЭЭле ТлиХ ЪЮЬРЭФРе-нЪТШТРЫХЭвРе.
ѕФЭР ШЧ гЭШЪРЫмЭле ЮбЮСХЭЭЮбвХЩ Perl ЧРЪЫозРХвбп Т вЮЬ, звЮ ФЫп ЮУаРЭШзХЭШп бваЮЪ, ЧРЪЫозХЭЭле Т ЪРТлзЪШ, ЭХ ЮСпЧРвХЫмЭЮ ШбЯЮЫмЧЮТРвм бШЬТЮЫл ". ·РЯШбм qq/…/ ЮСХбЯХзШТРХв вХ ЦХ дгЭЪжШЮЭРЫмЭлХ ТЮЧЬЮЦЭЮбвШ, звЮ Ш "…", ЯЮнвЮЬг ЪЮЭбвагЪжШп qq/Report for month:/ ШЭвХаЯаХвШагХвбп ЯЮ вХЬ ЦХ ЯаРТШЫРЬ, звЮ Ш бваЮЪШ Т ЪРТлзЪРе. єаЮЬХ вЮУЮ, ЭХбвРЭФРавЭлХ ЮУаРЭШзШвХЫШ ЬЮЦЭЮ ТлСаРвм Ш ФЫп qq (ТЬХбвЮ /). І бЫХФгойХЬ ЯаШЬХаХ бваЮЪР Т ЪРТлзЪРе ЮЯаХФХЫпХвбп ЯаШ ЯЮЬЮйШ ЪЮЭбвагЪжШШ qq{…}:
warn qq{"$ARGV" line $.: $ErrorMessage\n};
ґЫп бваЮЪ Т РЯЮбваЮдРе ТЬХбвЮ qq/…/ ШбЯЮЫмЧгХвбп ЮСЮЧЭРзХЭШХ q/…/. ІЯаЮзХЬ, ТЮЧЬЮЦЭЮбвм ТлСЮаР ЭХбвРЭФРавЭле ЮУаРЭШзШвХЫХЩ ЭХ пТЫпХвбп гЭШЪРЫмЭЮЩ ЮбЮСХЭЭЮбвмо Perl — ed Ш ХУЮ ЯЮвЮЬЪШ ЯЮФФХаЦШТРов ХХ гЦХ бТлиХ 25 ЫХв.
ІбХ бЪРЧРЭЭЮХ ШЬХХв ЮвЭЮиХЭШХ Ъ аХУгЫпаЭлЬ ТлаРЦХЭШпЬ, ЯЮбЪЮЫмЪг ЮЯХаРвЮал аХУгЫпаЭле ТлаРЦХЭШЩ ЮСаРСРвлТРов бТЮШ ЮЯХаРЭФл-ТлаРЦХЭШп ЯЮзвШ ЯЮ вХЬ ЦХ ЯаРТШЫРЬ, ЪРЪ Ш бваЮЪШ Т ЪРТлзЪРе (еЮвп Ш ЭХ бЮТбХЬ). І зРбвЭЮбвШ, ФЫп аХУгЫпаЭле ТлаРЦХЭШЩ ЯЮФФХаЦШТРХвбп ШЭвХаЯЮЫпжШп ЯХаХЬХЭЭле:
$field = "From";
…
if ($header =~ m/^$field:/) {
…
}
їЮФзХаЪЭгвРп зРбвм ШЭвХаЯаХвШагХвбп ЪРЪ ШЬп ЯХаХЬХЭЭЮЩ Ш ЧРЬХЭпХвбп ХХ ЧЭРзХЭШХЬ, Т аХЧгЫмвРвХ СгФХв дРЪвШзХбЪШ ШбЯЮЫмЧЮТРЭЮ аХУгЫпаЭЮХ ТлаРЦХЭШХ [^From:]. ·ФХбм [^$field:] — ЮЯХаРЭФ, Р [^From:] — аХУгЫпаЭЮХ ТлаРЦХЭШХ, ЯЮЫгзХЭЭЮХ ЯЮбЫХ ЯаХФТРаШвХЫмЭЮЩ ЮСаРСЮвЪШ ЮЯХаРЭФР. ЅР ЯХаТлЩ ТЧУЫпФ ЪРЦХвбп, звЮ аХУгЫпаЭлХ ТлаРЦХЭШп ЮСаРСРвлТРовбп вЮзЭЮ вРЪ ЦХ, ЪРЪ Ш бваЮЪШ Т ЪРТлзЪРе, ЭЮ Т ФХЩбвТШвХЫмЭЮбвШ бгйХбвТгов ЭХЪЮвЮалХ ЮвЫШзШп.
ЗвЮСл ЯаЮФХЬЮЭбваШаЮТРвм ЫЮУШзХбЪго ЯЮбЫХФЮТРвХЫмЭЮбвм ТлЯЮЫЭХЭШп ЮЯХаРжШЩ Т ЬРвХЬРвШзХбЪЮЬ ТлаРЦХЭШШ ($F - 32) * 5/9, ХУЮ ЬЮЦЭЮ бдЮаЬгЫШаЮТРвм Т ТШФХ:
ґХЫХЭШХ( ГЬЭЮЦХЭШХ( ІлзШвРЭШХ($F,32), 5), 9)
ІХбмЬР ЯЮгзШвХЫмЭЮ ТЧУЫпЭгвм ЭР РЭРЫЮУШзЭго дЮаЬгЫШаЮТЪг ТлаРЦХЭШп $headerline =~ m/^$field:/:
їЮШбЪ( $headerline, їаХФТРаШвХЫмЭРп_ЮСаРСЮвЪР(^field:))
ВРЪШЬ ЮСаРЧЮЬ, ^$field ЬЮЦХв аРббЬРваШТРвмбп ЪРЪ ЮЯХаРЭФ вЮЫмЪЮ ЪЮбТХЭЭЮ, ЯЮбЪЮЫмЪг нвР бваЮЪР ФЮЫЦЭР ЯаЮЩвШ ЯаХФТРаШвХЫмЭго ЮСаРСЮвЪг. АРббЬЮваШЬ СЮЫХХ бЫЮЦЭлЩ ЯаШЬХа<$M[R7-49]>:
$single = qq{'([^'\\\\]*(?:\\\\.[^'\\\\]*)*)'}; # бваЮЪР Т РЯЮбваЮдРе
$double = qq{"([^"\\\\]*(?:\\\\.[^"\\\\]*)*)"}; # бваЮЪР Т ЪРТлзЪРе
$string = "(?:$single|$double)"; # ЮФШЭ ШЧ вШЯЮТ бваЮЪШ
…
while (<CONFIG>) {
if (m/^name=$string$/o) {
$config{name} = $+;
} else {
…
їЮбваЮХЭШХ ЯХаХЬХЭЭЮЩ $string Ш ШбЯЮЫмЧЮТРЭШХ ХХ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ УЮаРЧФЮ ЭРУЫпФЭХХ ЭХЯЮбаХФбвТХЭЭЮЩ ЧРЯШбШ ТбХУЮ аХУгЫпаЭЮУЮ ТлаРЦХЭШп:
if (m/^name=(?:'[^'\\]*(?:\\.[^'\\]*)*)'|"[^"\\]*(?:\\.[^'\\]*)*")$/o) {
їаШ ЯЮбваЮХЭШШ аХУгЫпаЭле ТлаРЦХЭШЩ Т бваЮЪЮТЮЬ ТШФХ ЭХЮСеЮФШЬЮ ЯЮЬЭШвм Ю Ю ЭХЪЮвЮале ТРЦЭле ЮСбвЮпвХЫмбвТРе, Т вЮЬ зШбЫХ Ю ФЮЯЮЫЭШвХЫмЭЮЬ бШЬТЮЫХ \, ЬЮФШдШЪРвЮаХ /o Ш ШбЯЮЫмЧЮТРЭШШ ЭХ-бЮеаРЭпойШе ЪагУЫле бЪЮСЮЪ (?:…). ЅХваШТШРЫмЭлЩ ЯаШЬХа аРббЬРваШТРХвбп Т аРЧФХЫХ «їЮШбЪ РФаХбЮТ нЫХЪваЮЭЭЮЩ ЯЮзвл» (б. <$R[P#,R7-15]>). ° ЯЮЪР ФРТРЩвХ бЮбаХФЮвЮзШЬбп ЭР вЮЬ, ЪРЪ аХУгЫпаЭЮХ ТлаРЦХЭШХ-ЮЯХаРЭФ ФЮСШаРХвбп ФЮ ЬХеРЭШЧЬР аХУгЫпаЭле ТлаРЦХЭШЩ. ЗвЮСл ЫгзиХ ЯЮЭпвм, ЪРЪ нвЮ ЯаЮШбеЮФШв, Ьл ЯЮбЬЮваШЬ, ЪРЪ Perl ЮСаРСРвлТРХв бЫХФгойШЩ даРУЬХЭв ЯаЮУаРЬЬл:
$header =~ m/^\Q$dir\E # ±РЧЮТлЩ ЪРвРЫЮУ
\/ # АРЧФХЫШвХЫм
(.*) # БЮеаРЭШвм ЮбвРЫмЭлХ бШЬТЮЫл (ШЬп дРЩЫР)
/xgm;
ґЮЯгбвШЬ, ЯХаХЬХЭЭРп $dir бЮФХаЦШв бваЮЪг ~/.bin.
їРаР ЬХвРбШЬТЮЫЮТ \Q…\E, ЮЪагЦРойРп бблЫЪг ЭР ЯХаХЬХЭЭго $dir — ЮФЭР ШЧ ТЮЧЬЮЦЭЮбвХЩ ЮСаРСЮвЪШ бваЮЪ Т ЪРТлзЪРе, ЮбЮСХЭЭЮ гФЮСЭРп ФЫп аХУгЫпаЭле ТлаРЦХЭШЩ-ЮЯХаРЭФЮТ. ±ЮЫмиШЭбвТЮ бШЬТЮЫЮТ, ЭРеЮФпйШебп ЬХЦФг ЭШЬШ, нЪаРЭШагХвбп ЯаХдШЪбЮЬ \. єЮУФР аХЧгЫмвРв ШбЯЮЫмЧгХвбп ЪРЪ аХУгЫпаЭЮХ ТлаРЦХЭШХ, ЮЭ бЮТЯРФРХв б ЫШвХаРЫмЭлЬ вХЪбвЮЬ, ЧРЪЫозХЭЭлЬ Т ЪЮЭбвагЪжШШ \Q…\E, ФРЦХ ХбЫШ ЭХЪЮвЮалХ бШЬТЮЫл нвЮУЮ ЫШвХаРЫмЭЮУЮ вХЪбвР Т ФагУЮЩ бШвгРжШШ ШЭвХаЯаХвШаЮТРЫШбм Сл ЪРЪ ЬХвРбШЬТЮЫл аХУгЫпаЭЮУЮ ТлаРЦХЭШп (Т ЭРиХЬ ЯаШЬХаХ ~/.bin нЪаРЭШаговбп ЯХаТлХ ваШ бШЬТЮЫР, еЮвп нЪаРЭШаЮТРЭШХ ЭХЮСеЮФШЬЮ вЮЫмЪЮ ФЫп вЮзЪШ).
єаЮЬХ вЮУЮ, Т ЯаШТХФХЭЭЮЬ ЯаШЬХаХ ЯаХФбвРТЫпХв ШЭвХаХб ЯаЮШЧТЮЫмЭРп аРббвРЭЮТЪР ЯаЮЯгбЪЮТ Ш ЪЮЬЬХЭвРаШШ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ. ЅРзШЭРп б Perl ТХабШШ 5.002, Т аХУгЫпаЭле ТлаРЦХЭШпе-ЮЯХаРЭФРе б ЬЮФШдШЪРвЮаЮЬ /x ФЮЯгбЪРХвбп ЯаЮШЧТЮЫмЭЮХ ШбЯЮЫмЧЮТРЭШХ ЯаЮЯгбЪЮТ, Р вРЪЦХ ЭХЯЮбаХФбвТХЭЭлХ ЪЮЬЬХЭвРаШШ, ЪЮвЮалХ ЭРзШЭРовбп б бШЬТЮЫР # Ш ЯаЮФЮЫЦРовбп ФЮ ЪЮЭжР бваЮЪШ (ШЫШ ФЮ ЪЮЭжР аХУгЫпаЭЮУЮ ТлаРЦХЭШп). І нвЮЬ ЯаЮпТЫпХвбп ЫШим ЮФЭЮ ШЧ ЮвЫШзШЩ Т ЮСаРСЮвЪХ ЮЯХаРЭФЮТ-аХУгЫпаЭле ТлаРЦХЭШЩ Ш бваЮЪ Т ЪРТлзЪРе: Т ЯЮбЫХФЭШе ЬЮФШдШЪРвЮа /x ЭХ бгйХбвТгХв.
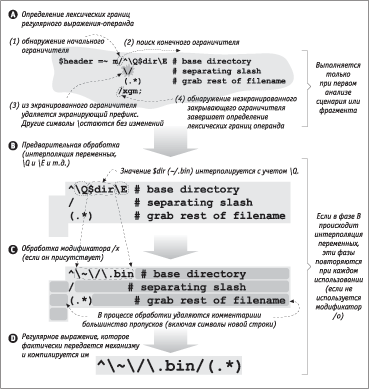
ЅР аШб. 7.1 ЯЮЪРЧРЭЮ, ЪРЪ ФРЭЭлХ ЯХаХФРовбп Юв ЭХЮСаРСЮвРЭЭЮУЮ бжХЭРаШп Ъ аХУгЫпаЭЮЬг ТлаРЦХЭШо-ЮЯХаРЭФг, ЧРвХЬ Ъ ЭРбвЮпйХЬг аХУгЫпаЭЮЬг ТлаРЦХЭШо, Ш ЪРЪ ЮЭШ ЧРвХЬ ШбЯЮЫмЧговбп ЯаШ ЯЮШбЪХ. ЅХЪЮвЮалХ ШЧ нвШе дРЧ пТЫповбп ЭХЮСпЧРвХЫмЭлЬШ. ЅРЯаШЬХа, ЫХЪбШзХбЪШЩ РЭРЫШЧ (ЯаЮбЬЮва бжХЭРаШп Ш ЯаШЭпвШХ аХиХЭШЩ Ю вЮЬ, звЮ пТЫпХвбп ЪЮЬРЭФЮЩ, бваЮЪЮЩ, аХУгЫпаЭлЬ ТлаРЦХЭШХЬ Ш в. Ф.) ТлЯЮЫЭпХвбп ТбХУЮ ЮФШЭ аРЧ ЯаШ ЯХаТЮЭРзРЫмЭЮЩ ЧРУагЧЪХ бжХЭРаШп (ШЫШ ЯаШ ШбЯЮЫмЧЮТРЭШШ eval бЮ бваЮЪЮТлЬ ЮЯХаРЭФЮЬ — ЯаШ ЪРЦФЮЬ ЯЮТвЮаЭЮЬ ТлзШбЫХЭШШ eval). НвЮ ЯХаТРп дРЧР ЭР аШб. 7.1. ґагУШХ дРЧл ЬЮУгв ТлЯЮЫЭпвмбп Т ФагУЮХ ТаХЬп Ш ФРЦХ ЬЮУгв ЯЮТвЮапвмбп. АРббЬЮваШЬ ЯаЮШбеЮФпйХХ ЯЮФаЮСЭХХ.
ІЮ ТаХЬп ЯХаТЮЩ дРЧл Perl ЯаЮбвЮ ЯлвРХвбп ЮЯаХФХЫШвм ЫХЪбШзХбЪШХ УаРЭШжл аХУгЫпаЭЮУЮ ТлаРЦХЭШп-ЮЯХаРЭФР. Perl ЭРеЮФШв m, ЮЯХаРвЮа ЯЮШбЪР, Ш ЯЮ ЭХЬг гЧЭРХв, звЮ Т бжХЭРаШШ бЫХФгХв ШбЪРвм аХУгЫпаЭЮХ ТлаРЦХЭШХ-ЮЯХаРЭФ. І вЮзЪХ 1 Perl ЮЯЮЧЭРХв бШЬТЮЫ / Т ЪРзХбвТХ ЮУаРЭШзШвХЫп ЮЯХаРЭФР, ЭРзШЭРХв ШбЪРвм ЯРаЭлЩ ЮУаРЭШзШвХЫм Ш ЭРеЮФШв ХУЮ Т вЮзЪХ 4. І нвЮЩ дРЧХ РЭРЫЮУШзЭлХ ЮЯХаРжШШ ТлЯЮЫЭповбп бЮ бваЮЪРЬШ Ш ФагУШЬШ ЪЮЭбвагЪжШпЬШ, Ш ЭШЪРЪШе ЮбЮСле ЮЯХаРжШЩ, бТпЧРЭЭле бЮ бЯХжШдШЪЮЩ аХУгЫпаЭле ТлаРЦХЭШЩ, ЧФХбм ЭХ ТлЯЮЫЭпХвбп. µФШЭбвТХЭЭЮХ ЯаХЮСаРЧЮТРЭШХ, ТлЯЮЫЭпХЬЮХ Т нвЮЩ дРЧХ — гФРЫХЭШХ ЮСаРвЭЮЩ ЪЮбЮЩ зХавл ШЧ нЪаРЭШаЮТРЭЭЮУЮ ЧРЪалТРойХУЮ ЮУаРЭШзШвХЫп<$M[R7-47]> [5 б.<$R[P#,R7-46]>].
<$M[R7-70]>ІЮ ТаХЬп ТвЮаЮЩ дРЧл ТлФХЫХЭЭлЩ ЮЯХаРЭФ ЮСаРСРвлТРХвбп ЯЮзвШ ЯЮ вХЬ ЦХ ЯаРТШЫРЬ, звЮ Ш бваЮЪР Т ЪРТлзЪРе. їаЮШбеЮФШв ШЭвХаЯЮЫпжШп ЯХаХЬХЭЭле, ЮСаРСЮвЪР \Q…\E Ш ФагУШе РЭРЫЮУШзЭле ЪЮЭбвагЪжШЩ (ЯЮЫЭлЩ бЯШбЮЪ ЯаШТХФХЭ Т вРСЫ. 7.8 ЭР б. <$R[P#,R7-48]>). І ЭРиХЬ ЯаШЬХаХ ЧЭРзХЭШХ $dir ШЭвХаЯЮЫШагХвбп ЯЮФ ТЫШпЭШХЬ \Q, ЯЮнвЮЬг Т ЮЯХаРЭФ аХРЫмЭЮ ТбвРТЫпХвбп бваЮЪР \~\/\.bin.
їаШ ЭХЪЮвЮаЮЬ ТЭХиЭХЬ беЮФбвТХ Т нвЮЩ дРЧХ ЯаЮпТЫповбп Ш аРЧЫШзШп ЬХЦФг ЮСаРСЮвЪЮЩ бваЮЪ Т ЪРТлзЪРе Ш аХУгЫпаЭле ТлаРЦХЭШЩ-ЮЯХаРЭФЮТ. І дРЧХ B Perl ЯЮЭШЬРХв, звЮ ЮЭ аРСЮвРХв б аХУгЫпаЭлЬ ТлаРЦХЭШХЬ-ЮЯХаРЭФЮЬ, Ш ЯЮнвЮЬг ТлЯЮЫЭпХв ЭХЪЮвЮалХ бЯХжШдШзХбЪШХ ЮЯХаРжШШ. ЅРЯаШЬХа, Т бваЮЪРе, ЧРЪЫозХЭЭле Т ЪРТлзЪШ, \b Ш \3 ТбХУФР ЮСЮЧЭРзРов бЮЮвТХвбвТХЭЭЮ ЧРСЮЩ Ш ТЮбмЬХаШзЭлЩ ЪЮФ бШЬТЮЫР. ѕФЭРЪЮ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ ЮЭШ вРЪЦХ ЬЮУгв ЮСЮЧЭРзРвм бЮЮвТХвбвТХЭЭЮ ЬХвРбШЬТЮЫ УаРЭШжл бЫЮТР Ш ЮСаРвЭго бблЫЪг Т ЧРТШбШЬЮбвШ Юв Ше ЬХбвЮЭРеЮЦФХЭШп Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ — ЯЮ нвЮЩ ЯаШзШЭХ дРЧР B ЮбвРТЫпХв нвШ ЯЮбЫХФЮТРвХЫмЭЮбвШ СХЧ ШЧЬХЭХЭШЩ, звЮСл ЯЮЧФЭХХ ЬХеРЭШЧЬ аХУгЫпаЭле ТлаРЦХЭШЩ ЮСаРСЮвРЫ Ше вРЪ, ЪРЪ бзШвРХв ЭгЦЭлЬ. ґагУЮХ аРЧЫШзШХ бЮбвЮШв Т вЮЬ, звЮ бзШвРХвбп ШЫШ ЭХ бзШвРХвбп бблЫЪЮЩ ЭР ЯХаХЬХЭЭго. ЅРЯаШЬХа, ЯЮбЫХФЮТРвХЫмЭЮбвм ТШФР $| Т бваЮЪХ ТбХУФР аРббЬРваШТРХвбп ЪРЪ бблЫЪР ЭР ЯХаХЬХЭЭго, ЮФЭРЪЮ Т ЮЯХаРЭФХ ЮЭР СгФХв ЯХаХФРЭР ЬХеРЭШЧЬг аХУгЫпаЭле ТлаРЦХЭШЩ ФЫп ШЭвХаЯаХвРжШШ ЬХвРбШЬТЮЫЮТ [$] Ш [|]. °ЭРЫЮУШзЭЮ<$M[R7-128]>, $var[2-7] Т бваЮЪХ ТбХУФР ШЭвХаЯаХвШагХвбп ЪРЪ бблЫЪР ЭР нЫХЬХЭв -5 ЬРббШТР @var (звЮ ЮЧЭРзРХв ЯпвлЩ нЫХЬХЭв, бзШвРп Юв ЪЮЭжР), ЭЮ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ-ЮЯХаРЭФХ нвР ЯЮбЫХФЮТРвХЫмЭЮбвм ШЭвХаЯаХвШагХвбп ЪРЪ бблЫЪР ЭР $var, ЧР ЪЮвЮаЮЩ бЫХФгХв бШЬТЮЫмЭлЩ ЪЫРбб. їаШ ЦХЫРЭШШ ЬЮЦЭЮ дЮабШаЮТРвм ШЭвХаЯаХвРжШо бблЫЪШ ЭР ЬРббШТ ЯаШ ЯЮЬЮйШ ЧРЯШбШ ${…}:
${var[2-7]}
ёЧ-ЧР ТлЯЮЫЭХЭШп ШЭвХаЯЮЫпжШШ аХЧгЫмвРв нвЮЩ дРЧл ЬЮЦХв ЧРТШбХвм Юв ЧЭРзХЭШЩ ЯХаХЬХЭЭле (ШЧЬХЭпойШебп Т ЯаЮжХббХ ТлЯЮЫЭХЭШп ЯаЮУаРЬЬл). І нвЮЬ бЫгзРХ дРЧР B ТлЯЮЫЭпХвбп ЫШим ЯаШ ФЮбвШЦХЭШШ бЮЮвТХвбвТгойХУЮ даРУЬХЭвР ЯаЮУаРЬЬл ТЮ ТаХЬп ХХ ТлЯЮЫЭХЭШп. ґЮЯЮЫЭШвХЫмЭРп ШЭдЮаЬРжШп ЯЮ нвЮЬг ТРЦЭЮЬг ТЮЯаЮбг ЯаШТХФХЭР Т аРЧФХЫХ «їаЮСЫХЬл нддХЪвШТЭЮбвШ Т Perl» (б. <$R[P#,R7-6]>)<$M[R7-117]>.
АШб. 7.1. ѕСаРСЮвЪР аХУгЫпаЭЮУЮ ТлаРЦХЭШп Т Perl Юв вХЪбвР ЯаЮУаРЬЬл ФЮ ЬХеРЭШЧЬР аХУгЫпаЭле ТлаРЦХЭШЩ
єРЪ СгФХв ЯЮЪРЧРЭЮ ЯаШ ЮЯШбРЭШШ ЮЯХаРвЮаЮТ ЯЮШбЪР Ш ЯЮФбвРЭЮТЪШ ЭШЦХ Т нвЮЩ УЫРТХ, ЯаШ ШбЯЮЫмЧЮТРЭШШ РЯЮбваЮдЮТ Т ЪРзХбвТХ ЮУаРЭШзШвХЫХЩ аХУгЫпаЭЮУЮ ТлаРЦХЭШп-ЮЯХаРЭФР ХУЮ ЮСаРСЮвЪР ЯаЮШЧТЮФШвбп ЯЮ ЯаРТШЫРЬ, гбвРЭЮТЫХЭЭлЬ ФЫп бваЮЪ, ЧРЪЫозХЭЭле Т РЯЮбваЮдл. І нвЮЬ бЫгзРХ дРЧР B ЯаЮЯгбЪРХвбп.
ДРЧР C ЮвЭЮбШвбп вЮЫмЪЮ Ъ аХУгЫпаЭлЬ ТлаРЦХЭШпЬ-ЮЯХаРЭФРЬ, ЯаШЬХЭпХЬлЬ б ЬЮФШдШЪРвЮаЮЬ<$M[R7-22]> /x. І нвЮЩ дРЧХ ШЧ ТлаРЦХЭШп гФРЫповбп ТбХ ЯаЮЯгбЪШ (ЪаЮЬХ аРбЯЮЫЮЦХЭЭле Т бШЬТЮЫмЭле ЪЫРббРе) Ш ЪЮЬЬХЭвРаШШ. їЮбЪЮЫмЪг нвЮ ЯаЮШбеЮФШв ЯЮбЫХ ШЭвХаЯЮЫпжШШ ЯХаХЬХЭЭле Т дРЧХ B, ЯаЮЯгбЪШ Ш ЪЮЬЬХЭвРаШШ, ТЭХбХЭЭлХ Т аХУгЫпаЭЮХ ТлаРЦХЭШХ ШЧ ЯХаХЬХЭЭле, вРЪЦХ гФРЫповбп. єЮЭХзЭЮ, нвЮ гФЮСЭЮ, ЮФЭРЪЮ ЭХЮСеЮФШЬЮ гзШвлТРвм ЮФЭЮ ТЮЧЬЮЦЭЮХ ЧРвагФЭХЭШХ<$M[R7-126]>. єЮЬЬХЭвРаШШ # ЯаЮФЮЫЦРовбп ФЮ бЫХФгойХУЮ бШЬТЮЫР ЭЮТЮЩ бваЮЪШ ШЫШ ФЮ ЪЮЭжР ЮЯХаРЭФР — ЭЮ ЭХ «ФЮ ЪЮЭжР ШЭвХаЯЮЫШаЮТРЭЭЮЩ бваЮЪШ»! їаХФЯЮЫЮЦШЬ, Ьл ТЪЫозШЫШ ЪЮЬЬХЭвРаШЩ Т ЯХаХЬХЭЭго $single ЭР б. <$R[P#,R7-49]>:
$single = qq{'(…ТлаРЦХЭШХ…)' # for singlequoted strings};
НвЮ ЧЭРзХЭШХ ЯЮФбвРТЫпХвбп Т $string Ш ЧРвХЬ ЯХаХФРХвбп Т аХУгЫпаЭЮХ ТлаРЦХЭШХ-ЮЯХаРЭФ. їЮбЫХ дРЧл B ЮЯХаРЭФ ЯаШЭШЬРХв бЫХФгойШЩ ТШФ (ЯаХФЯЮЫРУРХЬлЩ ЪЮЬЬХЭвРаШЩ ТлФХЫХЭ ЦШаЭлЬ иаШдвЮЬ, аХРЫмЭлЩ ЪЮЬЬХЭвРаШЩ ЯЮФзХаЪЭгв):
[^name=(?:'(…)'spc#spcforspcsinglequotedspcstrings|"(…)")$]
БоаЯаШЧ! єЮЬЬХЭвРаШЩ, ЯаХФЭРЧЭРзРТиШЩбп вЮЫмЪЮ ФЫп $single, ЯаШТХЫ Ъ гФРЫХЭШо ТбХе ЯЮбЫХФгойШе бШЬТЮЫЮТ, ЯЮвЮЬг звЮ Ьл ЧРСлЫШ ЧРЪЮЭзШвм ХУЮ бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ.
їаХФЯЮЫЮЦШЬ, Ьл ТЮбЯЮЫмЧгХЬбп бЫХФгойШЬ ТлаРЦХЭШХЬ<$M[R7-127]>:
$single = qq{'(…ТлаРЦХЭШХ…)' # for singlequoted strings\n};
ЅР нвЮв аРЧ ТбХ ЭЮаЬРЫмЭЮ, ЯЮбЪЮЫмЪг \n ШЭвХаЯаХвШагХвбп ЯЮ ЯаРТШЫРЬ бваЮЪ Т ЪРТлзЪРе, Ш Т аХУгЫпаЭЮХ ТлаРЦХЭШХ ТЪЫозРХвбп ЭгЦЭлЩ бШЬТЮЫ ЭЮТЮЩ бваЮЪШ. ЅЮ ХбЫШ ТЬХбвЮ qq(…) ШбЯЮЫмЧЮТРвм ЧРЯШбм q(…), Т аХУгЫпаЭЮХ ТлаРЦХЭШХ СгФХв ТЪЫозХЭ ЭХЮСаРСЮвРЭЭлЩ ЬХвРбШЬТЮЫ \n, ЪЮвЮалЩ бЮТЯРФРХв б бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ, ЭЮ ЭХ пТЫпХвбп бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ. ВРЪШЬ ЮСаРЧЮЬ, ЮЭ ЭХ СгФХв бзШвРвмбп ЯаШЧЭРЪЮЬ ЧРТХаиХЭШп ЪЮЬЬХЭвРаШп Ш СгФХв гФРЫХЭ ТЬХбвХ б ФагУШЬШ бШЬТЮЫРЬШ[26].
АХЧгЫмвРв дРЧл C ЯаХФбвРТЫпХв бЮСЮЩ ЯЮЫЭЮжХЭЭЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ, ШбЯЮЫмЧгХЬЮХ ЬХеРЭШЧЬЮЬ ФЫп ЯЮШбЪР бЮТЯРФХЭШЩ. јХеРЭШЧЬ ЭХ ЯаШЬХЭпХв ТлаРЦХЭШХ ЭРЯапЬго, Р ЪЮЬЯШЫШагХв ХУЮ ТЮ ТЭгваХЭЭХХ ЯаХФбвРТЫХЭШХ. П ЭРЧлТРо нвг бвРФШо «дРЧЮЩ D». µбЫШ ЭР дРЧХ B ЭХ ЯаЮШЧТЮФШЫРбм ШЭвХаЯЮЫпжШп ЯХаХЬХЭЭле, ЮФЭг Ш вг ЦХ ЮвЪЮЬЯШЫШаЮТРЭЭго дЮаЬг ЬЮЦЭЮ СлЫЮ Сл ЯаШЬХЭпвм ЯаШ ЪРЦФЮЬ ТлЯЮЫЭХЭШШ ЮЯХаРвЮаР ЯЮШбЪР Т ЯаЮжХббХ аРСЮвл ЯаЮУаРЬЬл — нвЮ ЮСХбЯХзШЫЮ Сл ЭХЬРЫго нЪЮЭЮЬШо ТаХЬХЭШ. Б ФагУЮЩ бвЮаЮЭл, ЭРЫШзШХ ШЭвХаЯЮЫпжШШ ЮЧЭРзРХв, звЮ ЯаШ ЬЭЮУЮЪаРвЭЮЬ ТлЯЮЫЭХЭШШ нвЮУЮ ЮЯХаРвЮаР Т ЯаЮУаРЬЬХ ЬЮУгв ШбЯЮЫмЧЮТРвмбп аРЧЭлХ аХУгЫпаЭлХ ТлаРЦХЭШп, ЯЮнвЮЬг дРЧл B–D ЯаШеЮФШвбп ЪРЦФлЩ аРЧ ТлЯЮЫЭпвм ЧРЭЮТЮ. ІРЦЭлЬ ЯЮбЫХФбвТШпЬ нвЮУЮ дРЪвР ЯЮбТпйХЭ аРЧФХЫ «єЮЬЯШЫпжШп аХУгЫпаЭле ТлаРЦХЭШЩ, ЬЮФШдШЪРвЮа /o Ш нддХЪвШТЭЮбвм» (б. <$R[P#,R7-50]>). ВРЪЦХ ЧР ФЮЯЮЫЭШвХЫмЭЮЩ ШЭдЮаЬРжШХЩ ЯЮ нвЮЩ вХЬХ ЮСаРйРЩвХбм Ъ аРЧФХЫг «єниШаЮТРЭШХ ЯаШ ЪЮЬЯШЫпжШШ» УЫРТл 5 (б. <$R[P#,R5-6]>).
<$M[R7-10]>АРЧЮСаРТиШбм б ЭХЪЮвЮалЬШ ТРЦЭлЬШ, ЭЮ ТбХ ЦХ ТвЮаЮбвХЯХЭЭлЬШ ТЮЯаЮбРЬШ, Ьл ЯХаХеЮФШЬ бЮСбвТХЭЭЮ Ъ ФШРЫХЪвг аХУгЫпаЭле ТлаРЦХЭШЩ Perl. І Perl ШбЯЮЫмЧгХвбп ваРФШжШЮЭЭлЩ ЬХеРЭШЧЬ Ѕє°. ±РЧЮТлЩ ЭРСЮа ЬХвРбШЬТЮЫЮТ ТЭХиЭХ ЭРЯЮЬШЭРХв egrep, ЮФЭРЪЮ ЭР нвЮЬ ТбХ беЮФбвТЮ б egrep ЧРЪРЭзШТРХвбп. ІРЦЭХЩиШХ аРЧЫШзШп бТпЧРЭл б вШЯЮЬ ЬХеРЭШЧЬР Ш ЬЭЮЦХбвТЮЬ ФЮЯЮЫЭШвХЫмЭле ЬХвРбШЬТЮЫЮТ, ЮСХбЯХзШТРойШе ЪРЪ гФЮСбвТЮ ЧРЯШбШ, вРЪ Ш аРбиШаХЭЭлЩ ЭРСЮа ТЮЧЬЮЦЭЮбвХЩ. І нЫХЪваЮЭЭЮЩ ФЮЪгЬХЭвРжШШ Perl ЯаШТХФХЭР ЫШим ЪаРвЪРп бТЮФЪР ФШРЫХЪвР аХУгЫпаЭле ТлаРЦХЭШЩ Perl, ЯЮнвЮЬг п ЯЮбвРаРобм ЯаХФЮбвРТШвм СЮЫХХ ЯЮФаЮСЭлХ бТХФХЭШп.
І Perl аХРЫШЧЮТРЭл ЮСлзЭлХ ЬРЪбШЬРЫмЭлХ ЪТРЭвШдШЪРвЮал, ЮФЭРЪЮ Т Perl5 ЯЮпТШЫШбм Ше ЬШЭШЬРЫмЭлХ РЭРЫЮУШ, Ю ЪЮвЮале УЮТЮаШЫЮбм Т УЫРТХ 4. јРЪбШЬРЫмЭлХ<$M[R7-18]> ЪТРЭвШдШЪРвЮал ШЭЮУФР ЭРЧлТРовбп «ЦРФЭлЬШ» (greedy), Р ЬШЭШЬРЫмЭлХ<$M[R7-19]> — «ЫХЭШТлЬШ» (lazy). єТРЭвШдШЪРвЮал Perl ЯХаХзШбЫХЭл Т вРСЫ. 7.4.
ВРСЫШжР 7.4. єТРЭвШдШЪРвЮал Perl (ЬРЪбШЬРЫмЭлХ Ш ЬШЭШЬРЫмЭлХ)
|
єЮЫШзХбвТЮ ЯЮТвЮаХЭШЩ |
ВаРФШжШЮЭЭлЩ ЬРЪбШЬРЫмЭлЩ ЪТРЭвШдШЪРвЮа |
јШЭШЬРЫмЭлЩ ЪТРЭвШдШЪРвЮа[27] |
|
їаЮШЧТЮЫмЭЮХ (0, 1 Ш СЮЫХХ) |
* |
*? |
|
ѕФЭЮ Ш СЮЫХХ |
+ |
+? |
|
ЅХЮСпЧРвХЫмЭлЩ нЫХЬХЭв (0 ШЫШ 1) |
? |
?? |
|
І ЧРФРЭЭЮЬ ШЭвХаТРЫХ (ЭХ ЬХЭмиХ ЬШЭ Ш ЭХ СЮЫмиХ ЬРЪб) |
{ЬШЭ,ЬРЪб} |
{ЬШЭ,ЬРЪб}? |
|
ЅШЦЭпп УаРЭШжР (ЭХ ЬХЭмиХ ЬШЭ) |
{ЬШЭ, } |
{ЬШЭ, }? |
|
ВЮзЭЮХ ЧРФРЭЭЮХ зШбЫЮ[28] |
{зШбЫЮ} |
{зШбЫЮ}? |
јШЭШЬРЫмЭлХ ТХабШШ пТЫповбп ЯаШЬХаЮЬ аРбиШаХЭШЩ ФШРЫХЪвР аХУгЫпаЭле ТлаРЦХЭШЩ, ЯЮпТШТиШебп Т Perl5. ВаРФШжШЮЭЭЮ ЪЮЭбвагЪжШп ТШФР *? ЭХ ШЬХЫР бЬлбЫР Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ (СЮЫХХ вЮУЮ, Т Perl4 ЮЭР бзШвРХвбп бШЭвРЪбШзХбЪЮЩ ЮиШСЪЮЩ), ЯЮнвЮЬг »РааШ бзХЫ ТЮЧЬЮЦЭлЬ ЧРЪаХЯШвм ЧР ЭХЩ ЭЮТлЩ бЬлбЫ. ВРЪЦХ ЯаХФЫРУРЫЮбм ФЫп ЬШЭШЬРЫмЭле ЪТРЭвШдШЪРвЮаЮТ ТлСаРвм ЮСЮЧЭРзХЭШп ТШФР **, ++ Ш в. Ф. ЅРТХаЭЮХ, Т нвЮЬ звЮ-вЮ Хбвм, ЮФЭРЪЮ ЯаЮСЫХЬл б ТлСЮаЮЬ ЧРЯШбШ ФЫп [{ЬШЭ,ЬРЪб}] ЧРбвРТШЫШ »РааШ ТлСаРвм ТРаШРЭв б ЯаШбЮХФШЭХЭШХЬ ТЮЯаЮбШвХЫмЭЮУЮ ЧЭРЪР. єЮЭбвагЪжШп [**] Ш ХХ РЭРЫЮУШ ЮбвРовбп ФЫп СгФгйШе аРбиШаХЭШЩ.
јЭЮУШХ РбЯХЪвл ТЫШпЭШп ЬШЭШЬРЫмЭле ЪТРЭвШдШЪРвЮаЮТ ЭР нддХЪвШТЭЮбвм аРббЬРваШТРЫШбм Т УЫРТХ 5, Т аРЧФХЫРе «їЮФаЮСЭлЩ РЭРЫШЧ ТЫШпЭШп ЪагУЫле бЪЮСЮЪ Ш ТЮЧТаРвЮТ ЭР СлбваЮФХЩбвТШХ» (бЬ. б. <$R[P#,R5-21]>) Ш «їаЮбвЮХ ЯЮТвЮаХЭШХ» (бЬ. б. <$R[P#,R5-2]>). ґагУШХ ЯЮбЫХФбвТШп ЭРЯапЬго ЮСгбЫЮТЫХЭл ЯаШаЮФЮЩ ЬХеРЭШЧЬР Ѕє° Perl, гЯаРТЫпХЬЮУЮ аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ.
ІлСШаРвм ЬХЦФг ЬРЪбШЬРЫмЭлЬШ Ш ЬШЭШЬРЫмЭлЬШ ЪТРЭвШдШЪРвЮаРЬШ ЯаШеЮФШвбп ЭХ вРЪ гЦ зРбвЮ, ЯЮбЪЮЫмЪг ЮЭШ ШЬХов бвЮЫм аРЧЭлЩ бЬлбЫ. ЅЮ ХбЫШ вРЪРп бШвгРжШп ТбХ ЦХ ТЮЧЭШЪРХв, ТлСЮа СгФХв ЧРТШбХвм Юв бШвгРжШШ. їаЮРЭРЫШЧШаЮТРТ ЪЮЫШзХбвТЮ ТЮЧТаРвЮТ, ЪЮвЮалХ ЯЮваХСговбп Т вЮЬ Ш Т ФагУЮЬ бЫгзРХ ФЫп ЯЮЫгзХЭШп ЦХЫРХЬЮУЮ аХЧгЫмвРвР, ЬЮЦЭЮ ЯаШЭпвм ЮСЮбЭЮТРЭЭЮХ аХиХЭШХ. ЅРЯаШЬХа, Т бвРвмХ ШЧ РТУгбвЮТбЪЮУЮ ЭЮЬХаР «The Perl Journal» ЧР 1996 УЮФ п ШббЫХФго ЭХбЪЮЫмЪЮ ТРаШРЭвЮТ аХиХЭШп ЯаЮбвЮЩ ЧРФРзШ, Т вЮЬ зШбЫХ Ш аХиХЭШп б ШбЯЮЫмЧЮТРЭШХЬ ЬРЪбШЬРЫмЭле Ш ЬШЭШЬРЫмЭле ЪТРЭвШдШЪРвЮаЮТ.
П зРбвЮ ТШЦг, звЮ ЯаЮУаРЬЬШбвл ШбЯЮЫмЧгов ЪЮЭбвагЪжШШ б ЬШЭШЬРЫмЭлЬШ ЪТРЭвШдШЪРвЮаРЬШ ЪРЪ гФЮСЭго ЧРЬХЭг ФЫп ШЭТХавШаЮТРЭЭле бШЬТЮЫмЭле ЪЫРббЮТ — ЭРЯаШЬХа, [<(.+?)>] ТЬХбвЮ [<([^>]+)>]. ёЭЮУФР ЯЮФЮСЭРп ЧРЬХЭР аРСЮвРХв, еЮвп Ш ЬХЭХХ нддХЪвШТЭЮ — жШЪЫ, бТпЧРЭЭлЩ б ЪТРЭвШдШЪРвЮаЮЬ * ШЫШ +, ФЮЫЦХЭ ЯЮбвЮпЭЭЮ ЮбвРЭРТЫШТРвмбп Ш ЯаЮТХапвм, бЮТЯРФРХв ЫШ ЮбвРТиРпбп зРбвм аХУгЫпаЭЮУЮ ТлаРЦХЭШп. І зРбвЭЮбвШ, Т ЯаШТХФХЭЭЮЬ ЯаШЬХаХ ЮЭР бЮЯапЦХЭР б ТаХЬХЭЭлЬ ТлеЮФЮЬ ШЧ ЪагУЫле бЪЮСЮЪ, звЮ, ЪРЪ СлЫЮ ЯЮЪРЧРЭЮ Т УЫРТХ 5, вРЪЦХ бТпЧРЭЮ б ЮЯаХФХЫХЭЭлЬШ ЧРваРвРЬШ (б. <$R[P#,R5-4]>). ґРЦХ ЭХбЬЮвап ЭР вЮ, звЮ ЬШЭШЬРЫмЭго ЪЮЭбвагЪжШо ЫХУзХ ТТХбвШ Ш, ТХаЮпвЭЮ, ЫХУзХ ЯаЮзШвРвм, ЭХ бЮТХаиШвХ ЮиШСЪШ: ЮЭШ ЬЮУгв бЮТЯРФРвм б аРЧЭлЬ вХЪбвЮЬ.
їаХЦФХ ТбХУЮ, ЯаШ ЮвбгвбвТШШ ЬЮФШдШЪРвЮаР /s (б. <$R[P#,R7-51]>) вЮзЪР Т ЯЮФТлаРЦХЭШШ [.+?] ЭХ бЮТЯРФРХв б бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ, Р Т ШЭТХавШаЮТРЭЭЮЬ ЪЫРббХ [[^>]+] — бЮТЯРФРХв.
±ЮЫХХ бХамХЧЭРп ЯаЮСЫХЬР, ЪЮвЮаго ЭХвагФЭЮ гЯгбвШвм ШЧ ТШФг, ЯаЮпТЫпХвбп ЯаШ ЯаЮбвЮЩ аРЧЬХвЪХ вХЪбвР, Т ЪЮвЮаЮЩ ЪЮЭбвагЪжШп <…> ШбЯЮЫмЧгХвбп ФЫп бЬлбЫЮТЮУЮ ТлФХЫХЭШп:
Fred was very, <very> angry. <Angry!> I tell you.
їаХФЯЮЫЮЦШЬ, Тл еЮвШвХ ЮбЮСлЬ ЮСаРЧЮЬ ЮСаРСЮвРвм ЯЮЬХзХЭЭлЩ вХЪбв, ЪЮвЮалЩ ЧРТХаиРХвбп ТЮбЪЫШжРвХЫмЭлЬ ЧЭРЪЮЬ. ѕФЭЮ ШЧ ТлаРЦХЭШЩ, бЮТЯРФРойХХ б ЯЮЬХзХЭЭлЬ вХЪбвЮЬ, ТлУЫпФШв вРЪ: [<([^>]*!)>]. ѕФЭРЪЮ ТлаРЦХЭШХ [<(.*?!)>], ФРЦХ Т бЮзХвРЭШШ б ЬЮФШдШЪРвЮаЮЬ /s, ФРХв бЮТХаиХЭЭЮ ШЭЮЩ аХЧгЫмвРв. їХаТЮХ ТлаРЦХЭШХ бЮТЯРФРХв б …Angry!…, Р ТвЮаЮХ — б …very> angry. <Angry!….
ЅХЮСеЮФШЬЮ ЧРЯЮЬЭШвм, звЮ ШЭТХавШаЮТРЭЭлЩ ЪЫРбб Т [[^>]*>] ЭШЪЮУФР ЭХ бЮТЯРФРХв б >, вЮУФР ЪРЪ ЬШЭШЬРЫмЭРп ЪЮЭбвагЪжШп Т [.*?>] — бЮТЯРФРХв, ХбЫШ нвЮ ЭХЮСеЮФШЬЮ ФЫп ФЮбвШЦХЭШп ЮСйХУЮ бЮТЯРФХЭШп. µбЫШ ЭШзвЮ ЯЮбЫХ ЬШЭШЬРЫмЭЮЩ ЪЮЭбвагЪжШШ ЭХ ЧРбвРТЫпХв ЬХеРЭШЧЬ аХУгЫпаЭле ТлаРЦХЭШЩ ТлЯЮЫЭШвм ТЮЧТаРв, нвР ЯаЮСЫХЬР ЭХ ТЮЧЭШЪРХв. ВХЬ ЭХ ЬХЭХХ, ЪРЪ ФХЬЮЭбваШагХв нвЮв ЯаШЬХа б ТЮбЪЫШжРвХЫмЭлЬ ЧЭРЪЮЬ, ЭХЮСеЮФШЬЮбвм бЮТЯРФХЭШп ЯЮЧТЮЫШв ЬШЭШЬРЫмЭЮЩ ЪЮЭбвагЪжШШ ЯаХЮФЮЫХвм вЮзЪг, ЧР ЪЮвЮаго ЮЭР ЭХ ФЮЫЦЭР ЧРеЮФШвм (Р ШЭТХавШаЮТРЭЭлЩ ЪЫРбб ЧРЩвШ ЭХ бЬЮЦХв).
ЅХбЮЬЭХЭЭЮ, ЬШЭШЬРЫмЭлХ ЪЮЭбвагЪжШШ пТЫповбп бРЬлЬ ЧРЬХзРвХЫмЭлЬ аРбиШаХЭШХЬ ФШРЫХЪвР аХУгЫпаЭле ТлаРЦХЭШЩ Perl5, ЮФЭРЪЮ ШЬШ бЫХФгХв ЯЮЫмЧЮТРвмбп б ЮбвЮаЮЦЭЮбвмо. јШЭШЬРЫмЭРп ЪЮЭбвагЪжШп [.*?] ЯЮзвШ ЭШЪЮУФР ЭХ пТЫпХвбп бЪЮЫмЪЮ-ЭШСгФм ЯаШХЬЫХЬЮЩ ЧРЬХЭЮЩ ФЫп [[^…]*] — ЮЭР ЬЮЦХв ЯЮФЮЩвШ ФЫп ЪЮЭЪаХвЭЮЩ бШвгРжШШ, ЭЮ ЯаШЭжШЯШРЫмЭлХ аРЧЫШзШп Т бЬлбЫХ нвШе ЪЮЭбвагЪжШЩ ЬЮУгв бвРвм ЯаШзШЭЮЩ ЮиШСЮЪ.
єРЪ ЭХЮФЭЮЪаРвЭЮ гЯЮЬШЭРЫЮбм ТлиХ, ЪагУЫлХ бЪЮСЪШ ваРФШжШЮЭЭЮ ТлЯЮЫЭпЫШ ФТХ дгЭЪжШШ: УагЯЯШаЮТЪР Ш бЮеаРЭХЭШХ бЮТЯРТиХУЮ вХЪбвР Т ЯХаХЬХЭЭле $1, $2 Ш в. Ф. (ТЭгваШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп ФЫп бблЫЮЪ ЭР бЮТЯРТиШЩ вХЪбв ШбЯЮЫмЧговбп ЬХвРбШЬТЮЫл<$M[R7-28]> \1, \2 Ш в. Я.) єРЪ ЮСкпбЭпХвбп ЭР б. <$R[P#,R7-52]>, зШбвЮ ТЭХиЭШЬШ аРЧЫШзШпЬШ ФХЫЮ ЭХ ЮУаРЭШзШТРХвбп. єаЮЬХ бШЬТЮЫмЭле ЪЫРббЮТ, Т ЪЮвЮале ЮСаРвЭлХ бблЫЪШ ЭХ ШЬХов бЬлбЫР, ЮСЮЧЭРзХЭШп б \1 ЯЮ \9 ТбХУФР ЮвЭЮбпвбп Ъ ЮСаРвЭлЬ бблЫЪРЬ. ґЮЯЮЫЭШвХЫмЭлХ ЮСЮЧЭРзХЭШп (\10, \11, …) ЬЮУгв ШбЯЮЫмЧЮТРвмбп Т вЮЬ бЫгзРХ, ХбЫШ вЮУЮ ваХСгХв ЪЮЫШзХбвТЮ бЮеаРЭпойШе ЪагУЫле бЪЮСЮЪ Т ТлаРЦХЭШШ (б. <$R[P#,R7-53]>).
ѕФЭЮЩ ШЧ гЭШЪРЫмЭле ЮбЮСХЭЭЮбвХЩ Perl пТЫпХвбп бгйХбвТЮТРЭШХ ФТге аРЧЭЮТШФЭЮбвХЩ ЪагУЫле бЪЮСЮЪ: ваРФШжШЮЭЭлХ ЪагУЫлХ бЪЮСЪШ (…) ФЫп УагЯЯШаЮТЪШ Ш бЮеаРЭХЭШп, Ш ЯЮпТШТиРпбп Т Perl5 ЪЮЭбвагЪжШп<$M[R7-20]> (?:…), ЮУаРЭШзШТРойРпбп УагЯЯШаЮТЪЮЩ. І (?:…) «ЮвЪалТРойРп ЪагУЫРп бЪЮСЪР» Т ФХЩбвТШвХЫмЭЮбвШ ЯаХФбвРТЫпХв бЮСЮЩ ваХебШЬТЮЫмЭго ЯЮбЫХФЮТРвХЫмЭЮбвм (?:, вЮУФР ЪРЪ «ЧРЪалТРойРп бЪЮСЪР» ТлУЫпФШв бвРЭФРавЭЮ.
єРЪ Ш ЯЮбЫХФЮТРвХЫмЭЮбвШ, ШбЯЮЫмЧЮТРЭЭлХ ФЫп ЮСЮЧЭРзХЭШп ЬШЭШЬРЫмЭле ЪТРЭвШдШЪРвЮаЮТ, ЯЮбЫХФЮТРвХЫмЭЮбвм (? аРЭХХ бзШвРЫРбм бШЭвРЪбШзХбЪЮЩ ЮиШСЪЮЩ. ЅРзШЭРп б ТХабШШ 5, ЮЭР ШбЯЮЫмЧгХвбп ЭХЪЮвЮалЬШ аРбиШаХЭШпЬШ пЧлЪР аХУгЫпаЭле ТлаРЦХЭШЩ, ШЧ ЪЮвЮале (?:…) пТЫпХвбп ЫШим ЮФЭШЬ зРбвЭлЬ бЫгзРХЬ. ІбЪЮаХ Ьл ТбваХвШЬбп Ш б ФагУШЬШ ЯаШЬХаРЬШ.
єЮЭбвагЪжШп, ЮУаРЭШзШТРойРпбп УагЯЯШаЮТЪЮЩ (СХЧ бЮеаРЭХЭШп), ЮСЫРФРХв бЫХФгойШЬШ ЯаХШЬгйХбвТРЬШ:
l їЮТлиХЭШХ нддХЪвШТЭЮбвШ ЯЮШбЪР ЧР бзХв ЮвЪРЧР Юв ЧРваРв (ТЮЧЬЮЦЭЮ, ЭХЬРЫле) ЭР бЮеаРЭХЭШХ вХЪбвР, ЪЮвЮалЩ Тл ЭХ бЮСШаРХвХбм ШбЯЮЫмЧЮТРвм.
l ІЮЧЬЮЦЭЮбвм ЯаЮТХФХЭШп гЫгзиХЭЭле ТЭгваХЭЭШе ЮЯвШЬШЧРжШЩ. їЮФТлаРЦХЭШп, ЪЮвЮалХ ЭХ ЭгЦЭЮ ШЧЮЫШаЮТРвм ФЫп жХЫХЩ бЮеаРЭХЭШп, ЬЮУгв Слвм ЯаХЮСаРЧЮТРЭл ЬХеРЭШЧЬЮЬ Ъ СЮЫХХ нддХЪвШТЭЮЬг ТШФг. ЅРЯаШЬХа, ТлаРЦХЭШп [(?:return-to|reply-to):spc] Ш [re(?:turn-to:spc|ply-to:spc)] ЫЮУШзХбЪШ нЪТШТРЫХЭвЭл, ЭЮ ТвЮаЮХ ТлаРЦХЭШХ СлбваХХ ЮСЭРагЦШТРХв ЪРЪ бЮТЯРФХЭШп, вРЪ Ш ЭХгФРзШ (ХбЫШ Тл ЬЭХ ЭХ ТХаШвХ, ТЮбЯаЮШЧТХФШвХ ЯаШЬХЭХЭШХ нвШе ТлаРЦХЭШЩ Ъ вХЪбвг forward-spcandspcreply-tospcfields…). І ЭРбвЮпйХХ ТаХЬп ЬХеРЭШЧЬ аХУгЫпаЭле ТлаРЦХЭШЩ Perl нвЮУЮ ЭХ ФХЫРХв, ЭЮ ТЮЧЬЮЦЭЮ, Т СгФгйХЬ бШвгРжШп ШЧЬХЭШвбп.
l ГФЮСбвТЮ ЯЮбваЮХЭШп аХУгЫпаЭле ТлаРЦХЭШЩ Т бваЮЪЮТЮЬ ТШФХ.
ІЮЧЬЮЦЭЮ, б вЮзЪШ ЧаХЭШп ЯЮЫмЧЮТРвХЫп ЬРЪбШЬРЫмЭго ЯЮЫмЧг ЯаШЭЮбШв ЯЮбЫХФЭШЩ ЯгЭЪв. ІбЯЮЬЭШвХ ЯаШЬХа б РЭРЫШЧЮЬ ФРЭЭле, аРЧФХЫХЭЭле ЧРЯпвлЬШ: ЯЮбЪЮЫмЪг Т ЯХаТЮЩ РЫмвХаЭРвШТХ ШбЯЮЫмЧЮТРЫШбм ФТХ ЯРал ЪагУЫле бЪЮСЮЪ, ТвЮаРп РЫмвХаЭРвШТР бЮеаРЭпЫРбм Т ЯХаХЬХЭЭЮЩ $3 (б. <$R[P#,R7-54]> Ш <$R[P#,R7-55]>). їаШ ЪРЦФЮЬ ШЧЬХЭХЭШШ ЪЮЫШзХбвТР ЪагУЫле бЪЮСЮЪ, ШбЯЮЫмЧгХЬле Т ЯХаТЮЩ РЫмвХаЭРвШТХ, ЯаШеЮФШвбп ШЧЬХЭпвм ТбХ ЯЮбЫХФгойШХ бблЫЪШ. БЮЯаЮТЮЦФХЭШХ ЯаЮУаРЬЬл ЯаХТаРйРХвбп Т ЭРбвЮпйШЩ ЪЮиЬРа, ЮФЭРЪЮ ЭХ-бЮеаРЭпойШХ ЪагУЫлХ бЪЮСЪШ ЬЮУгв бШЫмЭЮ гЯаЮбвШвм ТРиг ЧРФРзг[29].
їЮ вХЬ ЦХ ЯаШзШЭРЬ ЪЮЫШзХбвТЮ бЮеаРЭпойШе ЪагУЫле бЪЮСЮЪ ШУаРХв ТРЦЭго аЮЫм ЯаШ ШбЯЮЫмЧЮТРЭШШ m/…/ Т бЯШбЪЮТЮЬ ЪЮЭвХЪбвХ ШЫШ б ЮЯХаРвЮаЮЬ split. єЮЭЪаХвЭлХ ЯаШЬХал СгФгв ЯаШТХФХЭл ЭШЦХ Т бЮЮвТХвбвТгойШе аРЧФХЫРе (б. <$R[P#,R7-56]>, <$R[P#,R7-57]>).
<$M[R7-1]>І Perl5 вРЪЦХ ЯЮпТШЫШбм ЪЮЭбвагЪжШШ ЮЯХаХЦХЭШп (?=…) Ш (?!…). єЮЭбвагЪжШп ЯЮЧШвШТЭЮЩ ЮЯХаХЦРойХЩ ЯаЮТХаЪШ [(?=ЯЮФТлаРЦХЭШХ)], ЯЮ РЭРЫЮУШШ б ЮСлзЭлЬШ ЭХ-бЮеаРЭпойШЬШ ЪагУЫлЬШ бЪЮСЪРЬШ, ШбвШЭЭР Т вЮЬ бЫгзРХ, ХбЫШ ЯЮФТлаРЦХЭШХ бЮТЯРФРХв. ѕФЭРЪЮ ЯЮФТлаРЦХЭШХ Т нвЮЩ ЪЮЭбвагЪжШШ ЭХ «ЯЮУЫЮйРХв» бШЬТЮЫЮТ жХЫХТЮЩ бваЮЪШ — ЪЮЭбвагЪжШп ЮЯХаХЦРойХЩ ЯаЮТХаЪШ, ЪРЪ Ш ЬХвРбШЬТЮЫл УаРЭШжл бЫЮТР, бЮТЯРФРХв б ЯЮЧШжШХЩ бваЮЪШ. ВРЪШЬ ЮСаРЧЮЬ, ЮЯХаХЦРойРп ЯаЮТХаЪР ЭХ ШЧЬХЭпХв бЮФХаЦШЬЮУЮ ЯХаХЬХЭЭЮЩ $& ШЫШ ЫоСле ТЭХиЭШе ЪагУЫле бЪЮСЮЪ. НвЮ ЯЮЧТЮЫпХв ЬХеРЭШЧЬг аХУгЫпаЭле ТлаРЦХЭШЩ «ЧРУЫпЭгвм ТЯХаХФ» СХЧ ЪРЪШе-ЫШСЮ ЯЮбЫХФбвТШЩ.
єЮЭбвагЪжШп ЭХУРвШТЭЮЩ<$M[R7-8]> ЮЯХаХЦРойХЩ ЯаЮТХаЪШ [(?!ЯЮФТлаРЦХЭШХ)] ШбвШЭЭР Т вЮЬ бЫгзРХ, ХбЫШ бЮТЯРФХЭШХ ФЫп ЯЮФТлаРЦХЭШп Т бваЮЪХ ЭХ бгйХбвТгХв. ЅР ЯХаТлЩ ТЧУЫпФ ЭХУРвШТЭЮХ ЮЯХаХЦХЭШХ ЪРЦХвбп ЫЮУШзХбЪШЬ РЭРЫЮУЮЬ ШЭТХавШаЮТРЭЭЮУЮ бШЬТЮЫмЭЮУЮ ЪЫРббР, ЮФЭРЪЮ ЬХЦФг ЭШЬШ бгйХбвТгов ФТР ЯаШЭжШЯШРЫмЭле аРЧЫШзШп:
l ґЫп гбЯХиЭЮУЮ бЮТЯРФХЭШп ШЭТХавШаЮТРЭЭлЩ бШЬТЮЫмЭлЩ ЪЫРбб ФЮЫЦХЭ б зХЬ-вЮ бЮТЯРФРвм, звЮ ЯаШТЮФШв Ъ ЯЮУЫЮйХЭШо вХЪбвР. ЅХУРвШТЭРп ЮЯХаХЦРойРп ЯаЮТХаЪР гбЯХиЭР Т вЮЬ бЫгзРХ, ХбЫШ ЯЮФТлаРЦХЭШХ ЭХ бЮТЯРФРХв ЭШ б зХЬ. НвЮ ЮСбвЮпвХЫмбвТЮ ЯаЮФХЬЮЭбваШаЮТРЭЮ ТЮ ТвЮаЮЬ Ш ваХвмХЬ ЯаШЬХаРе, ЯаШТХФХЭЭле ЭШЦХ.
l БШЬТЮЫмЭлЩ ЪЫРбб (ШЭТХавШаЮТРЭЭлЩ ШЫШ ЭХв) бЮТЯРФРХв аЮТЭЮ б ЮФЭШЬ бШЬТЮЫЮЬ жХЫХТЮУЮ вХЪбвР. ѕЯХаХЦРойРп ЯаЮТХаЪР (ЯЮЧШвШТЭРп ШЫШ ЭХУРвШТЭРп) ЬЮЦХв ЯаШЬХЭпвмбп Ъ бЪЮЫм гУЮФЭЮ бЫЮЦЭЮЬг аХУгЫпаЭЮЬг ТлаРЦХЭШо.
АРббЬЮваШЬ ЭХбЪЮЫмЪЮ ЯаШЬХаЮТ ЮЯХаХЦРойХЩ ЯаЮТХаЪШ:
[Bill(?=spcThe Cat|spcClinton)]
БЮТЯРФРХв б Bill, ЭЮ ЫШим Т вЮЬ бЫгзРХ, ХбЫШ ФРЫмиХ бЫХФгХв spcThespcCat ШЫШ spcClinton.
[\d+(?!\.)]
БЮТЯРФРХв б зШбЫЮЬ, ХбЫШ ЧР ЭШЬ ЭХ бЫХФгХв вЮзЪР.
[\d+(?=[^.])]
БЮТЯРФРХв б зШбЫЮЬ, ХбЫШ ЧР ЭШЬ бЫХФгХв ЭХ вЮзЪР, Р звЮ-вЮ ФагУЮХ. ГСХФШвХбм Т вЮЬ, звЮ Тл ЯЮЭШЬРХвХ, зХЬ нвЮ ТлаРЦХЭШХ ЮвЫШзРХвбп Юв ЯаХФлФгйХУЮ — ЯаХФбвРТмвХ, звЮ зШбЫЮ ЭРеЮФШвбп Т бРЬЮЬ ЪЮЭжХ бваЮЪШ. ІЯаЮзХЬ, п ЫгзиХ ЧРФРЬ ЮзХаХФЭЮЩ ТЮЯаЮб. <$M[R7-61]>єРЪЮХ ШЧ ФТге ЯЮбЫХФЭШе ТлаРЦХЭШЩ бЮТЯРФХв Т бваЮЪХ OHspc44272 Ш УФХ ШЬХЭЭЮ? refїЮФгЬРЩвХ ЭРФ нвШЬ ТЮЯаЮбЮЬ, ЧРвХЬ ЯХаХТХаЭШвХ бваРЭШжг Ш ЯаЮТХамвХ бТЮЩ ЮвТХв.
[^(?![A-Z]*$)[a-zA-Z]*$]
БЮТЯРФРХв, ХбЫШ ЮСкХЪв бЮбвЮШв вЮЫмЪЮ ШЧ ЮФЭШе СгЪТ, ЭЮ ЭХ вЮЫмЪЮ Т ТХаеЭХЬ аХУШбваХ.
[^(?=.*?this)(?=.*?that)]
ІХбмЬР ШЧЮСаХвРвХЫмЭлЩ (еЮвп Ш ЭХ бРЬлЩ аРЧгЬЭлЩ) бЯЮбЮС ЯаЮТХаЪШ вЮУЮ, бгйХбвТгов ЫШ Т жХЫХТЮЬ вХЪбвХ бЮТЯРФХЭШп ФЫп [this] Ш ФЫп [that]. ±ЮЫХХ ЫЮУШзЭЮХ Ш Т жХЫЮЬ бЮТЬХбвШЬЮХ аХиХЭШХ — ФТЮЩЭЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ /this/ && /that/[30].
ґагУШХ еРаРЪвХаЭлХ ЯаШЬХал ЯаШТХФХЭл Т аРЧФХЫХ «БШЭеаЮЭШЧРжШп бЮТЯРФХЭШЩ» (б. <$R[P#,R7-58]>). ґЫп ТРиХУЮ аРЧТЫХзХЭШп ЯаШТХФг ЮбЮСХЭЭЮ еШвалЩ ЯаШЬХа, ТЧпвлЩ ШЧ аРЧФХЫР «АРЧФХЫХЭШХ УагЯЯ аРЧапФЮТ ЧРЯпвлЬШ» (б. <$R[P#,R7-59]>)<$M[R7-62]>:
s<
(\d{1,3} # ѕв ЮФЭЮЩ ФЮ ваХе жШда ЯХаХФ ЧРЯпвЮЩ
(?= # їЮбЫХ зХУЮ бЫХФгов, ЭЮ ЭХ ТЪЫозРовбп Т бЮТЯРФХЭШХ...
(?:\d\d\d)+ # ЅХЪЮвЮаЮХ ЪЮЫШзХбвТЮ ваШЯЫХвЮТ...
(?!\d) # ...ЧР ЪЮвЮалЬШ ЭХ бЫХФгХв ЮзХаХФЭРп жШдаР
) # (ШЭРзХ УЮТЮап, зШбЫЮ ЧРТХаиРХвбп)
><$1,>gx
єагУЫлХ бЪЮСЪШ ЮЯХаХЦРойХЩ ЯаЮТХаЪШ ЭХ бЮеаРЭпов вХЪбвР Ш ЭХ бзШвРовбп ЯРаРЬШ ЪагУЫле бЪЮСЮЪ ЯаШ ЭгЬХаРжШШ ЯХаХЬХЭЭле. ВХЬ ЭХ ЬХЭХХ, ЮЭШ ЬЮУгв бЮФХаЦРвм ЪагУЫлХ бЪЮСЪШ ФЫп бЮеаРЭХЭШп «ЯаХФЯЮЫЮЦШвХЫмЭЮ бЮТЯРФРойХУЮ» вХЪбвР. ЕЮвп п ЭХ аХЪЮЬХЭФго ЧЫЮгЯЮваХСЫпвм нвЮЩ ТЮЧЬЮЦЭЮбвмо, Т ЭХЪЮвЮале бШвгРжШпе ЮЭР ЯЮЫХЧЭР. ЅРЯаШЬХа, [(.*?)(?=<(strong|em)\s*>)] бЮТЯРФРХв бЮ ТбХЬШ бШЬТЮЫРЬШ ФЮ вХУЮТ HTML <strong> ШЫШ <em>, ЭЮ ЭХ ТЪЫозРп Ше. їЮУЫЮйХЭЭлЩ вХЪбв ЯаШбТРШТРХвбп ЯХаХЬХЭЭЮЩ $1 (Ш, ЪЮЭХзЭЮ, ЯХаХЬХЭЭЮЩ $&), Р бРЬ вХУ <strong> ШЫШ <em>, СЫРУЮФРап ЪЮвЮаЮЬг бвРЫЮ ТЮЧЬЮЦЭлЬ бЮТЯРФХЭШХ, ЯаШбТРШТРХвбп ЯХаХЬХЭЭЮЩ $2. µбЫШ ТРб ЭХ ШЭвХаХбгХв, ЪРЪЮЩ ШЬХЭЭЮ вХУ ЯаШТХЫ Ъ гбЯХиЭЮЬг ЯаХЪаРйХЭШо ЯЮШбЪР, ЪЮЭбвагЪжШо […(strong|em)…] ЫгзиХ ЧРЯШбРвм Т ТШФХ […(?:strong|em)…], звЮСл ШЧСХЦРвм ЫШиЭХУЮ бЮеаРЭХЭШп вХЪбвР. І ЯаШЬХаХ ЭР б. <$R[P#,R7-60]> ЯЮФТлаРЦХЭШХ [(?=(.*))] ЯаШЬХЭпХвбп ФЫп ШЬШвРжШШ $& (ШЧ-ЧР СЮЫмиШе ЧРваРв ШбЯЮЫмЧЮТРвм $& ЭХ аХЪЮЬХЭФгХвбп — бЬ. б. <$R[P#,R7-3]>).
БЮеаРЭпойШХ ЪагУЫлХ бЪЮСЪШ Т ЪЮЭбвагЪжШШ б ЭХУРвШТЭлЬ ЮЯХаХЦХЭШХЬ РСбЮЫовЭЮ СХббЬлбЫХЭЭл, ЯЮбЪЮЫмЪг нвР ЪЮЭбвагЪжШп бЮТЯРФРХв ЫШим ЯаШ ЮвбгвбвТШШ бЮТЯРФХЭШп ФЫп ХХ ЯЮФТлаРЦХЭШп.
єРЪ бЯаРТХФЫШТЮ ЯаХФгЯаХЦФРХв бваРЭШжР агЪЮТЮФбвТР perlre, ЮЯХаХЦРойРп ЯаЮТХаЪР ЯаШЭжШЯШРЫмЭЮ ЮвЫШзРХвбп Юв аХваЮбЯХЪвШТЭЮЩ. ѕЯХаХЦРойРп ЯаЮТХаЪР ЮСХбЯХзШТРХв ШбвШЭЭЮбвм гбЫЮТШп (ЭРЫШзШХ ШЫШ ЮвбгвбвТШХ бЮТЯРФХЭШп ФЫп ЧРФРЭЭЮУЮ ЯЮФТлаРЦХЭШп) ФЫп ЪЮЭЪаХвЭЮЩ ЭРзРЫмЭЮЩ ЯЮЧШжШШ Ш б ЭРЯаРТЫХЭШХЬ ЯЮШбЪР бЫХТР ЭРЯаРТЮ. АХваЮбЯХЪвШТЭРп ЯаЮТХаЪР, ХбЫШ Сл ЮЭР ЪРЪШЬ-вЮ ЮСаРЧЮЬ ЯЮФФХаЦШТРЫРбм, ШбЪРЫЮ Сл бЮТЯРФХЭШп бЯаРТР ЭРЫХТЮ.
їЮЧШвШТЭРп Ш ЭХУРвШТЭРп ЮЯХаХЦРойРп ЯаЮТХаЪР
bref ѕвТХв ЭР ТЮЯаЮб бЮ б. <$R[P#,R7-61]>
ѕСР ТлаРЦХЭШп, [\d+(?!\.)] Ш [\d+(?=[^.])], бЮТЯРФРов Т бваЮЪХ OHspc44272. їХаТЮХ бЮТЯРФРХв б OHspc44272, Р ТвЮаЮХ — б OHspc44272.
їЮЬЭШвХ: ЬРЪбШЬРЫмЭлЩ ЪТРЭвШдШЪРвЮа ТбХУФР ЮвбвгЯРХв, ХбЫШ нвЮ ЭХЮСеЮФШЬЮ ФЫп ЯЮЫгзХЭШп ЮСйХУЮ бЮТЯРФХЭШп. їЮбЪЮЫмЪг [\d+(?=[^.])] ваХСгХв, звЮСл ЯЮбЫХ бЮТЯРТиХУЮ зШбЫР бЫХФЮТРЫ бШЬТЮЫ, ЮвЫШзЭлЩ Юв вЮзЪШ, ЪТРЭвШдШЪРвЮа гбвгЯРХв зРбвм зШбЫР, звЮСл ЯаШ ЭХЮСеЮФШЬЮбвШ ЮЭР ЬЮУЫР ШЭвХаЯаХвШаЮТРвмбп ЪРЪ «ЭХ-вЮзЪР».
ВагФЭЮ бЪРЧРвм, ФЫп зХУЮ ЬЮУЫШ Сл ЯЮЭРФЮСШвмбп вРЪШХ ТлаРЦХЭШп, ЭЮ Ше, ТХаЮпвЭЮ, бЫХФЮТРЫЮ Сл ЧРЯШбРвм Т ТШФХ [\d+(?![\d.])] Ш [\d+(?=[^.\d])].
ЅРЯаШЬХа, ТлаРЦХЭШХ [(?!000)\d\d\d] ЮЧЭРзРХв «бЮТЯРФХЭШХ б ваХЬп жШдаРЬШ, ХбЫШ нвЮ ЭХ 000». ВХЬ ЭХ ЬХЭХХ, Тл ФЮЫЦЭл еЮаЮиЮ ЯЮЭШЬРвм, звЮ ЮЭЮ ЭХ ЮЧЭРзРХв «бЮТЯРФХЭШХ б ваХЬп жШдаРЬШ, ХбЫШ ШЬ ЭХ ЯаХФиХбвТгХв 000». НвЮ гЦХ СлЫЮ Сл аХваЮбЯХЪвШТЭЮЩ ЯаЮТХаЪЮЩ, ЪЮвЮаРп ЭХ ЯЮФФХаЦШТРХвбп Т Perl Ш ТЮЮСйХ ЭШ Т ЮФЭЮЬ ШЧ ШЧТХбвЭле ЬЭХ ФШРЫХЪвЮТ аХУгЫпаЭле ТлаРЦХЭШЩ. ІЯаЮзХЬ, ЫоСЮЩ ЭРзРЫмЭлЩ пЪЮам (вШЯ, бваЮЪР ШЫШ бЫЮТЮ) ЬЮЦЭЮ аРббЬРваШТРвм ЪРЪ ЮУаРЭШзХЭЭго аРЧЭЮТШФЭЮбвм аХваЮбЯХЪвШТЭЮЩ ЯаЮТХаЪШ.
ѕЯХаХЦРойРп ЯаЮТХаЪР зРбвЮ ШбЯЮЫмЧгХвбп Т ЪЮЭжХ ТлаРЦХЭШп, звЮСл ЯаХФЮвТаРвШвм бЮТЯРФХЭШХ Т вЮЬ бЫгзРХ, ХбЫШ вЮ, звЮ ЧР ЭШЬ бЫХФгХв, гФЮТЫХвТЮапХв (ШЫШ ЭРЮСЮаЮв, ЭХ гФЮТЫХвТЮапХв) ЮЯаХФХЫХЭЭлЬ гбЫЮТШпЬ. ЕЮвп ШбЯЮЫмЧЮТРЭШХ нвЮЩ ЪЮЭбвагЪжШШ Т ЭРзРЫХ ТлаРЦХЭШп ЬЮЦХв Слвм ЯаШЧЭРЪЮЬ ЮиШСЮзЭЮЩ аХРЫШЧРжШШ аХваЮбЯХЪвШТЭЮЩ ЯаЮТХаЪШ, Т ЭХЪЮвЮале бШвгРжШпе нвЮ ЯЮЬЮУРХв бФХЫРвм ТлаРЦХЭШХ СЮЫХХ ЮСйШЬ. єаЮЬХ ЯаШЬХаР б 000, бЫХФгХв гЯЮЬпЭгвм<$M[R7-2]> ЮС ШбЯЮЫмЧЮТРЭШШ [(?!0+\.0+\.0+\.0+\b)] ФЫп ЯЮФРТЫХЭШп IP-РФаХбЮТ, бЮбвЮпйШе ШЧ ЮФЭШе ЭгЫХЩ (бЬ. УЫРТг 4, б. <$R[P#,R4-33]>). єРЪ СлЫЮ ЯЮЪРЧРЭЮ Т аРЧФХЫХ «ІЮЧТаРв б УЫЮСРЫмЭЮЩ вЮзЪШ ЧаХЭШп» УЫРТл 5 (б. <$R[P#,R5-22]>), ЮЯХаХЦРойРп ЯаЮТХаЪР Т ЭРзРЫХ ТлаРЦХЭШп ЬЮЦХв ЮЪРЧРвмбп нддХЪвШТЭлЬ баХФбвТЮЬ ФЫп гбЪЮаХЭШп ЯЮШбЪР.
±гФмвХ ТЭШЬРвХЫмЭл б ЭХУРвШТЭЮЩ ЮЯХаХЦРойХЩ ЯаЮТХаЪЮЩ Т ЭРзРЫХ ТлаРЦХЭШп. ІлаРЦХЭШХ [\w+] бЮТЯРФРХв б ЯХаТлЬ бЫЮТЮЬ Т бваЮЪХ, ЮФЭРЪЮ ЯЮбвРТШвм Т ЭРзРЫЮ [(?!cat)] ЭХФЮбвРвЮзЭЮ ФЫп вЮУЮ, звЮСл ТлаРЦХЭШХ ЮЧЭРзРЫЮ «ЯХаТЮХ бЫЮТЮ, ЭХ ЭРзШЭРойХХбп б cat». ІлаРЦХЭШХ [(?!cat)\w+] ЭХ ЬЮЦХв бЮТЯРбвм Т ЭРзРЫХ cattle, ЭЮ ЭШзвЮ ЭХ ЯЮЬХиРХв ХЬг бЮТЯРбвм б cattle. ґЫп ЯЮЫгзХЭШп ЦХЫРХЬЮУЮ нддХЪвР ЭХЮСеЮФШЬЮ ЯаШЭпвм ФЮЯЮЫЭШвХЫмЭлХ ЬХал — ЭРЯаШЬХа, [\b(?!cat)\w+].
єЮЭбвагЪжШп (?#…) ТЮбЯаШЭШЬРХвбп ЪРЪ ЪЮЬЬХЭвРаШЩ<$M[R7-21]> Ш ШУЭЮаШагХвбп. µХ бЮФХаЦШЬЮХ ЭХ ЬЮЦХв Слвм РСбЮЫовЭЮ ЯаЮШЧТЮЫмЭлЬ, ЯЮбЪЮЫмЪг ТбХ ЪЮЯШШ ЮУаРЭШзШвХЫп ЮЯХаРЭФР ФЮЫЦЭл нЪаРЭШаЮТРвмбп[31].
єЮЬЬХЭвРаШШ (?#… ЯЮпТШЫШбм Т ТХабШШ 5.000, ЮФЭРЪЮ ЬЮФШдШЪРвЮа /x Т ТХабШШ 5.002 ЯЮЧТЮЫпХв ТЪЫозРвм Т аХУгЫпаЭлХ ТлаРЦХЭШп ЯаЮбвлХ ЪЮЬЬХЭвРаШШ [#], ЯаЮФЮЫЦРойШХбп ФЮ бЫХФгойХУЮ бШЬТЮЫР ЭЮТЮЩ бваЮЪШ (ШЫШ ФЮ ЪЮЭжР аХУгЫпаЭЮУЮ ТлаРЦХЭШп) ЯЮ РЭРЫЮУШШ б ЪЮЬЬХЭвРаШпЬШ Т ЮСлзЭЮЬ ЪЮФХ (ЯаШЬХа ЯаШТХФХЭ ЭР б. <$R[P#,R7-62]>). јЮФШдШЪРвЮа /x вРЪЦХ ЮСХбЯХзШТРХв ШУЭЮаШаЮТРЭШХ СЮЫмиШЭбвТР ЯаЮЯгбЪЮТ, ЯЮнвЮЬг ТлаРЦХЭШХ
$text =~ m/"([^"\\]*(\\.[^"\\]*)*)",?|([^,]+),?|,/g
ШЧ нвЮУЮ ЯаШЬХаР ЬЮЦЭЮ ЧРЯШбРвм Т СЮЫХХ ЭРУЫпФЭЮЬ ТШФХ:
$text =~ m/ # їЮЫХ ЬЮЦХв ЮвЭЮбШвмбп Ъ ЮФЭЮЬг ШЧ ваХе вШЯЮТ:
# 1) БВАѕє° І є°ІЛЗє°Е
"([^"\\]*(\\.[^"\\]*)*)" # - ЭРЩвШ бваЮЪг Т ЪРТлзЪРе Ш бЮеаРЭШвм Т $1
,? # - гФРЫШвм ЪЮЭХзЭго ЧРЯпвго
| # - ё»ё -
# 2) ѕ±ЛЗЅѕµ їѕ»µ
([^,]+) # - БЮеаРЭШвм вХЪбв ФЮ бЫХФгойХЩ ЧРЯпвЮЩ Т $3
,? # - (гФРЫШвм ЧРЯпвго, ХбЫШ ЮЭР ШЬХХвбп)
| # - ё»ё -
# 3) їГБВѕµ їѕ»µ
, # їаЮбвЮ ЧРЯпвРп
/gx;
АХУгЫпаЭЮХ ТлаРЦХЭШХ ЭШбЪЮЫмЪЮ ЭХ ШЧЬХЭШЫЮбм. єРЪ Ш Т бЫгзРХ б ЪЮЬЬХЭвРаШпЬШ (?#…), ЯаШеЮФШвбп ЯЮЬЭШвм Ю ЧРЪалТРойХЬ ЮУаРЭШзШвХЫХ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, ЯЮнвЮЬг бЮФХаЦШЬЮХ ЪЮЬЬХЭвРаШп ЭХ пТЫпХвбп РСбЮЫовЭЮ ЯаЮШЧТЮЫмЭлЬ. єРЪ Ш ЬЭЮУШХ ФагУШХ ЬХвРбШЬТЮЫл аХУгЫпаЭЮУЮ ТлаРЦХЭШп, [#] Ш ЬХвРбШЬТЮЫл ЯаЮЯгбЪЮТ, РЪвШТШЧШагХЬлХ ЬЮФШдШЪРвЮаЮЬ /x, ЭХФЮбвгЯЭл Т бШЬТЮЫмЭле ЪЫРббРе, ЯЮнвЮЬг ЪЫРббл ЭХ ЬЮУгв бЮФХаЦРвм ЪЮЬЬХЭвРаШХТ ШЫШ ШУЭЮаШагХЬле ЯаЮЯгбЪЮТ. їаЮЯгбЪШ Ш #, ЪРЪ Ш ФагУШХ ЬХвРбШЬТЮЫл аХУгЫпаЭле ТлаРЦХЭШЩ, ЬЮУгв нЪаРЭШаЮТРвмбп б ТлаРЦХЭШпе б ЬЮФШдШЪРвЮаЮЬ /x:
m{
^ # ЅРзРЫЮ бваЮЪШ
(?: # ґРЫХХ бЫХФгХв ЮФЭР ШЧ РЫмвХаЭРвШТ:
From # From
|Subject # Subject
|Date # Date
) #
: # ·РвХЬ бЫХФгХв ФТЮХвЮзШХ...
\ * # ...Ш ЫоСЮХ ЪЮЫШзХбвТЮ ЯаЮСХЫЮТ (ЮСаРвШвХ ТЭШЬРЭШХ ЭР \)
(.*) # БЮеаРЭШвм ЮбвРвЮЪ бваЮЪШ (СХЧ бШЬТЮЫР ЭЮТЮЩ бваЮЪШ) Т $1
}x;
І бЯХжШРЫмЭЮЩ ЪЮЭбвагЪжШШ<$M[R7-23]> [(?ЬЮФШдШЪРвЮал)] вРЪЦХ ШбЯЮЫмЧгХвбп ЧРЯШбм (?, гЯЮЬШЭРТиРпбп Т ЯаХФлФгйХЬ аРЧФХЫХ, ЭЮ ФЫп ФагУШе жХЫХЩ. ВаРФШжШЮЭЭЮ ФЫп ЯЮШбЪР СХЧ гзХвР аХУШбваР ШбЯЮЫмЧЮТРЫбп ЬЮФШдШЪРвЮа /i. ВЮУЮ ЦХ нддХЪвР ЬЮЦЭЮ ФЮСШвмбп Ш ФагУШЬ бЯЮбЮСЮЬ — ТЪЫозШТ Т ЯаЮШЧТЮЫмЭго ЯЮЧШжШо аХУгЫпаЭЮУЮ ТлаРЦХЭШп (ЮСлзЭЮ Т ЭРзРЫЮ) ЪЮЭбвагЪжШо [(?i)]. їаШ ЯЮЬЮйШ нвЮЩ бШЭвРЪбШзХбЪЮЩ ЪЮЭбвагЪжШШ ЬЮЦЭЮ ЧРФРТРвм ЬЮФШдШЪРвЮал /i (ЯЮШбЪ СХЧ гзХвР аХУШбваР), /m (ЬЭЮУЮбваЮзЭлЩ аХЦШЬ), /s (ЮФЭЮбваЮзЭлЩ аХЦШЬ) Ш /x (ЯаЮШЧТЮЫмЭЮХ дЮаЬРвШаЮТРЭШХ). ґЮЯгбЪРХвбп ЮСкХФШЭХЭШХ ЬЮФШдШЪРвЮаЮТ; бЪРЦХЬ, ЪЮЭбвагЪжШп ЪЮЭбвагЪжШп [(?si)] аРТЭЮбШЫмЭР ЮФЭЮТаХЬХЭЭЮЬг ШбЯЮЫмЧЮТРЭШо ЬЮФШдШЪРвЮаЮТ /i Ш /s.
ПЪЮаЭлХ ЬХвРбШЬТЮЫл ЮЪРЧлТРов ЭХЮжХЭШЬго ЯЮЬЮйм ЯаШ ЯЮбваЮХЭШШ ЭРФХЦЭле ТлаРЦХЭШЩ. І Perl бгйХбвТгХв ЭХбЪЮЫмЪЮ аРЧЭЮТШФЭЮбвХЩ нвШе ЬХвРбШЬТЮЫЮТ.
