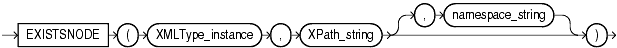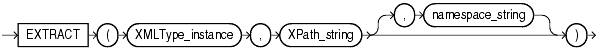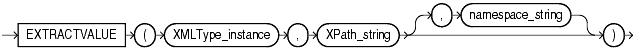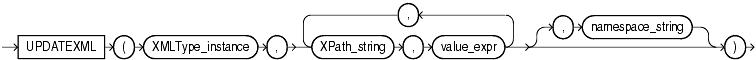| Oracle® XML DB Developer's Guide 10g Release 1 (10.1) Part Number B10790-01 |
|





|
View PDF |
| Oracle® XML DB Developer's Guide 10g Release 1 (10.1) Part Number B10790-01 |
|
|
View PDF |
This chapter describes XMLType operations and indexing for XML schema-based and non-schema-based applications. It includes guidelines for creating, manipulating, updating, querying, and indexing XMLType columns and tables.
This chapter contains these topics:
|
Note:
|
SQL functions such as existsNode(), extract(), XMLTransform(), and updateXML() operate on XML data inside SQL. XMLType datatype supports most of these as member functions.
You can query XML data from XMLType columns in the following ways:
By selecting XMLType columns through SQL, PL/SQL, or Java
By querying XMLType columns directly and using extract() and existsNode()
By using Oracle Text operators to query the XML content. See "Indexing XMLType Columns" and Chapter 9, " Full Text Search Over XML".
XPath is a W3C recommendation for navigating XML documents. XPath models the XML document as a tree of nodes. It provides a rich set of operations that walk the tree of nodes and also apply predicates and node test functions. Applying an XPath expression to an XML document can result in a set of nodes. For example, /PO/PONO selects all PONO child elements under the PO root element of the document.
Table 4-1 lists some common constructs used in XPath.
Table 4-1 Common XPath Constructs
| XPath Construct | Description |
|---|---|
| / |
Denotes the root of the tree in an XPath expression. For example, /PO refers to the child of the root node whose name is PO. |
| / |
Also used as a path separator to identify the children node of any given node. For example, /PurchaseOrder/Reference identifies the purchase order name element Reference, a child of the root element. |
| // |
Used to identify all descendants of the current node. For example, PurchaseOrder//ShippingInstructions matches any ShippingInstructions element under the PurchaseOrder element. |
| * |
Used as a wildcard to match any child node. For example, /PO/*/STREET matches any street element that is a grandchild of the PO element. |
| [ ] | Used to denote predicate expressions. XPath supports a rich list of binary operators such as OR, AND, and NOT. For example, /PO[PONO=20 and PNAME="PO_2"]/SHIPADDR select out the shipping address element of all purchase orders whose purchase order number is 20 and whose purchase order name is PO_2. [ ] is also used to denote an index into a list. For example, /PO/PONO[2] identifies the second purchase order number element under the PO root element. |
| Functions | XPath supports a set of built-in functions such as substring(), round(), and not(). In addition, XPath allows extension functions through the use of namespaces. In the Oracle namespace, http://xmlns.oracle.com/xdb, XML DB additionally supports the function ora:contains(). This functions behave just like the equivalent SQL function. |
The XPath must identify a single node, or a set of element, text, or attribute nodes. The result of the XPath cannot be a Boolean expression.
You can select XMLType data using PL/SQL, C, or Java. You can also use the SQL functions getClobVal(), getStringVal(), getNumberVal(), or getBlobVal(csid) functions to retrieve XML as a CLOB, VARCHAR, NUMBER, or BLOB, respectively.
Example 4-1 Selecting XMLType Columns using getClobVal()
This example shows how to select an XMLType column using getClobVal() in SQL*Plus:
set long 500
set pagesize 100
set linesize 132
--
create table XML_TABLE of XMLType;
Table created.
--
create table TABLE_WITH_XML_COLUMN(
FILENAME varchar2(64),
XML_DOCUMENT XMLType
);
Table created.
--
INSERT INTO XML_TABLE
VALUES
(
xmltype
(
bfilename('XMLDIR','purchaseOrder.xml'),
nls_charset_id('AL32UTF8')
)
);
1 row created.
--
INSERT INTO TABLE_WITH_XML_COLUMN (FILENAME, XML_DOCUMENT)
VALUES
(
'purchaseOrder.xml',
xmltype
(
bfilename('XMLDIR','purchaseOrder.xml'),
nls_charset_id('AL32UTF8')
)
);
1 row created.
--
select x.object_value.getCLOBVal()
from XML_TABLE x;
X.OBJECT_VALUE.GETCLOBVAL()
--------------------------------------------------------------------------------
<PurchaseOrder xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNames
paceSchemaLocation="http://localhost:8080/home/SCOTT/poSource/xsd/purchaseOrder.
xsd">
<Reference>SBELL-2002100912333601PDT</Reference>
<Actions>
<Action>
<User>SVOLLMAN</User>
</Action>
</Actions>
<Reject/>
<Requestor>Sarah J. Bell</Requestor>
<User>SBELL</User>
<CostCenter>S30</CostCenter>
<ShippingInstructions>
<name>Sarah J. Bell</name>
<address>400 Oracle Parkway
Redwood Shor
1 row selected.
--
select x.XML_DOCUMENT.getCLOBVal()
from TABLE_WITH_XML_COLUMN x;
X.XML_DOCUMENT.GETCLOBVAL()
--------------------------------------------------------------------------------
<PurchaseOrder xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNames
paceSchemaLocation="http://localhost:8080/home/SCOTT/poSource/xsd/purchaseOrder.
xsd">
<Reference>SBELL-2002100912333601PDT</Reference>
<Actions>
<Action>
<User>SVOLLMAN</User>
</Action>
</Actions>
<Reject/>
<Requestor>Sarah J. Bell</Requestor>
<User>SBELL</User>
<CostCenter>S30</CostCenter>
<ShippingInstructions>
<name>Sarah J. Bell</name>
<address>400 Oracle Parkway
Redwood Shor
1 row selected.
You can query XMLType data and extract portions of it using the existsNode(), extract(), or extractValue() functions. These functions use a subset of the W3C XPath recommendation to navigate the document.
Figure 4-1 and the following describes the syntax for the existsNode() XMLType function:
existsNode(XMLType_instance IN XMLType, XPath_string IN VARCHAR2, namespace_string IN varchar2 := null) RETURN NUMBER
The existsNode() XMLType function checks if the given XPath evaluation results in at least a single XML element or text node. If so, it returns the numeric value 1, otherwise, it returns a 0. The namespace parameter can be used to identify the mapping of prefix(es) specified in the XPath_string to the corresponding namespace(s).
Example 4-2 Using existsNode() on XMLType
The following example demonstrates how to use existsNode() on an XMLType instance in a query.
SELECT extract(object_value,'/PurchaseOrder/Reference') "REFERENCE" FROM PURCHASEORDER WHERE existsNode(object_value,'/PurchaseOrder[SpecialInstructions="Expidite"]') = 1
An XPath expression such as /PurchaseOrder/Reference results in a single node. Therefore, existsNode() will return 1 for that XPath. This is the same with /PurchaseOrder/Reference/text(), which results in a single text node.
An XPath expression such as /PO/POTYPE does not return any nodes. Therefore, an existsNode() on this would return the value 0.
To summarize, existsNode() member function can be used in queries and to create function-based indexes to speed up evaluation of queries.
The following example uses existsNode() to select rows with SpecialInstructions set to Expedite.
|
Note: When using theexistsNode() function in a query, always specify existsNode() in the WHERE clause as shown in this example, never in the SELECT list. |
Example 4-3 Using existsNode() to Find a node
SELECT object_value FROM PURCHASEORDER WHERE existsNode(object_value,'/PurchaseOrder[SpecialInstructions="Expidite"]') = 1; OBJECT_VALUE ---------------------------------------------------------------------------------- <PurchaseOrder xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" <PurchaseOrder xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" <PurchaseOrder xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" <PurchaseOrder xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" <PurchaseOrder xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" <PurchaseOrder xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" <PurchaseOrder xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" <PurchaseOrder xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" <PurchaseOrder xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" <PurchaseOrder xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" <PurchaseOrder xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" <PurchaseOrder xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" <PurchaseOrder xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 13 rows selected.
The extract() XMLType function is similar to the existsNode() function. It applies a VARCHAR2 XPath string with an optional namespace parameter and returns an XMLType instance containing an XML fragment. The syntax is described in Figure 4-2 and follows:
extract(XMLType_instance IN XMLType, XPath_string IN VARCHAR2,
namespace_string In varchar2 := null) RETURN XMLType;
extract() on XMLType extracts the node or a set of nodes from the document identified by the XPath expression. The extracted nodes can be elements, attributes, or text nodes. If multiple text nodes are referenced in the XPath, the text nodes are collapsed into a single text node value. Namespace can be used to supply namespace information for prefixes in the XPath string.
The XMLType resulting from applying an XPath through extract() need not be a well-formed XML document but can contain a set of nodes or simple scalar data. You can use the getStringVal() or getNumberVal() methods on XMLType to extract the scalar data.
