6.3. How awk Works
Before getting into all the details of awk, let's look at how it does its job, step by step. We'll look at a simple three-line file called names:
Tom Savage 100
Molly Lee 200
John Doe 300
The awk command follows:
% nawk '{print $1, $3}' names
- 1. Awk takes a line of input (from a file or pipe) and puts the line into an internal variable called $0. Each line is also called a record and is terminated by a newline, by default.

- 2. Next, the line is broken into fields (words) separated by whitespace. Each field is stored in a numbered variable, starting with $1. There can be as many as 100 fields.
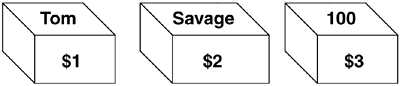
- 3. How does awk know that whitespace separates the fields? There is another internal variable, called FS, that designates the field separator. Initially, FS is assigned whitespacetabs and spaces. If the fields are separated by another character, such as a colon or dash, you can change the value of FS to designate the new field separator. (See "Field Separators" on page 169.)
- 4. When awk prints the fields, it uses the print function as follows:
{print $1,$3}
And the output shows each field separated by a space, as
Tom 100
Molly 200
John 300
Awk provides the space in the output between Tom and 100 for you because there is a comma placed between $1 and $3. The comma is special. It is mapped to another internal variable, called the output field separator (OFS). The OFS is assigned a space as its default. The comma generates whatever character has been assigned to the OFS variable.
- 5. After awk displays its output, it gets the next line in the file and stores that in $0, overwriting what was there. It then breaks that line into fields, and processes it. This continues until all the lines in the file have been processed.
|