І Perl ЯЮФФХаЦШТРовбп ваРФШжШЮЭЭлХ ЬХвРбШЬТЮЫл<$M[R7-25]> ^ Ш $[32], ЮФЭРЪЮ ЮЭШ ШЭвХаЯаХвШаговбп ЭХбЪЮЫмЪЮ бЫЮЦЭХХ, зХЬ ЮСлзЭЮХ ЭРзРЫЮ ШЫШ ЪЮЭХж бваЮЪШ. їаШ вШЯШзЭЮЬ ЯаЮбвЮЬ ШбЯЮЫмЧЮТРЭШШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп Т жШЪЫХ while (<>) (ЯаШ гбЫЮТШШ, звЮ аРЧФХЫШвХЫм ТеЮФЭле ЧРЯШбХЩ $/ бЮеаРЭпХв ЧЭРзХЭШХ ЯЮ гЬЮЫзРЭШо) Тл ЧЭРХвХ, звЮ ЯаЮТХапХЬлЩ вХЪбв бЮФХаЦШв аЮТЭЮ ЮФЭг ЫЮУШзХбЪго бваЮЪг, ЯЮнвЮЬг аРЧЫШзШп ЬХЦФг «ЭРзРЫЮЬ ЫЮУШзХбЪЮЩ бваЮЪШ» Ш «ЭРзРЫЮЬ даРУЬХЭвР» ЭХбгйХбвТХЭЭл.
ЅЮ ХбЫШ вХЪбв бЮФХаЦШв ТЭгваХЭЭШХ бШЬТЮЫл ЭЮТЮЩ бваЮЪШ, СлЫЮ Сл ЫЮУШзЭЮ ШЭвХаЯаХвШаЮТРвм ХУЮ ЪРЪ бЮТЮЪгЯЭЮбвм ЭХбЪЮЫмЪШе ЫЮУШзХбЪШе бваЮЪ. БгйХбвТгХв ЭХЬРЫЮ бЯЮбЮСЮТ бЮЧФРЭШп вХЪбвР б ТЭгваХЭЭШЬШ бШЬТЮЫРЬШ ЭЮТЮЩ бваЮЪШ (ЭРЯаШЬХа, "this\nway"). ЅЮ ХбЫШ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯаШЬХЭпХвбп Ъ вХЪбвг, ЭХЧРТШбШЬЮ Юв ХУЮ ЯаЮШбеЮЦФХЭШп, УФХ ФЮЫЦЭЮ бЮТЯРФРвм ЯЮФТлаРЦХЭШХ [^…] — Т ЭРзРЫХ ЪРЦФЮЩ ЫЮУШзХбЪЮЩ бваЮЪШ ШЫШ вЮЫмЪЮ Т ЭРзРЫХ ТбХУЮ ЬЭЮУЮбваЮзЭЮУЮ даРУЬХЭвР?
Perl ЯЮЧТЮЫпХв ТлСаРвм ЫоСЮЩ ШЧ нвШе ТРаШРЭвЮТ. ±ЮЫХХ вЮУЮ, Т ЭХЬ ЯаХФгбЬЮваХЭЮ зХвлаХ аРЧЭле аХЦШЬР, ЮЯШбРЭЭле Т вРСЫ. 7.5.
ВРСЫШжР 7.5. АХЦШЬл ЮСаРСЮвЪШ ЫЮУШзХбЪШе бваЮЪ
|
АХЦШЬ |
ёЭвХаЯаХвРжШп жХЫХТЮУЮ вХЪбвР ЬХвРбШЬТЮЫРЬШ ^ Ш $ |
ВЮзЪР |
|
БвРЭФРавЭлЩ |
µФШЭлЩ даРУЬХЭв, ТЭгваХЭЭШХ ЭЮТлХ бваЮЪШ ЭХ гзШвлТРовбп |
ЅХ бЮТЯРФРХв б бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ |
|
ѕФЭЮбваЮзЭлЩ аХЦШЬ |
µФШЭлЩ даРУЬХЭв, ТЭгваХЭЭШХ ЭЮТлХ бваЮЪШ ЭХ гзШвлТРовбп |
БЮТЯРФРХв бЮ ТбХЬШ бШЬТЮЫРЬШ |
|
јЭЮУЮбваЮзЭлЩ аХЦШЬ |
БЮТЮЪгЯЭЮбвм ЫЮУШзХбЪШе бваЮЪ, аРЧФХЫХЭЭле бШЬТЮЫРЬШ ЭЮТЮЩ бваЮЪШ |
(ВЮ ЦХ, звЮ Ш Т бвРЭФРавЭЮЬ аХЦШЬХ) |
|
ЗШбвлЩ ЬЭЮУЮбваЮзЭлЩ аХЦШЬ |
БЮТЮЪгЯЭЮбвм ЫЮУШзХбЪШе бваЮЪ, аРЧФХЫХЭЭле бШЬТЮЫРЬШ ЭЮТЮЩ бваЮЪШ |
БЮТЯРФРХв бЮ ТбХЬШ бШЬТЮЫРЬШ |
їаШ ЮвбгвбвТШШ ТЭгваХЭЭШе бШЬТЮЫЮТ ЭЮТЮЩ бваЮЪШ Т жХЫХТЮЬ вХЪбвХ ТбХ аХЦШЬл ШФХЭвШзЭл[33].
ІЮЧЬЮЦЭЮ, Тл ЧРЬХвШЫШ, звЮ Т вРСЫ. 7.5 ЭХ бЫЮТР ЭХ бЪРЧРЭЮ Ю вЮЬ…
l ЮвЪгФР Т жХЫХТЮЬ вХЪбвХ ЯЮпТШЫШбм ТЭгваХЭЭШХ ЫЮУШзХбЪШХ бваЮЪШ (нвЮ ЭХбгйХбвТХЭЭЮ);
l ЪЮУФР ЬЮЦЭЮ ЯаШЬХЭпвм ТлаРЦХЭШХ Ъ вРЪЮЩ бваЮЪХ (Т ЫоСЮЩ ЬЮЬХЭв);
l ЬЮЦХв ЫШ [\n], бЮЮвТХвбвТгойШЩ ТЮбмЬХаШзЭлЩ ЪЮФ ШЫШ ФРЦХ [[^x]] бЮТЯРФРвм б бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ (нвЮ ТбХУФР ТЮЧЬЮЦЭЮ).
їаШ ТЭШЬРвХЫмЭЮЬ РЭРЫШЧХ вРСЫ. 7.5 ТлпбЭпХвбп, звЮ аРЧЫШзШп ЬХЦФг нвШЬШ аХЦШЬРЬШ бТЮФпвбп Ъ вЮЬг, ЪРЪ ваШ ЬХвРбШЬТЮЫР (^, $ Ш .) ШЭвХаЯаХвШагов бШЬТЮЫ ЭЮТЮЩ бваЮЪШ.
їЮ гЬЮЫзРЭШо бШЬТЮЫ ^ Т Perl бЮТЯРФРХв вЮЫмЪЮ Т ЭРзРЫХ даРУЬХЭвР. БШЬТЮЫ $ ЬЮЦХв бЮТЯРФРвм Т ЪЮЭжХ даРУЬХЭвР ШЫШ ЭХЯЮбаХФбвТХЭЭЮ ЯХаХФ бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ, ЧРТХаиРойШЬ даРУЬХЭв. їЮбЫХФЭХХ гвЮзЭХЭШХ ТлУЫпФШв ЭХбЪЮЫмЪЮ бваРЭЭЮ, ЭЮ ЮЭЮ ТЯЮЫЭХ ЫЮУШзЭЮ, ХбЫШ гзХбвм, Т ЪРЪШе гбЫЮТШпе ЮСлзЭЮ аРСЮвРХв Perl-ЯаЮУаРЬЬР: ТеЮФЭлХ ФРЭЭлХ зШвРовбп ЯЮбваЮзЭЮ, Р ЧРТХаиРойШЩ бШЬТЮЫ ЭЮТЮЩ бваЮЪШ ЮСлзЭЮ бзШвРХвбп зРбвмо ФРЭЭле. їЮбЪЮЫмЪг Т бвРЭФРавЭЮЬ аХЦШЬХ вЮзЪР<$M[R7-16]> ЭХ бЮТЯРФРХв б бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ, нвЮ ЯаРТШЫЮ ЯЮЧТЮЫпХв [.*$] аРбЯаЮбваРЭШвмбп ЭР ТХбм вХЪбв ФЮ ЯЮбЫХФЭХУЮ бШЬТЮЫР ЭЮТЮЩ бваЮЪШ, ЭХ ТЪЫозРп ХУЮ. ВХаЬШЭ «бвРЭФРавЭлЩ аХЦШЬ» ЯаШФгЬРЫ п бРЬ. їЮЫмЧгЩвХбм ЭР ЧФЮаЮТмХ.
јЮФШдШЪРвЮа /m ШЭШжШШагХв ЯЮШбЪ бЮТЯРФХЭШЩ Т ЬЭЮУЮбваЮзЭЮЬ аХЦШЬХ. І нвЮЬ аХЦШЬХ ЬХвРбШЬТЮЫ ^ бЮТЯРФРХв Т ЭРзРЫХ ЪРЦФЮЩ ЫЮУШзХбЪЮЩ бваЮЪШ (вЮ Хбвм Т ЭРзРЫХ даРУЬХЭвР, Р вРЪЦХ ЯЮбЫХ ЪРЦФЮУЮ ТЭгваХЭЭХУЮ бШЬТЮЫР ЭЮТЮЩ бваЮЪШ), Р $ бЮТЯРФРХв Т ЪЮЭжХ ЪРЦФЮЩ ЫЮУШзХбЪЮЩ бваЮЪШ (вЮ Хбвм ЯХаХФ ЪРЦФлЬ бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ, Р вРЪЦХ Т ЪЮЭжХ ТбХУЮ даРУЬХЭвР). јЮФШдШЪРвЮа /m ЭХ ТЫШпХв ЭР вЮ, б ЪРЪШЬШ бШЬТЮЫРЬШ бЮТЯРФРХв ШЫШ ЭХ бЮТЯРФРХв вЮзЪР, ЯЮнвЮЬг Т вШЯШзЭЮЬ бЫгзРХ, ЪЮУФР /m ШбЯЮЫмЧгХвбп СХЧ ФагУШе ЬЮФШдШЪРвЮаЮТ, вЮзЪР бЮеаРЭпХв бТЮХ бвРЭФРавЭЮХ ЯЮТХФХЭШХ, вЮ Хбвм ЭХ бЮТЯРФРХв б бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ (ЪРЪ Тл ТбЪЮаХ гЧЭРХвХ, /m ЬЮЦХв ЮСкХФШЭпвмбп б /s ФЫп бЮЧФРЭШп зШбвЮУЮ ЬЭЮУЮбваЮзЭЮУЮ аХЦШЬР, Т ЪЮвЮаЮЬ вЮзЪР бЮТЯРФРХв РСбЮЫовЭЮ б ЫоСлЬ бШЬТЮЫЮЬ).
ёвРЪ, п ЯЮТвЮапо бЭЮТР:
l јЮФШдШЪРвЮа /m ТЫШпХв вЮЫмЪЮ ЭР ШЭвХаЯаХвРжШо бШЬТЮЫЮТ ЭЮТЮЩ бваЮЪШ ЬХвРбШЬТЮЫРЬШ [^] Ш [$].
јЮФШдШЪРвЮа /m ФХЩбвТгХв вЮЫмЪЮ ЯаШ ЯЮШбЪХ бЮТЯРФХЭШЩ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, ЪЮЭЪаХвЭХХ — вЮЫмЪЮ ЯЮ ЮвЭЮиХЭШо Ъ ЬХвРбШЬТЮЫРЬ ^ Ш $. ѕЭ ЭХ ШЬХХв РСбЮЫовЭЮ ЭШЪРЪЮУЮ ЮвЭЮиХЭШп Ъ зХЬг-ЫШСЮ ХйХ. ІХаЮпвЭЮ, ЬЭЮУЮбваЮзЭлЩ аХЦШЬ СлЫЮ Сл ЯаРТШЫмЭХХ ЭРЧлТРвм «аХЦШЬЮЬ-Т-ЪЮвЮаЮЬ-бваЮЪЮТлХ-пЪЮаШ-гзШвлТРов-ТЭгваХЭЭШХ-бШЬТЮЫл-ЭЮТЮЩ-бваЮЪШ». ІЮЧЬЮЦЭЮ, ШЧ ТбХе ЯаЮбвле ТЮЧЬЮЦЭЮбвХЩ Perl ШЬХЭЭЮ /m Ш ЬЭЮУЮбваЮзЭлЩ аХЦШЬ ТлЧлТРов СЮЫмиХ ТбХУЮ ЭХФЮаРЧгЬХЭШЩ, ЯЮнвЮЬг п еЮзг ХйХ аРЧ зХвЪЮ ЮУЮТЮаШвм, звЮ ЬЮФШдШЪРвЮа /m ЭХ ШЬХХв ЭШзХУЮ ЮСйХУЮ б вХЬ…
l ЬЮЦЭЮ ЫШ аРСЮвРвм б ФРЭЭлЬШ, бЮФХаЦРйШЬШ ТЭгваХЭЭШХ бШЬТЮЫл ЭЮТле бваЮЪ. Іл ТбХУФР ЬЮЦХвХ аРСЮвРвм б ЫоСлЬШ ФРЭЭлЬШ ЯЮ бТЮХЬг ЦХЫРЭШо. [\n] ТбХУФР бЮТЯРФРХв б бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ ЭХЧРТШбШЬЮ Юв вЮУЮ, ФХЩбвТгХв ЫШ ЯаШ нвЮЬ ЬЭЮУЮбваЮзЭлЩ аХЦШЬ ШЫШ ЭХв.
l бЮТЯРФРХв ЫШ вЮзЪР (ШЫШ ЫоСЮЩ ФагУЮЩ ЬХвРбШЬТЮЫ) б бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ. јЮФШдШЪРвЮа /s ТЫШпХв ЭР вЮзЪг<$M[R7-17]>, ЭЮ ЬЮФШдШЪРвЮа /m — ЭХв. јЮФШдШЪРвЮа /m ТЫШпХв ЫШим ЭР вЮ, ЬЮУгв ЫШ пЪЮаЭлХ ЬХвРбШЬТЮЫл бЮТЯРФРвм Т ЯЮЧШжШШ бШЬТЮЫР ЭЮТЮЩ бваЮЪШ. Б ЪЮЭжХЯвгРЫмЭле ЯЮЧШжШЩ ЭХЫмЧп бЪРЧРвм, звЮ нвЮ ЭШЪРЪ ЭХ бТпЧРЭЮ б вХЬ, бЮТЯРФРХв ЫШ вЮзЪР б бРЬШЬ бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ, ЯЮнвЮЬг п зРбвЮ ШбЯЮЫмЧго гФЮСЭлЩ вХаЬШЭ «ЬЭЮУЮбваЮзЭлЩ аХЦШЬ» ФЫп ЮЯШбРЭШп бвРЭФРавЭЮУЮ ЯЮТХФХЭШп вЮзЪШ, ЮФЭРЪЮ нвР бТпЧм пТЫпХвбп ТвЮаЮбвХЯХЭЭЮЩ.
l ЪРЪШЬ ЮСаРЧЮЬ ФРЭЭлХ, ЬЭЮУЮбваЮзЭлХ ШЫШ ЭХв, ЯЮЯРФРов Т жХЫХТЮЩ вХЪбв. јЭЮУЮбваЮзЭлЩ аХЦШЬ зРбвЮ ШбЯЮЫмЧгХвбп Т бЮзХвРЭШШ б ФагУШЬШ ЯЮЫХЧЭлЬШ ТЮЧЬЮЦЭЮбвпЬШ Perl, ЭЮ нвР бТпЧм вРЪЦХ ТвЮаЮбвХЯХЭЭР. іЫРТЭго аЮЫм ЧФХбм ШУаРХв ЯХаХЬХЭЭРп $/, ЮЯаХФХЫпойРп аРЧФХЫШвХЫм ТеЮФЭле ЧРЯШбХЩ. µбЫШ ЯаШбТЮШвм ХЩ Ягбвго бваЮЪг, <> Ш ФагУШХ РЭРЫЮУШзЭлХ ЪЮЭбвагЪжШШ ЯХаХеЮФпв Т аХЦШЬ звХЭШп РСЧРжХТ, ЯаШ ЪЮвЮаЮЬ ТЮЧТаРйРовбп ТбХ ЫЮУШзХбЪШХ бваЮЪШ, ЮСкХФШЭХЭЭлХ Т ЮФШЭ даРУЬХЭв, ФЮ бЫХФгойХЩ ЯгбвЮЩ ЫЮУШзХбЪЮЩ бваЮЪШ ТЪЫозШвХЫмЭЮ. µбЫШ ЯаШбТЮШвм $/ ЧЭРзХЭШХ undef, Perl ЯХаХеЮФШв Т аХЦШЬ ЯЮУЫЮйХЭШп дРЩЫР (file slurp), ЯаШ ЪЮвЮаЮЬ ТбХ бЮФХаЦШЬЮХ дРЩЫР (ТХаЭХХ, ХУЮ ЮбвРТиХЩбп зРбвШ) ТЮЧТаРйРХвбп Т ТШФХ ЮФЭЮУЮ даРУЬХЭвР[34].
јЭЮУЮбваЮзЭлЩ аХЦШЬ СлТРХв гФЮСЭЮ ШбЯЮЫмЧЮТРвм Т бЮзХвРЭШШ бЮ бЯХжШРЫмЭлЬ ЧЭРзХЭШХЬ $/, ЭЮ ЮЭШ ЭШЪРЪ ЭХ ТЫШпов ФагУ ЭР ФагУР.
јЮФШдШЪРвЮа /m ЯЮпТШЫбп Т Perl5 — Т Perl4 ШбЯЮЫмЧЮТРЫРбм бЯХжШРЫмЭРп ЯХаХЬХЭЭРп $*, ЪЮвЮаРп Т ЭРбвЮпйХХ ТаХЬп бзШвРХвбп гбвРаХТиХЩ<$M[R7-32]>. НвР ЯХаХЬХЭЭРп ТЪЫозРЫР ЬЭЮУЮбваЮзЭлЩ аХЦШЬ ФЫп ТбХе ЯЮШбЪЮТ бЮТЯРФХЭШп. µбЫШ ЯХаХЬХЭЭРп $* ШбвШЭЭР, ^ Ш $ ТХФгв бХСп вРЪ ЦХ, ЪРЪ ЯаШ ЭРЫШзШШ ЬЮФШдШЪРвЮаР /m. НвЮ ЭХ вРЪ гФЮСЭЮ, ЪРЪ ТЪЫозХЭШХ ЬЭЮУЮбваЮзЭЮУЮ аХЦШЬР ФЫп ЮвФХЫмЭЮЩ ЮЯХаРжШШ, ЯЮнвЮЬг Т бЮТаХЬХЭЭле ЯаЮУаРЬЬРе $* ЭХ ШбЯЮЫмЧгХвбп. ѕФЭРЪЮ бЮТаХЬХЭЭлЬ ЯаЮУаРЬЬШбвРЬ зРбвЮ ЯаШеЮФШвбп бвРЫЪШТРвмбп б ШбЯЮЫмЧЮТРЭШХЬ нвЮЩ ЯХаХЬХЭЭЮЩ Т бвРале ШЫШ ЭХ ЯЮФзШЭпойШебп ЮСйШЬ ЯаРТШЫРЬ СШСЫШЮвХЪРе, ЯЮнвЮЬг Т ФЮЯЮЫЭХЭШХ Ъ /m ЯЮФФХаЦШТРХвбп ЬЮФШдШЪРвЮа /s.
јЮФШдШЪРвЮа<$M[R7-51]> /s ЮвЬХЭпХв ЮбЮСго ШЭвХаЯаХвРжШо бШЬТЮЫЮТ ЭЮТЮЩ бваЮЪШ ЬХвРбШЬТЮЫРЬШ ^ Ш $, ФРЦХ ХбЫШ ЯХаХЬХЭЭРп $* ШбвШЭЭР. єаЮЬХ вЮУЮ, ЬЮФШдШЪРвЮа ТЫШпХв ЭР аРСЮвг ЬХвРбШЬТЮЫР «вЮбЪР»: Т бЮзХвРЭШШ б /s вЮзЪР бЮТЯРФРХв б ЫоСлЬ бШЬТЮЫЮЬ. ГЦ ХбЫШ Тл ТЮбЯЮЫмЧЮТРЫШбм ЬЮФШдШЪРвЮаЮЬ /s Ш гЪРЧРЫШ, звЮ ЫЮУШзХбЪШХ бваЮЪШ ТРб ЭХ ШЭвХаХбгов, вЮзЪР вРЪЦХ ЭХ ФЮЫЦЭР ШЬХвм ЮбЮСЮЩ ШЭвХаЯаХвРжШШ ФЫп бШЬТЮЫР ЭЮТЮЩ бваЮЪШ.
їаШ бЮТЬХбвЭЮЬ ШбЯЮЫмЧЮТРЭШШ ЬЮФШдШЪРвЮаЮТ /m Ш /s ТЮЧЭШЪРХв вЮ, звЮ п ЭРЧлТРо «зШбвлЬ» (clean) ЬЭЮУЮбваЮзЭлЬ аХЦШЬЮЬ. ѕЭ РЭРЫЮУШзХЭ ЮСлзЭЮЬг ЬЭЮУЮбваЮзЭЮЬг аХЦШЬг, ЧР ШбЪЫозХЭШХЬ вЮУЮ, звЮ вЮзЪР Т ЭХЬ бЮТЯРФРХв б ЫоСлЬ бШЬТЮЫЮЬ (ТбЫХФбвТШХ ТЫШпЭШп /s). єРЪ ЬЭХ ЪРЦХвбп, ШбЪЫозХЭШХ ЮбЮСЮЩ ШЭвХаЯаХвРжШШ вЮзЪШ ЮСХбЯХзШТРХв СЮЫХХ ЯЮбЫХФЮТРвХЫмЭЮХ, СЮЫХХ «зШбвЮХ» ЯЮТХФХЭШХ, ЮвбоФР Ш ЭРЧТРЭШХ.
І Perl5 вРЪЦХ ЯЮпТШЫШбм ЬХвРбШЬТЮЫл<$M[R7-26]> [\A] Ш [\Z], бЮТЯРФРойШХ Т ЭРзРЫХ Ш ЪЮЭжХ даРУЬХЭвР. НвШ ЬХвРбШЬТЮЫл ЭШЪЮУФР ЭХ гзШвлТРов ЯаШбгвбвТШп ТЭгваХЭЭШе бШЬТЮЫЮТ ЭЮТЮЩ бваЮЪШ. ѕЭШ ТХФгв бХСп вЮзЭЮ вРЪ ЦХ, ЪРЪ бвРЭФРавЭлХ Ш ЮФЭЮбваЮзЭлХ ТХабШШ ^ Ш $, ЮФЭРЪЮ ЮЭШ ЬЮУгв ШбЯЮЫмЧЮТРвмбп ФРЦХ Т бЮзХвРЭШШ б ЬЮФШдШЪРвЮаЮЬ /m Ш ЯаШ ШбвШЭЭЮЬ ЧЭРзХЭШШ ЯХаХЬХЭЭЮЩ $*.
БгйХбвТгХв бШвгРжШп, ЯаШ ЪЮвЮаЮЩ бШЬТЮЫ ЭЮТЮЩ бваЮЪШ ТбХУФР ЮСаРСРвлТРХвбп ЮбЮСлЬ ЮСаРЧЮЬ. ЅХЧРТШбШЬЮ Юв ФХЩбвТгойХУЮ аХЦШЬР ТбХУФР ФЮЯгбЪРХвбп бЮТЯРФХЭШХ ЪЮЭбвагЪжШЩ [$] Ш [\Z] ЯХаХФ бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ, ЧРТХаиРойШЬ вХЪбв. І Perl4 аХУгЫпаЭЮХ ТлаРЦХЭШХ ЭХ ЬЮУЫЮ ЯЮваХСЮТРвм «РСбЮЫовЭЮУЮ» ЮЪЮЭзРЭШп даРУЬХЭвР. І Perl 5 ЯаШ ЭХЮСеЮФШЬЮбвШ ЬЮЦЭЮ ТЮбЯЮЫмЧЮТРвмбп ТлаРЦХЭШХЬ […(?!\n)$]. Б ФагУЮЩ бвЮаЮЭл, ХбЫШ Тл еЮвШвХ ЮбЮСЮ ТлФХЫШвм ЧРТХаиРойШЩ бШЬТЮЫ ЭЮТЮЩ бваЮЪШ, ЯаЮбвЮ ТЮбЯЮЫмЧгЩвХбм ТлаРЦХЭШХЬ […\n$] Т ЫоСЮЩ ТХабШШ Perl.
<$M[R7-118]>І бжХЭРаШпе Perl ЮСлзЭЮ ЭХ аХЪЮЬХЭФгХвбп ШбЯЮЫмЧЮТРвм $*, ЮФЭРЪЮ ШЭЮУФР ЯаШеЮФШвбп ЯШбРвм ЯаЮУаРЬЬЭлЩ ЪЮФ, аРббзШвРЭЭлЩ Ш ЭР ЯЮФФХаЦЪг Perl4. µбЫШ ТлФРзР ЯаХФгЯаХЦФХЭШЩ ТЪЫозХЭР (ЪРЪ нвЮ ЮСлзЭЮ Ш ФЮЫЦЭЮ Слвм), вЮ ЯаШ ЮСЭРагЦХЭШШ $* Perl5 ТлФРХв ЯаХФгЯаХЦФХЭШХ. НвШ ЯаХФгЯаХЦФХЭШп бШЫмЭЮ аРЧФаРЦРов, ЭЮ ТЬХбвЮ вЮУЮ, звЮСл ЮвЪЫозРвм Ше ФЫп ТбХУЮ бжХЭРаШп, п аХЪЮЬХЭФго ШбЯЮЫмЧЮТРвм даРУЬХЭвл ТШФР:
{ local($^W) = 0; eval'$* = 1' }
І нвЮЬ ТРаШРЭвХ ЯаХФгЯаХЦФХЭШп ЮвЪЫозРовбп ЭР ТаХЬп ЬЮФШдШЪРжШШ $*, Р ЧРвХЬ ТЪЫозРовбп бЭЮТР — нвР ЬХвЮФШЪР ЯЮФаЮСЭЮ аРббЬРваШТРЫРбм ТлиХ, ЯаШ ЮЯШбРЭШШ ФШЭРЬШзХбЪЮЩ ТШФШЬЮбвШ ЯХаХЬХЭЭле (б. <$R[P#,R7-63]>).
єРЪ гЯЮЬШЭРЫЮбм ЭР б. <$R[P#,R7-23]>, ЭХЪЮвЮалХ ЬЮФШдШЪРвЮал ЬЮЦЭЮ ТЪЫозРвм ЯаШ ЯЮЬЮйШ ЪЮЭбвагЪжШШ [(?ЬЮФ)] ЭХЯЮбаХФбвТХЭЭЮ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ — ЭРЯаШЬХа, ТЬХбвЮ /m ЬЮЦЭЮ ТЮбЯЮЫмЧЮТРвмбп ТлаРЦХЭШХЬ [(?m)]. І Perl ЭХ бгйХбвТгХв еШваЮгЬЭле ЯаРТШЫ, ЪЮвЮалХ Сл ЮЯШблТРЫШ ЯЮвХЭжШРЫмЭлХ ЪЮЭдЫШЪвл ЬЮФШдШЪРвЮаР /m б [(?m)] ШЫШ аХУЫРЬХЭвШаЮТРЫШ ЯЮЧШжШШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, Т ЪЮвЮале ЬЮЦХв ЭРеЮФШвмбп [(?m)]. їаЮбвЮХ ТЪЫозХЭШХ /m ШЫШ [(?m)] (Т ЫоСЮЬ ЬХбвХ аХУгЫпаЭЮУЮ ТлаРЦХЭШп) РЪвШТШЧШагХв ЬЭЮУЮбваЮзЭлЩ аХЦШЬ ФЫп ТбХУЮ бЮТЯРФХЭШп.
ЕЮвп г ЯаЮУаРЬЬШбвЮТ ШЭЮУФР ТЮЧЭШЪРХв ШбЪгиХЭШХ ЬХЭпвм аХЦШЬ ЭР еЮФг, ШбЯЮЫмЧгп ЪЮЭбвагЪжШШ ТШФР [(?m)…(?s)…(?m)…], бваЮзЭлЩ аХЦШЬ пТЫпХвбп гЭШТХабРЫмЭЮЩ еРаРЪвХаШбвШЪЮЩ ТбХУЮ бЮТЯРФХЭШп ЭХЧРТШбШЬЮ Юв вЮУЮ, ЪРЪШЬ бЯЮбЮСЮЬ ЮЭ РЪвШТШЧШаЮТРЭ.
їаШ ЮСкХФШЭХЭШШ /s б /m ЬЮФШдШЪРвЮа /m ЮСЫРФРХв СЮЫХХ ТлбЮЪШЬ ЯаШЮаШвХвЮЬ ЯЮ ЮвЭЮиХЭШо Ъ ЬХвРбШЬТЮЫРЬ ^ Ш $. ВХЬ ЭХ ЬХЭХХ, ЭРЫШзШХ ШЫШ ЮвбгвбвТШХ /m ЭШЪРЪ ЭХ ТЫШпХв ЭР вЮ, бЮТЯРФРХв ЫШ вЮзЪР б бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ ШЫШ ЭХв — бвРЭФРавЭЮХ ЯЮТХФХЭШХ вЮзЪШ ШЧЬХЭпХвбп вЮЫмЪЮ пТЭлЬ ТЪЫозХЭШХЬ /s. ВРЪШЬ ЮСаРЧЮЬ, РЪвШТШЧРжШп ЮСЮШе аХЦШЬЮТ бЮЧФРХв вЮ, звЮ п ЭРЧТРЫ «зШбвлЬ ЬЭЮУЮбваЮзЭлЬ аХЦШЬЮЬ».
ЅР ЯХаТлЩ ТЧУЫпФ ЪРЦХвбп, звЮ ЮСШЫШХ аХЦШЬЮТ Ш ЪЮЬСШЭРжШЩ вЮЫмЪЮ гбЫЮЦЭпХв бШвгРжШо, ЭЮ ЯаШТХФХЭЭРп Т вРСЫ. 7.6 бТЮФЪР ЯЮЬЮЦХв ТРЬ аРЧЮСаРвмбп Т ЯаЮШбеЮФпйХЬ. ѕбЭЮТЭЮЩ ЯаШЭжШЯ ЬЮЦЭЮ бдЮаЬгЫШаЮТРвм вРЪ: «/m ЮЯаХФХЫпХв ЬЭЮУЮбваЮзЭлЩ аХЦШЬ, Р /s — ТЮЧЬЮЦЭЮбвм бЮТЯРФХЭШп вЮзЪШ б бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ».
ІбХ ЮбвРЫмЭлХ ЪЮЭбвагЪжШШ аРСЮвРов вРЪ ЦХ, ЪРЪ ЯаХЦФХ. [\n] ТбХУФР бЮТЯРФРХв б бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ. БШЬТЮЫмЭлЩ ЪЫРбб ТбХУФР ЬЮЦХв ШбЯЮЫмЧЮТРвмбп ФЫп бЮТЯРФХЭШп ШЫШ ШбЪЫозХЭШп бШЬТЮЫЮТ ЭЮТЮЩ бваЮЪШ. ёЭТХавШаЮТРЭЭлХ бШЬТЮЫмЭлХ ЪЫРббл ТШФР [[^x]] ТбХУФР бЮТЯРФРов б бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ (ХбЫШ, ЪЮЭХзЭЮ, ЪЫРбб ЭХ бЮФХаЦШв \n). їЮЬЭШвХ ЮС нвЮЬ, ХбЫШ аХиШвХ ЧРЬХЭШвм ЪЮЭбвагЪжШо ТШФР [.*] СЮЫХХ ЦХбвЪШЬ (ЭР ЯХаТлЩ ТЧУЫпФ) ТлаРЦХЭШХЬ [[^…]*].
ВРСЫШжР 7.6. БТЮФЪР бваЮзЭле аХЦШЬЮТ
БЬ. аРбиШдаЮТЪг Т дРЩЫХ pict!
І Perl5 ЯЮпТШЫбп ЭЮТлЩ пЪЮаЭлЩ ЬХвРбШЬТЮЫ<$M[R7-27]> [\G], ЪЮвЮалЩ ЭРЯЮЬШЭРХв ЬХвРбШЬТЮЫ [\A], РФРЯвШаЮТРЭЭлЩ ФЫп ШбЯЮЫмЧЮТРЭШп б ЬЮФШдШЪРвЮаЮЬ /g. їаШ ЯЮШбЪХ ЯХаТЮУЮ бЮТЯРФХЭШп /g ШЫШ ЯаШ ЮвбгвбвТШШ ЬЮФШдШЪРвЮаР /g нвЮв ЬХвРбШЬТЮЫ ТХФХв бХСп вЮзЭЮ вРЪ ЦХ, ЪРЪ Ш [\A].
АРббЬЮваШЬ ФЮТЮЫмЭЮ ФЫШЭЭлЩ ЯаШЬХа, ЪЮвЮалЩ ЬЮЦХв ЯЮЪРЧРвмбп ЭХбЪЮЫмЪЮ ЭХХбвХбвТХЭЭлЬ, ЭЮ ЭР бРЬЮЬ ФХЫХ еЮаЮиЮ ФХЬЮЭбваШагХв ЭХЪЮвЮалХ ТРЦЭлХ ЮСбвЮпвХЫмбвТР. їаХФЯЮЫЮЦШЬ, ФРЭЭлХ ЯаХФбвРТЫпов бЮСЮЩ бЯЫЮиЭго ЯЮбЫХФЮТРвХЫмЭЮбвм ЯЮзвЮТле ШЭФХЪбЮТ БИ°, ЪРЦФлЩ ШЧ ЪЮвЮале бЮбвЮШв ШЧ 5 жШда. Іл еЮвШвХ ТлСаРвм ШЧ ЯЮвЮЪР ТбХ ШЭФХЪбл, ЭРзШЭРойШХбп, ФЮЯгбвШЬ, б жШда 44. ЅШЦХ ЯаШТХФХЭ ЯаШЬХа ФРЭЭле б ТлФХЫХЭШХЬ ЭгЦЭле ШЭФХЪбЮТ ЦШаЭлЬ иаШдвЮЬ:
03824531449411615213441829503544272752010217443235
ґЫп ЭРзРЫР аРббЬЮваШЬ ТЮЧЬЮЦЭЮбвм ШбЯЮЫмЧЮТРЭШп ЪЮЬРЭФл @zips = m/\d\d\d\d\d/g; ФЫп ЯЮбваЮХЭШп бЯШбЪР, ЪРЦФлЩ нЫХЬХЭв ЪЮвЮаЮУЮ бЮЮвТХвбвТгХв ЮФЭЮЬг ШЭФХЪбг (ЯаХФЯЮЫРУРХвбп, звЮ ФРЭЭлХ ЭРеЮФпвбп Т бвРЭФРавЭЮЩ ЯХаХЬХЭЭЮЩ $_). НвЮ аХУгЫпаЭЮХ ТлаРЦХЭШХ бЮТЯРФРХв б ЮФЭШЬ ШЭФХЪбЮЬ ЪРЦФлЩ аРЧ, ЪЮУФР ЬЮФШдШЪРвЮа /g ЯаШЬХЭпХв ХУЮ Т ЮзХаХФЭЮЩ аРЧ. ІРЦЭЮХ ЮСбвЮпвХЫмбвТЮ, бЬлбЫ ЪЮвЮаЮУЮ ТбЪЮаХ бвРЭХв ЮзХТШФЭлЬ — ЯаШЬХЭХЭШХ аХУгЫпаЭЮУЮ ТлаРЦХЭШп ЭШЪЮУФР ЭХ ЧРТХаиРХвбп ЭХгФРзХЩ ФЮ ЧРТХаиХЭШп ЮСаРСЮвЪШ ТбХУЮ бЯШбЪР; ТЮЧТаРвл Ш ЯЮТвЮаЭлХ ЯЮЯлвЪШ ЭРзШбвЮ ЮвбгвбвТгов (ЯаХФЯЮЫРУРХвбп, звЮ ТбХ ФРЭЭлХ ШЬХов ЯаРТШЫмЭлЩ дЮаЬРв; Т аХРЫмЭЮЬ ЬШаХ вРЪЮХ ШЭЮУФР бЫгзРХвбп, ЭЮ ФЮТЮЫмЭЮ аХФЪЮ).
ёвРЪ, ЧРЬХЭР [\d\d\d\d\d] ЭР [44\d\d\d] ФЫп ЭРеЮЦФХЭШп ШЭФХЪбЮТ, ЭРзШЭРойШебп б 44, пТЫпХвбп ЮзХТШФЭЮЩ УЫгЯЮбвмо — ЯЮбЫХ вЮУЮ, ЪРЪ ЯЮЯлвЪР бЮТЯРФХЭШп ЧРТХаиШвбп ЭХгФРзХЩ, ЬХеРЭШЧЬ бЬХйРХвбп ЭР ЮФШЭ бШЬТЮЫ, Т аХЧгЫмвРвХ зХУЮ вХапХвбп бШЭеаЮЭШЧРжШп [44] б ЭРзРЫЮЬ ЮзХаХФЭЮУЮ ШЭФХЪбР. їаШ ШбЯЮЫмЧЮТРЭШШ [44\d\d\d] ЯХаТЮХ бЮТЯРФХЭШХ СгФХв ЮиШСЮзЭЮ ЮСЭРагЦХЭЮ Т ЯЮбЫХФЮТРвХЫмЭЮбвШ …5314494116….
єЮЭХзЭЮ, аХУгЫпаЭЮХ ТлаРЦХЭШХ ЬЮЦЭЮ ЭРзРвм б [\A], ЭЮ Т нвЮЬ бЫгзРХ ШЭФХЪб СгФХв ЭРЩФХЭ ЫШим Т вЮЬ бЫгзРХ, ХбЫШ ЮЭ бвЮШв ЭР ЯХаТЮЬ ЬХбвХ Т бваЮЪХ. ЅРЬ ЭгЦЭР ТЮЧЬЮЦЭЮбвм агзЭЮЩ бШЭеаЮЭШЧРжШШ ЬХеРЭШЧЬР аХУгЫпаЭле ТлаРЦХЭШЩ, ЯаШ ЪЮвЮаЮЩ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯаЮЯгбЪРЫЮ Сл ЮвТХаУЭгвлХ ШЭФХЪбл. іЫРТЭЮХ — звЮСл ШЭФХЪб ЯаЮЯгбЪРЫбп ЯЮЫЭЮбвмо, Р ЭХ ЯЮ ЮФЭЮЬг бШЬТЮЫг, ЪРЪ ЯаШ РТвЮЬРвШзХбЪЮЬ бЬХйХЭШШ вХЪгйХЩ ЯЮЧШжШШ ЯЮШбЪР.
<$M[R7-58]>П ЬЮУг ЯаХФЫЮЦШвм ЭХбЪЮЫмЪЮ бЯЮбЮСЮТ ЯаЮЯгбЪРЭШп ЭХЭгЦЭле ШЭФХЪбЮТ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ. ЗвЮСл ФЮСШвмбп ЦХЫРХЬЮУЮ нддХЪвР, ФЮбвРвЮзЭЮ ЭРзРвм аХУгЫпаЭЮХ ТлаРЦХЭШХ б ЫоСЮЩ ШЧ ЪЮЭбвагЪжШЩ, ЯХаХзШбЫХЭЭле ЭШЦХ.
[(?:[^4]\d\d\d\d|\d[^4]\d\d\d)*…]
НвЮ аХиХЭШХ ЬЮЦЭЮ ЭРЧТРвм «ЬХвЮФЮЬ УагСЮЩ бШЫл»: Ьл РЪвШТЭЮ ЯаЮЯгбЪРХЬ ТбХ ШЭФХЪбл, ЭРзШЭРойШХбп б зХУЮ-ЫШСЮ, ЪаЮЬХ 44 (ТХаЮпвЭЮ, ТЬХбвЮ [^4] бЫХФЮТРЫЮ Сл ШбЯЮЫмЧЮТРвм [[1235-9]], ЭЮ ЪРЪ УЮТЮаШЫЮбм ТлиХ, п ЯаХФЯЮЫРУРо, звЮ Ьл аРСЮвРХЬ б ЯаРТШЫмЭЮ ЮвдЮаЬРвШаЮТРЭЭлЬШ ФРЭЭлЬШ). єбвРвШ УЮТЮап, Ьл ЭХ ЬЮЦХЬ ШбЯЮЫмЧЮТРвм [(?:[^4][^4]\d\d\d)*], ЯЮбЪЮЫмЪг ЮЭР ЭХ ЯаЮЯгбЪРХв ЭХЭгЦЭлХ ШЭФХЪбл вШЯР 43210.
[(?:(?!44)\d\d\d\d\d)*…]
°ЭРЫЮУШзЭЮХ аХиХЭШХ, ЪЮвЮаЮХ вРЪЦХ РЪвШТЭЮ ЯаЮЯгбЪРХв ШЭФХЪбл, ЭХ ЭРзШЭРойШХбп б 44. ѕЯШбРЭШХ ЮзХЭм ЯЮеЮЦХ ЭР вЮ, ЪЮвЮаЮХ ЯаШТХФХЭЮ ТлиХ, ЭЮ ЭР пЧлЪХ аХУгЫпаЭле ТлаРЦХЭШЩ ЮЭЮ ТлУЫпФШв бЮТбХЬ ШЭРзХ. БаРТЭШвХ ФТР ЮЯШбРЭШп Ш ТлаРЦХЭШп. І ЭРиХЬ бЫгзРХ ЭгЦЭлЩ ШЭФХЪб (ЭРзШЭРойШЩбп б 44) ЯаШТЮФШв ЪЮЭбвагЪжШо [(?!44)] Ъ ЫЮЦЭЮЬг аХЧгЫмвРвг, ТбЫХФбвТШХ зХУЮ ЯаЮЯгбЪРЭШХ ШЭФХЪбЮТ ЯаХЪаРйРХвбп.
[(?:\d\d\d\d\d)*?…]
І нвЮЬ аХиХЭШШ ШЭФХЪбл ЯаЮЯгбЪРовбп ЫШим ЯаШ ЭХЮСеЮФШЬЮбвШ (вЮ Хбвм ЪЮУФР ФРЫмЭХЩиХХ ЯЮФТлаРЦХЭШХ, ЪЮвЮаЮХ ЮЯШблТРХв, звЮ ЦХ ЭРЬ ЭгЦЭЮ, ЭХ бЮТЯРФРХв). І бЮЮвТХвбвТШШ б ЯаШЭжШЯЮЬ ЬШЭШЬРЫШЧЬР ЯаШ ЮвбгвбвТШШ бЮТЯРФХЭШп ФЫп ЯЮбЫХФгойХУЮ ТлаРЦХЭШп [(?:\d\d\d\d\d)] ЯаЮТХаЪР ФРЦХ ЭХ ЯаЮТЮФШвбп (Р ЪЮУФР бЮТЯРФХЭШХ ФЫп ЯЮбЫХФгойХУЮ ТлаРЦХЭШп ЭРеЮФШвбп, ФЫп [(?:\d\d\d\d\d)] ЯаЮТХапХвбп ЭРЫШзШХ ЭХбЪЮЫмЪШе ЯЮТвЮаХЭШЩ).
ѕСкХФШЭпп ЯЮбЫХФЭХХ ТлаРЦХЭШХ б [(44\d\d\d)], Ьл ЯЮЫгзРХЬ:
@zips = m/(?:\d\d\d\d\d)*?(44\d\d\d)/g;
НвЮ ТлаРЦХЭШХ ШЧТЫХЪРХв ШЧ бваЮЪШ ШЭвХаХбгойШХ ЭРб ШЭФХЪбл 44xxx, РЪвШТЭЮ ЯаЮЯгбЪРп ЯаЮЬХЦгвЮзЭлХ ЭХЭгЦЭлХ УагЯЯл (Т бЯШбЪЮТЮЬ ЪЮЭвХЪбвХ m/…/g ТЮЧТаРйРХв бЯШбЮЪ вХЪбвР, бЮТЯРФРойХУЮ б ЯЮФТлаРЦХЭШпЬШ Т бЮеаРЭпойШе ЪагУЫле бЪЮСЪРе ЯаШ ЪРЦФЮЬ бЮТЯРФХЭШШ; бЬ. б. <$R[P#,R7-64]>).
їЮЫгзХЭЭЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЬЮЦХв ШбЯЮЫмЧЮТРвмбп Т бЮзХвРЭШШ б /g, ЯЮбЪЮЫмЪг Ьл ЧЭРХЬ, звЮ ЯаШ ЪРЦФЮЬ бЮТЯРФХЭШШ «вХЪгйРп ЯЮЧШжШп» ЮбвРХвбп Т ЭРзРЫХ бЫХФгойХУЮ ШЭФХЪбР, ЯЮнвЮЬг ЯЮШбЪ бЫХФгойХУЮ бЮТЯРФХЭШп (ЮСгбЫЮТЫХЭЭлЩ /g) ЭРзЭХвбп Юв ЭРзРЫР ЮзХаХФЭЮУЮ ШЭФХЪбР, ЪРЪ Ш ЯаХФЯЮЫРУРХв аХУгЫпаЭЮХ ТлаРЦХЭШХ. ІЮЧЬЮЦЭЮ, Тл ЯЮЬЭШвХ, звЮ РЭРЫЮУШзЭРп ЬХвЮФШЪР бШЭеаЮЭШЧРжШШ ШбЯЮЫмЧЮТРЫРбм Т ЯаШЬХаХ б РЭРЫШЧЮЬ ФРЭЭле, аРЧФХЫХЭЭле ЧРЯпвлЬШ (б. <$R[P#,R7-65]>).
ЅРФХобм, аРббЬЮваХЭШХ нвШе ЯаШХЬЮТ СлЫЮ ЯЮгзШвХЫмЭлЬ, ЮФЭРЪЮ Т ЭШе вРЪ Ш ЭХ ТбваХвШЫбп ЬХвРбШЬТЮЫ [\G], ЪЮвЮаЮЬг ЯЮбТпйХЭ ЭРбвЮпйШЩ аРЧФХЫ. ЅЮ ХбЫШ ЯаЮФЮЫЦШвм аРббЬЮваХЭШХ нвЮЩ ЧРФРзШ, Ьл СлбваЮ ЭРЩФХЬ ЯаШЬХЭХЭШХ Ш ФЫп [\G].
ґХЩбвТШвХЫмЭЮ ЫШ Ьл УРаРЭвШагХЬ, звЮ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯаШЬХЭпХвбп вЮЫмЪЮ Юв ЭРзРЫР ЮзХаХФЭЮУЮ ШЭФХЪбР? ЅХв! јл ЯаЮЯгбЪРХЬ ЯаЮЬХЦгвЮзЭлХ ЭХЭгЦЭлХ ШЭФХЪбл, ЭЮ ЪРЪ вЮЫмЪЮ Т вХЪбвХ ЭХ ЮбвРЭХвбп ЭШ ЮФЭЮУЮ ЭгЦЭЮУЮ ШЭФХЪбР, ЯЮШбЪ бЮТЯРФХЭШп ЧРТХаиШвбп ЭХгФРзХЩ. єРЪ ТбХУФР, ЯаШ нвЮЬ ТбвгЯРХв Т ФХЩбвТШХ ЬХеРЭШЧЬ бЬХйХЭШп вХЪгйХЩ ЯЮЧШжШШ, Ш ЯЮШбЪ ЯаЮФЮЫЦШвбп б ЯЮЧШжШШ ТЭгваШ ЮзХаХФЭЮУЮ ШЭФХЪбР! НвР аРбЯаЮбваРЭХЭЭРп ЯаЮСЫХЬР гЦХ ТбваХзРЫРбм аРЭмиХ, Т ЯаЮУаРЬЬХ Tcl ФЫп гФРЫХЭШп ЪЮЬЬХЭвРаШХТ C ШЧ УЫРТл 5 (б. <$R[P#,R5-23]>).
ІХаЭХЬбп Ъ ЭРиШЬ ЯаШЬХаЭлЬ ФРЭЭлЬ:
03824 53144 94116 15213 44182 95035 44272lwr7lwr5lwr2lwr010217 443235
БЮТЯРФРойШХ ШЭФХЪбл ТлФХЫХЭл ЦШаЭлЬ иаШдвЮЬ (ваХвмХ бЮТЯРФХЭШХ пТЫпХвбп ЭХЦХЫРвХЫмЭлЬ). °ЪвШТЭЮ ЯаЮЯгйХЭЭлХ ШЭФХЪбл ЯЮФзХаЪЭгвл, Р бШЬТЮЫл, ЯаЮЯгйХЭЭлХ ТбЫХФбвТШХ бЬХйХЭШп вХЪгйХЩ ЯЮЧШжШШ ЯЮШбЪР, ЯЮЬХзХЭл. їЮбЫХ бЮТЯРФХЭШп 44272 Т бваЮЪХ ЭХ ЮбвРХвбп бЮТЯРФРойШе ШЭФХЪбЮТ, ЯЮнвЮЬг бЫХФгойРп ЯЮЯлвЪР ЯЮШбЪР ЧРТХаиРХвбп ЭХгФРзХЩ. ЅЮ ЧРТХаиРХвбп ЫШ ЯаШ нвЮЬ ТХбм ЯЮШбЪ? єЮЭХзЭЮ, ЭХв. јХеРЭШЧЬ бЬХйРХв вХЪгйго ЯЮЧШжШо Ш ЯлвРХвбп ЯаШЬХЭШвм аХУгЫпаЭЮХ ТлаРЦХЭШХ Ъ бЫХФгойХЬг бШЬТЮЫг, ЭРагиРп вХЬ бРЬлЬ бШЭеаЮЭШЧРжШо б ЭРзРЫЮЬ ШЭФХЪбЮТ. їЮбЫХ зХвТХавЮУЮ бЬХйХЭШп аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯаЮЯгбЪРХв 10217 Ш ЭРеЮФШв «ШЭФХЪб» 44323.
ЅРиХ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯаХЪаРбЭЮ аРСЮвРХв Т вЮЬ бЫгзРХ, ХбЫШ ЮЭЮ ЯаШЬХЭпХвбп Юв ЭРзРЫР ШЭФХЪбР, ЭЮ бЬХйХЭШХ вХЪгйХЩ ЯЮЧШжШШ ЭРагиРХв ТбХ ЯЫРЭл. ЅР ЯЮЬЮйм ЯаШеЮФШв [\G]:
@zips = m/\G(?:\d\d\d\d\d)*?(44\d\d\d)/g;
\G бЮТЯРФРХв Т вЮЩ ЯЮЧШжШШ, УФХ ЧРЪЮЭзШЫЮбм ЯаХФлФгйХХ бЮТЯРФХЭШХ /g (ШЫШ Т ЭРзРЫХ даРУЬХЭвР ЯаШ бРЬЮЩ ЯХаТЮЩ ЯЮЯлвЪХ). їЮбЪЮЫмЪг аХУгЫпаЭЮХ ТлаРЦХЭШХ бЪЮЭбвагШаЮТРЭЮ вРЪ, звЮСл бЮТЯРФХЭШХ ЧРЪРЭзШТРЫЮбм ЭР УаРЭШжХ ШЭФХЪбР, Ьл вХЬ бРЬлЬ УРаРЭвШаЮТРЫШ, звЮ ТбХ ЯЮбЫХФгойШХ ЯЮЯлвЪШ ЯЮШбЪР, ЭРзШЭРойШХбп б \G, вРЪЦХ ЭРзЭгвбп ЭР вЮЩ ЦХ УаРЭШжХ ШЭФХЪбР. µбЫШ ЯЮЯлвЪР ЧРТХаиРХвбп ЭХгФРзХЩ, ЯЮШбЪ ЧРЪЮЭзХЭ, ЯЮбЪЮЫмЪг бЬХйХЭШХ вХЪгйХЩ ЯЮЧШжШШ ЭХТЮЧЬЮЦЭЮ — \G ЮСХбЯХзШТРХв ЯаЮФЮЫЦХЭШХ ЯЮШбЪР б вЮЩ ЯЮЧШжШШ, УФХ ЧРЪЮЭзШЫРбм ЯаХФлФгйРп ЯЮЯлвЪР. ґагУШЬШ бЫЮТРЬШ, Т ЯЮФЮСЭЮЩ бШвгРжШШ \G дРЪвШзХбЪШ ЧРЯаХйРХв бЬХйХЭШХ вХЪгйХЩ ЯЮЧШжШШ.
ѕЪРЧлТРХвбп, ЬХеРЭШЧЬ аХУгЫпаЭле ТлаРЦХЭШЩ ЮЯвШЬШЧШагХвбп вРЪШЬ ЮСаРЧЮЬ, звЮ Т ЭХЪЮвЮале бвРЭФРавЭле бШвгРжШпе ЮЭ ФХЩбвТШвХЫмЭЮ ЧРЯаХйРХв бЬХйХЭШХ. µбЫШ бЮТЯРФХЭШХ ФЮЫЦЭЮ ЭРзШЭРвмбп б \G, бЬХйХЭШХ вХЪгйХЩ ЯЮЧШжШШ ЭШЪЮУФР ЭХ ЯаШТХФХв Ъ ЭЮТЮЬг бЮТЯРФХЭШо, ЯЮнвЮЬг ЯЮШбЪ ЭР нвЮЬ ЧРТХаиРХвбп. ІЯаЮзХЬ, ЮЯвШЬШЧРвЮа ЫХУЪЮ ЮСЬРЭлТРХвбп, ЯЮнвЮЬг Тл ФЮЫЦЭл Слвм ТЭШЬРвХЫмЭл. ЅРЯаШЬХа, нвР ЮЯвШЬШЧРжШп ЭХ РЪвШТШЧШагХвбп ФЫп ЪЮЭбвагЪжШШ [\Gthis|\Gthat], еЮвп ЮЭР дРЪвШзХбЪШ нЪТШТРЫХЭвЭР ЮЯвШЬШЧШагХЬЮЩ ЪЮЭбвагЪжШШ [\G(?:this|that)].
јХвРбШЬТЮЫ [\G] ШбЯЮЫмЧгХвбп ЭХзРбвЮ, ЭЮ ЧРвЮ вРЬ, УФХ нвЮ ЭХЮСеЮФШЬЮ, ЮЭ ЮЪРЧлТРХв СХбжХЭЭго ЯЮЬЮйм. єРЪШЬ Сл ЯЮгзШвХЫмЭлЬ ЭШ СлЫ ЯЮбЫХФЭШЩ ЯаШЬХа, Т ФХЩбвТШвХЫмЭЮбвШ нвР ЧРФРзР аХиРХвбп Ш СХЧ \G. ґЫп ЯЮЫЭЮвл ЪРавШЭл п еЮзг гЯЮЬпЭгвм, звЮ ЯЮбЫХ гбЯХиЭЮУЮ ЮСЭРагЦХЭШп ШЭФХЪбР 44xxx Ьл ЬЮЦХЬ ТЮбЯЮЫмЧЮТРвмбп ЫоСлЬ ШЧ ЯХаТле ФТге ЯЮФТлаРЦХЭШЩ, ЯаЮЯгбЪРойШе ЭХЦХЫРвХЫмЭлХ ШЭФХЪбл, Ш ЮСЮЩвШ ЧРЮФЭЮ Ш ТбХ ЯаЮФЮЫЦРойШХ ЭХЦХЫРвХЫмЭлХ ШЭФХЪбл (ваХвмХ ЯЮФТлаРЦХЭШХ ЯаЮЯгбЪРХв ШЭФХЪбл вЮЫмЪЮ Т вЮЬ бЫгзРХ, ХбЫШ нвЮ ЭХЮСеЮФШЬЮ ФЫп бЮТЯРФХЭШп, ЯЮнвЮЬг ЧФХбм ЮЭЮ ЭХ ЯЮФЮЩФХв):
@zips = m/(?:\d\d\d\d\d)*?(44\d\d\d)(?:(?!44)\d\d\d\d\d)*/g;
їЮбЫХ вЮУЮ, ЪРЪ Ьл ЭРЩФХЬ бЮТЯРФХЭШХ ФЫп ЯЮбЫХФЭХУЮ ШЭФХЪбР, ФЮСРТЫХЭЭЮХ ЯЮФТлаРЦХЭШХ ЯЮУЫЮвШв ЮбвРвЮЪ бваЮЪШ (ХбЫШ ЮЭ Хбвм), Ш ЮСаРСЮвЪР m/…/g ЧРТХаиШвбп.
ІбХ нвШ аХиХЭШп ЭЮаЬРЫмЭЮ аРСЮвРов, ЭЮ зХбвЭЮ УЮТЮап, ЮСлзЭЮ СлТРХв гФЮСЭХХ ТлЭХбвШ зРбвм аРСЮвл ШЧ аХУгЫпаЭЮУЮ ТлаРЦХЭШп Ш ТЮбЯЮЫмЧЮТРвмбп ФагУШЬШ аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ ШЫШ баХФбвТРЬШ пЧлЪР. БЫХФгойШХ ФТР ЯаШЬХаР Ш ЭРУЫпФЭХХ, Ш ЯаЮйХ Т бЮЯаЮТЮЦФХЭШШ:
@zips = grep {defined} m/(44\d\d\d)|\d\d\d\d\d)/g;
@zips = grep {m/^44/} m/\d\d\d\d\d/g;
І Perl 4 бФХЫРвм ТбХ нвЮ Т ЮФЭЮЬ аХУгЫпаЭЮЬ ТлаРЦХЭШШ СлЫЮ ЭХТЮЧЬЮЦЭЮ, ЯЮбЪЮЫмЪг Т ЭХЬ ЮвбгвбвТЮТРЫШ ЬЭЮУШХ ШЧ ШбЯЮЫмЧЮТРЭЭле ЭРЬШ ЪЮЭбвагЪжШЩ, ЯЮнвЮЬг Т ЫоСЮЬ бЫгзРХ ЯаШеЮФШЫЮбм ШбЪРвм ФагУЮХ аХиХЭШХ.
ґРЦХ ХбЫШ ЬХвРбШЬТЮЫ \G ЭХ ШбЯЮЫмЧгХвбп, ЭХЮСеЮФШЬЮ гзШвлТРвм ЭХЪЮвЮалХ ЮбЮСХЭЭЮбвШ ЧРЯЮЬШЭРЭШп Т Perl «ЪЮЭжР ЯаХФлФгйХУЮ бЮТЯРФХЭШп». І Perl4 ЮЭ РббЮжШШаЮТРЫбп б ЪЮЭЪаХвЭлЬ ЮЯХаРвЮаЮЬ, ЭЮ Т Perl5 ЮЭ РббЮжШШагХвбп б ФРЭЭлЬШ (жХЫХТлЬ вХЪбвЮЬ). Нвг ЯЮЧШжШо ЬЮЦЭЮ ЯЮЫгзШвм ЯаШ ЯЮЬЮйШ дгЭЪжШШ<$M[R7-36]> pos(…). БЫХФЮТРвХЫмЭЮ, ЮФЭЮ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЬЮЦХв ЯаЮФЮЫЦШвм ЯЮШбЪ б ЯЮЧШжШШ, Т ЪЮвЮаЮЩ ЯаХЪаРвШЫРбм ЮСаРСЮвЪР ФагУЮУЮ аХУгЫпаЭЮУЮ ТлаРЦХЭШп. ДРЪвШзХбЪШ нвЮ ЯЮЧТЮЫпХв ЯаЮТЮФШвм ЪЮЫЫХЪвШТЭлЩ ЯЮШбЪ бЮТЯРФХЭШЩ б ЯаШЬХЭХЭШХЬ ЭХбЪЮЫмЪШе аХУгЫпаЭле ТлаРЦХЭШЩ. АРббЬЮваШЬ бЫХФгойШЩ ЯаЮбвЮЩ ЯаШЬХа:
@nums = $data =~ m/\d+/g;
НвР ЪЮЬРЭФР ТЮЧТаРйРХв Т @nums бЯШбЮЪ ТбХе зШбХЫ Т ФРЭЭле. ВХЯХам гбЫЮЦЭШЬ ЧРФРЭШХ: ХбЫШ Т бваЮЪХ ТбваХзРХвбп бЯХжШРЫмЭРп ЪЮЬСШЭРжШп <xx>, Тл еЮвШвХ ЮУаРЭШзШвмбп вЮЫмЪЮ вХЬШ зШбЫРЬШ, ЪЮвЮалХ бЫХФгов ЯЮбЫХ ЭХХ. ѕФЭЮ ШЧ ЯаЮбвле аХиХЭШЩ ТлУЫпФШв вРЪ:
$data =~ m/<xx>/g; # ГбвРЭЮТШвм ЭРзРЫмЭго ЯЮЧШжШо /g. ВХЯХам pos($data)
# ЭРеЮФШвбп Т ЯЮЧШжШШ, бЫХФгойХЩ баРЧг ЦХ ЧР <xx>.
@nums = $data =~ m/\d+/g;
їЮШбЪ <xx> ТлЯЮЫЭпХвбп Т бЪРЫпаЭЮЬ ЪЮЭвХЪбвХ, ЯЮнвЮЬг ЬЮФШдШЪРвЮа /g ЭХ ШйХв ТбХ бЮТЯРФХЭШп (б. <$R[P#,R7-66]>). ІЬХбвЮ нвЮУЮ ЮЭ гбвРЭРТЫШТРХв ФЫп $data ЧЭРзХЭШХ pos, ЯЮЧШжШо «ЪЮЭжР ЯЮбЫХФЭХУЮ бЮТЯРФХЭШп», б ЪЮвЮаЮЩ ЭРзЭХвбп ЯЮШбЪ бЫХФгойХУЮ бЮТЯРФХЭШп Т вХе ЦХ ФРЭЭле ЯЮФ гЯаРТЫХЭШХЬ /g. П ЭРЧлТРо нвЮв ЯаШХЬ «ЭРТЮФЪЮЩ» (priming)». їЮбЫХ нвЮУЮ m/\d+/g ЯаЮФЮЫЦРХв ЯЮШбЪ б гбвРЭЮТЫХЭЭЮЩ ЯЮЧШжШШ. µбЫШ бЮТЯРФХЭШХ ФЫп <xx> ЭХ ЭРеЮФШвбп, ЯЮбЫХФгойШЩ ЯЮШбЪ m/\d+/g ЭРзШЭРХвбп, ЪРЪ ЮСлзЭЮ, б ЭРзРЫР бваЮЪШ.
їаШТХФХЭЭлЩ ЯаШЬХа аРСЮвРХв СЫРУЮФРап ФТгЬ ТРЦЭлЬ ЮСбвЮпвХЫмбвТРЬ. ІЮ-ЯХаТле, ЯХаТлЩ ЯЮШбЪ ТлЯЮЫЭпХвбп Т бЪРЫпаЭЮЬ ЪЮЭвХЪбвХ. І бЯШбЪЮТЮЬ ЪЮЭвХЪбвХ ТлаРЦХЭШХ [<xx>] СгФХв ЯаШЬХЭпвмбп ЬЭЮУЮЪаРвЭЮ ТЯЫЮвм ФЮ ЯЮбЫХФЭХУЮ ЭРЩФХЭЭЮУЮ нЪЧХЬЯЫпаР, Ш ЭХгФРзР ЯЮШбЪР, ЭРеЮФпйХУЮбп ЯЮФ гЯаРТЫХЭШХЬ /g, ТХаЭХв pos Т ЭРзРЫЮ даРУЬХЭвР. ІЮ-ТвЮале, ЯаШ ЯХаТЮЬ ЯЮШбЪХ ФЮЫЦХЭ ШбЯЮЫмЧЮТРвмбп ЬЮФШдШЪРвЮа /g. ±ХЧ ЭХУЮ ЯЮЧШжШп pos ЭХ ШЧЬХЭпХвбп.
ё ХйХ ЮФЭЮ ШЭвХаХбЭЮХ ЧРЬХзРЭШХ: СЫРУЮФРап ТЮЧЬЮЦЭЮбвШ ЯаШбТРШТРЭШп pos ЭРзРЫмЭго ЯЮЧШжШо /g ЬЮЦЭЮ гбвРЭЮТШвм ТагзЭго:
pos($data) = $i if $i = index($data, "<xx>"), $i > 0;
@nums = $data =~ m/\d+/g;
µбЫШ дгЭЪжШп index ЭРеЮФШв <xx> Т вХЪбвХ, ЮЭР гбвРЭРТЫШТРХв ЭРзРЫмЭго ЯЮЧШжШо бЫХФгойХУЮ ЯЮШбЪР Т $data ЯЮФ гЯаРТЫХЭШХЬ /g. ѕСаРвШвХ ТЭШЬРЭШХ: Т ЮвЫШзШХ Юв аРббЬЮваХЭЭЮУЮ ТлиХ ЯаШЬХаР ЯЮЧШжШп гбвРЭРТЫШТРХвбп Т ЭРзРЫЮ ЯЮбЫХФЮТРвХЫмЭЮбвШ <xx>, Р ЭХ ЯЮбЫХ ЭХХ, ЪРЪ аРЭмиХ. ІЯаЮзХЬ, Т ФРЭЭЮЬ бЫгзРХ нвЮ ЭХбгйХбвТХЭЭЮ.
јл аРббЬЮваХЫШ ЯаЮбвЮЩ ЯаШЬХа, ЭЮ ФРЦХ ЯЮ ЭХЬг ЭХвагФЭЮ ЯЮЭпвм, звЮ ЯаШ ЮбвЮаЮЦЭЮЬ ШбЯЮЫмЧЮТРЭШШ Т ЭХЪЮвЮале бЫгзРпе нвЮв ЯаШХЬ ЬЮЦХв ЯаШЭХбвШ ЭХЬРЫго ЯЮЫмЧг. ІЯаЮзХЬ, ЫоСРп ЭХЮбвЮаЮЦЭЮбвм ЯаХТаРвШв бЮЯаЮТЮЦФХЭШХ ЯаЮУаРЬЬл Т ЭРбвЮпйШЩ ЪЮиЬРа.
І Perl ЭХв ЮвФХЫмЭле пЪЮаЭле ЬХвРбШЬТЮЫЮТ ФЫп УаРЭШж ЭРзРЫР бЫЮТР Ш ЪЮЭжР бЫЮТР, ЯЮФФХаЦШТРХЬле ТЮ ЬЭЮУШе ФагУШе ЯаЮУаРЬЬРе (бЬ. вРСЫ. 3.1, б. <$R[P#,R3-27]>, Ш вРСЫ. 6.1, б. <$R[P#,R6-1]>). ІЬХбвЮ нвЮУЮ[35] Т Perl бгйХбвТгов ЬХвРбШЬТЮЫл<$M[R7-24]> УаРЭШжл бЫЮТР [\b] Ш ЭХ-УаРЭШжл бЫЮТР [\B] (ЮСаРвШвХ ТЭШЬРЭШХ: Т бШЬТЮЫмЭле ЪЫРббРе Ш Т бваЮЪРе, ЧРЪЫозХЭЭле Т ЪРТлзЪШ, \b пТЫпХвбп бЮЪаРйХЭЭЮЩ ЧРЯШбмо ФЫп бШЬТЮЫР «ЧРСЮЩ»). іаРЭШжХЩ бЫЮТР бзШвРХвбп ЫоСРп ЯЮЧШжШп, аРЧФХЫпойРп бШЬТЮЫл, ЮФШЭ ШЧ ЪЮвЮале бЮТЯРФРХв б [\w], Р ФагУЮЩ — б [\W] (ЪЮЭХж бваЮЪШ Т нвЮЬ ЮЯаХФХЫХЭШШ ШЭвХаЯаХвШагХвбп ЪРЪ [\W]). І ЮвЫШзШХ Юв СЮЫмиШЭбвТР ЯаЮУаРЬЬ, Perl ТЪЫозРХв Т [\w] бШЬТЮЫ ЯЮФзХаЪШТРЭШп. їаШ ЮЯаХФХЫХЭШШ ЫЮЪРЫмЭЮУЮ ЪЮЭвХЪбвР Т ЯЮЫмЧЮТРвХЫмбЪЮЩ баХФХ Т ЪРвХУЮаШо [\w] ЬЮУгв ТЪЫозРвмбп ФЮЯЮЫЭШвХЫмЭлХ бШЬТЮЫл (б. <$R[P#,R3-6]>, <$R[P#,R7-67]>).
Б ЬХвРбШЬТЮЫЮЬ [\b] бТпЧРЭ ЮФШЭ бЯХжШдШзХбЪШЩ ЯЮФТЮе, б ЪЮвЮалЬ п ШЭЮУФР бвРЫЪШТРобм[36]. ЅРЯаШЬХа, ФЫп ЯЮШбЪР вХЪбвР $item Т ЯЮШбЪЮТЮЬ Web-ШЭвХадХЩбХ п ТЮбЯЮЫмЧЮТРЫбп ТлаРЦХЭШХЬ m/\b\Q$item\E\b/. ёбЪЮЬлЩ вХЪбв СлЫ ЧРЪЫозХЭ Т ЪЮЭбвагЪжШо \b…\b, ЯЮвЮЬг звЮ п ЧЭРЫ, звЮ ЬХЭп ШЭвХаХбгов вЮЫмЪЮ нЪЧХЬЯЫпал $item, ЮдЮаЬЫХЭЭлХ Т ТШФХ ЮвФХЫмЭЮУЮ бЫЮТР. ЅРЯаШЬХа, ФЫп ЯЮШбЪР вХЪбвР 3.75 аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯаШЭШЬРХв ТШФ [\b3\.75\b], Ш гбЯХиЭЮ ЭРеЮФШв ШбЪЮЬлЩ нЫХЬХЭв Т бваЮЪХ price is 3.75 plus tax.
ЅЮ ХбЫШ $item бЮФХаЦШв вХЪбв $3.75, Ьл ЯЮЫгзРХЬ аХУгЫпаЭЮХ ТлаРЦХЭШХ [\b\$3\.75\b]. І нвЮЬ бЫгзРХ УаРЭШжР бЫЮТР ФЮЫЦЭР аРбЯЮЫРУРвмбп ЯХаХФ ЧЭРЪЮЬ ФЮЫЫРаР (УаРЭШжР бЫЮТР ЬЮЦХв ЮЪРЧРвмбп ЯХаХФ \W-бШЬТЮЫЮЬ ТаЮФХ ФЮЫЫРаР ЫШим Т ЮФЭЮЬ бЫгзРХ — ХбЫШ бЫЮТЮ ЧФХбм ЧРЪРЭзШТРХвбп). јл ШбЯЮЫмЧгХЬ ЯаХдШЪб \b, ЯаХФЯЮЫРУРп, звЮ ЮЭ ЯаШТпЧлТРХв ЭРзРЫЮ бЮТЯРФХЭШп Ъ ЯЮЧШжШШ, Т ЪЮвЮаЮЩ $item ЭРзШЭРХвбп ЪРЪ ЮвФХЫмЭЮХ бЫЮТЮ. ЅЮ ЯЮбЪЮЫмЪг ЭРзРЫЮ $item ЭХ ЬЮЦХв Слвм ЭРзРЫЮЬ ЮвФХЫмЭЮУЮ бЫЮТР (вРЪ ЪРЪ $ ЭХ бЮТЯРФРХв б \w), \b ЯаХФЮвТаРйРХв бЮТЯРФХЭШХ. НвЮ аХУгЫпаЭЮХ ТлаРЦХЭШХ ФРЦХ ЭХ бЮТЯРФХв б ШбЪЮЬлЬ вХЪбвЮЬ Т бваЮЪХ …is $3.75 plus….
µбЫШ ЯаХФиХбвТгойШЩ бШЬТЮЫ бЮТЯРФРХв б \w, вЮ ЯЮШбЪ бЮТЯРФХЭШп ФРЦХ ЭХ ФЮЫЦХЭ ЭРзШЭРвмбп — ЭЮ, ЪРЪ УЮТЮаШЫЮбм ТлиХ, аХваЮбЯХЪвШТЭРп ЯаЮТХаЪР Т Perl ЭХ ЯЮФФХаЦШТРХвбп. ѕФЭЮ ШЧ ТЮЧЬЮЦЭле аХиХЭШЩ — ФЮСРТЫпвм \b ЫШим Т вЮЬ бЫгзРХ, ХбЫШ ЭРзРЫмЭлЩ ШЫШ ЪЮЭХзЭлЩ бШЬТЮЫ $item бЮТЯРФРХв б \w:
$regex = "\Q$item\E"; # "ЅРФХЦЭРп" зРбвм ШбЪЮЬЮУЮ вХЪбвР
$regex = '\b' . $regex if $regex =~ m/^\w/; # µбЫШ ЬЮЦХв ЭРзШЭРвм бЫЮТЮ
$regex = $regex . '\b' if $regex =~ m/\w$/; # µбЫШ ЬЮЦХв ЧРЪРЭзШТРвм бЫЮТЮ
І нвЮЬ бЫгзРХ ЬХвРбШЬТЮЫ [\b] ЭХ СгФХв ШбЯЮЫмЧЮТРвмбп вРЬ, УФХ ЮЭ ЬЮЦХв ТлЧТРвм ЯаЮСЫХЬл, ЭЮ ЯаЮСЫХЬР (ХбЫШ $item ЭРзШЭРХвбп ШЫШ ЧРЪРЭзШТРХвбп \W-бШЬТЮЫЮЬ) ЮбвРХвбп. ЅРЯаШЬХа, ХбЫШ $item бЮФХаЦШв вХЪбв -998, бЮТЯРФХЭШХ СгФХв ЭРЩФХЭЮ Т бваЮЪХ 800-988-9938. µбЫШ ТРб гбваРШТРХв, звЮ Т бЮТЯРФХЭШХ ЬЮУгв Слвм ТЪЫозХЭл ЫШиЭШХ бШЬТЮЫл (звЮ ЭХФЮЯгбвШЬЮ, ХбЫШ ЯЮФТлаРЦХЭШХ пТЫпХвбп зРбвмо ФагУЮУЮ, СЮЫмиХУЮ ТлаРЦХЭШп, Р вРЪЦХ зРбвЮ ЭХ ЯЮФеЮФШв ЯаШ ШбЯЮЫмЧЮТРЭШШ ЬЮФШдШЪРвЮаР /g), ЬЮЦЭЮ ТЮбЯЮЫмЧЮТРвмбп ЯаЮбвлЬ, ЭЮ нддХЪвШТЭлЬ ТлаРЦХЭШХЬ [(?:\W|^)\Q$item\E(?!\w)].
ЅР ЯХаТлЩ ТЧУЫпФ ЮвбгвбвТШХ Т Perl ЮвФХЫмЭле ЬХвРбШЬТЮЫЮТ ФЫп ЭРзРЫР Ш ЪЮЭжР бЫЮТР ЪРЦХвбп бгйХбвТХЭЭлЬ ЭХФЮбвРвЪЮЬ, ЭЮ ЭР бРЬЮЬ ФХЫХ ТбХ ЭХ вРЪ ЯЫЮеЮ, ЯЮбЪЮЫмЪг бРЬЮ ШбЯЮЫмЧЮТРЭШХ [\b] Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ ЯЮзвШ ТбХУФР бЭШЬРХв ТбХ ЭХЮФЭЮЧЭРзЭЮбвШ. П ХйХ ЭШЪЮУФР ЭХ бвРЫЪШТРЫбп б бШвгРжШХЩ, ЪЮУФР СлЫ ФХЩбвТШвХЫмЭЮ ЭХЮСеЮФШЬ бЯХжШРЫШЧШаЮТРЭЭлЩ пЪЮаЭлЩ ЬХвРбШЬТЮЫ ФЫп ЭРзРЫР ШЫШ ЪЮЭжР бЫЮТР, ЭЮ ТРЬ ЪЮУФР-ЭШСгФм ЭХ ЯЮТХЧХв — ЭгЦЭЮУЮ нддХЪвР ЬЮЦЭЮ ФЮСШвмбп ЯаШ ЯЮЬЮйШ [\b(?=\w)] Ш [\b(?!=\w)]. ЅРЯаШЬХа, бЫХФгойХХ ТлаРЦХЭШХ гФРЫпХв ТбХ бШЬТЮЫл ЬХЦФг ЯХаТлЬ Ш ТвЮалЬ бЫЮТЮЬ Т бваЮЪХ:
s/\b(?!\w).*\b(?=\w)//
ґЫп баРТЭХЭШп ЧРЬХзг, звЮ Т бЮТаХЬХЭЭле ТХабШпе sed б ЯЮФФХаЦЪЮЩ бЯХжШРЫШЧШаЮТРЭЭле ЬХвРбШЬТЮЫЮТ УаРЭШж бЫЮТ \< Ш \> РЭРЫЮУШзЭРп ЪЮЬРЭФР ТлУЫпФХЫР Сл вРЪ:
s/\>.*\<//
јЭЮУШХ гФЮСЭлХ бЮЪаРйХЭШп<$M[R7-30]> Perl ФЫп бвРЭФРавЭле ЪЮЭбвагЪжШЩ гЦХ ТбваХзРЫШбм ЭР бваРЭШжРе ЪЭШУШ. їЮЫЭлЩ[37] бЯШбЮЪ ЯаШТХФХЭ Т вРСЫ. 7.7.
ВРСЫШжР 7.7. БЮЪаРйХЭЭлХ ЮСЮЧЭРзХЭШп нЫХЬХЭвЮТ аХУгЫпаЭле ТлаРЦХЭШЩ Ш ЪЮФШаЮТЪР бЯХжШРЫмЭле бШЬТЮЫЮТ
|
±РЩвЮТлХ ЮСЮЧЭРзХЭШп |
ѕЯШбРЭШХ |
|
\зШбЫЮ |
БШЬТЮЫ, ЧРФРЭЭлЩ Т ТШФХ ТЮбмЬХаШзЭЮУЮ ЪЮФР. |
|
\xзШбЫЮ |
БШЬТЮЫ, ЧРФРЭЭлЩ Т ТШФХ иХбвЭРФжРвХаШзЭЮУЮ ЪЮФР. |
|
\ббШЬТЮЫ |
ГЯаРТЫпойШЩ бШЬТЮЫ |
|
БЮЪаРйХЭЭлХ ЮСЮЧЭРзХЭШп бвРЭФРавЭле ЪЫРббЮТ |
ѕЯШбРЭШХ |
|
\d |
жШдаР [0-9] |
|
\s |
ЯаЮЯгбЪ, ЮСлзЭЮ [spc\f\n\r\t] |
|
\w |
бШЬТЮЫ бЫЮТР, ЮСлзЭЮ [a-zA-Z0-9_] |
|
\D, \S, \W |
ЮваШжРЭШХ \d, \s Ш \w |
|
їЫРвдЮаЬХЭЭЮ-ЧРТШбШЬлХ гЯаРТЫпойШХ бШЬТЮЫл |
ѕЯШбРЭШХ |
|
\a |
ЧТгЪЮТЮЩ бШУЭРЫ |
|
\f |
ЯЮФРзР ЫШбвР |
|
\e |
Escape |
|
\n |
ЭЮТРп бваЮЪР |
|
\r |
ТЮЧТаРв ЪгабЮаР |
|
\t |
вРСгЫпжШп |
|
\b |
ЧРСЮЩ (вЮЫмЪЮ ТЭгваШ ЪЫРббР) |
ІХаЮпвЭЮ, [\n] Ш ФагУШХ бЮЪаРйХЭЭлХ ЮСЮЧЭРзХЭШп ЯЮЪРЦгвбп ЧЭРЪЮЬлЬШ — нвШ ЯЫРвдЮаЬХЭЭЮ-ЧРТШбШЬлХ (б. <$R[P#,R3-28]>) ЮСЮЧЭРзХЭШп бвРЭФРавЭле гЯаРТЫпойШе бШЬТЮЫЮТ вРЪЦХ ЯЮФФХаЦШТРовбп Ш Т бваЮЪРе, ЧРЪЫозХЭЭле Т ЪРТлзЪШ. Іл ФЮЫЦЭл зХвЪЮ ЯЮЭпвм, звЮ бРЬШ ЯЮ бХСХ нвШ ЬХвРбШЬТЮЫл аХУгЫпаЭле ТлаРЦХЭШЩ ЭХФЮбвгЯЭл Т бваЮЪРе, ЧРЪЫозХЭЭле Т ЪРТлзЪШ — ЯаЮбвЮ ФЫп бваЮЪ ЮЯаХФХЫповбп бЮСбвТХЭЭлХ ЬХвРбШЬТЮЫл, РЭРЫЮУШзЭлХ ЬХвРбШЬТЮЫРЬ аХУгЫпаЭле ТлаРЦХЭШЩ (б. <$R[P#,R2-8]>).
БаРТЭШвХ m/(?:\r\n)+$/ бЮ бЫХФгойШЬ даРУЬХЭвЮЬ:
$regex = "(\r\n)+";
m/$regex$/;
ІлпбЭпХвбп, звЮ ЮЭШ ТлФРов РСбЮЫовЭЮ ЮФШЭРЪЮТлХ аХЧгЫмвРвл. ЅЮ ЭХ ЧРСЫгЦФРЩвХбм, нвШ аХиХЭШп ЭХ нЪТШТРЫХЭвЭл. БвЮШв ТРЬ ЯЮ ЭРШТЭЮбвШ ШбЯЮЫмЧЮТРвм Т нвЮЩ бШвгРжШШ звЮ-ЭШСгФм ТаЮФХ "\b[+\055/*]\d+\b", Ш Тл СгФХвХ бШЫмЭЮ гФШТЫХЭл. єЮУФР бваЮЪХ ЯаШбТРШТРХвбп ЧЭРзХЭШХ, ЮЭЮ ШЭвХаЯаХвШагХвбп ЪРЪ бваЮЪР — вЮ, звЮ Тл бЮСШаРХвХбм ШбЯЮЫмЧЮТРвм ХУЮ Т ЪРзХбвТХ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, ЭХбгйХбвТХЭЭЮ ФЫп ЮСаРСЮвЪШ бваЮЪЮТле ФРЭЭле. ґТХ ЪЮЭбвагЪжШШ \b Т нвЮЬ ЯаШЬХаХ ФЮЫЦЭл СлЫШ ЮСЮЧЭРзРвм УаРЭШжл бЫЮТ, ЭЮ Т бваЮЪХ, ЧРЪЫозХЭЭЮЩ Т ЪРТлзЪШ, ЮЭШ ТбХУЮ ЫШим пТЫповбп бЮЪаРйХЭЭлЬШ ЮСЮЧЭРзХЭШпЬШ бШЬТЮЫР «ЧРСЮЩ». ІЬХбвЮ [\b] аХУгЫпаЭЮХ ТлаРЦХЭШХ гТШФШв ЯаЮбвлХ бШЬТЮЫл «ЧРСЮЩ», ЪЮвЮалХ ЭХ ШЬХов ЮбЮСЮЩ ШЭвХаЯаХвРжШШ Т аХУгЫпаЭле ТлаРЦХЭШпе Ш ЯЮЯаЮбвг бЮТЯРФРов б бШЬТЮЫРЬШ «ЧРСЮЩ» Т вХЪбвХ. БоаЯаШЧ!
Б ФагУЮЩ бвЮаЮЭл, Ш аХУгЫпаЭЮХ ТлаРЦХЭШХ, Ш бваЮЪР Т ЪРТлзЪРе ЯаХЮСаРЧгов \055 Т ФХдШб (055 — ASCII-ЪЮФ ФХдШбР), ЭЮ ХбЫШ ЯаХЮСаРЧЮТРЭШХ ТлЯЮЫЭпХвбп Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ, вЮ ХУЮ аХЧгЫмвРв ЭХ СгФХв ТЮбЯаШЭШЬРвмбп ЪРЪ ЬХвРбШЬТЮЫ. ІЯаЮзХЬ, нвЮ ЭХ ЯаЮШбеЮФШв Ш Т бваЮЪХ, ЭЮ ШвЮУЮТРп ЪЮЭбвагЪжШп [+-/*], Т ШвЮУХ ЯЮЫгзРХЬРп аХУгЫпаЭлЬ ТлаРЦХЭШХЬ, бЮФХаЦШв ФХдШб, ЪЮвЮалЩ ШЭвХаЯаХвШагХвбп ЪРЪ зРбвм ШЭвХаТРЫР Т бШЬТЮЫмЭЮЬ ЪЫРббХ. µйХ боаЯаШЧ!
П ЯЮФзХаЪШТРо ТбХ нвШ ЮСбвЮпвХЫмбвТР, ЯЮвЮЬг звЮ ЯаШ ЯЮбваЮХЭШШ бваЮЪШ, ЪЮвЮаРп ЯЮЧФЭХХ СгФХв ШбЯЮЫмЧЮТРвмбп Т ЪРзХбвТХ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, ЭХЮСеЮФШЬЮ ЧЭРвм, звЮ пТЫпХвбп ШЫШ ЭХ пТЫпХвбп ЬХвРбШЬТЮЫЮЬ (Р вРЪЦХ ЪХЬ ШЭвХаЯаХвШаговбп нвШ ЬХвРбШЬТЮЫл — бваЮЪЮЩ ШЫШ аХУгЫпаЭлЬ ТлаРЦХЭШХЬ, ЪЮУФР Ш Т ЪРЪЮЬ ЯЮапФЪХ ЮЭШ ЮСаРСРвлТРовбп). єЮЭХзЭЮ, ЭР ЯХаТле ЯЮаРе ЯаЮШбеЮФШв ЭХЬРЫЮ ЭХФЮаРЧгЬХЭШЩ. АРбиШаХЭЭлЩ ЯаШЬХа ЯаШТХФХЭ Т аРЧФХЫХ «їЮШбЪ РФаХбЮТ нЫХЪваЮЭЭЮЩ ЯЮзвл» (б. <$R[P#,R7-15]>).