For example, the XPath expression /PurchaseOrder/Reference identifies the PNAME element inside the XML document shown previously. The expression /PurchaseOrder/Reference/text(), on the other hand, refers to the text node of the Reference element.
|
Note: A text node is considered anXMLType. In other words, extract(object_value, '/PurchaseOrder/Reference/text()') still returns an XMLtype instance although the instance may actually contain only text. You can use getStringVal() to get the text value out as a VARCHAR2 result. |
Use text() node test function to identify text nodes in elements before using the getStringVal() or getNumberVal() to convert them to SQL data. Not having the text() node would produce an XML fragment.
For example, XPath expressions:
/PurchaseOrder/Reference identifies the fragment <Reference> ... </Reference>
/PurchaseOrder/Reference/text() identifies the value of the text node of the Reference element.
You can use the index mechanism to identify individual elements in case of repeated elements in an XML document. For example, if you have an XML document such as:
<PurchaseOrder xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation=
"http://localhost:8080/home/SCOTT/poSource/xsd/purchaseOrder.xsd">
<Reference>SBELL-2002100912333601PDT</Reference>
<Actions>
<Action>
<User>SVOLLMAN</User>
</Action>
</Actions>
<Reject/>
<Requestor>Sarah J. Bell</Requestor>
<User>SBELL</User>
<CostCenter>S30</CostCenter>
<ShippingInstructions>
<name>Sarah J. Bell</name>
<address>400 Oracle Parkway
Redwood Shores
CA
94065
USA</address>
<telephone>650 506 7400</telephone>
</ShippingInstructions>
<SpecialInstructions>Air Mail</SpecialInstructions>
<LineItems>
<LineItem ItemNumber="1">
<Description>A Night to Remember</Description>
<Part Id="715515009058" UnitPrice="39.95" Quantity="2"/>
</LineItem>
<LineItem ItemNumber="2">
<Description>The Unbearable Lightness Of Being</Description>
<Part Id="37429140222" UnitPrice="29.95" Quantity="2"/>
</LineItem>
<LineItem ItemNumber="3">
<Description>Sisters</Description>
<Part Id="715515011020" UnitPrice="29.95" Quantity="4"/>
</LineItem>
</LineItems>
</PurchaseOrder>
then you can use:
//LineItem[1] to identify the first LineItem element.
//LineItem[2] to identify the second LineItem element.
The result of extract() is always an XMLType. If applying the XPath produces an empty set, then extract() returns a NULL value.
To summarize, the extract() member function can be used in a number of ways. For example, to extract:
Numerical values on which function-based indexes can be created to speed up processing
Collection expressions for use in the FROM clause of SQL statements
Fragments for later aggregation to produce different documents
This example extracts the value of node, /Warehouse/Docks, of column, warehouse_spec in table oe.warehouses:
The following example uses extract() to query the value of the Reference column for orders with SpecialInstructions set to Expedite.
Example 4-4 Using extract() to Extract the Value of a Node
SELECT extract(object_value,'/PurchaseOrder/Reference') "REFERENCE" FROM PURCHASEORDER WHERE existsNode(object_value,'/PurchaseOrder[SpecialInstructions="Expidite"]') = 1; REFERENCE ------------------------------------------------------------ <Reference>AMCEWEN-20021009123336271PDT</Reference> <Reference>SKING-20021009123336321PDT</Reference> <Reference>AWALSH-20021009123337303PDT</Reference> <Reference>JCHEN-20021009123337123PDT</Reference> <Reference>AWALSH-20021009123336642PDT</Reference> <Reference>SKING-20021009123336622PDT</Reference> <Reference>SKING-20021009123336822PDT</Reference> <Reference>AWALSH-20021009123336101PDT</Reference> <Reference>WSMITH-20021009123336412PDT</Reference> <Reference>AWALSH-20021009123337954PDT</Reference> <Reference>SKING-20021009123338294PDT</Reference> <Reference>WSMITH-20021009123338154PDT</Reference> <Reference>TFOX-20021009123337463PDT</Reference> 13 rows selected.
|
Note: Functionsextract().getStringVal() and extractValue() differ in their treatment of entity encoding. Function extractValue() unescapes any encoded entities; extract().getStringVal() returns the data with entity encoding intact. |
The extractvalue() XMLType function takes as arguments an XMLType instance and an XPath expression. It returns a scalar value corresponding to the result of the XPath evaluation on the XMLType instance. Figure 4-3 describes the extractValue() syntax.
XML schema-based documents. For documents based on XML schema, if Oracle Database can infer the type of the return value, then a scalar value of the appropriate type is returned. Otherwise, the result is of type VARCHAR2.
Non- schema-based documents. If the extractValue() query can potentially be re-written, such as when the query is over a SQL/XML view, then a scalar value of the appropriate type is returned. Otherwise, the result is of type VARCHAR2.
The extractValue() function attempts to determine the proper return type from the XML schema of the document, or from other information such as the SQL/XML view. If the proper return type cannot be determined, then Oracle XML DB returns a VARCHAR2. With XML schema-based content, extractValue() returns the underlying datatype in most cases. For CLOB datatypes, it will return the CLOB directly.
If a specific datatype is desired, conversion functions such as to_char or to_date can be put around the extractValue() function call or around an extract.getStringVal(). This can help maintain consistency between different queries regardless of whether the queries can be rewritten.
extractValue() permits you to extract the desired value more easily than when using the equivalent extract() function. It is an ease-of-use and shortcut function. So instead of using:
extract(x,'path/text()').get(string|number)val()
you can replace extract().getStringVal() or extract().getnumberval() with extractValue() as follows:
extractValue(x, 'path/text()')
With extractValue() you can leave off the text(), but ONLY if the node pointed to by the 'path' part has only one child and that child is a text node. Otherwise, an error is thrown.
extractValue() has the same syntax as extract().
extractValue() has the following characteristics:
It always returns only scalar content, such as NUMBER, VARCHAR2, and so on.
It cannot return XML nodes or mixed content. It raises an error at compile or run time if it gets XML nodes as the result.
It always returns VARCHAR2 by default. If the node value is bigger than 4K, a runtime error occurs.
In the presence of XML schema information, at compile time, extractValue() can automatically return the appropriate datatype based on the XML schema information, if it can detect so at compile time of the query. For instance, if the XML schema information for the path /PO/POID indicates that this is a numerical value, then extractValue() returns a NUMBER.
If the extractValue() is on top of a SQL/XML view and the type can be determined at compile time, the appropriate type is returned.
If the XPath identifies a node, then it automatically gets the scalar content from its text child. The node must have exactly one text child. For example:
extractValue(xmlinstance, '/PurchaseOrder/Reference')
extracts out the text child of Reference. This is equivalent to:
extract(xmlinstance, '/PurchaseOrder/Reference/text()').getstringval()
Example 4–5 demonstrates usage of the extractValue() function. This query extracts the scalar value of the Reference column. This is in contrast to the extract() function shown in Example 4–4 where the entire <Reference> element is extracted.
Example 4-5 Extracting the Scalar Value of an XML Fragment Using extractValue()
SELECT extractValue(object_value,'/PurchaseOrder/Reference') "REFERENCE" FROM PURCHASEORDER WHERE existsNode(object_value,'/PurchaseOrder[SpecialInstructions="Expidite"]') = 1; REFERENCE ------------------------------------------------------------ AMCEWEN-20021009123336271PDT SKING-20021009123336321PDT AWALSH-20021009123337303PDT JCHEN-20021009123337123PDT AWALSH-20021009123336642PDT SKING-20021009123336622PDT SKING-20021009123336822PDT AWALSH-20021009123336101PDT WSMITH-20021009123336412PDT AWALSH-20021009123337954PDT SKING-20021009123338294PDT WSMITH-20021009123338154PDT TFOX-20021009123337463PDT 13 rows selected.
|
Note: Functionsextract().getStringVal() and extractValue() differ in their treatment of entity encoding. Function extractValue() unescapes any encoded entities; extract().getStringVal() returns the data with entity encoding intact. |
The following examples illustrate ways you can query XML data with SQL.
Example 4–6 inserts two rows into the PURCHASEORDER table and performs a query of data in those rows using extractValue().
Example 4-6 Querying XMLType Using extractValue() and existsNode()
INSERT INTO PURCHASEORDER
VALUES
(
xmltype
(
bfilename('XMLDIR','SMCCAIN-2002091213000000PDT.xml'),
nls_charset_id('AL32UTF8')
)
);
1 row created.
--
INSERT INTO PURCHASEORDER
VALUES
(
xmltype
(
bfilename('XMLDIR','VJONES-20020916140000000PDT.xml'),
nls_charset_id('AL32UTF8')
)
);
1 row created.
--
column REFERENCE format A32
column USERID format A8
column STATUS format A8
column STATUS_DATE format A12
set LINESIZE 132
--
SELECT extractValue(object_value,'/PurchaseOrder/Reference') REFERENCE,
extractValue(object_value,'/PurchaseOrder/*//User') USERID,
case
when existsNode(object_value,'/PurchaseOrder/Reject/Date') = 1
then 'Rejected'
else 'Accepted'
end "STATUS",
extractValue(object_value,'//Date') STATUS_DATE
FROM PURCHASEORDER
WHERE existsNode(object_value,'//Date') = 1
ORDER By extractValue(object_value,'//Date');
REFERENCE USERID STATUS STATUS_DATE
-------------------------------- -------- -------- ------------
VJONES-20020916140000000PDT SVOLLMAN Accepted 2002-10-11
SMCCAIN-2002091213000000PDT SKING Rejected 2002-10-12
2 rows selected.