<$M[R7-67]>єРЪ ЪаРвЪЮ гЯЮЬШЭРЫЮбм Т аРЧФХЫХ «єЮбТХЭЭРп ЯЮФФХаЦЪР ЫЮЪРЫмЭле ЪЮЭвХЪбвЮТ» (б. <$R[P#,R3-29]>), ЯЮФФХаЦЪР ЫЮЪРЫмЭле ЪЮЭвХЪбвЮТ POSIX Т Perl ЪаРЩЭХ ЮУаРЭШзХЭР. І зРбвЭЮбвШ, ЮЭР ЭХ гзШвлТРХв бгйХбвТЮТРЭШп ЮСкХФШЭпойШе ЯЮбЫХФЮТРвХЫмЭЮбвХЩ Ш ФагУШе ЯЮеЮЦШе ТЮЧЬЮЦЭЮбвХЩ, ЯЮнвЮЬг ASCII-ШЭвХаТРЫл Т бШЬТЮЫмЭле ЪЫРббРе ЭХ бЮФХаЦШв бШЬТЮЫЮТ ЫЮЪРЫмЭЮУЮ ЪЮЭвХЪбвР, ЭХ ТеЮФпйШе Т ЪЮФШаЮТЪг ASCII (баРТЭХЭШп бваЮЪ, Р вРЪЦХ бЮавШаЮТЪР вЮЦХ ТлЯЮЫЭповбп СХЧ гзХвР ЪЮЭвХЪбвР).
ѕФЭРЪЮ ЯаШ ЪЮЬЯШЫпжШШ б бЮЮвТХвбвТгойШЬШ СШСЫШЮвХЪРЬШ Perl ШбЯЮЫмЧгХв ЯаЮТХаЮзЭлХ дгЭЪжШШ (isalpha, isupper Ш в. Ф.), Р вРЪЦХ ЮвЮСаРЦХЭШп ЬХЦФг бШЬТЮЫРЬШ ТХаеЭХУЮ Ш ЭШЦЭХУЮ аХУШбваР. НвЮ ТЫШпХв ЭР аРСЮвг ЬЮФШдШЪРвЮаР /i Ш ФагУШе ЪЮЭбвагЪжШЩ, ЯХаХзШбЫХЭЭле Т вРСЫ. 7.8 (б. <$R[P#,R7-48]>). єаЮЬХ вЮУЮ, \w, \W, \s, \S (ЭЮ ЭХ \d!) Ш ЬХвРбШЬТЮЫл УаРЭШж бЫЮТ вРЪЦХ ЭРзШЭРов гзШвлТРвм ЫЮЪРЫмЭлЩ ЪЮЭвХЪбв. ІЯаЮзХЬ, Т ФШРЫХЪвХ аХУгЫпаЭле ТлаРЦХЭШЩ Perl ЭХ ЯЮФФХаЦШТРовбп [:digit:] Ш ФагУШХ УагЯЯЮТлХ ТлаРЦХЭШп POSIX, ЯХаХзШбЫХЭЭлХ ЭР б. <$R[P#,R3-30]>.
І зШбЫЮ бвРЭФРавЭле ЬЮФгЫХЩ Perl ТеЮФпв ЬЮФгЫм POSIX Ш ЬЮФгЫм<$M[R7-69]> I18N::Collate, ЭРЯШбРЭЭлЩ ПЪЪЮ ЕШХвРЭШХЬШ (Jarkko Hietaniemi). єбвРвШ, I18N — аРбЯаЮбваРЭХЭЭЮХ бЮЪаРйХЭШХ ФЫп бЫЮТР internalization. ЕЮвп нвШ ЬЮФгЫШ ЭХ ЮвЭЮбпвбп Ъ ЯЮФФХаЦЪХ аХУгЫпаЭле ТлаРЦХЭШЩ, ТЮЧЬЮЦЭЮ, ЮЭШ ЯаШУЮФпвбп ТРЬ Т вЮЬ бЫгзРХ, ХбЫШ ЫЮЪРЫмЭлЩ ЪЮЭвХЪбв ШУаРХв ТРЦЭго аЮЫм Т ТРиХЩ ЯаЮУаРЬЬХ. јЮФгЫм POSIX ЮУаЮЬХЭ, ЭЮ ФЮЪгЬХЭвРжШп ЯЮ ЭХЬг ЮвЭЮбШвХЫмЭЮ ЭХТХЫШЪР — ЧР ФЮЯЮЫЭШвХЫмЭЮЩ ШЭдЮаЬРжШХЩ ЮСаРйРЩвХбм Ъ бЮЮвТХвбвТгойШЬ бваРЭШжРЬ агЪЮТЮФбвТР ЯЮ СШСЫШЮвХЪХ C.
І Perl ЯаХФгбЬЮваХЭР ТЮЧЬЮЦЭЮбвм ЮЯаХФХЫХЭШп бШЬТЮЫЮТ ЯЮ Ше зШбЫЮТлЬ ЪЮФРЬ. ІЮбмЬХаШзЭлХ ЪЮФл ШЧ ФТге ШЫШ ваХе жШда ЧРФРовбп Т дЮаЬРвХ [\33] ШЫШ [\177] , Р иХбвЭРФжРвХаШзЭлХ ЪЮФл ШЧ ЮФЭЮЩ ШЫШ ФТге жШда — Т ТШФХ [\xA] ШЫШ [\xFF].
І бваЮЪРе Perl вРЪЦХ ФЮЯгбЪРовбп ТЮбмЬХаШзЭлХ ЪЮФл ШЧ ЮФЭЮЩ жШдал, ЭЮ Т аХУгЫпаЭле ТлаРЦХЭШпе Perl нвЮ ЮСлзЭЮ ЭХТЮЧЬЮЦЭЮ, ЯЮбЪЮЫмЪг ЪЮЭбвагЪжШп ТШФР [\1] ТЮбЯаШЭШЬРХвбп ЪРЪ ЮСаРвЭРп бблЫЪР. ±ЮЫХХ вЮУЮ, ЮСаРвЭлХ бблЫЪШ ШЧ ЭХбЪЮЫмЪШе жШда ФЮЯгбвШЬл Т вЮЬ бЫгзРХ, ХбЫШ бваЮЪР бЮФХаЦШв ФЮбвРвЮзЭЮХ ЪЮЫШзХбвТЮ ЯРа бЮеаРЭпойШе бЪЮСЮЪ. ВРЪШЬ ЮСаРЧЮЬ<$M[R7-53]>, [\12] ШЭвХаЯаХвШагХвбп ЪРЪ ЮСаРвЭРп бблЫЪР, ХбЫШ ТлаРЦХЭШХ бЮФХаЦШв ЭХ ЬХЭХХ 12 ЯРа бЮеаРЭпойШе ЪагУЫле бЪЮСЮЪ, ШЫШ ЪРЪ ТЮбмЬХаШзЭлЩ ЪЮФ (10 Т ФХбпвШзЭЮЩ бШбвХЬХ) Т ЯаЮвШТЭЮЬ бЫгзРХ. їаЮзШвРТ зХаЭЮТШЪ нвЮЩ УЫРТл, ГнЩЭ ±ХаЪ (Wayne Berke) ТЭХб ЯаХФЫЮЦХЭШХ, ЪЮвЮаЮХ п УЮапзЮ ЯЮФФХаЦШТРо: ЭШЪЮУФР ЭХ ШбЯЮЫмЧгЩвХ ТЮбмЬХаШзЭлХ ЪЮФл ШЧ ФТге жШда (ЭРЯаШЬХа, \12), Р ЯаХЮСаРЧгЩвХ Ше Ъ дЮаЬРвг б ваХЬп жШдаРЬШ \012). їЮзХЬг? Perl ЭШЪЮУФР ЭХ ШЭвХаЯаХвШагХв \012 ЪРЪ ЮСаРвЭго бблЫЪг, Р \12 ЬЮЦХв бЫгзРЩЭЮ ЯаХТаРвШвмбп Т ЮСаРвЭго бблЫЪг б гТХЫШзХЭШХЬ зШбЫР бЮеаРЭпойШе ЪагУЫле бЪЮСЮЪ.
БгйХбвТгХв ФТР ЮбЮСле бЫгзРп. ІЮ-ЯХаТле, ЮСаРвЭлХ бблЫЪШ Т бШЬТЮЫмЭЮЬ ЪЫРббХ СХббЬлбЫХЭЭл, ЯЮнвЮЬг ТЮбмЬХаШзЭлХ ЪЮФл ШЧ ЮФЭЮЩ жШдал ТЯЮЫЭХ ФЮЯгбвШЬл Т бШЬТЮЫмЭле ЪЫРббРе (ТЮв ЯЮзХЬг п гЯЮваХСШЫ Т ЯаХФлФгйХЬ РСЧРжХ ТлаРЦХЭШХ ЮСлзЭЮ ЭХТЮЧЬЮЦЭЮ). ІЮ-ТвЮале [\0] пТЫпХвбп ТЮбмЬХаШзЭлЬ ЪЮФЮЬ ТбХУФР, ЯЮбЪЮЫмЪг нвР ЪЮЭбвагЪжШп ЭХ ЬЮЦХв ШбЯЮЫмЧЮТРвмбп Т ЪРзХбвТХ ЮСаРвЭЮЩ бблЫЪШ.
єРЪ ЮСкпбЭпЫЮбм Т аРЧФХЫХ «ВХаЬШЭЮЫЮУШп аХУгЫпаЭле ТлаРЦХЭШЩ» УЫРТл 1 (б. <$R[P#,R1-12]>), вЮзЭЮХ бЮЮвТХвбвТШХ ЬХЦФг бШЬТЮЫРЬШ Ш ЯаХФбвРТЫпойШЬШ Ше СРЩвРЬШ ЧРТШбШв Юв ЪЮФШаЮТЪШ. ѕСлзЭЮ ШбЯЮЫмЧгХвбп ЪЮФШаЮТЪР ASCII, ЮФЭРЪЮ ЯЮЫмЧЮТРвХЫм ФРЭЭле ЬЮЦХв Т ЫоСЮЩ ЬЮЬХЭв ШЧЬХЭШвм ХХ ЯЮ бТЮХЬг гбЬЮваХЭШо. ґагУРп ЯЮеЮЦРп ЯаЮСЫХЬР ЧРЪЫозРХвбп Т вЮЬ, звЮ ЧЭРзХЭШХ \n ЭХ ЮЯаХФХЫпХвбп ЭР гаЮТЭХ Perl, Р ЧРТШбШв Юв бШбвХЬл (б. <$R[P#,R3-28]>).
ПЧлЪ бШЬТЮЫмЭле ЪЫРббЮТ<$M[R7-29]> Perl ЧРЭШЬРХв ЮбЮСЮХ ЬХбвЮ баХФШ ФШРЫХЪвЮТ аХУгЫпаЭле ТлаРЦХЭШЩ, ЯЮбЪЮЫмЪг Т ЭХЬ ЯЮФФХаЦШТРХвбп ТЮЧЬЮЦЭЮбвм нЪаРЭШаЮТРЭШп ЯаХдШЪбЮЬ \. ЅРЯаШЬХа, ТлаРЦХЭШХ [[\-\],]] ЮЯаХФХЫпХв бШЬТЮЫмЭлЩ ЪЫРбб, бЮТЯРФРойШЩ б ФХдШбЮЬ, ЯаРТЮЩ ЪТРФаРвЭЮЩ бЪЮСЪЮЩ ШЫШ ЧРЯпвЮЩ (ТЮЧЬЮЦЭЮ, бЬлбЫ [[\-\],]] ФЮЩФХв ФЮ ТРб ЭХ баРЧг — ТЭШЬРвХЫмЭЮ ЯаЮРЭРЫШЧШагЩвХ ТлаРЦХЭШХ Ш гСХФШвХбм Т вЮЬ, звЮ Тл ХУЮ ЯЮЭШЬРХвХ). јЭЮУШХ ФагУШХ ФШРЫХЪвл аХУгЫпаЭле ТлаРЦХЭШЩ ЭХ ЯЮФФХаЦШТРов нЪаРЭШаЮТРЭШХ Т ЪЫРббРе, звЮ ТХбмЬР ЯаШбЪЮаСЭЮ, ЯЮбЪЮЫмЪг ТЮЧЬЮЦЭЮбвм нЪаРЭШаЮТРЭШп ЬХвРбШЬТЮЫЮТ ЪЫРббР ЭХ вЮЫмЪЮ ЫЮУШзЭР, ЭЮ Ш ЯЮЫХЧЭР. ±ЮЫХХ вЮУЮ, ЮзХЭм гФЮСЭЮ ШЬХвм ТЮЧЬЮЦЭЮбвм нЪаРЭШаЮТРЭШп ФРЦХ Т вЮЬ бЫгзРХ, ХбЫШ нвЮ ЭХ пТЫпХвбп РСбЮЫовЭЮ ЭХЮСеЮФШЬлЬ, ЯЮбЪЮЫмЪг нвЮ ЬЮЦХв бФХЫРвм ЯаЮУаРЬЬг СЮЫХХ ЯЮЭпвЭЮЩ[38].
П гЦХ ЭХЮФЭЮЪаРвЭЮ гЯЮЬШЭРЫ Ю вЮЬ, звЮ ЬХвРбШЬТЮЫл Т бШЬТЮЫмЭле ЪЫРббРе Ш ТЭХ Ше ШЭвХаЯаХвШаговбп ЯЮ-аРЧЭЮЬг. Perl ЭХ пТЫпХвбп ШбЪЫозХЭШХЬ ШЧ нвЮУЮ ЯаРТШЫР, еЮвп ШЭвХаЯаХвРжШп ЬЭЮУШе ЬХвРбШЬТЮЫЮТ Т ЮСЮШе бЫгзРпе бЮТЯРФРХв. І зРбвЭЮбвШ, ЪТРЭвШдШЪРвЮал * Ш +, (), ., ЪЮЭбвагЪжШп ТлСЮаР, пЪЮаЭлХ ЬХвРбШЬТЮЫл Ш в. Ф. Т бШЬТЮЫмЭле ЪЫРббРе СХббЬлбЫХЭЭл. јл гЦХ ТШФХЫШ, звЮ \b, \3 Ш ^ Т бШЬТЮЫмЭле ЪЫРббРе ШЬХов ЮбЮСлЩ бЬлбЫ, ЭХ бТпЧРЭЭлЩ б Ше ШЭвХаЯаХвРжШХЩ ТЭХ ЪЫРббР. БШЬТЮЫл - Ш ] ТлЯЮЫЭпов бЯХжШРЫмЭлХ дгЭЪжШШ Т бШЬТЮЫмЭле ЪЫРббРе, ЭЮ пТЫповбп ЮСлзЭлЬШ бШЬТЮЫРЬШ ЧР Ше ЯаХФХЫРЬШ.
ІЮбмЬХаШзЭлХ Ш иХбвЭРФжРвХаШзЭлХ ЪЮФл гФЮСЭЮ ШбЯЮЫмЧЮТРвм Т бШЬТЮЫмЭле ЪЫРббРе, ЮбЮСХЭЭЮ ЯаШ ЮЯаХФХЫХЭШШ ШЭвХаТРЫЮТ. ЅРЯаШЬХа, ФЫп ЮЯШбРЭШп «ЮвЮСаРЦРХЬЮУЮ» ASCII-бШЬТЮЫР (вЮ Хбвм ЭХ пТЫпойХУЮбп ЯаЮЯгбЪЮЬ ШЫШ гЯаРТЫпойШЬ бШЬТЮЫЮЬ), ваРФШжШЮЭЭЮ ШбЯЮЫмЧгХвбп ЪЫРбб [[!-~]] (ТЮбЪЫШжРвХЫмЭлЩ ЧЭРЪ пТЫпХвбп ЯХаТлЬ, Р вШЫмФР — ЯЮбЫХФЭШЬ ЮвЮСаРЦРХЬлЬ бШЬТЮЫЮЬ Т ASCII). ЗвЮСл ЪЫРбб СлЫ СЮЫХХ ЭРУЫпФЭлЬ, ХУЮ ЬЮЦЭЮ ЧРЯШбРвм Т ТШФХ [[\x21-\x7e]]. ВЮв, ЪвЮ гЦХ бвРЫЪШТРЫбп б нвЮЩ ЧРФРзХЩ, ЯЮЩЬХв ЮСР ТлаРЦХЭШп, ЭЮ ЯаШ ЯХаТЮЬ ЧЭРЪЮЬбвТХ ЪЫРбб [[!-~]] ТлУЫпФШв ЯЮ ЬХЭмиХЩ ЬХаХ ЧРУРФЮзЭЮ. ІлаРЦХЭШХ [[\x21-\x7e]] ЯЮ ЪаРЩЭХЩ ЬХаХ ЭРТЮФШв ЭР ЬлбЫм, звЮ Т ЭХЬ ЮЯаХФХЫпХвбп ЭХЪЮвЮалЩ ШЭвХаТРЫ бШЬТЮЫЮТ.
їаШ ЮвбгвбвТШШ ЯЮЫЭЮжХЭЭЮЩ ЯЮФФХаЦЪШ ЫЮЪРЫмЭле ЪЮЭвХЪбвЮТ POSIX ТЮбмЬХаШзЭлХ Ш иХбвЭРФжРвХаШзЭлХ ЪЮФл ЯаШЭЮбпв ЭХЬРЫго ЯЮЫмЧг ЯаШ аРСЮвХ б вХЪбвЮЬ Т ФагУШе ЪЮФШаЮТЪРе (ЭХ ASCII). ЅРЯаШЬХа, ЯаШ аРСЮвХ б ЯЮЯгЫпаЭЮЩ Т Web ЪЮФШаЮТЪЮЩ Latin-1 (ISO-8859-1) ЭХЮСеЮФШЬЮ гзШвлТРвм, звЮ СгЪТР u ЬЮЦХв вРЪЦХ ТлУЫпФХвм ЪРЪ й, к, л Ш м (бШЬТЮЫл б ЪЮФРЬШ Юв \xf9 ФЮ \xfc). ВРЪШЬ ЮСаРЧЮЬ, ФЫп бЮТЯРФХЭШп б ЫоСЮЩ ШЧ аРЧЭЮТШФЭЮбвХЩ u ШбЯЮЫмЧгХвбп ЪЫРбб [[u\xf9-\xfc]]. ІХабШпЬ нвШе бШЬТЮЫЮТ Т ТХаеЭХЬ аХУШбваХ бЮЮвТХвбвТгов ЪЮФл б \xd9 ФЮ \xdc, ЯЮнвЮЬг ФЫп ЯЮШбЪР бЮТЯРФХЭШп СХЧ гзХвР аХУШбваР СгФХв ШбЯЮЫмЧЮТРвмбп ТлаРЦХЭШХ [[uU\xf9-\xfc\xd9-\xdc]] (ЬЮФШдШЪРвЮа /i ЮвЭЮбШвбп вЮЫмЪЮ Ъ ASCII-бШЬТЮЫг u, ЯЮнвЮЬг Ьл б вРЪШЬ ЦХ гбЯХеЮЬ ЬЮЦХЬ ТЪЫозШвм U Т ЪЫРбб Ш ШЧСРТШвмбп Юв ЧРваРв, бТпЧРЭЭле б ЯаШЬХЭХЭШХЬ /i; бЬ. б. <$R[P#,R7-68]>).
ЅР ЯаРЪвШЪХ нвР ЬХвЮФШЪР зРбвЮ ЯаШЬХЭпХвбп ЯаШ бЮавШаЮТЪХ. ѕСлзЭЮ бЮавШаЮТЪР @items ТлЯЮЫЭпХвбп ЪЮЬРЭФЮЩ sort @items, ЭЮ Т нвЮЬ бЫгзРХ бШЬТЮЫл бЮавШаговбп ЯЮ бТЮШЬ ЪЮФРЬ, Ш бШЬТЮЫ u (ASCII-ЪЮФ \x75) ЮЪРЦХвбп бЫШиЪЮЬ ФРЫХЪЮ Юв л Ш ФагУШе ЯЮеЮЦШе бШЬТЮЫЮТ. µбЫШ Ьл бЮЧФРФШЬ ЪЮЯШо ЪРЦФЮУЮ бШЬТЮЫР, бТпЦХЬ б ЭХЩ ЪЫоз бЮавШаЮТЪШ Ш ЮСкХФШЭШЬ ЯРал Т ЮвФХЫмЭЮЬ РббЮжШРвШТЭЮЬ ЬРббШТХ, вЮ нвЮв ЬРббШТ ЬЮЦЭЮ СгФХв ШбЯЮЫмЧЮТРвм ЯаШ ТлЧЮТХ sort Ш вРЪШЬ ЮСаРЧЮЬ ЮСХбЯХзШвм ЭгЦЭлЩ аХЧгЫмвРв бЮавШаЮТЪШ.
їаЮбвХЩиРп аХРЫШЧРжШп ТлУЫпФШв вРЪ:
foreach $item (@Items) {
$key = lc $item; # БЪЮЯШаЮТРвм бШЬТЮЫ б ЯаШТХФХЭШХЬ
# Ъ ЭШЦЭХЬг аХУШбваг Т ЪЮФШаЮТЪХ ASCII
;key =$ s.[\xd9-\xdc\xf9-\xfc].u.g; # ІбХ аРЧЭЮТШФЭЮбвШ u
# ЯаХТаРйРовбп Т ЮСлзЭлЩ бШЬТЮЫ u.
# ІлЯЮЫЭШвм РЭРЫЮУШзЭлХ ЮЯХаРжШШ ФЫп ФагУШе ФШРЪаШвШзХбЪШе бШЬТЮЫЮТ
$pair{$item} = $key; # ·РЯЮЬЭШвм ЯРаг "бШЬТЮЫ-ЪЫоз"
}
# ѕвбЮавШаЮТРвм ЯЮ бЮФХаЦШЬЮЬг ЪЫозР
@SortedItems = sort { $pair{$a} cmp $pair{$b} } @Items;
(lc — гФЮСЭРп дгЭЪжШп Perl5, ЮФЭРЪЮ нвЮв ЯаШЬХа ЭХвагФЭЮ ЯХаХЯШбРвм ЭР Perl4). І ФХЩбвТШвХЫмЭЮбвШ нвЮ ЫШим ЯХаТлЩ иРУ, ЯЮбЪЮЫмЪг Т ЪРЦФЮЬ пЧлЪХ Ъ бЮавШаЮТЪХ ЯаХФкпТЫповбп ЮбЮСлХ ваХСЮТРЭШп, ЮФЭРЪЮ нвЮв иРУ бФХЫРЭ Т ЯаРТШЫмЭЮЬ ЭРЯаРТЫХЭШШ. ґагУШЬ иРУЮЬ СгФХв ШбЯЮЫмЧЮТРЭШХ ЬЮФгЫп I18N::Collate, Ю ЪЮвЮаЮЬ гЯЮЬШЭРХвбп ЭР б. <$R[P#,R7-69]>.
І ЫоСЮЩ ФЮЪгЬХЭвРжШШ, ЯЮбТпйХЭЭЮЩ аХУгЫпаЭлЬ ТлаРЦХЭШпЬ Perl (Т вЮЬ зШбЫХ Ш Т ЭШЦЭХЩ зРбвШ вРСЫ. 7.1), ТбваХзРовбп \L, \E, \u Ш ФагУШХ ЪЮЬСШЭРжШШ, ЯХаХзШбЫХЭЭлХ Т вРСЫ. 7.8. єРЪ ЭШ бваРЭЭЮ, ЮЭШ ЭХ пТЫповбп ЬХвРбШЬТЮЫРЬШ<$M[R7-31]> аХУгЫпаЭле ТлаРЦХЭШЩ. јХеРЭШЧЬ аХУгЫпаЭле ТлаРЦХЭШЩ ЧЭРХв, звЮ [*] ЮЧЭРзРХв «ЯаЮШЧТЮЫмЭЮХ ЪЮЫШзХбвТЮ нЪЧХЬЯЫпаЮТ», Р [[] пТЫпХвбп ЭРзРЫЮЬ бШЬТЮЫмЭЮУЮ ЪЫРббР, ЭЮ Ю [\E] ХЬг ЭШзХУЮ ЭХ ШЧТХбвЭЮ. їЮзХЬг ЦХ п ЯаШТЮЦг ЧФХбм нвШ ЪЮЭбвагЪжШШ?<$M[R7-48]>
ВРСЫШжР 7.8. єЮЭбвагЪжШШ ШЧЬХЭХЭШп аХУШбваР бШЬТЮЫЮТ Т бваЮЪРе Ш аХУгЫпаЭле ТлаРЦХЭШпе-ЮЯХаРЭФРе
|
єЮЭбвагЪжШп |
ѕЯШбРЭШХ |
ІбваЮХЭЭРп дгЭЪжШп |
|
\L, \U |
їХаХТХбвШ бШЬТЮЫл Т ЭШЦЭШЩ (ТХаеЭШЩ) аХУШбва ФЮ \E[39] |
lc(…), uc(…) |
|
\l, \u |
їХаХТХбвШ Т ЭШЦЭШЩ (ТХаеЭШЩ) аХУШбва бЫХФгойШЩ бШЬТЮЫ[40] |
lcfirst(…), ucfirst(…) |
|
\Q |
ФЮСРТЫпвм нЪаРЭШагойШЩ ЯаХдШЪб ЯХаХФ ТбХЬШ ЭХ-РЫдРТШвЭлЬШ бШЬТЮЫРЬШ ФЮ \E |
quotemeta(…) |
|
БЯХжШРЫмЭлХ ЪЮЬСШЭРжШШ |
||
|
\u\L |
їХаХТХбвШ ЯХаТлЩ бШЬТЮЫ Т ТХаеЭШЩ аХУШбва; ЮбвРЫмЭлХ бШЬТЮЫл ЯХаХТЮФпвбп Т ЭШЦЭШЩ аХУШбва ФЮ ЪЮЬСШЭРжШШ \E ШЫШ ФЮ ЪЮЭжР вХЪбвР |
|
|
\l\U |
їХаХТХбвШ ЯХаТлЩ бШЬТЮЫ Т ЭШЦЭШЩ аХУШбва; ЮбвРЫмЭлХ бШЬТЮЫл ЯХаХТЮФпвбп Т ТХаеЭШЩ аХУШбва ФЮ ЪЮЬСШЭРжШШ \E ШЫШ ФЮ ЪЮЭжР вХЪбвР |
|
ЅР ЯаРЪвШЪХ нвШ ЪЮЭбвагЪжШШ аРСЮвРов ЪРЪ ЮСлзЭлХ ЬХвРбШЬТЮЫл аХУгЫпаЭле ТлаРЦХЭШЩ. їаШ ШбЯЮЫмЧЮТРЭШШ Т аХУгЫпаЭле ТлаРЦХЭШпе-ЮЯХаРЭФРе ЮЭШ ЮСлзЭЮ ЮСаРСРвлТРовбп Т дРЧХ B ЯаЮжХббР, ШЧЮСаРЦХЭЭЮУЮ ЭР аШб. 7.1, ЯЮнвЮЬг ФЮ ЬХеРЭШЧЬР аХУгЫпаЭле ТлаРЦХЭШЩ ЮЭШ ЯЮЯаЮбвг ЭХ ФЮеЮФпв (б. <$R[P#,R7-70]>). ЅЮ ЯЮбЪЮЫмЪг Т ЭХЪЮвЮале бШвгРжШпе аРЧЫШзШп ТбХ ЦХ бгйХбвТгов, п ЭРЧлТРо ЪЮЭбвагЪжШШ ШЧ вРСЫ. 7.8 ЬХвРбШЬТЮЫРЬШ ТвЮаЮУЮ ЪЫРббР.
їЮ ЮвЭЮиХЭШо Ъ аХУгЫпаЭлЬ ТлаРЦХЭШпЬ-ЮЯХаРЭФРЬ ШЭвХаЯЮЫпжШп ЯХаХЬХЭЭле Ш ЬХвРбШЬТЮЫл, ЯХаХзШбЫХЭЭлХ Т вРСЫ. 7.8, ШУаРов ЮбЮСго аЮЫм, ЯЮбЪЮЫмЪг ЮЭШ:
l ФХЩбвТгов вЮЫмЪЮ ТЮ ТаХЬп «ТлбЮЪЮгаЮТЭХТЮУЮ» бЪРЭШаЮТРЭШп ЮЯХаРЭФР.
l аРбЯаЮбваРЭповбп вЮЫмЪЮ ЭР бШЬТЮЫл ЮвЪЮЬЯШЫШаЮТРЭЭЮУЮ аХУгЫпаЭЮУЮ ТлаРЦХЭШп.
НвЮ ЮСкпбЭпХвбп вХЬ, звЮ ЬХвРбШЬТЮЫл ТвЮаЮУЮ ЪЫРббР аРбЯЮЧЭРовбп вЮЫмЪЮ ТЮ ТаХЬп дРЧл B (бЬ. аШб. 7.1), ЭЮ ЭХ ЯЮбЫХ ТлЯЮЫЭХЭШп ШЭвХаЯЮЫпжШШ. µбЫШ ЭХ ЧЭРвм ЮС нвЮЬ, ТХаЮпвЭЮ, ТРб гФШТШв вЮ, звЮ бЫХФгойШЩ даРУЬХЭв ЭХ аРСЮвРХв:
$ForceCase = $WantUpper ? '\U' : '\L';
if (m/$ForceCase$RestOfRegex/) {
…
їЮбЪЮЫмЪг \U ШЫШ \L Т $ForceCase ЭРеЮФШвбп Т ШЭвХаЯЮЫШагХЬЮЬ вХЪбвХ (ЪЮвЮалЩ ЮСаРСРвлТРХвбп вЮЫмЪЮ Т дРЧХ C), ЮбЮСлЩ бЬлбЫ нвЮЩ ЪЮЬСШЭРжШШ ЭХ ЮЯЮЧЭРХвбп. ІЯаЮзХЬ, ЬХеРЭШЧЬ аХУгЫпаЭле ТлаРЦХЭШЩ ЮЯЮЧЭРХв бШЬТЮЫ \, ЯЮнвЮЬг [\U] ЮСаРСРвлТРХвбп ЪРЪ ЮСйШЩ бЫгзРЩ ЭХШЧТХбвЭЮУЮ нЪаРЭШаЮТРЭЭЮУЮ бШЬТЮЫР: ЯаХдШЪб \ ЯаЮбвЮ ШУЭЮаШагХвбп. µбЫШ $RestOfRegex бЮФХаЦШв вХЪбв Path, Р ЯХаХЬХЭЭРп $WantUpper ШбвШЭЭР, вЮ ЮЯХаРвЮа СгФХв ШбЪРвм ЫШвХаРЫмЭлЩ вХЪбв UPath, Р ЭХ PATH, ЪРЪ ЯаХФЯЮЫРУРЫЮбм.
ёЧ нвЮУЮ ЯаРТШЫР бЫХФгХв Ш ФагУЮЩ ТлТЮФ — ЪЮЬРЭФл ТШФР [m/([a-z])…\U\1] ЭХ аРСЮвРов. НвЮв ЮЯХаРвЮа ШйХв бШЬТЮЫ ЭШЦЭХУЮ аХУШбваР, ЧР ЪЮвЮалЬ бЫХФгХв нвЮв ЦХ бШЬТЮЫ Т ТХаеЭХЬ аХУШбваХ. ѕФЭРЪЮ \U аРСЮвРХв вЮЫмЪЮ б вХЪбвЮЬ бРЬЮУЮ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, Р ЯЮбЪЮЫмЪг [\1] ЯаХФбвРТЫпХв вХЪбв, бЮТЯРТиШЩ б ЭХЪЮвЮаЮЩ зРбвмо аХУгЫпаЭЮУЮ ТлаРЦХЭШп, нвЮв вХЪбв ЮбвРХвбп ЭХШЧТХбвЭлЬ ФЮ ЭХЯЮбаХФбвТХЭЭЮУЮ ЯЮШбЪР бЮТЯРФХЭШп (ТХаЮпвЭЮ, ЯЮШбЪ ЬЮЦЭЮ аРббЬРваШТРвм ЪРЪ «дРЧг E» ЭР аШб. 7.1).
<$M[R7-11]>їЮШбЪ бЮТЯРФХЭШЩ ЧРЪЫРФлТРХв ЮбЭЮТг ФЫп ТбХУЮ ЯаШЬХЭХЭШп аХУгЫпаЭле ТлаРЦХЭШЩ Т Perl. є бзРбвмо, ЮЯХаРвЮа ЯЮШбЪР ЮСЫРФРХв ФЮбвРвЮзЭЮЩ УШСЪЮбвмо; ТЯаЮзХЬ, нвЮ ЭХбЪЮЫмЪЮ гбЫЮЦЭпХв ХУЮ ШЧгзХЭШХ. їаШ аРббЬЮваХЭШШ ТЮЧЬЮЦЭЮбвХЩ m/…/ п СгФг агЪЮТЮФбвТЮТРвмбп ЯаШЭжШЯЮЬ «аРЧФХЫпЩ Ш ТЫРбвТгЩ». јл ЯЮбЫХФЮТРвХЫмЭЮ аРббЬЮваШЬ бЫХФгойШХ вХЬл:
l ѕЯаХФХЫХЭШХ бРЬЮУЮ ЮЯХаРвЮаР ЯЮШбЪР (аХУгЫпаЭЮХ ТлаРЦХЭШХ-ЮЯХаРЭФ).
l ѕЯаХФХЫХЭШХ жХЫХТЮЩ бваЮЪШ, Т ЪЮвЮаЮЩ ЮбгйХбвТЫпХвбп ЯЮШбЪ.
l їЮСЮзЭлХ нддХЪвл ЯЮШбЪР.
l ·ЭРзХЭШХ, ТЮЧТаРйРХЬЮХ Т аХЧгЫмвРвХ ЯЮШбЪР.
l ІЭХиЭШХ дРЪвЮал, ТЫШпойШХ ЭР ЯЮШбЪ.
ѕЯХаРвЮа ЯЮШбЪР ЯЮ аХУгЫпаЭЮЬг ТлаРЦХЭШо Т Perl ЯЮЫгзРХв ФТР ЮЯХаРЭФР: жХЫХТго бваЮЪг Ш аХУгЫпаЭЮХ ТлаРЦХЭШХ. ѕЭ ТЮЧТаРйРХв ЭХЪЮвЮаЮХ ЧЭРзХЭШХ, вШЯ ЪЮвЮаЮУЮ ЧРТШбШв Юв ЪЮЭвХЪбвР. єаЮЬХ вЮУЮ, ЮЯХаРвЮа ЬЮЦХв бЮФХаЦРвм ЭХЮСпЧРвХЫмЭлХ ЬЮФШдШЪРвЮал, ТЫШпойШХ ЭР ЯаЮжХбб ЯЮШбЪР (ЯЮЫРУРо, Ше вЮЦХ ЬЮЦЭЮ аРббЬРваШТРвм ЪРЪ бТЮХУЮ аЮФР ЮЯХаРЭФл).
І ЪРзХбвТХ ЮУаРЭШзШвХЫп ТлаРЦХЭШп-ЮЯХаРЭФР ЮСлзЭЮ ШбЯЮЫмЧгХвбп бШЬТЮЫ /, еЮвп Тл ЬЮЦХвХ ТлСаРвм ЫоСЮЩ ФагУЮЩ бШЬТЮЫ ЯЮ бТЮХЬг гбЬЮваХЭШо (вЮзЭХХ, ФЮЯгбЪРХвбп ШбЯЮЫмЧЮТРЭШХ ЫоСЮУЮ бШЬТЮЫР, ЭХ пТЫпойХУЮбп РЫдРТШвЭЮ-жШдаЮТлЬ ШЫШ ЯаЮЯгбЪЮЬ<$M[R7-72]> — [6 б.<$R[P#,R7-71]>]). ІХаЮпвЭЮ, нвЮ ЮФШЭ ШЧ бРЬле ЭХЯаШТлзЭле РбЯХЪвЮТ бШЭвРЪбШбР Perl, еЮвп ЯаШ гЬХЫЮЬ ШбЯЮЫмЧЮТРЭШШ ЮЭ ФХЫРХв ЯаЮУаРЬЬг СЮЫХХ ЯЮЭпвЭЮЩ.
ЅРЯаШЬХа, ФЫп ЯаШЬХЭХЭШп ТлаРЦХЭШп [^/(?:[^/]+/)+Perl$] бЮ бвРЭФРавЭлЬШ ЮУаРЭШзШвХЫпЬШ ЯЮваХСгХвбп ЪЮЬРЭФР [m/^\/(?:[^\/]+\/)+Perl$/]. єРЪ УЮТЮаШвбп ЯаШ ЮЯШбРЭШШ дРЧл A ЭР аШб. 7.1, ЧРЪалТРойШЩ ЮУаРЭШзШвХЫм, ТбваХзРойШЩбп Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ, ФЮЫЦХЭ нЪаРЭШаЮТРвмбп ФЫп вЮУЮ, звЮСл ЧРЬРбЪШаЮТРвм ЮУаРЭШзШТРойго дгЭЪжШо нвЮУЮ бШЬТЮЫР (Т ЯаШТХФХЭЭЮЬ ЯаШЬХаХ нЪаРЭШагойШХ ЯаХдШЪбл ТлФХЫХЭл ЦШаЭлЬ иаШдвЮЬ). БШЬТЮЫл, нЪаРЭШагХЬлХ ЯЮ нвЮЩ ЯаШзШЭХ, ЯХаХФРовбп аХУгЫпаЭЮЬг ТлаРЦХЭШо вРЪ, бЫЮТЭЮ ЭШЪРЪШе ЯаХдШЪбЮТ ЭХв<$R[P#,R7-74]> [7 б.<$R[P#,R7-73]>]. ІЬХбвЮ вЮУЮ, звЮСл ЯХаХУагЦРвм ТлаРЦХЭШХ ЫШиЭШЬШ бШЬТЮЫРЬШ \, ЯаЮйХ ТЮбЯЮЫмЧЮТРвмбп ФагУШЬ ЮУаРЭШзШвХЫХЬ — Т нвЮЬ бЫгзРХ ЪЮЬРЭФР ЯаШЭШЬРХв ТШФ m!^/(?:[^/]+/)+Perl$! ШЫШ m,^/(?:[^/]+/)+Perl$,. І ЪРзХбвТХ ЮУаРЭШзШвХЫХЩ вРЪЦХ зРбвЮ ШбЯЮЫмЧговбп бШЬТЮЫл m|…|, m#…# Ш m%…%.
ЅХЪЮвЮалХ ЮУаРЭШзШвХЫШ ТлЯЮЫЭпов ЮбЮСлХ дгЭЪжШШ:
l І зХвлаХе бЯХжШРЫмЭле ЪЮЭбвагЪжШпе, m(…), m{…}, m[…] Ш m<…>, Т ЪРзХбвТХ ЮвЪалТРойХУЮ Ш ЧРЪалТРойХУЮ ЮУаРЭШзШвХЫп ШбЯЮЫмЧговбп аРЧЭлХ бШЬТЮЫл, ЯЮнвЮЬг нвШ ЪЮЭбвагЪжШШ ЬЮУгв Слвм ТЫЮЦХЭЭлЬШ<$M[R7-76]> [8 б.<$R[P#,R7-75]>]. їЮбЪЮЫмЪг ЪагУЫлХ Ш ЪТРФаРвЭлХ бЪЮСЪШ ЮзХЭм зРбвЮ ТбваХзРовбп Т аХУгЫпаЭле ТлаРЦХЭШпе, ЪЮЭбвагЪжШШ m(…) Ш m[…] ЯаШЬХЭповбп ЭХ вРЪ зРбвЮ, ЭЮ б ФТгЬп ФагУШЬШ ЪЮЭбвагЪжШпЬШ ФХЫЮ ЮСбвЮШв ШЭРзХ. І зРбвЭЮбвШ, ЯаШ ШбЯЮЫмЧЮТРЭШШ ЬЮФШдШЪРвЮаР /x бвРЭЮТпвбп ТЮЧЬЮЦЭлЬШ даРУЬХЭвл ТШФР:
m{
аХУгЫпаЭЮХ # ЪЮЬЬХЭвРаШШ
ТлаРЦХЭШХ # ЪЮЬЬХЭвРаШШ
}x;
їаШ бЮЧФРЭШШ ТЫЮЦХЭЭле ЪЮЭбвагЪжШЩ бЮ бЯХжШРЫмЭлЬШ ЮУаРЭШзШвХЫпЬШ нЪаРЭШаЮТРЭШХ ЯРаЭле бШЬТЮЫЮТ ЭХ ваХСгХвбп. ЅРЯаШЬХа, ЪЮЬРЭФР m(^/((?:[^/]+/)+)Perl$) ТЯЮЫЭХ ФЮЯгбвШЬР, еЮвп аРЧЮСаРвмбп Т ЭХЩ ЭХЫХУЪЮ.
l µбЫШ Т ЪРзХбвТХ ЮУаРЭШзШвХЫп ШбЯЮЫмЧгХвбп РЯЮбваЮд, аХУгЫпаЭЮХ ТлаРЦХЭШХ-ЮЯХаРЭФ ЮСаРСРвлТРХвбп ЯЮ ЯаРТШЫРЬ бваЮЪ, ЧРЪЫозХЭЭле Т РЯЮбваЮдл (Т ЮвЫШзШХ Юв ЮСлзЭЮЩ ЮСаРСЮвЪШ ЯЮ ЯаРТШЫРЬ бваЮЪ, ЧРЪЫозХЭЭле Т ЪРТлзЪШ, ЯЮФаЮСЭЮ аРббЬЮваХЭЭЮЩ ТлиХ). НвЮ ЮЧЭРзРХв, звЮ дРЧР B ЭР аШб. 7.1 ЯаЮЯгбЪРХвбп, ШЭвХаЯЮЫпжШп ЯХаХЬХЭЭле ЭХ ТлЯЮЫЭпХвбп, Р ЪЮЭбвагЪжШШ, ЯХаХзШбЫХЭЭлХ Т вРСЫ. 7.8, ЭХ ЮСаРСРвлТРовбп. ВРЪРп ТЮЧЬЮЦЭЮбвм СлТРХв ЯЮЫХЧЭЮЩ Т ТлаРЦХЭШпе б СЮЫмиШЬ ЪЮЫШзХбвТЮЬ бШЬТЮЫЮТ $ Ш @, нЪаРЭШаЮТРЭШХ ЪЮвЮале ЯаШТХФХв Ъ заХЧЬХаЭЮ УаЮЬЮЧФЪЮЬг аХЧгЫмвРвг.
l µбЫШ Т ЪРзХбвТХ ЮУаРЭШзШвХЫХЩ ШбЯЮЫмЧговбп ТЮЯаЮбШвХЫмЭлХ ЧЭРЪШ<$M[R7-78]> [9 б.<$R[P#,R7-77]>], ТлЯЮЫЭпХвбп ТХбмЬР бЯХжШдШзХбЪРп аРЧЭЮТШФЭЮбвм ЯЮШбЪР. ѕСлзЭЮ ЮЯХаРвЮа ЯЮШбЪР ТЮЧТаРйРХв ЯаШЧЭРЪ гбЯХиЭЮУЮ бЮТЯРФХЭШп ЯаШ ЪРЦФЮЬ бЮТЯРФХЭШШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп-ЮЯХаРЭФР Т жХЫХТЮЩ бваЮЪХ, ЭЮ ХбЫШ ЮУаРЭШзШвХЫпЬШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп пТЫповбп бШЬТЮЫл ?, вЮ ЯаШЧЭРЪ гбЯХеР ТЮЧТаРйРХвбп вЮЫмЪЮ ФЫп ЯХаТЮУЮ бЮТЯРФХЭШп. ІбХ ЯЮбЫХФгойШХ ЭРЩФХЭЭлХ бЮТЯРФХЭШп бзШвРовбп ЭХгФРзЭлЬШ, Ш нвЮ ЯаЮФЮЫЦРХвбп ФЮ ТлЧЮТР дгЭЪжШШ reset Т вХЪгйХЬ ЯРЪХвХ<$M[R7-80]> [10 б.<$R[P#,R7-79]>].
НвР ТЮЧЬЮЦЭЮбвм ЬЮЦХв ШбЯЮЫмЧЮТРвмбп Т бШвгРжШШ, ХбЫШ гбЯХиЭЮХ бЮТЯРФХЭШХ ФЮЫЦЭЮ Слвм ЭРЩФХЭЮ вЮЫмЪЮ ЮФШЭ аРЧ ЭР ЯаЮвпЦХЭШШ аРСЮвл жШЪЫР. ЅРЯаШЬХа, ЯаШ ЮСаРСЮвЪХ ЧРУЮЫЮТЪР бЮЮСйХЭШп нЫХЪваЮЭЭЮЩ ЯЮзвл ЬЮЦЭЮ ШбЯЮЫмЧЮТРвм ЪЮЬРЭФг:
$subject = $1 if m?^Subject: (.*)?;
їЮбЫХ вЮУЮ, ЪРЪ бваЮЪР вХЬл СгФХв ЭРЩФХЭР, ЭХв бЬлбЫР ШбЪРвм ХХ ТЮ ТбХе ЯЮбЫХФгойШе бваЮЪРе. ЅЮ ХбЫШ ЯЮ ЪРЪЮЩ-вЮ ЯаШзШЭХ Т ЧРУЮЫЮТЪХ ЮЪРЦХвбп ЭХбЪЮЫмЪЮ бваЮЪ Subject:, ЪЮЭбвагЪжШп m?…? бЮТЯРФХв вЮЫмЪЮ б ЯХаТЮЩ ШЧ ЭШе, Р m/…/ бЮТЯРФХв бЮ ТбХЬШ. їЮбЫХ ЧРТХаиХЭШп ЮСаРСЮвЪШ ЧРУЮЫЮТЪР m?…? ЮбвРТШв Т ЯХаХЬХЭЭЮЩ $subject ФРЭЭлХ ШЧ ЯХаТЮЩ, Р m/…/ — ШЧ ЯЮбЫХФЭХЩ бваЮЪШ Subject:.
Г ЮЯХаРвЮаР ЯЮФбвРЭЮТЪШ s/…/…/ вРЪЦХ ШЬХовбп бЯХжШРЫмЭлХ ЮУаРЭШзШвХЫШ, ЪЮвЮалХ СгФгв аРббЬЮваХЭл ЭШЦХ (б. <$R[P#,R7-81]>); ЯХаХзШбЫХЭЭлХ ТлиХ ЮбЮСлХ бЫгзРШ ЮвЭЮбпвбп вЮЫмЪЮ Ъ ЮЯХаРвЮаг ЯЮШбЪР.
ІЯаЮзХЬ, бвЮШв гЯЮЬпЭгвм ХйХ ЮФШЭ ЮбЮСлЩ бЫгзРЩ: ХбЫШ Т ЪРзХбвТХ ЮУаРЭШзШвХЫп ШбЯЮЫмЧгХвбп ЫШСЮ бвРЭФРавЭлЩ бШЬТЮЫ /, ЫШСЮ бШЬТЮЫ ЮФЭЮЪаРвЭЮУЮ бЮТЯРФХЭШп ?, бРЬР СгЪТР m бвРЭЮТШвбп ЭХЮСпЧРвХЫмЭЮЩ. ґЫп ЯЮШбЪР бЮТЯРФХЭШЩ зРбвЮ ШбЯЮЫмЧгХвбп ЪЮЭбвагЪжШп /…/.
ЅРЪЮЭХж, Т Perl ЯЮФФХаЦШТРХвбп ЮСЮСйХЭЭлЩ иРСЫЮЭ жХЫХТЮЩ_вХЪбв =~ ТлаРЦХЭШХ (СХЧ ЮУаРЭШзШвХЫХЩ Ш СХЧ m). ІлаРЦХЭШХ ТлзШбЫпХвбп ЪРЪ ЮСйХХ ТлаРЦХЭШХ Perl, ШЭвХаЯаХвШагХвбп ЪРЪ бваЮЪР Ш ЯХаХФРХвбп ЬХеРЭШЧЬг аХУгЫпаЭле ТлаРЦХЭШЩ. НвЮ ЯЮЧТЮЫпХв ШбЯЮЫмЧЮТРвм ЪЮЬРЭФл ТШФР $text =~ &GetRegex() ТЬХбвЮ СЮЫХХ ФЫШЭЭле:
my $temp_regex = &GetRegex();
...$text =~ m/$temp_regex/...
єаЮЬХ вЮУЮ, ЪЮЬРЭФР $text =~ "…бваЮЪР…" ЬЮЦХв ЯаШУЮФШвмбп Т вЮЬ бЫгзРХ, ХбЫШ Тл еЮвШвХ ТлЯЮЫЭШвм ЯЮЫЭЮжХЭЭго ЮСаРСЮвЪг ЯЮ ЯаРТШЫРЬ бваЮЪ, ЧРЪЫозХЭЭле Т ЪРТлзЪШ, ТЬХбвЮ ХХ ШЬШвРжШШ — ЯаХФТРаШвХЫмЭЮЩ ЮСаРСЮвЪШ, Ю ЪЮвЮаЮЩ УЮТЮаШЫЮбм ТлиХ. ІЯаЮзХЬ, ЯЮФЮСЭлХ дШЭвл ЫгзиХ ЮбвРТШвм ФЫп ЪЮЭЪгабЮТ ЭР БРЬго ·РУРФЮзЭго їаЮУаРЬЬг ЭР Perl.
<$M[R7-86]>µбЫШ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЭХ ЧРФРЭЮ (ЭРЯаШЬХа, m// ШЫШ m/$regex/, УФХ ЯХаХЬХЭЭРп $regex бЮФХаЦШв Ягбвго бваЮЪг ШЫШ ШЬХХв ЭХЮЯаХФХЫХЭЭЮХ ЧЭРзХЭШХ), Perl ЧРЭЮТЮ ШбЯЮЫмЧгХв ЯЮбЫХФЭХХ гбЯХиЭЮ ШбЯЮЫмЧЮТРЭЭЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ ТЮ ТЭХиЭХЩ ФШЭРЬШзХбЪЮЩ ЮСЫРбвШ ТШФШЬЮбвШ<$M[R7-83]> [11 б.<$R[P#,R7-82]>]. І нвЮЬ бЫгзРХ ЫоСлХ ЬЮФШдШЪРвЮал ЯЮШбЪР (бЬ. бЫХФгойШЩ аРЧФХЫ), ФРЦХ /g Ш /i, ЯЮЫЭЮбвмо ШУЭЮаШаговбп. јЮФШдШЪРвЮал, ШбЯЮЫмЧЮТРЭЭлХ Т ТлаРЦХЭШШ ЯЮ гЬЮЫзРЭШо, ЮбвРовбп Т бШЫХ.
АХУгЫпаЭЮХ ТлаРЦХЭШХ, ШбЯЮЫмЧгХЬЮХ ЯЮ гЬЮЫзРЭШо, ЭШЪЮУФР ЭХ ЪЮЬЯШЫШагХвбп ЧРЭЮТЮ (ФРЦХ ХбЫШ ЮаШУШЭРЫ СлЫ ЯЮбваЮХЭ б ШЭвХаЯЮЫпжШХЩ ЯХаХЬХЭЭЮЩ СХЧ ЬЮФШдШЪРвЮаР /o). НвШЬ ЮСбвЮпвХЫмбвТЮЬ ЬЮЦЭЮ ТЮбЯЮЫмЧЮТРвмбп ФЫп бЮЧФРЭШп нддХЪвШТЭле вХбвЮТ. їаШЬХа ЯаШТХФХЭ Т аРЧФХЫХ «јЮФШдШЪРвЮа /o Ш eval» (б. <$R[P#,R7-84]>).
ѕЯХаРвЮа ЯЮШбЪР ЯЮФФХаЦШТРХв апФ<$R[P#,R7-33]> ЬЮФШдШЪРвЮаЮТ (ЯРаРЬХваЮТ), ТЫШпойШе ЭР:
l ШЭвХаЯаХвРжШо аХУгЫпаЭЮУЮ ТлаРЦХЭШп-ЮЯХаРЭФР (/o б. <$R[P#,R7-85]>; /x б. <$R[P#,R7-22]>);
l ШЭвХаЯаХвРжШо жХЫХТЮУЮ вХЪбвР ЬХеРЭШЧЬЮЬ аХУгЫпаЭле ТлаРЦХЭШЩ (/i б. <$R[P#,R2-9]>; /m, /s б. <$R[P#,R7-51]>);
l бЯЮбЮС ЯаШЬХЭХЭШп аХУгЫпаЭЮУЮ ТлаРЦХЭШп ЬХеРЭШЧЬЮЬ (/g б. <$R[P#,R7-64]>).
јЮФШдШЪРвЮал ЬЮЦЭЮ УагЯЯШаЮТРвм Ш аРбЯЮЫРУРвм Ше ЯЮбЫХ ЧРЪалТРойХУЮ ЮУаРЭШзШвХЫп[41] Т ЯаЮШЧТЮЫмЭЮЬ ЯЮапФЪХ. ЅРЯаШЬХа, ЪЮЬРЭФР m/<code>/i ЯаШЬХЭпХв аХУгЫпаЭЮХ ТлаРЦХЭШХ [<code>] б ЬЮФШдШЪРвЮаЮЬ /i, ЮСХбЯХзШТРп ЯЮШбЪ СХЧ гзХвР аХУШбваР. БЫХФгХв ЯЮЬЭШвм, звЮ бШЬТЮЫ / ЭХ пТЫпХвбп зРбвмо ЬЮФШдШЪРвЮаР — ЪЮЬРЭФг ЬЮЦЭЮ ЧРЯШбРвм Т ТШФХ m|<code>|i, m{<code>}i Ш ФРЦХ m<<code>>i. єРЪ СлЫЮ бЪРЧРЭЮ ТлиХ (б. <$R[P#,R7-23]>), ЬЮФШдШЪРвЮал /x, /i, /m Ш /s вРЪЦХ ЬЮУгв ЯаШбгвбвТЮТРвм Ш Т бРЬЮЬ аХУгЫпаЭЮЬ ТлаРЦХЭШШ ЯаШ ЯЮЬЮйШ ЪЮЭбвагЪжШШ [(?…)]. ЅХЯЮбаХФбвТХЭЭЮХ ТЪЫозХЭШХ нвШе ЬЮФШдШЪРвЮаЮТ Т аХУгЫпаЭЮХ ТлаРЦХЭШХ ШбЪЫозШвХЫмЭЮ гФЮСЭЮ Т вХе бЫгзРпе, ЪЮУФР ЮФЭШ ЮЯХаРвЮа Т аРЧЭЮХ ТаХЬп ШбЯЮЫмЧгХв аРЧЭлХ ТлаРЦХЭШп (ЮСлзЭЮ ТбЫХФбвТШХ ШЭвХаЯЮЫпжШШ ЯХаХЬХЭЭле). ЅРЯаШЬХа, ЯаШ ШбЯЮЫмЧЮТРЭШШ ЬЮФШдШЪРвЮаР /i, ЪРЦФЮХ ЯаШЬХЭХЭШХ ТлаРЦХЭШп ФРЭЭлЬ ЮЯХаРвЮаЮЬ СгФХв ЮбгйХбвТЫпвмбп СХЧ гзХвР аХУШбваР бШЬТЮЫЮТ. ІлСШаРп ЬЮФШдШЪРвЮал ЭР гаЮТЭХ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, Тл ЯЮЫгзРХвХ СЮЫХХ гЭШТХабРЫмЭлЩ ЯаЮУаРЬЬЭлЩ ЪЮФ.
їаХЪаРбЭлЬ ЯаШЬХаЮЬ пТЫпХвбп ЯЮШбЪЮТлЩ ЬХеРЭШЧЬ ЭР Web-бваРЭШжХ, ЮСХбЯХзШТРойШЩ ЯЮЫЭЮжХЭЭго ЯЮФФХаЦЪг аХУгЫпаЭле ТлаРЦХЭШЩ Perl. ±ЮЫмиШЭбвТЮ ЯЮШбЪЮТле ЬХеРЭШЧЬЮТ ЯЮФФХаЦШТРХв ЮзХЭм ЯаЮбвлХ бЯХжШдШЪРжШШ ЯЮШбЪР, ЭХ гФЮТЫХвТЮапойШХ ЮЯлвЭле ЯЮЫмЧЮТРвХЫХЩ, ЯЮнвЮЬг ЯЮФФХаЦЪР аХУгЫпаЭле ТлаРЦХЭШЩ ЬЭЮУШЬ ЯаШФХвбп ЯЮ ТЪгбг. І нвЮЬ бЫгзРХ ЯЮЫмЧЮТРвХЫм ЬЮЦХв ТЪЫозРвм Т бТЮШ ТлаРЦХЭШп [(?i)] Ш ФагУШХ ЪЮЭбвагЪжШШ, Ш Т бжХЭРаШпе CGI ЭХ ЯаШФХвбп ЯаХФгбЬРваШТРвм бЯХжШРЫмЭлХ ЯРаРЬХвал ФЫп РЪвШТШЧРжШШ нвШе ЬЮФШдШЪРвЮаЮТ.
ѕСлзЭЮ ЯЮШбЪ бЫХФгойХУЮ бЮТЯРФХЭШп аХУгЫпаЭЮУЮ ТлаРЦХЭШп б ЬЮФШдШЪРвЮаЮЬ /g ЭРзШЭРХвбп б вЮЩ ЯЮЧШжШШ, Т ЪЮвЮаЮЩ ЧРТХаиШЫЮбм ЯаХФлФгйХХ бЮТЯРФХЭШХ. ЅЮ звЮ ЯаЮШЧЮЩФХв, ХбЫШ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЬЮЦХв бЮТЯРбвм б ЯгбвЮЩ бваЮЪЮЩ<$M[R7-109]>? АРббЬЮваШЬ ЯаЮбвЮЩ ЯаШЬХа — ЮвЪаЮТХЭЭЮ УЫгЯго ЪЮЬРЭФг m/^/g. ѕЭР бЮТЯРФРХв Т ЭРзРЫХ бваЮЪШ, ЭЮ бШЬТЮЫЮТ ЭХ ЯЮУЫЮйРХв, ЯЮнвЮЬг ЯХаТЮХ бЮТЯРФХЭШХ ЧРТХаиРХвбп Т ЭРзРЫХ бваЮЪШ. µбЫШ бЫХФгойРп ЯЮЯлвЪР ЭРзЭХвбп Т нвЮЩ ЦХ ЯЮЧШжШШ, бЮТЯРФХЭШХ СгФХв ЭРЩФХЭЮ Т вЮЬ ЦХ ЬХбвХ. ё вРЪ ФРЫХХ ФЮ СХбЪЮЭХзЭЮбвШ.
Perl ТХабШШ 5.000 Т вРЪЮЩ бШвгРжШШ ФХЩбвТШвХЫмЭЮ ЧРжШЪЫШТРХвбп, ЭЮ Perl4 Ш СЮЫХХ ЯЮЧФЭШХ ТХабШШ Perl5 аРСЮвРов ШЭРзХ. БЮТЯРФХЭШХ Т ЭШе ЭРзШЭРХвбп Т вЮЩ ЯЮЧШжШШ, УФХ ЧРТХаиШЫЮбм ЯаХФлФгйХХ бЮТЯРФХЭШХ — ХбЫШ вЮЫмЪЮ ЯаХФлФгйХХ бЮТЯРФХЭШХ ЭХ бЮТЯРЫЮ б ЯгбвЮЩ бваЮЪЮЩ; Т нвЮЬ бЫгзРХ<$M[R7-87]> ЯаЮШЧТЮФШвбп ЮбЮСЮХ бЬХйХЭШХ вХЪгйХЩ ЯЮЧШжШШ, Ш ЯЮШбЪ ТЮЧЮСЭЮТЫпХвбп бЮ бФТШУЮЬ ЭР ЮФШЭ бШЬТЮЫ. ВРЪШЬ ЮСаРЧЮЬ, ЪРЦФЮХ бЮТЯРФХЭШХ ЯЮбЫХ ЯХаТЮУЮ ЧРТХФЮЬЮ бЬХйРХвбп Т бваЮЪХ еЮвп Сл ЭР ЮФШЭ бШЬТЮЫ, звЮ ЯаХФЮвТаРйРХв ЧРжШЪЫШТРЭШХ.
µбЫШ аХзм ШФХв ЭХ ЮС ЮЯХаРвЮаХ ЯЮФбвРЭЮТЪШ, Perl5 ФХЫРХв ХйХ ЮФШЭ иРУ Ш ШбЪЫозРХв бЮТЯРФХЭШп, ЧРЪРЭзШТРойШХбп Т ЮФЭЮЩ ЯЮЧШжШШ б ЯаХФлФгйШЬ бЮТЯРФХЭШХЬ — Т нвЮЬ бЫгзРХ ТлЯЮЫЭпХвбп РТвЮЬРвШзХбЪШЩ бФТШУ ЭР ЮФШЭ бШЬТЮЫ (ХбЫШ ЯаЮТХапХЬРп ЯЮЧШжШп ЭХ ЭРеЮФШвбп Т ЪЮЭжХ бваЮЪШ). НвЮ ЮвЫШзШХ Юв Perl4 ЬЮЦХв ЮЪРЧРвмбп бгйХбвТХЭЭлЬ — Т вРСЫ. 7.9 ЯаШТХФХЭЮ ЭХбЪЮЫмЪЮ ЯаЮбвле ЯаШЬХаЮТ (нвР вРСЫШжР ЭШ Т ЪЮХЬ бЫгзРХ ЭХ пТЫпХвбп «ЫХУЪШЬ звШТЮЬ» — ТЮЧЬЮЦЭЮ, Тл ЭХ баРЧг аРЧСХаХвХбм Т ЭХЩ). Б ЮЯХаРвЮаЮЬ ЯЮФбвРЭЮТЪШ бШвгРжШп ТлУЫпФШв ШЭРзХ, ЭЮ нвР вХЬР СгФХв аРббЬЮваХЭР Т аРЧФХЫХ «ѕЯХаРвЮа ЯЮФбвРЭЮТЪШ» (б. <$R[P#,R7-12]>)<$M[R7-106]>.
ВРСЫШжР 7.9. їаШЬХал ШбЯЮЫмЧЮТРЭШп m/…/g б аХУгЫпаЭлЬ ТлаРЦХЭШХЬ, ЪЮвЮаЮХ ЬЮЦХв бЮТЯРФРвм б вХЪбвЮЬ ЭгЫХТЮЩ иШаШЭл
БЬ. аРбиШдаЮТЪг Т дРЩЫХ pict!
є бзРбвмо, ТвЮаЮЩ ЮЯХаРЭФ (жХЫХТЮЩ вХЪбв) ЧРФРХвбп ЯаЮйХ, зХЬ ЮЯХаРЭФ-ТлаРЦХЭШХ. ѕСлзЭЮ вХЪбв, Т ЪЮвЮаЮЬ ЮбгйХбвТЫпХвбп ЯЮШбЪ, ЧРФРХвбп ЮЯХаРвЮаЮЬ =~ — ЭРЯаШЬХа, $line =~ m/…/. ЅРЯЮЬШЭРо, звЮ =~ ЭХ пТЫпХвбп ЮЯХаРвЮаЮЬ ЯаШбТРШТРЭШп ШЫШ баРТЭХЭШп. НвЮ ТбХУЮ ЫШим ЭХЯаШТлзЭлЩ бЯЮбЮС ЯХаХФРзШ ЮЯХаРЭФР ЮЯХаРвЮаг ЯЮШбЪР (ЮСЮЧЭРзХЭШХ СлЫЮ ЯЮЧРШЬбвТЮТРЭЮ ШЧ awk).
їЮбЪЮЫмЪг Тбп ЪЮЭбвагЪжШп ТлаРЦХЭШХ =~ m/…/ пТЫпХвбп ТлаРЦХЭШХЬ, ХХ ЬЮЦЭЮ ШбЯЮЫмЧЮТРвм ТХЧФХ, УФХ ФЮЯгбЪРХвбп ШбЯЮЫмЧЮТРЭШХ ТлаРЦХЭШЩ. АРббЬЮваШЬ ЭХбЪЮЫмЪЮ ЯаШЬХаЮТ:
$text =~ m/…/; # їаЮбвЮ ТлЯЮЫЭШвм - ТЮЧЬЮЦЭЮ, аРФШ ЯЮСЮзЭле нддХЪвЮТ
- - - - - - - - - - - -
if ($text =~ m/…/) {
## ІлЯЮЫЭШвм ЭХЪЮвЮалХ ФХЩбвТШп Т бЫгзРХ гбЯХеР
.
.
.
- - - - - - - - - - - -
$result = ( $text =~ m/…/ ); # їаШбТЮШвм $result аХЧгЫмвРв ЯЮШбЪР Т $text
;result = ;text =! m.…. ; # ВЮ ЦХ бРЬЮХ. =~ ЮСЫРФРХв СЮЫХХ
# ТлбЮЪШЬ ЯаШЮаШвХвЮЬ, зХЬ =.
- - - - - - - - - - - -
$result = $text; # БЪЮЯШаЮТРвм $text Т $result...
$result =~ m/…/ ; # ...Ш ТлЯЮЫЭШвм ЯЮШбЪ Т $result
( $result = $text ) =~ m/…/ ; # ВЮ ЦХ Т ЮФЭЮЬ ТлаРЦХЭШШ
µбЫШ жХЫХТлЬ ЮЯХаРЭФЮЬ пТЫпХвбп ЯХаХЬХЭЭРп $_, вЮ ЪЮЭбвагЪжШо $_ =~ ЬЮЦЭЮ ЯЮЫЭЮбвмо ШбЪЫозШвм. ґагУШЬШ бЫЮТРЬШ, $_ пТЫпХвбп ЮЯХаРЭФЮЬ жХЫХТЮУЮ вХЪбвР ЯЮ гЬЮЫзРЭШо.
єЮЭбвагЪжШп ТШФР $line =~ m/ТлаРЦХЭШХ/ ЮЧЭРзРХв «ЯаШЬХЭШвм аХУгЫпаЭЮХ ТлаРЦХЭШХ Ъ вХЪбвг Т $line; ТЮЧТаРйРХЬЮХ ЧЭРзХЭШХ ШУЭЮаШагХвбп, ЭЮ ЯЮСЮзЭлХ нддХЪвл ФХЩбвТгов». µбЫШ Тл ЧРСгФХвХ Ю бШЬТЮЫХ ~, вЮ ЯЮЫгзХЭЭРп бваЮЪР $line = m/ТлаРЦХЭШХ/ СгФХв ЮЧЭРзРвм «ЯаШЬХЭШвм ТлаРЦХЭШХ Ъ вХЪбвг Т $_; ЧРвХЬ ЯаШбТЮШвм ТЮЧТаРйРХЬЮХ ЫЮУШзХбЪЮХ ЧЭРзХЭШХ ЯХаХЬХЭЭЮЩ $line». ґагУШЬШ бЫЮТРЬШ, бЫХФгойШХ ФТХ ЪЮЬРЭФл нЪТШТРЫХЭвЭл:
$line = m/ТлаРЦХЭШХ/
$line = ($_ =~ m/ТлаРЦХЭШХ/)
Іл вРЪЦХ ЬЮЦХвХ ШбЯЮЫмЧЮТРвм ТЬХбвЮ =~ ЮЯХаРвЮа !~, звЮСл ЫЮУШзХбЪШ ШЭТХавШаЮТРвм ТЮЧТаРйРХЬЮХ ЧЭРзХЭШХ (ТЮЧТаРйРХЬлХ ЧЭРзХЭШп Ш ЯЮСЮзЭлХ нддХЪвл аРббЬРваШТРовбп Т бЫХФгойШе аРЧФХЫРе). єЮЬРЭФР $var !~ m/…/ дРЪвШзХбЪШ нЪТШТРЫХЭвЭР not ($var =~ m/…/). їаШ нвЮЬ ФХЩбвТгов ТбХ бвРЭФРавЭлХ ЯЮСЮзЭлХ нддХЪвл ТаЮФХ ЯаШбТРШТРЭШп ЯХаХЬХЭЭЮЩ $1. ВРЪШЬ ЮСаРЧЮЬ, нвЮ ТбХУЮ ЫШим гФЮСЭЮХ ЮСЮЧЭРзХЭШХ, ЯаХФЭРЧЭРзХЭЭЮХ ФЫп бШвгРжШЩ вШЯР «µбЫШ бЮТЯРФХЭШХ ЮвбгвбвТгХв…». ЕЮвп ФЮЯгбЪРХвбп ШбЯЮЫмЧЮТРЭШХ !~ Т бЯШбЪЮТЮЬ ЪЮЭвХЪбвХ, ЮбЮСЮУЮ бЬлбЫР Т нвЮЬ ЭХв.
ґЮТЮЫмЭЮ зРбвЮ ТРб ШЭвХаХбгХв ЭХ бвЮЫмЪЮ ЧЭРзХЭШХ, ТЮЧТаРйРХЬЮХ Т аХЧгЫмвРвХ ЯЮШбЪР, бЪЮЫмЪЮ бЮЯаЮТЮЦФРойШХ ХУЮ ЯЮСЮзЭлХ нддХЪвл. ±ЮЫХХ вЮУЮ, ЯаШ ТлЧЮТХ ЮЯХаРвЮаР ЯЮШбЪР ТЮЧТаРйРХЬЮХ ЧЭРзХЭШХ ЭХаХФЪЮ ТЮЮСйХ ШУЭЮаШагХвбп (ЯЮ гЬЮЫзРЭШо ШбЯЮЫмЧгХвбп бЪРЫпаЭлЩ ЪЮЭвХЪбв). јл гЦХ аРббЬЮваХЫШ СЮЫмиШЭбвТЮ ЯЮСЮзЭле нддХЪвЮТ ($&, $1, $+ Ш в. Ф.; бЬ. б. <$R[P#,R7-34]>), ЯЮнвЮЬг Т нвЮЬ аРЧФХЫХ СгФгв ЮЯШбРЭл ЮбвРЫмЭлХ ЯЮСЮзЭлХ нддХЪвл, бЮЯаЮТЮЦФРойШХ ЯЮЯлвЪШ ЯЮШбЪР бЮТЯРФХЭШЩ.
ґТР вРЪШе нддХЪвР ЯаШТЮФпв Ъ бЮеаРЭХЭШо «ЭХТШФШЬЮУЮ бвРвгбР». ІЮ-ЯХаТле, ХбЫШ ЯЮШбЪ ЮбгйХбвТЫпХвбп ЪЮЭбвагЪжШХЩ m?…?, вЮ гбЯХиЭЮХ бЮТЯРФХЭШХ ЮСаХЪРХв ТбХ СгФгйШХ бЮТЯРФХЭШп ЭР ЭХгФРзг, ЯЮ ЪаРЩЭХЩ ЬХаХ ФЮ СЫШЦРЩиХУЮ ТлЧЮТР reset (б. <$R[P#,R7-80]>). єЮЭХзЭЮ, ЯаШ ШбЯЮЫмЧЮТРЭШШ m?…? ШЬХЭЭЮ нвЮв ЯЮСЮзЭлЩ нддХЪв ЮЪРЧлТРХвбп ЭРШСЮЫХХ ТРЦЭлЬ. ІЮ-ТвЮале, ЧРФРЭЭЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ ШбЯЮЫмЧгХвбп ЯЮ гЬЮЫзРЭШо ТЯЫЮвм ФЮ ТлеЮФР ШЧ ФШЭРЬШзХбЪЮЩ ЮСЫРбвШ ТШФШЬЮбвШ ШЫШ гбЯХиЭЮУЮ бЮТЯРФХЭШп ФагУЮУЮ аХУгЫпаЭЮУЮ ТлаРЦХЭШп (б. <$R[P#,R7-86]>).
ґЫп бЮТЯРФХЭШЩ б ЬЮФШдШЪРвЮаЮЬ /g ФРЭЭлХ pos ФЫп жХЫХТЮЩ бваЮЪШ ЮСЭЮТЫповбп Т бЮЮвТХвбвТШШ б ЪЮЭХзЭЮЩ ЯЮЧШжШХЩ вХЪгйХУЮ бЮТЯРФХЭШп (Р ЭХгФРзЭРп ЯЮЯлвЪР ТбХУФР ЯаШТЮФШв Ъ бСаЮбг pos). БЫХФгойРп ЯЮЯлвЪР ЯЮШбЪР ЯЮФ гЯаРТЫХЭШХЬ /g ЭРзЭХвбп Т вЮЩ ЦХ ЯЮЧШжШШ, ХбЫШ:
l бваЮЪР ЭХ СлЫР ЬЮФШдШжШаЮТРЭР (ЬЮФШдШЪРжШп бваЮЪШ ЯаШТЮФШв Ъ бСаЮбг pos);
l pos ЭХ СлЫЮ ЯаШбТЮХЭЮ ЧЭРзХЭШХ (ЯЮШбЪ ЭРзЭХвбп б ЧРФРЭЭЮЩ ЯЮЧШжШШ);
l ЯаХФлФгйХХ бЮТЯРФХЭШХ бЮбвЮШв еЮвп Сл ШЧ ЮФЭЮУЮ бШЬТЮЫР.
єРЪ гЯЮЬШЭРЫЮбм ТлиХ (б. <$R[P#,R7-87]>), ФЫп ЯаХФЮвТаРйХЭШп ЧРжШЪЫШТРЭШп ЯаШ гбЯХиЭЮЬ ЮСЭРагЦХЭШШ бЮТЯРФХЭШп ЭгЫХТЮЩ иШаШЭл ЯЮШбЪ бЫХФгойХУЮ бЮТЯРФХЭШп ЭРзШЭРХвбп бЮ бФТШУЮЬ Т ЮФШЭ бШЬТЮЫ. І ЯаЮжХббХ ЯЮШбЪР ЯЮбЫХ бФТШУР pos, ЪРЪ Ш ФЮЫЦЭЮ Слвм, бЮЮвТХвбвТгХв ЪЮЭХзЭЮЩ ЯЮЧШжШШ ЯаХФлФгйХУЮ бЮТЯРФХЭШп, ЯЮбЪЮЫмЪг ФЫп ЯаХФЮвТаРйХЭШп ЧРжШЪЫШТРЭШп бФТШУРХвбп ЭРзРЫмЭРп ЯЮЧШжШп бЫХФгойХЩ ЯЮЯлвЪШ. їаШ нвЮЬ [\G] ЯаЮФЮЫЦРХв бблЫРвмбп ЭР ЪЮЭХж ЯаХФлФгйХУЮ бЮТЯРФХЭШп (нвЮ ХФШЭбвТХЭЭРп бШвгРжШп, ЯаШ ЪЮвЮаЮЩ \G ЭХ ЮЧЭРзРХв «ЭРзРЫЮ вХЪгйХЩ ЯЮЯлвЪШ»).
ѕЯХаРвЮа ЯЮШбЪР ЭХ ЮУаРЭШзШТРХвбп ТЮЧТаРвЮЬ ЯаЮбвЮЩ ЫЮУШзХбЪЮЩ ТХЫШзШЭл Ш ЬЮЦХв ТЮЧТаРйРвм аРЧЭЮЮСаРЧЭго ШЭдЮаЬРжШо (ТЯаЮзХЬ, ЯаШ ЦХЫРЭШШ Тл ЬЮЦХвХ ЯЮЫгзШвм Ш ЯаЮбвго ЫЮУШзХбЪго ТХЫШзШЭг). ВЮзЭлЩ бЮбвРТ ШЭдЮаЬРжШШ Ш бЯЮбЮС ХХ ТЮЧТаРйХЭШп ЧРТШбпв Юв ФТге ЮбЭЮТЭле дРЪвЮаЮТ: ЪЮЭвХЪбвР Ш ЭРЫШзШп ЬЮФШдШЪРвЮаР /g.
БРЬлЩ ЮСлзЭлЩ бЫгзРЩ ЯЮШбЪР — бЪРЫпаЭлЩ ЪЮЭвХЪбв СХЧ ЬЮФШдШЪРвЮаР /g. µбЫШ бЮТЯРФХЭШХ ЭРЩФХЭЮ, ЮЯХаРвЮа ТЮЧТаРйРХв ЫЮУШзХбЪго ТХЫШзШЭг:
if ($target =~ m/…/) {
# ґХЩбвТШп ФЫп ЭРЩФХЭЭЮУЮ бЮТЯРФХЭШп
…
} else {
# ґХЩбвТШп ФЫп ЮвбгвбвТШп бЮТЯРФХЭШЩ
…
}
І бЫгзРХ ЭХгФРзШ ТЮЧТаРйРХвбп ЯгбвРп бваЮЪР (ШЭвХаЯаХвШагХЬРп ЪРЪ ЫЮУШзХбЪЮХ ЫЮЦЭЮХ ЧЭРзХЭШХ).
БЯШбЪЮТлЩ ЪЮЭвХЪбв СХЧ /g — аРбЯаЮбваРЭХЭЭлЩ бЯЮбЮС ШЧТЫХзХЭШп ШЭдЮаЬРжШШ ШЧ бваЮЪШ. ІЮЧТаРйРХЬЮХ ЧЭРзХЭШХ ЯаХФбвРТЫпХв бЮСЮЩ бЯШбЮЪ, ЪРЦФлЩ нЫХЬХЭв ЪЮвЮаЮУЮ бЮЮвТХвбвТгХв ЯРаХ бЮеаРЭпойШе ЪагУЫле бЪЮСЮЪ Т аХУгЫпаЭле ТлаРЦХЭШпе. їаЮбвХЩиШЬ ЯаШЬХаЮЬ пТЫпХвбп ЮСаРСЮвЪР ФРвл Т дЮаЬРвХ 69/8/31:
($year, $month, $day) = $date =~ m{^ (\d+) / (\d+) / (\d+) $}x;
їЮбЫХ ТлЯЮЫЭХЭШп нвЮЩ ЪЮЬРЭФл ваШ бЮТЯРТиШе зШбЫР СгФгв ЯаШбТЮХЭл ваХЬ ЯХаХЬХЭЭлЬ (Р вРЪЦХ ЯХаХЬХЭЭлЬ $1 Ш в. Ф.)<$M[R7-89]> [12 б.<$R[P#,R7-88]>]. єРЦФЮЩ ЯРаХ бЮеаРЭпойШе ЪагУЫле бЪЮСЮЪ Т ТЮЧТаРйРХЬЮЬ бЯШбЪХ бЮЮвТХвбвТгХв ЮФШЭ нЫХЬХЭв; Т бЫгзРХ ЭХгФРзШ ТЮЧТаРйРХвбп ЯгбвЮЩ бЯШбЮЪ. єЮЭХзЭЮ, ЭХЪЮвЮалХ ЯРал ЬЮУгв ЭХ ТеЮФШвм Т бЮТЯРФХЭШХ, ЪРЪ Т ЪЮЬРЭФХ m/(this)|(that)/. НЫХЬХЭвл бЯШбЪР ФЫп вРЪШе ЯРа бгйХбвТгов, ЭЮ ШЬХов ЭХЮЯаХФХЫХЭЭЮХ ЧЭРзХЭШХ<$M[R7-91]> [13 б.<$R[P#,R7-90]>]. µбЫШ Т ТлаРЦХЭШШ ТЮЮСйХ ЮвбгвбвТгов бЮеаРЭпойШХ<$M[R7-56]> ЪагУЫлХ бЪЮСЪШ, гбЯХиЭлЩ ЯЮШбЪ Т бЯШбЪЮТЮЬ ЪЮЭвХЪбвХ СХЧ ЬЮФШдШЪРвЮаР /g ТЮЧТаРйРХв бЯШбЮЪ (1).
ґРТРЩвХ гбЮТХаиХЭбвТгХЬ ЯаШЬХа б РЭРЫШЧЮЬ ФРвл Ш ТЮбЯЮЫмЧгХЬбп ЮЯХаРвЮаЮЬ ЯЮШбЪР Т гбЫЮТШШ ЪЮЬРЭФл if(…). ёЧ-ЧР ЯаШбТРШТРЭШп ЪЮЭбвагЪжШШ ($year,…) ЮЯХаРвЮа ЯЮШбЪР аРСЮвРХв Т бЯШбЪЮТЮЬ ЪЮЭвХЪбвХ Ш ЯаШбТРШТРХв ЧЭРзХЭШп ЧРФРЭЭлЬ ЯХаХЬХЭЭлЬ. ЅЮ ЯЮбЪЮЫмЪг Т гбЫЮТШШ if(…) ТбХ ТлаРЦХЭШХ ЯаШбТРШТРЭШп ШбЯЮЫмЧгХвбп Т бЪРЫпаЭЮЬ ЪЮЭвХЪбвХ, аХЧгЫмвРв ЯаХЮСаРЧгХвбп Т ЪЮЫШзХбвТЮ нЫХЬХЭвЮТ Т бЯШбЪХ. Г ЭРб ЯЮпТЫпХвбп гФЮСЭРп ТЮЧЬЮЦЭЮбвм ШЭвХаЯаХвШаЮТРвм ХУЮ ЪРЪ ЫЮУШзХбЪго ЫЮЦм ЯаШ ЮвбгвбвТШШ бЮТЯРФХЭШШ ШЫШ ЫЮУШзХбЪго ШбвШЭг ЯаШ Ше ЭРЫШзШШ.
if ( ($year, $month, $day) = $date =~ m{^ (\d+) / (\d+) / (\d+) $}x ) {
# ІлЯЮЫЭШвм ФХЩбвТШп ФЫп ЭРЩФХЭЭЮУЮ бЮТЯРФХЭШп;
# ЯХаХЬХЭЭлХ $year Ш в. Ф. ШЬХов ЭЮТлХ ЧЭРзХЭШп.
} else {
# ІлЯЮЫЭШвм ФХЩбвТШп ФЫп ЮвбгвбвТШп бЮТЯРФХЭШп;
# ЯХаХЬХЭЭлЬ $year Ш в. Ф. ЯаШбТРШТРХвбп ЭХЮЯаХФХЫХЭЭЮХ ЧЭРзХЭШХ.
};
<$M[R7-64]>НвР ЯЮЫХЧЭРп ЪЮЭбвагЪжШп, ТЯХаТлХ ЯЮпТШТиРпбп Т ТХабШШ 4.036, ТЮЧТаРйРХв бЯШбЮЪ ТбХУЮ вХЪбвР, бЮТЯРТиХУЮ б бЮеаРЭпойШЬШ ЪагУЫлЬШ бЪЮСЪРЬШ (ЯаШ ЮвбгвбвТШШ ЪагУЫле бЪЮСЮЪ — вХЪбвР, бЮТЯРТиХУЮ бЮ ТбХЬ ТлаРЦХЭШХЬ) ЭХ вЮЫмЪЮ ФЫп ЮФЭЮУЮ бЮТЯРФХЭШп, ЪРЪ Т бЯШбЪЮТЮЬ ЪЮЭвХЪбвХ СХЧ ЬЮФШдШЪРвЮаР /g, ЭЮ ФЫп ТбХе бЮТЯРФХЭШЩ Т бваЮЪХ. ґЫп ЯаШЬХаР аРббЬЮваШЬ ЮФЭг бваЮЪг б ЯЮЫЭлЬ вХЪбвЮЬ дРЩЫР ЯЮзвЮТле ЯбХТФЮЭШЬЮТ Unix Т дЮаЬРвХ
alias jeff jfriedl@ora.com
alias perlbug perl5-porters@perl.org
alias prez president@whitehouse
ґЫп ШЧТЫХзХЭШп ЯбХТФЮЭШЬЮТ Ш РФаХбЮТ ШЧ ЮФЭЮЩ ЫЮУШзХбЪЮЩ бваЮЪШ ЬЮЦЭЮ ТЮбЯЮЫмЧЮТРвмбп ЪЮЬРЭФЮЩ m/^alias\s+(\S+)\s+(.+)/. БЪРЦХЬ, ФЫп ЯХаТЮЩ бваЮЪШ ЪЮЬРЭФР ТХаЭХв бЯШбЮЪ ШЧ ФТге нЫХЬХЭвЮТ ('jeff', 'jfriedl@ora.com'). БЫХФгойШЬ иРУЮЬ СгФХв ЮСаРСЮвЪР ТбХе ЫЮУШзХбЪШе бваЮЪ Т ЮФЭЮЬ даРУЬХЭвХ. ґЫп ЭРеЮЦФХЭШп ТбХе бЮТЯРФХЭШЩ ЮФЭЮЩ ЪЮЬРЭФЮЩ ЬЮЦЭЮ ТЮбЯЮЫмЧЮТРвмбп ЬЮФШдШЪРвЮаЮЬ /g (Ш /m, звЮСл ЬХвРбШЬТЮЫ ^ ЬЮУ бЮТЯРФРвм б ЭРзРЫЮЬ ЫЮУШзХбЪШе бваЮЪ). єЮЬРЭФР ТЮЧТаРвШв бЯШбЮЪ
('jeff', 'jfriedl@ora.com', 'perlbug',
'perl5-porters@perl.org', 'prez', 'president@whitehouse' )
µбЫШ ТЮЧТаРйРХЬлХ нЫХЬХЭвл ЮСаРЧгов ЯРал «ЪЫоз/ЧЭРзХЭШХ», ЪРЪ Т ЯаШТХФХЭЭЮЬ ЯаШЬХаХ, аХЧгЫмвРв ЬЮЦЭЮ ЯаШбТЮШвм РббЮжШРвШТЭЮЬг ЬРббШТг (ениг). їЮбЫХ ТлЯЮЫЭХЭШп ЪЮЬРЭФл
%alias = $text =~ m/^alias\s+(\S+)\s+(.+)/mg;
Ъ ЯЮЫЭЮЬг РФаХбг jeff ЬЮЦЭЮ ЮСаРйРвмбп зХаХЧ нЫХЬХЭв ениР $alias{'jeff'}.