Example 4–7 demonstrates using a cursor in PL/SQL to query XML data. A local XMLType instance is used to store transient data.
Example 4-7 Querying Transient XMLType Data
declare
xNode XMLType;
vText VARCHAR2(256);
vReference VARCHAR2(32);
cursor getPurchaseOrder (REFERENCE in VARCHAR2) is
SELECT object_value XML
FROM PURCHASEORDER
WHERE
EXISTSNODE(object_value,'/PurchaseOrder[Reference="'|| REFERENCE || '"]')
= 1;
begin
vReference := 'EABEL-20021009123335791PDT';
FOR c IN getPurchaseOrder(vReference)
LOOP
xNode := c.XML.extract('//Requestor');
vText := xNode.extract('//text()').getStringVal();
dbms_output.put_line(' The Requestor for Reference ' || vReference ||
' is '|| vText);
END LOOP;
vReference := 'PTUCKER-20021009123335430PDT';
FOR c IN getPurchaseOrder(vReference)
LOOP
xNode := c.XML.extract('//LineItem[@ItemNumber="1"]/Description');
vText := xNode.extract('//text()').getStringVal();
dbms_output.put_line(' The Description of LineItem[1] for Reference '
|| vReference || ' is '|| vText);
END LOOP;
end;/
The Requestor for Reference EABEL-20021009123335791PDT is Ellen S. Abel
The Description of LineItem[1] for Reference PTUCKER-20021009123335430PDT is Picnic at Hanging Rock
PL/SQL procedure successfully completed.
Example 4–8 shows how to extract data from an XML purchase order and insert it into a SQL relational table using the extract() function.
Example 4-8 Extracting Data From an XML Document and Inserting It Into a Table
create table PURCHASEORDER_TABLE(
REFERENCE VARCHAR2(28) PRIMARY KEY,
REQUESTER VARCHAR2(48),
ACTIONS XMLTYPE,
USERID VARCHAR2(32),
COSTCENTER VARCHAR2(3),
SHIPTONAME VARCHAR2(48),
ADDRESS VARCHAR2(512),
PHONE VARCHAR2(32),
REJECTEDBY VARCHAR2(32),
DATEREJECTED DATE,
COMMENTS VARCHAR2(2048),
SPECIALINSTRUCTIONS VARCHAR2(2048)
);
Table created.
create table PURCHASEORDER_LINEITEM(
REFERENCE,
FOREIGN KEY ("REFERENCE") REFERENCES "PURCHASEORDER_TABLE" ("REFERENCE") ON DELETE CASCADE,
LINENO NUMBER(10),
PRIMARY KEY ("REFERENCE","LINENO"),
UPC VARCHAR2(14),
DESCRIPTION VARCHAR2(128),
QUANTITY NUMBER(10),
UNITPRICE NUMBER(12,2)
);
Table created.
insert into PURCHASEORDER_TABLE(
REFERENCE,
REQUESTER,
ACTIONS,
USERID,
COSTCENTER,
SHIPTONAME,
ADDRESS,
PHONE,
REJECTEDBY,
DATEREJECTED,
COMMENTS,
SPECIALINSTRUCTIONS)
select x.object_value.extract('/PurchaseOrder/Reference/text()').getStringVal(),
x.object_value.extract('/PurchaseOrder/Requestor/text()').getStringVal(),
x.object_value.extract('/PurchaseOrder/Actions'),
x.object_value.extract('/PurchaseOrder/User/text()').getStringVal(),
x.object_value.extract('/PurchaseOrder/CostCenter/text()').getStringVal(),
x.object_value.extract('/PurchaseOrder/ShippingInstructions/name/text()').getStringVal(),
x.object_value.extract('/PurchaseOrder/ShippingInstructions/address/text()').getStringVal(),
x.object_value.extract('/PurchaseOrder/ShippingInstructions/telephone/text()').getStringVal(),
x.object_value.extract('/PurchaseOrder/Rejection/User/text()').getStringVal(),
x.object_value.extract('/PurchaseOrder/Rejection/Date/text()').getStringVal(),
x.object_value.extract('/PurchaseOrder/Rejection/Comments/text()').getStringVal(),
x.object_value.extract('/PurchaseOrder/SpecialInstructions/text()').getStringVal()
from PURCHASEORDER x
where x.object_value.existsNode('/PurchaseOrder[Reference="EABEL-20021009123336251PDT"]') = 1;
1 row created.
insert into PURCHASEORDER_LINEITEM(
REFERENCE,
LINENO,
UPC,
DESCRIPTION,
QUANTITY,
UNITPRICE)
select x.object_value.extract('/PurchaseOrder/Reference/text()').getStringVal(),
value(l).extract('/LineItem/@ItemNumber').getNumberVal(),
value(l).extract('/LineItem/Part/@Id').getNumberVal(),
value(l).extract('/LineItem/Description/text()').getStringVal(),
value(l).extract('/LineItem/Part/@Quantity').getNumberVal(),
value(l).extract('/LineItem/Part/@UnitPrice').getNumberVal()
from PURCHASEORDER x,
table (xmlsequence(value(x).extract('/PurchaseOrder/LineItems/LineItem'))) l
where existsNode(object_value,'/PurchaseOrder[Reference="EABEL-20021009123336251PDT"]') = 1;
3 rows created.
set linesize 132
column USERID format A8
column SPECIALINSTRUCTIONS format A32
column DESCRIPTION format A34
--
select REFERENCE, USERID, SHIPTONAME, SPECIALINSTRUCTIONS
from PURCHASEORDER_TABLE;
REFERENCE USERID SHIPTONAME SPECIALINSTRUCTIONS
-------------------------------- -------- ------------------------------------------------ -------------------
EABEL-20021009123336251PDT EABEL Ellen S. Abel Counter to Counter
1 row selected.
select REFERENCE, LINENO, UPC, DESCRIPTION, QUANTITY
from PURCHASEORDER_LINEITEM;
REFERENCE LINENO UPC DESCRIPTION QUANTITY
-------------------------------- ---------- -------------- ---------------------------------- ----------
EABEL-20021009123336251PDT 1 37429125526 Samurai 2: Duel at Ichijoji Temple 3
EABEL-20021009123336251PDT 2 37429128220 The Red Shoes 4
EABEL-20021009123336251PDT 3 715515009058 A Night to Remember 1
3 rows selected.
|
Note: PNAME is NULL, because the input XML document did not have the element called PNAME under PO. Also, the preceding example used //CITY to search for the city element at any depth. |
Example 4–9 shows how to extract data from an XML purchase order and insert it into a SQL relational table using the extractValue() function.
Example 4-9 Extracting Data from an XML Document and Inserting It Into a Table Using extractValue()
create or replace procedure InsertPurchaseOrder(PurchaseOrder xmltype)
as
REFERENCE VARCHAR2(28);
begin
insert into PURCHASEORDER_TABLE
(
REFERENCE,
REQUESTER,
ACTIONS,
USERID,
COSTCENTER,
SHIPTONAME,
ADDRESS,
PHONE,
REJECTEDBY,
DATEREJECTED,
COMMENTS,
SPECIALINSTRUCTIONS
)
values
(
extractValue(PurchaseOrder,'/PurchaseOrder/Reference'),
extractValue(PurchaseOrder,'/PurchaseOrder/Requestor'),
extract(PurchaseOrder,'/PurchaseOrder/Actions'),
extractValue(PurchaseOrder,'/PurchaseOrder/User'),
extractValue(PurchaseOrder,'/PurchaseOrder/CostCenter'),
extractValue(PurchaseOrder,'/PurchaseOrder/ShippingInstructions/name'),
extractValue(PurchaseOrder,'/PurchaseOrder/ShippingInstructions/address'),
extractValue(PurchaseOrder,'/PurchaseOrder/ShippingInstructions/telephone'),
extractValue(PurchaseOrder,'/PurchaseOrder/Rejection/User'),
extractValue(PurchaseOrder,'/PurchaseOrder/Rejection/Date'),
extractValue(PurchaseOrder,'/PurchaseOrder/Rejection/Comments'),
extractValue(PurchaseOrder,'/PurchaseOrder/SpecialInstructions')
)
returning REFERENCE
into REFERENCE;
insert into PURCHASEORDER_LINEITEM
(
REFERENCE,
LINENO,
UPC,
DESCRIPTION,
QUANTITY,
UNITPRICE
)
select REFERENCE,
extractValue(value(l),'/LineItem/@ItemNumber'),
extractValue(value(l),'/LineItem/Part/@Id'),
extractValue(value(l),'/LineItem/Description'),
extractValue(value(l),'/LineItem/Part/@Quantity'),
extractValue(value(l),'/LineItem/Part/@UnitPrice')
from table(xmlsequence(extract(PurchaseOrder,'/PurchaseOrder/LineItems/LineItem'))) l;
end;/
Procedure created.
call insertPurchaseOrder(xmltype(bfilename('XMLDIR','purchaseOrder.xml'),nls_charset_id('AL32UTF8')));
Call completed.
set linesize 132
column USERID format A8
column SPECIALINSTRUCTIONS format A32
column DESCRIPTION format A34
--
select REFERENCE, USERID, SHIPTONAME, SPECIALINSTRUCTIONS
from PURCHASEORDER_TABLE;
REFERENCE USERID SHIPTONAME SPECIALINSTRUCTIONS
-------------------------------- -------- ------------------------------------------------ -------------------
SBELL-2002100912333601PDT SBELL Sarah J. Bell Air Mail
1 row selected.