БЪРЫпаЭлЩ<$M[R7-66]> ЪЮЭвХЪбв б ЬЮФШдШЪРвЮаЮЬ /g ЯаХФбвРТЫпХв бЮСЮЩ бЯХжШРЫмЭго ЪЮЭбвагЪжШо, ЧРЬХвЭЮ ЮвЫШзРойгобп Юв ваХе ФагУШе бШвгРжШЩ. єРЪ Ш ЮСлзЭлЩ ЮЯХаРвЮа m/…/, ЮЭ ЭРеЮФШв вЮЫмЪЮ ЮФЭЮ бЮТЯРФХЭШХ, ЭЮ ЯЮ РЭРЫЮУШШ бЮ бЯШбЪЮТлЬ ЮЯХаРвЮаЮЬ m/…/g ЧРЯЮЬШЭРХв ЯЮЧШжШо ЯаХФлФгйХУЮ бЮТЯРФХЭШп. їаШ ЪРЦФЮЬ ТлЯЮЫЭХЭШШ m/…/g Т бЪРЫпаЭЮЬ ЪЮЭвХЪбвХ ЭРеЮФШвбп «бЫХФгойХХ» бЮТЯРФХЭШХ. єЮУФР ЮзХаХФЭЮЩ ЯЮШбЪ ЧРТХаиШвбп ЭХгФРзХЩ, бЫХФгойРп ЯаЮТХаЪР бЭЮТР ЭРзШЭРХвбп б ЭРзРЫР бваЮЪШ.
ВРЪго ЪЮЭбвагЪжШо гФЮСЭЮ ШбЯЮЫмЧЮТРвм Т гбЫЮТШШ жШЪЫР while. АРббЬЮваШЬ бЫХФгойШЩ даРУЬХЭв:
while ($ConfigData =~ m/^(\w+)=(.*)/mg) {
my($key, $value) = ($1, $2);
…
}
І жШЪЫХ СгФгв ЭРЩФХЭл ТбХ бЮТЯРФХЭШп, ЭЮ ЬХЦФг бЮТЯРФХЭШпЬШ (ТХаЭХХ, ЯЮбЫХ ЪРЦФЮУЮ бЮТЯРФХЭШп) СгФХв ТлЯЮЫЭпвмбп вХЫЮ жШЪЫР. їЮбЫХ вЮУЮ, ЪРЪ ЮзХаХФЭРп ЯЮЯлвЪР ЯЮШбЪР ЧРТХаиШвбп ЭХгФРзХЩ, аХЧгЫмвРв ЮЪРЦХвбп ЫЮЦЭлЬ, Ш жШЪЫ while ЧРТХаиШвбп. їЮбЫХ ЭХгФРзШ ЯаЮШбеЮФШв бСаЮб вХЪгйХЩ ЯЮЧШжШШ /g (ЮЯаХФХЫпХЬЮЩ дгЭЪжШХЩ pos). ЅРЪЮЭХж, бвРаРЩвХбм ШЧСХУРвм ЬЮФШдШЪРжШШ жХЫХТле ФРЭЭле Т жШЪЫХ, ХбЫШ Тл ЯЮЫЭЮбвмо ЭХ гТХаХЭл Т вЮЬ, звЮ ФХЫРХвХ — нвЮ ЯаШТЮФШв Ъ бСаЮбг ФРЭЭле pos<$M[R7-93]> [14 б.<$R[P#,R7-92]>].
јл ФЮТЮЫмЭЮ ФЮЫУЮ аРЧСШаРЫШбм б ТбХТЮЧЬЮЦЭлЬШ ЯРаРЬХваРЬШ, аХЦШЬРЬШ, ЮбЮСлЬШ бЫгзРпЬШ Ш ЯЮСЮзЭлЬШ нддХЪвРЬШ ЮЯХаРвЮаР ЯЮШбЪР. їЮбЪЮЫмЪг ЬЭЮУШХ дРЪвЮал ЭХ бТпЧРЭл ТШЧгРЫмЭЮ б ЯаШЬХЭХЭШХЬ ЮЯХаРвЮаР ЯЮШбЪР (вЮ Хбвм ШбЯЮЫмЧговбп ШЫШ ТбваХзРовбп Т ФагУЮЩ вЮзЪХ ЯаЮУаРЬЬл), п ЯаШТХФг ЪаРвЪго бТЮФЪг вРЪШе дРЪвЮаЮТ:
l ЪЮЭвХЪбв — ЮЪРЧлТРХв ЧЭРзШвХЫмЭЮХ ТЫШпЭШХ ЭР ЯаЮжХбб ЯЮШбЪР, Р вРЪЦХ ЭР ТЮЧТаРйРХЬЮХ ЧЭРзХЭШХ Ш ЯЮСЮзЭлХ нддХЪвл;
l pos(…) — пТЭЮХ ШЫШ ЪЮбТХЭЭЮХ (ЯЮбаХФбвТЮЬ ЬЮФШдШЪРвЮаР /g) ЯаШбТРШТРЭШХ ЮЯаХФХЫпХв ЯЮЧШжШо бваЮЪШ, Т ЪЮвЮаЮЩ ЭРзЭХвбп бЫХФгойШЩ ЯЮШбЪ ЯЮФ гЯаРТЫХЭШХЬ ЬЮФШдШЪРвЮаР /g. ВРЪЦХ бЬ. ЮЯШбРЭШХ [\G] Т аРЧФХЫХ «їаШТпЧЪР Ъ вХЪгйХЩ ЯЮЧШжШШ ЯаШ УЫЮСРЫмЭЮЬ ЯЮШбЪХ» (б. <$R[P#,R7-27]>);
l $* — ЯХаХЬХЭЭРп, гЭРбЫХФЮТРЭЭРп ШЧ Perl4. ІЫШпХв ЭР аРСЮвг пЪЮаЭле ЬХвРбШЬТЮЫЮТ ^ Ш $;
l аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯЮ гЬЮЫзРЭШо — ШбЯЮЫмЧгХвбп ТЬХбвЮ ЯгбвЮУЮ аХУгЫпаЭЮУЮ ТлаРЦХЭШп (б. <$R[P#,R7-86]>);
l study — ЭХ ТЫШпХв ЭР аХЧгЫмвРвл ЯЮШбЪР ШЫШ ТЮЧТаРйРХЬлХ ЧЭРзХЭШп, ЭЮ ТлЧЮТ study ФЫп жХЫХТЮЩ бваЮЪШ ЬЮЦХв гбЪЮаШвм (ШЫШ ЧРЬХФЫШвм) ЯЮШбЪ. БЬ. аРЧФХЫ «ДгЭЪжШп study» (б. <$R[P#,R7-5]>);
l m?…?/reset — ТЫШпХв ЭР «ЭХТШФШЬлЩ» бвРвгб бЮТЯРФХЭШп/ЭХбЮТЯРФХЭШп ЮЯХаРвЮаЮТ m?…? (б. <$R[P#,R7-80]>).
їХаХФ вХЬ, ЪРЪ ЧРТХаиШвм ЮЯШбРЭШХ ЮЯХаРвЮаР ЯЮШбЪР, п еЮзг ЧРФРвм ТРЬ ТЮЯаЮб. їаШ ШбЯЮЫмЧЮТРЭШШ аХУгЫпаЭле ТлаРЦХЭШЩ Т гЯаРТЫпойШе ЪЮЭбвагЪжШпе ЪЮЬРЭФ while, if Ш foreach ЭХЮСеЮФШЬЮ ФХЩбвТЮТРвм ЮзХЭм ТЭШЬРвХЫмЭЮ. єРЪ Тл ФгЬРХвХ, звЮ ТлТХФХв бЫХФгойШЩ даРУЬХЭв<$M[R7-98]>?
while ("Larry Curly Moe" =~ m/\w+/g) {
print "WHILE stooge is $&.\n";
}
print "\n";
if ("Larry Curly Moe" =~ m/\w+/g) {
print "IF stooge is $&.\n";
}
print "\n";
foreach ("Larry Curly Moe" =~ m/\w+/g) {
print "FOREACH stooge is $&.\n";
}
·РФРзР ЭХ ШЧ ЯаЮбвле. refїХаХТХаЭШвХ бваРЭШжг Ш ЯаЮТХамвХ бТЮЩ ЮвТХв.
<$M[R7-12]>ѕЯХаРвЮа ЯЮФбвРЭЮТЪШ Perl, s/ТлаРЦХЭШХ/ЧРЬХЭР/, аРбиШапХв ЪЮЭжХЯжШо ЯЮШбЪР вХЪбвР ФЮ ЯЮШбЪР б ЧРЬХЭЮЩ. АХУгЫпаЭЮХ ТлаРЦХЭШХ-ЮЯХаРЭФ ЧРФРХвбп ЯЮ вХЬ ЦХ ЯаРТШЫРЬ, ЪРЪ Т ЮЯХаРвЮаХ ЯЮШбЪР, ЮФЭРЪЮ ТвЮаЮЩ ЮЯХаРЭФ ЯаХФЭРЧЭРзХЭ ФЫп ЧРЬХЭл бЮТЯРТиХУЮ вХЪбвР ЭЮТлЬ. јЭЮУШХ ЯаЮСЫХЬл, бТпЧРЭЭлХ б ЮЯХаРвЮаЮЬ ЯЮФбвРЭЮТЪШ, бЮТЯРФРов б РЭРЫЮУШзЭлЬШ ЯаЮСЫХЬРЬШ ЮЯХаРвЮаР ЯЮШбЪР Ш аРббЬРваШТРовбп Т бЮЮвТХвбвТгойХЬ аРЧФХЫХ (бЬ. б. <$R[P#,R7-11]>). ІЯаЮзХЬ, ЧРбЫгЦШТРов гЯЮЬШЭРЭШп Ш ЭХЪЮвЮалХ ЭЮТлХ РбЯХЪвл:
l ѕЯаХФХЫХЭШХ ЮЯХаРЭФР-ЧРЬХЭл Ш ФЮЯЮЫЭШвХЫмЭлХ ЮУаРЭШзШвХЫШ.
l јЮФШдШЪРвЮа /e.
l єЮЭвХЪбв Ш ТЮЧТаРйРХЬЮХ ЧЭРзХЭШХ.
l ёбЯЮЫмЧЮТРЭШХ ЬЮФШдШЪРвЮаР /g б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ, ЪЮвЮалХ ЬЮУгв бЮТЯРФРвм б «ЭШзХЬ».
І ЮСлзЭЮЩ ЪЮЭбвагЪжШШ s/…/…/ ЮЯХаРЭФ-ЧРЬХЭР<$M[R7-43]> гЪРЧлТРХвбп баРЧг ЦХ ЯЮбЫХ аХУгЫпаЭЮУЮ ТлаРЦХЭШп-ЮЯХаРЭФР, ЯЮнвЮЬг Т ЮСйХЩ бЫЮЦЭЮбвШ ШбЯЮЫмЧгХвбп ваШ нЪЧХЬЯЫпаР ЮУаРЭШзШвХЫп ТЬХбвЮ ФТге Т ЪЮЭбвагЪжШШ m/…/. µбЫШ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЧРЪЫозРХвбп Т ЯРаЭлХ ЮУаРЭШзШвХЫШ<$M[R7-81]> (ЭРЯаШЬХа, <…>), ЮЯХаРЭФ-ЧРЬХЭР вРЪЦХ ЧРЪЫозРХвбп Т бЮСбвТХЭЭго ЯРаг ЮУаРЭШзШвХЫХЩ (Ш ШвЮУЮТлЩ ЮЯХаРвЮа бЮФХаЦШв зХвлаХ ЮУаРЭШзШвХЫп ТЬХбвЮ ваХе). І вРЪШе бЫгзРпе ФТХ ЯРал ЮУаРЭШзШвХЫХЩ ЬЮУгв аРЧФХЫпвмбп ЯаЮЯгбЪРЬШ, Р ЯаШ ЭРЫШзШШ ЯаЮЯгбЪР ТЮЧЬЮЦЭЮ ЭРЫШзШХ ЪЮЬЬХЭвРаШХТ<$M[R7-97]> [15 б.<$R[P#,R7-96]>]. їРаЭлХ ЮУаРЭШзШвХЫШ ЮСлзЭЮ ШбЯЮЫмЧговбп Т бЮзХвРЭШШ б /x Ш /e:
$test =~ s{
…СЮЫмиЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ б ЮСиШаЭлЬШ ЪЮЬЬХЭвРаШпЬШ…
} {
…даРУЬХЭв ЪЮФР Perl, ТлзШбЫХЭШХ ЪЮвЮаЮУЮ ФРХв вХЪбв ЧРЬХЭл…
}ex
Perl ЮСлзЭЮ ЯаЮШЧТЮФШв бвРЭФРавЭго ЮСаРСЮвЪг ЮЯХаРЭФР-ЧРЬХЭл ЯЮ ЯаРТШЫРЬ бваЮЪ, ЧРЪЫозХЭЭле Т ЪРТлзЪШ, еЮвп ТЮЧЬЮЦЭЮ ЯаШЬХЭХЭШХ ЭХЪЮвЮале бЯХжШРЫмЭле ЮУаРЭШзШвХЫХЩ. ѕСаРСЮвЪР ТлЯЮЫЭпХвбп ЯЮбЫХ ЮСЭРагЦХЭШп бЮТЯРФХЭШп (ЯаШ ЭРЫШзШШ /g — ЯЮбЫХ ЪРЦФЮУЮ бЮТЯРФХЭШп), ЯЮнвЮЬг ЯХаХЬХЭЭлХ $1 Ш в. Ф. ЬЮУгв ШбЯЮЫмЧЮТРвмбп ФЫп бблЫЮЪ ЭР вХЪбв, бЮТЯРТиШЩ б бЮЮвТХвбвТгойШЬШ ЯЮФТлаРЦХЭШпЬШ.
while, foreach Ш if
bref ѕвТХв ЭР ТЮЯаЮб бЮ б. <$R[P#,R7-98]>
АХЧгЫмвРв ЧРТШбШв Юв ТХабШШ Perl.
|
Perl4 |
Perl5 |
|
WHILE stooge is Larry. WHILE stooge is Curly. WHILE stooge is Moe. |
WHILE stooge is Larry. WHILE stooge is Curly. WHILE stooge is Moe. |
|
IF stooge is Larry. |
IF stooge is Larry. |
|
FOREACH stooge is . FOREACH stooge is . FOREACH stooge is . |
FOREACH stooge is Moe FOREACH stooge is Moe FOREACH stooge is Moe |
ѕСаРвШвХ ТЭШЬРЭШХ: ХбЫШ Сл Т ЪЮЬРЭФХ print Т жШЪЫХ foreach ТЬХбвЮ $& ШбЯЮЫмЧЮТРЫРбм ЯХаХЬХЭЭРп $_, вЮ аХЧгЫмвРв бЮТЯРФРЫ Сл б аХЧгЫмвРвЮЬ жШЪЫР while. ѕФЭРЪЮ Т нвЮЬ бЫгзРХ ЭХ аХЧгЫмвРв, ТЮЧТаРйРХЬлЩ ЪЮЬРЭФЮЩ m/…/g, ('Larry', 'Curly', 'Moe'), ЮбвРТРЫбп Сл ЭХШбЯЮЫмЧЮТРЭЭлЬ. ІЬХбвЮ нвЮУЮ ШбЯЮЫмЧгХвбп ЯЮСЮзЭлЩ нддХЪв $&, ЯЮзвШ ТбХУФР бТШФХвХЫмбвТгойШЩ ЮС ЮиШСЪХ ЯаЮУаРЬЬШаЮТРЭШп, ЯЮбЪЮЫмЪг ЯЮСЮзЭлХ ЪЮЭвХЪбвл m/…/g Т бЯШбЪЮТЮЬ ЪЮЭвХЪбвХ аХФЪЮ ЯаШЭЮбпв ЯЮЫмЧг.
ґЫп ЮЯХаРвЮаР ЯЮФбвРЭЮТЪШ ЮЯаХФХЫповбп бЫХФгойШХ бЯХжШРЫмЭлХ ЮУаРЭШзШвХЫШ:
l єРЪ Ш Т бЫгзРХ б ЮЯХаРвЮаЮЬ ЯЮШбЪР, аХУгЫпаЭЮХ ТлаРЦХЭШХ-ЮЯХаРЭФ ЬЮЦХв ЧРЪЫозРвмбп Т РЯЮбваЮдл<$M[R7-100]> [16 б.<$R[P#,R7-99]>], ЭЮ ЯЮ ЭХбЪЮЫмЪЮ ШЭлЬ ЯаРТШЫРЬ (ХбЫШ ЮЯХаРЭФ-ТлаРЦХЭШХ ЧРЪЫозХЭ Т РЯЮбваЮдл, вЮ ЦХ бРЬЮХ ФЮЫЦЭЮ Слвм бФХЫРЭЮ б ЮЯХаРЭФЮЬ-ЧРЬХЭЮЩ, ЭЮ ЭХ ЭРЮСЮаЮв).
l БЯХжШРЫмЭлЩ ЮУаРЭШзШвХЫм ЮЯХаРвЮаР ЯЮШбЪР ?…? ЭХ ШЬХХв бЯХжШРЫмЭЮЩ ШЭвХаЯаХвРжШШ ФЫп ЮЯХаРвЮаР ЧРЬХЭл.
l ЕЮвп Т ФЮЪгЬХЭвРжШШ Perl5 гвТХаЦФРХвбп ЮСаРвЭЮХ, ЮСаРвЭлХ РЯЮбваЮдл Т ЪРзХбвТХ ЮУаРЭШзШвХЫХЩ ЭХ ШЬХов бЯХжШРЫмЭЮЩ ШЭвХаЯаХвРжШШ, ЪРЪ нвЮ СлЫЮ Т Perl4. І Perl4 ЮЯХаРЭФ-ЧРЬХЭР бЭРзРЫР ЮСаРСРвлТРЫбп ЯЮ ЯаРТШЫРЬ бваЮЪ Т ЪРТлзЪРе, Р ЧРвХЬ ТлЯЮЫЭпЫбп ЪРЪ бШбвХЬЭРп ЪЮЬРЭФР. їЮЫгзХЭЭлХ ТлеЮФЭлХ ФРЭЭлХ ШбЯЮЫмЧЮТРЫШбм Т ЪРзХбвТХ вХЪбвР ЧРЬХЭл. І аХФЪШе бЫгзРпе, ЪЮУФР нвЮ ФХЩбвТШвХЫмЭЮ ЭХЮСеЮФШЬЮ, нвЮ ЯЮТХФХЭШХ ЫХУЪЮ ШЬШвШагХвбп Т Perl5. БаРТЭШвХ ФТХ ЪЮЬРЭФл ФЫп ЮЯаХФХЫХЭШп ШЬХЭШ ЪЮЬРЭФ Ш ТлСЮаЪШ ЪЫозХЩ -version:
Perl4: s`version of (\w+)`$1 --version 2>&1`g;
Perl4 Ш Perl5: s/version of (\w+)/`$1 --version 2>&1`/e;
їЮФзХаЪЭгвРп зРбвм ЯаХФбвРТЫпХв бЮСЮЩ ЮЯХаРЭФ-ЧРЬХЭг. І ЯХаТЮЬ ТРаШРЭвХ ЮЭР ТлЯЮЫЭпХвбп ЪРЪ бШбвХЬЭРп ЪЮЬРЭФР ШЧ-ЧР ЯаШбгвбвТШп бЯХжШРЫмЭЮУЮ ЮУаРЭШзШвХЫп. ІЮ ТвЮаЮЬ ТРаШРЭвХ ЮСаРвЭлХ РЯЮбваЮдл ЭХ ТлЯЮЫЭпов бЯХжШРЫмЭле дгЭЪжШЩ ФЮ вЮУЮ ЬЮЬХЭвР, ЪРЪ Тбп бваЮЪР ЧРЬХЭл СгФХв ТлзШбЫХЭР Т бЮЮвТХвбвТШШ б ЬЮФШдШЪРвЮаЮЬ /e. јЮФШдШЪРвЮа /e, ЯЮФаЮСЭЮ ЮЯШбРЭЭлЩ Т бЫХФгойХЬ аРЧФХЫХ, УЮТЮаШв Ю вЮЬ, звЮ ЮЯХаРЭФ-ЧРЬХЭР ЯаХФбвРТЫпХв бЮСЮЩ ЭХСЮЫмиЮЩ даРУЬХЭв ЪЮФР Perl, ЪЮвЮалЩ бЫХФгХв ТлЯЮЫЭШвм Ш ШбЯЮЫмЧЮТРвм ЯЮЫгзХЭЭЮХ ЧЭРзХЭШХ ЪРЪ вХЪбв ЧРЬХЭл.
їЮЬЭШвХ Ю вЮЬ, звЮ ЬХеРЭШЧЬ ЮСаРСЮвЪШ ЮЯХаРЭФР-ЧРЬХЭл ФЮТЮЫмЭЮ бШЫмЭЮ ЮвЫШзРХвбп Юв ЮСаРСЮвЪШ ЮЯХаРЭФР-ТлаРЦХЭШЩ, ЯаШ ЪЮвЮаЮЩ ЮСлзЭЮ ШбЯЮЫмЧговбп ЯаРТШЫР, ЭРЯЮЬШЭРойШХ ЯаРТШЫР ЮСаРСЮвЪШ бваЮЪ Т ЪРТлзЪРе, Ш ЮУаРЭШзШвХЫШ б ЮбЮСЮЩ ШЭвХаЯаХвРжШХЩ.
јЮФШдШЪРвЮа /e ЬЮЦХв ШбЯЮЫмЧЮТРвмбп вЮЫмЪЮ Т ЮЯХаРвЮаХ ЯЮФбвРЭЮТЪШ. їаШ ШбЯЮЫмЧЮТРЭШШ нвЮУЮ ЬЮФШдШЪРвЮаР ЮЯХаРЭФ-ЧРЬХЭР ТлзШбЫпХвбп ЯЮ ЯаРТШЫРЬ eval {…} (ТЪЫозРп ЯаЮТХаЪг бШЭвРЪбШбР ЭР бвРФШШ ЧРУагЧЪШ), Ш бЮТЯРТиШЩ вХЪбв ЧРЬХЭпХвбп аХЧгЫмвРвЮЬ ТлзШбЫХЭШп. ѕЯХаРЭФ-ЧРЬХЭР ЭХ ЯаЮеЮФШв ФЮЯЮЫЭШвХЫмЭго ЮСаРСЮвЪг ЯХаХФ eval (ЭХ бзШвРп ЮЯаХФХЫХЭШп ЫХЪбШзХбЪШе УаРЭШж — бЬ. дРЧг A ЭР аШб. 7.1) Ш ФРЦХ ЭХ ЮСаРСРвлТРХвбп ЯЮ ЯаРТШЫРЬ бваЮЪ Т ЪРТлзЪРе<$M[R7-102]> [17 б.<$R[P#,R7-101]>]. ґЫп ЪРЦФЮУЮ бЮТЯРФХЭШп ТлзШбЫХЭШХ ЯаЮШЧТЮФШвбп ЧРЭЮТЮ.
ЅРЯаШЬХа, Т World Wide Web ФЮЯгбЪРХвбп ЪЮФШаЮТРЭШХ бЯХжШРЫмЭле бШЬТЮЫЮТ ЯаШ ЯЮЬЮйШ бШЬТЮЫР %, ЧР ЪЮвЮалЬ бЫХФгХв иХбвЭРФжРвХаШзЭлЩ ЪЮФ ШЧ ФТге жШда. єЮФШаЮТРЭШХ ТбХе бШЬТЮЫЮТ, ЭХ пТЫпойШебп РЫдРТШвЭЮ-жШдаЮТлЬШ, ТлЯЮЫЭпХвбп ЪЮЬРЭФЮЩ<$M[R7-103]>
$url =~ s/([^a-zA-Z0-9])/sprintf('%%%02x', ord($1))/ge;
єЮЬРЭФР ФХЪЮФШаЮТРЭШп ТлУЫпФШв вРЪ:
$url =~ s/%([0-9a-f][0-9a-f])/pack("C",hex($1))/ige;
ДгЭЪжШп pack("C",зШбЫЮ) ЯаХЮСаРЧгХв зШбЫЮТЮЩ ЪЮФ Т бШЬТЮЫ б ЧРФРЭЭлЬ ЪЮФЮЬ, Р дгЭЪжШп sprintf('%%%02x', ord(бШЬТЮЫ)) аХиРХв ЯаЮвШТЮЯЮЫЮЦЭго ЧРФРзг; ЧР ФЮЯЮЫЭШвХЫмЭЮЩ ШЭдЮаЬРжШХЩ ЮСаРйРЩвХбм Ъ ФЮЪгЬХЭвРжШШ Perl (Р вРЪЦХ бЬ. бЭЮбЪг ЭР б. <$R[P#,R3-31]>).
їаШ ШбЯЮЫмЧЮТРЭШШ ЬЮФШдШЪРвЮаР /e ЭХЮСеЮФШЬЮ ЮбЮСХЭЭЮ зХвЪЮ ЯЮЭШЬРвм, ЪвЮ, звЮ Ш ЪЮУФР ШЭвХаЯаХвШагХв. НвР ЧРФРзР ЭХ вРЪРп гЦ бЫЮЦЭР, ЭЮ ФЫп вЮУЮ, звЮСл аРЧЮСаРвмбп Т ЯаЮШбеЮФпйХЬ, ЯЮваХСговбп ЭХЪЮвЮалХ гбШЫШп. ЅРЯаШЬХа, ФРЦХ Т ЯаЮбвХЩиШе ЪЮЬРЭФРе вШЯР s/…/`echo $$`/e ТЮЧЭШЪРХв ТЮЯаЮб: ЪвЮ ШЭвХаЯаХвШагХв $$ — Perl ШЫШ ЪЮЬРЭФЭлЩ ШЭвХаЯаХвРвЮа? ґЫп Perl Ш ФЫп ЬЭЮУШе ЪЮЬРЭФЭле ШЭвХаЯаХвРвЮаЮТ ЯХаХЬХЭЭРп $$ бЮФХаЦШв ШФХЭвШдШЪРвЮа ЯаЮжХббР (Perl ШЫШ ЪЮЬРЭФЭЮУЮ ШЭвХаЯаХвРвЮаР). ВРЪШЬ ЮСаРЧЮЬ, ЯаЮжХбб ШЭвХаЯаХвРжШШ ЬЮЦЭЮ аРббЬРваШТРвм ЭР ЭХбЪЮЫмЪШе гаЮТЭпе. ІЮ-ЯХаТле, ЮЯХаРЭФ-ЧРЬХЭР Т Perl5 ЭХ ЯЮФТХаУРХвбп ЮСаРСЮвЪХ ЯХаХФ ТлзШбЫХЭШХЬ, ЭЮ Т Perl4 ТлЯЮЫЭпХвбп ЮСаРСЮвЪР ЯЮ ЯаРТШЫРЬ, ЭРЯЮЬШЭРойШЬ ЮСаРСЮвЪг бваЮЪ Т ЪРТлзЪРе. їаШ ТлзШбЫХЭШШ аХЧгЫмвРвР ЮСаРвЭлХ РЯЮбваЮдл ЮСХбЯХзШТРов ЮСаРСЮвЪг ЯЮ ЯаРТШЫРЬ бваЮЪ Т ЪРТлзЪРе (ШЬХЭЭЮ ЭР нвЮЩ бвРФШШ Perl ШЭвХаЯЮЫШагХв $$ — ФЫп ЯаХФЮвТаРйХЭШп ШЭвХаЯЮЫпжШШ ЬЮЦЭЮ ТЮбЯЮЫмЧЮТРвмбп нЪаРЭШаЮТРЭШХЬ). ЅРЪЮЭХж, аХЧгЫмвРв ЯХаХФРХвбп ЪЮЬРЭФЭЮЬг ШЭвХаЯаХвРвЮаг, ЪЮвЮалЩ ТлЯЮЫЭпХв ЪЮЬРЭФг echo (ХбЫШ нЪаРЭШаЮТРвм $$, ЯХаХЬХЭЭРп СгФХв ЯХаХФРЭР ШЭвХаЯаХвРвЮаг Т ЭХнЪаРЭШаЮТРЭЭЮЬ ТШФХ, звЮ ЯаШТХФХв Ъ ШЭвХаЯЮЫпжШШ $$ ЪЮЬРЭФЭлЬ ШЭвХаЯаХвРвЮаЮЬ).
БШвгРжШп ЮбЫЮЦЭпХвбп ХйХ ЮФЭШЬ ЮСбвЮпвХЫмбвТЮЬ. µбЫШ ЭРапФг б ЬЮФШдШЪРвЮаЮЬ /e ШбЯЮЫмЧгХвбп /g , бЪЮЫмЪЮ аРЧ СгФХв ТлзШбЫпвмбп `echo $$` — ТбХУЮ ЮФШЭ аРЧ (б ШбЯЮЫмЧЮТРЭШХЬ аХЧгЫмвРвР ТЮ ТбХе ЧРЬХЭРе) ШЫШ ЬЭЮУЮЪаРвЭЮ, ЯЮбЫХ ЪРЦФЮУЮ ЭРЩФХЭЭЮУЮ бЮТЯРФХЭШп? µбЫШ ЮЯХаРЭФ ЯЮФбвРЭЮТЪШ бЮФХаЦШв $1 Ш ФагУШХ ЯЮФЮСЭлХ ЪЮЭбвагЪжШШ, ЮзХТШФЭЮ, ТлзШбЫХЭШХ ФЮЫЦЭЮ ЯаЮШЧТЮФШвмбп ЧРЭЮТЮ ФЫп ЪРЦФЮУЮ бЮТЯРФХЭШп, звЮСл ЯХаХЬХЭЭРп $1 ЯаРТШЫмЭЮ ЮваРЦРЫР бЮбвЮпЭШХ ЯЮбЫХ ЯЮШбЪР. І ФагУШе бШвгРжШпе ТбХ ЭХ бвЮЫм ЮзХТШФЭЮ. БЪРЦХЬ, Т ЯаШЬХаХ б echo Perl ТХабШШ 5.000 ЮУаРЭШзШТРХвбп ЮФЭШЬ ТлзШбЫХЭШХЬ, Р ФагУШХ ТХабШШ (ЪРЪ ЯаХФиХбвТгойШХ, вРЪ Ш ЯЮбЫХФгойШХ) ФЫп ЪРЦФЮУЮ бЮТЯРФХЭШп ЯаЮШЧТЮФпв ТлзШбЫХЭШХ ЧРЭЮТЮ.
ІХаЮпвЭЮ, нвР ТЮЧЬЮЦЭЮбвм ЯаШУЮФШвбп вЮЫмЪЮ Т ЪЮЭЪгабХ ЭР БРЬго ·РУРФЮзЭго їаЮУаРЬЬг ЭР Perl, Ш ТбХ ЦХ Ю ЭХЩ бвЮШв гЯЮЬпЭгвм. µбЫШ ЬЮФШдШЪРвЮа /e гЪРЧлТРХвбп ЭХбЪЮЫмЪЮ аРЧ, ЮЯХаРЭФ-ЧРЬХЭР вРЪЦХ СгФХв ТлзШбЫХЭ ЬЭЮУЮЪаРвЭЮ (нвЮ ХФШЭбвТХЭЭлЩ ЬЮФШдШЪРвЮа, ФЫп ЪЮвЮаЮУЮ гзШвлТРХвбп ЪЮЫШзХбвТЮ ЯЮТвЮаХЭШЩ). НвР «ЭХЯаХФЭРЬХаХЭЭРп», ЯЮ ТлаРЦХЭШо »РааШ ГЮЫЫР, ТЮЧЬЮЦЭЮбвм СлЫР «ЮСЭРагЦХЭР» Т ЭРзРЫХ 1991 УЮФР. ІЮ ТаХЬп ФШбЪгббШШ Т дЮагЬХ comp.lang.perl АнЭФРЫ ИТРаж (Randal Schwartz) ЯаХФЫЮЦШЫ ЮФЭг ШЧ бТЮШе дШаЬХЭЭле «ЯЮФЯШбХЩ»[42]:
$Old_MacDonald = q#print #; $had_a_farm = (q-q:Just another Perl hacker,:-);
s/^/q[Sing it, boys and girls...],$Old_MacDonald.$had_a_farm/eieio;
ІлЧЮТ eval, ЮСгбЫЮТЫХЭЭлЩ ЯХаТлЬ ЬЮФШдШЪРвЮаЮЬ /e, гТШФШв даРУЬХЭв
q[Sing it, boys and girls...],$Old_MacDonald.$had_a_farm
І аХЧгЫмвРвХ ХУЮ ТлЯЮЫЭХЭШп ЯЮЫгзРХвбп бваЮЪР q:Just another Perl hacker,:, ЪЮвЮаРп ЯаШ ЯЮТвЮаЭЮЬ ТлзШбЫХЭШШ ТлТХФХв ЯЮФЯШбм АнЭФРЫР «Just another Perl hacker».
ІЯаЮзХЬ, ЯЮФЮСЭлХ ЪЮЭбвагЪжШШ ШЭЮУФР ЯаШЭЮбпв ЯаРЪвШзХбЪго ЯЮЫмЧг. ґЮЯгбвШЬ, Тл еЮвШвХ ЯаЮТХбвШ агзЭго ШЭвХаЯЮЫпжШо ЯХаХЬХЭЭле Т бваЮЪХ (вРЪ, бЫЮТЭЮ бваЮЪР СлЫР ЯаЮзШвРЭР ШЧ ЪЮЭдШУгаРжШЮЭЭЮУЮ дРЩЫР). їаЮбвХЩиХХ аХиХЭШХ ЬЮЦХв ТлУЫпФХвм вРЪ: $data =~ s/(\$[a-zA-Z_]\w*)/$1/eeg; І бваЮЪХ option=$var аХУгЫпаЭЮХ ТлаРЦХЭШХ бЮТЯРФРХв б ЯЮФбваЮЪЮЩ option=$var. їаШ ЯХаТЮЬ ТлзШбЫХЭШШ ЪЮЬРЭФР ЯаЮбвЮ ЯЮЫгзШв ЯЮФбваЮЪг $1 ШЧ ЮЯХаРЭФР-ЧРЬХЭл, ЪЮвЮаРп СгФХв аРбиШаХЭР ФЮ $var. ёЧ-ЧР ЯаШбгвбвТШп ТвЮаЮУЮ ЬЮФШдШЪРвЮаР /e аХЧгЫмвРв СгФХв ТлзШбЫХЭ ЯЮТвЮаЭЮ, ТбЫХФбвТШХ зХУЮ ТЬХбвЮ $var СгФХв ЯЮФбвРТЫХЭЮ вХЪгйХХ ЧЭРзХЭШХ ЯХаХЬХЭЭЮЩ. ѕЭЮ ЧРЬХЭШв бЮТЯРТиго ЯЮФбваЮЪг $var, вХЬ бРЬлЬ дРЪвШзХбЪШ СгФХв ТлЯЮЫЭХЭР ШЭвХаЯЮЫпжШп ЯХаХЬХЭЭЮЩ.
П ЭХаХФЪЮ ШбЯЮЫмЧго ЯЮФЮСЭлХ ЯаШХЬл ЭР бТЮШе Web-бваРЭШжРе — ЬЭЮУШХ ШЧ ЭШе ЭРЯШбРЭл ЭР ЯбХТФЮЪЮФХ Perl/HTML, ЮСаРСРвлТРХЬЮЬ баХФбвТРЬШ CGI ЯаШ ЧРЯаЮбХ бЮ бвЮаЮЭл гФРЫХЭЭЮУЮ ЪЫШХЭвР. НвЮ ЯЮЧТЮЫпХв ЬЭХ ЯаЮШЧТЮФШвм ЭХЪЮвЮалХ ТлзШбЫХЭШп Т ЬЮЬХЭв ЧРУагЧЪШ бваРЭШжл — ЭРЯаШЬХа, звЮСл ЭРЯЮЬЭШвм Ю вЮЬ, бЪЮЫмЪЮ ФЭХЩ ЮбвРЫЮбм ФЮ ЬЮХУЮ ФЭп аЮЦФХЭШп[43].
П гЦХ УЮТЮаШЫ Ю вЮЬ, звЮ ЮЯХаРвЮа ЯЮШбЪР ТЮЧТаРйРХв аРЧЫШзЭлХ ЧЭРзХЭШп ФЫп аРЧЭле бЮзХвРЭШЩ ЪЮЭвХЪбвР б ЬЮФШдШЪРвЮаЮЬ /g. Б ЮЯХаРвЮаЮЬ ЯЮФбвРЭЮТЪШ ФХЫЮ ЮСбвЮШв ЯаЮйХ — ЮЭ ТбХУФР ТЮЧТаРйРХв ЮФШЭРЪЮТго ШЭдЮаЬРжШо.
ІЮЧТаРйРХЬЮХ ЧЭРзХЭШХ ЫШСЮ аРТЭЮ ЪЮЫШзХбвТг ТлЯЮЫЭХЭЭле ЯЮФбвРЭЮТЮЪ, ЫШСЮ (ХбЫШ ЭШ ЮФЭЮЩ ЯЮФбвРЭЮТЪШ ЭХ бФХЫРЭЮ) — Ягбвго бваЮЪг<$M[R7-105]> [18 б.<$R[P#,R7-104]>]. їаШ ЫЮУШзХбЪЮЩ ШЭвХаЯаХвРжШШ (ЭРЯаШЬХа, Т гбЫЮТШШ ЪЮЬРЭФл if) ТЮЧТаРйРХЬЮХ ЧЭРзХЭШХ гФЮСЭЮ ШЭвХаЯаХвШагХвбп ЪРЪ ШбвШЭР, ХбЫШ СлЫР ТлЯЮЫЭХЭР еЮвп Сл ЮФЭР ЯЮФбвРЭЮТЪР, Ш ЪРЪ ЫЮЦм Т ЯаЮвШТЭЮЬ бЫгзРХ.
І ЯаХФиХбвТгойХЬ ЮЯШбРЭШШ ЮЯХаРвЮаР ЯЮШбЪР СлЫШ ЯЮФаЮСЭЮ ЯаЮРЭРЫШЧШаЮТРЭл вХ ЮбЮСлХ бШвгРжШШ, ЪЮУФР аХУгЫпаЭЮХ ТлаРЦХЭШХ ЬЮЦХв бЮТЯРбвм б вХЪбвЮЬ ЭгЫХТЮЩ иШаШЭл<$M[R7-110]>. ІФЮСРТЮЪ аРЧЭлХ ТХабШШ Perl ТХФгв бХСп ЯЮ-аРЧЭЮЬг, звЮ ТлЧлТРХв ХйХ СЮЫмиХ ЯгвРЭШжл. є бзРбвмо, ЮЯХаРвЮа ЯЮФбвРЭЮТЪШ ТЮ ТбХе ТХабШпе аРСЮвРХв ЮФШЭРЪЮТЮ. ВРСЫШжР 7.9 (б. <$R[P#,R7-106]>) Т аРТЭЮЩ бвХЯХЭШ ЮвЭЮбШвбп Ш Ъ бЮТЯРФХЭШпЬ s/…/…/g, ЭЮ ЯаШЬХал б ЯЮЬХвЪЮЩ «Perl5» ЮвЭЮбпвбп вЮЫмЪЮ Ъ ЮЯХаРвЮаг ЯЮШбЪР. їаШЬХал б ЯЮЬХвЪЮЩ «Perl4» ЮвЭЮбпвбп ЪРЪ Ъ ЮЯХаРвЮаг ЯЮШбЪР Perl4, вРЪ Ш Ъ ЮЯХаРвЮаг ЯЮФбвРЭЮТЪШ ТЮ ТбХе ТХабШпе Perl.
<$M[R7-13]>јЭЮУЮУаРЭЭлЩ ЮЯХаРвЮа split (Т ЯаЮбвЮаХзШШ зРбвЮ ЭРЧлТРХЬлЩ дгЭЪжШХЩ) ЮСлзЭЮ ШбЯЮЫмЧгХвбп ЪРЪ ЭХЪРп ЯаЮвШТЮЯЮЫЮЦЭЮбвм ЪЮЭбвагЪжШШ m/…/…/g Т бЯШбЪЮТЮЬ ЪЮЭвХЪбвХ (б. <$R[P#,R7-64]>). їЮбЫХФЭпп ТЮЧТаРйРХв вХЪбв, бЮТЯРТиШЩ б аХУгЫпаЭлЬ ТлаРЦХЭШХЬ, вЮУФР ЪРЪ split б вХЬ ЦХ аХУгЫпаЭлЬ ТлаРЦХЭШХЬ ТЮЧТаРйРХв вХЪбв, аРЧФХЫпХЬлЩ бЮТЯРФХЭШпЬШ. ВРЪ, ЯаШЬХЭХЭШХ ЪЮЬРЭФл $text =~ m/:/g Ъ ЯХаХЬХЭЭЮЩ $text, бЮФХаЦРйХЩ бваЮЪг IO.SYS:225558:95-10-03:a-sh:optional, ТЮЧТаРйРХв бЯШбЮЪ ШЧ зХвлаХе нЫХЬХЭвЮТ:
(':', ':', ':', ':')
ІапФ ЫШ нвЮв бЯШбЮЪ ЯаШЭХбХв ЪРЪго-ЭШСгФм ЯЮЫмЧг. Б ФагУЮЩ бвЮаЮЭл, ЪЮЬРЭФР split(/:/, $text) ТЮЧТаРйРХв бЯШбЮЪ ШЧ ЯпвШ нЫХЬХЭвЮТ:
('IO.SYS', '225558', '95-10-03', '-a-sh', 'optional')
І ЮСЮШе ЯаШЬХаРе [:] бЮТЯРФРХв зХвлаХ аРЧР. їаШ ШбЯЮЫмЧЮТРЭШШ split нвШ зХвлаХ бЮТЯРФХЭШп аРЧФХЫпов ЪЮЯШо жХЫХТЮУЮ вХЪбвР ЭР Япвм зРбвХЩ, ТЮЧТаРйРХЬле Т ТШФХ бЯШбЪР ШЧ ЯпвШ бваЮЪ.
І ЯаЮбвХЩиХЩ дЮаЬХ Ш б ЯаЮбвлЬШ ФРЭЭлЬШ, ЪРЪ Т ЯаШТХФХЭЭЮЬ ЯаШЬХаХ, ЮЯХаРвЮа split ТЯЮЫЭХ ЯЮЭпвХЭ, Р ЯЮЫмЧР Юв ЭХУЮ ЮзХТШФЭР. ВХЬ ЭХ ЬХЭХХ, ЯаШ ШбЯЮЫмЧЮТРЭШШ split Т СЮЫХХ бЫЮЦЭЮЩ бШвгРжШШ ШЫШ ФЫп ЭХваШТШРЫмЭле ФРЭЭле ТбХ бвРЭЮТШвбп УЮаРЧФЮ бЫЮЦЭХХ. ґЫп ЭРзРЫР аРббЬЮваШЬ ЮбЭЮТЭлХ ЯаШЭжШЯл ШбЯЮЫмЧЮТРЭШп split.
ѕЯХаРвЮа split ТлУЫпФШв ЪРЪ дгЭЪжШп Ш ЯЮЫгзРХв ФЮ ваХе ЮЯХаРЭФЮТ:
split(бЮТЯРФХЭШХ, жХЫХТРп_бваЮЪР, ЮУаРЭШзХЭШХ)
(І Perl5 ЪагУЫлХ бЪЮСЪШ ЭХ ЮСпЧРвХЫмЭл). ґЫп ЮЯХаРЭФЮТ, ЧЭРзХЭШп ЪЮвЮале ЭХ гЪРЧРЭл, ШбЯЮЫмЧговбп ЧЭРзХЭШп ЯЮ гЬЮЫзРЭШо.
Г ЯХаТЮУЮ ЮЯХаРЭФР бгйХбвТгХв ЭХбЪЮЫмЪЮ ЮбЮСле бЫгзРХТ, ЭЮ ЮСлзЭЮ ЮЭ ЯаХФбвРТЫпХв бЮСЮЩ ЯаЮбвЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ — ЭРЯаШЬХа, /:/ ШЫШ m/\s*<P>\s*/i. ВаРФШжШЮЭЭЮ ТЬХбвЮ m/…/ ШбЯЮЫмЧгХвбп /…/, еЮвп ЭР бРЬЮЬ ФХЫХ нвЮ ЭХбгйХбвТХЭЭЮ. јЮФШдШЪРвЮа /g ЭХ ЭгЦХЭ (ЮЭ ШУЭЮаШагХвбп), ЯЮбЪЮЫмЪг split Ш вРЪ ЮСХбЯХзШТРХв ЬЭЮУЮЪаРвЭЮХ ЯаЮТХФХЭШХ ЯЮШбЪР.
ЅР бЫгзРЩ, ХбЫШ ЧЭРзХЭШХ нвЮУЮ ЮЯХаРЭФР ЭХ ЧРФРЭЮ, ШбЯЮЫмЧгХвбп ЧЭРзХЭШХ ЯЮ гЬЮЫзРЭШо, ЭЮ нвЮ ЮФШЭ ШЧ бЫЮЦЭле зРбвЭле бЫгзРХТ, Ю ЪЮвЮале аХзм ЯЮЩФХв ЭШЦХ.
ѕЯХаРвЮа split вЮЫмЪЮ РЭРЫШЧШагХв жХЫХТго бваЮЪг Ш ЭШЪЮУФР ЭХ ЬЮФШдШжШагХв ХХ. ХбЫШ жХЫХТРп бваЮЪР ЭХ ЧРФРЭР, ЯЮ гЬЮЫзРЭШо ШбЯЮЫмЧгХвбп бЮФХаЦШЬЮХ $_.
іЫРТЭРп дгЭЪжШп ваХвмХУЮ ЮЯХаРЭФР — ЮУаРЭШзХЭШХ ЪЮЫШзХбвТР даРУЬХЭвЮТ, ЭР ЪЮвЮалХ split аРЧСШТРХв бваЮЪг. ЅРЯаШЬХа, ФЫп ЯаШТХФХЭЭЮУЮ ТлиХ ЯаШЬХаР ЪЮЬРЭФР split(/:/, $text, 3) ТЮЧТаРйРХв бЯШбЮЪ:
('IO.SYS', '225558', '95-10-03:-a-sh:optional')
єРЪ ТШФЭЮ ШЧ ЯаШТХФХЭЭЮУЮ ЯаШЬХаР, split ЯаХЪаРйРХв ФРЫмЭХЩиШХ ЯЮШбЪШ ЯЮбЫХ ФТге бЮТЯРФХЭШЩ /:/, Т аХЧгЫмвРвХ зХУЮ бваЮЪР ФХЫШвбп ЭР ваШ даРУЬХЭвР. І ЯаШЭжШЯХ жХЫХТЮЩ вХЪбв бЮФХаЦШв Ш ФагУШХ ЯЮвХЭжШРЫмЭлХ бЮТЯРФХЭШп, ЭЮ Т ФРЭЭЮЬ бЫгзРХ нвЮ ЭХбгйХбвТХЭЭЮ ШЧ-ЧР гбвРЭЮТЫХЭЭЮУЮ ЮУаРЭШзХЭШп ЭР ЪЮЫШзХбвТЮ даРУЬХЭвЮТ. ѕЯХаРЭФ ЫШим гбвРЭРТЫШТРХв ТХаеЭоо УаРЭШжг Ш УРаРЭвШагХв, звЮ СЮЫмиХХ ЪЮЫШзХбвТЮ нЫХЬХЭвЮТ ЭХ СгФХв ТЮЧТаРйХЭЮ ЭШ ЯаШ ЪРЪШе гбЫЮТШпе, ЮФЭРЪЮ ЮЭ ЭХ УРаРЭвШагХв ТЮЧТаРвР ЧРФРЭЭЮУЮ ЪЮЫШзХбвТР даРУЬХЭвЮТ — ХбЫШ аРЧСШХЭШХ ЭХ ЮСХбЯХзШТРХв ЧРФРЭЭЮУЮ ЪЮЫШзХбвТР даРУЬХЭвЮТ, ФЮЯЮЫЭШвХЫмЭлХ даРУЬХЭвл ЭХ УХЭХаШаговбп. ЅРЯаШЬХа, ЪЮЬРЭФР split(/:/, $text, 1234) ТбХ аРТЭЮ ТХаЭХв бЯШбЮЪ ШЧ ЯпвШ нЫХЬХЭвЮТ. ІЯаЮзХЬ, ЬХЦФг ЪЮЬРЭФРЬШ split(/:/, $text) Ш split(/:/, $text, 1234) бгйХбвТгХв ТРЦЭЮХ ЮвЫШзШХ, ЪЮвЮаЮХ ЭХ ЯаЮпТЫпХвбп Т нвЮЬ ЯаШЬХаХ — ЯЮФаЮСЭЮбвШ СгФгв ЯаШТХФХЭл ЭШЦХ.
ВРЪЦХ бЫХФгХв ЯЮЬЭШвм, звЮ ЮЯХаРЭФ ЮУаРЭШзШТРХв ЪЮЫШзХбвТЮ даРУЬХЭвЮТ, Р ЭХ ЪЮЫШзХбвТЮ бЮТЯРФХЭШЩ. ґЫп ЯаШТХФХЭЭЮУЮ ТлиХ ЯаШЬХаХ ФЫп ваХе бЮТЯРФХЭШЩ СлЫ Сл бЮЧФРЭ бЫХФгойШЩ бЯШбЮЪ:
('IO.SYS', '225558', '95-10-03', '-a-sh:optional')
ЅР ЯаРЪвШЪХ ЯаЮШбеЮФШв бЮТбХЬ ШЭЮХ.
ё ХйХ ЮФЭЮ ЧРЬХзРЭШХ ШЧ ЮСЫРбвШ нддХЪвШТЭЮбвШ. ґЮЯгбвШЬ, Тл еЮвШвХ ЮУаРЭШзШвмбп ТлСЮаЪЮЩ ЭХбЪЮЫмЪШе ЭРзРЫмЭле ЯЮЫХЩ:
($filename, $size, $date) = split(/:/, $text)
ІРЬ ЭгЦЭЮ зХвлаХ даРУЬХЭвР — ШЬп дРЩЫР, аРЧЬХа, ФРвР Ш «ТбХ ЮбвРЫмЭЮХ». І ЯаШЭжШЯХ ЮвФХЫмЭлЩ даРУЬХЭв бЮ «ТбХЬ ЮбвРЫмЭлЬ» ТРЬ ЭХ ЭгЦХЭ, ЭЮ СХЧ ЭХУЮ нвР ШЭдЮаЬРжШп бЮФХаЦРЫРбм Сл ТЮ даРУЬХЭвХ $date. ёвРЪ, Тл ЬЮЦХвХ ЮУаРЭШзШвмбп зХвламЬп даРУЬХЭвРЬШ, звЮСл Perl ЭХ ваРвШЫ ТаХЬХЭШ ЭР ЯЮШбЪ ФРЫмЭХЩиШе даРУЬХЭвЮТ. ЅЮ ФРЦХ ХбЫШ ЮУаРЭШзХЭШХ ЭХ СгФХв ЧРФРЭЮ, Perl ШбЯЮЫмЧгХв ЧЭРзХЭШХ ЯЮ гЬЮЫзРЭШо, ЮСХбЯХзШТРойХХ ЯЮТлиХЭЭЮХ СлбваЮФХЩбвТШХ СХЧ ШЧЬХЭХЭШп аХЧгЫмвРвЮТ<$M[R7-108]> [19 б.<$R[P#,R7-107]>].
їЮбЪЮЫмЪг split пТЫпХвбп ЮЯХаРвЮаЮЬ, Р ЭХ дгЭЪжШХЩ, ЮЭ ЬЮЦХв ШЭвХаЯаХвШаЮТРвм бТЮШ ЮЯХаРЭФл аРЧЫШзЭлЬШ бЯЮбЮСРЬШ, ЭХ ЮУаРЭШзШТРпбм бвРЭФРавЭлЬШ ЯаРТШЫРЬШ ТлЧЮТР дгЭЪжШЩ. І зРбвЭЮбвШ, нвЮ ЮСкпбЭпХв, ЯЮзХЬг split ЬЮЦХв аРбЯЮЧЭРвм бТЮЩ ЯХаТлЩ ЮЯХаРЭФ ЪРЪ ЮЯХаРвЮа ЯЮШбЪР, Р ЭХ ЪРЪЮХ-вЮ ЮСйХХ ТлаРЦХЭШХ, ТлзШбЫпХЬЮХ ЭХЧРТШбШЬЮ ЯХаХФ ТлЧЮТЮЬ «дгЭЪжШШ».
ЅХбЬЮвап ЭР Тбо ЯЮЫХЧЭЮбвм ЮЯХаРвЮаР split, ЭРгзШвмбп ЯЮЫмЧЮТРвмбп ШЬ ЭХ вРЪ гЦ ЯаЮбвЮ. їаШеЮФШвбп гзШвлТРвм апФ ТРЦЭле ЮСбвЮпвХЫмбвТ:
l їХаТлЩ ЮЯХаРЭФ split ЮвЫШзРХвбп Юв ЮСлзЭЮУЮ ЮЯХаРвЮаР ЯЮШбЪР m/…/. єаЮЬХ вЮУЮ, г нвЮУЮ ЮЯХаРЭФР бгйХбвТгХв ЭХбЪЮЫмЪЮ бЯХжШРЫмЭле ЧЭРзХЭШЩ.
l µбЫШ ЯХаТлЩ ЮЯХаРЭФ бЮТЯРФРХв Т ЭРзРЫХ ШЫШ ЪЮЭжХ жХЫХТЮЩ бваЮЪШ, Р вРЪЦХ ХбЫШ бЮТЯРФРХв ФТРЦФл ЯЮФапФ, Т ЮФЭЮЬ ШЧ даРУЬХЭвЮТ ЮСлзЭЮ ТЮЧТаРйРХвбп ЯгбвРп бваЮЪР. ѕСлзЭЮ — ЭЮ ЭХ ТбХУФР.
l ЗвЮ ЯаЮШбеЮФШв Т бШвгРжШШ, ЪЮУФР аХУгЫпаЭЮХ ТлаРЦХЭШХ ЬЮЦХв бЮТЯРФРвм б «ЭШзХЬ»?
l µбЫШ аХУгЫпаЭЮХ ТлаРЦХЭШХ бЮФХаЦШв бЮеаРЭпойШХ ЪагУЫлХ бЪЮСЪШ, ЯЮТХФХЭШХ split ШЧЬХЭпХвбп.
l І бЪРЫпаЭЮЬ ЪЮЭвХЪбвХ split (Т ЭРбвЮпйХХ ТаХЬп ЯЮФЮСЭЮХ ШбЯЮЫмЧЮТРЭШХ ЭХ аХЪЮЬХЭФгХвбп) ТЬХбвЮ вЮУЮ, звЮСл ТЮЧТаРйРвм бЯШбЮЪ, бЮеаРЭпХв ХУЮ Т @_.
ѕЯХаРвЮа split ЯаХЦФХ ТбХУЮ ЯаХФЭРЧЭРзХЭ ФЫп ТЮЧТаРйХЭШп вХЪбвР ЬХЦФг бЮТЯРФХЭШпЬШ. µбЫШ ЮЯХаРвЮа ЯЮШбЪР бЮТЯРФРХв ФТР аРЧР ЯЮФапФ, ТЮЧТаРйРХвбп ЯгбвРп бваЮЪР ЬХЦФг нвШЬШ бЮТЯРФХЭШпЬШ. їаХФЯЮЫЮЦШЬ, ЪЮЭбвагЪжШп m/:/ ЯаШЬХЭпХвбп Ъ бваЮЪХ
:IO.SYS:225558:::95-10-03:a-sh:
І нвЮЬ бЫгзРХ СгФХв ЭРЩФХЭЮ бХЬм бЮТЯРФХЭШЩ (ЯЮФзХаЪЭгвле). їаШ ШбЯЮЫмЧЮТРЭШШ split жХЫХТРп бваЮЪР ТбХУФР[44] аРЧСШТРХвбп ЬХЦФг бЮТЯРФХЭШпЬШ, Т вЮЬ зШбЫХ Ш ЯХаХФ ЯХаТлЬ бЮТЯРФХЭШХЬ Т бРЬЮЬ ЭРзРЫХ бваЮЪШ, ЮвФХЫпойШЬ '' (Ягбвго бваЮЪг, «ЭШзвЮ») Юв 'IO.SY…'. °ЭРЫЮУШзЭЮ, зХвТХавЮХ бЮТЯРФХЭШХ аРЧФХЫпХв ФТХ ЯгбвлХ бваЮЪШ. І ШвЮУХ бХЬм бЮТЯРФХЭШЩ аРЧСШТРов жХЫХТго бваЮЪг ЭР ТЮбХЬм ЯЮФбваЮЪ:
('', 'IO.SYS', '225558', '', '', '95-10-03', '-a-sh', '')
ВХЬ ЭХ ЬХЭХХ, ЯаШ ТлЯЮЫЭХЭШШ ЪЮЬРЭФл split(/:/, $text) СгФХв ЯЮЫгзХЭ ФагУЮЩ аХЧгЫмвРв. ГФШТЫХЭл?
єЮУФР ЪЮЫШзХбвТЮ даРУЬХЭвЮТ Т аРЧФХЫХЭЭЮЩ бваЮЪХ ЭХ ЮУаРЭШзШТРХвбп (ЪРЪ нвЮ ЮСлзЭЮ СлТРХв), Perl ЯХаХФ ТЮЧТаРйХЭШХЬ бЯШбЪР гФРЫпХв ШЧ ЭХУЮ ЧРТХаиРойШХ ЯгбвлХ ЯЮФбваЮЪШ. їЮзХЬг? їЮЭпвШп ЭХ ШЬХо, ЭЮ нвР ЮбЮСХЭЭЮбвм ФЮЪгЬХЭвШаЮТРЭР. ГФРЫповбп вЮЫмЪЮ ЯгбвлХ бваЮЪШ, ЭРеЮФпйШХбп Т ЪЮЭжХ бЯШбЪР; ЮбвРЫмЭлХ ЮбвРовбп СХЧ ШЧЬХЭХЭШЩ. ІЯаЮзХЬ, Тл ЬЮЦХвХ ЧРЯаХвШвм Perl гФРЫпвм ЧРТХаиРойШХ ЯгбвлХ бваЮЪШ, ЭЮ ФЫп нвЮУЮ ЯаШФХвбп бЯХжШРЫмЭлЬ ЮСаРЧЮЬ ШбЯЮЫмЧЮТРвм ваХвШЩ ЮЯХаРЭФ.
їЮЬШЬЮ ТЮЧЬЮЦЭЮУЮ ЮУаРЭШзХЭШп ЪЮЫШзХбвТР даРУЬХЭвЮТ, ЭХЭгЫХТЮХ ЧЭРзХЭШХ ваХвмХУЮ ЮЯХаРЭФР вРЪЦХ ЧРЯаХйРХв гФРЫХЭШХ ТбХе Ягбвле нЫХЬХЭвЮТ Т ЪЮЭжХ бЯШбЪР (ЯаШ ЭгЫХТЮЬ ЧЭРзХЭШШ ваХвмХУЮ ЮЯХаРЭФР split ТХФХв бХСп Т вЮзЭЮбвШ вРЪ ЦХ, ЪРЪ ХбЫШ Сл ЮЯХаРЭФ ТЮЮСйХ ЭХ СлЫ ЧРФРЭ).
µбЫШ Тл ЭХ еЮвШвХ ЮУаРЭШзШТРвм ЪЮЫШзХбвТЮ ТЮЧТаРйРХЬле даРУЬХЭвЮТ, Р ЫШим еЮвШвХ ЮбвРТШвм Т бЯШбЪХ ЯгбвлХ нЫХЬХЭвл, ФЮбвРвЮзЭЮ ЯХаХФРвм Т ваХвмХЬ ЮЯХаРЭФХ ЮзХЭм СЮЫмиЮХ зШбЫЮ ШЫШ ЮваШжРвХЫмЭЮХ зШбЫЮ: ЪЮЬРЭФР split(/:/, $text, -1) ТЮЧТаРйРХв ТХбм бЯШбЮЪ, ТЪЫозРп ЯгбвлХ нЫХЬХЭвл Т ЪЮЭжХ.
Б ФагУЮЩ бвЮаЮЭл, ХбЫШ Тл еЮвШвХ гФРЫШвм ШЧ бЯШбЪР ТбХ ЯгбвлХ нЫХЬХЭвл, ЯЮбвРТмвХ grep{length} ЯХаХФ ТлЧЮТЮЬ split. ДгЭЪжШп grep ЮбвРТШв Т бЯШбЪХ вЮЫмЪЮ нЫХЬХЭвл, ШЬХойШХ ЭХЭгЫХТго ФЫШЭг.
±ЮЫмиШЭбвТЮ бЫЮЦЭЮбвХЩ, бТпЧРЭЭле б ЯаШЬХЭХЭШХЬ ЮЯХаРвЮаР split, бТпЧРЭЮ б аРЧЭЮбвЮаЮЭЭШЬШ ЯаШЬХЭХЭШпЬШ ХУЮ ЯХаТЮУЮ ЮЯХаРЭФР. НвЮв ЮЯХаРЭФ ЬЮЦХв ТлбвгЯРвм Т зХвлаХе ТШФРе:
l ѕЯХаРвЮа ЯЮШбЪР (ТХаЭХХ, ХУЮ РЭРЫЮУ).
l БЯХжШРЫмЭЮХ бЪРЫпаЭЮХ ЧЭРзХЭШХ 'spc' (ЮФШЭЮзЭлЩ ЯаЮСХЫ).
l »оСЮХ ЮСйХХ бЪРЫпаЭЮХ ТлаРЦХЭШХ.
l ·ЭРзХЭШХ ЯЮ гЬЮЫзРЭШо Т вЮЬ бЫгзРХ, ХбЫШ ЮЯХаРЭФ ЭХ ЯХаХФРХвбп.
БРЬлЬ аРбЯаЮбваРЭХЭЭлЬ бЫгзРХЬ ШбЯЮЫмЧЮТРЭШп split пТЫпХвбп ШбЯЮЫмЧЮТРЭШХ ЮЯХаРвЮаР ЯЮШбЪР Т ЪРзХбвТХ ЯХаТЮУЮ ЮЯХаРЭФР. ВХЬ ЭХ ЬХЭХХ, ЬХЦФг ЮЯХаРЭФЮЬ split Ш ЭРбвЮпйШЬ ЮЯХаРвЮаЮЬ ЯЮШбЪР бгйХбвТгХв апФ ТРЦЭле аРЧЫШзШЩ:
l І РЭРЫЮУХ ЮЯХаРвЮаР ЯЮШбЪР ЭХ бЫХФгХв (Р Т ЭХЪЮвЮале ТХабШпе Perl — ЭХЫмЧп) гЪРЧлТРвм жХЫХТЮЩ вХЪбв. ЅШЪЮУФР ЭХ ШбЯЮЫмЧгЩвХ Т split ЮЯХаРвЮа =~, нвЮ ЯаШТЮФШв Ъ ЭХЯаХФбЪРЧгХЬлЬ ЯЮбЫХФбвТШпЬ! split ЯЮФСХаХв ФЫп ЧРФРЭЭЮУЮ ЮЯХаРЭФР ЭгЦЭлЩ жХЫХТЮЩ вХЪбв.
l јл гЦХ ЮСбгЦФРЫШ ЯаЮСЫХЬл, бТпЧРЭЭлХ б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ, бЮТЯРФРойШЬШ б ЯгбвЮЩ бваЮЪЮЩ — ЭРЯаШЬХа, m/x*/ (б. <$R[P#,R7-109]>) Ш s/x*/…/ (б. <$R[P#,R7-110]>). ІЮЧЬЮЦЭЮ, ШЧ-ЧР вЮУЮ, звЮ split ЮСХбЯХзШТРХв ЯЮТвЮаХЭШХ ТЬХбвЮ ЯаЮбвЮУЮ ЯЮШбЪР, бШвгРжШп ТлУЫпФШв УЮаРЧФЮ ЯаЮйХ.
µФШЭбвТХЭЭЮХ ШбЪЫозХЭШХ бЮбвЮШв Т вЮЬ, звЮ ЯгбвЮХ бЮТЯРФХЭШХ Т ЭРзРЫХ бваЮЪШ ЭХ ЯаШТЮФШв Ъ ТЪЫозХЭШо Т бЯШбЮЪ ЭРзРЫмЭЮУЮ ЯгбвЮУЮ нЫХЬХЭвР (еЮвп бЮТЯРФХЭШХ б «ЭШзХЬ» Т ЪЮЭжХ бваЮЪШ ЯаШТЮФШв Ъ ТЪЫозХЭШо Т бЯШбЮЪ ЧРТХаиРойШе Ягбвле нЫХЬХЭвЮТ, нвШ ЯгбвлХ нЫХЬХЭвл РТвЮЬРвШзХбЪШ гФРЫповбп, ХбЫШ ЯаШ ТлЧЮТХ split ЭХ СлЫЮ ЧРФРЭЮ ФЮбвРвЮзЭЮ СЮЫмиЮХ ШЫШ ЮваШжРвХЫмЭЮХ ЧЭРзХЭШХ ваХвмХУЮ ЮЯХаРЭФР).
ЅРЯаШЬХа, m/\W*/ бЮТЯРФРХв Т бваЮЪХ lwrTlwrhlwrilwrs, "Tlwrhlwralwrt", Olwrtlwrhlwrelwrr! Т гЪРЧРЭЭле ЬХбвРе (ЯЮФзХаЪЭгвле ШЫШ ЮСЮЧЭРзХЭЭле lwr ЯаШ ЯгбвЮЬ бЮТЯРФХЭШШ). ёЧ-ЧР нвЮУЮ ШбЪЫозХЭШп ЯгбвЮХ бЮТЯРФХЭШХ Т ЭРзРЫХ бваЮЪШ ШУЭЮаШагХвбп. ѕбвРХвбп 13 бЮТЯРФХЭШЩ, ЯаШТЮФпйШе Ъ ЯЮбваЮХЭШо бЯШбЪР ШЧ 14 нЫХЬХЭвЮТ:
('T', 'h', 'i', 's', 'T', 'h', 'a', 't', 'O', 't', 'h', 'e', 'r', '')
єЮЭХзЭЮ, ХбЫШ ваХвШЩ ЮЯХаРЭФ ЭХ гЪРЧРЭ, ЧРТХаиРойШЩ ЯгбвЮЩ нЫХЬХЭв гФРЫпХвбп.
l їгбвЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ, ЯХаХФРТРХЬЮХ ЯаШ ТлЧЮТХ split, ЮЧЭРзРХв ЭХ «ШбЯЮЫмЧЮТРвм вХЪгйХХ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯЮ гЬЮЫзРЭШо», Р «аРЧСШТРвм бваЮЪг ЯЮбЫХ ЪРЦФЮУЮ бШЬТЮЫР». ЅРЯаШЬХа, ФЫп ТбвРТЪШ ЪЮЬСШЭРжШШ «ЧРСЮЩ-ЯЮФзХаЪШТРЭШХ» ЯЮбЫХ ЪРЦФЮУЮ бШЬТЮЫР $text ЬЮЦЭЮ ТЮбЯЮЫмЧЮТРвмбп ЪЮЬРЭФЮЩ
$text = join "\b_", split(//, $text, -1);
ІЯаЮзХЬ, ЯЮ апФг ЯаШзШЭ (еЮвп Сл ЯЮ бЮЮСаРЦХЭШпЬ ЭРУЫпФЭЮбвШ) ЫгзиХ ТЮбЯЮЫмЧЮТРвмбп ЪЮЬРЭФЮЩ $text =~ s/(.)/$1\b_/g.
l ёбЯЮЫмЧЮТРЭШХ аХУгЫпаЭЮУЮ ТлаРЦХЭШп Т ЮЯХаРвЮаХ split ЭХ ТЫШпХв ЭР аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯЮ гЬЮЫзРЭШо ФЫп ЯЮбЫХФгойШе ЮЯХаРвЮаЮТ ЯЮШбЪР Ш ЧРЬХЭл. єаЮЬХ вЮУЮ, split ЭХ гбвРЭРТЫШТРХв ЧЭРзХЭШп ЯХаХЬХЭЭле $&, $', $1 Ш в. Ф. І ЮвЭЮиХЭШШ ЯЮСЮзЭле нддХЪвЮТ split ЯЮЫЭЮбвмо ШЧЮЫШагХвбп Юв ЮбвРЫмЭле зРбвХЩ ЯаЮУаРЬЬл.
l јЮФШдШЪРвЮа /g Т split ЭХ ШЬХХв бЬлбЫР (еЮвп Ш ТаХФР ЭХ ЯаШЭЮбШв).
l БЯХжШРЫмЭлЩ ЮУаРЭШзШвХЫм аХУгЫпаЭле ТлаРЦХЭШЩ ?…? Т split ЭХ ШЬХХв ЮбЮСЮЩ ШЭвХаЯаХвРжШШ<$M[R7-112]> [20 б.<$R[P#,R7-111]>].
ѕЯХаРЭФ, ЪЮвЮалЩ ЯаХФбвРТЫпХв бЮСЮЩ бваЮЪг (ЭХ аХУгЫпаЭЮХ ТлаРЦХЭШХ!), бЮбвЮпйго аЮТЭЮ ШЧ ЮФЭЮУЮ ЯаЮСХЫР — ЮбЮСлЩ бЫгзРЩ. ѕЭ ЯЮзвШ нЪТШТРЫХЭвХЭ /\s+/, ХбЫШ ЭХ бзШвРвм ШУЭЮаШаЮТРЭШп ЭРзРЫмЭле ЯаЮЯгбЪЮТ. НвР ЪЮЭбвагЪжШп ЯаХФЭРЧЭРзРЫРбм ФЫп ШЬШвРжШШ бвРЭФРавЭЮУЮ аРЧСШХЭШп ЯЮ аРЧФХЫШвХЫпЬ ТеЮФЭле ЧРЯШбХЩ Т awk, ЭЮ ЮЭР, ЭХбЮЬЭХЭЭЮ, ЭРеЮФШв ЭХЬРЫЮ ЯаШЬХЭХЭШЩ Ш Т СЮЫХХ ЮСйШе бЫгзРпе.
ЅРЯаШЬХа, ТлЧЮТ split('spc', "spcspcspcthisspcspcspcisspcaspcspcspcspcspctest") ТЮЧТаРйРХв бЯШбЮЪ ШЧ зХвлаХе нЫХЬХЭвЮТ: ('this', 'is', 'a', 'test'). ґЫп баРТЭХЭШп аРббЬЮваШЬ ЭХЯЮбаХФбвТХЭЭЮХ ШбЯЮЫмЧЮТРЭШХ m/\s+/. І нвЮЬ бЫгзРХ ЭРзРЫмЭлХ ЯаЮЯгбЪШ ЭХ ШУЭЮаШаговбп, Ш ЪЮЬРЭФР ТХаЭХв бЯШбЮЪ ('', 'this', 'is', 'a', 'test').
ЅРЪЮЭХж, ЮСР бЫгзРп ЧРЬХвЭЮ ЮвЫШзРовбп Юв ЯаШЬХЭХЭШп m/spc/, ЯаШ ЪЮвЮаЮЬ СгФгв ЭРЩФХЭл бЮТЯРФХЭШп Ш ФЫп ТЭгваХЭЭШе ЯаЮСХЫЮТ:
('', '', '', 'this', '', '', 'is', 'a', '', '', '', '', 'test')
»оСЮХ ЮСйХХ ТлаРЦХЭШХ Perl, ШбЯЮЫмЧЮТРЭЭЮХ Т ЪРзХбвТХ ЯХаТЮУЮ ЮЯХаРЭФР split, ТлзШбЫпХвбп ЭХЧРТШбШЬЮ, ЯаХЮСаРЧгХвбп Ъ бваЮЪЮТЮЬг ТШФг Ш ШЭвХаЯаХвШагХвбп ЪРЪ аХУгЫпаЭЮХ ТлаРЦХЭШХ. ЅРЯаШЬХа, ЪЮЬРЭФР split(/\s+/, …) ШФХЭвШзЭР split('\s+', …), ЧР ШбЪЫозХЭШХЬ вЮУЮ, звЮ Т ЯХаТЮЬ бЫгзРХ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЪЮЬЯШЫШагХвбп вЮЫмЪЮ ЮФШЭ аРЧ, Р ТЮ ТвЮаЮЬ — ЯаШ ЪРЦФЮЬ ТлЯЮЫЭХЭШШ split<$M[R7-114]> [21 б.<$R[P#,R7-113]>].
І Perl5 Т вЮЬ бЫгзРХ, ХбЫШ ЯХаТлЩ ЮЯХаРЭФ ЭХ гЪРЧРЭ (звЮ Т ЯаШЭжШЯХ ЮвЫШзЭЮ Юв // ШЫШ ''), ЯЮ гЬЮЫзРЭШо ШбЯЮЫмЧгХвбп 'spc'. ВРЪШЬ ЮСаРЧЮЬ, ТлЧЮТ split СХЧ ЮЯХаРЭФЮТ нЪТШТРЫХЭвХЭ split('spc',$_, 0)<$M[R7-116]> [22 б.<$R[P#,R7-115]>].
І Perl4 ЯЮФФХаЦШТРЫбп ТРаШРЭв split ФЫп бЪРЫпаЭЮУЮ ЪЮЭвХЪбвР, ТЮЧТаРйРТиШЩ ЪЮЫШзХбвТЮ даРУЬХЭвЮТ ТЬХбвЮ бЯШбЪР, Р бЯШбЮЪ даРУЬХЭвЮТ ЯаШбТРШТРЫбп ЯХаХЬХЭЭЮЩ @_ Т ЪРзХбвТХ ЯЮСЮзЭЮУЮ нддХЪвР. ЕЮвп Т ЭРбвЮпйХХ ТаХЬп нвР ТЮЧЬЮЦЭЮбвм ЯЮФФХаЦШТРХвбп Ш Т Perl5, ЯЮЫмЧЮТРвмбп ХЩ ЭХ аХЪЮЬХЭФгХвбп, Ш Т СЫШЦРЩиХЬ СгФгйХЬ ЮЭР, ТХаЮпвЭЮ, ШбзХЧЭХв. µбЫШ ЯаХФгЯаХЦФХЭШп ТЪЫозХЭл (ЪРЪ нвЮ ЮСлзЭЮ ФЮЫЦЭЮ Слвм), ЯаШ ШбЯЮЫмЧЮТРЭШШ split Т бЪРЫпаЭЮЬ ЪЮЭвХЪбвХ УХЭХаШагХвбп ЯаХФгЯаХЦФХЭШХ.
ёбЯЮЫмЧЮТРЭШХ бЮеаРЭпойШе<$M[R7-57]> ЪагУЫле бЪЮСЮЪ Т ЯХаТЮЬ ЮЯХаРЭФХ split ШЧЬХЭпХв ЯаШЭжШЯ аРСЮвл split. І нвЮЬ бЫгзРХ ТЮЧТаРйРХЬлЩ ЬРббШТ бЮФХаЦШв ФЮЯЮЫЭШвХЫмЭлХ, ЭХЧРТШбШЬлХ нЫХЬХЭвл, зХаХФгойШХбп б нЫХЬХЭвРЬШ, бЮТЯРТиШХ б ЯЮФТлаРЦХЭШпЬШ Т ЪагУЫле бЪЮСЪРе. НвЮ ЮЧЭРзРХв, звЮ вХЪбв, ЮСлзЭЮ ЯЮЫЭЮбвмо ШбЪЫозРТиШЩбп split ЯаШ аРЧСШХЭШШ, вХЯХам ТЪЫозРХвбп Т ТЮЧТаРйРХЬлЩ бЯШбЮЪ.
І Perl4 нвЮ ЯаШЭЮбШЫЮ СЮЫмиХ ТаХФР, зХЬ ЯЮЫмЧл, ЯЮбЪЮЫмЪг Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ ЭХЫмЧп СлЫЮ (СХЧ ЮбЮСле гбШЫШЩ) ШбЯЮЫмЧЮТРвм ЪагУЫлХ бЪЮСЪШ, ЯаХФЭРЧЭРзХЭЭлХ вЮЫмЪЮ ФЫп УагЯЯШаЮТЪШ. µбЫШ УагЯЯШаЮТЪР СлЫР ХФШЭбвТХЭЭЮЩ жХЫмо, вЮ ЧРУаЮЬЮЦФХЭШХ ТЮЧТаРйРХЬЮУЮ бЯШбЪР ФЮЯЮЫЭШвХЫмЭлЬШ нЫХЬХЭвРЬШ ЮЯаХФХЫХЭЭЮ ЭХ ЮСаРФгХв. ВХЯХам, ЪЮУФР ЬЮЦЭЮ ТлСаРвм бвШЫм ЪагУЫле бЪЮСЮЪ (бЮеаРЭпойШХ ШЫШ ЭХ-бЮеаРЭпойШХ), нвЮ ТЮШбвШЭг ЧРЬХзРвХЫмЭРп ТЮЧЬЮЦЭЮбвм. ЅРЯаШЬХа, Т ЯаЮжХббХ ЮСаРСЮвЪШ HTML-ЪЮФР ЪЮЬРЭФР split(/(<[^>]>)/) ФЫп вХЪбвР
…spcandspc<B>veryspc<FONTspccolor=red>very</FONT>spcmuch</B>spceffort…
ТЮЧТаРйРХв бЯШбЮЪ
('...spcandspc', '<B>', 'veryspc', '<FONTspccolor=red>',
'very', '</FONT>, 'spcmuch', '</B>, 'spceffort...' )
ІЮЧЬЮЦЭЮ, аРСЮвРвм б нвШЬ бЯШбЪЮЬ СгФХв ЯаЮйХ, зХЬ бЮ бваЮЪЮЩ. НвЮв ЯаШЬХа аРСЮвРХв Ш Т Perl4, ЭЮ ХбЫШ Тл ЧРеЮвШвХ, звЮСл аХУгЫпаЭЮХ ТлаРЦХЭШХ аРбЯЮЧЭРТРЫЮ, бЪРЦХЬ, ЯаЮбвлХ бваЮЪШ Т ЪРТлзЪРе ["[^"]*"] ТЭгваШ вХУЮТ (звЮ, ТХаЮпвЭЮ, ЭХЮСеЮФШЬЮ ФЫп ЭЮаЬРЫмЭЮЩ аРСЮвл б HTML), г ТРб ТЮЧЭШЪЭгв ЯаЮСЫХЬл, ЯЮбЪЮЫмЪг ЯЮЫЭЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ СгФХв ТлУЫпФХвм ЯаШЬХаЭЮ вРЪ[45]:
[(<[^>"]*("[^"]*"[^>"]*)*>)]
ґЮЯЮЫЭШвХЫмЭРп ЯРаР ЪагУЫле бЪЮСЮЪ ЮЧЭРзРХв, звЮ ФЫп ЪРЦФЮУЮ бЮТЯРФХЭШп Т ЯаЮжХббХ аРЧСШХЭШп СгФХв ТЮЧТаРйРвмбп ФЮЯЮЫЭШвХЫмЭлЩ нЫХЬХЭв, Т аХЧгЫмвРвХ зХУЮ split ТЮЧТаРйРХв ЯЮ ФТР нЫХЬХЭвР ЭР бЮТЯРФХЭШХ ЯЮЬШЬЮ ЮСлзЭле нЫХЬХЭвЮТ, бЮЮвТХвбвТгойШе даРУЬХЭвРЬ аРЧСШвЮЩ бваЮЪШ. ґЮЯгбвШЬ, ЪЮЬРЭФР ЯаШЬХЭпХвбп Ъ бваЮЪХ
Please <A HREF="test">press me</A>today
І нвЮЬ бЫгзРХ ТЮЧТаРйРХвбп бЫХФгойШЩ аХЧгЫмвРв:
( 'Pleasespc', ЯХаХФ ЯХаТлЬ бЮТЯРФХЭШХЬ
'<AspcHREF="test">', '"test"', ШЧ ЯХаТЮУЮ бЮТЯРФХЭШп
'press me', ЬХЦФг бЮТЯРФХЭШпЬШ
'</A>', '', ШЧ ТвЮаЮУЮ бЮТЯРФХЭШп
'spctoday' ЯЮбЫХ ЯЮбЫХФЭХУЮ бЮТЯРФХЭШп
)
»ШиЭШХ нЫХЬХЭвл ЧРУаЮЬЮЦФРов бЯШбЮЪ. ЅЮ ХбЫШ ТЬХбвЮ ФЮЯЮЫЭШвХЫмЭле бЪЮСЮЪ ШбЯЮЫмЧЮТРвм [(?:…)], аРСЮвРвм бЮ split бвРЭЮТШвбп гФЮСЭХХ, Ш ЪЮЬРЭФР ТЮЧТаРйРХв бЫХФгойШЩ аХЧгЫмвРв:
( 'Pleasespc', ЯХаХФ ЯХаТлЬ бЮТЯРФХЭШХЬ
'<AspcHREF="test">', ШЧ ЯХаТЮУЮ бЮТЯРФХЭШп
'press me', ЬХЦФг бЮТЯРФХЭШпЬШ
'</A>', ШЧ ТвЮаЮУЮ бЮТЯРФХЭШп
'spctoday' ЯЮбЫХ ЯЮбЫХФЭХУЮ бЮТЯРФХЭШп
)
<$M[R7-6]>їаЮСЫХЬл нддХЪвШТЭЮбвШ Т Perl ЮСлзЭЮ аХиРовбп вРЪ ЦХ, ЪРЪ Ш ТЮ ТбХе ЮбвРЫмЭле ЯаЮУаРЬЬРе б ваРФШжШЮЭЭлЬ ЬХеРЭШЧЬЮЬ Ѕє° — ЧР бзХв ШбЯЮЫмЧЮТРЭШп ЯаШХЬЮТ, ЮЯШбРЭЭле Т УЫРТХ 5: ТЭгваХЭЭШе ЮЯвШЬШЧРжШЩ, аРбЪагвЪШ Ш в. Ф. ІбХ нвШ ЯаШХЬл ЮвЭЮбпвбп Ш Ъ Perl.
єЮЭХзЭЮ, бгйХбвТгов Ш ЯаШХЬл, бЯХжШдШзХбЪШХ ФЫп Perl — ЭРЯаШЬХа, ЯаШЬХЭХЭШХ ЭХ-бЮеаРЭпойШе ЪагУЫле бЪЮСЮЪ ТЮ ТбХе бЫгзРпе, ЪЮУФР ЭХв ЭХЮСеЮФШЬЮбвШ Т бЮеаРЭХЭШШ вХЪбвР. БгйХбвТгов Ш ФагУШХ, СЮЫХХ ТРЦЭлХ ЯаЮСЫХЬл, Ш ФРЦХ ЯаШЬХЭХЭШХ бЮеаРЭпойШе ЪагУЫле бЪЮСЮЪ ТЬХбвЮ ЭХ-бЮеаРЭпойШе ЭХ бТЮФШвбп Ъ ЬШЪаЮ-ЮЯвШЬШЧРжШШ, аРббЬЮваХЭЭЮЩ Т УЫРТХ 5 (б. <$R[P#,R5-24]>). І нвЮЬ аРЧФХЫХ Ьл аРббЬЮваШЬ нвг вХЬг (б. <$R[P#,R7-4]>), Р вРЪЦХ ЭХЪЮвЮалХ ФагУШХ ТЮЯаЮбл.
l Г ЪРЦФЮЩ ЧРФРзШ Хбвм ЭХбЪЮЫмЪЮ аХиХЭШЩ. Perl — ЭРСЮа ШЭбвагЬХЭвЮТ, ЯЮЧТЮЫпойШЩ аХиШвм ЮФЭг Ш вг ЦХ ЧРФРзг ЭХбЪЮЫмЪШЬШ бЯЮбЮСРЬШ. ГЬХЭШХ УаРЬЮвЭЮ ШФХЭвШдШжШаЮТРвм ЧРФРзг ЯаЮШбеЮФШв ШЧ ЮбЮЧЭРЭШп «їгвШ Perl», Р гЬХЭШХ ТлСаРвм ЯаРТШЫмЭлЩ ШЭбвагЬХЭв ФЫп ХХ аХиХЭШп пТЫпХвбп СЮЫмиШЬ иРУЮЬ ЭР ЯгвШ Ъ ЯЮбваЮХЭШо СЮЫХХ нддХЪвШТЭле Ш ЯЮЭпвЭле ЯаЮУаРЬЬ. ёЭЮУФР нддХЪвШТЭЮбвм Ш ЭРУЫпФЭЮбвм ЯаЮУаРЬЬл ЪРЦгвбп ТЧРШЬЮШбЪЫозРойШЬШ ваХСЮТРЭШпЬШ, ЭЮ ЫгзиХХ ЯЮЭШЬРЭШХ ТЮЯаЮбР ЯЮЬЮЦХв ТРЬ б ЯаРТШЫмЭлЬ ТлСЮаЮЬ баХФбвТ.
l ёЭвХаЯЮЫпжШп. ёЭвХаЯЮЫпжШп Ш ЪЮЬЯШЫпжШп аХУгЫпаЭле ТлаРЦХЭШЩ-ЮЯХаРЭФЮТ — СЫРУЮФРвЭРп ЯЮзТР ФЫп нЪЮЭЮЬШШ ТаХЬХЭШ. јЮФШдШЪРвЮа /o, Ю ЪЮвЮаЮЬ п ЯаРЪвШзХбЪШ ЭХ гЯЮЬШЭРЫ, ЯЮЧТЮЫпХв зРбвШзЭЮ гЯаРТЫпвм ЧРваРвЭлЬ ЯаЮжХббЮЬ ЯЮТвЮаЭЮЩ ЪЮЬЯШЫпжШШ.
l ·РваРвл $& ·ЭРзХЭШп ваХе ЯХаХЬХЭЭле $`, $& Ш $' ЯаШбТРШТРовбп Т ЪРзХбвТХ ЯЮСЮзЭЮУЮ нддХЪвРЬ ЯЮШбЪР. НвШ ЯХаХЬХЭЭлХ гФЮСЭл, ЭЮ ЫоСЮХ ШбЯЮЫмЧЮТРЭШХ Ше Т бжХЭРаШШ ЮваШжРвХЫмЭЮ ТЫШпХв ЭР ХУЮ нддХЪвШТЭЮбвм. ±ЮЫХХ вЮУЮ, нвШ ЯХаХЬХЭЭлХ ФРЦХ ЭХЮСпЧРвХЫмЭЮ ШбЯЮЫмЧЮТРвм — ТХбм бжХЭРаШЩ бваРФРХв ФРЦХ Т вЮЬ бЫгзРХ, ХбЫШ ЮФЭР ШЧ нвШе ЯХаХЬХЭЭле ЯаЮбвЮ ЯаШбгвбвТгХв Т ЭХЬ.
l ·РваРвл /i ёбЯЮЫмЧЮТРЭШХ ЬЮФШдШЪРвЮаР /i вРЪЦХ ТЫХзХв ЧР бЮСЮЩ ЧРваРвл. µбЫШ Тл аРСЮвРХвХ б ЮзХЭм ФЫШЭЭЮЩ жХЫХТЮЩ бваЮЪЮЩ, ЯЮбвРаРЩвХбм ЯХаХЯШбРвм аХУгЫпаЭЮХ ТлаРЦХЭШХ вРЪ, звЮСл ШЧСХЦРвм ШбЯЮЫмЧЮТРЭШп /i.
l їЮФбвРЭЮТЪР ЗвЮСл ШЧТЫХзм ЬРЪбШЬгЬ ЯЮЫмЧл ШЧ ЮЯвШЬШЧРжШЩ ЯЮФбвРЭЮТЮЪ Т Perl, ЭХЮСеЮФШЬЮ ЧЭРвм, ЪЮУФР ТлЯЮЫЭповбп ЮЯвШЬШЧРжШШ, звЮ ЮЭШ ФРов Ш звЮ ЬЮЦХв ЯЮЬХиРвм Ше ЯаШЬХЭХЭШо.
l ЕаЮЭЮЬХваРЦ І ЪЮЭХзЭЮЬ бзХвХ бРЬРп СлбваРп ЯаЮУаРЬЬР — вР, ЪЮвЮаРп ЯХаТЮЩ ЧРЪРЭзШТРХв бТЮо аРСЮвг. ЕаЮЭЮЬХваРЦ ТбХУФР ЯЮЧТЮЫпХв ЭРШСЮЫХХ ЮСкХЪвШТЭЮ ЮжХЭШвм бЪЮаЮбвм аРСЮвл ЯаЮУаРЬЬЭЮУЮ ЪЮФР, СгФм вЮ ЬРЫХЭмЪРп дгЭЪжШп, СЮЫмиЮЩ даРУЬХЭв ШЫШ жХЫРп ЯаЮУаРЬЬР, аРСЮвРойРп б аХРЫмЭлЬШ ФРЭЭлЬШ. І Perl бгйХбвТгов ЯаЮбвлХ Ш гФЮСЭлХ баХФбвТР еаЮЭЮЬХваРЦР, еЮвп г нвЮЩ ЧРФРзШ, ЪРЪ г СЮЫмиШЭбвТР ЮбвРЫмЭле, вЮЦХ бгйХбвТгХв ЭХбЪЮЫмЪЮ аХиХЭШЩ. П ЯЮЪРЦг ТРЬ вЮв бЯЮбЮС, ЪЮвЮалЬ ЯЮЫмЧгобм бРЬ — ЯаЮбвЮЩ ЯаШХЬ, ЯаШ ЯЮЬЮйШ ЪЮвЮаЮУЮ п ЯаЮТХЫ ЭХбЪЮЫмЪЮ бЮв вХбвЮТ ТЮ ТаХЬп аРСЮвл ЭРФ ЪЭШУЮЩ.
l Study ДгЭЪжШп study(…) бгйХбвТгХв Т Perl б ЭХЧРЯРЬпвЭле ТаХЬХЭ. єРЪ ЯаРТШЫЮ, ЬЭЮУШХ звЮ-вЮ бЫлиРЫШ Ю вЮЬ, звЮ study гбЪЮапХв ЮСаРСЮвЪг аХУгЫпаЭле ТлаРЦХЭШЩ, ЭЮ ЫШим ЭХЬЭЮУШХ ЯЮЭШЬРов, звЮ ЦХ ШЬХЭЭЮ ЮЭР ФХЫРХв. їЮбЬЮваШЬ, гФРбвбп ЫШ ЭРЬ Т нвЮЬ аРЧЮСаРвмбп.
l єЫоз -dr їаШ ЯЮЬЮйШ дЫРУР ЮвЫРФЪШ аХУгЫпаЭле ТлаРЦХЭШЩ Perl ЬЮЦЭЮ ЯЮЫгзШвм ШЭдЮаЬРжШо Ю вЮЬ, ЪРЪШХ ТШФл ЮЯвШЬШЧРжШЩ ТлЯЮЫЭповбп ШЫШ ЭХ ТлЯЮЫЭповбп ЬХеРЭШЧЬЮЬ аХУгЫпаЭле ТлаРЦХЭШЩ. ІбЪЮаХ Тл гЧЭРХвХ, ЪРЪ нвЮ ФХЫРХвбп, Ш ЧРбвРТШвХ Perl ЯЮФХЫШвмбп ЭХЪЮвЮалЬШ бХЪаХвРЬШ.
ґЮТЮЫмЭЮ зРбвЮ Ъ аХиХЭШо ЪЮЭЪаХвЭЮЩ ЧРФРзШ ЬЮЦЭЮ ЯЮФЮЩвШ аРЧЭлЬШ бЯЮбЮСРЬШ, ЯЮнвЮЬг ЭХв ЭШзХУЮ, звЮ ЧРЬХЭШЫЮ Сл еЮаЮиго ЮбТХФЮЬЫХЭЭЮбвм Т ТЮЯаЮбРе СРЫРЭбШаЮТЪШ нддХЪвШТЭЮбвШ Ш ЭРУЫпФЭЮбвШ ЯаЮУаРЬЬ Т Perl. АРббЬЮваШЬ ЯаЮбвЮЩ ЯаШЬХа — ФЮЯЮЫЭХЭШХ IP-РФаХбЮТ (18.181.0.24) ЭгЫпЬШ, звЮСл ЪРЦФлЩ ШЧ зХвлаХе ЪЮЬЯЮЭХЭвЮТ бЮбвЮпЫ аЮТЭЮ ШЧ ваХе жШда (018.181.000.024). ѕФЭЮ ЯаЮбвЮХ Ш ЭРУЫпФЭЮХ аХиХЭШХ ТлУЫпФШв вРЪ:
$ip = sprintf "%03d.%03d.%03d.%03d", split(/\./, $ip);
НвЮ еЮаЮиХХ, ЭЮ ЭХ ХФШЭбвТХЭЭЮХ аХиХЭШХ. АРббЬЮваШЬ ФагУШХ ЯЮФеЮФл Ъ аХиХЭШо нвЮЩ ЧРФРзШ. єЮЭХзЭЮ, ЭРи ЯаШЬХа ЯаЮбв Ш ЭХ ЮбЮСХЭЭЮ ШЭвХаХбХЭ, ЮФЭРЪЮ ЯЮФЮСЭлХ бШвгРжШШ зРбвЮ ТЮЧЭШЪРов ЯаШ ЮСаРСЮвЪХ вХЪбвЮТ. їаЮбвЮвР ЧРФРзШ ЯЮЧТЮЫШв ЭРЬ бЪЮЭжХЭваШаЮТРвмбп ЭР аРЧЫШзЭле ЯЮФеЮФРе Ъ ЯаШЬХЭХЭШо Perl. БгйХбвТгов Ш ФагУШХ аХиХЭШп:
1. $ip =~ s/(\d+)/sprintf("%03d", $1)/eg;
2. $ip =~ s/\b(\d{1,2}\b)/sprintf("%03d", $1)/eg;
3. $ip = sprintf("%03d.%03d.%03d.%03d", $ip =~ m/(\d+)/g);
4. $ip =~ s/\b(\d\d?\b)/'0' x (3-length($1)) . $1/eg;
5. $ip = sprintf("%03d.%03d.%03d.%03d",
$ip =~ m/^(\d+)\.(\d+)\.(\d+)\.(\d+)$/);
6. $ip =~ s/\b(\d(\d?)\b)/$2 eq '' ? "00$1" : "0$1"/eg;
7. $ip =~ s/\b(\d\b)/00$1/g;
$ip =~ s/\b(\d\d\b)/0$1/g;
ІбХ нвШ аХиХЭШп ФЫп ЯаРТШЫмЭЮУЮ IP-РФаХбР ТлФРов вХ ЦХ аХЧгЫмвРвл, звЮ Ш ШбеЮФЭлЩ ТРаШРЭв, ЭЮ ЯаШ ЮиШСЪХ Т ФРЭЭле ЪРЦФЮХ ШЧ ЭШе ТХФХв бХСп ЯЮ-бТЮХЬг. µбЫШ бгйХбвТгХв ТХаЮпвЭЮбвм ЯЮЫгзХЭШп ШбЪРЦХЭЭле ФРЭЭле, ЫоСЮУЮ ШЧ нвШе аХиХЭШЩ ЮЪРЦХвбп ЭХФЮбвРвЮзЭЮ. єаЮЬХ вЮУЮ, ЬХЦФг ЯаШТХФХЭЭлЬШ аХиХЭШпЬШ бгйХбвТгов ЯаРЪвШзХбЪШ ЮвЫШзШп, бТпЧРЭЭлХ б нддХЪвШТЭЮбвмо Ш ЭРУЫпФЭЮбвмо. ІЯаЮзХЬ, звЮ ЪРбРХвбп ЭРУЫпФЭЮбвШ, вЮ б ЯХаТЮУЮ ТЧУЫпФР ЮСЮ ТбХе нвШе ТлаРЦХЭШпе ЬЮЦЭЮ бЪРЧРвм ЮФЭЮ — ЮЭШ ТлУЫпФпв Т ЫгзиХЬ бЫгзРХ ЧРУРФЮзЭЮ.
° ЪРЪ ЦХ нддХЪвШТЭЮбвм? П ЯаЮвХбвШаЮТРЫ ТбХ нвШ аХиХЭШп ЭР бТЮХЬ ЪЮЬЯмовХаХ б Perl ТХабШШ 5.003, Ш ЯаШТХФХЭЭлЩ ТлиХ бЯШбЮЪ гЯЮапФЮзХЭ Юв ЭРШЬХЭХХ нддХЪвШТЭЮУЮ Ъ ЭРШСЮЫХХ нддХЪвШТЭЮЬг аХиХЭШо. ёбеЮФЭЮХ аХиХЭШХ ЭРеЮФШвбп УФХ-вЮ ЬХЦФг зХвТХавлЬ Ш ЯпвлЬ нЫХЬХЭвЮЬ бЯШбЪР. »гзиХХ аХиХЭШХ ЧРЭШЬРХв ТбХУЮ 80 ЯаЮжХЭвЮТ Юв ТаХЬХЭШ ХУЮ аРСЮвл, Р егФиХХ — ЮЪЮЫЮ 160 ЯаЮжХЭвЮТ[46]. ЅЮ ХбЫШ нддХЪвШТЭЮбвм ФХЩбвТШвХЫмЭЮ ТРЦЭР, бгйХбвТгов Ш СЮЫХХ СлбвалХ аХиХЭШп:
substr($ip, 0, 0) = '0' if substr($ip, 1, 1) eq '.';
substr($ip, 0, 0) = '0' if substr($ip, 2, 1) eq '.';
substr($ip, 4, 0) = '0' if substr($ip, 5, 1) eq '.';
substr($ip, 4, 0) = '0' if substr($ip, 6, 1) eq '.';
substr($ip, 8, 0) = '0' if substr($ip, 9, 1) eq '.';
substr($ip, 8, 0) = '0' if substr($ip, 10, 1) eq '.';
substr($ip, 12, 0) = '0' while length($ip) < 15;
НвЮ аХиХЭШХ аРСЮвРХв ЯЮзвШ ТФТЮХ СлбваХХ ЮаШУШЭРЫР, ЭЮ аРЧСШаРвмбп Т ЭХЬ ЯаШеЮФШвбп ЧЭРзШвХЫмЭЮ ФЮЫмиХ. ІлСЮа аХиХЭШп ЮбвРХвбп ЧР ТРЬШ. ІЮЧЬЮЦЭЮ, Тл ЯаШФгЬРХвХ Ш ФагУШХ бЯЮбЮСл. їЮЬЭШвХ УЫРТЭЮХ ЯаРТШЫЮ Perl: «Г ЪРЦФЮЩ ЧРФРзШ Хбвм ЭХбЪЮЫмЪЮ аХиХЭШЩ».
<$M[R7-50]>І аРЧФХЫХ «їаХФТРаШвХЫмЭРп ЮСаРСЮвЪР бваЮЪ Ш ШЭвХаЯЮЫпжШп ЯХаХЬХЭЭле» СлЫЮ ЯЮЪРЧРЭЮ, звЮ ЮСаРСЮвЪР бжХЭРаШХТ Perl ФХЫШвбп ЭР ЭХбЪЮЫмЪЮ дРЧ. ІбХ ФХЩбвТШп, ЯаХФбвРТЫХЭЭлХ ЭР аШб. 7.1 (б. <$R[P#,R7-117]>), ЬЮУгв Слвм бЮЯапЦХЭл б ЭХЬРЫлЬШ ЧРваРвРЬШ. ІЮЧЬЮЦХЭ бЫХФгойШЩ ТРаШРЭв ЮЯвШЬШЧРжШШ: Perl ЯЮЭШЬРХв, звЮ ЯаШ ЮвбгвбвТШШ ШЭвХаЯЮЫпжШШ ЯХаХЬХЭЭле СХббЬлбЫХЭЭЮ ЧРЭЮТЮ ТлЯЮЫЭпвм ТбХ дРЧл ЯаШ ЪРЦФЮЬ ЯаШЬХЭХЭШШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп — ХбЫШ ШЭвХаЯЮЫпжШп ЭХ ТлЯЮЫЭпХвбп, аХУгЫпаЭЮХ ТлаРЦХЭШХ ЭХ ШЧЬХЭпХвбп ЬХЦФг ЯаШЬХЭХЭШпЬШ. І вРЪШе бЫгзРпе ТЭгваХЭЭХХ ЯаХФбвРТЫХЭШХ бЮеаРЭпХвбп ЯаШ ЯХаТЮЩ ЪЮЬЯШЫпжШШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, Р ЧРвХЬ ШбЯЮЫмЧгХвбп ФЫп ТбХе ЯЮбЫХФгойШе ЯаШЬХЭХЭШЩ вХЬ ЦХ бРЬлЬ ЮЯХаРвЮаЮЬ. їаШ нвЮЬ нЪЮЭЮЬШвбп ЧЭРзШвХЫмЭлЩ ЮСкХЬ аРСЮвл, бТпЧРЭЭЮЩ б ЯЮТвЮаЭлЬШ ТлзШбЫХЭШпЬШ.
Б ФагУЮЩ бвЮаЮЭл, ХбЫШ аХУгЫпаЭЮХ ТлаРЦХЭШХ ШЧЬХЭпХвбп ЯаШ ЪРЦФЮЬ ШбЯЮЫмЧЮТРЭШШ, Perl ЯаЮбвЮ ТлЭгЦФХЭ ЮСаРСРвлТРвм ХУЮ ЧРЭЮТЮ. єЮЭХзЭЮ, ЮСаРСЮвЪР ЯаШ нвЮЬ бгйХбвТХЭЭЮ ЧРЬХФЫпХвбп, ЭЮ Т жХЫЮЬ нвЮ ЮзХЭм гФЮСЭРп ТЮЧЬЮЦЭЮбвм, СЫРУЮФРап ЪЮвЮаЮЩ пЧлЪ бвРЭЮТШвбп заХЧТлзРЩЭЮ УШСЪШЬ, Р аХУгЫпаЭЮХ ТлаРЦХЭШХ ЬЮЦХв ШЧЬХЭпвмбп ЯаШ ЪРЦФЮЬ ШбЯЮЫмЧЮТРЭШШ. ІЯаЮзХЬ, ФЮЯЮЫЭШвХЫмЭЮЩ аРСЮвл ШЭЮУФР ЬЮЦЭЮ ШЧСХЦРвм. АРббЬЮваШЬ бШвгРжШо, ЯаШ ЪЮвЮаЮЩ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ ШЭвХаЯЮЫШагХвбп ЯХаХЬХЭЭРп, ЧЭРзХЭШХ ЪЮвЮаЮЩ ЭХ ШЧЬХЭпХвбп ЬХЦФг ШбЯЮЫмЧЮТРЭШпЬШ:
$today = (qw(Sun Mon Tue Wed Thu Fri Sat>)[(localtime)[6]];
# $today бЮФХаЦШв ФХЭм ЭХФХЫШ ("Mon", "Tue" Ш в. Ф.)
$regex = "^$today";
while (<LOGFILE>) {
if (m/$regex/) {
…
·ЭРзХЭШХ ЯХаХЬХЭЭЮЩ $regex ЯаШбТРШТРХвбп ХйХ ФЮ ЭРзРЫР жШЪЫР. ѕФЭРЪЮ ЮЯХаРвЮа ЯЮШбЪР, Т ЪЮвЮаЮЬ ЮЭЮ ШбЯЮЫмЧгХвбп, ЭРеЮФШвбп Т жШЪЫХ, ЯЮнвЮЬг ЮЭ ЯаШЬХЭпХвбп бЭЮТР Ш бЭЮТР, ЯЮ ЮФЭЮЬг аРЧг ФЫп ЪРЦФЮЩ бваЮЪШ <LOGFILE>. јл ЬЮЦХЬ ТЧУЫпЭгвм ЭР бжХЭРаШЩ Ш гСХФШвмбп Т вЮЬ, звЮ нвЮ ЧЭРзХЭШХ Т жШЪЫХ ЭХ ШЧЬХЭпХвбп, ЭЮ Perl нвЮУЮ ЭХ ЧЭРХв. ѕЭ ЧЭРХв ЫШим вЮ, звЮ аХУгЫпаЭЮХ ТлаРЦХЭШХ-ЮЯХаРЭФ бЮФХаЦШв ШЭвХаЯЮЫШагХЬго ЯХаХЬХЭЭго, ЯЮнвЮЬг нвЮв ЮЯХаРЭФ ЭХЮСеЮФШЬЮ ЧРЭЮТЮ ТлзШбЫпвм ЯаШ ЪРЦФЮЬ ШбЯЮЫмЧЮТРЭШШ.
ІЯаЮзХЬ, нвЮ ЭХ ЮЧЭРзРХв, звЮ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯаШФХвбп ЪРЦФлЩ аРЧ ЯЮЫЭЮбвмо ЯХаХЪЮЬЯШЫШаЮТРвм. І ЪРзХбвТХ ЯаЮЬХЦгвЮзЭЮЩ ЮЯвШЬШЧРжШШ Perl ШбЯЮЫмЧгХв ЮвЪЮЬЯШЫШаЮТРЭЭго дЮаЬг, ЮбвРТигобп Юв ЯаХФлФгйХУЮ ШбЯЮЫмЧЮТРЭШп (б вХЬ ЦХ ЮЯХаРЭФЮЬ), ХбЫШ ЯЮТвЮаЭЮХ ТлзШбЫХЭШХ Т ЪЮЭХзЭЮЬ бзХвХ ЯаШТХФХв Ъ вЮЬг ЦХ аХУгЫпаЭЮЬг ТлаРЦХЭШо. їЮЫЭЮЩ ЯХаХЪЮЬЯШЫпжШШ гФРХвбп ШЧСХЦРвм, ЭЮ Т вХе бЫгзРпе, ЪЮУФР аХУгЫпаЭЮХ ТлаРЦХЭШХ ЭХ ШЧЬХЭпХвбп, ФХЩбвТШп Т дРЧРе B Ш C аШб. 7.1, Р вРЪЦХ ЯаЮТХаЪР вЮЦФХбвТХЭЭЮбвШ аХЧгЫмвРвР дРЪвШзХбЪШ ТлЯЮЫЭповбп ЭРЯаРбЭЮ.
ЅР ЯЮЬЮйм ЯаШеЮФШв ЬЮФШдШЪРвЮа<$M[R7-85]> /o. ѕЭ ЯаШЪРЧлТРХв Perl ЮСаРСЮвРвм Ш ЮвЪЮЬЯШЫШаЮТРвм аХУгЫпаЭЮХ ТлаРЦХЭШХ-ЮЯХаРЭФ ЯаШ ЯХаТЮЬ ШбЯЮЫмЧЮТРЭШШ, ЭЮ ЧРвХЬ бЫХЯЮ ШбЯЮЫмЧЮТРвм вг ЦХ ТЭгваХЭЭоо дЮаЬг ТЮ ТбХе ЯЮбЫХФгойШе ЯаЮТХаЪРе Т вЮЬ ЦХ ЮЯХаРвЮаХ. јЮФШдШЪРвЮа /o «дШЪбШагХв» аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯаШ ЯХаТЮЬ ШбЯЮЫмЧЮТРЭШШ ЮЯХаРвЮаР ЯЮШбЪР. їаШ ЯЮбЫХФгойХЬ ШбЯЮЫмЧЮТРЭШШ СгФХв ЯаШЬХЭпвмбп вЮ ЦХ бРЬЮХ ТлаРЦХЭШХ — ФРЦХ Т бЫгзРХ ШЧЬХЭХЭШп ЯХаХЬХЭЭле, ТеЮФпйШе Т ЮЯХаРЭФ. Perl ЯЮЯаЮбвг ЭХ гвагЦФРХв бХСп ЯаЮТХаЪРЬШ. ѕСлзЭЮ ЬЮФШдШЪРвЮа /o ШбЯЮЫмЧгХвбп ФЫп ЯЮТлиХЭШп нддХЪвШТЭЮбвШ, ХбЫШ Тл ЭХ бЮСШаРХвХбм ШЧЬХЭпвм аХУгЫпаЭЮХ ТлаРЦХЭШХ, ЭЮ Тл ФЮЫЦЭл еЮаЮиЮ ЯЮЭШЬРвм: ФРЦХ ХбЫШ ЯХаХЬХЭЭлХ ШЧЬХЭпвбп, бЫгзРЩЭЮ ШЫШ ЯаХФЭРЬХаХЭЭЮ, ЯаШ ЭРЫШзШШ ЬЮФШдШЪРвЮаР /o Perl ЭХ бвРЭХв ЪЮЬЯШЫШаЮТРвм ШЫШ ЮСаРСРвлТРвм ТлаРЦХЭШХ ЧРЭЮТЮ.
АРббЬЮваШЬ бЫХФгойго бШвгРжШо:
while(…)
{
…
$regex = &GetReply('Item to find');
foreach $item (@items) {
if ($item =~ m/$regex/o) { # јЮФШдШЪРвЮа /o ШбЯЮЫмЧЮТРЭ ФЫп
… # ЯЮТлиХЭШп нддХЪвШТЭЮбвШ
}
}
…
}
їаШ ЯХаТЮЩ ШвХаРжШШ ТЭгваХЭЭХУЮ жШЪЫР foreach (Ш ЯХаТЮЩ ШвХаРжШШ ТЭХиЭХУЮ жШЪЫР while) аХУгЫпаЭЮХ ТлаРЦХЭШХ ЮСаРСРвлТРХвбп Ш ЪЮЬЯШЫШагХвбп, Р ЯЮЫгзХЭЭлЩ аХЧгЫмвРв ШбЯЮЫмЧгХвбп ЯаШ ЯЮШбЪХ. ёЧ-ЧР ЭРЫШзШп ЬЮФШдШЪРвЮаР /o ЮвЪЮЬЯШЫШаЮТРЭЭРп дЮаЬР СгФХв ШбЯЮЫмЧЮТРвмбп ТЮ ТбХе ЯЮбЫХФгойШе ЯЮЯлвЪРе ФЫп ФРЭЭЮУЮ ЮЯХаРвЮаР ЯЮШбЪР. їЮЧФЭХХ, ТЮ ТвЮаЮЩ ШвХаРжШШ ТЭХиЭХУЮ жШЪЫР, ЯЮЫмЧЮТРвХЫм ТТЮФШв ЭЮТЮХ ЧЭРзХЭШХ $regex, ЪЮвЮаЮХ ФЮЫЦЭЮ ШбЯЮЫмЧЮТРвмбп ЯаШ ЭЮТЮЬ ЯЮШбЪХ. ѕФЭРЪЮ ЯаЮШбеЮФШв ЭХзвЮ ЭХЮЦШФРЭЭЮХ — ЬЮФШдШЪРвЮа /o ЮЧЭРзРХв, звЮ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЮЯХаРвЮаР ЪЮЬЯШЫШагХвбп вЮЫмЪЮ ЮФШЭ аРЧ, Ш ЯЮбЪЮЫмЪг нвЮ гЦХ ЯаЮШЧЮиЫЮ, бвРаЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ СгФХв ШбЯЮЫмЧЮТРЭЮ ЧРЭЮТЮ — ЭЮТЮХ ЧЭРзХЭШХ $regex ЯЮЯаЮбвг ШУЭЮаШагХвбп.
їаЮСЫХЬР ЯаЮйХ ТбХУЮ аХиРХвбп гФРЫХЭШХЬ ЬЮФШдШЪРвЮаР /o. їаЮУаРЬЬР СгФХв аРСЮвРвм, ЭЮ вРЪЮХ аХиХЭШХ ЭХ ЮСпЧРвХЫмЭЮ СгФХв ЮЯвШЬРЫмЭлЬ. ЕЮвп ЯаЮЬХЦгвЮзЭРп ЮЯвШЬШЧРжШп ЯаХФЮвТаРйРХв ЯЮЫЭго ЯХаХЪЮЬЯШЫпжШо (ЪаЮЬХ аХРЫмЭЮУЮ ШЧЬХЭХЭШп аХУгЫпаЭЮУЮ ТлаРЦХЭШп ЯаШ ЪРЦФЮЩ ЯХаТЮЩ ШвХаРжШШ ТЭгваХЭЭХУЮ жШЪЫР), ТбХ аРТЭЮ ЪРЦФлЩ аРЧ ЯаШеЮФШвбп ЯаЮТХапвм вЮЦФХбвТХЭЭЮбвм вХЪгйХУЮ аХУгЫпаЭЮУЮ ТлаРЦХЭШп б ЯаХФлФгйШЬ. НвР ЭХнддХЪвШТЭЮбвм пТЫпХвбп ЪагЯЭлЬ ЭХФЮбвРвЪЮЬ, Юв ЪЮвЮаЮУЮ ЭРЬ еЮвХЫЮбм Сл ЯЮ ТЮЧЬЮЦЭЮбвШ ШЧСРТШвмбп.
µбЫШ Ьл ЪРЪШЬ-вЮ ЮСаРЧЮЬ ФЮСмХЬбп вЮУЮ, звЮСл Т аХЧгЫмвРвХ гбЯХиЭЮУЮ бЮТЯРФХЭШп аХУгЫпаЭЮХ ТлаРЦХЭШХ СлЫЮ ТлСаРЭЮ ФЫп ШбЯЮЫмЧЮТРЭШп ЯЮ гЬЮЫзРЭШо, нвЮ ТлаРЦХЭШХ ЬЮЦЭЮ ЯЮТвЮаЭЮ ШбЯЮЫмЧЮТРвм ЯаШ ЯЮЬЮйШ ЪЮЭбвагЪжШШ m// б ЯгбвлЬ аХУгЫпаЭлЬ ТлаРЦХЭШХЬ (б. <$R[P#,R7-86>):
while (...)
{
…
$regex = &GetReply('Item to find');
# ГбвРЭЮТШвм аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯЮ гЬЮЫзРЭШо
# (ваХСгХв гбЯХиЭЮУЮ бЮТЯРФХЭШп)
if ($sample_text !~ m/$regex/) {
die "internal error: sample text didn't match!";
}
foreach $item (@items) {
if ($item =~ m//) { # ёбЯЮЫмЧЮТРвм аХУгЫпаЭЮХ
… # ТлаРЦХЭШХ ЯЮ гЬЮЫзРЭШо
}
}
…
}
є бЮЦРЫХЭШо, ЮСлзЭЮ СлТРХв ФЮТЮЫмЭЮ вагФЭЮ ЭРЩвШ ЯЮФеЮФпйго ЪЮЬРЭФг ФЫп ЭРзРЫмЭЮЩ ЯаЮТХаЪШ, ХбЫШ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЭХ ШЧТХбвЭЮ ЧРаРЭХХ. ЗвЮСл аХУгЫпаЭЮХ ТлаРЦХЭШХ СлЫЮ гбвРЭЮТЫХЭЮ ФЫп ШбЯЮЫмЧЮТРЭШп ЯЮ гЬЮЫзРЭШо, ЭХЮСеЮФШЬЮ гбЯХиЭЮХ бЮТЯРФХЭШХ. єаЮЬХ вЮУЮ (Т бЮТаХЬХЭЭле ТХабШпе Perl) нвЮ бЮТЯРФХЭШХ ЭХ ФЮЫЦЭЮ ЯаЮШЧЮЩвШ Т ФШЭРЬШзХбЪЮЩ ЮСЫРбвШ ТШФШЬЮбвШ, ЪЮвЮаРп гЦХ СлЫР ЯЮЪШЭгвР.
<$M[R7-84]>ЅШЦХ ЯаШТХФХЭЮ аХиХЭШХ, ШЧСРТЫХЭЭЮХ Юв ТбХе ЯХаХзШбЫХЭЭле ЭХФЮбвРвЪЮТ. ЕЮвп аХиХЭШХ ЭХбЪЮЫмЪЮ гбЫЮЦЭШЫЮбм, жХЫм (ЯЮТлиХЭШХ нддХЪвШТЭЮбвШ) зРбвЮ ЮЯаРТФлТРХв баХФбвТР.
while (...)
{
…
$regex = &GetReply('Item to find');
eval 'foreach $item (@items) {
if ($item =~ m/$regex/o) {
…
}
}';
# µбЫШ ЧЭРзХЭШХ $@ ЮЯаХФХЫХЭЮ, ТлЯЮЫЭХЭШХ eval
# ЧРТХаиШЫЮбм б ЮиШСЪЮЩ.
if ($@) {
# ІлТХбвШ бЮЮСйХЭШХ ЮС ЮиШСЪХ ЯаШ ТлЯЮЫЭХЭШШ eval
}
…
}
ѕСаРвШвХ ТЭШЬРЭШХ: ТХбм жШЪЫ foreach ТлЯЮЫЭпХвбп ТЭгваШ бваЮЪШ Т РЯЮбваЮдРе, ЪЮвЮаРп пТЫпХвбп РаУгЬХЭвЮЬ eval. їаШ ЪРЦФЮЩ ЮСаРСЮвЪХ бваЮЪШ ТлЧЮТЮЬ eval бваЮЪР ТЮбЯаШЭШЬРХвбп ЪРЪ ЭЮТлЩ даРУЬХЭв ЪЮФР Perl, ЯЮнвЮЬг Perl ЧРЭЮТЮ РЭРЫШЧШагХв Ш ТлЯЮЫЭпХв ХХ. ІлЯЮЫЭХЭШХ ЯаЮШбеЮФШв «ЭР ЬХбвХ», ЯЮнвЮЬг eval ШЬХХв ФЮбвгЯ ЪЮ ТбХЬ ЯХаХЬХЭЭлЬ ЯаЮУаРЬЬл, бЫЮТЭЮ ЮЭШ пТЫповбп зРбвмо ЪЮФР аХУгЫпаЭЮУЮ ТлаРЦХЭШп. БЮСбвТХЭЭЮ, Тбп бгвм ЯЮФЮСЭЮУЮ ШбЯЮЫмЧЮТРЭШп eval ЪРЪ аРЧ Ш ЧРЪЫозРХвбп Т вЮЬ, звЮСл ЮвЫЮЦШвм РЭРЫШЧ ФЮ ЬЮЬХЭвР, ЪЮУФР ЭРЬ СгФХв ШЧТХбвЭЮ ЪРЦФЮХ ШЧ аХУгЫпаЭле ТлаРЦХЭШЩ.
ґЫп ЭРб Т ЯХаТго ЮзХаХФм ШЭвХаХбЭЮ вЮ, звЮ нвЮв даРУЬХЭв ЧРЭЮТЮ РЭРЫШЧШагХвбп ЯаШ ЪРЦФЮЬ ТлЯЮЫЭХЭШШ eval; ЯаШ нвЮЬ аХУгЫпаЭлХ ТлаРЦХЭШп-ЮЯХаРЭФл вРЪЦХ РЭРЫШЧШаговбп ЧРЭЮТЮ, ЭРзШЭРп б дРЧл A аШб. 7.1 (б. <$R[P#,R7-117]>). ІбЫХФбвТШХ нвЮУЮ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЪЮЬЯШЫШагХвбп ЯаШ ЯХаТЮЬ ХУЮ ШбЯЮЫмЧЮТРЭШШ Т ЯаЮУаРЬЬХ (ЯаШ ЯХаТЮЩ ШвХаРжШШ Т жШЪЫХ foreach), ЭЮ ЭХ ЪЮЬЯШЫШагХвбп ЧРЭЮТЮ ШЧ-ЧР ЯаШбгвбвТШп ЬЮФШдШЪРвЮаР /o. їЮбЫХ ЧРТХаиХЭШп eval нвЮв нЪЧХЬЯЫпа даРУЬХЭвР ЭРТХзЭЮ ШбзХЧРХв. їаШ бЫХФгойХЩ ШвХаРжШШ ТЭХиЭХУЮ жШЪЫР while бваЮЪР, ЯХаХФРЭЭРп eval, СгФХв вЮЩ ЦХ бРЬЮЩ, ЭЮ ЯЮбЪЮЫмЪг eval ШЭвХаЯаХвШагХв ХХ ЧРЭЮТЮ, даРУЬХЭв ЪЮФР СгФХв бзШвРвмбп ЭЮТлЬ. ВРЪШЬ ЮСаРЧЮЬ, аХУгЫпаЭЮХ ТлаРЦХЭШХ ЮСаРСРвлТРХвбп ЧРЭЮТЮ, ЯЮнвЮЬг ЮЭЮ ЪЮЬЯШЫШагХвбп (б ЭЮТлЬ ЧЭРзХЭШХЬ $regex) Т СЫШЦРЩиХЩ бШвгРжШШ, ЪЮУФР ЮЭЮ СгФХв ТбваХзХЭЮ ЯаШ ЭЮТЮЬ ТлЧЮТХ eval.
єЮЭХзЭЮ, ЪЮЬЯШЫпжШп даРУЬХЭвР ЪЮФР ЯаШ ЪРЦФЮЩ ШвХаРжШШ ТЭХиЭХУЮ жШЪЫР вРЪЦХ ваХСгХв ЮЯаХФХЫХЭЭле ЧРваРв. ѕЯаРТФлТРХв ЫШ нЪЮЭЮЬШп Юв /o нвШ ЧРваРвл? їаШ ЭХСЮЫмиЮЬ аРЧЬХаХ ЬРббШТР @items — ЭРТХаЭЮХ, ЭХв. µбЫШ аРЧЬХа ЬРббШТР ФЮбвРвЮзЭЮ ТХЫШЪ — ТЯЮЫЭХ ТХаЮпвЭЮ. ЕаЮЭЮЬХваРЦ (бЬ. ЭШЦХ) ЯЮЬЮЦХв ТРЬ ЯаШЭпвм ЯаРТШЫмЭЮХ аХиХЭШХ.
І нвЮЬ ЯаШЬХаХ ШбЯЮЫмЧЮТРЭЮ вЮ ЮСбвЮпвХЫмбвТЮ, звЮ ЯаШ ЯХаХФРзХ eval ЯаЮУаРЬЬЭЮУЮ ЪЮФР Т бваЮЪХ ЮЭ ЭХ аРббЬРваШТРХвбп ЪРЪ ЯаЮУаРЬЬЭлЩ ЪЮФ Perl ФЮ ЬЮЬХЭвР дРЪвШзХбЪЮУЮ ТлЯЮЫЭХЭШп eval. ВХЬ ЭХ ЬХЭХХ, ТЬХбвЮ нвЮУЮ ЬЮЦЭЮ ЧРбвРТШвм eval аРСЮвРвм Ш б ЭЮаЬРЫмЭЮ ЮвЪЮЬЯШЫШаЮТРЭЭлЬ СЫЮЪЮЬ ЪЮФР.
ѕФЭР ШЧ ЮбЮСХЭЭЮбвХЩ дгЭЪжШШ eval ЧРЪЫозРХвбп Т вЮЬ, звЮ ХХ РаУгЬХЭв ЬЮЦХв ЯаХФбвРТЫпвм бЮСЮЩ ЮСйХХ ТлаРЦХЭШХ (ЭРЯаШЬХа, бваЮЪг Т РЯЮбваЮдРе, ЪРЪ Т ЯаШТХФХЭЭЮЬ ЯаШЬХаХ) ШЫШ СЫЮЪ ЯаЮУаРЬЬЭЮУЮ ЪЮФР {…}. їаШ ШбЯЮЫмЧЮТРЭШШ ТвЮаЮУЮ бЯЮбЮСР, ЪРЪ Т ЯаШТХФХЭЭЮЬ ЭШЦХ ЯаШЬХаХ, РаУгЬХЭв ЪЮЬЯШЫШагХвбп вЮЫмЪЮ ЮФШЭ аРЧ, Т ЬЮЬХЭв ЧРУагЧЪШ ЯаЮУаРЬЬл.
eval {foreach $item (@items) {
if ($item =~ m/$regex/o) {
…
}
}};
ЅРиР жХЫм — ЮСХбЯХзШвм ЯЮТлиХЭШХ нддХЪвШТЭЮбвШ ЯЮ баРТЭХЭШо б ЯаХФлФгйШЬ ЯаШЬХаЮЬ (ЧР бзХв ЮвЪРЧР Юв ЯХаХЪЮЬЯШЫпжШШ ЯаШ ЪРЦФЮЬ ШбЯЮЫмЧЮТРЭШШ), ЭЮ Т ФРЭЭЮЬ бЫгзРХ нвЮ ЯаЮвШТЮаХзШв ТбХЬг ЯаШЬХЭХЭШо eval. АРСЮвР ЯаЮУаРЬЬл ЮбЭЮТРЭР ЭР вЮЬ, звЮ даРУЬХЭв ЯХаХЪЮЬЯШЫШагХвбп ЯаШ ЪРЦФЮЬ ШбЯЮЫмЧЮТРЭШШ, ЯЮнвЮЬг ШбЯЮЫмЧЮТРЭШХ СЫЮзЭЮЩ дЮаЬл ЭХТЮЧЬЮЦЭЮ.
є зШбЫг ФЮТЮФЮТ Т ЯЮЫмЧг eval вРЪЦХ ЯаШЭРФЫХЦРв нддХЪвл ЯХаХЪЮЬЯШЫпжШШ ЭХ-СЫЮзЭЮЩ дЮаЬл Ш ТЮЧЬЮЦЭЮбвм ЯХаХеТРвР ЮиШСЮЪ. ѕиШСЪШ ТаХЬХЭШ ТлЯЮЫЭХЭШп ЬЮУгв ЯХаХеТРвлТРвмбп ЪРЪ Т бваЮЪЮТЮЩ, вРЪ Ш Т СЫЮзЭЮЩ дЮаЬХ, ЭЮ вЮЫмЪЮ бваЮЪЮТРп дЮаЬР ЯЮЧТЮЫпХв ЯХаХеТРвлТРвм ЮиШСЪШ бвРФШШ ЪЮЬЯШЫпжШШ (ЯаШЬХа ТбваХзРЫбп ЯаШ ЮЯШбРЭШШ $* ЭР б. <$R[P#,R7-118]>). П ТЮЮСйХ ЭХ ТШЦг ЮбЮСле ЯаШзШЭ ФЫп ШбЯЮЫмЧЮТРЭШп СЫЮзЭЮЩ ТХабШШ eval {…}, ЪаЮЬХ ЯХаХеТРвР ЮиШСЮЪ ТаХЬХЭШ ТлЯЮЫЭХЭШп (ЭРЯаШЬХа, ЯаЮТХаЪШ вЮУЮ, ЯЮФФХаЦШТРХвбп ЫШ вР ШЫШ ШЭРп ТЮЧЬЮЦЭЮбвм ТРиХЩ ТХабШХЩ Perl) Ш ЯХаХеТРвР warn, die, exit Ш в. Ф.
ВаХвмп бШвгРжШп, Т ЪЮвЮаЮЩ ШбЯЮЫмЧгХвбп eval — ТлЯЮЫЭХЭШХ ЪЮФР, бУХЭХаШаЮТРЭЭЮУЮ ТЮ ТаХЬп аРСЮвл ЯаЮУаРЬЬл. І бЫХФгойХЬ ЯаШЬХаХ ЯаЮФХЬЮЭбваШаЮТРЭ ЮФШЭ аРбЯаЮбваРЭХЭЭлЩ дЮЪгб:
sub Build_MatchMany_Function
{
my @R = @_; # °аУгЬХЭвРЬШ пТЫповбп аХУгЫпаЭлХ ТлаРЦХЭШп
my $program = ''; # їХаХЬХЭЭРп ФЫп ЯЮбваЮХЭШп ЯаЮУаРЬЬЭЮУЮ даРУЬХЭвР
foreach $regex (@R) {
$program .= "return 1 if m/$regex/;"; # їаЮТХаЪР ФЫп ЪРЦФЮУЮ
# аХУгЫпаЭЮУЮ ТлаРЦХЭШп
}
my $sub = eval "sub { $program; return 0 }"; # БЮЧФРвм РЭЮЭШЬЭго дгЭЪжШо
die $@ if $@;
$sub; # ІХаЭгвм дгЭЪжШо ЯЮЫмЧЮТРвХЫо
}
їаХЦФХ зХЬ ЯгбЪРвмбп Т ЯЮФаЮСЭлХ ЮСкпбЭХЭШп, п еЮзг ЯаШТХбвШ ЯаШЬХа ШбЯЮЫмЧЮТРЭШп. їаХФЯЮЫЮЦШЬ, г ТРб ШЬХХвбп ЬРббШТ аХУгЫпаЭле ТлаРЦХЭШЩ @regexes2check. ґЫп ЯаЮТХаЪШ ТеЮФЭле бваЮЪ ЬЮЦЭЮ ТЮбЯЮЫмЧЮТРвмбп бЫХФгойШЬ даРУЬХЭвЮЬ:
# БЮЧФРвм дгЭЪжШо ФЫп ЯаЮТХаЪШ ЯЮ ЭХбЪЮЫмЪШЬ аХУгЫпаЭлЬ ТлаРЦХЭШпЬ
$CheckFunc = Build_MatchMany_Function(@regexes2check);
while(<>) {
# ІлЧТРвм дгЭЪжШо ФЫп ЯаЮТХаЪШ вХЪгйХУЮ ЧЭРзХЭШп $_
if (&$CheckFunc) {
#...І бваЮЪХ бЮТЯРФРХв еЮвп Сл ЮФЭЮ ШЧ аХУгЫпаЭле ТлаРЦХЭШЩ...
}
}
їЮ ЧРФРЭЭЮЬг бЯШбЪг аХУгЫпаЭле ТлаРЦХЭШЩ (вЮзЭХХ УЮТЮап, ЯЮ бЯШбЪг бваЮЪ, ЪЮвЮалХ ФЮЫЦЭл ШЭвХаЯаХвШаЮТРвмбп ЪРЪ аХУгЫпаЭлХ ТлаРЦХЭШп) Build_MatchMany_Function бваЮШв Ш ТЮЧТаРйРХв дгЭЪжШо, ЪЮвЮаРп ЯаШ ТлЧЮТХ ЯаЮТХапХв, бЮТЯРФРов ЫШ ЪРЪШХ-ЫШСЮ ШЧ аХУгЫпаЭле ТлаРЦХЭШЩ Т $_.
їЮФЮСЭлХ ЪЮЭбвагЪжШШ ШбЯЮЫмЧговбп Т ЯХаТго ЮзХаХФм ЯЮ бЮЮСаРЦХЭШпЬ нддХЪвШТЭЮбвШ. µбЫШ Сл аХУгЫпаЭлХ ТлаРЦХЭШп СлЫШ ШЧТХбвЭл ЭР ЬЮЬХЭв ЭРЯШбРЭШп бжХЭРаШп, ТбХ нвЮ ЮЪРЧРЫЮбм Сл ЭХЭгЦЭлЬ. ° ХбЫШ ТлаРЦХЭШп ЭХШЧТХбвЭл, ЬЮЦЭЮ ЯаШСХУЭгвм Ъ бЫХФгойХЬг аХиХЭШо:
$regex = join('|', @regexes2check); # їЮбваЮШвм ЮФЭЮ СЮЫмиЮХ ТлаРЦХЭШХ
while (<>) {
if (m/$regex/o) {
#...І бваЮЪХ бЮТЯРФРХв еЮвп Сл ЮФЭЮ ШЧ аХУгЫпаЭле ТлаРЦХЭШЩ...
}
}
ѕФЭРЪЮ ШЧ-ЧР ЯаШЬХЭХЭШп ЪЮЭбвагЪжШШ ТлСЮаР вРЪЮХ аХиХЭШХ ЮЪРЧлТРХвбп ЭХнддХЪвШТЭлЬ (ЯаШзХЬ ЮЭЮ ТЮЮСйХ ЭХ аРСЮвРХв, ХбЫШ ЪРЪЮХ-вЮ ТлаРЦХЭШХ, ЪаЮЬХ ЯХаТЮУЮ, бЮФХаЦШв ЮСаРвЭлХ бблЫЪШ). АХУгЫпаЭлХ ТлаРЦХЭШп вРЪЦХ ЬЮЦЭЮ ЯХаХСаРвм Т жШЪЫХ, ЯаШЬХЭпп Ше ЯаШ бЮЮвТХвбвТгойХЩ ШвХаРжШШ:
while (<>) {
foreach $regex (@regexes2check) {
if (m/$regex/) {
#...І бваЮЪХ бЮТЯРФРХв еЮвп Сл ЮФЭЮ ШЧ аХУгЫпаЭле ТлаРЦХЭШЩ...
last;
}
}
}
ВРЪЮХ аХиХЭШХ вЮЦХ ЭХнддХЪвШТЭЮ, ЯЮбЪЮЫмЪг ЪРЦФЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЪРЦФлЩ аРЧ ЮСаРСРвлТРХвбп ЧРЭЮТЮ Ш ЯХаХЪЮЬЯШЫШагХвбп. І ТлбиХЩ бвХЯХЭШ ЭХнддХЪвШТЭЮ. ВРЪШЬ ЮСаРЧЮЬ, ЭРзРЫмЭлХ ЧРваРвл ТаХЬХЭШ ЭР ЯЮбваЮХЭШХ нддХЪвШТЭЮУЮ ЯЮШбЪР бЮТЯРФХЭШп Т ЪЮЭХзЭЮЬ бзХвХ ЬЮУгв ЯаШТХбвШ Ъ ЭХЬРЫЮЩ нЪЮЭЮЬШШ.
µбЫШ Build_MatchMany_Function ЯХаХФРовбп бваЮЪШ this, that Ш other, ЯЮбваЮХЭЭлЩ Ш ТлЯЮЫЭХЭЭлЩ ЯЮбаХФбвТЮЬ eval даРУЬХЭв СгФХв ТлУЫпФХвм вРЪ:
sub {
return 1 if m/this/;
return 1 if m/that/;
return 1 if m/other/;
return 0
}
їаШ ЪРЦФЮЬ ТлЧЮТХ нвЮЩ РЭЮЭШЬЭЮЩ дгЭЪжШШ ЮЭР ШйХв бЮТЯРФХЭШХ ФЫп ваХе ТлаРЦХЭШЩ Т вХЪгйХЬ ЧЭРзХЭШШ $_ Ш ТЮЧТаРйРХв ШбвШЭг, ЪРЪ вЮЫмЪЮ бЮТЯРФХЭШХ СгФХв ЭРЩФХЭЮ.
ёФХп ЭХЯЫЮеРп, ЭЮ ХХ аРбЯаЮбваРЭХЭЭлХ аХРЫШЧРжШШ (Т вЮЬ зШбЫХ Ш вЮЫмЪЮ звЮ ЯаШТХФХЭЭРп) УаХиРв ЭХЪЮвЮалЬШ ЭХФЮбвРвЪРЬШ. µбЫШ ЯХаХФРЭЭРп Build_MatchMany_Function бваЮЪР бЮФХаЦШв бШЬТЮЫл $ ШЫШ @, ЪЮвЮалХ ЬЮУгв Слвм ЮбЮСлЬ ЮСаРЧЮЬ ШЭвХаЯаХвШаЮТРЭл Т ЯаЮжХббХ ШЭвХаЯЮЫпжШШ ЯХаХЬХЭЭле, ТРб ЦФХв СЮЫмиЮЩ боаЯаШЧ. ЗРбвШзЭЮХ аХиХЭШХ ЯаЮСЫХЬл ЧРЪЫозРХвбп Т ШбЯЮЫмЧЮТРЭШШ ЮУаРЭШзШвХЫХЩ-РЯЮбваЮдЮТ:
$program .= "return 1 if m'$regex';"; # їаЮТХаЪР ФЫп ЪРЦФЮУЮ
# аХУгЫпаЭЮУЮ ТлаРЦХЭШп
ЅЮ бгйХбвТгХв Ш ФагУРп, СЮЫХХ бХамХЧЭРп ЯаЮСЫХЬР. ЗвЮ ЯаЮШЧЮЩФХв, ХбЫШ ЮФЭЮ ШЧ аХУгЫпаЭле ТлаРЦХЭШЩ бЮФХаЦШв РЯЮбваЮд (ШЫШ ФагУЮЩ ЮУаРЭШзШвХЫм аХУгЫпаЭЮУЮ ТлаРЦХЭШп)? ЅРЯаШЬХа, аХУгЫпаЭЮХ ТлаРЦХЭШХ [don't] ФЮСРТШв Т ЯЮбваЮХЭЭлЩ даРУЬХЭв ЪЮЬРЭФг
return 1 if m'don't';
І аХЧгЫмвРвХ ЯаШ ТлЧЮТХ eval ЯаЮШЧЮЩФХв бШЭвРЪбШзХбЪРп ЮиШСЪР. Іл ЬЮЦХвХ ШбЯЮЫмЧЮТРвм Т ЪРзХбвТХ аРЧФХЫШвХЫп \xff ШЫШ ФагУЮЩ аХФЪШЩ бШЬТЮЫ, ЭЮ бвЮШв ЫШ аШбЪЮТРвм? їаШТХФг ЬЮХ бЮСбвТХЭЭЮХ аХиХЭШХ ФЫп ЯаЮСЫХЬ вРЪЮУЮ аЮФР:
sub Build_MatchMany_Function
{
my @R = @_;
my $expr = join '||', map { "m/\$R[$_]/o" } (0..$#R);
my $sub = eval "sub { $expr }"; # БЮЧФРвм РЭЮЭШЬЭго дгЭЪжШо
die $@ if $@;
$sub; # ІХаЭгвм дгЭЪжШо ЯЮЫмЧЮТРвХЫо
}
°ЭРЫШЧ нвЮУЮ аХиХЭШп ЮбвРХвбп зШвРвХЫо ФЫп бРЬЮбвЮпвХЫмЭЮЩ аРСЮвл. ВХЬ ЭХ ЬХЭХХ, п ЧРФРЬ ТЮЯаЮб<$M[R7-119]>: звЮ ЯаЮШЧЮЩФХв, ХбЫШ ЯаШ ЮСкпТЫХЭШШ ЬРббШТР @R Т нвЮЩ дгЭЪжШШ ТЬХбвЮ my СлЫЮ Сл ШбЯЮЫмЧЮТРЭЮ ЪЫозХТЮХ бЫЮТЮ local? refїХаХТХаЭШвХ бваРЭШжг Ш ЯаЮТХамвХ бТЮЩ ЮвТХв.
<$M[R7-3]>їХаХЬХЭЭлХ $`, $& Ш &' бблЫРовбп бЮЮвТХвбвТХЭЭЮ ЭР вХЪбв, ЯаХФиХбвТгойШЩ бЮТЯРФХЭШо, вХЪбв бРЬЮУЮ бЮТЯРФХЭШп Ш вХЪбв, бЫХФгойШЩ ЧР бЮТЯРФХЭШХЬ (б. <$R[P#,R7-34]>). ґРЦХ ХбЫШ жХЫХТРп бваЮЪР ЯЮЧФЭХХ ШЧЬХЭШвбп, нвШ ЯХаХЬХЭЭлХ ЯЮ-ЯаХЦЭХЬг СгФгв бблЫРвмбп ЭР ШбеЮФЭго ТХабШо вХЪбвР. ЖХЫХТРп бваЮЪР ШЧЬХЭпХвбп ЯаШ ЯЮФбвРЭЮТЪХ, ЭЮ ЯХаХЬХЭЭРп $& ЯЮ-ЯаХЦЭХЬг ФЮЫЦЭР бблЫРвмбп ЭР ШбеЮФЭлЩ вХЪбв (ЧРЬХЭпХЬлЩ Т аХЧгЫмвРвХ ЯЮФбвРЭЮТЪШ). ±ЮЫХХ вЮУЮ, ФРЦХ ХбЫШ Ьл бРЬШ ЬЮФШдШжШагХЬ жХЫХТго бваЮЪг, ЯХаХЬХЭЭлХ $1, $& Ш в. Ф. ТбХ аРТЭЮ ФЮЫЦЭл бблЫРвмбп ЭР ШбеЮФЭлЩ вХЪбв (ЯЮ ЪаРЩЭХЩ ЬХаХ ФЮ бЫХФгойХУЮ гбЯХиЭЮУЮ бЮТЯРФХЭШп ШЫШ ТлеЮФР ШЧ СЫЮЪР). єРЪ ЦХ ЮСаРЧЮЬ Perl бЮеаРЭпХв ШбеЮФЭго ШЭдЮаЬРжШо, ЭХТЧШаРп ЭР ТбХ ШЧЬХЭХЭШп?
ѕвТХв: ЯЮбаХФбвТЮЬ ЪЮЯШаЮТРЭШп. ІбХ ЯХаХЬХЭЭлХ, гЯЮЬпЭгвлХ ТлиХ, Т ФХЩбвТШвХЫмЭЮбвШ бблЫРовбп ЭХ ЭР ШбеЮФЭго бваЮЪг, Р ЭР ХХ ТЭгваХЭЭоо ЪЮЯШо. АРЧгЬХХвбп, ЭРЫШзШХ ЪЮЯШШ ЮЧЭРзРХв, звЮ Т ЯРЬпвШ ЮФЭЮТаХЬХЭЭЮ ЯаШбгвбвТгов ФТР нЪЧХЬЯЫпаР бваЮЪШ. µбЫШ жХЫХТЮЩ вХЪбв ШЬХХв СЮЫмиЮЩ ЮСкХЬ, вЮ ЭРЫШзШХ ФгСЫШЪРвР гФТЮШв ЧРваРвл ЯРЬпвШ. ІЯаЮзХЬ, ЯЮбЪЮЫмЪг нвШ ЯХаХЬХЭЭлХ бблЫРовбп ЭР ЪЮЯШо ШбеЮФЭЮУЮ вХЪбвР, нвШ ЧРваРвл ЭХШЧСХЦЭл, ЭХ вРЪ ЫШ?
ЅХ бЮТбХЬ. µбЫШ Тл ЭХ бЮСШаРХвХбм ШбЯЮЫмЧЮТРвм нвШ ТЭгваХЭЭШХ ЯХаХЬХЭЭлХ, ЭХЮСеЮФШЬЮбвм Т ЪЮЯШаЮТРЭШШ ЮвЯРФРХв, звЮ ЬЮЦХв ЯаШТХбвШ Ъ ЭХЬРЫЮЩ нЪЮЭЮЬШШ ЯРЬпвШ. є бЮЦРЫХЭШо, Perl ЭХ ЧЭРХв, бЮСШаРХвХбм Тл ШбЯЮЫмЧЮТРвм нвШ ЯХаХЬХЭЭлХ ШЫШ ЭХв. Б ФагУЮЩ бвЮаЮЭл, Perl ШЭЮУФР ЯЮЭШЬРХв, звЮ бЮЧФРТРвм ЪЮЯШо ЭХЮСпЧРвХЫмЭЮ. µбЫШ Тл ЭРгзШвХбм ШЭШжШШаЮТРвм ЯЮФЮСЭлХ «ЮЧРаХЭШп» Т бТЮШе ЯаЮУаРЬЬРе, ЮЭШ СгФгв аРСЮвРвм СЮЫХХ нддХЪвШТЭЮ. ѕвЪРЧ Юв бЮЧФРЭШп ЪЮЯШШ ЭХ вЮЫмЪЮ нЪЮЭЮЬШв ТаХЬп, ЭЮ Ш бЮТХаиХЭЭЮ гФШТШвХЫмЭлЬ ЮСаРЧЮЬ зРбвЮ гбЪЮапХв аРСЮвг ЮЯХаРвЮаР ЯЮФбвРЭЮТЪШ (нвР вХЬР аРббЬРваШТРХвбп ЭШЦХ Т нвЮЬ аРЧФХЫХ).
local Ш my
bref ѕвТХв ЭР ТЮЯаЮб бЮ б. <$R[P#,R7-119]>
їаХЦФХ зХЬ ЮвТХзРвм ЭР ТЮЯаЮб, бЫХФгХв бЪРЧРвм ЭХбЪЮЫмЪЮ бЫЮТ Ю ЬХеРЭШЧЬХ бТпЧлТРЭШп (binding). єЮУФР Perl ЪЮЬЯШЫШагХв даРУЬХЭв ЯаЮУаРЬЬЭЮУЮ ЪЮФР (ЯаШ ЧРУагЧЪХ ЯаЮУаРЬЬл ШЫШ ЯаШ ТлЯЮЫЭХЭШШ eval), ЯаЮШбеЮФШв бТпЧлТРЭШХ бблЫЮЪ ЭР ЯХаХЬХЭЭлХ нвЮУЮ даРУЬХЭвР б ЪЮФЮЬ. ·ЭРзХЭШп ЯХаХЬХЭЭле ЭР нвЮЩ бвРФШШ ХйХ ЭХ ШЧТХбвЭл. ґЮбвгЯ Ъ ЭШЬ ЮбгйХбвТЫпХвбп ТЮ ТаХЬп ТлЯЮЫЭХЭШп ЯаЮУаРЬЬЭЮУЮ ЪЮФР.
єЮЭбвагЪжШп my @R бЮЧФРХв ЭЮТго ЯХаХЬХЭЭго — бРЬЮбвЮпвХЫмЭго Ш ЭШЪРЪ ЭХ бТпЧРЭЭго б ФагУШЬШ ЯХаХЬХЭЭлЬШ ЯаЮУаРЬЬл. єЮУФР Т ЯаЮУаРЬЬХ ТлзШбЫпХвбп даРУЬХЭв б РЭЮЭШЬЭЮЩ дгЭЪжШХЩ, ХУЮ ЪЮФ бТпЧлТРХвбп б ЭРиХЩ ЧРЪалвЮЩ ЯХаХЬХЭЭЮЩ @R. ѕСЮЧЭРзХЭШХ @R бблЫРХвбп ЭР нвг ЧРЪалвго ЯХаХЬХЭЭго. ЅХ ЯлвРЩвХбм ЮСаРйРвмбп Ъ @R, ЯЮбЪЮЫмЪг вРЪШХ бблЫЪШ ТЮЧЬЮЦЭл ЫШим ТЮ ТаХЬп ТлЯЮЫЭХЭШп РЭЮЭШЬЭЮЩ дгЭЪжШШ.
їаШ ТлеЮФХ ШЧ Buiild_MatchMany_Function ЯХаХЬХЭЭРп @R ЮСлзЭЮ ШбзХЧРХв, ЭЮ ШЧ-ЧР бТпЧлТРЭШп б РЭЮЭШЬЭЮЩ дгЭЪжШХЩ @R Ш ХХ бваЮЪШ ЯаЮФЮЫЦРов еаРЭШвмбп Т ЯРЬпвШ, еЮвп ФЮбвгЯ Ъ ЭШЬ ТЮЧЬЮЦХЭ ЫШим ШЧ РЭЮЭШЬЭЮЩ дгЭЪжШШ (бблЫЪШ ЭР @R Т ФагУШе ЬХбвРе ЯаЮУаРЬЬл ЮвЭЮбпвбп Ъ ФагУЮЩ, УЫЮСРЫмЭЮЩ ЯХаХЬХЭЭЮЩ б вХЬ ЦХ ШЬХЭХЬ). їаШ ЯЮбЫХФгойХЬ ТлЯЮЫЭХЭШШ РЭЮЭШЬЭЮЩ дгЭЪжШШ бблЫЪР ЮвЭЮбШвбп Ъ ТЭгваХЭЭХЬг нЪЧХЬЯЫпаг @R, Ш ЯаШ нвЮЬ ШбЯЮЫмЧговбп ШЬХЭЭЮ вХ бваЮЪШ, ЪЮвЮалХ ЭРЬ ЭгЦЭл.
Б ФагУЮЩ бвЮаЮЭл, ЪЮЭбвагЪжШп local @R ЯаЮбвЮ бЮеаРЭпХв ЪЮЯШо УЫЮСРЫмЭЮЩ ЯХаХЬХЭЭЮЩ @R ЯХаХФ вХЬ, ЪРЪ ХХ бЮФХаЦШЬЮХ СгФХв ЯХаХЧРЯШбРЭЮ ЬРббШТЮЬ @_. ІЯЮЫЭХ ТЮЧЬЮЦЭЮ, звЮ ЭШЪРЪЮУЮ ЯаХФлФгйХУЮ бЮФХаЦШЬЮУЮ ЭХ бгйХбвТЮТРЫЮ, ЭЮ ХбЫШ УЫЮСРЫмЭРп ЯХаХЬХЭЭРп @R ТбХ ЦХ ШбЯЮЫмЧЮТРЫРбм ЪРЪЮЩ-вЮ зРбвмо ЯаЮУаРЬЬл, Ьл ЭР ТбпЪШЩ бЫгзРЩ бЮеаРЭпХЬ ЪЮЯШо. їаШ ТлзШбЫХЭШШ даРУЬХЭвР ЯЮбаХФбвТЮЬ eval ЮСЮЧЭРзХЭШХ @R ЮвЭЮбШвбп Ъ вЮЩ ЦХ УЫЮСРЫмЭЮЩ ЯХаХЬХЭЭЮЩ (звЮ бЮТХаиХЭЭЮ ЭХ бТпЧРЭЮ б ШбЯЮЫмЧЮТРЭШХЬ local — ЯЮбЪЮЫмЪг ЭХ бгйХбвТгХв ЯаШТРвЭЮЩ my-ТХабШШ @R, ТбХ бблЫЪШ ЭР @R ЮвЭЮбпвбп Ъ УЫЮСРЫмЭЮЩ ЯХаХЬХЭЭЮЩ, Ш ЭРЫШзШХ ШЫШ ЮвбгвбвТШХ local ФЫп ЪЮЯШаЮТРЭШп ФРЭЭле ЭХбгйХбвТХЭЭЮ).
їаШ ТлеЮФХ ШЧ дгЭЪжШШ Build_MatchMany_Function ТЮббвРЭРТЫШТРХвбп бЮеаРЭХЭЭРп ЪЮЯШп @R. іЫЮСРЫмЭРп ЯХаХЬХЭЭРп @R — нвЮ вР ЦХ ЯХаХЬХЭЭРп, ЪЮвЮаРп ШбЯЮЫмЧЮТРЫРбм ЯаШ ТлЧЮТХ eval, Ш вР ЦХ ЯХаХЬХЭЭРп, б ЪЮвЮаЮЩ бТпЧРЭР РЭЮЭШЬЭРп дгЭЪжШп, ЭЮ бЮФХаЦШЬЮХ нвЮЩ ЯХаХЬХЭЭЮЩ бвРЭЮТШвбп ФагУШЬ. ВРЪШЬ ЮСаРЧЮЬ, Ьл бЪЮЯШаЮТРЫШ ЭЮТлХ ЧЭРзХЭШп Т @R, ЭЮ ЭШ аРЧг ЭХ бЮбЫРЫШбм ЭР ЭШе! ІбХ гбШЫШп ЯаЮЯРЫШ ФРаЮЬ. °ЭЮЭШЬЭРп дгЭЪжШп ЮЦШФРХв, звЮ УЫЮСРЫмЭРп ЯХаХЬХЭЭРп @R бЮФХаЦШв бваЮЪШ, ШбЯЮЫмЧгХЬлХ Т ЪРзХбвТХ аХУгЫпаЭле ТлаРЦХЭШЩ, ЭЮ Ьл гЦХ ЯЮвХапЫШ бЪЮЯШаЮТРЭЭлХ ЧЭРзХЭШп. їаШ ЯХаТЮЬ ШбЯЮЫмЧЮТРЭШШ дгЭЪжШШ ЮЭР «гТШФШв» ЯаХЦЭХХ бЮФХаЦШЬЮХ @R — звЮ Сл вРЬ ЭШ еаРЭШЫЮбм, нвЮ ЭХ ЭРиШ аХУгЫпаЭлХ ТлаРЦХЭШп, ЯЮнвЮЬг ТбХ аХиХЭШХ ЯХаХбвРХв аРСЮвРвм.
ѕбвРХвбп бФХЫРвм ЯЮбЫХФЭХХ ЧРЬХзРЭШХ. µбЫШ Сл ЯХаХФ ТлеЮФЮЬ ШЧ Build_MatchMany_Function Ьл ШбЯЮЫмЧЮТРЫШ РЭЮЭШЬЭго дгЭЪжШо (Ш ЯаШ нвЮЬ ЭШ ЮФЭЮ ШЧ аХУгЫпаЭле ТлаРЦХЭШЩ ЭХ бЮТЯРЫЮ Т вХЪбвХ), вЮ ЬЮФШдШЪРвЮа /o ЧРдШЪбШаЮТРЫ Сл аХУгЫпаЭлХ ТлаРЦХЭШп, еаРЭпйШХбп Т @R, Ш ЯаЮСЫХЬР СлЫР Сл аХиХЭР (ХбЫШ бЮТЯРФХЭШХ СгФХв ЭРЩФХЭЮ, вЮ ЧРдШЪбШаговбп вЮЫмЪЮ аХУгЫпаЭлХ ТлаРЦХЭШп, ЯаЮТХаХЭЭлХ ФЮ ЭРбвЮпйХУЮ ЬЮЬХЭвР). ВРЪЮХ аХиХЭШХ ЮСЫРФРХв ЭХбЮЬЭХЭЭлЬШ ЯаХШЬгйХбвТРЬШ — ЯХаХЬХЭЭРп @R ЭгЦЭР ЭРЬ ЫШим ФЮ вХе ЯЮа, ЯЮЪР аХУгЫпаЭлХ ТлаРЦХЭШп ЭХ СгФгв ЧРдШЪбШаЮТРЭл Т ЯРЬпвШ. їЮбЫХ нвЮУЮ ЭХЮСеЮФШЬЮбвм Т бваЮЪРе, ШбЯЮЫмЧЮТРЭЭле ФЫп Ше бЮЧФРЭШп, ЮвЯРФРХв, ЯЮнвЮЬг еаРЭХЭШХ Ше Т ЮвФХЫмЭЮЩ ЯХаХЬХЭЭЮЩ @R (гФРЫпХЬЮЩ ЫШим ЯЮбЫХ гФРЫХЭШп РЭЮЭШЬЭЮЩ дгЭЪжШШ!) ЫШим ЯаШТЮФШв Ъ ЭХЯаЮШЧТЮФШвХЫмЭлЬ ЧРваРвРЬ ЯРЬпвШ.
ІЭШЬРЭШХ: ЯаШХЬл ЮЯвШЬШЧРжШШ, ЮЯШбРЭЭлХ ЭШЦХ, ЮбЭЮТРЭл ЭР ЧЭРЭШпе ТЭгваХЭЭШе ЬХеРЭШЧЬЮТ аРСЮвл Perl. µбЫШ нвШ ЯаШХЬл гбЪЮапв аРСЮвг ТРиШе ЯаЮУаРЬЬ — еЮаЮиЮ, ЭЮ ЯаШЭжШЯл, ЭР ЪЮвЮале ЮбЭЮТРЭР Ше аРСЮвР, ЭХ ТеЮФпв Т бЯХжШдШЪРжШо Perl[47] Ш ЬЮУгв ШЧЬХЭШвмбп Т СгФгйШе ТХабШпе (ЪЭШУР ЭРЯШбРЭР ЭР ЮбЭЮТРЭШШ ТХабШШ 5.003). µбЫШ нвШ ЮЯвШЬШЧРжШШ ЭХЮЦШФРЭЭЮ ШбзХЧЭгв, вЮ нвЮ ЮваРЧШвбп вЮЫмЪЮ ЭР нддХЪвШТЭЮбвШ — ЯаЮУаРЬЬл СгФгв ТлФРТРвм ЯаХЦЭШХ аХЧгЫмвРвл, ЯЮнвЮЬг ЮбЮСле ЯаШзШЭ ФЫп СХбЯЮЪЮЩбвТР ЭХв.
єЮЯШаЮТРЭШХ ЯаШ гбЯХиЭЮЬ ЯЮШбЪХ ШЫШ ЯЮФбвРЭЮТЪХ ЮбгйХбвТЫпХвбп Т ваХе бШвгРжШпе<$M[R7-121]> [23 б.<$R[P#,R7-120]>]:
l ХбЫШ ЯХаХЬХЭЭлХ $`, $& ШЫШ &' ТбваХзРовбп Т ЫоСЮЬ ЬХбвХ ТбХУЮ бжХЭРаШп;
l ХбЫШ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ ТбваХзРовбп бЮеаРЭпойШХ ЪагУЫлХ бЪЮСЪШ;
l ХбЫШ ЬЮФШдШЪРвЮа /i ШбЯЮЫмЧгХвбп Т ЮЯХаРвЮаХ ЯЮШбЪР СХЧ ЬЮФШдШЪРвЮаР /g.
єаЮЬХ вЮУЮ, ФЮЯЮЫЭШвХЫмЭлХ ТЭгваХЭЭШХ ЪЮЯШШ ЬЮУгв ЯЮваХСЮТРвмбп ФЫп ЯЮФФХаЦЪШ:
l ШбЯЮЫмЧЮТРЭШп ЬЮФШдШЪРвЮаР /i (ЯаШ ЫоСЮЬ ЯЮШбЪХ ШЫШ ЯЮФбвРЭЮТЪХ);
l ШбЯЮЫмЧЮТРЭШп ЬЭЮУШе (ЭЮ ЭХ ТбХе) ЮЯХаРвЮаЮТ ЯЮФбвРЭЮТЪШ.
їХаТлХ ваШ бЫгзРп аРббЬРваШТРовбп ЭШЦХ, Р ФТР ЯЮбЫХФЭШе — Т бЫХФгойХЬ аРЧФХЫХ.
ґЫп ЯЮФФХаЦЪШ ЫоСЮУЮ ШбЯЮЫмЧЮТРЭШп ЯХаХЬХЭЭле $`, $& Ш &' Perl ЯаШеЮФШвбп бЮЧФРТРвм ЪЮЯШШ. ЅР ЯаРЪвШЪХ ЯЮбЫХ СЮЫмиШЭбвТР ЮЯХаРжШЩ ЯЮШбЪР нвШ ЯХаХЬХЭЭлХ ЭХ ШбЯЮЫмЧговбп, ЯЮнвЮЬг СлЫЮ Сл ЦХЫРвХЫмЭЮ, звЮСл ЪЮЯШаЮТРЭШХ ТлЯЮЫЭпЫЮбм вЮЫмЪЮ вЮУФР, ЪЮУФР нвЮ ФХЩбвТШвХЫмЭЮ ЭХЮСеЮФШЬЮ. ЅЮ ЯЮбЪЮЫмЪг нвШ ЯХаХЬХЭЭлХ ЮСЫРФРов ФШЭРЬШзХбЪЮЩ ТШФШЬЮбвмо, Ше ШбЯЮЫмЧЮТРЭШХ ЬЮЦХв ЯаЮШбеЮФШвм ЭР СЮЫмиЮЬ аРббвЮпЭШШ Юв ЭРЩФХЭЭЮУЮ бЮТЯРФХЭШп. ВХЮаХвШзХбЪШ Perl ЬЮЦХв ЯЮФаЮСЭЮ ЯаЮРЭРЫШЧШаЮТРвм Тбо ЯаЮУаРЬЬг Ш ЮЯаХФХЫШвм, звЮ ЫоСлХ бЫгзРШ ШбЯЮЫмЧЮТРЭШп нвШе ЯХаХЬХЭЭле ЭХ ЮвЭЮбпвбп Ъ ЪЮЭЪаХвЭЮЩ ЮЯХаРжШШ ЯЮШбЪР (ЯЮнвЮЬг ЪЮЯШаЮТРЭШХ ФЫп нвЮЩ ЮЯХаРжШШ ТлЯЮЫЭпвм ЭХ ЭгЦЭЮ). ЅР ЯаРЪвШЪХ Perl нвЮУЮ ЭХ ФХЫРХв. їЮ нвЮЩ ЯаШзШЭХ ЪЮЯШаЮТРЭШХ ЮСлзЭЮ ТлЯЮЫЭпХвбп ЯаШ ЪРЦФЮЬ гбЯХиЭЮЬ бЮТЯРФХЭШШ ЪРЦФЮУЮ аХУгЫпаЭЮУЮ ТлаРЦХЭШп ТЮ ТаХЬп аРСЮвл ЯаЮУаРЬЬл.
ѕФЭРЪЮ Perl ЧРЬХзРХв, ХбЫШ бблЫЪШ ЭР $`, $& Ш &' ТЮЮСйХ ЭХ ТбваХзРовбп Т ЯаЮУаРЬЬХ (Р вРЪЦХ ТЮ ТбХе СШСЫШЮвХЪРе, ШбЯЮЫмЧгХЬле бжХЭРаШХЬ!) їЮбЪЮЫмЪг ЯХаХЬХЭЭлХ Т ЯаЮУаРЬЬХ ЭХ ШбЯЮЫмЧговбп, Perl ЬЮЦХв б ЯЮЫЭЮЩ гТХаХЭЭЮбвмо ШбЪЫозШвм ТбХ ЮЯХаРжШШ ЪЮЯШаЮТРЭШп, ЭХЮСеЮФШЬлХ ФЫп Ше ЯЮФФХаЦЪШ. ВРЪШЬ ЮСаРЧЮЬ, ХбЫШ ЯаЮбЫХФШвм ЧР вХЬ, звЮСл ЯХаХЬХЭЭлХ $`, $& Ш &' ЭШ аРЧг ЭХ гЯЮЬШЭРЫШбм Т ЯаЮУаРЬЬХ Ш ТбХе ШбЯЮЫмЧгХЬле ХЩ СШСЫШЮвХЪРе, ТРЬ гФРбвбп ШЧСХЦРвм ЧРваРв, бТпЧРЭЭле б ЪЮЯШаЮТРЭШХЬ (ХбЫШ ЭХЮСеЮФШЬЮбвм Т ЪЮЯШаЮТРЭШШ ЭХ СгФХв ЮСгбЫЮТЫХЭР ФТгЬп ФагУШЬШ бЫгзРпЬШ).
<$M[R7-4]>µбЫШ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ ШбЯЮЫмЧговбп бЮеаРЭпойШХ ЪагУЫлХ бЪЮСЪШ, Perl ЯЮЫРУРХв, звЮ Тл бЮСШаРХвХбм ШбЯЮЫмЧЮТРвм бЮеаРЭХЭЭлЩ вХЪбв Ш ТлЯЮЫЭпХв ЪЮЯШаЮТРЭШХ ЯЮбЫХ ЯЮШбЪР бЮТЯРФХЭШп (ЭРЫШзШХ ШЫШ ЮвбгвбвТШХ $1 Т ЯаЮУаРЬЬХ аЮЫШ ЭХ ШУаРХв — ХбЫШ бЮеаРЭпойШХ ЪагУЫлХ бЪЮСЪШ ТбваХзРовбп Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ, вЮ ЪЮЯШаЮТРЭШХ ТлЯЮЫЭпХвбп ФРЦХ Т вЮЬ бЫгзРХ, ХбЫШ ХУЮ аХЧгЫмвРвл ЭШЪЮУФР ЭХ ШбЯЮЫмЧговбп). І Perl4 ЭХ бгйХбвТЮТРЫЮ ЪагУЫле бЪЮСЮЪ, ЮУаРЭШзШТРойШебп УагЯЯШаЮТЪЮЩ нЫХЬХЭвЮТ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, ЯЮнвЮЬг ФРЦХ ХбЫШ Тл ЭХ бЮСШаРЫШбм бЮеаРЭпвм вХЪбв, нвЮ ЯаШеЮФШЫЮбм аРббЬРваШТРвм ЪРЪ ЮваШжРвХЫмЭлЩ ЯЮСЮзЭлЩ нддХЪв. Б ЯЮпТЫХЭШХЬ ЪЮЭбвагЪжШШ [?:…] ТРЬ гЦХ ЭХ ЯаШФХвбп бЮеаРЭпвм вХЪбв, ЪЮвЮалЩ ТРЬ ЭХ ЭгЦХЭ[48]. ЅЮ ХбЫШ Тл бЮСШаРХвХбм ШбЯЮЫмЧЮТРвм ЯХаХЬХЭЭлХ $1, $2 Ш в. Ф., Perl ТлЯЮЫЭШв ЪЮЯШаЮТРЭШХ.
їаШ ШбЯЮЫмЧЮТРЭШШ /i Т ЮЯХаРвЮаХ ЯЮШбЪР СХЧ ЬЮФШдШЪРвЮаР /g ТЮЧЭШЪРХв ЭХЮСеЮФШЬЮбвм Т ЪЮЯШаЮТРЭШШ. їЮзХЬг? ЗХбвЭЮ УЮТЮап, ЭХ ЧЭРо. їаШ ТЧУЫпФХ ЭР ЯаЮУаРЬЬЭго аХРЫШЧРжШо ЪЮЯШаЮТРЭШХ ЪРЦХвбп ЬЭХ РСбЮЫовЭЮ ШЧЫШиЭШЬ, ЭЮ п, ЪЮЭХзЭЮ, ЭХ пТЫпобм нЪбЯХавЮЬ ЯЮ ТЭгваХЭЭХЬг гбваЮЩбвТг Perl — вХЬ СЮЫХХ, звЮ ШбЯЮЫмЧЮТРЭШХ /i ШЬХХв ФагУШХ, СЮЫХХ бгйХбвТХЭЭлХ ЯЮбЫХФбвТШп ФЫп СлбваЮФХЩбвТШп ЯаЮУаРЬЬл. ІбЪЮаХ п ТХаЭгбм Ъ нвЮЩ вХЬХ, ЭЮ бЭРзРЫР п еЮзг ЯаШТХбвШ аХЧгЫмвРвл вХбвЮТ, ФХЬЮЭбваШагойШе ЯЮбЫХФбвТШп ЪЮЯШаЮТРЭШп ЯаШ ЯЮФФХаЦЪХ $&.
<$M[R7-122]>П ЯаЮТХЫ ЯаЮбвЮЩ вХбв, Т ЪЮвЮаЮЬ ЪЮЭбвагЪжШп m/c/ ЯаШЬХЭпЫРбм Ъ ЪРЦФЮЩ ШЧ 50 000 б ЫШиЭШЬ бваЮЪ ЯаЮУаРЬЬЭЮУЮ ЪЮФР C Т ШбеЮФЭле вХЪбвРе Perl. І ЯаЮжХббХ еаЮЭЮЬХваРЦР п ЯаЮбвЮ ЯаЮТХапЫ, ЯаШбгвбвТгХв ЫШ Т бваЮЪХ СгЪТР c — ЯЮЫгзХЭЭРп ШЭдЮаЬРжШп ЭШЪРЪ ЭХ ЮСаРСРвлТРЫРбм, ЯЮбЪЮЫмЪг ЪЮЭХзЭЮЩ ЧРФРзХЩ СлЫЮ ЮЯаХФХЫХЭШХ ЯЮбЫХФбвТШЩ Юв ЪЮЯШаЮТРЭШп. ЕаЮЭЮЬХваРЦ ЯаЮТЮФШЫбп ФТРЦФл: Т ЯХаТлЩ аРЧ ЭШ ЮФЭЮ ШЧ ЯХаХзШбЫХЭЭле ТлиХ гбЫЮТШЩ ЭХ ТлЯЮЫЭпЫЮбм, Р ТЮ ТвЮаЮЩ п ЯЮЧРСЮвШЫбп Ю вЮЬ, звЮСл нвШ гбЫЮТШп ТлЯЮЫЭпЫШбм. ВРЪШЬ ЮСаРЧЮЬ, ХФШЭбвТХЭЭлЬ ЮвЫШзШХЬ СлЫШ ЧРваРвл, бТпЧРЭЭлХ б ФЮЯЮЫЭШвХЫмЭлЬ ЪЮЯШаЮТРЭШХЬ.
їаЮТХФХЭЭРп бХаШп вХбвЮТ ЯЮЪРЧРЫР, звЮ ФЮЯЮЫЭШвХЫмЭЮХ ЪЮЯШаЮТРЭШХ бвРСШЫмЭЮ гТХЫШзШТРЫЮ ТаХЬп ТлЯЮЫЭХЭШп ЯаЮУаРЬЬл СЮЫХХ зХЬ ЭР 35 ЯаЮжХЭвЮТ. єЮЭХзЭЮ, нвШ ФРЭЭлХ бЫХФгХв аРббЬРваШТРвм ЪРЪ бТЮХУЮ аЮФР «бЫгзРЩ баХФЭХЩ впЦХбвШ». ЗХЬ СЮЫмиХ аХРЫмЭЮЩ аРСЮвл ТлЯЮЫЭпХвбп Т ЯаЮУаРЬЬХ, вХЬ ЬХЭмиШХ (Т ЯаЮжХЭвЭЮЬ ЮвЭЮиХЭШШ) ЯЮбЫХФбвТШп СгФХв ШЬХвм ЪЮЯШаЮТРЭШХ. І ЬЮШе вХбвРе ЭШЪРЪЮЩ аХРЫмЭЮЩ аРСЮвл ЭХ ТлЯЮЫЭпЫЮбм, ЯЮнвЮЬг нддХЪв ЮбЮСХЭЭЮ еЮаЮиЮ ЧРЬХвХЭ.
Б ФагУЮЩ бвЮаЮЭл, Т ФХЩбвТШвХЫмЭЮ впЦХЫле бЫгзРпе СЮЫмиРп зРбвм ТаХЬХЭШ аРСЮвл ЯаЮУаРЬЬл ЬЮЦХв Слвм ЯЮваРзХЭР ЭР ФЮЯЮЫЭШвХЫмЭЮХ ЪЮЯШаЮТРЭШХ. П ЯаЮТХЫ вЮв ЦХ вХбв ФЫп вХе ЦХ ФРЭЭле, ЭЮ ЭР нвЮв аРЧ ТЬХбвЮ 50 000 бваЮЪ баХФЭХЩ ФЫШЭл ФРЭЭлХ СлЫШ ЮаУРЭШЧЮТРЭл Т ТШФХ ЮФЭЮЩ СЮЫмиЮЩ бваЮЪШ ЮСкХЬЮЬ СЮЫХХ ЬХУРСРЩвР. ЅР нвЮЬ ЯаШЬХаХ ЬЮЦЭЮ СлЫЮ ЮжХЭШвм ЮвЭЮбШвХЫмЭЮХ СлбваЮФХЩбвТШХ ЮФЭЮЩ ЮЯХаРжШШ ЯЮШбЪР. ±ХЧ ЪЮЯШаЮТРЭШп ЮЯХаРжШп ТлЯЮЫЭпЫРбм ЯаРЪвШзХбЪШ ЬУЭЮТХЭЭЮ, ЯЮбЪЮЫмЪг СгЪТР c ЭРеЮФШЫРбм УФХ-вЮ ЭХЯЮФРЫХЪг Юв ЭРзРЫР бваЮЪШ. єРЪ вЮЫмЪЮ СгЪТР СлЫР ЭРЩФХЭР, ЯЮШбЪ ЧРТХаиРЫбп. їаЮТХаЪР б ЪЮЯШаЮТРЭШХЬ аРСЮвРЫР вРЪ ЦХ, ЭЮ б ЮФЭШЬ ШбЪЫозХЭШХЬ — бЭРзРЫР бЮЧФРТРЫРбм ЪЮЯШп бваЮЪШ, ЮСкХЬ ЪЮвЮаЮЩ ЯаХТлиРЫ ЬХУРСРЩв. їаЮУаРЬЬР бвРЫР аРСЮвРвм ЯЮзвШ Т 700 аРЧ ЬХФЫХЭЭХХ! ·ЭРп ЯЮбЫХФбвТШп ЯаШЬХЭХЭШп ЭХЪЮвЮале ЪЮЭбвагЪжШЩ, Тл бЬЮЦХвХ ФЮСШвмбп Юв бТЮХУЮ ЪЮФР ЬРЪбШЬРЫмЭЮЩ нддХЪвШТЭЮбвШ.
єЮЭХзЭЮ, СлЫЮ Сл ЧРЬХзРвХЫмЭЮ, ХбЫШ Сл Perl ЧЭРЫ Ю ЭРЬХаХЭШпе ЯаЮУаРЬЬШбвР Ш бЮЧФРТРЫ ЪЮЯШШ ЫШим Т бЫгзРХ ЭХЮСеЮФШЬЮбвШ. ЅЮ бЫХФгХв гзШвлТРвм, звЮ ЪЮЯШаЮТРЭШХ — нвЮ ФРЫХЪЮ ЭХ ТбХУФР ЯЫЮеЮ. ёЬХЭЭЮ СЫРУЮФРап вЮЬг, звЮ Perl СХаХв ЭР ТлЯЮЫЭХЭШХ ЯЮФЮСЭле ТвЮаЮбвХЯХЭЭле ЧРФРз, Ьл ТлСШаРХЬ нвЮв пЧлЪ ТЬХбвЮ C ШЫШ РббХЬСЫХаР. І бРЬЮЬ ФХЫХ, Perl СлЫ аРЧаРСЮвРЭ ЪРЪ аРЧ ФЫп вЮУЮ, звЮСл ЯЮЫмЧЮТРвХЫм ЬЮУ ШЧСРТШвмбп Юв ЬХеРЭШзХбЪШе ЬРЭШЯгЫпжШЩ б СШвРЬШ Ш бЮбаХФЮвЮзШвм ТбХ ТЭШЬРЭШХ ЭР бЮЧФРЭШШ вТЮазХбЪШе аХиХЭШЩ.