--
select REFERENCE, LINENO, UPC, DESCRIPTION, QUANTITY
from PURCHASEORDER_LINEITEM;
REFERENCE LINENO UPC DESCRIPTION QUANTITY
-------------------------------- ---------- -------------- ---------------------------------- ----------
SBELL-2002100912333601PDT 1 715515009058 A Night to Remember 2
SBELL-2002100912333601PDT 2 37429140222 The Unbearable Lightness Of Being 2
SBELL-2002100912333601PDT 3 715515011020 Sisters 4
3 rows selected.
Example 4–10 demonstrates some operations you can perform using the extract() and existsNode() functions. This example extracts the purchase order name from the purchase order element PurchaseOrder, for customers with "ll" (double L) in their names and the word "Shores" in the shipping instructions.
Example 4-10 Searching XML Data with extract() and existsNode()
SELECT p.object_value.extract('/PurchaseOrder/Requestor/text()').getStringVal() NAME, count(*)
FROM PURCHASEORDER p
WHERE p.object_value.existsNode
(
'/PurchaseOrder/ShippingInstructions[ora:contains(address/text(),"Shores")>0]',
'xmlns:ora="http://xmlns.oracle.com/xdb'
) = 1
AND p.object_value.extract('/PurchaseOrder/Requestor/text()').getStringVal() like '%ll%'
GROUP BY p.object_value.extract('/PurchaseOrder/Requestor/text()').getStringVal();
NAME COUNT(*)
-------------------- ----------
Allan D. McEwen 9
Ellen S. Abel 4
Sarah J. Bell 13
William M. Smith 7
4 rows selected.
Example 4–11 shows the proceeding query rewritten using the extractValue() function.
Example 4-11 Searching XML Data with extractValue()
SELECT extractValue(object_value,'/PurchaseOrder/Requestor') NAME, count(*)
FROM PURCHASEORDER p
WHERE existsNode
(
object_value,
'/PurchaseOrder/ShippingInstructions[ora:contains(address/text(),"Shores")>0]',
'xmlns:ora="http://xmlns.oracle.com/xdb'
) = 1
AND extractValue(object_value,'/PurchaseOrder/Requestor/text()') like '%ll%'
GROUP BY extractValue(object_value,'/PurchaseOrder/Requestor');
NAME COUNT(*)
-------------------- ----------
Allan D. McEwen 9
Ellen S. Abel 4
Sarah J. Bell 13
William M. Smith 7
4 rows selected.
Example 4–12 shows usage of the extract() function to extract nodes identified by an XPath expression. An XMLType instance containing the XML fragment is returned by the extract() call. The result may be a set of nodes, a singleton node, or a text value. You can determine whether the result is a fragment using the isFragment() function on the XMLType.
|
Note: You cannot insert fragments intoXMLType columns. You can use SYS_XMLGEN() to convert a fragment into a well-formed document by adding an enclosing tag. See "SYS_XMLGEN() Function". You can, however, query further on the fragment using the various XMLType functions. |
Example 4-12 Extracting Fragments from XMLType Using extract()
select extractValue(object_value,'/PurchaseOrder/Reference') REFERENCE,
count(*)
from PURCHASEORDER,
table (xmlsequence(extract(object_value,' //LineItem[Part@Id="37429148327"]'))) l
where extract(object_value,'/PurchaseOrder/LineItems/LineItem[Part/@Id="37429148327"]').isFragment() = 1
group by extractValue(object_value,'/PurchaseOrder/Reference')
order by extractValue(object_value,'/PurchaseOrder/Reference');
REFERENCE COUNT(*)
-------------------------------- ----------
AWALSH-20021009123337303PDT 1
AWALSH-20021009123337954PDT 1
DAUSTIN-20021009123337553PDT 1
DAUSTIN-20021009123337613PDT 1
LSMITH-2002100912333722PDT 1
LSMITH-20021009123337323PDT 1
PTUCKER-20021009123336291PDT 1
SBELL-20021009123335771PDT 1
SKING-20021009123335560PDT 1
SMCCAIN-20021009123336151PDT 1
SMCCAIN-20021009123336842PDT 1
SMCCAIN-2002100912333894PDT 1
TFOX-2002100912333681PDT 1
TFOX-20021009123337784PDT 3
WSMITH-20021009123335650PDT 1
WSMITH-20021009123336412PDT 1
16 rows selected.
This section talks about updating transient XML instances and XML data stored in tables.
For CLOB-based storage, an update effectively replaces the whole document. To update the whole XML document use the SQL UPDATE statement. The right hand side of the UPDATE statement SET clause must be an XMLType instance. This can be created using the SQL functions and XML constructors that return an XML instance, or by using the PL/SQL DOM APIs for XMLType or Java DOM API, that change and bind existing XML instances.
Example 4–13 updates an XMLType instance using the UPDATE statement.
|
Note: Updates for non-schema based XML documents always update the whole XML document. |
Example 4-13 Updating XMLType Using the UPDATE Statement
select extractValue(object_value,'/PurchaseOrder/Reference') REFERENCE,
extractValue(value(l),'/LineItem/@ItemNumber') LINENO,
extractValue(value(l),'/LineItem/Description') DESCRIPTION
from PURCHASEORDER,
table (xmlsequence(extract(object_value,'//LineItem'))) l
WHERE existsNode(object_value,'/PurchaseOrder[Reference="DAUSTIN-20021009123335811PDT"]') = 1
and ROWNUM < 6;
REFERENCE LINENO DESCRIPTION
-------------------------------- ------- --------------------------------
DAUSTIN-20021009123335811PDT 1 Nights of Cabiria
DAUSTIN-20021009123335811PDT 2 For All Mankind
DAUSTIN-20021009123335811PDT 3 Dead Ringers
DAUSTIN-20021009123335811PDT 4 Hearts and Minds
DAUSTIN-20021009123335811PDT 5 Rushmore
5 rows selected.
--
UPDATE PURCHASEORDER
SET object_value = xmltype
(
bfilename('XMLDIR','NEW-DAUSTIN-20021009123335811PDT.xml'),
nls_charset_id('AL32UTF8')
)
WHERE existsNode(object_value,'/PurchaseOrder[Reference="DAUSTIN-20021009123335811PDT"]') = 1;
1 row updated.
--
select extractValue(object_value,'/PurchaseOrder/Reference') REFERENCE,
extractValue(value(l),'/LineItem/@ItemNumber') LINENO,
extractValue(value(l),'/LineItem/Description') DESCRIPTION
from PURCHASEORDER,
table (xmlsequence(extract(object_value,'//LineItem'))) l
WHERE existsNode(object_value,'/PurchaseOrder[Reference="DAUSTIN-20021009123335811PDT"]') = 1;
REFERENCE LINENO DESCRIPTION
-------------------------------- ------- --------------------------------
DAUSTIN-20021009123335811PDT 1 Dead Ringers
DAUSTIN-20021009123335811PDT 2 Getrud
DAUSTIN-20021009123335811PDT 3 Branded to Kill
3 rows selected.
updateXML() function takes in a source XMLType instance, and a set of XPath value pairs. Figure 4-4 illustrates the updateXML() syntax. It returns a new XML instance consisting of the original XMLType instance with appropriate XML nodes updated with the given values. The optional namespace parameter specifies the namespace mapping of prefix(es) in the XPath parameters.
updateXML() can be used to update or replace elements, attributes, and other nodes with new values. They cannot be directly used to insert new nodes or delete existing ones. The containing parent element should be updated with the new values instead.
updateXML() updates only the transient XML instance in memory. Use a SQL UPDATE statement to update data stored in tables. The updateXML() syntax is:
UPDATEXML(xmlinstance, xpath1, value_expr1
[, xpath2, value_expr2]...[,namespace_string]);
Example 4–14 demonstrates using the updateXML() function in the right hand side of an UPDATE statement to update the XML document in the table instead of creating a new one. Note that updateXML() updates the whole document, not just the part selected.
Example 4-14 Updating XMLType Using UPDATE and updateXML()
SELECT extract(object_value,'/PurchaseOrder/Actions/Action[1]') ACTION FROM PURCHASEORDER WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1; ACTION --------------------------------------------------------------------------------------------------------------- <Action> <User>SVOLLMAN</User> </Action> 1 row selected. UPDATE PURCHASEORDER SET object_value = updateXML(object_value,'/PurchaseOrder/Actions/Action[1]/User/text()','SKING') WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1; 1 row updated. SELECT extract(object_value,'/PurchaseOrder/Actions/Action[1]') ACTION FROM PURCHASEORDER WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1; ACTION -------------------------------------------------------------------------------------------------------- <Action> <User>SKING</User> </Action> 1 row selected.
Example 4–15 shows how you can update multiple nodes using the updateXML() function.