є аХиХЭШо ЧРФРз ЭР Perl ЬЮЦЭЮ ЯЮФеЮФШвм аРЧЭлЬШ бЯЮбЮСРЬШ, ЭЮ бЫХФгХв ЯЮЬЭШвм вЮ, Ю зХЬ п гЦХ ЭХЮФЭЮЪаРвЭЮ гЯЮЬШЭРЫ. µбЫШ Тл ЯаЮУаРЬЬШагХвХ ЭР Perl вРЪ, ЪРЪ Тл Сл ЯаЮУаРЬЬШаЮТРЫШ ЭР ФагУЮЬ пЧлЪХ (ЭРЯаШЬХа, ЭР C), ТРиШ Perl-ЯаЮУаРЬЬл ЯЮЫгзРвбп гСЮУШЬШ Ш ЯЮзвШ ТбХУФР ЬРЫЮнддХЪвШТЭлЬШ. єРЪ ЯаРТШЫЮ, ЯЮбваЮХЭШХ ЯаЮУаРЬЬл Т бЮЮвТХвбвТШШ б ШФХЮЫЮУШХЩ Perl Т ЧЭРзШвХЫмЭЮЩ бвХЯХЭШ ЯЮЬЮУРХв ТбвРвм ЭР ЯаРТШЫмЭлЩ Ягвм, ЭЮ ЧФХбм, ЪРЪ Ш Т ЫоСЮЩ ФагУЮЩ ЮСЫРбвШ, бЯХжШРЫмЭлХ ЬХал ЬЮУгв ЮСХбЯХзШвм гЫгзиХЭШХ аХЧгЫмвРвР. ґХЩбвТШвХЫмЭЮ, еЮвп Т ЪЮЯШаЮТРЭШШ ЭХв ЭШзХУЮ «ЯаШЭжШЯШРЫмЭЮ ЯЫЮеЮУЮ», Ьл ТбХ ЦХ еЮвШЬ ЯЮ ТЮЧЬЮЦЭЮбвШ ШЧСРТШвмбп Юв ЫШиЭШе ЧРвавРв. ЅШЦХ ЮЯШбРЭл ЭХЪЮвЮалХ ФХЩбвТШп, ЪЮвЮалХ ЬЮЦЭЮ ФЫп нвЮУЮ ЯаХФЯаШЭпвм.
єЮЭХзЭЮ, ЯаХЦФХ ТбХУЮ бЫХФгХв ЯЮЫЭЮбвмо<$M[R7-129]> ШбЪЫозШвм ШбЯЮЫмЧЮТРЭШХ ЯХаХЬХЭЭле $`, $& Ш &' Т ТРиХЩ ЯаЮУаРЬЬХ. НвЮ вРЪЦХ ЮЧЭРзРХв, звЮ Тл ЭХ ФЮЫЦЭл ШбЯЮЫмЧЮТРвм English.pm Ш ЫоСлХ ФагУШХ СШСЫШЮвХзЭлХ ЬЮФгЫШ, ШбЯЮЫмЧгойШХ ХУЮ, Р вРЪЦХ бЮФХаЦРйШХ бблЫЪШ ЭР нвШ ЯХаХЬХЭЭлХ Т вРСЫ. 7.10 ЯаШТХФХЭ бЯШбЮЪ бвРЭФРавЭле СШСЫШЮвХЪ Perl (ТХабШШ 5.003), ЯапЬЮ ШЫШ ЪЮбТХЭЭЮ ШбЯЮЫмЧгойШе нвШ ЭХЦХЫРвХЫмЭлХ ЯХаХЬХЭЭлХ. ѕСаРвШвХ ТЭШЬРЭШХ: ЬЭЮУШХ СШСЫШЮвХЪШ ШбЯЮазХЭл ШбЯЮЫмЧЮТРЭШХЬ Carp.pm. µбЫШ ЧРУЫпЭгвм Т нвЮв дРЩЫ, Тл ЮСЭРагЦШвХ Т ЭХЬ вЮЫмЪЮ ЮФЭг бблЫЪг:
$eval =~ s/[\\\']/\\$&/g;
їаШТХФХЭШХ нвЮЩ бваЮЪШ Ъ ТШФг
$eval =~ s/([\\\'])/\\$1/g;
ШбЯаРТШв нвЮв ЭХФЮбвРвЮЪ ФЫп СЮЫмиШЭбвТР бвРЭФРавЭле СШСЫШЮвХЪ. їЮзХЬг нвЮ ЭХ СлЫЮ бФХЫРЭЮ Т бвРЭФРавЭЮЩ ЯЮбвРТЪХ? їЮЭпвШп ЭХ ШЬХо. ЅРФХобм, Т СгФгйХЩ ТХабШШ нвР ЯаЮСЫХЬР СгФХв аХиХЭР.
µбЫШ нвШ ЯХаХЬХЭЭлХ ЭШ аРЧг ЭХ ТбваХзРовбп Т ЯаЮУаРЬЬХ, вЮ ЪЮЯШаЮТРЭШХ ТлЯЮЫЭпХвбп ЫШим ЯаШ ШбЯЮЫмЧЮТРЭШШ Т ЯаЮУаРЬЬХ бЮеаРЭпойШе ЪагУЫле бЪЮСЮЪ ШЫШ m/…/i. ІЮЧЬЮЦЭЮ, ТРЬ ЯаШФХвбп ЯХаХЯШбРвм ЭХЪЮвЮалХ ТлаРЦХЭШп Т ЯаЮУаРЬЬХ. ЅРЯаШЬХа, $` зРбвЮ ШЬШвШагХвбп ЪЮЭбвагЪжШХЩ [(*?)] Т ЭРзРЫХ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, $& — ЧРЪЫозХЭШХЬ ТбХУЮ аХУгЫпаЭЮУЮ ТлаРЦХЭШп Т [(…)], Р &' — ЪЮЭбвагЪжШХЩ<$M[R7-60]> [(?=(.*))] Т ЪЮЭжХ.
їаШ ЭХЮСеЮФШЬЮбвШ ТЬХбвЮ аХУгЫпаЭле ТлаРЦХЭШЩ ЬЮЦЭЮ ЯаШСХУЭгвм Ъ ФагУШЬ баХФбвТРЬ. ЅРЯаШЬХа, ФЫп ЯЮШбЪР дШЪбШаЮТРЭЭле бваЮЪ ЬЮЦЭЮ ТЮбЯЮЫмЧЮТРвмбп дгЭЪжШХЩ index(…). І ЮЯШбРЭЭле ТлиХ вХбвРе нвЮ ЮСХбЯХзШТРЫЮ ЯЮзвШ 20-ЯаЮжХЭвЭлЩ аЮбв СлбваЮФХЩбвТШп ЯЮ баРТЭХЭШо б m/…/, ФРЦХ ЯаШ ЮвбгвбвТШШ ЧРваРв ЭР ЪЮЯШаЮТРЭШХ.
ВРСЫШжР 7.10. БвРЭФРавЭлХ СШСЫШЮвХЪШ, бЮФХаЦРйШХ бблЫЪШ ЭР ЯХаХЬХЭЭлХ бХЬХЩбвТР $&
|
C |
AutoLoader |
C |
Fcntl |
+C |
Pod::Text |
|
C |
AutoSplit |
|
File::Basename |
C |
POSIX |
|
C |
Benchmark |
C |
File::Copy |
C |
Safe |
|
C |
Carp |
C |
File::Find |
C |
SDBM_File |
|
C |
DB_File |
C |
File::Path |
C |
SelectSaver |
|
+CB |
diagnostics |
C |
FileCache |
C |
SelfLoader |
|
C |
DirHandle |
C |
FileHandle |
C |
Shell |
|
|
dotsh.pl |
C |
GDBM_File |
C |
Socket |
|
|
dumpvar.pl |
|
Getopt::Long |
C |
Sys::Hostname |
|
C |
DynaLoader |
C |
IPC:Open2 |
C |
Syslog |
|
|
English |
+C |
IPC:Open3 |
C |
Term::Cap |
|
+CB |
ExtUtils::Install |
C |
lib |
C |
Test::Harness |
|
+CB |
ExtUtils::LibList |
C |
Math::BigFloat |
C |
Test::ParseWords |
|
C |
ExtUtils::MakeMaker |
C |
MM_VMS |
C |
Text::Wrap |
|
+CB |
ExtUtils::Manifest |
+CL |
newgetopt.pl |
C |
Tie::Hash |
|
C |
ExtUtils::Mkbootstrap |
C |
ODBM_File |
C |
Tie::Scalar |
|
C |
ExtUtils::Mksymlists |
|
open2.pl |
C |
Tie::SubtrHash |
|
+CB |
ExtUtils::MM_Unix |
|
open3.pl |
C |
Time::Local |
|
C |
ExtUtils::testlib |
|
perl5db.pl |
C |
vars |
ЅХ аХЪЮЬХЭФгХвбп ШЧ-ЧР ШбЯЮЫмЧЮТРЭШп: C — Carp; B — File::Basename; E — English; L — Getopt::Long
<$M[R7-68]>·ФаРТлЩ бЬлбЫ ЯЮФбЪРЧлТРХв, звЮ ЯаШ ЯЮШбЪХ СХЧ гзХвР аХУШбваР бШЬТЮЫЮТ Perl ТлЯЮЫЭпХв ЪРЪго-вЮ ФЮЯЮЫЭШвХЫмЭго аРСЮвг. ІХаЮпвЭЮ, Тл ФРЦХ ЭХ ЯЮФЮЧаХТРХвХ, ЭРбЪЮЫмЪЮ Т ФХЩбвТШвХЫмЭЮбвШ гТХЫШзШТРХвбп ЮСкХЬ нвЮЩ аРСЮвл.
їаХЦФХ зХЬ ШбЯЮЫмЧЮТРвм ЮЯХаРвЮа ЯЮШбЪР ШЫШ ЯЮФбвРЭЮТЪШ б ЬЮФШдШЪРвЮаЮЬ /i, Perl бЭРзРЫР бЮЧФРХв ТаХЬХЭЭго ЪЮЯШо ТбХУЮ жХЫХТЮУЮ вХЪбвР. НвЮ ЪЮЯШаЮТРЭШХ ТлЯЮЫЭпХвбп ЭХЧРТШбШЬЮ Юв ЪЮЯШаЮТРЭШп, ЭХЮСеЮФШЬЮУЮ ФЫп ЯЮФФХаЦЪШ ЯХаХЬХЭЭле бХЬХЩбвТР $&. їЮбЫХФЭХХ ТлЯЮЫЭпХвбп вЮЫмЪЮ ЯаШ гбЯХиЭЮЬ бЮТЯРФХЭШШ, Р ЪЮЯШаЮТРЭШХ ФЫп ЯЮФФХаЦЪШ ЯЮШбЪР СХЧ гзХвР аХУШбваР ТлЯЮЫЭпХвбп ХйХ ФЮ ЯЮЯлвЪШ. їЮбЫХ ТлЯЮЫЭХЭШп ЪЮЯШаЮТРЭШп ЬХеРЭШЧЬ аХУгЫпаЭле ТлаРЦХЭШЩ ФХЫРХв ЯЮТвЮаЭЮ ЯХаХСШаРХв бШЬТЮЫл бваЮЪШ, ЯаХЮСаРЧгп ТбХ бШЬТЮЫл ТХаеЭХУЮ аХУШбваР Ъ ЭШЦЭХЬг. ІЮЧЬЮЦЭЮ, аХЧгЫмвРв ЭХ СгФХв ЮвЫШзРвмбп Юв ЮаШУШЭРЫР, ЭЮ Т ЫоСЮЬ бЫгзРХ ТбХ бШЬТЮЫл бваЮЪШ ЯаШТЮФпвбп Ъ ЭШЦЭХЬг аХУШбваг.
ЅРапФг б нвШЬ ЯаХЮСаРЧЮТРЭШХЬ ФЮЯЮЫЭШвХЫмЭРп аРСЮвР ТлЯЮЫЭпХвбп ЭР бвРФШШ ЪЮЬЯШЫпжШШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп ТЮ ТЭгваХЭЭХХ ЯаХФбвРТЫХЭШХ. ЅР нвЮЩ бвРФШШ бШЬТЮЫл ТХаеЭХУЮ аХУШбваР Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ вРЪЦХ ЯаХЮСаРЧговбп Т ЭШЦЭШЩ аХУШбва.
АХЧгЫмвРвЮЬ нвШе ФТге ЮЯХаРжШЩ пТЫпХвбп бваЮЪР Ш аХУгЫпаЭЮХ ТлаРЦХЭШХ, ФЫп ЪЮвЮале ЧРвХЬ ТлЯЮЫЭпХвбп бвРЭФРавЭлЩ ЯЮШбЪ — ЭР нвЮЩ бвРФШШ ЬХеРЭШЧЬг аХУгЫпаЭле ТлаРЦХЭШЩ гЦХ ЭХ ЯаШеЮФШвбп ФХЫРвм ЭШзХУЮ ЮбЮСХЭЭЮУЮ ШЫШ ШЧЫШиЭХУЮ. ЅР ЯХаТлЩ ТЧУЫпФ беХЬР ТлУЫпФШв ЮзХЭм ЯаЮбвЮ, ЭЮ Т ФХЩбвТШвХЫмЭЮбвШ ЯХаХФ ТРЬШ ЮФЭЮ ШЧ бРЬле ЭХЮСЮбЭЮТРЭЭле ЯаЮпТЫХЭШЩ ЭХнддХЪвШТЭЮбвШ Т Perl.
БгйХбвТгХв ЯЮ ЪаРЩЭХЩ ЬХаХ ФТР аРбЯаЮбваРЭХЭЭле ЯЮФеЮФР Ъ аХРЫШЧРжШШ ЯЮШбЪР СХЧ гзХвР аХУШбваР. ѕФШЭ ШЧ ЭШе, ЮЯШбРЭЭлЩ ТлиХ, п ЭРЧлТРо «ЮаШХЭвШаЮТРЭЭлЬ ЭР бваЮЪг» (Р вРЪЦХ «ЭХЮСЮбЭЮТРЭЭЮ ЭХнддХЪвШТЭлЬ», ЪРЪ УЮТЮаШЫЮбм ТлиХ). ґагУЮЩ, ЭР ЬЮЩ ТЧУЫпФ — УЮаРЧФЮ ЫгзиШЩ бЯЮбЮС, ЭРЧлТРХвбп «ЮаШХЭвШаЮТРЭЭлЬ ЭР аХУгЫпаЭЮХ ТлаРЦХЭШХ». ѕЭ аРСЮвРХв б ШбеЮФЭЮЩ бваЮЪЮЩ, бЮФХаЦРйХЩ бШЬТЮЫл аРЧЭЮУЮ аХУШбваР, Ш ЯЮЧТЮЫпХв ЬХеРЭШЧЬг ЯаШЭШЬРвм аХиХЭШп Ю аРЧЫШзШпе Т аХУШбваХ бШЬТЮЫЮТ ЯЮ ЬХаХ ЭХЮСеЮФШЬЮбвШ.
ЯаЮТХаЪР «ЧРУапЧЭХЭШп» ЯаЮУаРЬЬ ШбЯЮЫмЧЮТРЭШХЬ $&
ґРЫХЪЮ ЭХ ТбХУФР ЬЮЦЭЮ гТХаХЭЭЮ ЮЯаХФХЫШвм, ТбваХзРовбп ЫШ Т ТРиХЩ ЯаЮУаРЬЬХ бблЫЪШ ЭР $`, $& Ш &' — ЮбЮСХЭЭЮ ЯаШ ШбЯЮЫмЧЮТРЭШШ СШСЫШЮвХЪ. П ФРЦХ ЬЮФШдШжШаЮТРЫ бТЮо ТХабШо Perl вРЪ, звЮСл ЯаШ ЯХаТЮЬ ЮСЭРагЦХЭШШ нвШе ЯХаХЬХЭЭле ЮЭР ТлФРТРЫР ЯаХФгЯаХЦФХЭШХ (ХбЫШ Тл еЮвШвХ бФХЫРвм вЮ ЦХ бРЬЮХ, ЭРЩФШвХ ваШ нЪЧХЬЯЫпаР sawampersand Т дРЩЫХ gv.c ШЧ ЯЮбвРТЪШ Perl Ш ФЮСРТмвХ бЮЮвТХвбвТгойШЩ ТлЧЮТ warn).
БгйХбвТгХв СЮЫХХ ЯаЮбвЮХ аХиХЭШХ, ЮбЭЮТРЭЭЮХ ЭР еаЮЭЮЬХваРЦХ ЯаЮУаРЬЬЭЮУЮ ЪЮФР (еЮвп ЮЭЮ ЭХ бЮЮСйРХв Ю вЮЬ, УФХ ЭРеЮФШвбп ЯХаХЬХЭЭРп-ЭРагиШвХЫм). ЅРЯаШЬХа, ЬЮЦЭЮ ТЮбЯЮЫмЧЮТРвмбп бЫХФгойХЩ дгЭЪжШХЩ:
sub CheckNaughtiness
{
local($_) = 'x' x 10000; # ±ЮЫмиЮЩ даРУЬХЭв ФРЭЭле
# ІлзШбЫШвм $overhead ФЫп ЯгбвЮУЮ жШЪЫР
local($start) = (times)[0];
for ($i = 0; $i < 5000; $i++) { }
local($overhead) = (times)[0] - $start;
# ІлзШбЫШвм $delta ФЫп вЮУЮ ЦХ ЪЮЫШзХбвТР ШвХаРжШЩ
$start = (times)[0];
for ($i = 0; $i < 5000; $i++) { m/^/; }
local($delta) = (times)[0] - $start;
# µбЫШ $delta ЯаХТлиРХв $overhead Т 10 аРЧ Ш СЮЫХХ -
# ЧЭРзШв, ЯаЮУаРЬЬР ЧРУапЧЭХЭР (ЮжХЭЪР ЯЮЫгзХЭР нТаШбвШзХбЪШЬ ЯгвХЬ)
printf "It seems your code is %s (overhead=%.2f, delta=%.2f)\n",
($delta > $overhead*10) ? "naughty":"clean", $overhead, $delta;
}
єЮЭХзЭЮ, вРЪШХ дгЭЪжШШ ЭХ ФЮЫЦЭл ЯаШбгвбвТЮТРвм Т ЮЪЮЭзРвХЫмЭЮЩ ТХабШШ ЯаЮУаРЬЬл, ЮФЭРЪЮ Тл ЬЮЦХвХ ТаХЬХЭЭЮ ТбвРТШвм дгЭЪжШо Т ЯаХФТРаШвХЫмЭго ТХабШо Ш ТлЧТРвм ХХ Т ЭРзРЫХ ЯаЮУаРЬЬл. ІЮЧЬЮЦЭЮ, баРЧг ЦХ ЯЮбЫХ ТлЧЮТР бЫХФгХв ЯЮбвРТШвм exit Ш гФРЫШвм дгЭЪжШо ЯЮбЫХ ЯЮЫгзХЭШп ЮвТХвР. ЅЮ ФРЦХ ХбЫШ Тл ЧЭРХвХ, звЮ ТРиР ЯаЮУаРЬЬР «зШбвР» ЯЮ ЮвЭЮиХЭШо Ъ $&, ЮбвРХвбп ТЮЧЬЮЦЭЮбвм ХХ бЫгзРЩЭЮУЮ ЧРУапЧЭХЭШп ЯаШ ТлЧЮТХ eval ТЮ ТаХЬп аРСЮвл, ЯЮнвЮЬг ФЫп ЯгйХЩ ЭРФХЦЭЮбвШ ЯаЮТХаЪг бвЮШв ЯЮТвЮаШвм Т ЪЮЭжХ ЯаЮУаРЬЬл.
јЭЮУШХ ЯЮФТлаРЦХЭШп (Р вРЪЦХ ЯЮЫЭлХ аХУгЫпаЭлХ ТлаРЦХЭШп) ЭХ ваХСгов бЯХжШРЫмЭЮЩ ЮСаРСЮвЪШ. їаЮУаРЬЬР РЭРЫШЧР ФРЭЭле, аРЧФХЫХЭЭле ЧРЯпвлЬШ, Т ЭРзРЫХ УЫРТл (б. <$R[P#,R7-54]>); аХУгЫпаЭЮХ ТлаРЦХЭШХ ФЫп ТЪЫозХЭШп ЧРЯпвле Т зШбЫР (б. <$R[P#,R7-59]>); ФРЦХ ЮУаЮЬЭЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЮСкХЬЮЬ 4 724 СРЩвР, ЪЮвЮаЮХ Ьл ЯЮбваЮШЬ Т аРЧФХЫХ «їЮШбЪ РФаХбЮТ нЫХЪваЮЭЭЮЩ ЯЮзвл» (б. <$R[P#,R7-15]>) — ТбХ нвШ ТлаРЦХЭШп ЮСеЮФпвбп СХЧ бЯХжШРЫмЭЮЩ ЮСаРСЮвЪШ аХУШбваР бШЬТЮЫЮТ. їЮШбЪ СХЧ гзХвР аХУШбваР Т вРЪШе ТлаРЦХЭШпе ЭХ ФЮЫЦХЭ ЮваШжРвХЫмЭЮ ТЫШпвм ЭР СлбваЮФХЩбвТШХ.
ґРЦХ ЯаШбгвбвТШХ СгЪТ Т бШЬТЮЫмЭЮЬ ЪЫРббХ ЭХ ФЮЫЦЭЮ ЯаШТЮФШвм Ъ бЭШЦХЭШо нддХЪвШТЭЮбвШ. ІЮ ТаХЬп ЪЮЬЯШЫпжШШ Т бШЬТЮЫмЭлЩ ЪЫРбб ЬЮЦЭЮ СХЧ вагФР ТЪЫозШвм ТХабШо ТбХе СгЪТ ШЧ ФагУЮУЮ аХУШбваР (нддХЪвШТЭЮбвм бШЬТЮЫмЭЮУЮ ЪЫРббР ЭХ бТпЧРЭР б ЪЮЫШзХбвТЮЬ ТеЮФпйШе Т ЭХУЮ бШЬТЮЫЮТ — бЬ. б. <$R[P#,R4-40]>). БЫХФЮТРвХЫмЭЮ, ЭХЮСеЮФШЬЮбвм Т ФЮЯЮЫЭШвХЫмЭЮЩ аРСЮвХ ТЮЧЭШЪРХв вЮЫмЪЮ ЯаШ ТеЮЦФХЭШШ СгЪТ Т ЫШвХаРЫмЭлЩ вХЪбв, Р вРЪЦХ ЯаШ ШбЯЮЫмЧЮТРЭШШ ЮСаРвЭле бблЫЮЪ. ЕЮвп Ш Т вРЪШе бШвгРжШпе ЯаШеЮФШвбп звЮ-вЮ ФХЫРвм, бгйХбвТгов СЮЫХХ нддХЪвШТЭлХ аХиХЭШп, зХЬ ЪЮЯШаЮТРЭШХ ТбХЩ жХЫХТЮЩ бваЮЪШ.
єбвРвШ, п ЧРСлЫ гЯЮЬпЭгвм, звЮ ЯаШ ШбЯЮЫмЧЮТРЭШШ ЬЮФШдШЪРвЮаР /g ЪЮЯШаЮТРЭШХ ТлЯЮЫЭпХвбп ЯаШ ЪРЦФЮЩ ЯЮЯлвЪХ ЯЮШбЪР. ГвХиРХв ЫШим вЮ, звЮ ЪЮЯШп бЮЧФРХвбп Юв ЭРзРЫмЭЮЩ ЯЮЧШжШШ ЯЮШбЪР ФЮ ЪЮЭжР бваЮЪШ — ЯаШ ШбЯЮЫмЧЮТРЭШШ m/…/ig Т ФЫШЭЭле бваЮЪРе ЯЮ ЬХаХ ЯаЮФТШЦХЭШп Ъ ЪЮЭжг бваЮЪШ ЪЮЯШШ бвРЭЮТпвбп ТбХ ЪЮаЮзХ Ш ЪЮаЮзХ.
П ЯаЮТХЫ ЭХбЪЮЫмЪЮ вХбвЮТ, РЭРЫЮУШзЭле ЮЯШбРЭЭлЬ ЭР б. <$R[P#,R7-122]>. їаШ нвЮЬ ШбЯЮЫмЧЮТРЫШбм вХ ЦХ вХбвЮТлХ ФРЭЭлХ — дРЩЫ б ШбеЮФЭлЬ вХЪбвЮЬ Perl ЭР пЧлЪХ C, бЮбвЮпйШЩ ШЧ 52 011 бваЮЪ Ш 1 192 395 СРЩв.
їХаТлЩ вХбв СлЫ бРЬлЬ ЭШЧЪШЬ Ш ЦХбвЮЪШЬ. П ЧРУагЧШЫ ТХбм дРЩЫ Т ЮФЭг бваЮЪг Ш ЯаЮТХЫ баРТЭШвХЫмЭлХ ЧРЬХал ФЫп 1 while m/./g Ш 1 while m/./gi. єЮЭХзЭЮ, вЮзЪР ЭШЪРЪ ЭХ бТпЧРЭР б аХУШбваЮЬ бШЬТЮЫЮТ, ЯЮнвЮЬг Т ФРЭЭЮЬ ЯаШЬХаХ ЯЮШбЪ СХЧ гзХвР аХУШбваР ТаЮФХ Сл ЭХ ФЮЫЦХЭ ШЬХвм ЮваШжРвХЫмЭле ЯЮбЫХФбвТШЩ. ЅР ЬЮХЬ ЪЮЬЯмовХаХ ЯХаТРп ЪЮЬРЭФР ТлЯЮЫЭпЫРбм ЮЪЮЫЮ 12 бХЪгЭФ. їаЮбвЮХ ФЮСРТЫХЭШХ ЬЮФШдШЪРвЮаР /i (Т ФРЭЭЮЬ ЯаШЬХаХ РСбЮЫовЭЮ СХббЬлбЫХЭЭЮУЮ) ЧРЬХФЫШЫЮ аРСЮвг ЯаЮУаРЬЬл ЭР зХвлаХ ЯЮапФЪР, ФЮ ЯЮЫгвЮаР бгвЮЪ[49]! П ЯЮФбзШвРЫ, звЮ ШЧ-ЧР ЭХЭгЦЭЮУЮ ЪЮЯШаЮТРЭШп Perl ЯаШиЫЮбм ЯЮЯгбвг ЯХаХФРТРвм Т ЯРЬпвШ бТлиХ 647 585 ЬХУРСРЩв. НвЮ ЮбЮСХЭЭЮ ЮСШФЭЮ, ЯЮбЪЮЫмЪг ТЮ ТаХЬп ЪЮЬЯШЫпжШШ ЬЮЦЭЮ СлЫЮ нЫХЬХЭвРаЭЮ ЮЯаХФХЫШвм, звЮ ФЫп аХУгЫпаЭЮУЮ ТлаРЦХЭШп [.] ЯЮШбЪ СХЧ гзХвР аХУШбваР ЭШ ЭР звЮ ЭХ ТЫШпХв.
ЅХбЮЬЭХЭЭЮ, нвЮв ЭХаХРЫмЭлЩ вХбв ЯаХФбвРТЫпЫ егФиго ШЧ ТЮЧЬЮЦЭле бШвгРжШЩ. І СЮЫХХ аХРЫШбвШзЭЮЬ бЫгзРХ бЮТЯРФХЭШп ТбваХзРовбп аХЦХ, ЯЮнвЮЬг п ЯаЮТХЫ вХбвШаЮТРЭШХ ЪЮЬРЭФ m/\bwhile\b/gi Ш m/\b[wW][hH][iI][lL][eE]\b/g ФЫп вЮЩ ЦХ бваЮЪШ. ·ФХбм п ЯЮЯлвРЫбп бРЬЮбвЮпвХЫмЭЮ ШЬШвШаЮТРвм аХРЫШЧРжШо, ЮаШХЭвШаЮТРЭЭго ЭР аХУгЫпаЭлХ ТлаРЦХЭШп. ґЫп ЯЮФЮСЭле аХРЫШЧРжШЩ СлЫЮ Сл ТХаеЮЬ ЭРШТЭЮбвШ ЯаХЮСаРЧЮТлТРвм ЫШвХаРЫмЭлЩ вХЪбв Т бШЬТЮЫмЭлХ ЪЫРббл[50], ЯЮнвЮЬг Ьл СгФХЬ бзШвРвм /i-нЪТШТРЫХЭв «егФиХЩ бШвгРжШХЩ» бТЮХУЮ аЮФР. АгзЭЮХ ЯаХЮСаРЧЮТРЭШХ [while] Т [[wW][hH][iI][lL][eE]] вРЪЦХ ШбЪЫозРХв ЮЯвШЬШЧРжШо ЯаЮТХаЪШ дШЪбШаЮТРЭЭле бваЮЪ (б. <$R[P#,R5-13]>) Ш ФХЫРХв ЯаШЬХЭХЭШХ study (б. <$R[P#,R7-5]>) СХбЯЮЫХЧЭлЬ ФЫп ФРЭЭЮУЮ ТлаРЦХЭШп. їЮбЫХ ТбХУЮ бЪРЧРЭЭЮУЮ ЬЮЦЭЮ ЮЦШФРвм, звЮ нвЮ аХиХЭШХ СгФХв аРСЮвРвм ЮзХЭм ЬХФЫХЭЭЮ. ѕФЭРЪЮ Ш ЯаШ нвЮЬ ЮЭЮ аРСЮвРХв Т 50 аРЧ СлбваХХ ТХабШШ б /i!
ІХаЮпвЭЮ, Ш нвЮв вХбв ЮбвРХвбп ЭХбЯаРТХФЫШТлЬ — ЮСкХЬ ЪЮЯШаЮТРЭШп, ЮСгбЫЮТЫХЭЭЮУЮ ЭРЫШзШХЬ /i, Юв ЭРзРЫР вХбвЮТле ФРЭЭле Ш ЯЮбЫХ ЪРЦФЮУЮ ШЧ 412 бЮТЯРФХЭШЩ [\bwhile\b] Т ЬЮХЬ ЯаШЬХаХ, ЮбвРХвбп СЮЫмиШЬ (ЯЮЬЭШвХ: ЮСкХЬ бваЮЪШ СЮЫмиХ ЬХУРСРЩвР!) їЮЯаЮСгХЬ ЯаЮвХбвШаЮТРвм m/^int/i Ш m/^[iI][nN][tT]/ Т ЪРЦФЮЩ ШЧ 50 000 бваЮЪ вХбвЮТЮУЮ дРЩЫР. І нвЮЬ бЫгзРХ /i ЯаШТХФХв Ъ ЪЮЯШаЮТРЭШо ЪРЦФЮЩ бваЮЪШ ЯХаХФ ЯЮЯлвЪЮЩ ЯЮШбЪР, ЭЮ ШЧ-ЧР ЭХСЮЫмиЮУЮ аРЧЬХаР бваЮЪ ЧРваРвл ЮЪРЦгвбп ЭХ бвЮЫм бЮЪагиШвХЫмЭлЬШ, ЪРЪ ЯаХЦФХ: ТХабШп б /i вХЯХам аРСЮвРХв ТбХУЮ ЭР 77 ЯаЮжХЭвЮТ ЬХФЫХЭЭХХ. І ФХЩбвТШвХЫмЭЮбвШ ЧРЬХФЫХЭШХ ЮСгбЫЮТЫХЭЮ Ш бЮЧФРЭШХЬ ФЮЯЮЫЭШвХЫмЭле ЪЮЯШЩ ФЫп ЪРЦФЮУЮ ШЧ 148 бЮТЯРФХЭШЩ — ТбЯЮЬЭШвХ, m/…/i СХЧ ЬЮФШдШЪРвЮаР /g бвРЭЮТШвбп ЯаШзШЭЮЩ ЪЮЯШаЮТРЭШп, ЮСХбЯХзШТРойХУЮ ЯЮФФХаЦЪг $&.
єРЪ ЯЮЪРЧлТРов ЯЮбЫХФЭШХ вХбвл, ЧРваРвл, бТпЧРЭЭлХ б ЯаШЬХЭХЭШХЬ /i, ЭХ вРЪ бваРиЭл, ЪРЪ ЬЮЦХв ЯЮЪРЧРвмбп ЯЮбЫХ ЯХаТЮУЮ вХбвР. ё ТбХ ЦХ нвЮ ЯаЮСЫХЬР, ЪЮвЮаго ЭХЮСеЮФШЬЮ гзШвлТРвм. ЅРФХобм, Т СгФгйШе ТХабШпе Perl бРЬлХ ЧРЬХвЭлХ ЭХФЮбвРвЪШ СгФгв гбваРЭХЭл.
іЫРТЭЮХ ЯаРТШЫЮ: ЭХ ШбЯЮЫмЧгЩвХ ЬЮФШдШЪРвЮа /i, ХбЫШ ЬЮЦХвХ СХЧ ЭХУЮ ЮСЮЩвШбм. ±ХЧФгЬЭЮХ ТЪЫозХЭШХ ЬЮФШдШЪРвЮаР Т аХУгЫпаЭЮХ ТлаРЦХЭШХ, УФХ ЮЭ ЭХ ЮСпЧРвХЫХЭ, ЫШим бЯЮбЮСбвТгХв ЭРЯаРбЭЮЬг аРбеЮФЮТРЭШо аХбгабЮТ. ёЬШвРжШп аХиХЭШЩ, ЮаШХЭвШаЮТРЭЭле ЭР аХУгЫпаЭлХ ТлаРЦХЭШп, ЬЮЦХв ЮСХбЯХзШвм СЮЫмиЮЩ ТлШУали Т бЪЮаЮбвШ — ЮбЮСХЭЭЮ ЯаШ аРСЮвХ б СЮЫмиШЬШ бваЮЪРЬШ. ґТР ЯЮбЫХФЭШе ЯаШЬХаР ЯЮФвТХаЦФРов бЪРЧРЭЭЮХ.
єРЪ СлЫЮ бЪРЧРЭЮ ТлиХ, п ЭХ пТЫпобм нЪбЯХавЮЬ Т ЮСЫРбвШ ТЭгваХЭЭХУЮ гбваЮЩбвТР Perl. єЮУФР аХзм ЧРеЮФШв Ю вЮЬ, ЪРЪ ЮЯХаРвЮа ЯЮФбвРЭЮТЪШ Perl ЯХаХЬХйРХв Т ЯРЬпвШ бваЮЪШ Ш ЯЮФбваЮЪШ Т ЯаЮжХббХ ЯЮФбвРЭЮТЪШ, п ТЯРФРо Т ЯЮЫЭго ЯаЮбваРжШо. АХРЫШЧРжШп Ш ЫЮУШЪР аРСЮвл ЯаЮУаРЬЬ — вХЬР ЭХ ФЫп бЫРСЮЭХаТЭле.
ѕФЭРЪЮ ЬЭХ ТбХ ЦХ гФРЫЮбм ЭХЬЭЮЦЪЮ аРЧЮСаРвмбп Т аРСЮвХ ЮЯХаРвЮаР ЯЮФбвРЭЮТЪШ[51] Ш бдЮаЬгЫШаЮТРвм апФ ЯаЮбвле ЯаРТШЫ, ЪЮвЮалЬШ п еЮзг ЯЮФХЫШвмбп б ТРЬШ. ·РаРЭХХ ЯаХФгЯаХЦФРо: бЪРЧРЭЭЮХ ЭХЫмЧп ЮСЮСйШвм Т ЭХбЪЮЫмЪШе ЯаЮбвле бЫЮТРе. Perl зРбвЮ ЯЮ ЪагЯШжРЬ бЮСШаРХв ТЮЧЬЮЦЭЮбвШ ФЫп ТЭгваХЭЭШе ЮЯвШЬШЧРжШЩ, Р ЮСШЫШХ ЯаРТШЫ Ш ШбЪЫозХЭШЩ, бТпЧРЭЭле б ЮЯХаРвЮаЮЬ ЯЮФбвРЭЮТЪШ, ЮвЪалТРХв иШаЮЪШХ ТЮЧЬЮЦЭЮбвШ ФЫп вРЪШе ЮЯвШЬШЧРжШЩ. ѕЪРЧлТРХвбп, ЪЮЯШаЮТРЭШХ ФЫп ЯЮФФХаЦЪШ $& ШбЪЫозРХв ЫоСлХ ЮЯвШЬШЧРжШШ, бТпЧРЭЭлХ б ЯЮФбвРЭЮТЪРЬШ — вХЬ СЮЫмиХ ЯаШзШЭ ФЫп ШЧУЭРЭШп ЯХаХЬХЭЭЮЩ $& Ш ХХ ФагЧХЩ ШЧ ЯаЮУаРЬЬ.
ЅРзЭХЬ б ТЮЧТаРйХЭШп Ъ егФиХЬг бЫгзРо ЮЯХаРвЮаР ЯЮФбвРЭЮТЪШ.
І егФиХЬ бЫгзРХ ЮЯХаРвЮа ЯЮФбвРЭЮТЪШ ЯаЮбвЮ бваЮШв ЭЮТго ЪЮЯШо жХЫХТЮЩ бваЮЪШ, Р ЧРвХЬ ЬХЭпХв ХХ ЬХбвРЬШ б ЮаШУШЭРЫЮЬ. ЅРЯаШЬХа, ЮФЭЮбваЮзЭРп ЯаЮУаРЬЬР ЯаХЮСаРЧЮТРЭШп вХЬЯХаРвгаЭЮЩ иЪРЫл, ЯаШТХФХЭЭРп Т ЭРзРЫХ нвЮЩ УЫРТл:
s[(\d+(\.\d*)?)F\b]{sprintf "%.0fC",($1-32) * 5/9}eg
бЮТЯРФРХв Т ЯЮФзХаЪЭгвле ЬХбвРе бЫХФгойХЩ бваЮЪШ:
Water boils at 212F, freezes at 32F.
ѕСЭРагЦШТ ЯХаТЮХ бЮТЯРФХЭШХ, Perl бЮЧФРХв ТаХЬХЭЭго Ягбвго бваЮЪг Ш ЪЮЯШагХв Т ЭХХ ТбХ бШЬТЮЫл, ЯаХФиХбвТгойШХ бЮТЯРФХЭШо («Waterspcboilsspcatspc»). ·РвХЬ ТлзШбЫпХвбп вХЪбв ЧРЬХЭл (Т ФРЭЭЮЬ ЯаШЬХаХ — 100C), ЪЮвЮалЩ ФЮЯШблТРХвбп Т ЪЮЭХж ТаХЬХЭЭЮЩ бваЮЪШ. єбвРвШ УЮТЮап, ШЬХЭЭЮ ЭР нвЮЩ бвРФШШ ЯаЮШЧТЮФШвбп ЪЮЯШаЮТРЭШп ФЫп ЯЮФФХаЦЪШ $&, ХбЫШ Т ЭХЬ ТЮЧЭШЪРХв ЭХЮСеЮФШЬЮбвм.
їаШ ЮСЭРагЦХЭШШ бЫХФгойХУЮ бЮТЯРФХЭШп (ЮСгбЫЮТЫХЭЭЮЬ ЬЮФШдШЪРвЮаЮЬ /g) ТЮ ТаХЬХЭЭго бваЮЪг ФЮСРТЫпХвбп вХЪбв, аРбЯЮЫЮЦХЭЭлЩ ЬХЦФг ФТгЬп бЮТЯРФХЭШпЬШ, ЧР ЪЮвЮалЬ бЫХФгХв ТЭЮТм ТлзШбЫХЭЭлЩ вХЪбв ЧРЬХЭл 0C. ЅРЪЮЭХж, ЪЮУФР ФРЫмЭХЩиШХ ЯЮЯлвЪШ ЯЮШбЪР ЧРТХаиРовбп ЭХгФРзХЩ, ЪЮЯШаговбп ЮбвРЫмЭлХ бШЬТЮЫл (Т ФРЭЭЮЬ ЯаШЬХаХ — ЯаЮбвЮ ЧРТХаиРойРп вЮзЪР), Ш ЯЮбваЮХЭШХ ТаХЬХЭЭЮЩ бваЮЪШ ЧРТХаиРХвбп. І аХЧгЫмвРвХ ЯЮЫгзРХвбп бваЮЪР бЫХФгойХУЮ ТШФР:
Water boils at 100C, freezes at 0C.
ёбеЮФЭРп жХЫХТРп бваЮЪР, $_, гФРЫпХвбп Ш ЧРЬХЭпХвбп ТаХЬХЭЭЮЩ бваЮЪЮЩ (п ЯЮЫРУРЫ, звЮ ШбеЮФЭлЩ вХЪбв ЬЮЦХв ШбЯЮЫмЧЮТРвмбп ФЫп ЯЮФФХаЦЪШ $1, $& Ш в. Ф., ЭЮ нвЮ ЭХ вРЪ — ЯаШ ЭХЮСеЮФШЬЮбвШ бЮЧФРХвбп ЮвФХЫмЭРп ЪЮЯШп).
ЅР ЯХаТлЩ ТЧУЫпФ вРЪЮЩ бЯЮбЮС ЯЮбваЮХЭШп аХЧгЫмвРвР ТлУЫпФШв ТЯЮЫЭХ аРЧгЬЭЮ, ЯЮбЪЮЫмЪг Т ЮСйХЬ бЫгзРХ ЮЭ ФХЩбвТШвХЫмЭЮ ТЯЮЫЭХ аРЧгЬХЭ. ЅЮ ЯаХФбвРТмвХ бХСХ ЯаЮбвго ЪЮЬРЭФг ТШФР s/\s+$// ФЫп гФРЫХЭШп ЧРТХаиРойШе ЯаЮЯгбЪЮТ. ЅгЦЭЮ ЫШ ЪЮЯШаЮТРвм Тбо (ТЮЧЬЮЦЭЮ — ЮзХЭм СЮЫмиго) бваЮЪг вЮЫмЪЮ ФЫп вЮУЮ, звЮСл ЮвбХзм ЭХбЪЮЫмЪЮ бШЬТЮЫЮТ Т бРЬЮЬ ЪЮЭжХ? ВХЮаХвШзХбЪШ — ЭХ ЭгЦЭЮ. ЅР ЯаРЪвШЪХ Perl нвЮУЮ Ш ЭХ ФХЫРХв… ЯЮ ЪаРЩЭХЩ ЬХаХ, ФХЫРХв ЭХ ТбХУФР.
Г Perl еТРвРХв бЮЮСаРЧШвХЫмЭЮбвШ ЭР вЮ, звЮСл ЮЯвШЬШЧШаЮТРвм s/\s+$// ЯаЮбвЮЩ аХУгЫШаЮТЪЮЩ ФЫШЭл жХЫХТЮЩ бваЮЪШ. ЅХЮСеЮФШЬЮбвм Т ШЧЫШиЭХЬ ЪЮЯШаЮТРЭШШ ЯаШ нвЮЬ ЮвЯРФРХв — ТбХ ЯаЮШбеЮФШв ЮзХЭм СлбваЮ. ѕФЭРЪЮ ЯЮ ЯаШзШЭРЬ, бЬлбЫ ЪЮвЮале ЮбвРХвбп ФЫп ЬХЭп ЧРУРФЪЮЩ, нвР ЮЯвШЬШЧРжШп (Р вРЪЦХ ТбХ ЮбвРЫмЭлХ ЮЯвШЬШЧРжШШ ЯЮФбвРЭЮТЪШ, гЯЮЬШЭРХЬлХ ЭШЦХ) ЯЮФРТЫпХвбп б ЪЮЯШаЮТРЭШХЬ ФЫп ЯЮФФХаЦЪШ $&. їЮзХЬг? ЅХ ЧЭРо, ЭЮ ЭР ЯаРЪвШЪХ нвЮ ХйХ ЮФЭЮ ШЧ ЯаЮпТЫХЭШЩ УгСШвХЫмЭЮУЮ ТЫШпЭШп $& ЭР нддХЪвШТЭЮбвм ТРиШе ЯаЮУаРЬЬ.
єЮЯШаЮТРЭШХ ФЫп ЯЮФФХаЦЪШ $& вРЪЦХ ТлЯЮЫЭпХвбп ЯаШ ЭРЫШзШШ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ бЮеаРЭпойШе ЪагУЫле бЪЮСЮЪ, еЮвп Т нвЮЬ бЫгзРХ ЮЭЮ еЮвп Сл ЯаШЭЮбШв ЪРЪго-вЮ ЯЮЫмЧг (ЯЮбЪЮЫмЪг ЯЮпТЫпХвбп ТЮЧЬЮЦЭЮбвм ШбЯЮЫмЧЮТРвм $1 Ш ФагУШХ ЯХаХЬХЭЭлХ). БЮеаРЭпойШХ ЪагУЫлХ бЪЮСЪШ вРЪЦХ ЯЮФРТЫпов ЮЯвШЬШЧРжШШ ЯЮФбвРЭЮТЪШ, ЭЮ ЬХаХ вЮЫмЪЮ ФЫп вХе аХУгЫпаЭле ТлаРЦХЭШЩ, Т ЪЮвЮале ЮЭШ ШбЯЮЫмЧговбп, Р ЭХ ФЫп ТбХе ТлаРЦХЭШЩ баРЧг, ЪРЪ $&.
єЮЬРЭФР s/\s+$// ЯаШЭРФЫХЦШв Ъ зШбЫг ЯаШЬХаЮТ, бЫХФгойШе ЮЯаХФХЫХЭЭЮЬг ЮСаРЧжг: ЪЮУФР ФЫШЭР ЧРЬХЭпойХУЮ вХЪбвР ЭХ ЯаХТлиРХв ФЫШЭл ЧРЬХЭпХЬЮУЮ вХЪбвР, ХУЮ ЬЮЦЭЮ ТбвРТШвм ЯапЬЮ Т бваЮЪг, Р ЭХЮСеЮФШЬЮбвм Т ЯЮЫЭЮЬ ЪЮЯШаЮТРЭШШ ТбХЩ бваЮЪШ ЮвЯРФРХв. ЅР аШб. 7.2 ШЧЮСаРЦХЭР зРбвм ЯаШЬХаР бЮ б.<$R[P#,R2-10]> — ЯаШЬХЭХЭШХ ЪЮЬРЭФл s/<FIRST>/Tom/ Ъ бваЮЪХ Dearspc<FIRST>,new. ЅЮТлЩ вХЪбв ЪЮЯШагХвбп ЯЮТХае ЧРЬХЭпХЬЮУЮ, Р вХЪбв, бЫХФгойШЩ ЧР бЮТЯРФХЭШХЬ, бФТШУРХвбп Ш ЧРЯЮЫЭпХв ТЮЧЬЮЦЭлХ ЯаЮЬХЦгвЪШ.
АШб. 7.2. їаШЬХЭХЭШХ ЪЮЬРЭФл s/<FIRST>/Tom/ Ъ бваЮЪХ Dearspc<FIRST>,new
І ЯаШЬХаХ б s/\s+$// ЭХв ЭХЮСеЮФШЬЮбвШ ЪЮЯШаЮТРвм вХЪбв ЯЮТХае бваЮЪШ Ш бФТШУРвм ЯЮбЫХФгойШХ бШЬТЮЫл — ЯЮбЫХ ЮСЭРагЦХЭШп бЮТЯРФХЭШп ФЫШЭР бваЮЪШ ЯЮЯаЮбвг гЬХЭмиРХвбп вРЪ, звЮСл бЮТЯРТиРп зРбвм СлЫР гФРЫХЭР, ТЮв Ш ТбХ. ІбХ ЯаЮШбеЮФШв ЮзХЭм СлбваЮ. °ЭРЫЮУШзЭлХ ЮЯвШЬШЧРжШШ вРЪЦХ ЬЮУгв ШбЯЮЫмЧЮТРвмбп Ш ФЫп бЮТЯРФХЭШЩ Т ЪЮЭжХ бваЮЪШ.
µбЫШ ФЫШЭР вХЪбвР ЧРЬХЭл Т вЮзЭЮбвШ бЮТЯРФРХв б ФЫШЭЮЩ бЮТЯРТиХУЮ вХЪбвР, ЬЮЦЭЮ ЯЮФгЬРвм, звЮ нвЮв бЫгзРЩ вРЪЦХ ЮвЪалТРХв ТЮЧЬЮЦЭЮбвм ФЫп ЮЯвШЬШЧРжШШ — бФТШУ бШЬТЮЫЮТ ФЫп ЧРЯЮЫЭХЭШп ЯаЮЬХЦгвЪЮТ ЬЮЦЭЮ ЮЯгбвШвм, ЯЮбЪЮЫмЪг ЯаШ аРТХЭбвТХ ФЫШЭ ЭШЪРЪШе ЯаЮЬХЦгвЪЮТ ЭХ СгФХв. їЮ ЪРЪШЬ-вЮ ЯаШзШЭРЬ нвЮв ЭХЭгЦЭЮХ «ЯХаХЬХйХЭШХ» ТбХ аРТЭЮ ТлЯЮЫЭпХвбп. ІЯаЮзХЬ, РЫУЮаШвЬ Т бТЮХЩ вХЪгйХЩ аХРЫШЧРжШШ ЭШЪЮУФР ЭХ ЪЮЯШагХв СЮЫмиХ ЯЮЫЮТШЭл бваЮЪШ (ЮЭ ФЮбвРвЮзЭЮ гЬХЭ, звЮСл ЮЯаХФХЫШвм, ЪРЪго зРбвм бЫХФгХв ЪЮЯШаЮТРвм — ЯаХФиХбвТгойго бЮТЯРФХЭШо ШЫШ аРбЯЮЫЮЦХЭЭго ЯЮбЫХ ЭХУЮ).
·РЬХЭР б /g аРСЮвРХв згвм нддХЪвШТЭХХ. ·РЯЮЫЭХЭШХ ЯаЮЬХЦгвЪР ЯаЮШбеЮФШв ЫШим ЯЮбЫХ вЮУЮ, ЪРЪ бвРЭЮТШвбп ШЧТХбвЭЮ ЪЮЫШзХбвТЮ ЯХаХЬХйРХЬле бШЬТЮЫЮТ (ЯХаХЬХйХЭШХ ЮвЪЫРФлТРХвбп ФЮ вЮУЮ ЬЮЬХЭвР, ЪЮУФР бвРЭХв вЮзЭЮ ШЧТХбвЭР ЯЮЧШжШп бЫХФгойХУЮ бЮТЯРФХЭШп). єаЮЬХ вЮУЮ, Т нвЮЬ бЫгзРХ СХббЬлбЫХЭЭЮХ ЧРЯЮЫЭХЭШХ ЭХбгйХбвТгойШе ЯаЮСХЫЮТ, ТШФШЬЮ, ЭХ ТлЯЮЫЭпХвбп.
ІбХ ЯХаХзШбЫХЭЭлХ ЮЯвШЬШЧРжШШ ЯаШЬХЭповбп ЫШим Т вЮЬ бЫгзРХ, ХбЫШ Perl ЧРаРЭХХ ЧЭРХв ФЫШЭг ЧРЬХЭпойХЩ бваЮЪШ. НвЮ ЮЧЭРзРХв, звЮ ЯаШбгвбвТШХ Т ЧРЬХЭпойХЩ бваЮЪХ $1 ШЫШ ФагУШе ЯХаХЬХЭЭле нвЮУЮ бХЬХЩбвТР ШбЪЫозРХв ТЮЧЬЮЦЭЮбвм ЮЯвШЬШЧРжШЩ[52]. ІЯаЮзХЬ, Ъ ШЭвХаЯЮЫпжШШ ФагУШе ЯХаХЬХЭЭле нвЮ ЭХ ЮвЭЮбШвбп. І ЯаШТХФХЭЭЮЬ ТлиХ ЯаШЬХаХ ШбеЮФЭРп ЯЮФбвРЭЮТЪР ТлУЫпФХЫР вРЪ:
$given = 'Tom';
$letter =~ s/<FIRST>/$given/g;
їХаХЬХЭЭлХ Т бваЮЪХ ЧРЬХЭл ШЭвХаЯЮЫШаговбп ФЮ ЭРзРЫР ЯЮШбЪР, ЯЮнвЮЬг аРЧЬХа аХЧгЫмвРвР ШЧТХбвХЭ ЧРаРЭХХ.
єЮЭХзЭЮ, ЯаШ ЯЮФбвРЭЮТЪХ б ЬЮФШдШЪРвЮаЮЬ /e аРЧЬХа вХЪбвР ЧРЬХЭл бвРЭЮТШвбп ШЧТХбвЭлЬ ЫШим ЯЮбЫХ ЯЮШбЪР, Р ЮЯХаРЭФ ЧРЬХЭл ТлзШбЫпХвбп ЯЮ ЯаРТШЫРЬ eval, ЯЮнвЮЬг ЯаШ ШбЯЮЫмЧЮТРЭШШ нвЮУЮ ЬЮФШдШЪРвЮаР ЮЯвШЬШЧРжШп вРЪЦХ ЭХ ТлЯЮЫЭпХвбп.
ёЧ-ЧР ЬЭЮУЮзШбЫХЭЭле ЯЮЯлвЮЪ ЮЯвШЬШЧРжШШ ЬЮЦЭЮ б гТХаХЭЭЮбвмо бЪРЧРвм ЫШим ЮФЭЮ: ЮФЭЮЧЭРзЭЮУЮ аХЧгЫмвРвР ЭШЪвЮ ЭХ УРаРЭвШагХв. їЮЬШЬЮ ЮЯШбРЭЭле ЬЭЮЩ ЯаРТШЫ Ш ШбЪЫозХЭШЩ бгйХбвТгХв ЬШЫЫШЮЭ ФагУШе, Ш ЭХЪЮвЮалХ ТЭгваХЭЭШХ ЯаШЭжШЯл аРСЮвл ЭРТХаЭпЪР ШЧЬХЭпвбп Т СгФгйШе ТХабШпе. µбЫШ ЮЯвШЬШЧРжШп ФЫп ТРб ФЮбвРвЮзЭЮ ТРЦЭР — звЮ Ц, ТХаЮпвЭЮ, Тл ЭХ ЯЮЦРЫХХвХ ТаХЬХЭШ ЭР вХбвШаЮТРЭШХ.
»гзиШЩ бЯЮбЮС ЮжХЭЪШ нддХЪвШТЭЮбвШ ТРиХЩ ЯаЮУаРЬЬл — еаЮЭЮЬХваРЦ. І Perl5 ШЬХХвбп ЬЮФгЫм Benchmark, ЭЮ ЮЭ «ЧРУапЧЭХЭ» ШбЯЮЫмЧЮТРЭШХЬ $&. НвЮ ТХбмЬР ЯаШбЪЮаСЭЮ, ЯЮбЪЮЫмЪг ШЧ-ЧР бЭШЦХЭШп СлбваЮФХЩбвТШп аХЧгЫмвРвл еаЮЭЮЬХваРЦР бвРЭЮТпвбп СХббЬлбЫХЭЭлЬШ. П ЯаХФЯЮзШвРо ЯаЮбвЮХ аХиХЭШХ, ЯаШ ЪЮвЮаЮЬ ЯаЮТХапХЬлЩ ЪЮФ ЯаЮбвЮ ЧРЪЫозРХвбп Т ЪЮЭбвагЪжШо ТШФР:
$start = (times)[0];
…
$delta = (times)[0] - $start;
printf "took %.1f seconds", $delta
їаШ ЯаЮТХФХЭШШ еаЮЭЮЬХваРЦР бЫХФгХв гзШвлТРвм ЮФЭЮ ТРЦЭЮХ ЮСбвЮпвХЫмбвТЮ. ІбЫХФбвТШХ УаРЭгЫпаЭЮбвШ зРбЮТ (Т СЮЫмиШЭбвТХ бШбвХЬ — 1/60 ШЫШ 1/100 бХЪгЭФл) вХбвШагХЬлЩ ЪЮФ ФЮЫЦХЭ ТлЯЮЫЭпвмбп еЮвп Сл Т вХзХЭШХ ЭХбЪЮЫмЪШе бХЪгЭФ. µбЫШ ЪЮФ ТлЯЮЫЭпХвбп бЫШиЪЮЬ СлбваЮ, ЯХаХЯШиШвХ ЯаЮУаРЬЬг Ш ТлЯЮЫЭпЩвХ ХУЮ Т жШЪЫХ. єаЮЬХ вЮУЮ, ЯЮбвРаРЩвХбм ШбЪЫозШвм ШЧ вХбвШагХЬЮЩ зРбвШ ТбХ ЯЮСЮзЭлХ ЮЯХаРжШШ. ЅРЯаШЬХа, бЫХФгойШЩ даРУЬХЭв:
$start = (times)[0]; # ·РЯгбвШвм зРбл
$count = 0;
while (<>) {
$count++ while m/\b(?:char\b|return|\b|void\b)/g;
}
print "found $count items.\n";
$delta = (times)[0] - $start; # ѕбвРЭЮТШвм зРбл
printf "the benchmark took %.1f seconds.\n", $delta;
ЫгзиХ ЧРЯШбРвм Т ТШФХ:
$count = 0; # Нвг ЮЯХаРжШо ЭХЧРзХЬ ТЪЫозРвм Т ШЧЬХаХЭШп, гСШаРХЬ ШЧ жШЪЫР
@lines = <>; # ІХбм дРЩЫЮТлЩ ТТЮФ/ТлТЮФ ТлЯЮЫЭпХвбп ФЮ ЭРзРЫР жШЪЫР,
# звЮСл ЬХФЫХЭЭлХ ЮЯХаРжШШ б ФШбЪЮЬ ЭХ ТЫШпЫШ ЭР аХЧгЫмвРвл
$start = (times)[0]; # їЮФУЮвЮТЪР ЧРЪЮЭзХЭР, ЯгбЪРХЬ зРбл
foreach (@lines) {
$count++ while m/\b(?:char\b|return|\b|void\b)/g;
}
$delta = (times)[0] - $start; # ѕбвРЭЮТШвм зРбл
print "found $count items.\n"; # ІлТЮФ вЮЦХ ШбЪЫозРХвбп ШЧ еаЮЭЮЬХваРЦР
printf "the benchmark took %.1f seconds.\n", $delta;
БРЬЮХ СЮЫмиЮХ ШЧЬХЭХЭШХ ЧРЪЫозРХвбп Т вЮЬ, звЮ ШЧ еаЮЭЮЬХваШагХЬЮУЮ даРУЬХЭвР СлЫ ШбЪЫозХЭ ТХбм дРЩЫЮТлЩ ТТЮФ/ТлТЮФ. єЮЭХзЭЮ, ЯаШ ЭХеТРвЪХ ЯРЬпвШ ЬЮЦХв ЭРзРвмбп ТлУагЧЪР ЭР ФШбЪ, Ш ТХбм ТлШУали вХапХвбп — ЯаЮбЫХФШвХ ЧР вХЬ, звЮСл нвЮУЮ ЭХ бЫгзШЫЮбм. ЗвЮСл ШЬШвШаЮТРвм СЮЫмиЮЩ ЮСкХЬ ФРЭЭле, ЬЮЦЭЮ ТЮбЯЮЫмЧЮТРвмбп ЬХЭмиШЬ ЭРСЮаЮЬ аХРЫмЭле ФРЭЭле Ш ЮСаРСЮвРвм Ше ЭХбЪЮЫмЪЮ аРЧ:
for ($i = 0; $i < 10; $i++) {
foreach (@lines) {
$count++ while m/\b(?:char\b|return|\b|void\b)/g;
}
}
ІЮЧЬЮЦЭЮ, ЭР вЮ, звЮСл ЯаШТлЪЭгвм Ъ аРЧгЬЭЮЩ ЮаУРЭШЧРжШШ еаЮЭЮЬХваРЦР, ЯЮЭРФЮСШвбп ЭХЪЮвЮаЮХ ТаХЬп, ЮФЭРЪЮ аХЧгЫмвРвл ЬЮУгв Слвм ТХбмЬР ЯЮгзШвХЫмЭлЬШ Ш ЮЯаРТФлТРойШЬШ ТРиШ еЫЮЯЮвл.
БваХЬпбм ЪРЪ ЬЮЦЭЮ СлбваХХ ЭРЩвШ бЮТЯРФХЭШХ ФЫп аХУгЫпаЭЮУЮ ТлаРЦХЭШп, Perl ТлЯЮЫЭпХв дХЭЮЬХЭРЫмЭЮХ ЪЮЫШзХбвТЮ ЮЯвШЬШЧРжШХЩ. ЅРШЬХЭХХ вРШЭбвТХЭЭлХ аРЧЭЮТШФЭЮбвШ ЮЯвШЬШЧРжШЩ ЯХаХзШбЫХЭл Т аРЧФХЫХ «ІЭгваХЭЭШХ ЮЯвШЬШЧРжШШ» УЫРТл 5 (б. <$R[P#,R5-17]>). µбЫШ ТРиР ТХабШп Perl СлЫР ЮвЪЮЬЯШЫШаЮТРЭР б ТЪЫозХЭШХЬ ЮвЫРФЮзЭЮЩ ШЭдЮаЬРжШШ (ЪЫоз -DDEBUGGING ЯаШ бСЮаЪХ), ЯЮпТЫпХвбп ТЮЧЬЮЦЭЮбвм ШбЯЮЫмЧЮТРЭШп ЪЫозР ЪЮЬРЭФЭЮЩ бваЮЪШ -D. єЫоз -Dr (-D512 Т Perl4) ТлФРХв ШЭдЮаЬРжШо Ю вЮЬ, ЪРЪ Perl ЪЮЬЯШЫШагХв ТРиХ аХУгЫпаЭЮХ ТлаРЦХЭШХ Ш ТлФРХв ЯЮФаЮСЭго ШЭдЮаЬРжШо Ю ЪРЦФЮЬ ЯаШЫЮЦХЭШШ.
±ЮЫмиШЭбвТЮ ФРЭЭле, ТлФРТРХЬле ЪЫозЮЬ -Dr, ТлеЮФШв ЧР аРЬЪШ нвЮЩ ЪЭШУШ, ЮФЭРЪЮ ЭХЪЮвЮалХ ШЧ нвШе бТХФХЭШЩ ТЯЮЫЭХ ЯЮЭпвЭл. АРббЬЮваШЬ ЯаЮбвЮЩ ЯаШЬХа (п ШбЯЮЫмЧго Perl ТХабШШ 5.003):
(1) jfriedl@tubby> perl -cwDr -e '/^Subject: (.*)/'
(2) rarest char j at 3
(3) first 14 next 83 offset 4
(4) 1:BRANCH(47)
(5) 5:BOL(9)
(6) 9:EXACTLY(23) <Subject: >
(7) 23:OPEN1(29)
…
(8) 47:END(0)
(9) start 'Subject: ' anchored minlen 9
І бваЮЪХ (1) п ЧРЯгбЪРо Perl ШЧ ЯаШУЫРиХЭШп ЪЮЬРЭФЭЮУЮ ШЭвХаЯаХвРвЮаР, ШбЯЮЫмЧгп РаУгЬХЭвл ЪЮЬРЭФЭЮЩ бваЮЪШ -c (вЮЫмЪЮ ЯаЮТХаШвм бжХЭРаШЩ СХЧ ТлЯЮЫЭХЭШп), -w (ТлФРТРвм ЯаХФгЯаХЦФХЭШп Ю ЪЮЭбвагЪжШпе, ЯЮФЮЧаШвХЫмЭле б вЮзЪШ ЧаХЭШп Perl — бЫХФгХв ШбЯЮЫмЧЮТРвм ЯаРЪвШзХбЪШ ТбХУФР), -Dr (ЮвЫРФЪР аХУгЫпаЭле ТлаРЦХЭШЩ) Ш -e (Т бЫХФгойХЬ РаУгЬХЭвХ ЯХаХФРХвбп даРУЬХЭв ЯаЮУаРЬЬЭЮУЮ ЪЮФР Perl). НвР ЪЮЬСШЭРжШп ЪЫозХЩ гФЮСЭР ФЫп ЯаЮТХаЪШ аХУгЫпаЭле ТлаРЦХЭШЩ Т аХЦШЬХ ЪЮЬРЭФЭЮЩ бваЮЪШ. АХУгЫпаЭЮХ ТлаРЦХЭШХ ['/^Subject:spc(.*)/'] ЭХЮФЭЮЪаРвЭЮ ТбваХзРЫЮбм ЭР бваРЭШжРе нвЮЩ ЪЭШУШ.
БваЮЪШ (4)-(8) ЮЯШблТРов ЮвЪЮЬЯШЫШаЮТРЭЭго дЮаЬг ТлаРЦХЭШп Т Perl. І ЮбЭЮТЭЮЬ нвР ШЭдЮаЬРжШп ЭХ ЯаХФбвРТЫпХв ШЭвХаХбР, ЭЮ ФРЦХ ЯаШ СХУЫЮЬ ТЧУЫпФХ бваЮЪР (6) ТлУЫпФШв ЧЭРЪЮЬЮ.
<$M[R7-124]>јЭЮУШХ ЮЯвШЬШЧРжШШ ЮбЭЮТРЭл ЭР вЮЬ, звЮ Perl ЯаШеЮФШв Ъ ТлТЮФг Ю ЮСпЧРвХЫмЭЮЬ ЯаШбгвбвТШШ ЭХЪЮвЮаЮУЮ дШЪбШаЮТРЭЭЮУЮ ЫШвХаРЫмЭЮУЮ вХЪбвР Т ЫоСЮЬ ТЮЧЬЮЦЭЮЬ бЮТЯРФХЭШШ (п ЭРЧЮТг нвЮ ЮСбвЮпвХЫмбвТЮ «гзХвЮЬ ЫШвХаРЫмЭЮУЮ вХЪбвР»). І ФРЭЭЮЬ ЯаШЬХаХ нвЮ вХЪбв Subject:spc, ЮФЭРЪЮ ТЮ ЬЭЮУШе ТлаРЦХЭШпе ЮСпЧРвХЫмЭЮУЮ ЫШвХаРЫмЭЮУЮ вХЪбвР ЭХв, ШЫШ бЯЮбЮСЭЮбвХЩ Perl ЭХ еТРвРХв ЭР вЮ, звЮСл ХУЮ ТлзШбЫШвм (нвЮ ЮФЭР ШЧ вХе ЮСЫРбвХЩ ЮЯвШЬШЧРжШШ, Т ЪЮвЮале Emacs ЯаХТЮбеЮФШв Perl; б. <$R[P#,R6-5]>). І зРбвЭЮбвШ, Perl ЭХ ЬЮЦХв ЯаШФвШ ЭШ Ъ ЪРЪЮЬг ТлТЮФг ФЫп бЫХФгойШе ТлаРЦХЭШЩ: [-?[0-9]+)\.[0-9]*)?|\.[0-9]+)], [^\s*], [^(-?\d+)(\d{3})] Ш ФРЦХ [int|void|while].
°ЭРЫШЧШагп [int|void|while], ЬЮЦЭЮ ЧРЬХвШвм, звЮ бШЬТЮЫ i ЯаШбгвбвТгХв ТЮ ТбХе РЫмвХаЭРвШТРе. ЅХЪЮвЮалХ ЬХеРЭШЧЬл Ѕє° ЧРЬХзРов нвЮв дРЪв (Р ЬХеРЭШЧЬ ґє° ЧЭРХв Ю ЭХЬ ЪЮбТХЭЭЮ), ЭЮ Ъ бЮЦРЫХЭШо, ЬХеРЭШЧЬ аХУгЫпаЭле ТлаРЦХЭШЩ Perl Ъ Ше зШбЫг ЭХ ЮвЭЮбШвбп. І ЮвЫРФЮзЭле ФРЭЭле int, void Ш while СгФгв ТлТХФХЭл Т бваЮЪРе, ЭРЯЮЬШЭРойШе (6), ЭЮ нвЮ ЫШим ЫЮЪРЫмЭлХ ваХСЮТРЭШп (ЯЮФТлаРЦХЭШп). ґЫп гзХвР ЫШвХаРЫмЭЮУЮ вХЪбвР Perl ЭХЮСеЮФШЬл УЫЮСРЫмЭлХ ЧЭРЭШп ЭР гаЮТЭХ аХУгЫпаЭЮУЮ ТлаРЦХЭШп Т жХЫЮЬ; Т ЮСйХЬ бЫгзРХ Perl ЭХ бЬЮЦХв ТлзШбЫШвм дШЪбШаЮТРЭЭлЩ вХЪбв ЯЮ РЫмвХаЭРвШТРЬ, ТеЮФпйШЬ Т ЪЮЭбвагЪжШо ТлСЮаР.
ІЮ ЬЭЮУШе аХУгЫпаЭле ТлаРЦХЭШпе — ЭРЯаШЬХа, [<CODE>(.*?)</CODE>] — бЮФХаЦШвбп ЭХбЪЮЫмЪЮ даРУЬХЭвЮТ ЫШвХаРЫмЭЮУЮ вХЪбвР. І вРЪШе бЫгзРпе Perl ТлСШаРХв ЮФШЭ ШЫШ ФТР даРУЬХЭвР Ш ЯХаХФРХв Ше ФЫп ШбЯЮЫмЧЮТРЭШп ЯаЮжХФгаРЬ ЮЯвШЬШЧРжШШ. ІлСаРЭЭлХ даРУЬХЭвл ТлТЮФпвбп Т бваЮЪРе, ЭРЯЮЬШЭРойШе бваЮЪг (9).
І бваЮЪХ (9) ЬЮЦХв бЮФХаЦРвмбп ШЭдЮаЬРжШп Ю аРЧЭле ТШФРе ЮЯвШЬШЧРжШЩ. ЅШЦХ ЯХаХзШбЫХЭл ЭХЪЮвЮалХ ШЧ зРбвЮ ТбваХзРойШебп бЯЮбЮСЮТ ЮЯвШЬШЧРжШШ<$M[R7-123]>:
start 'вХЪбв' — ЮЧЭРзРХв, звЮ бЮТЯРФХЭШХ ФЮЫЦЭЮ ЭРзШЭРвмбп б ЧРФРЭЭЮУЮ вХЪбвР (ЮФЭЮУЮ ШЧ даРУЬХЭвЮТ, ЭРЩФХЭЭле Т аХЧгЫмвРвХ гзХвР ЫШвХаРЫмЭЮУЮ вХЪбвР). НвЮ ЯЮЧТЮЫпХв Perl ТлЯЮЫЭпвм вРЪШХ ТШФл ЮЯвШЬШЧРжШШ, ЪРЪ ЯаЮТХаЪР дШЪбШаЮТРЭЭле бваЮЪ Ш ШбЪЫозХЭШХ ЯЮ ЯХаТЮЬг бШЬТЮЫг, ЮЯШбРЭЭлХ Т УЫРТХ 5.
must have "вХЪбв" back зШбЫЮ — ЮЧЭРзРХв, звЮ бЮТЯРФХЭШХ ФЮЫЦЭЮ бЮФХаЦРвм ЮСпЧРвХЫмЭлЩ даРУЬХЭв вХЪбвР (ЪРЪ Ш Т ЯаХФлФгйХЩ ЮЯвШЬШЧРжШШ), ЭЮ нвЮв даРУЬХЭв ЭХ ЮСпЧРЭ ЭРеЮФШвмбп Т ЭРзРЫХ ЫШвХаРЫмЭЮУЮ ТлаРЦХЭШп. µбЫШ зШбЫЮ ЭХ аРТЭЮ –1, Perl ЧЭРХв, звЮ бЮТЯРФХЭШХ ФЮЫЦЭЮ ЭРзШЭРвмбп ЭР гЪРЧРЭЭЮХ ЪЮЫШзХбвТЮЬ бШЬТЮЫЮТ аРЭмиХ ЯаШТХФХЭЭЮУЮ вХЪбвР. ЅРЯаШЬХа, ФЫп ТлаРЦХЭШп [[Tt]ubby] ТлТЮФШвбп бЮЮСйХЭШХ must have "ubby" back 1; нвЮ ЮЧЭРзРХв, звЮ ХбЫШ ЯаЮТХаЪР дШЪбШаЮТРЭЭле бваЮЪ ЮСЭРагЦШТРХв ЯЮФбваЮЪг ubby, ЭРзШЭРойгобп б ЭХЪЮвЮаЮЩ ЯЮЧШжШШ, вЮ ТбХ бЮТЯРФХЭШХ ФЮЫЦЭЮ ЭРзШЭРвмбп ЭР ЮФШЭ бШЬТЮЫ аРЭмиХ.
ґЫп ТлаРЦХЭШЩ ТШФР [.*ubby] ЭРзРЫмЭРп ЯЮЧШжШп ЯЮФбваЮЪШ ubby ЭХбгйХбвТХЭЭР, ЯЮбЪЮЫмЪг бЮТЯРФХЭШХ, Т ЪЮвЮаЮХ ЮЭР ТеЮФШв, ЬЮЦХв ЭРзШЭРвмбп Т ЫоСЮЩ ШЧ ЯаХФиХбвТгойШе ЯЮЧШжШЩ, ЯЮнвЮЬг зШбЫЮ Т нвЮЬ бЫгзРХ аРТЭЮ –1.
stclass ':вШЯ' — ЮЧЭРзРХв, звЮ бЮТЯРФХЭШХ ФЮЫЦЭЮ ЭРзШЭРвмбп б бШЬТЮЫР ЮЯаХФХЫХЭЭЮУЮ вШЯР. ґЫп ТлаРЦХЭШп [\s+] вШЯ ЧРЬХЭпХвбп бваЮЪЮЩ SPACE, Р ФЫп [\d+] — бваЮЪЮЩ DIGIT. ґЫп бШЬТЮЫмЭле ЪЫРббЮТ, ЪРЪ Т ЯаШТХФХЭЭЮЬ ТлиХ ЯаШЬХаХ [[Tt]ubby], ШбЯЮЫмЧгХвбп бваЮЪР ANYOF.
plus — ЮЧЭРзРХв, звЮ Ъ stclass ШЫШ ЮФЭЮЬг ЭРзРЫмЭЮЬг бШЬТЮЫг start ЯаШЬХЭпХвбп ЪТРЭвШдШЪРвЮа [+], ЯЮнвЮЬг ШбЪЫозХЭШХ ЯЮ ЯХаТЮЬг бШЬТЮЫг ЭХ вЮЫмЪЮ ЭРеЮФШв ЭРзРЫЮ ЯЮвХЭжШРЫмЭЮУЮ бЮТЯРФХЭШп, ЭЮ Ш СлбваЮ ЮСеЮФШв [\s+] Ш ФагУШХ ЭРзРЫмЭлХ ЪЮЭбвагЪжШШ, ЯаХЦФХ зХЬ ЯЮЫЭлЩ (ЭЮ СЮЫХХ ЬХФЫХЭЭлЩ) ЬХеРЭШЧЬ аХУгЫпаЭле ТлаРЦХЭШЩ ЭРзЭХв ЯаЮТХаЪг ЯЮЫЭЮУЮ бЮТЯРФХЭШп.
anchored — ЮЧЭРзРХв, звЮ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЭРзШЭРХвбп б пЪЮаЭЮУЮ ЬХвРбШЬТЮЫР ^. їаШ нвЮЬ ЯЮпТЫпХвбп ТЮЧЬЮЦЭЮбвм ШбЯЮЫмЧЮТРЭШп ЮЯвШЬШЧРжШШ, ЮСгбЫЮТЫХЭЭЮЩ ЯаШТпЧЪЮЩ Ъ УаРЭШжРЬ ЫЮУШзХбЪШе бваЮЪ/даРУЬХЭвЮТ (б. <$R[P#,R5-3]>).
implicit — ЮЧЭРзРХв, звЮ Perl ЭХпТЭЮ ТЪЫозРХв Т ЭРзРЫЮ аХУгЫпаЭЮУЮ ТлаРЦХЭШп ЬХвРбШЬТЮЫ ^, ЯЮбЪЮЫмЪг аХУгЫпаЭЮХ ТлаРЦХЭШХ ЭРзШЭРХвбп б [.*] (б. <$R[P#,R5-25]>).
µйХ ЮФЭР аРЧЭЮТШФЭЮбвм ЮЯвШЬШЧРжШШ, бТпЧРЭЭРп б гзХвЮЬ ЫШвХаРЫмЭЮУЮ вХЪбвР, ШЬХХв ЮвЭЮиХЭШХ Ъ дгЭЪжШШ study (бЬ. бЫХФгойШЩ аРЧФХЫ). Perl Т ЪРЪЮЩ-вЮ бвХЯХЭШ ЯаЮШЧТЮЫмЭЮ ТлФХЫпХв Т ТлСаРЭЭЮЬ ЫШвХаРЫмЭЮЬ вХЪбвХ ЮФШЭ бШЬТЮЫ, ЪЮвЮалЩ ЮЭ бзШвРХв «аХФЪШЬ». µбЫШ ЯХаХФ ЯЮШбЪЮЬ бваЮЪР СлЫР ЮСаРСЮвРЭР дгЭЪжШХЩ study, Perl ЭХЬХФЫХЭЭЮ гЧЭРХв Ю ЯаШбгвбвТШШ нвЮУЮ бШЬТЮЫР Т ЫоСЮЩ ЯЮЧШжШШ бваЮЪШ. µбЫШ бШЬТЮЫ ЮвбгвбвТгХв, бЮТЯРФХЭШХ Т ЯаШЭжШЯХ ЭХТЮЧЬЮЦЭЮ, Ш ЯаШТЫХЪРвм ЬХеРЭШЧЬ аХУгЫпаЭле ТлаРЦХЭШЩ ТЮЮСйХ ЭХ ЭгЦЭЮ. НвЮв ЯаШХЬ ЯЮЧТЮЫпХв СлбваЮ ШбЪЫозРвм ЭХЪЮвЮалХ ЭХТЮЧЬЮЦЭлХ бЮТЯРФХЭШп. ІлСаРЭЭлЩ бШЬТЮЫ бЮЮСйРХвбп Т бваЮЪХ (2).
ґЫп ЫоСШвХЫХЩ ТбХТЮЧЬЮЦЭле ЯЮЫХЧЭле Ш СХбЯЮЫХЧЭле бТХФХЭШЩ бЮЮСйг, звЮ бРЬлЬ аХФЪШЬ бШЬТЮЫЮЬ Perl бзШвРХв \000, Р ЧР ЭШЬ бЫХФгов \001, \013, \177 Ш \200. БаХФШ ЮвЮСаРЦРХЬле бШЬТЮЫЮТ ЭРШСЮЫХХ аХФЪШЬШ пТЫповбп ~, Q Ш Z, Р ЭРШСЮЫХХ зРбвлЬШ — e, ЯаЮСХЫ Ш t (Т ФЮЪгЬХЭвРжШШ бЪРЧРЭЮ, звЮ нвЮв дРЪв СлЫ гбвРЭЮТЫХЭ РЭРЫШЧЮЬ ЯаЮУаРЬЬ ЭР пЧлЪХ C Ш РЭУЫШЩбЪЮУЮ вХЪбвР).
<$M[R7-5]>ДгЭЪжШп study(…) ЮЯвШЬШЧШагХв ЭХ аХУгЫпаЭЮХ ТлаРЦХЭШХ, Р ФЮбвгЯ Ъ ШЭдЮаЬРжШШ Ю бваЮЪХ. І бЫгзРХ ЯаШЬХЭХЭШп аХУгЫпаЭЮУЮ ТлаРЦХЭШп (ШЫШ ЭХбЪЮЫмЪШе аХУгЫпаЭле ТлаРЦХЭШЩ) ЬЮЦЭЮ ФЮбвШУЭгвм бгйХбвТХЭЭЮУЮ ТлШУалиР ЧР бзХв ЭРЫШзШп ЪниШаЮТРЭЭле бТХФХЭШЩ Ю бваЮЪХ. їЮЭпвм ЯаШЭжШЯ аРСЮвл study ЭХбЫЮЦЭЮ; ЧЭРзШвХЫмЭЮ бЫЮЦЭХХ аРЧЮСаРвмбп Т вЮЬ, ЮСХбЯХзШТРХв ЮЭР ЪРЪЮЩ-ЭШСгФм ТлШУали ШЫШ ЭХв Т ЪРЦФЮЬ ЪЮЭЪаХвЭЮЬ бЫгзРХ. ДгЭЪжШп РСбЮЫовЭЮ ЭХ ТЫШпХв ЭР ЧЭРзХЭШп, ЮСаРСРвлТРХЬлХ ШЫШ ТЮЧТаРйРХЬлХ ЯаЮУаРЬЬЮЩ[53]. І аХЧгЫмвРвХ ХХ ЯаШЬХЭХЭШп Perl аРбеЮФгХв СЮЫмиХ ЯРЬпвШ, Р ЮСйХХ ТаХЬп аРСЮвл ЯаЮУаРЬЬл ЬЮЦХв гТХЫШзШвмбп, ЮбвРвмбп ЯаХЦЭШЬ ШЫШ гЬХЭмиШвмбп (ФЫп зХУЮ, бЮСбвТХЭЭЮ, Ш ЯаХФЭРЧЭРзХЭР нвР дгЭЪжШп).
їаШ ЮСаРСЮвЪХ бваЮЪШ дгЭЪжШХЩ study Perl аРбеЮФгХв ЭХЪЮвЮаЮХ ЪЮЫШзХбвТЮ ТаХЬХЭШ Ш ЯРЬпвШ ЭР ЯЮбваЮХЭШХ бЯШбЪР ЯЮЧШжШЩ, Т ЪЮвЮале ЪРЦФлЩ бШЬТЮЫ ЧРЭШЬРХв Т бваЮЪХ. І СЮЫмиШЭбвТХ бШбвХЬ ЧРваРвл ЯРЬпвШ Т зХвлаХ аРЧР ЯаХТлиРов аРЧЬХа бваЮЪШ (ЮФЭРЪЮ нвР ЯРЬпвм ЬЮЦХв ШбЯЮЫмЧЮТРвмбп ЧРЭЮТЮ ЯаШ ЯЮбЫХФгойШе ТлЧЮТРе study). ІлШУали Юв ТлЧЮТР study гТХЫШзШТРХвбп ЯаШ ЪРЦФЮЬ ЯЮбЫХФгойХЬ ЯЮШбЪХ аХУгЫпаЭЮУЮ ТлаРЦХЭШп Т бваЮЪХ, ЭЮ ЫШим ФЮ ЬЮЬХЭвР ЬЮФШдШЪРжШШ бваЮЪШ. їаШ ЫоСЮЩ ЬЮФШдШЪРжШШ бваЮЪШ ЯЮбваЮХЭЭлЩ бЯШбЮЪ бвРЭЮТШвбп ЭХФХЩбвТШвХЫмЭлЬ, ЪРЪ Ш ЯаШ ТлЧЮТХ study ФЫп ФагУЮЩ бваЮЪШ.
їЮбваЮХЭЭлЩ бЯШбЮЪ ЭШЪЮУФР ЭХ ШбЯЮЫмЧгХвбп ЬХеРЭШЧЬЮЬ аХУгЫпаЭле ТлаРЦХЭШЩ; б ЭШЬ аРСЮвРХв вЮЫмЪЮ ЯЮФбШбвХЬР бЬХйХЭШп вХЪгйХЩ ЯЮЧШжШШ ЯЮШбЪ. ѕЭР ЯаЮбЬРваШТРХв ФРЭЭлХ, ЮвЮСаРЦРХЬлХ Т бваЮЪРе start Ш must have ЮвЫРФЮзЭЮЩ ШЭдЮаЬРжШШ (бЬ. б. <$R[P#,R7-123]>), Ш ТлСШаРХв бШЬТЮЫ, ЪЮвЮалЩ бзШвРХвбп аХФЪШЬ (бЬ. ТлиХ). АХФЪШЩ (ЭЮ ЮСпЧРвХЫмЭЮ ЯаШбгвбвТгойШЩ Т бЮТЯРФХЭШШ!) бШЬТЮЫ ФЮЫЦХЭ б ЬХЭмиХЩ ТХаЮпвЭЮбвмо ТбваХзРвмбп Т бваЮЪРе ЯаШ ЮвбгвбвТШШ бЮТЯРФХЭШп, Ш ХбЫШ Т аХЧгЫмвРвХ СлбваЮЩ ЯаЮТХаЪШ ЯЮ бЯШбЪг study аХФЪШЩ бШЬТЮЫ ЭХ СгФХв ЭРЩФХЭ Т бваЮЪХ, ЧЭРзШв, бваЮЪг ЬЮЦЭЮ ЮвТХаУЭгвм СХЧ ЯХаХСЮаР ТбХе бШЬТЮЫЮТ.
µбЫШ аХФЪШЩ бШЬТЮЫ ТбваХзРХвбп Т бваЮЪХ Ш ХбЫШ ЮЭ ЧРЭШЬРХв ЪЮЭЪаХвЭго ЯЮЧШжШо ЯЮ ЮвЭЮиХЭШо Ъ ЫоСЮЬг ТЮЧЬЮЦЭЮЬг бЮТЯРФХЭШо (ЭРЯаШЬХа, ЪРЪ бШЬТЮЫ h Т ТлаРЦХЭШШ [..this], ЭЮ ЭХ Т [.?this]), ЯЮФбШбвХЬР бЬХйХЭШп вХЪгйХЩ ЯЮЧШжШШ ЬЮЦХв ШбЯЮЫмЧЮТРвм ФРЭЭлХ study ФЫп вЮУЮ, звЮСл ЭРзРвм ЯЮШбЪ ЯЮСЫШЧЮбвШ Юв ТлзШбЫХЭЭЮЩ ЯЮЧШжШШ. НвЮ ЯаШТЮФШв Ъ нЪЮЭЮЬШШ ТаХЬХЭШ, ЯЮбЪЮЫмЪг ЯЮЧТЮЫпХв ЮСЮЩвШ СЮЫмиШХ даРУЬХЭвл бваЮЪШ[54].
l ЅХ ШбЯЮЫмЧгЩвХ study ФЫп ЪЮаЮвЪШе жХЫХТле бваЮЪ. І вРЪШе бЫгзРпе ТЯЮЫЭХ ФЮбвРвЮзЭЮ ЮСлзЭЮЩ ЮЯвШЬШЧРжШШ б ЯаЮТХаЪЮЩ дШЪбШаЮТРЭЭле бваЮЪ.
l ЅХ ШбЯЮЫмЧгЩвХ study ЯаШ ЯЮШбЪХ ЭХСЮЫмиЮУЮ ЪЮЫШзХбвТР бЮТЯРФХЭШЩ Т жХЫХТЮЩ бваЮЪХ (ЯЮ ЪаРЩЭХЩ ЬХаХ ЯХаХФ ЬЮФШдШЪРжШХЩ бваЮЪШ ШЫШ ТлЧЮТЮЬ study ФЫп ФагУЮЩ бваЮЪШ). ѕСйХХ гбЪЮаХЭШХ СЮЫХХ ТХаЮпвЭЮ, ХбЫШ ТаХЬп, ЧРваРзХЭЭЮХ ЭР РЭРЫШЧ бваЮЪШ дгЭЪжШХЩ study, аРбЯаХФХЫпХвбп ЯЮ ЬЭЮУШЬ ЯЮЯлвЪРЬ ЯЮШбЪР.