Example 4-15 Updating Multiple Text Nodes and Attribute Values Using updateXML()
SELECT extractValue(object_value,'/PurchaseOrder/Requestor') Name,
extract(object_value,'/PurchaseOrder/LineItems') LINEITEMS
FROM PURCHASEORDER
WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1;
NAME LINEITEMS
---------------- ------------------------------------------------------------------------
Sarah J. Bell <LineItems>
<LineItem ItemNumber="1">
<Description>A Night to Remember</Description>
<Part Id="715515009058" UnitPrice="39.95" Quantity="2"/>
</LineItem>
<LineItem ItemNumber="2">
<Description>The Unbearable Lightness Of Being</Description>
<Part Id="37429140222" UnitPrice="29.95" Quantity="2"/>
</LineItem>
<LineItem ItemNumber="3">
<Description>Sisters</Description>
<Part Id="715515011020" UnitPrice="29.95" Quantity="4"/>
</LineItem>
</LineItems>
1 row selected.
UPDATE PURCHASEORDER
SET object_value = updateXML
(
object_value,
'/PurchaseOrder/Requestor/text()','Stephen G. King',
'/PurchaseOrder/LineItems/LineItem[1]/Part/@Id','786936150421',
'/PurchaseOrder/LineItems/LineItem[1]/Description/text()','The Rock',
'/PurchaseOrder/LineItems/LineItem[3]',
XMLType
(
'<LineItem ItemNumber="99">
<Description>Dead Ringers</Description>
<Part Id="715515009249" UnitPrice="39.95" Quantity="2"/>
</LineItem>'
)
)
WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1;
1 row updated.
SELECT extractValue(object_value,'/PurchaseOrder/Requestor') Name,
extract(object_value,'/PurchaseOrder/LineItems') LINEITEMS
FROM PURCHASEORDER
WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1;
NAME LINEITEMS
---------------- ------------------------------------------------------------------------
Stephen G. King <LineItems>
<LineItem ItemNumber="1">
<Description>The Rock</Description>
<Part Id="786936150421" UnitPrice="39.95" Quantity="2"/>
</LineItem>
<LineItem ItemNumber="2">
<Description>The Unbearable Lightness Of Being</Description>
<Part Id="37429140222" UnitPrice="29.95" Quantity="2"/>
</LineItem>
<LineItem ItemNumber="99">
<Description>Dead Ringers</Description>
<Part Id="715515009249" UnitPrice="39.95" Quantity="2"/>
</LineItem>
</LineItems>
1 row selected.
Example 4–16 demonstrates how you can use the updateXML() function to update selected nodes within a collection.
Example 4-16 Updating Selected Nodes Within a Collection Using updateXML()
SELECT extractValue(object_value,'/PurchaseOrder/Requestor') Name,
extract(object_value,'/PurchaseOrder/LineItems') LINEITEMS
FROM PURCHASEORDER
WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1;
NAME LINEITEMS
---------------- ------------------------------------------------------------------------
Sarah J. Bell <LineItems>
<LineItem ItemNumber="1">
<Description>A Night to Remember</Description>
<Part Id="715515009058" UnitPrice="39.95" Quantity="2"/>
</LineItem>
<LineItem ItemNumber="2">
<Description>The Unbearable Lightness Of Being</Description>
<Part Id="37429140222" UnitPrice="29.95" Quantity="2"/>
</LineItem>
<LineItem ItemNumber="3">
<Description>Sisters</Description>
<Part Id="715515011020" UnitPrice="29.95" Quantity="4"/>
</LineItem>
</LineItems>
1 row selected.
UPDATE PURCHASEORDER
SET object_value = updateXML
(
object_value,
'/PurchaseOrder/Requestor/text()','Stephen G. King',
'/PurchaseOrder/LineItems/LineItem/Part[@Id="715515009058"]/@Quantity',25,
'/PurchaseOrder/LineItems/LineItem[Description/text()="The Unbearable Lightness Of Being"]',
XMLType
(
'<LineItem ItemNumber="99">
<Part Id="786936150421" Quantity="5" UnitPrice="29.95"/>
<Description>The Rock</Description>
</LineItem>'
)
)
WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1;
1 row updated.
SELECT extractValue(object_value,'/PurchaseOrder/Requestor') Name,
extract(object_value,'/PurchaseOrder/LineItems') LINEITEMS
FROM PURCHASEORDER
WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1;
NAME LINEITEMS
---------------- ------------------------------------------------------------------------
Stephen G. King <LineItems>
<LineItem ItemNumber="1">
<Description>A Night to Remember</Description>
<Part Id="715515009058" UnitPrice="39.95" Quantity="25"/>
</LineItem>
<LineItem ItemNumber="99">
<Part Id="786936150421" Quantity="5" UnitPrice="29.95"/>
<Description>The Rock</Description>
</LineItem>
<LineItem ItemNumber="3">
<Description>Sisters</Description>
<Part Id="715515011020" UnitPrice="29.95" Quantity="4"/>
</LineItem>
</LineItems>
1 row selected.
If you update an XML element to NULL, Oracle Database removes the attributes and children of the element, and the element becomes empty. The type and namespace properties of the element are retained. A NULL value for an element update is equivalent to setting the element to empty.
If you update the text node of an element to NULL, Oracle Database removes the text value of the element, and the element itself remains, but is empty.
Example 4–17 updates the Description element, Quantity element, and the text() node for the Quantity element to NULL using the updateXML() function.
Setting an attribute to NULL, similarly sets the value of the attribute to the empty string.
You cannot use updateXML() to remove, add, or delete a particular element or an attribute. To do so, you must update the containing element with a new value.
Example 4-17 NULL Updates With updateXML()
SELECT extractValue(object_value,'/PurchaseOrder/Requestor') Name,
extract(object_value,'/PurchaseOrder/LineItems') LINEITEMS
FROM PURCHASEORDER
WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1;
NAME LINEITEMS
---------------- ------------------------------------------------------------------------
Sarah J. Bell <LineItems>
<LineItem ItemNumber="1">
<Description>A Night to Remember</Description>
<Part Id="715515009058" UnitPrice="39.95" Quantity="2"/>
</LineItem>
<LineItem ItemNumber="2">
<Description>The Unbearable Lightness Of Being</Description>
<Part Id="37429140222" UnitPrice="29.95" Quantity="2"/>
</LineItem>
<LineItem ItemNumber="3">
<Description>Sisters</Description>
<Part Id="715515011020" UnitPrice="29.95" Quantity="4"/>
</LineItem>
</LineItems>
1 row selected.
UPDATE PURCHASEORDER
SET object_value = updateXML
(
object_value,
'/PurchaseOrder/LineItems/LineItem[Part/@Id="715515009058"]/Description',null,
'/PurchaseOrder/LineItems/LineItem/Part[@Id="715515009058"]/@Quantity',null,
'/PurchaseOrder/LineItems/LineItem[Description/text()="The Unbearable Lightness Of Being"]',null
)
WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1;
1 row updated.
--
SELECT extractValue(object_value,'/PurchaseOrder/Requestor') Name,
extract(object_value,'/PurchaseOrder/LineItems') LINEITEMS
FROM PURCHASEORDER
WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1;
NAME LINEITEMS
---------------- ------------------------------------------------------------------------
Sarah J. Bell <LineItems>
<LineItem ItemNumber="1">
<Description/>
<Part Id="715515009058" UnitPrice="39.95" Quantity=""/>
</LineItem>
<LineItem/>
<LineItem ItemNumber="3">
<Description>Sisters</Description>
<Part Id="715515011020" UnitPrice="29.95" Quantity="4"/>
</LineItem>
</LineItems>
1 row selected.
The XPath expressions in the updateXML() Statement shown in Example 4–18 are processed by Oracle XML DB and rewritten into the equivalent object relational SQL statement given in Example 4–19.
Example 4-18 XPATH Rewrite with UpdateXML()
SELECT extractValue(object_value,'/PurchaseOrder/User') FROM PURCHASEORDER WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1; EXTRACTVAL ---------- SBELL 1 row selected. -- UPDATE PURCHASEORDER SET object_value = updateXML(object_value,'/PurchaseOrder/User/text()','SVOLLMAN') WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1; 1 row updated. -- SELECT extractValue(object_value,'/PurchaseOrder/User') FROM PURCHASEORDER WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1; EXTRACTVAL ---------- SVOLLMAN 1 row selected.
Example 4-19 Rewritten Object Relational Equivalent of XPATH Rewrite with UpdateXML()
SELECT extractValue(object_value,'/PurchaseOrder/User') FROM PURCHASEORDER WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1; EXTRACTVAL ---------- SBELL 1 row selected. -- UPDATE PURCHASEORDER p SET p."XMLDATA"."USERID" = 'SVOLLMAN' WHERE p."XMLDATA"."REFERENCE" = 'SBELL-2002100912333601PDT'; 1 row updated. -- SELECT extractValue(object_value,'/PurchaseOrder/User') FROM PURCHASEORDER WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1; EXTRACTVAL ---------- SVOLLMAN 1 row selected.
You can update the same XML node more than once in the updateXML() statement. For example, you can update both /EMP[EMPNO=217] and /EMP[EMPNAME="Jane"]/EMPNO, where the first XPath identifies the EMPNO node containing it as well. The order of updates is determined by the order of the XPath expressions in left-to-right order. Each successive XPath works on the result of the previous XPath update.