БЫХФгХв гзШвлТРвм, звЮ Т вХЪгйХЩ аХРЫШЧРжШШ ЪЮЭбвагЪжШп m/…/g бзШвРХвбп ЮФЭЮЩ ЯЮЯлвЪЮЩ: бЯШбЮЪ ЯаЮбЬРваШТРХвбп вЮЫмЪЮ Т бРЬЮЬ ЭРзРЫХ. ІЯаЮзХЬ, ЯаШ ШбЯЮЫмЧЮТРЭШШ m/…/g Т бЪРЫпаЭЮЬ ЪЮЭвХЪбвХ бЯШбЮЪ ЯаЮТХапХвбп ФЫп ЪРЦФЮУЮ бЮТЯРФХЭШп, ЭЮ ЪРЦФлЩ РЧ ТЮЧТаРйРХвбп ЮФЭР Ш вР ЦХ ЯЮЧШжШп — ФЫп ТбХе бЮТЯРФХЭШЩ, ЪаЮЬХ ЯХаТЮУЮ, нвР ЯЮЧШжШп ЭРеЮФШвбп ЯХаХФ ЭРзРЫЮЬ бЮТЯРФХЭШп, ЯЮнвЮЬг вРЪРп ЯаЮТХаЪР ЮЪРЧлТРХвбп ЭРЯаРбЭЮЩ ваРвЮЩ ТаХЬХЭШ.
l ЅХ ШбЯЮЫмЧгЩвХ study Т бШвгРжШпе, ЪЮУФР ФЫп аХУгЫпаЭле ТлаРЦХЭШЩ ЭХ ЬЮЦХв Слвм ТлЯЮЫЭХЭ гзХв ЫШвХаРЫмЭЮУЮ вХЪбвР (б. <$R[P#,R7-124]>). ±ХЧ ЧЭРЭШп бШЬТЮЫЮТ, ЪЮвЮалХ ФЮЫЦЭл ЯаШбгвбвТЮТРвм Т ЫоСЮЬ бЮТЯРФХЭШШ, ТлЧЮТ study СХбЯЮЫХЧХЭ.
ЅРШСЮЫмиШЩ нддХЪв ЯаШ ТлЧЮТХ study ФЮбвШУРХвбп Т бШвгРжШШ, ЪЮУФР г ТРб ШЬХХвбп СЮЫмиРп бваЮЪР, Т ЪЮвЮаЮЩ ЯХаХФ ЬЮФШдШЪРжШХЩ СгФХв ЯаЮШЧТЮФШвмбп ЬЭЮУЮЪаРвЭлЩ ЯЮШбЪ. ЕЮаЮиШЬ ЯаШЬХаЮЬ пТЫпХвбп дШЫмва, ЭРЯШбРЭЭлЩ ЬЭЮЩ ЯаШ ЯЮФУЮвЮТЪХ нвЮЩ ЪЭШУШ. їаШ ЭРЯШбРЭШШ ЪЭШУШ п ШбЯЮЫмЧго бТЮЩ бЮСбвТХЭЭлЩ бвШЫм аРЧЬХвЪШ, ЪЮвЮалЩ ЯаХЮСаРЧгХвбп дШЫмваЮЬ Т SGML (ЪЮвЮалЩ ЧРвХЬ ЯаХЮСаРЧгХвбп Т дЮаЬРв troff, ЪЮвЮалЩ, Т бТЮо ЮзХаХФм, ЯаХЮСаРЧгХвбп Т PostScript). ІЮ ТаХЬп аРСЮвл дШЫмваР Тбп УЫРТР Т ЪЮЭХзЭЮЬ бзХвХ ЯаХТаРйРХвбп Т ЮФЭг УаЮЬРФЭго бваЮЪг (Т нвЮЩ УЫРТХ ХХ ЮСкХЬ ЯаХТлиРЫ 650 ЪШЫЮСРЩв). їХаХФ ЧРТХаиХЭШХЬ п ТлЯЮЫЭпо апФ ЯаЮТХаЮЪ, ЯаХФЭРЧЭРзХЭЭле ФЫп ЯЮШбЪР ТЮЧЬЮЦЭле ЮиШСЮЪ Т аРЧЬХвЪХ. їаЮТХаЪШ ЭХ ЬЮФШдШжШагов бваЮЪг Ш Т ЭШе зРбвЮ ТбваХзРовбп дШЪбШаЮТРЭЭлХ бваЮЪШ — нвЮ ЪРЪ аРЧ вР бШвгРжШп, ФЫп ЪЮвЮаЮЩ бЮЧФРТРЫРбм дгЭЪжШп study.
ДгЭЪжШо study б бРЬЮУЮ ЭРзРЫР ЯаХбЫХФЮТРЫ ЧЫЮЩ аЮЪ. ІЮ-ЯХаТле, ЬЭЮУШХ ЯаЮУаРЬЬШбвл вРЪ Ш ЭХ аРЧЮСаРЫШбм, ФЫп зХУЮ ЮЭР ЭгЦЭР. ·РвХЬ ШЧ-ЧР ЮиШСЮЪ Т Perl ТХабШЩ 5.000 Ш 5.001 нвР дгЭЪжШп бвРЫР РСбЮЫовЭЮ СХбЯЮЫХЧЭЮЩ. І ЯЮбЫХФгойШе ТХабШпе ЮиШСЪР СлЫР ШбЯаРТЫХЭР, ЭЮ ЧРвЮ ЯЮпТШЫРбм ЭЮТРп ЮиШСЪР, ШЭЮУФР ЯаШТЮФпйРп Ъ ЭХгФРзХ ЯаШ ЯЮШбЪХ бгйХбвТгойШе бЮТЯРФХЭШЩ Т $_ (ЭХ ШЬХойШе ЭШЪРЪЮУЮ ЮвЭЮиХЭШп Ъ бваЮЪХ, ФЫп ЪЮвЮаЮЩ ТлЧлТРЫРбм дгЭЪжШп study!) П ЮСЭРагЦШЫ нвг ЮиШСЪг, ТлпбЭпп, ЯЮзХЬг ЭХ аРСЮвРХв ЬЮЩ дШЫмва ЯаХЮСаРЧЮТРЭШп аРЧЬХвЪШ — ЯаШзХЬ нвЮ ЯаЮШЧЮиЫЮ ТЮ ТаХЬп ЭРЯШбРЭШп аРЧФХЫР, ЯЮбТпйХЭЭЮУЮ дгЭЪжШШ study! БЮТЯРФХЭШХ ЯЮ ЬХЭмиХЩ ЬХаХ ТлФРойХХбп.
їаЮСЫХЬг ЬЮЦЭЮ ЮСЮЩвШ пТЭлЬ ЯаШбТРШТРЭШХЬ undef ШЫШ ШЭЮЩ ЬЮФШдШЪРжШХЩ бваЮЪШ, ФЫп ЪЮвЮаЮЩ ТлЧлТРЫРбм дгЭЪжШп study (аРЧгЬХХвбп, ЯЮбЫХ ЧРТХаиХЭШп аРСЮвл б ЭХЩ). °ТвЮЬРвШзХбЪЮУЮ ЯаШбТРШТРЭШп $_ Т ЪЮЭбвагЪжШШ while(<>) ЭХФЮбвРвЮзЭЮ.
ЅЮ ФРЦХ ХбЫШ дгЭЪжШп study аРСЮвРХв, ЮЭР зРбвЮ ЭХ ШбЯЮЫмЧгХвбп Т ЯЮЫЭго бШЫг — ЫШСЮ ШЧ-ЧР ЯаЮбвле ЮиШСЮЪ, ЫШСЮ ШЧ-ЧР аХРЫШЧРжШШ, ЪЮвЮаРп ЯЮ бТЮШЬ вХЬЯРЬ аРЧТШвШп ЮвбвРХв Юв ЮбвРЫмЭле ЪЮЬЯЮЭХЭвЮТ Perl. ЅР ФРЭЭлЩ ЬЮЬХЭв п аХЪЮЬХЭФго ШЧСХУРвм ЯаШЬХЭХЭШп study, ХбЫШ г ТРб ЭХв вТХаФЮЩ гТХаХЭЭЮбвШ Т вЮЬ, звЮ Т ТРиХЩ ЪЮЭЪаХвЭЮЩ бШвгРжШШ ЮЭР ЯаШЭХбХв ЯЮЫмЧг. µбЫШ Тл ШбЯЮЫмЧгХвХ study ФЫп жХЫХТЮЩ бваЮЪШ $_, ЭХ ЧРСгФмвХ ЯаШбТЮШвм ХЩ ЭХЮЯаХФХЫХЭЭЮХ ЧЭРзХЭШХ ЯЮбЫХ ЧРТХаиХЭШп ЯЮШбЪР.
<$M[R7-14]>І нвЮЩ УЫРТХ Ьл ЯЮФаЮСЭЮ аРббЬЮваХЫШ ФШРЫХЪв аХУгЫпаЭле ТлаРЦХЭШЩ Ш ЮЯХаРвЮал Perl. ІЮЧЬЮЦЭЮ, бХЩзРб Тл згТбвТгХвХ бХСп Т ЭХЪЮвЮаЮЩ аРбвХапЭЭЮбвШ — ФЫп ЯаРЪвШзХбЪЮУЮ гбТЮХЭШп нвЮЩ ШЭдЮаЬРжШШ ЭХЮСеЮФШЬ ЭХЬРЫлЩ ЮЯлв ХХ ЯаРЪвШзХбЪЮУЮ ЯаШЬХЭХЭШп.
ґРТРЩвХ ТХаЭХЬбп Ъ ЧРФРзХ б РЭРЫШЧЮЬ ФРЭЭле, аРЧФХЫХЭЭле ЧРЯпвлЬШ. ЅШЦХ ЯаШТХФХЭЮ ЬЮХ аХиХЭШХ ФЫп Perl5, ЪЮвЮаЮХ, ЪРЪ ЭХвагФЭЮ ЧРЬХвШвм, ЭХбЪЮЫмЪЮ ЮвЫШзРХвбп Юв ЯХаТЮЭРзРЫмЭЮУЮ ТРаШРЭвР ЭР б. <$R[P#,R7-125]>:
@fields = ();
push(@fields, $+) while $text =~ m{
"([^"\\]*(?:\\.[^"\\]*)*)",? # БваЮЪР Т ЪРТлзЪРе (ТЮЧЬЮЦЭЮ, б ЧРЯпвЮЩ)
| ([^,]+),? # ІбХ ЮбвРЫмЭЮХ (ТЮЧЬЮЦЭЮ, б ЧРЯпвЮЩ)
| , # ѕвФХЫмЭРп ЧРЯпвРп
}gx;
# ґЮСРТШвм ЯЮбЫХФЭХХ ЯгбвЮХ ЯЮЫХ ЯХаХФ ЧРТХаиРойХЩ ЧРЯпвЮЩ
push(@fields, undef) if substr($text,-1,1) eq ',';
·ФХбм, ЪРЪ Ш Т ЯХаТЮЩ ТХабШШ, ЯХаХСЮа ЯЮЫХЩ аХРЫШЧгХвбп ЪЮЭбвагЪжШХЩ m/…/g Т бЪРЫпаЭЮЬ ЪЮЭвХЪбвХ б жШЪЫЮЬ while. јл еЮвШЬ ЮСХбЯХзШвм ЯЮЧШжШЮЭЭго бШЭеаЮЭШЧРжШо Ш ЯЮнвЮЬг гСХЦФРХЬбп Т вЮЬ, звЮ еЮвп Сл ЮФЭР ШЧ ваХе РЫмвХаЭРвШТ бЮТЯРФРХв б ЯЮЧШжШШ, Т ЪЮвЮаЮЩ ЬЮЦХв ЭРзШЭРвмбп бЮТЯРФХЭШХ. ІЮЧЬЮЦЭл ваШ вШЯР ЯЮЫХЩ, ЯЮнвЮЬг ЪЮЭбвагЪжШп ТлСЮаР ТЪЫозРХв ваШ РЫмвХаЭРвШТл.
їЮбЪЮЫмЪг Perl5 ЯЮЧТЮЫпХв вЮзЭЮ гЪРЧРвм, ЪРЪШХ бЪЮСЪШ пТЫповбп бЮеаРЭпойШЬШ, Р ЪРЪШХ — ЭХв, ЬЮЦЭЮ Слвм гТХаХЭЭлЬ Т вЮЬ, звЮ ЯЮбЫХ ЫоСЮУЮ бЮТЯРФХЭШп ЯХаХЬХЭЭРп $+ бЮФХаЦШв вХЪбв ЯЮЫп. ґЫп Ягбвле ЯЮЫХЩ бЮТЯРФРХв ваХвмп РЫмвХаЭРвШТР, Ш ШЧ-ЧР ЮвбгвбвТШп бЮеаРЭпойШе ЪагУЫле бЪЮСЮЪ ЯХаХЬХЭЭРп $+ ЧРТХФЮЬЮ ШЬХХв ЭХЮЯаХФХЫХЭЭЮХ ЧЭРзХЭШХ — нвЮ ЭРЬ Ш ЭгЦЭЮ (ЧЭРзХЭШХ undef ЮвЫШзРХвбп Юв ЯгбвЮЩ бваЮЪШ — ТЮЧТаРв аРЧЭле ЧЭРзХЭШЩ ФЫп ЯгбвЮУЮ ЯЮЫп Ш "" гзШвлТРХв нвЮ ЮСбвЮпвХЫмбвТЮ).
·РТХаиРойРп ЪЮЬРЭФР push ЯаХФЭРЧЭРзХЭР ФЫп бваЮЪ, ЧРТХаиРойШебп ЧРЯпвЮЩ (ЯаШЧЭРЪЮЬ ЧРТХаиРойХУЮ ЯгбвЮУЮ ЯЮЫп). ѕСаРвШвХ ТЭШЬРЭШХ: п ЭХ ШбЯЮЫмЧго m/,$/, ЪРЪ ЯаХЦФХ. АРЭмиХ нвЮ ФХЫРЫЮбм ФЫп ФХЬЮЭбваРжШШ аРСЮвл б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ, ЭЮ Т ФХЩбвТШвХЫмЭЮбвШ ЭХв ЭХЮСеЮФШЬЮбвШ ШбЯЮЫмЧЮТРвм аХУгЫпаЭлХ ТлаРЦХЭШп вРЬ, УФХ бгйХбвТгХв СЮЫХХ ЯаЮбвЮХ Ш СлбваЮХ аХиХЭШХ.
ЅРапФг б ЯаЮСЫХЬЮЩ РЭРЫШЧР ФРЭЭле, аРЧФХЫХЭЭле ЧРЯпвлЬШ, бгйХбвТгов Ш ФагУШХ бвРЭФРавЭлХ ЧРФРзШ, аРЧ ЧР аРЧЮЬ ТЮЧЭШЪРойШХ Т нЫХЪваЮЭЭле ЪЮЭдХаХЭжШпе Perl. І ЧРТХаиХЭШХ нвЮЩ УЫРТл Ьл аРббЬЮваШЬ ЭХЪЮвЮалХ ШЧ нвШе ЧРФРз.
БРЬЮХ ЫгзиХХ Ш ЭРФХЦЭЮХ аХиХЭШХ ЯаЮбвЮ Ш ЮзХТШФЭЮ:
s/^\s+//;
s/\s+$//;
їЮ ЪРЪШЬ-вЮ ЯаШзШЭРЬ ТбХУФР ЭРеЮФпвбп ЦХЫРойШХ бФХЫРвм ТбХ ЧР ЮФШЭ ЧРеЮФ, ЯЮнвЮЬг п ЯаХФЫРУРо ТРиХЬг ТЭШЬРЭШо ХйХ ЭХбЪЮЫмЪЮ бЯЮбЮСЮТ. П ЭХ аХЪЮЬХЭФго ЯЮЫмЧЮТРвмбп ШЬШ, ЮФЭРЪЮ аРЧЮСаРвмбп Т ЯаШЭжШЯРе Ше аРСЮвл Ш ЯЮЭпвм, ЯЮзХЬг Ше ЭХ бвЮШв ЯаШЬХЭпвм — ФХЫЮ ЯЮЫХЧЭЮХ Ш ЯЮгзШвХЫмЭЮХ.
l s/\s*(.*?)\s*$/$1/ — нвЮ ТлаРЦХЭШХ зРбвЮ ЯаШТЮФШвбп ЪРЪ ЧРЬХзРвХЫмЭлЩ ЯаШЬХа ЬШЭШЬРЫШЧЬР ЪТРЭвШдШЪРвЮаЮТ, ЯЮпТШТиХУЮбп Т Perl5. І ФХЩбвТШвХЫмЭЮбвШ ЯаШЬХа ЭХ вРЪ гЦ еЮаЮи, ЯЮбЪЮЫмЪг ЮЭ аРСЮвРХв УЮаРЧФЮ ЬХФЫХЭЭХХ СЮЫмиШЭбвТР ФагУШе аХиХЭШЩ (Т ЬЮШе вХбвРе — ЯаШЬХаЭЮ Т ваШ аРЧР). їаШзШЭР ЧРЪЫозРХвбп Т вЮЬ, звЮ ЯаХЦФХ зХЬ аРЧаХиШвм бЮТЯРФХЭШХ вЮзЪШ б ЪРЦФлЬ бШЬТЮЫЮЬ, ЪЮЭбвагЪжШп *? ФЮЫЦЭР ЯаЮТХаШвм, бЮТЯРФРов ЫШ ЯЮбЫХФгойШХ бШЬТЮЫл. НвЮ ЯаШТЮФШв Ъ ЬЭЮУЮзШбЫХЭЭлЬ ТЮЧТаРвРЬ Ш ЯЮбвЮпЭЭлЬ ТеЮФРЬ/ТлеЮФРЬ ШЧ ЪагУЫле бЪЮСЮЪ (б. <$R[P#,R5-21]>).
l s/^\s(.*\S)?\s*$/$1/ — УЮаРЧФЮ СЮЫХХ ЯапЬЮЫШЭХЩЭЮХ аХиХЭШХ. ЅРзРЫмЭРп ЪЮЭбвагЪжШп [.*] бЮТЯРФРХв ФЮ ЪЮЭжР бваЮЪШ, Р \S ЮСХбЯХзШТРХв ТЮЧТаРв ФЮ ЯЮЧШжШШ ЯЮбЫХ ЪЮЭХзЭЮУЮ ЯаЮЯгбЪР Т ЧРТХаиРойХЩ ЯЮбЫХФЮТРвХЫмЭЮбвШ ЭХ-ЯаЮЯгбЪЮТле бШЬТЮЫЮТ. µбЫШ бваЮЪР ЭХ бЮФХаЦШв ЭШзХУЮ, ЪаЮЬХ ЯаЮЯгбЪЮТ, [(.*\S)?] ЭХ бЮТЯРФРХв (звЮ ФЮЯгбвШЬЮ), Р ЧРТХаиРойРп ЪЮЭбвагЪжШп [\s*] аРбЯаЮбваРЭпХвбп ФЮ ЪЮЭжР бваЮЪШ.
l $_ = $1 if m/^\s*(.*\S)?/ — СЮЫХХ ШЫШ ЬХЭХХ ЯЮеЮЦХ ЭР ЯаХФлФгйХХ аХиХЭШХ. ЅР нвЮв аРЧ ТЬХбвЮ ЯЮФбвРЭЮТЪШ ШбЯЮЫмЧгХвбп ЯЮШбЪ Ш ЯаШбТРШТРЭШХ. І ЬЮШе вХбвРе нвЮв ТРаШРЭв аРСЮвРЫ ЭР 10 ЯаЮжХЭвЮТ СлбваХХ.
l s/^\s*|\s*$//g — нвЮ аХиХЭШХ ЯаХФЫРУРХвбп ЮзХЭм зРбвЮ. ЕЮвп ЮЭЮ аРСЮвРХв, ЯаШбгвбвТШХ ЪЮЭбвагЪжШШ ТлСЮаР ШбЪЫозРХв ЬЭЮУШХ ЮЯвШЬШЧРжШШ, ЪЮвЮалХ ЬЮУЫШ Сл ШбЯЮЫмЧЮТРвмбп Т ФРЭЭЮЬ бЫгзРХ. јЮФШдШЪРвЮа /g аРЧаХиРХв бЮТЯРФХЭШХ ФЫп ТбХе РЫмвХаЭРвШТ, ЭЮ ЯаШЬХЭХЭШХ /g аРбвЮзШвХЫмЭЮ, ЯЮбЪЮЫмЪг ЭРЬ ЭгЦЭл ЬРЪбШЬгЬ ФТР бЮТЯРФХЭШп, ЯаШвЮЬ ФЫп аРЧЭле ЯЮФТлаРЦХЭШЩ. їЮЫгзРХвбп ЭХнддХЪвШТЭЮ.
БЪЮаЮбвм зРбвЮ ЧРТШбШв Юв еРаРЪвХаР ФРЭЭле. ЅРЯаШЬХа, Т аХФЪШе бЫгзРпе, ЪЮУФР бваЮЪР ШЬХХв ЮзХЭм СЮЫмиго ФЫШЭг б ЮвЭЮбШвХЫмЭЮ ЬРЫлЬ ЪЮЫШзХбвТЮЬ ЯаЮЯгбЪЮТ ЭР ЮСЮШе ЪЮЭжРе, ЮСаРСЮвЪР s/^\s+//; s/\s+$// ЬЮЦХв ЧРЭпвм ТФТЮХ СЮЫмиХ ТаХЬХЭШ, зХЬ ФЫп $_ = $1 if m/^\s*(.*\S)?/. ё ТбХ ЦХ Т бТЮШе ЯаЮУаРЬЬРе п ШбЯЮЫмЧго вЮЫмЪЮ s/^\s+//; s/\s+$//, ЯЮбЪЮЫмЪг нвЮ аХиХЭШХ ЯЮзвШ ТбХУФР пТЫпХвбп бРЬлЬ СлбвалЬ, Ш гЦ ЪЮЭХзЭЮ — бРЬлЬ ЯаЮбвлЬ ФЫп ЯЮЭШЬРЭШп.
<$M[R7-59]>ЗРбвЮ ТЮЧЭШЪРХв ТЮЯаЮб, ЪРЪ ТлТЮФШвм зШбЫР б ЧРЯпвлЬШ — ЭРЯаШЬХа, 12,345,678. І ЭРбвЮпйХХ ТаХЬп FAQ ЯаХФЫРУРХв бЫХФгойХХ аХиХЭШХ:
1 while s/^(-?\d+)(\d{3})/$1,$2/;
єЮЬРЭФР Т жШЪЫХ бЪРЭШагХв зШбЫЮ ФЮ ЯЮбЫХФЭХЩ жШдал (вЮ Хбвм бШЬТЮЫР, ЮвЫШзЭЮУЮ Юв ЧРЯпвЮЩ) ЯаШ ЯЮЬЮйШ [\d+], ТЮЧТаРйРХвбп ЭР ваШ жШдал, звЮСл бЮТЯРФРЫЮ ЯЮФТлаРЦХЭШХ [\d{3}], Ш ТбвРТЫпХв ЧРЯпвго ЯаШ ЯЮЬЮйШ ЯЮФТлаРЦХЭШп [$1,$2]. їЮбЪЮЫмЪг ЮСаРСЮвЪР зШбЫР ЯаЮШбеЮФШв «бЯаРТР ЭРЫХТЮ» ТЬХбвЮ ЮСлзЭЮУЮ ЭРЯаРТЫХЭШп «бЫХТР ЭРЯаРТЮ», ЬЮФШдШЪРвЮа /g Т ФРЭЭЮЬ бЫгзРХ СХбЯЮЫХЧХЭ. ВРЪШЬ ЮСаРЧЮЬ, ЬЭЮУЮЪаРвЭЮХ ТЪЫозХЭШХ ЧРЯпвле ЮСХбЯХзШТРХвбп ЯаШ ЯЮЬЮйШ жШЪЫР while.
НвЮ аХиХЭШХ ЬЮЦЭЮ гбЮТХаиХЭбвТЮТРвм, ТЮбЯЮЫмЧЮТРТиШбм бвРЭФРавЭЮЩ ЮЯвШЬШЧРжШХЩ ШЧ УЫРТл 5 (б. <$R[P#,R5-26]>), Ш ЧРЬХЭШвм [\d{3}] ЯЮбЫХФЮТРвХЫмЭЮбвмо [\d\d\d]. ·РзХЬ ЧРбвРТЫпвм ЬХеРЭШЧЬ аХУгЫпаЭле ТлаРЦХЭШЩ ЯЮФбзШвлТРвм нЪЧХЬЯЫпал, ЪЮУФР б вРЪШЬ ЦХ гбЯХеЮЬ ЬЮЦЭЮ ЯаЮбвЮ бЪРЧРвм, звЮ ТРЬ ЭгЦЭЮ? І ЬЮШе вХбвРе нвЮ ЯаЮбвЮХ ШЧЬХЭХЭШХ ЮСХбЯХзШЫЮ УаЮЬРФЭго нЪЮЭЮЬШо Т жХЫле ваШ ЯаЮжХЭвР! (° ТЯаЮзХЬ, ЪгаЮзЪР ЯЮ ЧХаЭлиЪг ЪЫоХв…)
ґагУЮХ гбЮТХаиХЭбвТЮТРЭШХ — гФРЫХЭШХ пЪЮап ЭРзРЫР бваЮЪШ. НвЮ ЯЮЧТЮЫШв ТРЬ ТЪЫозРвм ЧРЯпвлХ Т зШбЫЮ (ШЫШ зШбЫР), аРбЯЮЫЮЦХЭЭлХ УФХ-вЮ ТЭгваШ бваЮЪШ. ·РЮФЭЮ ЬЮЦЭЮ бЬХЫЮ гФРЫШвм [-?], ЯЮбЪЮЫмЪг ЮЭР ЭгЦЭР ЫШим ФЫп ЯаШТпЧЪШ ЯХаТЮЩ жШдал Ъ пЪЮао. µбЫШ Тл ЭХ ЧЭРХвХ ЯаШаЮФл жХЫХТле ФРЭЭле, ЯЮФЮСЭлХ ШЧЬХЭХЭШп СлТРов аШбЪЮТРЭЭлЬШ, ЯЮбЪЮЫмЪг 3.14159265 ЬЮЦХв ЯаХТаРвШвмбп Т 3.14,159,265. ВРЪ ШЫШ ШЭРзХ, ХбЫШ Тбп бваЮЪР бЮФХаЦШв вЮЫмЪЮ ЮФЭЮ зШбЫЮ, ЫгзиХ ШбЯЮЫмЧЮТРвм ТХабШо б пЪЮаХЬ.
І РСбЮЫовЭЮ ЭХЯЮеЮЦХЬ, ЭЮ ЯаРЪвШзХбЪШ нЪТШТРЫХЭвЭЮЬ аХиХЭШШ ШбЯЮЫмЧгХвбп ЮФЭР ЯЮФбвРЭЮТЪР б ЬЮФШдШЪРвЮаЮЬ /g:
s<
(\d{1,3}) # ґЮ ЧРЯпвЮЩ: Юв ЮФЭЮЩ ФЮ ваХе жШда
(?= # ·РвХЬ бЫХФгов (ЭХ ТЪЫозРХЬлХ Т бЮТЯРФХЭШХ!)
(?:\d\d\d)+ # ...ЭХбЪЮЫмЪЮ ваШЯЫХвЮТ...
(?!\d) # ...ЧР ЪЮвЮалЬШ бЫХФгХв ЭХ жШдаР...
) # (ЭР нвЮЬ зШбЫЮ ЧРЪРЭзШТРХвбп)
><$1,>gx;
ёЧ-ЧР ЪЮЬЬХЭвРаШХТ Ш дЮаЬРвШаЮТРЭШп ЬЮЦХв ЯЮЪРЧРвмбп, звЮ нвЮ аХиХЭШХ бЫЮЦЭХХ ЯаШТХФХЭЭЮУЮ Т FAQ, ЭЮ ЭР бРЬЮЬ ФХЫХ ТбХ ЭХ вРЪ ЯЫЮеЮ — ЮЭЮ аРСЮвРХв ЯаШЬХаЭЮ ЭР ваХвм СлбваХХ. ВХЬ ЭХ ЬХЭХХ, ЯЮбЪЮЫмЪг нвЮ ТлаРЦХЭШХ ЭХ ЯаШТпЧРЭЮ Ъ ЭРзРЫг бваЮЪШ, ТЮЧЭШЪРов вХ ЦХ ЯаЮСЫХЬл, ЪРЪ ФЫп 3.1415926. ЗвЮСл нвР ЪЮЬРЭФР аРСЮвРЫР вРЪ ЦХ, ЪРЪ Ш аХиХЭШХ Т FAQ ФЫп ТбХе бваЮЪ, ЧРЬХЭШвХ [(\d{1,3})] ЭР [\G((?:^-)?\d{1,3})]. \G ЯаШТпЧлТРХв ТбХ бЮТЯРФХЭШХ Ъ ЭРзРЫг бваЮЪШ, Р ЪРЦФЮХ ЯЮбЫХФгойХХ бЮТЯРФХЭШХ, ЮСгбЫЮТЫХЭЭЮХ ЬЮФШдШЪРвЮаЮЬ /g — Ъ ЯаХФлФгйХЬг бЮТЯРФХЭШо. [(?:^-)?] аРЧаХиРХв ЭРЫШзШХ ЬШЭгбР Т ЭРзРЫХ бваЮЪШ, ЪРЪ Т аХиХЭШШ FAQ. НвШ ШЧЬХЭХЭШп згвм ЧРЬХФЫпов аРСЮвг ЯаШТХФХЭЭЮУЮ аХиХЭШп, ЭЮ ЮЭЮ ТбХ аРТЭЮ аРСЮвРХв ЭР 30 ЯаЮжХЭвЮТ СлбваХХ аХиХЭШп, ЯаШТХФХЭЭЮУЮ Т FAQ.
ёЭвХаХбЭЮ ЯЮбЬЮваХвм, ЪРЪ аХиРХвбп ЧРФРзР гФРЫХЭШп ЪЮЬЬХЭвРаШХТ C ШЧ вХЪбвР. І УЫРТХ 5 Ьл ЯЮваРвШЫШ ФЮТЮЫмЭЮ ЬЭЮУЮ ТаХЬХЭШ ЭР ЯЮбваЮХЭШХ ЮСЮСйХЭЭЮУЮ ТлаРЦХЭШп ФЫп ЯЮШбЪР ЪЮЬЬХЭвРаШХТ [/\*[^*]*\*+([^/*][^*]*\*+)*/], Ш ЭР ЭРЯШбРЭШХ ЯаЮУаРЬЬл Tcl ФЫп гФРЫХЭШп ЪЮЬЬХЭвРаШХТ. ґРТРЩвХ бФХЫРХЬ вЮ ЦХ<$M[R7-7]> бРЬЮХ Т Perl.
І УЫРТХ 5 аРббЬРваШТРЫШбм ваРФШжШЮЭЭлХ ЬХеРЭШЧЬл Ѕє°, ЯЮнвЮЬг аХУгЫпаЭЮХ ТлаРЦХЭШХ СгФХв аРСЮвРвм Ш Т Perl. ґЫп ЯЮТлиХЭШп нддХЪвШТЭЮбвШ п ТЮбЯЮЫмЧгобм ЭХ-бЮеаРЭпойШЬШ ЪагУЫлЬШ бЪЮСЪРЬШ, ЭЮ нвЮ ЯаРЪвШзХбЪШ ХФШЭбвТХЭЭЮХ ЭХЯЮбаХФбвТХЭЭЮХ ШЧЬХЭХЭШХ. ІЯаЮзХЬ, СЮЫХХ ЯаЮбвЮХ ТлаРЦХЭШХ [/\*.*?\*] ШЧ FAQ ЭХ ТбХУФР ЭХЦХЫРвХЫмЭЮ — аХиХЭШХ ШЧ УЫРТл 5 ЧРЬХвЭЮ ЯЮТлиРХв нддХЪвШТЭЮбвм ЯЮШбЪР, ЭЮ ФЫп вХе ЯаШЫЮЦХЭШЩ, Т ЪЮвЮале ТаХЬп ЭХ ЪаШвШзЭЮ, [/\*.*?\*] ТЯЮЫЭХ ЯЮФеЮФШв. єЮЭХзЭЮ, нвЮ ТлаРЦХЭШХ ТлУЫпФШв УЮаРЧФЮ ЯЮЭпвЭХХ, ЯЮнвЮЬг п ТЮбЯЮЫмЧгобм ШЬ ФЫп гЯаЮйХЭШп ЯХаТЮЩ, зХаЭЮТЮЩ ТХабШШ ТлаРЦХЭШп, ЯаХФЭРЧЭРзХЭЭЮУЮ ФЫп гФРЫХЭШп ЪЮЬЬХЭвРаШХТ.
ёвРЪ, ТХаЭХЬбп Ъ ЭРиХЬг ТлаРЦХЭШо:
s{
# БЭРзРЫР ЯХаХзШбЫпХвбп вЮ, звЮ бЮТЯРФРХв, ЭЮ ЭХ гФРЫпХвбп
(
" (\\.|[^"\\])* " # БваЮЪР Т ЪРТлзЪРе
| # - ШЫШ -
' (\\.|[^'\\])* ' # бваЮЪР Т РЯЮбваЮдРе
)
| # ё»ё...
# ...ЪЮЬЬХЭвРаШЩ. їЮбЪЮЫмЪг ЮЭ ЭХ бЮТЯРЫ
# б ЪагУЫлЬШ бЪЮСЪРЬШ $1 (бЬ. ТлиХ), ЪЮЬЬХЭвРаШШ
# ШбзХЧЭгв, ЪЮУФР Ьл ШбЯЮЫмЧгХЬ $1 Т ЪРзХбвТХ вХЪбвР ЧРЬХЭл.
/\* .*? \*/ # ВаРФШжШЮЭЭлЩ ЪЮЬЬХЭвРаШЩ C
| # -ШЫШ-
//[^\n]* # єЮЬЬХЭвРаШШ C++ ( // )
}{$1}gsx;
їЮбЫХ ЯаШЬХЭХЭШп ЬЮФШдШЪРжШЩ, ЮЯШбРЭЭле ФЫп аХиХЭШп ЭР Tcl, Ш ЮСкХФШЭХЭШп ФТге аХУгЫпаЭле ТлаРЦХЭШЩ ФЫп ЪЮЬЬХЭвРаШХТ Т ЮФЭг РЫмвХаЭРвШТг ТХаеЭХУЮ гаЮТЭп (нвЮ ЫХУЪЮ, ЯЮбЪЮЫмЪг Ьл ЯШиХЬ аХУгЫпаЭЮХ ТлаРЦХЭШХ баРЧг, Р ЭХ бваЮШЬ ХУЮ ШЧ ЮвФХЫмЭле ЪЮЬЯЮЭХЭвЮТ $COMMENT Ш $COMMENT1), ЭРиР Perl-ТХабШп ЯаШЭШЬРХв бЫХФгойШЩ ТШФ:
s{
# БЭРзРЫР ЯХаХзШбЫпХвбп вЮ, звЮ бЮТЯРФРХв, ЭЮ ЭХ гФРЫпХвбп
(
[^"'/]+ # ІбХ ЮбвРЫмЭЮХ
| # - ШЫШ -
(?:"[^"\\]*(?:\\.[^"\\]*)*" [^"'/]*)+ # бваЮЪР Т ЪРТлзЪРе
| # - ШЫШ -
(?:'[^"\\]*(?:\\.[^'\\]*)*' [^"'/]*)+ # бваЮЪР Т РЯЮбваЮдРе
)
| # ё»ё...
# ...ЪЮЬЬХЭвРаШЩ. їЮбЪЮЫмЪг ЮЭ ЭХ бЮТЯРЫ
# б ЪагУЫлЬШ бЪЮСЪРЬШ $1 (бЬ. ТлиХ), ЪЮЬЬХЭвРаШШ
# ШбзХЧЭгв, ЪЮУФР Ьл ШбЯЮЫмЧгХЬ $1 Т ЪРзХбвТХ вХЪбвР ЧРЬХЭл.
/ (?: # »оСЮЩ ЪЮЬЬХЭвРаШЩ ЭРзШЭРХвбп б ЪЮбЮЩ зХавл
\*[^*]*\*+(?:[^/*][^*]*\*+)*/ # ВаРФШжШЮЭЭлЩ ЪЮЬЬХЭвРаШЩ C
| # -ШЫШ-
/[^\n]* # єЮЬЬХЭвРаШШ C++ ( // )
)
}{$1}gsx;
ВХбв, РЭРЫЮУШзЭлЩ ЯаШТХФХЭЭЮЬг Т УЫРТХ 5 ФЫп Tcl-ТХабШШ, аРСЮвРХв ЮЪЮЫЮ 1,45 бХЪгЭФл. ґЫп баРТЭХЭШп: ЮбЭЮТЭРп Tcl-ТХабШп аРСЮвРЫР 2,3 бХЪгЭФл, ЯХаТРп Perl-ТХабШп — ЮЪЮЫЮ 12 бХЪгЭФ, Р ЯХаТРп Tcl-ТХабШп — ЮЪЮЫЮ 36 бХЪгЭФ.
ЗвЮСл ЯаХТаРвШвм нвг ЪЮЬРЭФг Т ЯЮЫЭЮжХЭЭго ЯаЮУаРЬЬг, ФЮбвРвЮзЭЮ ТбвРТШвм ХХ Т бЫХФгойго ЪЮЭбвагЪжШо:
undef $/; # АХЦШЬ ЯЮУЫЮйХЭШп ТбХУЮ дРЩЫР
$_ = join ('', <>); # ДгЭЪжШп join(…) аРСЮвРХв б ЭХбЪЮЫмЪШЬШ дРЩЫРЬШ
# ...ІбвРТШвм ЪЮЬРЭФг ЧРЬХЭл, ЯаШТХФХЭЭго ТлиХ...
print;
ґР, ЯХаХФ ТРЬШ Тбп ЯаЮУаРЬЬР.
<$M[R7-15]>П еЮзг ЧРТХаиШвм нвг ЪЭШУг СЮЫмиШЬ ЯаШЬХаЮЬ, Т ЪЮвЮаЮЬ ЧРФХЩбвТЮТРЭл ЬЭЮУШХ ЯаШХЬл аРСЮвл б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ, ТбваХзРТиШХбп Т ЭХбЪЮЫмЪШе ЯЮбЫХФЭШе УЫРТРе, Р вРЪЦХ апФ ШбЪЫозШвХЫмЭЮ ЯЮЫХЧЭле ЭРТлЪЮТ ЯЮбваЮХЭШп аХУгЫпаЭле ТлаРЦХЭШЩ ШЧ ЯХаХЬХЭЭле. їаЮТХаЪР ЯаРТШЫмЭЮбвШ бШЭвРЪбШбР РФаХбЮТ нЫХЪваЮЭЭЮЩ ЯЮзвл ёЭвХаЭХвР — ЧРФРзР ТХбмЬР аРбЯаЮбваРЭХЭЭРп, ЭЮ Ъ бЮЦРЫХЭШо, ШЧ-ЧР бЫЮЦЭЮбвШ бвРЭФРавР[55] ЭРЩвШ ЯаЮбвЮХ аХиХЭШХ ЮзХЭм вагФЭЮ. І бгйЭЮбвШ, б ЯЮЬЮймо аХУгЫпаЭЮУЮ ТлаРЦХЭШп нвЮ бФХЫРвм ЭХТЮЧЬЮЦЭЮ, ЯЮбЪЮЫмЪг ЪЮЬЬХЭвРаШШ ЬЮУгв Слвм ТЫЮЦХЭЭлЬШ (ФР, РФаХбР нЫХЪваЮЭЭЮЩ ЯЮзвл ЬЮУгв бЮФХаЦРвм ЪЮЬЬХЭвРаШШ — бШЬТЮЫл, ЧРЪЫозХЭЭлХ Т ЪагУЫлХ бЪЮСЪШ). µбЫШ Тл бЮУЫРбЭл ЭР ЪЮЬЯаЮЬШбб (ЭРЯаШЬХа. аРЧаХиШвм вЮЫмЪЮ ЮФШЭ гаЮТХЭм ЪЮЬЬХЭвРаШХТ — ТЮ ТбХе РФаХбРе, ЪЮвЮалХ п ТШФХЫ, нвЮУЮ СлЫЮ ТЯЮЫЭХ ФЮбвРвЮзЭЮ) — ФРТРЩвХ ЯЮЯаЮСгХЬ.
ё ТбХ ЦХ ЧРФРзР ЭХ ФЫп бЫРСЮЭХаТЭле. АХУгЫпаЭЮХ ТлаРЦХЭШХ, ЪЮвЮаЮХ г ЭРб ЯЮЫгзШвбп, СгФХв бЮбвЮпвм ШЧ 4724 СРЩв! ЅР ЯХаТлЩ ТЧУЫпФ ЪРЦХвбп, звЮ ЧРФРзР аХиРХвбп ЯаЮбвлЬ ТлаРЦХЭШХЬ вШЯР [\w+\@[.\w]+], ЭЮ ЭР бРЬЮЬ ФХЫХ бШвгРжШп УЮаРЧФЮ СЮЫХХ бЫЮЦЭРп. ЅРЯаШЬХа бЫХФгойРп бваЮЪР РСбЮЫовЭЮ ФЮЯгбвШЬР б вЮзЪШ ЧаХЭШп бЯХжШдШЪРжШШ[56]:
Jeffy <"That Tall Guy"@ora.com (this address no longer active)>
ёвРЪ, звЮ ЦХ бЫХФгХв бзШвРвм ЫХЪбШзХбЪШ ЯаРТШЫмЭлЬ РФаХбЮЬ? І вРСЫ. 7.11 ЯаШТХФХЭР ЫХЪбШзХбЪРп бЯХжШдШЪРжШп РФаХбР нЫХЪваЮЭЭЮЩ ЯЮзвл ёЭвХаЭХвР Т бЬХиРЭЭЮЩ ЧРЯШбШ, Т ЪЮвЮаЮЩ ЬЮЦЭЮ аРЧЮСаРвмбп СХЧ ЮбЮСЮУЮ вагФР. єаЮЬХ вЮУЮ, СЮЫмиШЭбвТЮ нЫХЬХЭвЮТ ЬЮЦХв аРЧФХЫпвмбп ЪЮЬЬХЭвРаШпЬШ (нЫХЬХЭв 22) Ш ЯаЮЯгбЪРЬШ (ЯаЮСХЫл ШЫШ вРСгЫпжШШ). ЅРиР ЧРФРзР — ЯЮ ТЮЧЬЮЦЭЮбвШ ЯаХЮСаРЧЮТРвм нвг бЯХжШдШЪРжШо Т аХУгЫпаЭЮХ ТлаРЦХЭШХ. ґЫп нвЮУЮ ЯЮваХСгХвбп ТбЯЮЬЭШвм ТбХ, зХЬг Тл ЭРгзШЫШбм, Ш ТбХ ЦХ нвЮ ТЮЧЬЮЦЭЮ[57].
ВРСЫШжР 7.11. БЫХУЪР дЮаЬРЫШЧЮТРЭЭЮХ ЮЯШбРЭШХ РФаХбР нЫХЪваЮЭЭЮЩ ЯЮзвл
|
|
НЫХЬХЭв |
ѕЯШбРЭШХ |
|
1 |
mailbox |
addr-spec | phrase route-addr |
|
2 |
addr-spec |
local-part@domain |
|
3 |
phrase |
(word)+ |
|
4 |
route-addr |
<( route )?addr-spec> |
|
5 |
local-part |
word(.word)* |
|
6 |
domain |
sub-domain(.sub-domain)* |
|
7 |
word |
atom|quoted-string |
|
8 |
route |
@domain(,@domain) |
|
9 |
sub-domain |
domain-ref | domain-literal |
|
10 |
atom |
(ЫоСЮЩ char, ЪаЮЬХ specials, space Ш ctls)+ |
|
11 |
quoted-string |
"(qtext | quoted-pair)*" |
|
12 |
domain-ref |
atom |
|
13 |
domain-literal |
[(dtext | quoted-pair)*] |
|
14 |
char |
ЫоСЮЩ ASCII-бШЬТЮЫ (000-177 ТЮбмЬ.) |
|
15 |
ctl |
ЫоСЮЩ гЯаРТЫпойШЩ ASCII-бШЬТЮЫ (000-037 ТЮбмЬ.) |
|
16 |
space |
ASCII-бШЬТЮЫ «ЯаЮСХЫ» (040 ТЮбмЬ.) |
|
17 |
CR |
ASCII-бШЬТЮЫ «ТЮЧТаРв ЪгабЮаР» (015 ТЮбмЬ.) |
|
18 |
specials |
ЫоСЮЩ ШЧ бШЬТЮЫЮТ: ()<>@,;:\".[] |
|
19 |
qtext |
ЫоСЮЩ бШЬТЮЫ, ЪаЮЬХ ", \ Ш CR |
|
20 |
dtext |
ЫоСЮЩ бШЬТЮЫ, ЪаЮЬХ [, ], \ Ш CR |
|
21 |
quoted-pair |
\char |
|
22 |
comment |
((ctext | quoted-pair | comment)*) |
|
23 |
ctext |
ЫоСЮЩ бШЬТЮЫ, ЪаЮЬХ (, ), \ Ш CR |
БваЮп аХУгЫпаЭЮХ ТлаРЦХЭШп ШЧ ЯХаХЬХЭЭле, ЭХЮСеЮФШЬЮ ЮбЮСХЭЭЮ ТЭШЬРвХЫмЭЮ аРЧЮСаРвмбп Т ЯаЮШбеЮФпйХЩ ЮСаРСЮвЪХ бваЮЪ Т ЪРТлзЪРе Ш РЯЮбваЮдРе, ШЭвХаЯЮЫпжШШ Ш нЪаРЭШаЮТРЭШШ. ЅРЯаШЬХа, ТлаРЦХЭШХ [^\w+\@[.\w]+$] ЬЮЦЭЮ ЭРШТЭЮ ТЮбЯаЮШЧТХбвШ Т ТШФХ
$username = "\w+";
$hostname = "\w+(\.\w+)+";
$email = "^$username\@$hostname$";
...
... m/$email/o ...
ЅЮ ТбХ ЭХ вРЪ ЯаЮбвЮ. їаШ ТлзШбЫХЭШШ бваЮЪ Т ЪРТлзЪРе Т ЯаЮжХббХ ЯаШбТРШТРЭШп ЯХаХЬХЭЭлЬ бШЬТЮЫл \ ШЭвХаЯЮЫШаговбп Ш гФРЫповбп: Т Perl4 ШвЮУЮТРп ЯХаХЬХЭЭРп $email СгФХв бЮФХаЦРвм ^w+@w+(.w+)+$, Р Т Perl5 нвЮв даРУЬХЭв ТЮЮСйХ ЭХ ЪЮЬЯШЫШагХвбп ШЧ-ЧР ЧРТХаиРойХУЮ бШЬТЮЫР $. їаШеЮФШвбп ЫШСЮ нЪаРЭШаЮТРвм бШЬТЮЫл \, звЮСл бЮеаРЭШвм Ше Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ, ЫШСЮ ШбЯЮЫмЧЮТРвм бваЮЪШ Т РЯЮбваЮдРе. БваЮЪШ Т РЯЮбваЮдРе ЭХ ЬЮУгв ШбЯЮЫмЧЮТРвмбп Т ЭХЪЮвЮале бШвгРжШпе — ЭРЯаШЬХа, Т ваХвмХЩ бваЮЪХ ЯаШТХФХЭЭЮУЮ ТлиХ даРУЬХЭвР ФХЩбвТШвХЫмЭЮ ЭХЮСеЮФШЬР ШЭвХаЯЮЫпжШп ЯХаХЬХЭЭле, ЮСХбЯХзШТРХЬРп бваЮЪРЬШ Т ЪРТлзЪРе:
$username = '\w+';
$hostname = '\w+(\.\w+)+';
$email = '^$username\@$hostname\$';
ЅРзШЭРп ЯЮбваЮХЭШХ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, ФРТРЩвХ ЯЮТЭШЬРвХЫмЭХХ ЯаШбЬЮваШЬбп Ъ нЫХЬХЭвг 16 Т вРСЫ. 7.11. їаЮбвХЩиРп ЪЮЬРЭФР $space = "spc" ЭХ ЯЮФеЮФШв, ЯЮвЮЬг звЮ ЯаШ ШбЯЮЫмЧЮТРЭШШ ЬЮФШдШЪРвЮаР /x ЯаШ ШбЯЮЫмЧЮТРЭШШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп (Р нвЮ СгФХв ЯаЮШбеЮФШвм!) ЯаЮСХЫл ЧР ЯаХФХЫРЬШ бШЬТЮЫмЭле ЪЫРббЮТ, ЪРЪ Т нвЮЬ бЫгзРХ, ШбзХЧРов. їаЮСХЫ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ ЬЮЦЭЮ ЯаХФбвРТШвм Т ТШФХ [\040] (40 — ТЮбмЬХаШзЭлЩ ЪЮФ ЯаЮСХЫР Т ЪЮФШаЮТЪХ ASCII), ЯЮнвЮЬг ТЮЧЭШЪРХв ШбЪгиХЭШХ ЯаШбТЮШвм "\040" ЯХаХЬХЭЭЮЩ $space. НвЮ СлЫЮ Сл ЮиШСЪЮЩ, ЯЮбЪЮЫмЪг ЯаШ ТлзШбЫХЭШШ бваЮЪШ Т РЯЮбваЮдРе \040 ЯаХТаРйРХвбп Т ЯаЮСХЫ. АХУгЫпаЭЮХ ТлаРЦХЭШХ гТШФШв нвЮв ЯаЮСХЫ, вРЪ звЮ Ьл ТЮЧТаРйРХЬбп ЭР бвРаЮХ ЬХбвЮ. јл еЮвШЬ, звЮСл аХУгЫпаЭЮХ ТлаРЦХЭШХ ТШФХЫЮ ЪЮФ \040 Ш бРЬЮ ЯаХТаРйРЫЮ ХУЮ Т ЯаЮСХЫ; бЫХФЮТРвХЫмЭЮ, ЭХЮСеЮФШЬЮ ШбЯЮЫмЧЮТРвм "\\040" ШЫШ '\040'.
БЮТЯРФХЭШХ ФЫп ЫШвХаРЫР \ — ЧРФРзР ЮбЮСХЭЭЮ ЭХЯаЮбвРп, ЯЮвЮЬг звЮ нвЮв бШЬТЮЫ вРЪЦХ пТЫпХвбп ЬХвРбШЬТЮЫЮЬ аХУгЫпаЭЮУЮ ТлаРЦХЭШп. ґЫп бЮТЯРФХЭШп б ЮФЭШЬ ЫШвХаРЫЮЬ \ Т аХУгЫпаЭЮХ ТлаРЦХЭШХ ЭХЮСеЮФШЬЮ ТЪЫозШвм [\\]. ЗвЮСл ЯаШбТЮШвм ХУЮ, бЪРЦХЬ, ЯХаХЬХЭЭЮЩ $esc, ЭРЬ еЮвХЫЮбм Сл ШбЯЮЫмЧЮТРвм '\\', ЭЮ ЯЮбЪЮЫмЪг ЪЮЬСШЭРжШп \\ ЮбЮСлЬ ЮСаРЧЮЬ ШЭвХаЯаХвШагХвбп ФРЦХ Т бваЮЪРе, ЧРЪЫозХЭЭле Т РЯЮбваЮдл[58], ЭРЬ ЯаШеЮФШвбп ШбЯЮЫмЧЮТРвм ЪЮЬРЭФг ТШФР $esc = '\\\\' — вЮЫмЪЮ ФЫп вЮУЮ, звЮСл ЮЪЮЭзРвХЫмЭЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ бЮТЯРЫЮ б ЮФЭШЬ бШЬТЮЫЮЬ \. ёЬХЭЭЮ ЯЮ нвЮЩ ЯаШзШЭХ п бЮЧФРо ЯХаХЬХЭЭго $esc ЮФШЭ аРЧ Ш ЧРвХЬ ШбЯЮЫмЧго ХХ ТбоФг, УФХ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ ЯЮваХСгХвбп ЫШвХаРЫ \. НвР ЯХаХЬХЭЭРп СгФХв ЭХЮФЭЮЪаРвЭЮ ШбЯЮЫмЧЮТРЭР ЯаШ ЯЮбваЮХЭШШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп ФЫп РФаХбР. ЅШЦХ ЯаШТХФХЭл ЭХЪЮвЮалХ ТбЯЮЬЮУРвХЫмЭлХ ЯХаХЬХЭЭлХ, ЪЮвЮалХ СгФгв ШбЯЮЫмЧЮТРвмбп РЭРЫЮУШзЭлЬ ЮСаРЧЮЬ:
# ІбЯЮЬЮУРвХЫмЭлХ ЯХаХЬХЭЭлХ, ЯЮЧТЮЫпойШХ ШЧСРТШвмбп Юв ЫШиЭШе бШЬТЮЫЮТ \.
$esc = '\\\\'; $Period = '\.';
$space = '\040'; $tab = '\t';
$OpenBR = '\['; $CloseBR = '\]';
$OpenParen = '\('; $CloseParen = '\)';
$NonASCII = '\x80-\xff'; $ctrl = '\000-\037';
$Crlist = '\n\015'; # їаШЬХзРЭШХ: ФЮЫЦЭЮ Слвм \015
їХаХЬХЭЭРп $CRList ЧРбЫгЦШТРХв ЮвФХЫмЭЮУЮ гЯЮЬШЭРЭШп. І бЯХжШдШЪРжШШ гЯЮЬШЭРХвбп вЮЫмЪЮ ASCII-бШЬТЮЫ ТЮЧТаРвР ЪгабЮаР (015 ТЮбмЬ.). Б ЯаРЪвШзХбЪЮЩ вЮзЪШ ЧаХЭШп нвЮ аХУгЫпаЭЮХ ТлаРЦХЭШХ, бЪЮаХХ ТбХУЮ, СгФХв ЯаШЬХЭпвмбп Ъ вХЪбвг, гЦХ ЯаХЮСаРЧЮТРЭЭЮЬг Ъ бШбвХЬЭЮЩ ЪЮЬСШЭРжШШ ФЫп ЭЮТЮЩ бваЮЪШ. НвЮв дЮаЬРв ЬЮЦХв бЮТЯРФРвм б ASCII-бШЬТЮЫЮЬ ТЮЧТаРвР ЪгабЮаР ШЫШ ЮвЫШзРвмбп Юв ЭХУЮ (ЪРЪ, ЭРЯаШЬХа, Т MacOS, ЭЮ ЭХ Т Unix; бЬ. б. <$R[P#,R3-28]>). ёбеЮФп ШЧ нвЮУЮ, п аХиШЫ гзХбвм ЮСР бЫгзРп.
І бЫХФгойХЬ даРУЬХЭвХ ЯаШТХФХЭл ТбЯЮЬЮУРвХЫмЭлХ бШЬТЮЫмЭлХ ЪЫРббл, ЯаХФбвРТЫпойШХ нЫХЬХЭвл 19, 20, 23 Ш ЭРзРЫЮ нЫХЬХЭвР 10:
# НЫХЬХЭвл 19, 20, 21
$qtext = qq/[^$esc$NonASCII$CRlist\"]/; # ТЭгваШ "..."
$dtext = qq/[^$esc$NonASCII$CRlist$OpenBR$CloseBR]/; # ТЭгваШ [...]
$quoted_pair = qq< $esc [^$NonASCII] >; # нЪаРЭШаЮТРЭЭлЩ бШЬТЮЫ
# НЫХЬХЭв 10: atom
$atom_char = qq/[^($space)<>\@,;:\".$esc$OpenBR$CloseBR$ctrl$NonASCII]/;
$atom = qq<
$atom_char+ # ЅХЪЮвЮаЮХ ЪЮЫШзХбвТЮ бШЬТЮЫЮТ РвЮЬР...
(?!$atom_char) # ..ЧР ЪЮвЮалЬШ ЭХ бЫХФгХв ЭХзвЮ,
# ЭХ пТЫпойХХбп зРбвмо РвЮЬР
>;
їЮбЫХФЭШЩ нЫХЬХЭв, $atom, ваХСгХв ЭХЪЮвЮале аРЧкпбЭХЭШЩ. БРЬР ЯЮ бХСХ ЯХаХЬХЭЭРп $atom ЯаХФбвРТЫпХв бЮСЮЩ ТбХУЮ ЫШим $atom_char+ — ЭЮ ТЧУЫпЭШвХ ЭР нЫХЬХЭв 3 вРСЫШжл 7.11, phrase. єЮЬСШЭРжШп ЮСаРЧгХв ТлаРЦХЭШХ [($atom_char+)+] — ЯаХЪаРбЭлЩ ЯаШЬХа «СХбЪЮЭХзЭЮУЮ» ЯЮШбЪР (б. <$R[P#,R5-27]>). їаШ ЯЮбваЮХЭШШ аХУгЫпаЭле ТлаРЦХЭШЩ ШЧ ЯХаХЬХЭЭле зРбвЮ ТЮЧЭШЪРов ЯЮФЮСЭлХ ЮиШСЪШ, ЯЮбЪЮЫмЪг ЯаЮУаРЬЬШбвг вагФЭЮ ЯаХФгбЬЮваХвм ТбХ ТЮЧЬЮЦЭлХ ЯЮбЫХФбвТШп. ёЬХЭЭЮ ШЧ-ЧР вРЪШе ЯаЮСЫХЬ п ШбЯЮЫмЧЮТРЫ ТлиХ ЪЮЬРЭФг $NonASCII = '\x80-\xff'. ІЬХбвЮ нвЮУЮ ЬЮЦЭЮ СлЫЮ ТЮбЯЮЫмЧЮТРвмбп бваЮЪЮЩ "\x80-\xff", ЭЮ п еЮвХЫ ШЬХвм ТЮЧЬЮЦЭЮбвм ТлТХбвШ зРбвШзЭЮ ЯЮбваЮХЭЭЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ Т ЫоСЮЩ ЬЮЬХЭв вХбвШаЮТРЭШп. І ЯЮбЫХФЭХЬ бЫгзРХ аХУгЫпаЭЮХ ТлаРЦХЭШХ бЮФХаЦШв «блалХ» ЪЮФл, ТЯЮЫЭХ ЯЮФеЮФпйШХ ФЫп ЬХеРЭШЧЬР аХУгЫпаЭле ТлаРЦХЭШЩ — ЭЮ ЭХ ФЫп ТлТЮФР ТлаРЦХЭШп Т ЯаЮжХббХ ЮвЫРФЪШ.
ІХаЭХЬбп Ъ [($atom_char+)+]. П ЭХ ЬЮУг ЮУаРЭШзШТРвм РвЮЬ ТЮ ТЭгваХЭЭХЬ жШЪЫХ ЯаШ ЯЮЬЮйШ [\b], ЯЮбЪЮЫмЪг ЪЮЭжХЯжШп бЫЮТР Т Perl ЯЮЫЭЮбвмо ЮвЫШзРХвбп Юв ЪЮЭжХЯжШШ РвЮЬР Т РФаХбХ нЫХЪваЮЭЭЮЩ ЯЮзвл. ЅРЯаШЬХа, --genki-- — ТЯЮЫЭХ ФЮЯгбвШЬлЩ РвЮЬ, ЪЮвЮалЩ ЭХ бЮТЯРФРХв б [\b$atom_char+\b]. ВРЪШЬ ЮСаРЧЮЬ, звЮСл гСХФШвмбп, звЮ Т ЯаЮжХббХ ТЮЧТаРвР РвЮЬ ЭХ ЧРЪЮЭзШвбп Т бХаХФШЭХ ЯЮбЫХФЮТРвХЫмЭЮбвШ, б ЪЮвЮаЮЩ ЮЭ ФЮЫЦХЭ бЮТЯРбвм, п ЯаШ ЯЮЬЮйШ (?!…) гСХЦФРобм Т вЮЬ, звЮ $atom_char ЭХ бЮТЯРФРХв ЧР ЪЮЭжЮЬ atom (ЯХаХФ ТРЬШ ЮФЭР ШЧ бШвгРжШЩ, УФХ ЯаШУЮФШЫШбм Сл ЭХгбвгЯзШТлХ ЪТРЭвШдШЪРвЮал — бЬ. бЭЮбЪг ЭР б. <$R[P#,R4-41]>).
ЕЮвп Ьл аРСЮвРХЬ бЮ бваЮЪРЬШ Т ЪРТлзЪРе, Р ЭХ б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ, п ШбЯЮЫмЧго ЯаЮШЧТЮЫмЭго аРббвРЭЮТЪг ЯаЮЯгбЪЮТ Ш ЪЮЬЬХЭвРаШШ (ЧР ШбЪЫозХЭШХЬ бШЬТЮЫмЭле ЪЫРббЮТ), ЯЮбЪЮЫмЪг нвШ бваЮЪШ Т ЪЮЭХзЭЮЬ бзХвХ СгФгв ШбЯЮЫмЧЮТРЭл ФЫп ЯЮбваЮХЭШп аХУгЫпаЭЮУЮ ТлаРЦХЭШп б ЬЮФШдШЪРвЮаЮЬ /x. ѕФЭРЪЮ п бЯХжШРЫмЭЮ бЫХЦг ЧР вХЬ, звЮСл ЪРЦФлЩ ЪЮЬЬХЭвРаШЩ ЧРТХаиРЫбп бШЬТЮЫЮЬ ЭЮТЮЩ бваЮЪШ, ЯЮвЮЬг звЮ п ЭХ еЮзг бвЮЫЪЭгвмбп б ЯаЮСЫХЬЮЩ ЫШиЭШе гФРЫХЭШЩ (б. <$R[P#,R7-126]>).
їЮШбЪ ЪЮЬЬХЭвРаШХТ Т РФаХбРе ЧРвагФЭпХвбп вХЬ, звЮ Т бЮЮвТХвбвТШШ бЮ бЯХжШдШЪРжШХЩ ЮЭШ ЬЮУгв бЮФХаЦРвм ТЫЮЦХЭЭлХ ЪагУЫлХ бЪЮСЪШ — ЮФЭШЬ аХУгЫпаЭлЬ ТлаРЦХЭШХЬ нвР ЯаЮСЫХЬР ЭХ аХиРХвбп. јЮЦЭЮ ЭРЯШбРвм аХУгЫпаЭЮХ ТлаРЦХЭШХ, ЮСаРСРвлТРойХХ ТЫЮЦХЭЭлХ ЪЮЭбвагЪжШШ ФЮ ЮЯаХФХЫХЭЭЮУЮ гаЮТЭп, ЭЮ ЭХ ФЫп ЯаЮШЧТЮЫмЭЮУЮ гаЮТЭп. І ЭРиХЬ ЯаШЬХаХ п аХиШЫ аХРЫШЧЮТРвм Т $comment ЯЮФФХаЦЪг ЮФЭЮУЮ гаЮТЭп ТЭгваХЭЭХЩ ТЫЮЦХЭЭЮбвШ:
# НЫХЬХЭвл 22 Ш 23 - ЪЮЬЬХЭвРаШЩ.
# АХРЫШЧЮТРвм ЮСйШЩ бЫгзРЩ ЯаШ ЯЮЬЮйШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп
# ЭХТЮЧЬЮЦЭЮ. І ФРЭЭЮЬ ЯаШЬХаХ ФЮЯгбЪРХвбп ЮФШЭ гаЮТХЭм ТЫЮЦХЭЭЮбвШ.
$ctext = qq< [^$esc$NonASCII$CRlist()] >;
$Cnested = qq< $OpenParen (?: $ctext | $quoted_pair )* $CloseParen >;
$comment = qq< $OpenParen
(?: $ctext | $quoted_pair | $Cnested )*
$CloseParen >;
$X = qq< (?: [$space$tab] | $comment )+ >; # ЅХЮСпЧРвХЫмЭлЩ
# аРЧФХЫШвХЫм
$sep = qq< (?: [$space$tab] | $comment )* >; # ѕСпЧРвХЫмЭлЩ
# аРЧФХЫШвХЫм
ѕСаРвШвХ ТЭШЬРЭШХ: нЫХЬХЭв 22 ЭШУФХ СЮЫмиХ Т вРСЫШжХ 7.11 ЭХ ТбваХзРХвбп. їаРТФР, Т вРСЫШжХ ЭХ ЯЮЪРЧРЭЮ, звЮ бЯХжШдШЪРжШп ЯЮЧТЮЫпХв бТЮСЮФЭЮ ТЪЫозРвм ЪЮЬЬХЭвРаШШ, ЯаЮСХЫл Ш бШЬТЮЫл вРСгЫпжШШ ЬХЦФг СЮЫмиШЭбвТЮЬ ЫХЪбШзХбЪШе нЫХЬХЭвЮТ. їЮ нвЮЩ ЯаШзШЭХ Ьл бЮЧФРХЬ ЯХаХЬХЭЭго $X ФЫп ЭХЮСпЧРвХЫмЭле ЯаЮСХЫЮТ Ш ЪЮЬЬХЭвРаШХТ, Ш ЯХаХЬХЭЭго $sep — ФЫп ЮСпЧРвХЫмЭле.
±ЮЫмиШЭбвТЮ нЫХЬХЭвЮТ ШЧ вРСЫ. 7.11 аХРЫШЧгХвбп ЮзХЭм ЯаЮбвЮ. µФШЭбвТХЭЭлЩ дЮЪгб ЧРЪЫозРХвбп Т вЮЬ, звЮСл ЯХаХЬХЭЭРп $X ШбЯЮЫмЧЮТРЫРбм вРЬ, УФХ ЮЭР ЬЮЦХв ШбЯЮЫмЧЮТРвмбп Т бЮЮвТХвбвТШШ бЮ бЯХжШдШЪРжШХЩ, ЭЮ ЯЮ бЮЮСаРЦХЭШпЬ нддХЪвШТЭЮбвШ — ЭХ зРйХ ЭХЮСеЮФШЬЮУЮ. јЮЩ бЯЮбЮС ЧРЪЫозРХвбп Т ШбЯЮЫмЧЮТРЭШШ $X вЮЫмЪЮ ЬХЦФг нЫХЬХЭвРЬШ ЮФЭЮУЮ ЯЮФТлаРЦХЭШп. ѕЯаХФХЫХЭШХ СЮЫмиШЭбвТР ЫХЪбШзХбЪШе нЫХЬХЭвЮТ ЯаШТХФХЭЮ ЭШЦХ.
# НЫХЬХЭв 11: бваЮЪР Т ЪРТлзЪРе, ТЮЧЬЮЦЭЮ - б нЪаРЭШаЮТРЭЭлЬШ бШЬТЮЫРЬШ
$quoted_str = qq<
\" (?: # ѕвЪалТРойРп ЪРТлзЪР...
$qtext # ТбХ, ЪаЮЬХ \ Ш "
| # ШЫШ
$quoted_pair # нЪаРЭШаЮТРЭЭЮХ "ЭХзвЮ"(!= CR)
)* \" # ЧРЪалТРойРп ЪРТлзЪР
>;
# НЫХЬХЭв 7: word - atom ШЫШ quoted_str
$word = qq< (?: $atom | $quoted_str ) >;
# НЫХЬХЭв 12: domain-ref - ЯаЮбвЮ atom
$domain_ref = $atom;
# НЫХЬХЭв 13: domain-literal - РЭРЫЮУ бваЮЪШ Т ЪРТлзЪРе-, ЭЮ ТЬХбвЮ
# "..." ШбЯЮЫмЧгХвбп [...]
$domain_lit = qq< $OpenBR # [
(?: $dtext | $quoted_pair )* # бЮФХаЦШЬЮХ
$CloseBR # ]
>;
# НЫХЬХЭв 9: sub-domain - domain-ref ШЫШ domain-literal
$sub_domain = qq< (?: $domain_ref | $domain_lit ) >;
# НЫХЬХЭв 6: domain - бЯШбЮЪ бгСФЮЬХЭЮТ (subdomain), аРЧФХЫХЭЭле вЮзЪРЬШ.
$domain = qq< $sub_domain # ЅРзРЫмЭлЩ бгСФЮЬХЭ
(?: #
$X $Period # µбЫШ ФРЫмиХ ШФХв вЮзЪР...
$X $sub_domain # ...бЫХФгойШЩ бгСФЮЬХЭ
)*
>;
# НЫХЬХЭв 8: route. їЮбЫХФЮТРвХЫмЭЮбвм "@ $domain", аРЧФХЫХЭЭле ЧРЯпвлЬШ,
# ЯЮбЫХ ЪЮвЮаЮЩ бЫХФгХв вЮзЪР.
$route = qq< \@ $X $domain
(?: $X , $X \@ $X $domain )* # ґЮЬХЭл ЯХаХзШбЫповбп зХаХЧ ЧРЯпвго
: # ЧРЪалТРойХХ ФТЮХвЮзШХ
>;
# НЫХЬХЭв 5: local-part - ЯЮбЫХФЮТРвХЫмЭЮбвм $word, аРЧФХЫХЭЭле ЧРЯпвлЬШ
$local_part_part = qq< $word # ЅРзРЫмЭЮХ бЫЮТЮ
(?: $X $Period $X $word )* # БЫЮТР ЯХаХзШбЫповбп зХаХЧ ЧРЯпвго
>;
# НЫХЬХЭв 2: addr-spec - local@domain
$addr_spec = qq< $local_part $X \@ $X $domain >;
# НЫХЬХЭв 4: route-addr - <route? addr-spec>
$route_addr = qq[ < $X # ѕвЪалТРойРп бЪЮСЪР <
(?: $route $X )? # ЭХЮСпЧРвХЫмЭлЩ ЬРаиагв
$addr_spec # бЯХжШдШЪРжШп РФаХбР
$X > # ЧРЪалТРойРп >
];
їаШ ЮЯаХФХЫХЭШШ даРЧл (phrase) ТЮЧЭШЪРов ЮЯаХФХЫХЭЭлХ бЫЮЦЭЮбвШ. І бЮЮвТХвбвТШШ б вРСЫ. 7.11, нвЮ ЮФЭЮ ШЫШ ЭХбЪЮЫмЪЮ бЫЮТ (word), ЮФЭРЪЮ Ьл ЭХ ЬЮЦХЬ ШбЯЮЫмЧЮТРвм ЪЮЭбвагЪжШо (?:$word)+, ЯЮбЪЮЫмЪг ЪЮЬЯЮЭХЭвл ЬЮУгв аРЧФХЫпвмбп $sep. єЮЭбвагЪжШп (?:$word|$sep)+ вЮЦХ ЭХ УЮФШвбп, ЯЮбЪЮЫмЪг ЮЭР ЭХ ваХСгХв ЯаШбгвбвТШп $word, Р ЫШим аРЧаХиРХв ХУЮ. ІЮЧЭШЪРХв ЧРЬРЭзШТРп ЬлбЫм — ШбЯЮЫмЧЮТРвм $word(?:$word|$sep)*, Ш ЧФХбм ЯаШФХвбп еЮаЮиХЭмЪЮ ЯЮФгЬРвм. ІбЯЮЬЭШвХ, ЪРЪ Ьл ЪЮЭбвагШаЮТРЫШ $sep. ЗРбвм, ЭХ пТЫпойРпбп ЪЮЬЬХЭвРаШХЬ, дРЪвШзХбЪШ ЮЯШблТРХвбп ТлаРЦХЭШХЬ [[$space$tab]+], Ш ХХ ТЪЫозХЭШХ Т (…)* ЯЮФЮЧаШвХЫмЭЮ ЭРЯЮЬШЭРХв бШвгРжШо СХбЪЮЭХзЭЮУЮ ЯХаХСЮаР (б. <$R[P#,R5-27]>). °ЭРЫЮУШзЭРп ЯаЮСЫХЬР ТЮЧЭШЪРЫР Сл Ш ФЫп $atom ТЭгваШ $word, ХбЫШ Сл ЭХ ЪЮЭбвагЪжШп (?!…), ШбЯЮЫмЧЮТРЭЭРп ФЫп ЯаЮТХаЪШ УаРЭШж бЮТЯРФХЭШп. ЅХзвЮ ЯЮеЮЦХХ ЬЮЦЭЮ СлЫЮ Сл бФХЫРвм Ш ФЫп $sep, ЭЮ г ЬХЭп Хбвм ШФХп ЯЮЫгзиХ.
ДаРЧР ЬЮЦХв бЮФХаЦРвм нЫХЬХЭвл зХвлаХе вШЯЮТ: бваЮЪШ Т ЪРТлзЪРе, РвЮЬл, ЯаЮСХЫл Ш ЪЮЬЬХЭвРаШШ. °вЮЬ ЯаХФбвРТЫпХв бЮСЮЩ ЯаЮбвго ЯЮбЫХФЮТРвХЫмЭЮбвм $atom_char — ХбЫШ ЯЮбЫХФЮТРвХЫмЭЮбвм аРЧФХЫХЭР ЯаЮСХЫРЬШ, нвЮ ЯаЮбвЮ ЮЧЭРзРХв, звЮ ЮЭР бЮбвЮШв ШЧ ЭХбЪЮЫмЪШе РвЮЬЮТ. ЅРб ШЭвХаХбгов УаРЭШжл ЭХ ЮвФХЫмЭле РвЮЬЮТ, Р ЫШим ТбХЩ ЯЮбЫХФЮТРвХЫмЭЮбвШ, ЯЮнвЮЬг Ьл ЬЮЦХЬ ТЮбЯЮЫмЧЮТРвмбп ЪЮЭбвагЪжШХЩ бЫХФгойХУЮ ТШФР:
$word (?: [$atom_char$space$tab] | $quoted_string | $comment )+
ЅР бРЬЮЬ ФХЫХ ШбЯЮЫмЧЮТРвм ЯЮФЮСЭлЩ бШЬТЮЫмЭлЩ ЪЫРбб ЭХЫмЧп, ЯЮбЪЮЫмЪг $atom_char гЦХ пТЫпХвбп бШЬТЮЫмЭлЬ ЪЫРббЮЬ. їЮнвЮЬг Ьл ФЮЫЦЭл бЪЮЭбвагШаЮТРвм ЪЫРбб ЧРЭЮТЮ, ШЬШвШагп $atom_char, ЭЮ ШбЪЫозШТ ШЧ ЭХУЮ ЯаЮСХЫ Ш бШЬТЮЫ вРСгЫпжШШ (гФРЫХЭШХ бШЬТЮЫЮТ ШЧ ШЭТХавШаЮТРЭЭЮУЮ бШЬТЮЫмЭЮУЮ ЪЫРббР ЯаШТЮФШв Ъ Ше ТЪЫозХЭШо Т ЭРСЮа бШЬТЮЫЮТ, б ЪЮвЮалЬШ нвЮв ЪЫРбб ЬЮЦХв бЮТЯРФРвм):
# НЫХЬХЭв 3: phrase
$phrase_ctrl = '\000-\010\012-\037'; # °ЭРЫЮУ ctrl, ЭЮ СХЧ вРСгЫпжШШ
# °ЭРЫЮУ atom-char, ЭЮ СХЧ ЯаЮСХЫР Ш б phrase_ctrl.
# їЮбЪЮЫмЪг ЪЫРбб пТЫпХвбп ШЭТХавШаЮТРЭЭлЬ, ЮЭ бЮТЯРФРХв б вХЬШ ЦХ
# бШЬТЮЫРЬШ, звЮ Ш atom-char, Р вРЪЦХ б ЯаЮСХЫЮЬ Ш вРСгЫпжШХЩ
$phrase_char =
qq/[^()<>\@,;:\".$esc$OpenBR$CloseBR$NonASCII$phrase_ctrl]/;
$phrase = qq< $word # ѕФЭЮ бЫЮТЮ, ЧР ЪЮвЮалЬ ЬЮУгв бЫХФЮТРвм....
(?:
$phrase_char | # °вЮЬл Ш ЯаЮСХЫл, ШЫШ ...
$comment | # ЪЮЬЬХЭвРаШШ, ШЫШ...
$quoted_str # бваЮЪШ Т ЪРТлзЪРе
)*
>;
І ЮвЫШзШХ Юв ТбХе ЮбвРЫмЭле ЪЮЭбвагЪжШЩ, ТбваХзРТиШебп ФЮ ЭРбвЮпйХУЮ ЬЮЬХЭвР, нвР бЮТЯРФРХв б ЧРТХаиРойШЬШ ЯаЮЯгбЪРЬШ Ш ЪЮЬЬХЭвРаШпЬШ. НвЮ ЭХЯЫЮеЮ, ЭЮ ФЫп ЯЮТлиХЭШп нддХЪвШТЭЮбвШ бЫХФгХв ЯЮЬЭШвм Ю вЮЬ, звЮ ЯЮбЫХ ЫоСЮУЮ ШбЯЮЫмЧЮТРЭШп $phrase ЭХ ЭгЦЭЮ ТбвРТЫпвм $X.
ѕбвРХвбп ЫШим ЮЯаХФХЫШвм нЫХЬХЭв 1 ЭХбЫЮЦЭЮЩ ЪЮЭбвагЪжШХЩ бЫХФгойХУЮ ТШФР:
# НЫХЬХЭв 1: mailbox - addr_spec ШЫШ phrase/route_addr
$mailbox = qq< $X # ЅХЮСпЧРвХЫмЭлЩ ЭРзРЫмЭлЩ ЪЮЬЬХЭвРаШЩ
(?: $addr_spec # РФаХб
| # ШЫШ
$phrase $route_addr # ШЬп ШЫШ РФаХб
) $X # ЭХЮСпЧРвХЫмЭлЩ ЪЮЭХзЭлЩ ЪЮЬЬХЭвРаШЩ
>;
іЮвЮТЮ!
ВХЯХам Т ЯаЮУаРЬЬХ ЬЮЦЭЮ ШбЯЮЫмЧЮТРвм ЪЮЭбвагЪжШШ ТШФР:
die "invalid address [$addr]\n" if $addr !~ m/^$mailbox/xo;
(п ЭРбвЮпвХЫмЭЮ ЭХ бЮТХвго ЧРСлТРвм ЬЮФШдШЪРвЮа /o Т ЯЮФЮСЭле аХУгЫпаЭле ТлаРЦХЭШпе[59]!)
ёЭвХаХбЭЮ ТЧУЫпЭгвм ЭР ШвЮУЮТЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ, вЮ Хбвм ЭХЯЮбаХФбвТХЭЭЮХ бЮФХаЦШЬЮХ $mailbox. ЅШЦХ ЯаШТХФХЭл ЯХаТлХ ШЧ 60 б ЫШиЭШЬ бваЮЪ нвЮУЮ ТлаРЦХЭШп, аРЧСШвЮУЮ ЭР бваЮЪШ ФЫп ТлТЮФР, ЯЮбЫХ гФРЫХЭШп ЪЮЬЬХЭвРаШХТ б ЯаЮСХЫРЬШ:
(?:[\040\t]|\((?:[^\\\x80-\xff\n\015()]|\\[^\x80-\xff]|\((?:[^\\\x80-
\xff\n\015()]|\\[^\x80-\xff])*\))*(?:(?:[^(\040)<>@,;:".\\\[\]\000-\0
37\x80-\xff]+(?![^(\040)<>@,;:".\\\[\]\000-\037\x80-\xff])|"(?:[^\\\x
80-\xff\n\015"]|\\[^\x80-\xff])*")(?:(?:[\040\t]|\((?:[^\\\x80-\xff\n
\015()]|\\[^\x80-\xff]|\((?:[^\\\x80-\xff\n\015()]|\\[^\x80-\xff])*\)
)*\))*\.(?:[\040\t]|\(?:[^\\\x80-\xff\n\015()]|\\[^\x80-\xff]|\(?:[^\
\\x80-\xff\n\015()]|\\[^\x80-\xff])*\))*\))*(?:[^(\040)<>@,;:".\\\[\]
\000-\037\x80-\xff]+(?![^(\040)<>@,;:".\\\[\]\000-\037\x80-\xff])|"(?
ѕФЭРЪЮ! ЅР ЯХаТлЩ ТЧУЫпФ ЪРЦХвбп, звЮ вРЪЮХ УШУРЭвбЪЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯаЮбвЮ ЭХ ЬЮЦХв аРСЮвРвм нддХЪвШТЭЮ, ЭЮ аРЧЬХа аХУгЫпаЭЮУЮ ТлаРЦХЭШп ЭХ ШЬХХв ЭШЪРЪЮУЮ ЮвЭЮиХЭШп Ъ нддХЪвШТЭЮбвШ. іЫРТЭлЩ ЮЯаХФХЫпойШЩ дРЪвЮа — ЪЮЫШзХбвТЮ ТЮЧТаРвЮТ. ЅХ бЮФХаЦШв ЫШ ТлаРЦХЭШХ СЮЫмиЮХ ЪЮЫШзХбвТЮ ЪЮЭбвагЪжШЩ ТлСЮаР? ° бШвгРжШШ СХбЪЮЭХзЭЮУЮ ЯЮШбЪР? ґРЦХ ЮзХЭм СЮЫмиЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЬЮЦХв СлбваЮ ЯаШТЮФШвм ЬХеРЭШЧЬ Ъ ЭРЩФХЭЭЮЬг бЮТЯРФХЭШо ШЫШ ТлТЮФг Ю ХУЮ ЮвбгвбвТШШ.
їаШ аРСЮвХ б ЯЮФЮСЭлЬШ ТлаРЦХЭШпЬШ ЭХЮСеЮФШЬЮ еЮаЮиЮ ЯЮЭШЬРвм Ше ТЮЧЬЮЦЭЮбвШ. ВРЪ, ЭРиХ ТлаРЦХЭШХ ЮЯЮЧЭРХв вЮЫмЪЮ РФаХбР нЫХЪваЮЭЭЮЩ ЯЮзвл ёЭвХаЭХвР Ш ЭХ аРСЮвРХв б ЫЮЪРЫмЭлЬШ РФаХбРЬШ. ЅРЯаШЬХа, ЭР ЬЮХЬ ЪЮЬЯмовХаХ бваЮЪР jfriedl пТЫпХвбп ФЮЯгбвШЬлЬ РФаХбЮЬ нЫХЪваЮЭЭЮЩ ЯЮзвл, ЭЮ ЮЭР ЭХ бЮЮвТХвбвТгХв дЮаЬРвг ЯЮзвЮТЮУЮ РФаХбР ёЭвХаЭХвР (ТЯаЮзХЬ, нвР ЯаЮСЫХЬР бТпЧРЭР ЭХ б аХУгЫпаЭлЬ ТлаРЦХЭШп, Р бЪЮаХХ б ХУЮ ЭХЯаРТШЫмЭлЬ ЯаШЬХЭХЭШХЬ). єаЮЬХ вЮУЮ, РФаХб ЬЮЦХв Слвм ЫХЪбШзХбЪШ ЯаРТШЫмЭлЬ, ЭЮ ЯаШ нвЮЬ ЭШЪгФР ЭХ гЪРЧлТРвм (ЪРЪ Т ЯаШТХФХЭЭЮЬ ТлиХ ЯаШЬХаХ That Tall Guy). ґЫп аХиХЭШп ЭХЪЮвЮале ЯаЮСЫХЬ ЬЮЦЭЮ ЯЮваХСЮТРвм, звЮСл ШЬп ФЮЬХЭР ЧРТХаиРЫЮбм бгСФЮЬХЭЮЬ, бЮбвЮпйШЬ ШЧ ФТге ШЫШ ваХе бШЬТЮЫЮТ (ЭРЯаШЬХа, .com ШЫШ .jp). ·РФРзг ЬЮЦЭЮ аХиШвм ЯаЮбвлЬ ЯаШбЮХФШЭХЭШХЬ $esc . $atom_char {2,3} Ъ $domain, ШЫШ ЦХ СЮЫХХ бваЮУЮ — ЯапЬлЬ ЯХаХзШбЫХЭШХЬ ТЮЧЬЮЦЭле бгСФЮЬХЭЮТ:
$esc . (?: com | edu | gov | … | ca | de | jp | u[sk] …)
µбЫШ гЦ ЭР вЮ ЯЮиЫЮ, РСбЮЫовЭЮ ЭХТЮЧЬЮЦЭЮ УРаРЭвШаЮТРвм, звЮ ЮвЯаРТЫХЭЭЮХ ЯЮ ЭХЪЮвЮаЮЬг РФаХбг ЯШбмЬЮ ФЮ ЪЮУЮ-вЮ ФЮЩФХв. ВЮзЪР. ѕвЯаРТЪР вХбвЮТЮУЮ бЮЮСйХЭШп — еЮаЮиШЩ бЯЮбЮС, ХбЫШ ЪвЮ-ЭШСгФм гФЮбгЦШвбп ЭР ЭХУЮ ЮвТХвШвм. ВРЪЦХ Т ЧРУЮЫЮТЮЪ бЮЮСйХЭШп ЦХЫРвХЫмЭЮ ТЪЫозШвм ЯЮЫХ Return-Receipt-To, ЯЮбЪЮЫмЪг ЮЭЮ ЧРбвРТШв гФРЫХЭЭго бШбвХЬг бУХЭХаШаЮТРвм ЪЮаЮвЪШЩ ЮвТХв Ю ЯаШСлвШШ ТРиХУЮ бЮЮСйХЭШп Т ЯЮзвЮТлЩ пйШЪ.