Here are some guidelines for preserving DOM fidelity when using updateXML():
When you update an element to NULL, you make that element appear empty in its parent, such as in <myElem/.When you update a text node inside an element to NULL, you remove that text node from the element.When you update an attribute node to NULL, you make the value of the attribute become the empty string, for example, myAttr="".
When you update a complexType element to NULL, you make the element appear empty in its parent, for example, <myElem/>.When you update a SQL-inlined simpleType element to NULL, you make the element disappear from its parent.When you update a text node to NULL, you are doing the same thing as setting the parent simpleType element to NULL. Furthermore, text nodes can appear only inside simpleTypes when DOM fidelity is not preserved, since there is no positional descriptor with which to store mixed content.When you update an attribute node to NULL, you remove the attribute from the element.
In most cases, updateXML() materializes the whole input XML document in memory and updates the values. However, it is optimized for UPDATE statements on XML schema-based object-relationally stored XMLType tables and columns so that the function updates the value directly in the column. If all of the rewrite conditions are met, then the updateXML() is rewritten to update the object-relational columns directly with the values.
For example, the XPath expressions in the updateXML() statement shown in Example 4–20 are processed by Oracle XML DB and re-written into the equivalent object relational SQL statement shown in Example 4–21.
|
See Also: Chapter 3, " Using Oracle XML DB" and Chapter 5, " XML Schema Storage and Query: The Basics" for information on the conditions for XPath rewrite. |
Example 4-20 XPath expressions in updateXML() Statement
SELECT extractValue(object_value,'/PurchaseOrder/User') FROM PURCHASEORDER WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1; EXTRACTVAL ---------- SBELL 1 row selected. -- UPDATE PURCHASEORDER SET object_value = updateXML(object_value,'/PurchaseOrder/User/text()','SVOLLMAN') WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1; 1 row updated. -- SELECT extractValue(object_value,'/PurchaseOrder/User') FROM PURCHASEORDER WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1; EXTRACTVAL ---------- SVOLLMAN 1 row selected.
Example 4-21 Object Relational Equivalent of updateXML() Statement
SELECT extractValue(object_value,'/PurchaseOrder/User') FROM PURCHASEORDER WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1; EXTRACTVAL ---------- SBELL 1 row selected. -- UPDATE PURCHASEORDER p SET p."XMLDATA"."USERID" = 'SVOLLMAN' WHERE p."XMLDATA"."REFERENCE" = 'SBELL-2002100912333601PDT'; 1 row updated. -- SELECT extractValue(object_value,'/PurchaseOrder/User') FROM PURCHASEORDER WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1; EXTRACTVAL ---------- SVOLLMAN 1 row selected.
You can use updateXML() to create new views of XML data. Example 4–22 creates a view of the PURCHASEORDER table using the updateXML() function.
Example 4-22 Creating Views Using updateXML()
CREATE OR REPLACE VIEW purchaseorder_summary of XMLType
as
select updateXML
(
object_value,
'/PurchaseOrder/Actions',null,
'/PurchaseOrder/ShippingInstructions',null,
'/PurchaseOrder/LineItems',null
) as XML
FROM PURCHASEORDER p;
View created.
select object_value
from
PURCHASEORDER_SUMMARY
where existsNode(object_value, '/PurchaseOrder[Reference="DAUSTIN-20021009123335811PDT"]') = 1;
OBJECT_VALUE
----------------------------------------------------------------------------------
<PurchaseOrder xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation=
"http://localhost:8080//home/SCOTT/poSource/xsd/purchaseOrder.xsd">
<Reference>DAUSTIN-20021009123335811PDT</Reference>
<Actions/>
<Reject/>
<Requestor>David L. Austin</Requestor>
<User>DAUSTIN</User>
<CostCenter>S30</CostCenter>
<ShippingInstructions/>
<SpecialInstructions>Courier</SpecialInstructions>
<LineItems/>
</PurchaseOrder>
1 row selected.
Chapter 3 provided a basic introduction to creating indexes on XML documents that have been stored using the structured storage option. It demonstrated how to use the extractValue() function to create indexes on XMLType documents stored in tables or columns that are based on the structured storage option.
This section discusses other indexing techniques including:
XPATH REWRITE for indexes on Singleton Elements or Attributes
Creating B-Tree Indexes on the Contents of a Collection
Creating Function-Based Indexes on XMLType Tables and Columns
CTXXPath Indexes on XMLType Columns
Oracle Text Indexes on XMLType Columns
When indexes are created on structured XMLType tables or columns, XML DB attempts to re-write the XPath expressions provided to the extractValue() function into CREATE INDEX statements that operate directly on the underlying objects.
For instance, given an index created as shown in Example 4–23, XPath re-write will re-write the index resulting in the create index statement shown in Example 4–24 being executed. As can be seen, the rewritten index is created directly on the columns that manage the attributes of the underlying SQL objects. This technique works well when the Element or Attribute being indexed only occurs once in the XML Document.
You might often need to create an index over nodes that occur more than once in the target document. For instance, assume you wanted to create an index on the Id attribute of the LineItem element. A logical first attempt would be to create an index using the syntax shown in Example 4–25.
Example 4-25 Using extractValue() to Create an Index on a repeating Element or Attributes
CREATE INDEX iLINEITEM_UPCCODE
ON PURCHASEORDER
(extractValue(object_value,'/PurchaseOrder/LineItems/LineItem/Part/@Id'));
(extractValue(object_value,'/PurchaseOrder/LineItems/LineItem/Part/@Id'))
*
ERROR at line 3:
ORA-19025: EXTRACTVALUE returns value of only one node
As can be seen, when the Element or Attribute being indexed occurs multiple times in the document, the create index fails because extractValue() is only allowed to return a single value for each row it processes. It is possible to create an Index replacing extractValue() with extract().getStringVal() as shown in Example 4–26.
Example 4-26 Using extract().getStringVal() to Create a Function-Based Index on an extract()
CREATE INDEX iLINEITEM_UPCCODE ON PURCHASEORDER ( extract(object_value,'PurchaseOrder/LineItems/LineItem/Part/@Id').getStringVal()); Index created.
This allows the Create Index statement to succeed. However, the index that is created is not what is expected. The index is created by invoking the extract() and getStringVal() functions for each row in the table and then indexing the result of the function against the rowid of the row.
The problem with this technique, is that when the XPath expression supplied to the extract() function, the extract() function can only returns multiple nodes. The result of the extract() function is a single XMLType consisting of a fragment containing the matching nodes. The result of invoking getStringVal() on an XMLType that contains a fragment is a concatenation of the nodes in question as shown in Example 4–27.
As can be seen, what is indexed for this row is the concatenation of the 3 UPC codes, not each of the individual UPC codes. In general, care should be taken when creating an index using the extract() function. It is unlikely that this index will be useful.
As was shown in Chapter 3, for Schema-Based XMLType, the best way to resolve this issue is adopt a storage structure that uses nested tables to force each node that is indexed to be stored as a separate row. The index can then be created directly on the nested table using object relational SQL similar to the SQL that is generated by XPath re-write.
Example 4-27 Problem with using extract().getStringVal() to Create a Function-Based Index on an extract() Function
SELECT extract(object_value,'/PurchaseOrder/LineItems') XML,
extract(object_value,'PurchaseOrder/LineItems/LineItem/Part/@Id').getStringVal() INDEX_VALUE
FROM PURCHASEORDER
WHERE existsNode(object_value,'/PurchaseOrder[Reference="SBELL-2002100912333601PDT"]') = 1;
XML INDEX_VALUE
-------------------------------------------------------------------- --------------
<LineItems> 71551500905837
<LineItem ItemNumber="1"> 42914022271551
<Description>A Night to Remember</Description> 5011020
<Part Id="715515009058" UnitPrice="39.95" Quantity="2"/>
</LineItem>
<LineItem ItemNumber="2">
<Description>The Unbearable Lightness Of Being</Description>
<Part Id="37429140222" UnitPrice="29.95" Quantity="2"/>
</LineItem>
<LineItem ItemNumber="3">
<Description>Sisters</Description>
<Part Id="715515011020" UnitPrice="29.95" Quantity="4"/>
</LineItem>
</LineItems>
1 row selected.
The index that is created in Example 4–26 is an example of a function-based index. A function-based index is created by evaluating the specified functions for each row in the table. In that particular case, the results of the functions were not useful and consequently the index itself was not useful. However, there are many cases were function-based indexes are useful.
One example of when a function-based index is useful is when the XML content is not being managed using structured storage. In this case, instead of the CREATE INDEX statement being re-written, the index will be created by invoking the function on the XML content and indexing the result.
Given the table created in Example 4–28, which uses CLOB storage rather than structured storage to persist the XML, the following CREATE INDEX statement will result in a function-based index being created on the value of the text node belonging to the Reference element. As the example shows, this index will enforce the unique constraint on the value of the text node associated with the Reference element.
Example 4-28 Creating a Function-Based Index on a CLOB-based XMLType()
create table PURCHASEORDER_CLOB of XMLTYPE
XMLType store as CLOB
ELEMENT "http://localhost:8080/home/SCOTT/poSource/xsd/purchaseOrder.xsd#PurchaseOrder";
Table created.
--
insert into PURCHASEORDER_CLOB
select object_value from PURCHASEORDER;
134 rows created.
--
create unique index iPURCHASEORDER_REFERENCE
on PURCHASEORDER_CLOB
(extractValue(object_value,'/PurchaseOrder/Reference'));
Index created.
--
insert into PURCHASEORDER_CLOB
VALUES
(
xmltype
(
bfilename('XMLDIR','EABEL-20021009123335791PDT.xml'),
nls_charset_id('AL32UTF8')
)
);
insert into PURCHASEORDER_CLOB*
ERROR at line 1:
ORA-00001: unique constraint (SCOTT.IPURCHASEORDER_REFERENCE) violated
One thing to bear in mind when creating and using function-based indexes is that the optimizer will only consider using the index when the function included in the WHERE clause is identical to the function used to create the index.
Consider the queries in Example 4–29 which both find a PurchaseOrder-based value of the text node associated with the Reference element. Note that the first query, which uses existsNode() to locate the document, does not use the index, while the second query, which uses extractValue(), does use the index.
Example 4-29 Queries that use Function-Based indexes
explain plan for
select object_value
from PURCHASEORDER_CLOB
where existsNode(object_value,'/PurchaseOrder[Reference="EABEL-20021009123335791PDT"') = 1;
Explained.
--
set ECHO OFF
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------
Plan hash value: 3761539978
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 4004 | 3 (34)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| PURCHASEORDER_CLOB | 2 | 4004 | 3 (34)| 00:00:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(EXISTSNODE(SYS_MAKEXML('3A7F7DBBEE5543A486567A908C71D65A',3664,"PU
RCHASEORDER_CLOB"."XMLDATA"),'/PurchaseOrder[Reference="EABEL-20021009123335791P
DT"')=1)
15 rows selected.
--
explain plan for
select object_value
from PURCHASEORDER_CLOB
where extractValue(object_value,'/PurchaseOrder/Reference') = 'EABEL-20021009123335791PDT';
Explained.
--
set ECHO OFF
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------
Plan hash value: 1408177405
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 2002 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| PURCHASEORDER_CLOB | 1 | 2002 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | IPURCHASEORDER_REFERENCE | 1 | | | 00:00:01 |
--------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access(EXTRACTVALUE(SYS_MAKEXML('3A7F7DBBEE5543A486567A908C71D65A',3664,"XMLDATA"),'/Purc
haseOrder/Reference')='EABEL-20021009123335791PDT')
Note
-----
- warning: inconsistencies found in estimated optimizer costs
- dynamic sampling used for this statement
20 rows selected.
Function-based indexes can be created on both structured and unstructured schema-based XMLType tables and columns as well as non-schema-based XMLType tables and columns. If XPath re-write cannot process the XPath expression supplied as part of the Create Index statement, the statement will result in a function-based index being created.
An example of this would be creating an index based on the existsNode() function. The existsNode() function simply returns 1 or 0 depending on whether or not a document contains a node that matches the supplied XPath expression. This means that it is not possible for XPath re-write to generate an equivalent object-relational CREATE INDEX statement. In general, since existsNode() returns 0, or 1, it makes sense to use BITMAP indexes when creating an index based on the existsNode() function.
In Example 4–30, an index is created that can be used to speed up a query that searches for instances of a rejected PurchaseOrder by looking for the presence of a text() node under the element /PurchaseOrder/Reject/User.
Since the index is a function-based index, it can be used with structured and unstructured schema-based XMLType tables and columns, as well as non-schema-based XMLType tables and columns.
Example 4-30 Creating a Function-Based index on Schema-Based XMLType
SELECT extractValue(object_value,'/PurchaseOrder/Reference')
from PURCHASEORDER
where existsNode(object_Value,'/PurchaseOrder/Reject/User/text()') = 1;
EXTRACTVALUE(OBJECT_VALUE,'/PU
------------------------------
SMCCAIN-2002091213000000PDT
1 row selected.
--
CREATE BITMAP INDEX iPURCHASEORDER_REJECTED
ON PURCHASEORDER
(existsNode(object_Value,'/PurchaseOrder/Reject/User/text()'));
Index created.
--
call dbms_stats.gather_table_stats(USER,'PURCHASEORDER');
Call completed.
--
explain plan for
SELECT extractValue(object_value,'/PurchaseOrder/Reference')
from PURCHASEORDER
where existsNode(object_Value,'/PurchaseOrder/Reject/User/text()') = 1;
Explained.
--
set ECHO OFF
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------
Plan hash value: 841749721
-----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 419 | 4 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| PURCHASEORDER | 1 | 419 | 4 (0)| 00:00:01 |
-----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("PURCHASEORDER"."SYS_NC00018$" IS NOT NULL)
13 rows selected.
The indexing techniques outlined earlier in this chapter require you to be aware in advance of the set of XPath expressions that will be used when searching XML content. Oracle XML DB also makes it possible to create a CTXXPATH index—a general purpose XPath-based index, based on Oracle Text technology, that can be used to improve the performance of any existsNode() based search. Such an index has the following advantages:
You do not need prior knowledge of the XPath expressions that will be searched on.
It can be used with both structured and unstructured schema-based XMLType tables and columns, as well as non-schema-based XMLType tables and columns.
It can be used to create indexes that make it improve the performance of searches that involve XPath expressions that target nodes that occur multiple times within a document.
The CTXXPATH index is based on Oracle Text Technology and the functionality provided in the HASPATH and INPATH operators provided by the Oracle Text CONTAINS function. The HASPATH and INPATH operators allow high performance XPath-like searches to be performed over XML content. Unfortunately, they do not support true XPath compliant syntax.
The CTXXPATH index is designed to re-write the XPath expression supplied to existsNode() into HASPATH and INPATH operators that can use the underlying text index to quickly locate a superset of the documents that match the supplied XPath expression. Each document identified by the text index is then checked, using a DOM-based evaluation, to ensure that it is a true match for the supplied XPath expression. Due to the asynchronous nature of the underlying text technology, the CTXXPATH index will also perform a DOM based evaluation of all un-indexed documents to see if they also should be included in the result set.
CTXXPATH indexing has the following characteristics:
Can only be used to speed up existsNode() processing. It acts as a primary filter for the existsNode() function. In other words, it provides a superset of the results that existsNode() would provide
CTXXPATH index will only work for queries where the XPath expressions that identify the required documents are supplied using an existsNode() function that appears in the WHERE clause of the SQL statement being executed.
Only handles a limited set of XPath expressions. See "Choosing the Right Plan: Using CTXXPATH Index in existsNode() Processing" for the list of XPath expressions not supported by the index.
Only supports the STORAGE preference parameter. See "Creating CTXXPATH Storage Preferences With CTX_DDL. Statements".
Data Manipulation Language (DML) operations such as updating and deleting are asynchronous. You must use a special command to synchronize the DML operations, in a similar fashion to Oracle Text index. Despite the asynchronous nature of DML operations, CTXXPATH indexing still follows the transactional semantics of existsNode() by also returning unindexed rows as part of its result set in order to guarantee its requirement of returning a superset of the valid results.
Create CTXXPATH indexes in the same way that you create Oracle Text indexes, using the syntax:
CREATE INDEX [schema.]index ON [schema.]table(XMLType column) INDEXTYPE IS ctxsys.CTXXPATH [PARAMETERS(paramstring)];
where
paramstring = '[storage storage_pref] [memory memsize] [populate | nopopulate]'
Example 4–31 demonstrates how to create a CTXXPATH index for XPath searching.
The only preference allowed in CTXXPATH indexing is the STORAGE preference. Create the STORAGE preference in the same way that you would for an Oracle Text index as shown in Example 4–32.
|
Note: You must be granted execute privileges on theCTXSYS.CTX_DLL package in order to create storage preferences. |
Example 4-32 Creating and Using Storage Preferences for CTXXPATH Indexes
begin
ctx_ddl.create_preference('CLOB_XPATH_STORE', 'BASIC_STORAGE');
ctx_ddl.set_attribute('CLOB_XPATH_STORE', 'I_TABLE_CLAUSE',
'tablespace USERS storage (initial 1K)');
ctx_ddl.set_attribute('CLOB_XPATH_STORE', 'K_TABLE_CLAUSE',
'tablespace USERS storage (initial 1K)');
ctx_ddl.set_attribute('CLOB_XPATH_STORE', 'R_TABLE_CLAUSE',
'tablespace USERS storage (initial 1K)');
ctx_ddl.set_attribute('CLOB_XPATH_STORE', 'N_TABLE_CLAUSE',
'tablespace USERS storage (initial 1K)');
ctx_ddl.set_attribute('CLOB_XPATH_STORE', 'I_INDEX_CLAUSE',
'tablespace USERS storage (initial 1K)');
end;/
PL/SQL procedure successfully completed.
create index PURCHASEORDER_CLOB_XPATH
on PURCHASEORDER_CLOB (object_value)
indextype is CTXSYS.CTXXPATH
PARAMETERS('storage CLOB_XPATH_STORE memory 120M');
Index created.
--
explain plan for
select extractValue(object_value,'/PurchaseOrder/Reference')
from PURCHASEORDER_CLOB
where existsNode(object_value,'//LineItem/Part[@Id="715515011624"]') = 1;
Explained.