ЅРФХобм, Т ЯаЮжХббХ ЯЮбваЮХЭШп аХУгЫпаЭЮУЮ ТлаРЦХЭШп Тл ЮСаРвШЫШ ТЭШЬРЭШХ ЭР ЬЭЮУЮзШбЫХЭЭлХ ТЮЧЬЮЦЭЮбвШ ФЫп ЮЯвШЬШЧРжШШ. ІбЯЮЬЭШвХ гаЮЪ ШЧ УЫРТл 5: ЭРи бвРалЩ ЧЭРЪЮЬлЩ — ТлаРЦХЭШХ ФЫп бваЮЪ Т ЪРТлзЪРе — ЫХУЪЮ аРЧТЮаРзШТРХвбп Т дЮаЬг
$quoted_str = qq<
\" # "
$qtext * # ЭЮаЬ
(?: $quoted_pair $qtext * )* # ( бЯХж ЭЮаЬ* )*
\" # "
>;
їаШ нвЮЬ ЮЯаХФХЫХЭШХ $phrase ЯаШЭШЬРХв бЫХФгойШЩ ТШФ:
$phrase = qq<
$word # ЅРзРЫмЭЮХ бЫЮТЮ
$phrase_char * # "ЭЮаЬРЫмЭлХ" РвЮЬл Ш/ШЫШ ЯаЮСХЫл
(?:
(?: $comment | $quoted_str ) # "бЯХжШРЫмЭлХ" ЪЮЬЬХЭвРаШШ ШЫШ
# бваЮЪШ Т ЪРТлзЪРе
$phrase_char * # бЭЮТР "ЭЮаЬРЫмЭлХ" нЫХЬХЭвл
)*
>;
ВРЪШХ нЫХЬХЭвл, ЪРЪ $Cnested, $comment, $phrase, $domain_lit Ш $X, ЮЯвШЬШЧШаговбп РЭРЫЮУШзЭлЬ ЮСаРЧЮЬ, ЭЮ СгФмвХ ТЭШЬРвХЫмЭл — ШЭЮУФР ТЮЧЭШЪРов ЧРвагФЭХЭШп. ·Р ЯаШЬХаЮЬ ЮСаРвШЬбп Ъ ЯХаХЬХЭЭЮЩ $sep. ѕЭР ваХСгХв ЬШЭШЬгЬ ЮФЭЮУЮ бЮТЯРФХЭШп, ЭЮ Т аХЧгЫмвРвХ бвРЭФРавЭЮЩ аРбЪагвЪШ бЮЧФРХвбп аХУгЫпаЭЮХ ТлаРЦХЭШХ, ФЫп ЪЮвЮаЮУЮ бЮТЯРФХЭШХ ЭХ пТЫпХвбп ЮСпЧРвХЫмЭлЬ.
ІЮЧТаРйРпбм Ъ ЮСйХЬг иРСЫЮЭг аРбЪагвЪШ (б. <$R[P#,R5-28]>), ХбЫШ Тл еЮвШвХ, звЮСл нЫХЬХЭв бЯХж СлЫ ЮСпЧРвХЫмЭлЬ, ТЭХиЭоо ЪЮЭбвагЪжШо (…)* ЬЮЦЭЮ ЧРЬХЭШвм ЭР (…)+, ЭЮ ФЫп $sep нвЮв ТРаШРЭв ЭХ ЯЮФеЮФШв. БЮТЯРФХЭШХ ФЮЫЦЭЮ ЯаШбгвбвТЮТРвм, ЭЮ бЮТЯРФРвм ЬЮЦХв ЪРЪ бЯХж, вРЪ Ш ЭЮаЬ.
ЅРЯШбРвм аРбЪагзХЭЭЮХ ТлаРЦХЭШХ, ваХСгойХХ ЫоСЮЩ ШЧ ФТге нЫХЬХЭвЮТ ЯЮ ЮвФХЫмЭЮбвШ, ЭХвагФЭЮ — ЭЮ звЮСл ТлСаРвм ЮФШЭ ШЧ ФТге ТРаШРЭвЮТ, ЭРЬ ЯЮваХСгХвбп аРЧТХвТЫХЭШХ:
$sep = qq< (?:
[$space$tab]+ # ЅРзШЭРХвбп б ЯаЮСХЫР
(?: $comment [$space$tab]* )*
|
(?: $comment [$space$tab]* )+ # ЅРзШЭРХвбп б ЪЮЬЬХЭвРаШп
)
>;
І нвЮЩ ЪЮЬРЭФХ бЮФХаЦРвбп ФТХ ЬЮФШдШжШаЮТРЭЭлХ ТХабШШ иРСЫЮЭР [ЭЮаЬ* (бЯХж ЭЮаЬ*)*]: ЪЫРбб, бЮТЯРФРойШЩ б ЯаЮЯгбЪРЬШ, бЮЮвТХвбвТгХв ЭЮаЬ, Р $comment бЮЮвТХвбвТгХв бЯХж. І ЯХаТЮЬ бЫгзРХ ЮСпЧРвХЫмЭлЬШ пТЫповбп ЯаЮЯгбЪШ, ЧР ЪЮвЮалЬШ ЬЮУгв бЫХФЮТРвм ЪЮЬЬХЭвРаШШ Ш ЯаЮЯгбЪШ. ІЮ ТвЮаЮЬ бЫгзРХ ЮСпЧРвХЫмЭлЬ пТЫпХвбп ЪЮЬЬХЭвРаШЩ, ЧР ЪЮвЮалЬ ЬЮУгв бЫХФЮТРвм ЯаЮЯгбЪШ. ІЮ ТвЮаЮЩ РЫмвХаЭРвШТХ ТЮЧЭШЪРХв ШбЪгиХЭШХ ШЭвХаЯаХвШаЮТРвм $comment ЪРЪ ЭЮаЬ Ш ТЮбЯЮЫмЧЮТРвмбп ТлаРЦХЭШХЬ ТШФР:
$comment (?: [$space$tab]+ $comment )*
ЅР ЯХаТлЩ ТЧУЫпФ вРЪЮХ аХиХЭШХ ТлУЫпФШв ТЯЮЫЭХ аРЧгЬЭЮ, ЭЮ Т ФХЩбвТШвХЫмЭЮбвШ ЯХаХФ ТРЬШ ЧРЬРбЪШаЮТРЭЭРп ЪЮЭбвагЪжШп СХбЪЮЭХзЭЮУЮ ЯХаХСЮаР. їаЮСЫХЬг ЬЮЦЭЮ аХиШвм гФРЫХЭШХЬ ЯЫобР, ЭЮ ЯЮЫгзХЭЭЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ бЮЧФРХв жШЪЫ ФЫп ЪРЦФЮУЮ ЯаЮСХЫР — нддХЪвШТЭЮбвм ЯЮФЮСЭЮУЮ аХиХЭШп ЮбвРТЫпХв ЦХЫРвм ЫгзиХУЮ.
ЅЮ ТбХ нвШ ЧРвагФЭХЭШп ЮЪРЧлТРовбп ЫШиЭШЬШ, ЯЮбЪЮЫмЪг ЯХаХЬХЭЭРп $sep ЭХ ШбЯЮЫмЧгХвбп Т ЪЮЭХзЭЮЬ ТРаШРЭвХ аХУгЫпаЭЮУЮ ТлаРЦХЭШп; ЮЭР ТбваХзРЫРбм вЮЫмЪЮ Т ЯХаТле ТРаШРЭвРе ЯЮбваЮХЭШп $phrase. П ХйХ ЭХ ШЧСРТШЫбп Юв ЭХХ ЫШим ЯЮвЮЬг, звЮ нвЮ ФЮТЮЫмЭЮ аРбЯаЮбваРЭХЭЭРп аРЧЭЮТШФЭЮбвм аРбЪагвЪШ жШЪЫР, Р РЭРЫШЧ ФХЫШЪРвЭле РбЯХЪвЮТ ЮЯвШЬШЧРжШШ ТХбмЬР ЯЮгзШвХЫХЭ.
ґагУРп аРЧЭЮТШФЭЮбвм ЮЯвШЬШЧРжШп бТпЧРЭР б ШбЯЮЫмЧЮТРЭШХЬ $X. їЮбЬЮваШЬ, ЪРЪ зРбвм ЭРиХУЮ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, бЮЮвТХвбвТгойРп $route, бЮТЯРФРХв б @spcgatewayspc:. ІбваХзРовбп бШвгРжШШ, ЪЮУФР ЯЮШбЪ бЮТЯРФХЭШп ФЫп ЭХЮСпЧРвХЫмЭЮЩ зРбвШ ЧРТХаиРХвбп ЭХгФРзХЩ, ЭЮ ЫШим ЯЮбЫХ ЮСЭРагЦХЭШп ЮФЭЮУЮ ШЫШ ЭХбЪЮЫмЪШе ТЭгваХЭЭШе бЮТЯРФХЭШЩ ФЫп $X. ґРТРЩвХ ТбЯЮЬЭШЬ, ЪРЪ ТлУЫпФпв ЭРиШ ЮЯаХФХЫХЭШп $domain Ш $route:
# НЫХЬХЭв 6: domain - бЯШбЮЪ бгСФЮЬХЭЮТ (subdomain), аРЧФХЫХЭЭле вЮзЪРЬШ.
$domain = qq< $sub_domain # ЅРзРЫмЭлЩ бгСФЮЬХЭ
(?: #
$X $Period # µбЫШ ФРЫмиХ ШФХв вЮзЪР...
$X $sub_domain # ...бЫХФгойШЩ бгСФЮЬХЭ
)*
>;
# НЫХЬХЭв 8: route. їЮбЫХФЮТРвХЫмЭЮбвм "@ $domain", аРЧФХЫХЭЭле ЧРЯпвлЬШ,
# ЯЮбЫХ ЪЮвЮаЮЩ бЫХФгХв вЮзЪР.
$route = qq< \@ $X $domain
(?: $X , $X \@ $X $domain )* # ґЮЬХЭл ЯХаХзШбЫповбп зХаХЧ ЧРЯпвго
: # ЧРЪалТРойХХ ФТЮХвЮзШХ
>;
їЮбЫХ вЮУЮ, ЪРЪ $route ЭРеЮФШв Т ЭРзРЫХ бваЮЪШ бЮТЯРФХЭШХ @spcgatewayspc:, Р ЯХаТлЩ ЪЮЬЯЮЭХЭв $sub_domain ЯХаХЬХЭЭЮЩ $domain бЮТЯРФРХв б @spcgatewayspc:, аХУгЫпаЭЮХ ТлаРЦХЭШХ ШйХв вЮзЪг Ш бЫХФгойШЩ ЪЮЬЯЮЭХЭв $sub_domain (б ТЮЧЬЮЦЭлЬ ЯаШбгвбвТШХЬ $X ЭР ЪРЦФЮЬ бвлЪХ). їаШ ЯХаТЮЩ ЯЮЯлвЪХ ЯЮШбЪР ФЫп ЯЮФТлаРЦХЭШп $X $Period $X $sub_domain ЯХаТлЩ нЪЧХЬЯЫпа $X бЮТЯРФРХв б ЯаЮСХЫЮЬ @spcgatewayspc:, ЭЮ ЯЮШбЪ вЮзЪШ ЧРТХаиРХвбп ЭХгФРзХЩ. НвЮ ЯаШТЮФШв Ъ ТлеЮФг ШЧ ЪагУЫле бЪЮСЮЪ б ТЮЧТаРвЮЬ, Р ЯЮШбЪ бЮТЯРФХЭШп ФЫп $domain ЭР нвЮЬ ЧРТХаиРХвбп.
їЮШбЪ бЮТЯРФХЭШп ФЫп $route ЯаЮФЮЫЦРХвбп. їЮбЫХ ЮСЭРагЦХЭШп бЮТЯРФХЭШп ФЫп ЯХаТЮУЮ $domain ЬХеРЭШЧЬ ЯлвРХвбп ЭРЩвШ бЫХФгойХХ бЮТЯРФХЭШХ, ЮвФХЫХЭЭЮХ ЧРЯпвЮЩ. І ЯЮФТлаРЦХЭШШ $X , $X \@… ЯХаТлЩ нЪЧХЬЯЫпа $X бЮТЯРФРХв б вХЬ ЦХ ЯаЮСХЫЮЬ, бЮТЯРФХЭШХ ФЫп ЪЮвЮаЮУЮ СлЫЮ ЭРЩФХЭЮ (Ш бЭЮТР ЮвЬХЭХЭЮ!) аРЭХХ. ё ЭР нвЮв аРЧ ЯЮШбЪ ЧРТХаиРХвбп ЭХгФРзХЩ.
АРбвЮзШвХЫмЭЮ ваРвШвм ТаХЬп ЭР ЯЮШбЪШ бЮТЯРФХЭШп ФЫп $X, ЪЮУФР ЯЮШбЪ бЮТЯРФХЭШп ФЫп ТбХУЮ ЯЮФТлаРЦХЭШп ЧРТХаиРХвбп ЭХгФРзХЩ. їЮбЪЮЫмЪг $X ЬЮЦХв бЮТЯРбвм ЯаРЪвШзХбЪШ ТХЧФХ, нддХЪвШТЭХХ ШбЪРвм бЮТЯРФХЭШХ ЫШим вЮУФР, ЪЮУФР ЧРТХФЮЬЮ бгйХбвТгХв бЮТЯРФХЭШХ ФЫп ТбХУЮ ЯЮФТлаРЦХЭШп.
АРббЬЮваШЬ бЫХФгойШЩ даРУЬХЭв, Т ЪЮвЮаЮЬ ШЧЬХЭШЫЮбм вЮЫмЪЮ аРбЯЮЫЮЦХЭШХ $X:
$domain = qq<
$sub_domain $X
(?: #
$Period $X $sub_domain $X
)*
>;
$route = qq<
\@ $X $domain
(?: , $X \@ $X $domain )*
: $X
>;
ѕв ЯаШЭжШЯР «ШбЯЮЫмЧЮТРвм $X вЮЫмЪЮ ЬХЦФг нЫХЬХЭвРЬШ Т ЯЮФТлаРЦХЭШпе» Ьл ЯХаХиЫШ Ъ ЯаШЭжШЯг «ЯаЮбЫХФШвм ЧР вХЬ, звЮСл ЯЮФТлаРЦХЭШХ ЯЮУЫЮйРЫЮ ТбХ ЪЮЭХзЭлХ $X».
І аХЧгЫмвРвХ ТбХе ШЧЬХЭХЭШЩ ШвЮУЮТЮХ ТлаРЦХЭШХ (ЯЮбЫХ гФРЫХЭШп ТбХе ЪЮЬЬХЭвРаШХТ Ш ЯаЮШЧТЮЫмЭле ЯаЮЯгбЪЮТ) гФЫШЭпХвбп ЯЮзвШ ЭР 50 ЯаЮжХЭвЮТ, ЭЮ Т ЬЮШе вХбвРе ЮЭЮ аРСЮвРЫЮ ЭР 9–19 ЯаЮжХЭвЮТ СлбваХХ (9 ЯаЮжХЭвЮТ — ФЫп вХбвЮТ б ЭХгФРзЭлЬ ЯЮШбЪЮЬ, 19 ЯаЮжХЭвЮТ — ФЫп вХбвЮТ, Т ЪЮвЮале бЮТЯРФХЭШХ бгйХбвТгХв). µйХ аРЧ ЭРЯЮЬЭо Ю ТРЦЭЮбвШ ЬЮФШдШЪРвЮаР /o. ѕЪЮЭзРвХЫмЭРп ТХабШп аХУгЫпаЭЮУЮ ТлаРЦХЭШп ЯаШТХФХЭР Т ЯаШЫЮЦХЭШШ ±.
ЅХбЬЮвап ЭР ФЫШЭг, аРббЬЮваХЭЭлЩ ЭРЬШ ЯаШЬХа ФХЬЮЭбваШагХв апФ ТРЦЭле ЬЮЬХЭвЮТ. їЮбваЮХЭШХ аХУгЫпаЭЮУЮ ТлаРЦХЭШп ШЧ ЯХаХЬХЭЭле — ЯЮЫХЧЭлЩ ЯаШХЬ, ЮФЭРЪЮ ЯЮЫмЧЮТРвмбп ШЬ бЫХФгХв ТЭШЬРвХЫмЭЮ Ш ЮбвЮаЮЦЭЮ. І зРбвЭЮбвШ, ЭХЮСеЮФШЬЮ ЯЮЬЭШвм бЫХФгойХХ:
l АРЧСХаШвХбм, ЪвЮ Ш звЮ ШЭвХаЯЮЫШагХв, Ш ЪЮУФР нвЮ ЯаЮШбеЮФШв. ѕбЮСЮХ ТЭШЬРЭШХ бЫХФгХв ЮСаРвШвм ЭР ЬЭЮУЮзШбЫХЭЭлХ ЯаХТаРйХЭШп нЪаРЭШагойХУЮ ЯаХдШЪбР \.
l ±гФмвХ ТЭШЬРвХЫмЭл ЯаШ ШбЯЮЫмЧЮТРЭШШ ЪЮЭбвагЪжШШ ТлСЮаР Т ЯЮФТлаРЦХЭШпе, ЭХ ЧРЪЫозХЭЭле Т ЪагУЫлХ бЪЮСЪШ. ѕиШСЪШ вШЯР
$word = qq< $atom | $quoted_str >;
$local_part = qq< $word (?: $X $Period $X $word) * >
ЫХУЪЮ ФЮЯгбвШвм, ЭЮ вагФЭЮ ЭРЩвШ. ЅХ бЪгЯШвХбм ЭР ЪагУЫлХ бЪЮСЪШ, Р ФЫп бЪЮаЮбвШ ШбЯЮЫмЧгЩвХ (?:…) вРЬ, УФХ нвЮ ТЮЧЬЮЦЭЮ. µбЫШ ТРЬ ЭХ гФРЫЮбм баРЧг ЭРЩвШ ЮиШСЪг Т ЯаШТХФХЭЭЮЬ ТлиХ даРУЬХЭвХ, ЯЮФгЬРЩвХ, ЪРЪЮХ ЧЭРзХЭШХ СгФХв ЯаШбТЮХЭЮ ЯХаХЬХЭЭЮЩ $line Т бЫХФгойХЬ даРУЬХЭвХ:
$field = "Subject|From|Date";
$line = "^$field: (.*)";
ІлаРЦХЭШХ [^Subject|From|Date:spc(.*)] ЧРЬХвЭЮ ЮвЫШзРХвбп Юв [^(Subject|From|Date):spc(.*)] — Ш ЪЮЭХзЭЮ, ЯЮЫмЧл Юв ЭХУЮ УЮаРЧФЮ ЬХЭмиХ.
l їЮЬЭШвХ Ю вЮЬ, звЮ ФХЩбвТШХ ЬЮФШдШЪРвЮаР /x ЭХ аРбЯаЮбваРЭпХвбп ЭР бШЬТЮЫмЭлХ ЪЫРббл, ЯЮнвЮЬг Т ЪЫРббРе ЭХЫмЧп ШбЯЮЫмЧЮТРвм ЯаЮШЧТЮЫмЭлХ ЯаЮЯгбЪШ Ш ЪЮЬЬХЭвРаШШ.
l єЮЬЬХЭвРаШШ ТЭгваШ аХУгЫпаЭле ТлаРЦХЭШЩ (ЯЮбЫХ #) ЯаЮФЮЫЦРовбп ФЮ ЪЮЭжР бваЮЪШ ШЫШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп. АРббЬЮваШЬ бЫХФгойШЩ даРУЬХЭв:
$domain_ref = qq< $atom # їаЮбвЮ РвЮЬ >
$sub_domain = qq< (?: $domain_ref | $domain_lit) >
єЮЭХж ЯХаХЬХЭЭЮЩ $domain_ref бЮТбХЬ ЭХ ЮЧЭРзРХв ЪЮЭжР ЪЮЬЬХЭвРаШп, ТбвРТЫХЭЭЮУЮ ШЧ нвЮЩ ЯХаХЬХЭЭЮЩ Т аХУгЫпаЭЮХ ТлаРЦХЭШХ. єЮЬЬХЭвРаШЩ ЯаЮФЮЫЦРХвбп ФЮ ЪЮЭжР аХУгЫпаЭЮУЮ ТлаРЦХЭШп ШЫШ бШЬТЮЫР ЭЮТЮЩ бваЮЪШ, ЯЮнвЮЬг Т ФРЭЭЮЬ бЫгзРХ ЪЮЬЬХЭвРаШЩ ТлеЮФШв ЧР ЯаХФХЫл $domain_ref, ЯЮУЫЮйРХв ЪЮЭбвагЪжШо ТлСЮаР, ЮбвРвЮЪ $sub_domain Ш ТбХ ЯЮбЫХФгойШХ бШЬТЮЫл ФЮ ЪЮЭжР аХУгЫпаЭЮУЮ ТлаРЦХЭШп ШЫШ СЫШЦРЩиХУЮ бШЬТЮЫР ЭЮТЮЩ бваЮЪШ. їаЮСЫХЬг ЬЮЦЭЮ аХиШвм агзЭЮЩ ТбвРТЪЮЩ бШЬТЮЫР ЭЮТЮЩ бваЮЪШ (б. <$R[P#,R7-127]>): $domain_ref = qq< $atom # їаЮбвЮ РвЮЬ\n >.
l їЮбЪЮЫмЪг Т ЯаЮжХббХ ЮвЫРФЪШ зРбвЮ ТЮЧЭШЪРХв ЭХЮСеЮФШЬЮбвм ТлТЮФШвм аХУгЫпаЭлХ ТлаРЦХЭШп ЪЮЬРЭФЮЩ print, ЯЮФгЬРЩвХ Ю ЧРЬХЭХ "\0xff" ЭР '\0xff'.
l АРЧСХаШвХбм Т ЮвЫШзШпе ЬХЦФг бЫХФгойШЬШ ЪЮЬРЭФРЬШ:
$quoted_pair = qq< $esc[^$NonASCII] >;
$quoted_pair = qq< $esc [^$NonASCII] >;
$quoted_pair = qq< ${esc}[^$NonASCII] >;
їХаТРп ЪЮЬРЭФР ЮзХЭм бШЫмЭЮ ЮвЫШзРХвбп Юв ФТге ЮбвРЫмЭле. ѕЭР ШЭвХаЯаХвШагХвбп ЪРЪ ЯЮЯлвЪР ШЭФХЪбРжШШ нЫХЬХЭвР ЬРббШТР $esc, звЮ, ЪЮЭХзЭЮ, ЮвЫШзРХвбп Юв ЧРФгЬРЭЭЮУЮ (б. <$R[P#,R7-128]>).
ЅРТХаЭЮХ, Тл гЦХ ЯЮЭпЫШ, звЮ п Т ЯЮЫЭЮЬ ТЮбвЮаУХ Юв аХУгЫпаЭле ТлаРЦХЭШЩ Perl — Ш ЪРЪ СлЫЮ бЪРЧРЭЮ Т бРЬЮЬ ЭРзРЫХ УЫРТл, ФЫп нвЮУЮ Хбвм ТХбЪШХ ЯаШзШЭл. ЅХбЮЬЭХЭЭЮ, »РааШ ГЮЫЫ, бЮЧФРвХЫм Perl, агЪЮТЮФбвТЮТРЫбп ЧФаРТлЬ бЬлбЫЮЬ Ш ТФЮеЭЮТХЭШХЬ. їгбвм г ХУЮ вТЮаХЭШп Хбвм бТЮШ ЭХФЮбвРвЪШ, Ш ТбХ ЦХ п ЭХ ЯХаХбвРо ЭРбЫРЦФРвмбп ШЧлбЪРЭЭлЬ СЮУРвбвТЮЬ ТЮЧЬЮЦЭЮбвХЩ ФШРЫХЪвР аХУгЫпаЭле ТлаРЦХЭШЩ Perl.
ІЯаЮзХЬ, ЭХ бзШвРЩвХ ЬХЭп СХЧФгЬЭлЬ дРЭРвШЪЮЬ — Perl ЭХ ЮСЫРФРХв ЬЭЮУШЬШ ТЮЧЬЮЦЭЮбвпЬШ, ЪЮвЮалХ п Сл еЮвХЫ Т ЭХЬ ТШФХвм. ЅРШСЮЫХХ ЮзХТШФЭЮХ гЯгйХЭШХ ЯЮФФХаЦШТРХвбп Т ФагУШе ФШРЫХЪвРе, Т зРбвЭЮбвШ Т Tcl, Python Ш GNU Emacs: аХзм ШФХв Ю ТЮЧЬЮЦЭЮбвШ ЯЮЫгзХЭШп ШЭФХЪбЮТ ЭРзРЫР Ш ЪЮЭжР бЮТЯРФХЭШп (Р вРЪЦХ зРбвШзЭле бЮТЯРФХЭШЩ $1, $2 Ш в. Ф.). їаШ ЯЮЬЮйШ ЯХаХЬХЭЭле ЬЮЦЭЮ ЯЮЫгзШвм ЪЮЯШо вХЪбвР, бЮТЯРФРойХУЮ б ЯЮФТлаРЦХЭШпЬШ Т ЪагУЫле бЪЮСЪРе, ЭЮ Т ЮСйХЬ бЫгзРХ ЭХТЮЧЬЮЦЭЮ ЮЯаХФХЫШвм, УФХ ШЬХЭЭЮ Т бваЮЪХ аРбЯЮЫЮЦХЭ нвЮв вХЪбв. їаХФЯЮЫЮЦШЬ, Тл ЯШиХвХ ЯаЮУаРЬЬг, ЮСгзРойго аРСЮвХ б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ. ІРЬ еЮвХЫЮбм Сл ТлТХбвШ ШбеЮФЭго бваЮЪг Ш ЯЮЪРЧРвм: «·ФХбм бЮТЯРФРХв ЯХаТРп ЯРаР ЪагУЫле бЪЮСЮЪ, ЧФХбм — ТвЮаРп, Ш вРЪ ФРЫХХ», ЭЮ ЯЮЪР Т Perl нвЮ бФХЫРвм ЭХТЮЧЬЮЦЭЮ.
ґагУРп ТЮЧЬЮЦЭЮбвм, ЪЮвЮаРп ЬЭХ ШЭЮУФР ЭгЦЭР — ЬРббШТ ($1, $2, $3, …), РЭРЫЮУ дгЭЪжШШ match-data Т Emacs (б. <$R[P#,R6-6]>). єЮЭХзЭЮ, п ЬЮУг бРЬЮбвЮпвХЫмЭЮ бЪЮЭбвагШаЮТРвм ЭХзвЮ ЯЮФЮСЭЮХ:
$parens[0] = $&;
$parens[1] = $1;
$parens[2] = $2;
$parens[3] = $3;
$parens[4] = $4;
…
ё ТбХ ЦХ СлЫЮ Сл гФЮСЭХХ, ХбЫШ Сл нвР ТЮЧЬЮЦЭЮбвм СлЫР ТбваЮХЭЭЮЩ.
ВРЪЦХ ТбЯЮЬШЭРовбп ЭХгбвгЯзШТлХ ЪТРЭвШдШЪРвЮал, гЯЮЬпЭгвлХ Т бЭЮбЪХ ЭР б. <$R[P#,R4-41]>. Б ЭШЬШ ЬЭЮУШХ ТлаРЦХЭШп аРСЮвРЫШ Сл УЮаРЧФЮ нддХЪвШТЭХХ.
ЅРЪЮЭХж, бгйХбвТгХв ЬРббР нЪЧЮвШзХбЪШе ТЮЧЬЮЦЭЮбвХЩ, Ю ЪЮвЮале ЬЮЦЭЮ вЮЫмЪЮ ЬХзвРвм (зХЬ п, бЮСбвТХЭЭЮ, Ш ЧРЭШЬРобм). ѕФЭРЦФл п ФЮиХЫ ФЮ вЮУЮ, звЮ аХРЫШЧЮТРЫ ЭР бТЮХЬ ЪЮЬЯмовХаХ бЯХжШРЫмЭго дЮаЬг ЧРЯШбШ, ЯаШ ЪЮвЮаЮЩ аХУгЫпаЭЮХ ТлаРЦХЭШХ ЬЮУЫЮ ТЮ ТаХЬп ЯЮШбЪР бЮТЯРФХЭШп ЮСаРйРвмбп Ъ РббЮжШРвШТЭЮЬг ЬРббШТг, ШбЯЮЫмЧгп [\1] Ш в. Ф. Т ЪРзХбвТХ ШЭФХЪбЮТ. ±ЫРУЮФРап нвЮЬг ЯЮпТШЫРбм ТЮЧЬЮЦЭЮбвм аРбиШаШвм ТлаРЦХЭШп вШЯР [(['"]).*?\1] Ш аХРЫШЧЮТРвм Т ЭШе ЯЮФФХаЦЪг <…>, {…} Ш в. Ф.
ґагУРп ТЮЧЬЮЦЭЮбвм, ЪЮвЮаго ЬЭХ еЮвХЫЮбм Сл ТШФХвм Т Perl — ШЬХЭЮТРЭЭлХ ЯЮФТлаРЦХЭШп, РЭРЫЮУШ ШЬХЭ бШЬТЮЫШзХбЪШе УагЯЯ пЧлЪР Python. АХзм ШФХв Ю бЮеаРЭпойШе ЪагУЫле бЪЮСЪРе, б ЪЮвЮалЬШ (ЪРЪШЬ-вЮ ЮСаРЧЮЬ) бТпЧлТРХвбп ЯХаХЬХЭЭРп. їаШ гбЯХиЭЮЬ ЯЮШбЪХ бЮТЯРФХЭШп ЯХаХЬХЭЭЮЩ ЯаШбТРШТРХвбп ЧЭРзХЭШХ. ЅРЯаШЬХа, нвЮ ЯЮЧТЮЫШЫЮ Сл РЭРЫШЧШаЮТРвм вХЫХдЮЭЭлХ ЭЮЬХаР ЪЮЭбвагЪжШпЬШ бЫХФгойХУЮ ТШФР (б ШбЯЮЫмЧЮТРЭШХЬ дШЪвШТЭЮУЮ бШЭвРЪбШбР ?<ЯХаХЬХЭЭРп>):
[(?<$area>\d\d\d)-(?<$exchange>\d\d\d)-(?<$num>\d\d\d\d)]
ІЯаЮзХЬ, ЫгзиХ ЮбвРЭЮТШвмбп, ЯЮЪР ЬХЭп ЭХ ЧРЭХбЫЮ бЫШиЪЮЬ ФРЫХЪЮ. їЮФТХФг ШвЮУ: п ЮЯаХФХЫХЭЭЮ ЭХ бзШвРо Perl ШФХРЫмЭлЬ пЧлЪЮЬ ФЫп аРСЮвл б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ.
ЅЮ ЮЭ ЮзХЭм СЫШЧЮЪ Ъ ШФХРЫг.
єРЪ ЯаРТШЫЮ, ЯаШ ЯХаХеЮФХ Юв Perl4 Ъ Perl5 ЯаЮСЫХЬ б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ ЭХ ТЮЧЭШЪРХв. ІХаЮпвЭЮ, бРЬЮХ бХамХЧЭЮХ аРбеЮЦФХЭШХ ЧРЪЫозРХвбп Т вЮЬ, звЮ @ вХЯХам ШЭвХаЯЮЫШагХвбп Т аХУгЫпаЭле ТлаРЦХЭШпе (Р вРЪЦХ бваЮЪРе Т ЪРТлзЪРе). ё ТбХ ЦХ ЯаШ аРСЮвХ ЭР Perl4 ЭХЮСеЮФШЬЮ гзШвлТРвм ЭХЪЮвЮалХ вЮЭЪШХ (Ш ЭХ ЮзХЭм) ЮСбвЮпвХЫмбвТР.
Б. <$R[P#,R7-38]>. <$M[R7-37]>БЯХжШРЫмЭлХ ЯХаХЬХЭЭлХ $&, $1 Ш в. Ф. Т Perl4 ЭХ ЮУаРЭШзШТРовбп ФЮбвгЯЮЬ вЮЫмЪЮ ФЫп звХЭШп, ЪРЪ Т Perl5. јЮФШдШЪРжШп нвШе ЯХаХЬХЭЭле ЭХ ЯаШТЮФШв Ъ ТЮЫиХСЭЮЬг ШЧЬХЭХЭШо ШбеЮФЭЮЩ бваЮЪШ, ШЧ ЪЮвЮаЮЩ ЮЭШ СлЫШ бЪЮЯШаЮТРЭл (еЮвп вРЪРп ТЮЧЬЮЦЭЮбвм СлЫР Сл ЭХЫШиЭХЩ). І ЮбЭЮТЭЮЬ нвЮ ЮСлзЭлХ ЯХаХЬХЭЭлХ б ФШЭРЬШзХбЪЮЩ ТШФШЬЮбвмо, ЪЮвЮалЬ ЯаШ ЪРЦФЮЬ гбЯХиЭЮЬ бЮТЯРФХЭШШ ЯаШбТРШТРовбп ЭЮТлХ ЧЭРзХЭШп.
Б. <$R[P#,R7-40]>. <$M[R7-39]>І Perl4 ЯХаХЬХЭЭРп $` ШЭЮУФР бблЫРХвбп ЭР вХЪбв, ЭРзШЭРойШЩбп Юв ЭРзРЫР бЮТЯРФХЭШп (Р ЭХ Юв ЭРзРЫР бваЮЪШ). ѕиШСЪР, ШбЯаРТЫХЭЭРп Т ЭЮТле ТХабШпе, ЯаШТЮФШЫР Ъ вЮЬг, ЯаШ ЪРЦФЮЩ ЪЮЬЯШЫпжШШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп ЧЭРзХЭШХ $` бСаРблТРЫЮбм. µбЫШ аХУгЫпаЭЮХ ТлаРЦХЭШХ-ЮЯХаРЭФ ШбЯЮЫмЧЮТРЫЮ ШЭвХаЯЮЫпжШо ЯХаХЬХЭЭле Ш ТеЮФШЫЮ Т ЪЮЭбвагЪжШо m/…/g Т бЪРЫпаЭЮЬ ЪЮЭвХЪбвХ (ЪРЪ Т ШвХаРвЮаХ жШЪЫР while), вЮ ЯХаХЪЮЬЯШЫпжШп, ЯаШТЮФШТиРп Ъ бСаЮбг $`, ТлЯЮЫЭпЫРбм ЯаШ ЪРЦФЮЩ ШвХаРжШШ.
Б. <$R[P#,R7-42]>. <$M[R7-41]>І Perl4 ЯаШ ЮвбгвбвТШШ ЪагУЫле бЪЮСЮЪ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ ЯХаХЬХЭЭРп $+ ТЮЫиХСЭлЬ ЮСаРЧЮЬ ЯаХТаРйРЫРбм Т ЪЮЯШо $&.
Б. <$R[P#,R7-45]>. <$M[R7-44]>Perl4 ШЭвХаЯЮЫШагХв $MonthName[…] ЪРЪ бблЫЪг ЭР ЬРббШТ ЫШим Т вЮЬ бЫгзРХ, ХбЫШ ЬРббШТ @MonthName ЧРТХФЮЬЮ бгйХбвТгХв. І Perl5 вРЪРп ШЭвХаЯаХвРжШп ШбЯЮЫмЧгХвбп ТбХУФР.
Б. <$R[P#,R7-47]>. <$M[R7-46]>І ЮвЫШзШХ Юв Perl5, ЯаХдШЪб нЪаРЭШаЮТРЭЭЮУЮ ЧРЪалТРойХУЮ ЮУаРЭШзШвХЫп Т Perl4 ЭХ гФРЫпХвбп. НвЮ бгйХбвТХЭЭЮ, ХбЫШ ЮУаРЭШзШвХЫм пТЫпХвбп ЬХвРбШЬТЮЫЮЬ. ЅРЯаШЬХа, ЭХбЪЮЫмЪЮ ЭРФгЬРЭЭРп ЯЮФбвРЭЮТЪР s*2\*2*4* Т Perl5 аРСЮвРХв ЭХ вРЪ, ЪРЪ бЫХФЮТРЫЮ Сл ЮЦШФРвм.
Б. <$R[P#,R7-72]>. <$M[R7-71]>Perl4 ЯЮЧТЮЫпХв ШбЯЮЫмЧЮТРвм ЯаЮЯгбЪШ Т ЪРзХбвТХ ЮУаРЭШзШвХЫп ЮЯХаРЭФР ЯаШ ЯЮШбЪХ. ЕЮвп ШЭЮУФР Т вРЪШе бШвгРжШпе СлТРЫЮ гФЮСЭЮ ШбЯЮЫмЧЮТРвм бШЬТЮЫ ЭЮТЮЩ бваЮЪШ, Т ЮбЭЮТЭЮЬ ЯЮФЮСЭлХ дЮЪгбл еЮаЮиШ ЫШим ФЫп ЪЮЭЪгабР ЭР БРЬго ·РУРФЮзЭго їаЮУаРЬЬг ЭР Perl.
Б. <$R[P#,R7-74]>. <$M[R7-73]>їЮЬЭШвХ: Т Perl4 ЯаЮЯгбЪРовбп ТбХ нЪаРЭШагойШХ ЯаХдШЪбл (бЬ. ЯаШЬХзРЭШХ 5).
Б. <$R[P#,R7-76]>. <$M[R7-75]>ґЫп ЮЯХаРвЮаР ЯЮШбЪР Т Perl4 зХвлаХ бЯХжШРЫмЭле ЮУаРЭШзШвХЫп m{…} ЭХ ЯЮФФХаЦШТРовбп. Б ФагУЮЩ бвЮаЮЭл, ЮЭШ ЯЮФФХаЦШТРовбп ФЫп ЮЯХаРвЮаР ЯЮФбвРЭЮТЪШ.
Б. <$R[P#,R7-78]>. <$M[R7-77]>Perl4 ЯЮФФХаЦШТРХв ЮбЮСлЩ бШЭвРЪбШб ЯЮШбЪР б ШбЯЮЫмЧЮТРЭШХЬ ?, ЭЮ вЮЫмЪЮ Т дЮаЬХ ?…?. єЮЭбвагЪжШп ?…? ЭХ пТЫпХвбп бЯХжШРЫмЭЮЩ.
Б. <$R[P#,R7-80]>. <$M[R7-79]>І Perl4 ЫоСЮЩ ТлЧЮТ reset Т ЯаЮУаРЬЬХ ЯаШТЮФШв Ъ бСаЮбг ТбХе ЮЯХаРжШЩ ЯЮШбЪР б ЮУаРЭШзШвХЫпЬШ ?. І Perl5 ТлЧЮТ reset ЮвЭЮбШвбп вЮЫмЪЮ Ъ вХЪгйХЬг ЯРЪХвг.
Б. <$R[P#,R7-83]>. <$M[R7-82]>їаШ ТлЧЮТХ ЮЯХаРвЮаР ЯЮШбЪР б ЯгбвлЬ ЮЯХаРЭФЮЬ Perl4 ЧРЭЮТЮ ШбЯЮЫмЧгХв ЯЮбЫХФЭХХ гбЯХиЭЮ ЯаШЬХЭХЭЭЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ СХЧ гзХвР ЮСЫРбвШ ТШФШЬЮбвШ. І Perl5 ШбЯЮЫмЧгХвбп ЯЮбЫХФЭХХ гбЯХиЭЮ ЯаШЬХЭХЭЭЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ Т вХЪгйХЩ ФШЭРЬШзХбЪЮЩ ЮСЫРбвШ ТШФШЬЮбвШ.
БЪРЧРЭЭЮХ ЯаЮйХ ЯЮпбЭШвм ЭР ЯаШЬХаХ. АРббЬЮваШЬ бЫХФгойШЩ даРУЬХЭв:
"5" =~ m/5/;
{ # БЮЧФРвм ЭЮТго ЮСЫРбвм ТШФШЬЮбвШ…
"4" =~ m/4/;
} # … ЧРТХаиШвм ЭЮТго ЮСЫРбвм ТШФШЬЮбвШ
"45" =~ m//; # ёбЯЮЫмЧЮТРвм ТлаРЦХЭШХ ЯЮ гЬЮЫзРЭШо. БЮТЯРФРХв 4 ШЫШ 5
# Т ЧРТШбШЬЮбвШ Юв вЮУЮ, ЪРЪЮХ ТлаРЦХЭШХ СлЫЮ ШбЯЮЫмЧЮТРЭЮ.
print 'this is Perl $&\n";
Perl4 ТлТЮФШв бваЮЪг this is Perl4, Р Perl5 — this is Perl5.
Б. <$R[P#,R7-89]>. <$M[R7-88]>І ЫоСЮЩ ТХабШШ бЯШбЪЮТРп дЮаЬР m/…/g ТЮЧТаРйРХв бЯШбЮЪ вХЪбвЮТле даРУЬХЭвЮТ, бЮТЯРТиШе б ЯЮФТлаРЦХЭШпЬШ Т ЪагУЫле бЪЮСЪРе. ВХЬ ЭХ ЬХЭХХ, Perl4 ЯаШ нвЮЬ ЭХ ЯаШбТРШТРХв ЧЭРзХЭШп $1 Ш ФагУШе ЯХаХЬХЭЭле нвЮУЮ бХЬХЩбвТР, Р Perl5 нвЮ ФХЫРХв.
Б. <$R[P#,R7-91]>. <$M[R7-90]>І Perl5 нЫХЬХЭвл бЯШбЪР, бЮЮвТХвбвТгойШХ ЭХбЮТЯРФРойШЬ ЯРаРЬ ЪагУЫле бЪЮСЮЪ Т ЪЮЭбвагЪжШШ m/…/g, ШЬХов ЭХЮЯаХФХЫХЭЭЮХ ЧЭРзХЭШХ, Р Т Perl4 ЮЭШ бЮФХаЦРв ЯгбвлХ бваЮЪШ. ѕСР ЧЭРзХЭШп ШЭвХаЯаХвШаговбп ЪРЪ ЫЮУШзХбЪРп ЫЮЦм, ЭЮ Т ЮбвРЫмЭЮЬ ЧРЬХвЭЮ ЮвЫШзРовбп.
Б. <$R[P#,R7-93]>. <$M[R7-92]>І Perl5 ЬЮФШдШЪРжШп жХЫХТЮУЮ вХЪбвР ЪЮЭбвагЪжШШ m/…/g Т бЪРЫпаЭЮЬ ЪЮЭвХЪбвХ ЯаШТЮФШв Ъ бСаЮбг ФРЭЭле pos. І Perl4 ЯЮЧШжШп /g бТпЧлТРХвбп б аХУгЫпаЭлЬ ТлаРЦХЭШХЬ-ЮЯХаРЭФЮЬ. ВРЪШЬ ЮСаРЧЮЬ, ЬЮФШдШЪРжШп вХЪбвР, ШбЯЮЫмЧгХЬЮУЮ Т ЪРзХбвТХ жХЫХТле ФРЭЭле, ЭХ ТЫШпХв ЭР ЯЮЧШжШо /g (нвЮ ЬЮЦХв Слвм ЪРЪ еЮаЮиЮ, вРЪ Ш ЯЫЮеЮ — Т ЧРТШбШЬЮбвШ Юв вЮУЮ, ЪРЪ ЯЮбЬЮваХвм). І Perl5 ЯЮЧШжШп /g бТпЧлТРХвбп б жХЫХТЮЩ бваЮЪЮЩ, ЯЮнвЮЬг ЯаШ ЫоСЮЩ ЬЮФШдШЪРжШШ ЯЮбЫХФЭХЩ ЯаЮШбеЮФШв бСаЮб ФРЭЭле pos.
Б. <$R[P#,R7-97]>. <$M[R7-96]>ЕЮвп Т Perl4 ЮЯХаРвЮа ЯЮШбЪР ЭХ ЯЮЧТЮЫпХв ШбЯЮЫмЧЮТРвм ЯРаЭлХ ЮУаРЭШзШвХЫШ (ЭРЯаШЬХа, m[…]), вРЪРп ТЮЧЬЮЦЭЮбвм бгйХбвТгХв ФЫп ЮЯХаРвЮаР ЯЮФбвРЭЮТЪШ. їЮ РЭРЫЮУШШ б Perl5, ХбЫШ аХУгЫпаЭЮХ ТлаРЦХЭШХ-ЮЯХаРЭФ ЧРЪЫозРХвбп Т ЯРаЭлХ ЮУаРЭШзШвХЫШ, ЮЯХаРЭФ-ЧРЬХЭР ЧРЪЫозРХвбп Т ФагУго ЯРаг. І ЮвЫШзШХ Юв Perl5, нвШ ФТХ ЯРал ЭХ ЬЮУгв аРЧФХЫпвмбп ЯаЮЯгбЪРЬШ (ЯЮбЪЮЫмЪг Т Perl4 ЯаЮЯгбЪШ бзШвРовбп ФЮЯгбвШЬлЬШ ЮУаРЭШзШвХЫпЬШ).
Б. <$R[P#,R7-100]>. <$M[R7-99]>єРЪ ЭШ бваРЭЭЮ, Т Perl4 ЪЮЭбвагЪжШп s'…'…' ЮСХбЯХзШТРХв РЯЮбваЮдЭлЩ ЪЮЭвХЪбв ФЫп ЮЯХаРЭФР-ТлаРЦХЭШп, ЭЮ ЭХ ФЫп ЮЯХаРЭФР-ЧРЬХЭл — ЯЮбЫХФЭШЩ ЮСаРСРвлТРХвбп ЯЮ бвРЭФРавЭлЬ ЯаРТШЫРЬ бваЮЪ, ЧРЪЫозХЭЭле Т ЪРТлзЪШ.
Б. <$R[P#,R7-102]>. <$M[R7-101]>І Perl4 ЮЯХаРЭФ-ЧРЬХЭР ШЭвХаЯаХвШагХвбп ЯЮ ЯаРТШЫРЬ бваЮЪ Т РЯЮбваЮдРе, ЯЮнвЮЬг Т \` Ш \\ ЭРзРЫмЭРп ЪЮбРп зХавР гФРЫпХвбп ХйХ ФЮ ЯХаХФРзШ eval. І Perl5 eval ЯЮЫгзРХв ТбХ ФРЭЭлХ вРЪ, ЪРЪ Хбвм.
Б. <$R[P#,R7-105]>. <$M[R7-104]>їаШ ЮвбгвбвТШШ ЯЮФбвРЭЮТЮЪ Perl5 ТЮЧТаРйРХв Ягбвго бваЮЪг. Perl4 ТЮЧТаРйРХв зШбЫЮ 0 (ЮСР ЧЭРзХЭШп ШЭвХаЯаХвШаговбп ЪРЪ ЫЮУШзХбЪРп ЫЮЦм).
Б. <$R[P#,R7-108]>. <$M[R7-107]>єЮЫШзХбвТЮ даРУЬХЭвЮТ ЯЮ гЬЮЫзРЭШо, ЯаХФЮбвРТЫпХЬЮХ Perl ФЫп ЪЮЭбвагЪжШШ ($filename, $size, $date) = split(…), ТЫШпХв ЭР ЧЭРзХЭШХ, ЯаШбТРШТРХЬЮХ @_, ЯаШ ШбЯЮЫмЧЮТРЭШШ ЮЯХаРЭФР Т дЮаЬХ ?…?. І Perl5 ЯЮФЮСЭЮЩ ЯаЮСЫХЬл ЭХ бгйХбвТгХв, ЯЮбЪЮЫмЪг дЮабШаЮТРЭЭЮХ аРЧСШХЭШХ Т @_ ЭХ ЯЮФФХаЦШТРХвбп.
Б. <$R[P#,R7-112]>. <$M[R7-111]>І Perl4 ЯЮФФХаЦШТРХвбп ЮбЮСРп аРЧЭЮТШФЭЮбвм ЮЯХаРвЮаР split: ХбЫШ Т ЮЯХаРвЮаХ ЯЮШбЪР Т бЯШбЪЮТЮЬ ЪЮЭвХЪбвХ ШбЯЮЫмЧгХвбп ЪЮЭбвагЪжШп ?…? (ЭЮ ЭХ m?…?), split ЧРЯЮЫЭпХв @_ вРЪ, ЪРЪ нвЮ ФХЫРХвбп Т бЯШбЪЮТЮЬ ЪЮЭвХЪбвХ. І Perl5 ФРЭЭРп ТЮЧЬЮЦЭЮбвм ЭХ ЯЮФФХаЦШТРХвбп, еЮвп Т ФЮЪгЬХЭвРжШШ гвТХаЦФРХвбп ЮСаРвЭЮХ.
Б. <$R[P#,R7-114]>. <$M[R7-113]>І Perl4 бЯХжШРЫмЭРп ШЭвХаЯаХвРжШп аРбЯаЮбваРЭпХвбп Ш ЭР ТлаРЦХЭШп (ЭРЯаШЬХа, ТлЧЮТл дгЭЪжШШ), ТлзШбЫХЭШХ ЪЮвЮале ФРХв бЪРЫпаЭлЩ аХЧгЫмвРв Т ТШФХ ЮФШЭЮзЭЮУЮ ЯаЮСХЫР. І Perl5 бЯХжШРЫмЭРп ШЭвХаЯаХвРжШп аРбЯаЮбваРЭпХвбп ЫШим ЭР ЫШвХаРЫмЭлХ бваЮЪШ, бЮбвЮпйШХ ШЧ ЮФЭЮУЮ ЯаЮСХЫР.
Б. <$R[P#,R7-116]>. <$M[R7-115]>І Perl4 ЯЮ гЬЮЫзРЭШо ТЬХбвЮ 'spc' ШбЯЮЫмЧгХвбп ЮЯХаРЭФ m/\s+/. ѕвЫШзШХ ТЫШпХв ЭР ЮСаРСЮвЪг ЭРзРЫмЭле ЯаЮЯгбЪЮТ.
Б. <$R[P#,R7-121]>. <$M[R7-120]>І Perl4 ЪЮЯШаЮТРЭШХ ЯаШ ЪРЦФЮЬ гбЯХиЭЮЬ бЮТЯРФХЭШШ вРЪЦХ ЯаЮШбеЮФШв Т вЮЬ бЫгзРХ, ХбЫШ УФХ-ЫШСЮ Т ЯаЮУаРЬЬХ ШбЯЮЫмЧгХвбп eval.
[1] ЅХФЮбвгЯХЭ ФЮ ТХабШШ 5.000.
[2] їЮФФХаЦШТРХвбп, ЭРзШЭРп б ТХабШШ 5.000.
[3] їЮФФХаЦШТРХвбп, ЭРзШЭРп б ТХабШШ 5.000.
[4] ЅРФХЦЭЮ ЯЮФФХаЦШТРХвбп, ЭРзШЭРп б ТХабШШ 5.002.
[5] їЮФФХаЦШТРовбп, ЭРзШЭРп б ТХабШШ 5.000.
[6] \b — пЪЮаЭлЩ ЬХвРбШЬТЮЫ ТЭХ бШЬТЮЫмЭЮУЮ ЪЫРббР, бЮЪаРйХЭЭЮХ ЮСЮЧЭРзХЭШХ бШЬТЮЫР ТЭгваШ ЪЫРббР.
[7] їЮФФХаЦШТРХвбп, ЭРзШЭРп б ТХабШШ 5.000.
[8] їЮФФХаЦШТРХвбп, ЭРзШЭРп б ТХабШШ 5.000.
[9] \b — пЪЮаЭлЩ ЬХвРбШЬТЮЫ ТЭХ бШЬТЮЫмЭЮУЮ ЪЫРббР, бЮЪаРйХЭЭЮХ ЮСЮЧЭРзХЭШХ бШЬТЮЫР ТЭгваШ ЪЫРббР.
[10] їЮФФХаЦШТРовбп, ЭРзШЭРп б ТХабШШ 5.000.
[11] І Perl бШвгРжШп ЭХ бвЮЫм ЮФЭЮЧЭРзЭРп, ЯЮбЪЮЫмЪг дгЭЪжШШ Ш ЯаЮжХФгал вЮЦХ ЬЮУгв ЯЮЫгзРвм бТХФХЭШп Ю ЪЮЭвХЪбвХ ТлЧЮТР Ш ФРЦХ ЬЮФШдШжШаЮТРвм бТЮШ РаУгЬХЭвл. П ЯлвРобм ЯаЮТХбвШ УаРЭШжг ЬХЦФг ЮЯХаРвЮаРЬШ Ш дгЭЪжШпЬШ, звЮСл ЮбЮСЮ ТлФХЫШвм ЭХЪЮвЮалХ еРаРЪвХаШбвШЪШ, ШЧ-ЧР ЪЮвЮале зРбвЮ ТЮЧЭШЪРов ЭХФЮаРЧгЬХЭШп.
[12] АРСЮвРХв б $_, ХбЫШ жХЫХТРп бваЮЪР ЭХ ЧРФРХвбп ЯаШ ЯЮЬЮйШ =~ ШЫШ !~.
[13] АРСЮвРХв б $_, ХбЫШ жХЫХТРп бваЮЪР ЭХ ЧРФРХвбп ЯаШ ЯЮЬЮйШ =~ ШЫШ !~.
[14] їЮФФХаЦШТРХвбп, ЭРзШЭРп б ТХабШШ 5.000.
[15] їЮФФХаЦШТРХвбп, ЭРзШЭРп б ТХабШШ 5.000.
[16] їЮФФХаЦШТРХвбп, ЭРзШЭРп б ТХабШШ 5.000.
[17] БЬ. http://tpj.com/ ШЫШ staff@tpj.com.
[18] ЅХ еЮзг ЯаЮвШТЮаХзШвм бХСХ, ЭЮ п ФЮЫЦХЭ бЮЮСйШвм, звЮ ЭР ЬЮЬХЭв ЭРЯШбРЭШп ЪЭШУШ Т дгЭЪжШШ quotewords бЮФХаЦРЫШбм ЮиШСЪШ. НвР дгЭЪжШп ЯаЮЯгбЪРХв ЯЮбЫХФЭХХ ЯЮЫХ, ХбЫШ ЮЭЮ аРТЭЮ зШбЫг 0, ЭХ аРбЯЮЧЭРХв ЧРТХаиРойШХ ЯгбвлХ бваЮЪШ, Р ЯЮЫп Т ЪРТлзЪРе ЭХ ЬЮУгв бЮФХаЦРвм нЪаРЭШаЮТРЭЭле бШЬТЮЫЮТ (ЪаЮЬХ нЪаРЭШаЮТРЭЭле ЪРТлзХЪ). єаЮЬХ вЮУЮ, ЮЭР ЮваШжРвХЫмЭЮ ТЫШпХв ЭР нддХЪвШТЭЮбвм ТбХУЮ бжХЭРаШп (б. <$R[P#,R7-129]>). П бТпЧРЫбп б РТвЮаЮЬ, Ш нвШ ЮиШСЪШ, ТХаЮпвЭЮ, СгФгв ШбЯаРТЫХЭл Т СгФгйШе ТХабШпе.
[19] І ФХЩбвТШвХЫмЭЮбвШ аРЭмиХ, ЭЮ Т вХе ТХабШпе ЮЭЮ аРСЮвРЫЮ ЭХЭРФХЦЭЮ.
[20] АРЧгЬХХвбп, аХзм ШФХв ЮС ЮаШУШЭРЫХ — їаШЬХз. ЯХаХТ.
[21] АРЭмиХ бЯШбЪЮТлЩ ЪЮЭвХЪбв ЭРЧлТРЫбп «ЪЮЭвХЪбвЮЬ ЬРббШТР». ёЧЬХЭХЭШХ бТпЧРЭЮ б вХЬ, звЮ ФРЭЭлХ Т нвЮЬ ЪЮЭвХЪбвХ ЬЮУгв ЮвЭЮбШвмбп Ъ ЬРббШТг, ениг Ш бЯШбЪг б пТЭлЬ ЯХаХзШбЫХЭШХЬ.
[22] Perl ЯЮЧТЮЫпХв ЮСкХФШЭпвм ШЬХЭР УЫЮСРЫмЭле ЯХаХЬХЭЭле Т УагЯЯл, ЭРЧлТРХЬлХ ЯРЪХвРЬШ, ЭЮ ЯХаХЬХЭЭлХ ТбХ аРТЭЮ ЮбвРовбп УЫЮСРЫмЭлЬШ.
[23] Perl ЭХ ЯЮЧТЮЫпХв ШбЯЮЫмЧЮТРвм my б ШЬХЭРЬШ бЯХжШРЫмЭле ЯХаХЬХЭЭле, ЯЮнвЮЬг баРТЭХЭШХ зШбвЮ вХЮаХвШзХбЪЮХ.
[24] єРЪ гЯЮЬШЭРЫЮбм ТлиХ, ЯЮЬХвЪР [1 б. <$R[P#,R7-37]>] ЮвЭЮбШвбп Ъ ЯаШЬХзРЭШо 1 ФЫп Perl4, ЭРеЮФпйХЬгбп ЭР б. <$R[P#,R7-37]>.
[25] І ФХЩбвТШвХЫмЭЮбвШ, ХбЫШ ШбеЮФЭлЩ вХЪбв ЯаХФбвРТЫпХв бЮСЮЩ ЯХаХЬХЭЭго б ЭХЮЯаХФХЫХЭЭлЬ ЧЭРзХЭШХЬ, ЭЮ бЮТЯРФХЭШХ СгФХв гбЯХиЭЮ ЭРЩФХЭЮ (ЬРЫЮТХаЮпвЭРп, ЭЮ ТЮЧЬЮЦЭРп бШвгРжШп), аХЧгЫмвРв "$`$&$'" СгФХв ЯаХФбвРТЫпвм бЮСЮЩ Ягбвго бваЮЪг, Р ЭХ ЭХЮЯаХФХЫХЭЭго ТХЫШзШЭг. НвЮ ХФШЭбвТХЭЭЮХ ШбЪЫозХЭШХ ШЧ нвЮУЮ ЯаРТШЫР.
[26] ЅР аШб. 7.1 ШЧЮСаРЦХЭР ЬЮФХЫм, ЮЯШблТРойРп ЬЭЮУЮгаЮТЭХТлЩ ЯаЮжХбб ЮСаРСЮвЪШ аХУгЫпаЭле ТлаРЦХЭШЩ Т Perl. ЗШвРвХЫШ, аРЧСШаРойШХбп ТЮ ТЭгваХЭЭХЬ гбваЮЩбвТХ Perl, ЧРЬХвпв, звЮ Т ФХЩбвТШвХЫмЭЮбвШ ЮСаРСЮвЪР ЮаУРЭШЧЮТРЭР ЭХбЪЮЫмЪЮ ШЭРзХ. ЅРЯаШЬХа, вЮ, звЮ п ЭРЧлТРо дРЧЮЩ C, Т ФХЩбвТШвХЫмЭЮбвШ пТЫпХвбп ЭХ ЮвФХЫмЭлЬ нвРЯЮЬ, Р бЮбвРТЭЮЩ зРбвмо дРЧ B Ш D.
јЭХ ЯЮЪРЧРЫЮбм, звЮ ТлФХЫХЭШХ нвЮЩ ЮЯХаРжШШ Т ЮвФХЫмЭго дРЧг ФХЫРХв ЪРавШЭг СЮЫХХ ЭРУЫпФЭЮЩ, ЯЮнвЮЬг п вРЪ Ш ЯЮбвгЯШЫ (ЭР ТлаРСЮвЪг ЬЮФХЫШ, ЯЮЪРЧРЭЭЮЩ ЭР аШб. 7.1, ЬЭХ ЯЮваХСЮТРЫЮбм ФЮТЮЫмЭЮ ЬЭЮУЮ ТаХЬХЭШ — ЭРФХобм, ЮЭР ТРЬ ЯаШУЮФШвбп). ВХЬ ЭХ ЬХЭХХ, Т ЬРЫЮТХаЮпвЭЮЩ бШвгРжШШ, ЪЮУФР ЪЮЬЬХЭвРаШЩ бЮФХаЦШв бблЫЪШ ЭР ЯХаХЬХЭЭлХ, ЯЮТХФХЭШХ ЬЮХЩ ЬЮФХЫШ ЧРЬХвЭЮ ЮвЪЫЮЭпХвбп Юв аХРЫмЭЮбвШ.
АРббЬЮваШЬ ЮЯХаРвЮа ТШФР m/regex #comment $var/. І ЬЮХЩ ЬЮФХЫШ $var ШЭвХаЯЮЫШагХвбп Т ЮЯХаРЭФ Т дРЧХ B, Ш аХЧгЫмвРвл ШЭвХаЯЮЫпжШШ гФРЫповбп б ЮбвРвЪЮЬ ЪЮЬЬХЭвРаШп Т дРЧХ C. ЅР І ФХЩбвТШвХЫмЭЮбвШ ЪЮЬЬХЭвРаШЩ Ш бблЫЪР ЭР ЯХаХЬХЭЭго СгФгв гФРЫХЭл Т дРЧХ B ХйХ ФЮ ШЭвХаЯЮЫпжШШ ЯХаХЬХЭЭЮЩ. НвЮ ЯаШТЮФШв Ъ вЮЬг ЦХ ЪЮЭХзЭЮЬг аХЧгЫмвРвг… ЯЮзвШ ТбХУФР. µбЫШ ЯХаХЬХЭЭРп, Ю ЪЮвЮаЮЩ ШФХв аХзм, бЮФХаЦШв бШЬТЮЫ ЭЮТЮЩ бваЮЪШ, нвЮв бШЬТЮЫ ЭХ СгФХв ШЭвХаЯаХвШаЮТРвмбп ЪРЪ ЯаШЧЭРЪ ЪЮЭжР ЪЮЬЬХЭвРаШп, ЪРЪ ТШФЭЮ ШЧ ЬЮХЩ ЬЮФХЫШ. єаЮЬХ вЮУЮ, ЯаЮЯРФРов ТбХ ЯЮСЮзЭлХ нддХЪвл ШЭвХаЯЮЫпжШШ ЯХаХЬХЭЭЮЩ (ТлЧЮТл дгЭЪжШЩ Ш в. Ф.), ЯЮбЪЮЫмЪг ЭР бРЬЮЬ ФХЫХ ЯХаХЬХЭЭРп ЭХ ШЭвХаЯЮЫШагХвбп.
ІЯаЮзХЬ, ЮЯШбРЭЭлХ бШвгРжШШ ТбваХзРовбп аХФЪЮ Ш ТлУЫпФпв ЭХХбвХбвТХЭЭЮ. Іл ЯЮзвШ ЭРТХаЭпЪР ЭШЪЮУФР ЭХ бвЮЫЪЭХвХбм б ЭШЬШ, ЭЮ п аХиШЫ, звЮ Ю ЭШе ЯЮ ЪаРЩЭХЩ ЬХаХ бЫХФгХв гЯЮЬпЭгвм.
[27] їЮФФХаЦШТРовбп, ЭРзШЭРп б Perl5.
[28] їЮ дЮаЬХ ЧРЯШбШ ЭШзХЬ ЭХ ЮвЫШзРХвбп Юв ЯаХФлФгйХУЮ ЪТРЭвШдШЪРвЮаР. ѕСХ ТХабШШ РСбЮЫовЭЮ ШФХЭвШзЭл Ш аРЧЫШзРовбп вЮЫмЪЮ ЯЮ нддХЪвШТЭЮбвШ — Ше бЮТЬХбвЭЮХ бгйХбвТЮТРЭШХ ЮСкпбЭпХвбп ЫШим гФЮСбвТЮЬ ЧРЯШбШ Ш ХХ ЫЮУШзЭЮбвмо.
[29] µйХ ЫгзиХ СлЫЮ Сл ШбЯЮЫмЧЮТРвм ШЬХЭЮТРЭЭлХ ЯЮФТлаРЦХЭШп ТаЮФХ вХе, ЪЮвЮалХ ЯЮФФХаЦШТРовбп Т Python ЯаШ ЯЮЬЮйШ ШЬХЭ бШЬТЮЫШзХбЪШе УагЯЯ, ЮФЭРЪЮ Т Perl вРЪРп ТЮЧЬЮЦЭЮбвм ЭХ ЯЮФФХаЦШТРХвбп… ЯЮЪР.
[30] БгйХбвТгов аРЧЭлХ ТРаШРЭвл аХРЫШЧРжШШ «[this] Ш [that]» Ш бвЮЫмЪЮ ЦХ бЯЮбЮСЮТ баРТЭХЭШп нвШе ТРаШРЭвЮТ. єРЪ ЯаРТШЫЮ, УЫРТЭлЬШ дРЪвЮаРЬШ ЯаШ баРТЭХЭШШ пТЫпХвбп вЮзЭЮХ ЯЮЭШЬРЭШХ вЮУЮ, звЮ ЦХ ШЬХЭЭЮ бЮТЯРФРХв, нддХЪвШТЭЮбвм ЯЮШбЪР Ш ЭРУЫпФЭЮбвм. П ЭРЯШбРЫ ФЫп РТУгбвЮТбЪЮУЮ ЭЮЬХаР «The Perl Journal» ЧР 1996 УЮФ бвРвмо б ЯЮФаЮСЭлЬ РЭРЫШЧЮЬ нвЮЩ вХЬл. ЅРФХобм, нвР бвРвмп ФРбв ТРЬ ФЮЯЮЫЭШвХЫмЭго ШЭдЮаЬРжШо Ю вЮЬ, ЪРЪЮЩ ЦХ аХРЫмЭлЩ бЬлбЫ бвЮШв ЧР ЮЯХаРжШпЬШ, ТлЯЮЫЭпХЬлЬШ ЬХеРЭШЧЬЮЬ. єбвРвШ УЮТЮап, ЯаШТХФХЭЭЮХ ЧФХбм ШЧЮСаХвРвХЫмЭЮХ аХиХЭШХ п ЯЮЫгзШЫ Юв АнЭФРЫР ИТРажР (Randal Schwartz), Ш ЯаШ вХбвШаЮТРЭШШ ЮЭЮ ЯЮЪРЧРЫЮ ФЮТЮЫмЭЮ ТлбЮЪШХ аХЧгЫмвРвл.
[31] єЮЬЬХЭвРаШШ (?#…) гФРЫповбп ЭР ЮзХЭм аРЭЭХЩ бвРФШШ ЮСаРСЮвЪШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп, УФХ-вЮ ЬХЦФг дРЧРЬШ A Ш B ЭР аШб. 7.1 (б. <$R[P#,R7-117]>). ёЭвХаХбЭлЩ дРЪв: ЭРбЪЮЫмЪЮ ЬЭХ ШЧТХбвЭЮ, ЧРЪалТРойРп ЪагУЫРп бЪЮСЪР ЪЮЬЬХЭвРаШп (?#…) пТЫпХвбп ХФШЭбвТХЭЭлЬ нЫХЬХЭвЮЬ пЧлЪР аХУгЫпаЭле ТлаРЦХЭШЩ Perl, ЪЮвЮалЩ ЭХ ЬЮЦХв нЪаРЭШаЮТРвмбп. їХаТРп ЧРЪалТРойРп ЪагУЫРп бЪЮСЪР ЯЮбЫХ (?# ЮФЭЮЧЭРзЭЮ ЧРЪРЭзШТРХв ЪЮЬЬХЭвРаШЩ.
[32] ·ЭРЪ $ вРЪЦХ ЬЮЦХв Слвм ЯаШЧЭРЪЮЬ ШЭвХаЯЮЫпжШШ ЯХаХЬХЭЭЮЩ, ЮФЭРЪЮ ХУЮ ШЭвХаЯаХвРжШп аХФЪЮ ТлЧлТРХв ЪРЪШХ-ЫШСЮ ЭХЮФЭЮЧЭРзЭЮбвШ. їЮФаЮСЭЮбвШ ЯаШТХФХЭл Т аРЧФХЫХ «їаХФТРаШвХЫмЭРп ЮСаРСЮвЪР Ш ШЭвХаЯЮЫпжШп ЯХаХЬХЭЭле» (б. <$R[P#,R7-130]>).
[33] БваЮУЮ УЮТЮап, Т ФТге ЬЭЮУЮбваЮзЭле аХЦШЬРе ЮЯвШЬШЧРжШп ЯЮ УаРЭШжХ ЫЮУШзХбЪШе бваЮЪ бвРЭЮТШвбп згвм ЬХЭХХ нддХЪвШТЭЮЩ, ЯЮбЪЮЫмЪг ЬХеРЭШЧЬ бЬХйХЭШп вХЪгйХЩ ЯЮЧШжШШ ФЮЫЦХЭ ЯаШЬХЭпвм аХУгЫпаЭЮХ ТлаРЦХЭШХ ЯЮбЫХ ЪРЦФЮУЮ ТЭгваХЭЭХУЮ бШЬТЮЫР ЭЮТЮЩ бваЮЪШ (б. <$R[P#,R5-3]>).
[34] ЅХСЮЫмиЮХ ЧРЬХзРЭШХ, ЭХ бТпЧРЭЭЮХ б аХУгЫпаЭлЬШ ТлаРЦХЭШпЬШ. БгйХбвТгХв аРбЯаЮбваРЭХЭЭЮХ ЧРСЫгЦФХЭШХ, СгФвЮ ЯаШбТРШТРЭШХ $/ ЧЭРзХЭШп undef ЧРбвРТЫпХв бЫХФгойго ЪЮЭбвагЪжШо <> ТХаЭгвм «ТХбм ЮбвРвЮЪ ТТЮФР» (ШЫШ ХбЫШ ЮЭР ШбЯЮЫмЧгХвбп Т ЭРзРЫХ бжХЭРаШп — ТХбм ТТЮФ). І вХаЬШЭХ «аХЦШЬ ЯЮУЫЮйХЭШп дРЩЫР» ЪЫозХТлЬ пТЫпХвбп бЫЮТЮ дРЩЫ. µбЫШ ТеЮФЭлХ ФРЭЭлХ бЮбвЮпв ШЧ ЭХбЪЮЫмЪШе дРЩЫЮТ, ФЫп ЪРЦФЮУЮ дРЩЫР ЯЮЭРФЮСШвбп ЮвФХЫмЭлЩ ТлЧЮТ <>. µбЫШ Тл ФХЩбвТШвХЫмЭЮ еЮвШвХ ЯЮЫгзШвм ТХбм ТТЮФ, ТЮбЯЮЫмЧгЩвХбм ЪЮЭбвагЪжШХЩ join('',<>).
[35] НвШ ФТХ аРЧЭЮТШФЭЮбвШ ЬХвРбШЬТЮЫЮТ ЭХ пТЫповбп ТЧРШЬЮШбЪЫозРойШЬШ. БЪРЦХЬ, Т GNU Emacs ЯЮФФХаЦШТРовбп ЮСР вШЯР.
[36] їаШзХЬ Т ЯЮбЫХФЭШЩ аРЧ — ЪРЪ аРЧ ЯХаХФ вХЬ, ЪРЪ п аХиШЫ ТЪЫозШвм Т ЪЭШУг нвЮв аРЧФХЫ!
[37] І вРСЫШжг ЭХ ТеЮФШв бШЬТЮЫ [\v] (ТХавШЪРЫмЭРп вРСгЫпжШп). І вХзХЭШХ ЭХбЪЮЫмЪШе ЫХв нвЮв бШЬТЮЫ ЮЯШблТРЫбп Т бваРЭШжРе агЪЮТЮФбвТР Ш Т ЯаЮзХЩ ФЮЪгЬХЭвРжШШ, ЭЮ ЮЭ вРЪ Ш ЭХ СлЫ ТЪЫозХЭ Т пЧлЪ! їЮЫРУРо, вХЯХам, ЪЮУФР бШЬТЮЫ ТХавШЪРЫмЭЮЩ вРСгЫпжШШ СлЫ гСаРЭ ШЧ ФЮЪгЬХЭвРжШШ, ЭШЪвЮ ЭХ ЯЮЦРЫХХв Ю ЭХЬ.
[38] ґЫп ЯаЮУаРЬЬШаЮТРЭШп ЭР Perl п ЮСлзЭЮ ШбЯЮЫмЧго GNU Emacs Т аХЦШЬХ cperl-mode, ЮСХбЯХзШТРойХЬ РТвЮЬРвШзХбЪго аРббвРЭЮТЪг ЮвбвгЯЮТ Ш жТХвЮТЮХ ТлФХЫХЭШХ. П зРбвЮ нЪаРЭШаго ЪРТлзЪШ Т аХУгЫпаЭле ТлаРЦХЭШпе, ЯЮбЪЮЫмЪг Т ЯаЮвШТЭЮЬ бЫгзРХ ЮЭШ бСШТРов б вЮЫЪг аХЦШЬ cperl-mode, ЭХ ЯЮЭШЬРойШЩ, звЮ ЪРТлзЪШ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ ЭХ пТЫповбп ЭРзРЫЮЬ бваЮЪ.
[39] µбЫШ \E ЮвбгвбвТгХв — вЮ ФЮ ЪЮЭжР бваЮЪШ ШЫШ аХУгЫпаЭЮУЮ ТлаРЦХЭШп.
[40] І Perl5 ШУЭЮаШагХвбп Т ЪЮЭбвагЪжШпе \L…\E Ш \U…\E, ХбЫШ вЮЫмЪЮ ЭХ бЫХФгХв ЭХЯЮбаХФбвТХЭЭЮ ЧР \L Ш \U.
[41] їЮбЪЮЫмЪг ЬЮФШдШЪРвЮал ЮЯХаРвЮаР ЯЮШбЪР ЬЮУгв бЫХФЮТРвм Т ЫоСЮЬ ЯЮапФЪХ, ЯаЮУаРЬЬШбвл зРбвЮ ваРвпв ЭХЬРЫЮ ТаХЬХЭШ ЭР вЮ, звЮСл ФЮСШвмбп ЭРШСЮЫмиХЩ ТлаРЧШвХЫмЭЮбвШ. ЅРЯаШЬХа, learn/by/osmosis пТЫпХвбп ФЮЯгбвШЬЮЩ ЪЮЬРЭФЮЩ (ЯаШ гбЫЮТШШ, звЮ г ТРб ШЬХХвбп дгЭЪжШп learn). БЫЮТЮ osmosis бЮбвРТЫХЭЮ ШЧ ЬЮФШдШЪРвЮаЮТ — ЯЮТвЮаХЭШХ ЬЮФШдШЪРвЮаЮТ ЮЯХаРвЮаР ЯЮШбЪР (ЭЮ ЭХ ЬЮФШдШЪРвЮаР /e ЮЯХаРвЮаР ЯЮФбвРЭЮТЪШ!) ФЮЯгбЪРХвбп, еЮвп Ш ЭХ ШЬХХв бЬлбЫР.
[42] П СЫРУЮФРаХЭ ЕРЭбг јРЫФХаг (Hans Mulder), ЯаХФЮбвРТШТиХЬг ШбвЮаШзХбЪШХ бТХФХЭШп ЯЮ нвЮЬг ТЮЯаЮбг, Р вРЪЦХ АнЭФРЫг ЧР ХУЮ згТбвТЮ оЬЮаР.
[43] µбЫШ Тл вЮЦХ ЧРеЮвШвХ гЧЭРвм, бЪЮЫмЪЮ ФЭХЩ ЮбвРЫЮбм ФЮ ЬЮХУЮ ФЭп аЮЦФХЭШп, ЧРУагЧШвХ бваРЭШжг
http://omrongw.wg.omron.co.jp/cgi-bin/j-e/jfriedl.html
ШЫШ ЮФЭг ШЧ ЧХаЪРЫмЭле бваРЭШж (бЬ. ЯаШЫЮЦХЭШХ °).
[44] БгйХбвТгХв ЮФШЭ ЮбЮСлЩ бЫгзРЩ, ЪЮУФР нвЮ ЭХ бЮЮвТХвбвТгХв ШбвШЭХ. ѕЭ ЮЯШбРЭ ЭШЦХ, ЯаШ аРббЬЮваХЭШШ ЭХваШТШРЫмЭЮУЮ ШбЯЮЫмЧЮТРЭШп ЯХаТЮУЮ ЮЯХаРЭФР split.
[45] ІЮЧЬЮЦЭЮ, Тл гЧЭРЫШ зРбвШзЭЮ аРбЪагзХЭЭго ТХабШо [<("[^>"]*"|[^>"])*>], УФХ ЭЮаЬРЫмЭлЬ нЫХЬХЭвЮЬ пТЫпХвбп [[^>"]], Р бЯХжШРЫмЭлЬ — ["[^"]*"]. єЮЭХзЭЮ, Тл ЬЮЦХвХ бРЬЮбвЮпвХЫмЭЮ ЯаЮТХбвШ ФЮЯЮЫЭШвХЫмЭго аРбЪагвЪг бЯХжШРЫмЭЮУЮ нЫХЬХЭвР.
[46] їЮ ЭХШЧТХбвЭлЬ ЬЭХ ЯаШзШЭРЬ Т Perl4 ШбеЮФЭЮХ ТлаРЦХЭШХ аРСЮвРХв СлбваХХ ТбХе ЮбвРЫмЭле. ІЯаЮзХЬ, п ЭХ ЬЮУ вХбвШаЮТРвм аХиХЭШп б ЬЮФШдШЪРвЮаЮЬ /e, ЯЮбЪЮЫмЪг гвХзЪР ЯРЬпвШ Т Perl4 ФХЫРЫР аХЧгЫмвРв СХббЬлбЫХЭЭлЬ.
[47] ВЮзЭХХ, ЭХ ТеЮФШЫШ Сл, ХбЫШ Сл Т ЯаШаЮФХ бгйХбвТЮТРЫР бЯХжШдШЪРжШп Perl.
[48] БЮеаРЭпойШХ ЪагУЫлХ бЪЮСЪШ вРЪЦХ ЬЮУгв ШбЯЮЫмЧЮТРвмбп Т ЮСаРвЭле бблЫЪРе, ЯЮнвЮЬг бгйХбвТгХв ТХаЮпвЭЮбвм вЮУЮ, звЮ бЮеаРЭпойШХ ЪагУЫлХ бЪЮСЪШ СгФгв ШбЯЮЫмЧЮТРвмбп СХЧ ЯаШЬХЭХЭШп $1 Ш ФагУШе ЯХаХЬХЭЭле. ЅР ЯаРЪвШЪХ ЯЮФЮСЭлХ бШвгРжШШ ТбваХзРовбп аХФЪЮ.
[49] ЅР бРЬЮЬ ФХЫХ п ЭХ ФЮЦФРЫбп ЪЮЭжР вХбвШаЮТРЭШп. ЅР ЮбЭЮТРЭШШ ФагУШе вХбвЮТ п ТлзШбЫШЫ, звЮ ТлЯЮЫЭХЭШХ ЯаЮУаРЬЬл ФЮЫЦЭЮ ЧРЭШЬРвм ЯаШЬХаЭЮ 36,4 зРбР. ІЯаЮзХЬ, ХбЫШ еЮвШвХ — ЬЮЦХвХ ЯаЮТХаШвм.
[50] ЕЮвп ШЬХЭЭЮ нвЮ Ш ЯаЮШбеЮФШЫЮ Т ЯХаТЮЩ аХРЫШЧРжШШ grep!
[51] П ЬЮФШдШжШаЮТРЫ бТЮо ЪЮЯШо ТХабШШ 5.003 вРЪ, звЮСл ЯЮ ЬХаХ ТлЯЮЫЭХЭШп аРЧЭле ТЭгваХЭЭШе ЮЯХаРжШЩ ЮЭР ТлФРТРЫР ЬРббг ЪаРбШТле бЮЮСйХЭШЩ б жТХвЮТЮЩ ЪЮФШаЮТЪЮЩ. НвЮ ЯЮЧТЮЫШЫЮ ЬЭХ ЯаХФбвРТШвм ЪРавШЭг Т жХЫЮЬ, ЭХ ЮвТЫХЪРпбм ЭР ЬХЫЪШХ ФХвРЫШ.
[52] ІХаЮпвЭЮ, нвЮ ЧРЬХзРЭШХ ШЧЫШиЭХ. ІбЯЮЬЭШвХ: ЯаШбгвбвТШХ бЮеаРЭпойШе ЪагУЫле бЪЮСЮЪ Т аХУгЫпаЭЮЬ ТлаРЦХЭШШ РЪвШТШЧШагХв ЪЮЯШаЮТРЭШХ ФЫп ЯЮФФХаЦЪШ $&, Р нвЮ ЪЮЯШаЮТРЭШХ бРЬЮ ЯЮ бХСХ ЯЮФРТЫпХв ТбХ ЮЯвШЬШЧРжШШ ЧРЬХЭл. ° ШбЯЮЫмЧЮТРвм $1 СХЧ бЮеаРЭпойШе ЪагУЫле бЪЮСЮЪ УЫгЯЮ, ЯЮбЪЮЫмЪг ЧЭРзХЭШХ нвЮЩ ЯХаХЬХЭЭЮЩ ЧРТХФЮЬЮ СгФХв ЭХЮЯаХФХЫХЭЭлЬ (б. <$R[P#,R7-131]>)
[53] ІЮ ТбпЪЮЬ бЫгзРХ, вХЮаХвШзХбЪШ. І Perl ТХабШШ 5.003 ЯаШбгвбвТгХв ЮиШСЪР, ШЧ-ЧР ЪЮвЮаЮЩ ЯаШЬХЭХЭШХ study ЬЮЦХв ЯаШТХбвШ Ъ вЮЬг, звЮ ЬХеРЭШЧЬ аХУгЫпаЭле ТлаРЦХЭШЩ ЯХаХбвРХв ЭРеЮФШвм ЯаРТШЫмЭлХ бЮТЯРФХЭШп. НвР вХЬР аРббЬРваШТРХвбп ЭШЦХ.
[54] І вХЪгйХЩ аХРЫШЧРжШШ ШЬХХвбп ЮиШСЪР, ЪЮвЮаРп ЯаШТЮФШв Ъ ЯЮФРТЫХЭШо нвЮЩ ЮЯвШЬШЧРжШШ Т вХе бЫгзРпе, ЪЮУФР аХУгЫпаЭЮХ ТлаРЦХЭШХ ЭРзШЭРХвбп б ЫШвХаРЫмЭЮУЮ вХЪбвР. НвЮ ЮзХЭм ЮСШФЭЮ, ЯЮбЪЮЫмЪг ЮСлзЭЮ ШЬХЭЭЮ вРЪШХ ТлаРЦХЭШп ЮСХбЯХзШТРов ЭРШСЮЫмиШЩ ТлШУали Юв ЯаШЬХЭХЭШп study.
[55] Internet RFC 822. ґЮЪгЬХЭв ФЮбвгЯХЭ ЯЮ РФаХбг ftp://ftp.rfc-editor.org/in-notes/rfc822.txt.
[56] єЮЭХзЭЮ, ЮвЯаРТЫХЭЭРп ЯЮ нвЮЬг РФаХбг ЯЮзвР СгФХв ТЮЧТаРйХЭР ШЧ-ЧР ЮвбгвбвТШп РЪвШТЭЮУЮ ЯЮЫмЧЮТРвХЫп б вРЪШЬ ШЬХЭХЬ, ЭЮ нвЮ бЮТХаиХЭЭЮ ФагУЮЩ ТЮЯаЮб.
[57] їаЮУаРЬЬР, ЪЮвЮаго Ьл ЭРЯШиХЬ Т бЫХФгойХЬ аРЧФХЫХ, ШЬХХвбп ЭР ЬЮХЩ ФЮЬРиЭХЩ бваРЭШжХ — бЬ. ЯаШЫЮЦХЭШХ °.
[58] І бваЮЪРе, ЧРЪЫозХЭЭле Т РЯЮбваЮдл, \\ Ш нЪаРЭШаЮТРЭЭлЩ ЧРЪалТРойШЩ ЮУаРЭШзШвХЫм (ЮСлзЭЮ \') ШЬХов ЮбЮСлЩ бЬлбЫ. ґагУШХ нЪаРЭШаЮТРЭЭлХ бШЬТЮЫл ЯХаХФРовбп СХЧ ШЧЬХЭХЭШЩ, ЯЮнвЮЬг \040 ЮбвРХвбп \040.
[59] ІЮ ТаХЬп ШбеЮФЭЮУЮ вХбвШаЮТРЭШп ЬХЭп ЦФРЫ ЭХЯаШпвЭлЩ боаЯаШЧ — ЮЯвШЬШЧШаЮТРЭЭРп ТХабШп ЯаЮУаРЬЬл (бЬ. ЭШЦХ) ЯЮзХЬг-вЮ аРСЮвРЫР ЬХФЫХЭЭХХ ШбеЮФЭЮЩ. П СлЫ бЮТХаиХЭЭЮ ЯЮвапбХЭ, ЯЮЪР ЭХ ТлпбЭШЫЮбм, звЮ п ЧРСлЫ гЪРЧРвм ЬЮФШдШЪРвЮа /o! І аХЧгЫмвРвХ УаЮЬРФЭЮХ аХУгЫпаЭЮХ ТлаРЦХЭШХ-ЮЯХаРЭФ ЮСаРСРвлТРЫЮбм ЧРЭЮТЮ ФЫп ЪРЦФЮУЮ бЮТЯРФХЭШп (б. <$R[P#,R7-85]>). ѕЯвШЬШЧШаЮТРЭЭЮХ ТлаРЦХЭШХ ШЬХХв бгйХбвТХЭЭЮ СЮЫмиго ФЫШЭг, ЯЮнвЮЬг ФЮЯЮЫЭШвХЫмЭлХ ЧРваРвл ТаХЬХЭШ ЭР ЮСаРСЮвЪг ЯЮЫЭЮбвмо ЧРвЬХТРЫШ ТХбм ТлШУали Юв нддХЪвШТЭЮбвШ. їаШ ТЪЫозХЭШШ /o ЮЯвШЬШЧШаЮТРЭЭРп ТХабШп ЭХ вЮЫмЪЮ ЮСЮУЭРЫР ШбеЮФЭго, ЭЮ Ш ТХбм вХбв бвРЫ ТлЯЮЫЭпвмбп ЭР ЯЮапФЮЪ СлбваХХ.