--
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------
Plan hash value: 2191955729
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 2031 | 4 (0)| 00:00:01 |
|* 1 | TABLE ACCESS BY INDEX ROWID| PURCHASEORDER_CLOB | 1 | 2031 | 4 (0)| 00:00:01 |
| 2 | DOMAIN INDEX | PURCHASEORDER_CLOB_XPATH | | | 4 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(EXISTSNODE(SYS_MAKEXML('3A7F7DBBEE5543A486567A908C71D65A',3664,"PURCHASEORDER_CLOB
"."XMLDATA"),'//LineItem/Part[@Id="715515011624"]')=1)
Note
-----
- dynamic sampling used for this statement
19 rows selected.
Example 4-33 illustrates how to synchronize DML operations using the SYNC_INDEX procedure in the CTX_DDL package.
Example 4-34 illustrates how to optimize the CTXXPATH index using the OPTIMIZE_INDEX procedure in the CTX_DDL package.
It is not guaranteed that a CTXXPATH index will always be used to speed up existsNode() processing for the following reasons:
Oracle Database cost-based optimizer may decide it is too costly to use CTXXPATH index as a primary filter
XPath expressions cannot all be handled by CTXXPATH index. The following XPath constructs cannot be handled by CTXXPATH index:
XPath functions
Numerical range operators
Numerical equality
Arithmetic operators
UNION operator "|"
Parent and sibling axes
An attribute following a *, //, .. , in other words,'/A/*/@attr', '/A//@attr', '/A//../@attr'
'.' or '*' at the end of the path expression
A predicate following '.' or '*'
String literal equalities are supported with the following restrictions:
The left hand side must be a path ('.' by itself is not allowed, for example .="dog")
The right hand side must be a literal
Anything not expressible by abbreviated syntax is also not supported
For the cost-based optimizer to better estimate the costs and selectivities for the existsNode() function, you must first gather statistics on your CTXXPATH indexing by using the ANALYZE command or DBMS_STATS package as follows:
ANALYZE INDEX myPathIndex COMPUTE STATISTICS;
or you can simply analyze the whole table:
ANALYZE TABLE XMLTab COMPUTE STATISTICS;
XPath queries on XML schema-based XMLType table are candidates for XPath query rewrite. An existsNode() expression in a query may be rewritten to a set of operators on the underlying object-relational columns of the schema-based table. In such a case, the CTXXPATH index can no longer be used by the query, since it can only be used to satisfy existsNode() queries on the index expression, specified during index creation time.
In Example 4–35, a CTXXPATH index is created on table PURCHASEORDER. The existsNode() expression specified in the WHERE clause gets rewritten into an expression that checks if the underlying object-relational column is not NULL. This is in accordance with XPath query rewrite rules. If the hint /*+ NO_XML_QUERY_REWRITE */ causes XPath query rewrite to be turned off for the query, the existsNode() expression is left unchanged.
Example 4-35 Creating a CTXXPATH Index on a Schema-Based XMLType Table
create index PURCHASEORDER_XPATH
on PURCHASEORDER (object_value)
indextype is CTXSYS.CTXXPATH;
Index created.
--
explain plan for
select extractValue(object_value,'/PurchaseOrder/Reference')
from PURCHASEORDER
where existsNode(object_value,'/PurchaseOrder/LineItems/LineItem[Description="The Rock"]') = 1;
Explained.
--
set ECHO OFF
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------
Plan hash value: 122532357
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 13 | 65520 | 823 (1)| 00:00:10 |
|* 1 | HASH JOIN SEMI | | 13 | 65520 | 823 (1)| 00:00:10 |
| 2 | TABLE ACCESS FULL | PURCHASEORDER | 134 | 56146 | 4 (0)| 00:00:01 |
|* 3 | INDEX FAST FULL SCAN| LINEITEM_TABLE_IOT | 13 | 60073 | 818 (0)| 00:00:10 |
--------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("NESTED_TABLE_ID"="PURCHASEORDER"."SYS_NC0003400035$")
3 - filter("DESCRIPTION"='The Rock')
Note
-----
- dynamic sampling used for this statement
20 rows selected.
--
explain plan for
select /*+ NO_XML_QUERY_REWRITE */ extractValue(object_value,'/PurchaseOrder/Reference')
from PURCHASEORDER
where existsNode(object_value,'/PurchaseOrder/LineItems/LineItem[Description="The Rock"]') = 1;
Explained.
--
set ECHO OFF
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------
Plan hash value: 3192700042
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 419 | 4 (0)| 00:00:01 |
|* 1 | TABLE ACCESS BY INDEX ROWID| PURCHASEORDER | 1 | 419 | 4 (0)| 00:00:01 |
| 2 | DOMAIN INDEX | PURCHASEORDER_XPATH | | | 4 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(EXISTSNODE(SYS_MAKEXML('3A7F7DBBEE5543A486567A908C71D65A',3664,"PURCHASEORDER
"."XMLEXTRA","PURCHASEORDER"."XMLDATA"),'/PurchaseOrder/LineItems/LineItem[Description="The
Rock"]')=1)
16 rows selected.
Use tracing to determine whether or not an index is being used.
The choice of whether to use CTXXPATH indexes depends on the storage options used, the size of the documents being indexed, and the query mix involved.
CTXXPATH indexes can be used for existsnode() queries on non-schema-based XMLType tables and columns when the data is stored as a CLOB. CTXXPATH indexes are also useful when CLOB portions of schema-based documents are queried. The term CLOB-based storage is used to apply to these cases. CTXXPATH indexes can also be used for existsnode() queries on schema-based XMLType columns, tables and views, as well as non-schema-based views. The term object-relational storage is used to apply to these cases.
CLOB-based storage. If the storage option used is CLOB-based storage:
Check the query mix to see if a significant fraction involves the same set of XPath expressions. If so, then Oracle Corporation recommends that you create function-based indexes for those expressions.
Check the query mix to see if a significant fraction involves existsnode() queries. CTXXPATH indexes are particularly useful if there are a large number of small documents and for existsnode() queries with low selectivity, that is, with relatively fewer number of hits. Under such scenarios, build CTXXPATH indexes.
As a general rule, the use of indexes is recommended for Online Transaction Processing (OLTP) environments with few updates.
Object-Relational storage. If the storage option is object-relational:
Check the query mix to see if a significant fraction involves XPath queries that can be rewritten. Chapter 5, " XML Schema Storage and Query: The Basics" lists the set of XPath queries that can potentially get rewritten. The set of XPath queries that are actually rewritten depends on the type of XPath query as well as the registered XML schema. B*tree, Bitmap and other relational and domain indexes can further be built to improve performance. XPath rewrite offers significant performance advantages. Use it in general. It is enabled by default.
Check the query mix to see if a significant fraction involves the same set of XPath expressions. If so, then Oracle Corporation recommends that you create function-based indexes for these expressions. In the presence of XPath rewrite, the XPath expressions are sometimes better evaluated using function-based indexes when:
The queries involve traversing through collections. For example, in extractvalue(/PurchaseOrder/Lineitems/Lineitem/Addresses/Address), multiple collections are traversed under XPath rewrite.
The queries involve returning a scalar element of a collection. For example, in extractvalue(/PurchaseOrder/PONOList/PONO[1]), a single scalar item needs to be returned, and function-based indexes are more efficient for this. In such a case, you can turn off XPath rewrite using query-level or session-level hints, and use the function-based index
Of the non-rewritten queries, check the query mix to see if a significant fraction involves existsnode() queries. If so, then you should build CTXXPATH indexes. CTXXPATH indexes are particularly useful if there are a large number of small documents, and for existsnode() queries with low selectivity, that is, with relatively fewer number of hits.
|
Note: The use of indexes is in general recommended for OLTP environments that are seldom updated. MaintainingCTXXPATH and function-based indexes when there are frequent updates adds an additional overhead. Take this into account when deciding whether function-based indexes, CTXXPATH indexes, or both should be built and maintained. When both types of indexes are built, the Oracle Database cost-based optimizer makes a cost-based decision which index to use. Try to first determine statistics on the CTXXPATH indexing in order to assist the optimizer in choosing the CTXXPATH index when appropriate. |
You can create an Oracle Text index on an XMLType column. An Oracle Text index enables the CONTAINS operator for Full Text Search over XML.
To create an Oracle Text index, use the CREATE INDEX SQL statement with the INDEXTYPE specified as shown in Example 4–36.
Example 4-36 Creating an Oracle Text Index
create index iPurchaseOrderTextIndex
on purchaseorder p (object_value)
indextype is ctxsys.context;
Index created.
You can also perform Oracle Text operations such as CONTAINS and SCORE on XMLType columns. Example 4–37 shows and Oracle Text search using CONTAINS.
Example 4-37 Searching XML Data Using CONTAINS
SELECT DISTINCT extractValue(object_value,'/PurchaseOrder/ShippingInstructions/address') "Address"
from purchaseorder
where CONTAINS(object_value,
'$(Fortieth) INPATH (PurchaseOrder/ShippingInstructions/address)') > 0;
Address
---------------------------------------------------------------
1200 East Forty Seventh Avenue
New York
NY
10024
USA
1 row selected.
|
See Also: Chapter 9 "Full Text Search Over XML" for more information on using Oracle Text operations with XML DB. |