|
|
< Free Open Study > |
|
1.7 Quiz Answer1.7.1 Reading
|
 ^cat$ ^cat$ |
Literally means: matches if the line has a beginning-of-line (which, of course, all lines have), followed immediately by c·a·t, and then followed immediately by the end of the line. Effectively means: a line that consists of only cat no extra words, spaces, punctuation... just 'cat'. |
|
^$ |
Literally means: matches if the line has a beginning-of-line, followed immediately by the end of the line. Effectively means: an empty line (with nothing in it, not even spaces). |
|
^ |
Literally means: matches if the line has a beginning-of-line. Effectively meaningless! Since every line has a beginning, every line will matcheven lines that are empty! |
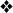 Answer to the question in Section 1.4.3
.
Answer to the question in Section 1.4.3
.
Why doesn't
q[^u]![]() match 'Qantas' or 'Iraq'?
match 'Qantas' or 'Iraq'?
Qantas didn't match because the regular expression called for a lowercase q,
whereas the Q in Qantas is uppercase. Had we used
Q[^u]![]() instead, we
would have found it, but not the others, since they don't have an uppercase
Q. The expression
[Qq][^u]
instead, we
would have found it, but not the others, since they don't have an uppercase
Q. The expression
[Qq][^u]![]() would have found them all.
would have found them all.
The Iraq example is somewhat of a trick question. The regular expression calls for q followed by a character that's not u, which precludes matching q at the end of the line. Lines generally have newline characters at the very end, but a little fact I neglected to mention (sorry!) is that egrep strips those before checking with the regular expression, so after a line-ending q, there's no non-u to be matched.
Don't feel too bad because of the trick question. [4] Let me assure you that had egrep not automatically stripped the newlines (many other tools don't strip them), or had Iraq been followed by spaces or other words or whatnot, the line would have matched. It is important to eventually understand the little details of each tool, but at this point what I'd like you to come away with from this exercise is that a character class, even negated, still requires a character to match.
[4] Once, in fourth grade, I was leading the spelling bee when I was asked to spell "miss." My answer was "m·i·s·s." Miss Smith relished in telling me that no, it was "M·i·s·s" with a capital M, that I should have asked for an example sentence, and that I was out. It was a traumatic moment in a young boy's life. After that, I never liked Miss Smith, and have since been a very poor speler.
Answer to the question in Section 1.4.9
.
In this case, "optional" means that it is allowed once, but is not required.
That means using
?![]() . Since the thing that's optional is larger than one character,
we must use parentheses:
(···)?
. Since the thing that's optional is larger than one character,
we must use parentheses:
(···)?![]() . Inserting into our expression, we get:
. Inserting into our expression, we get:
<HR( •+SIZE•*=•*[0-9]+)? •*>
Note that the ending
•*![]() is kept outside of the
(···)?
is kept outside of the
(···)?![]() . This still allows something
such as <HR•>. Had we included it within the parentheses, ending
spaces would have been allowed only when the size component was
present.
. This still allows something
such as <HR•>. Had we included it within the parentheses, ending
spaces would have been allowed only when the size component was
present.
Similarly, notice that the
•+![]() before SIZE
is included within the parentheses.
Were it left outside them, a space would have been required after the HR,
even when the SIZE part wasn't there. This would cause '<HR>' to not match.
before SIZE
is included within the parentheses.
Were it left outside them, a space would have been required after the HR,
even when the SIZE part wasn't there. This would cause '<HR>' to not match.
Answer to the question in Section 1.5.3.5
.
There are various solutions, but we can use similar logic as before. This time,
I'll break the task into three groups: one for the morning (hours 00 through
09, with the leading zero being optional), one for the daytime (hours 10
through 19), and one for the evening (hours 20 through 23). This can be
rendered in a pretty straightforward way:
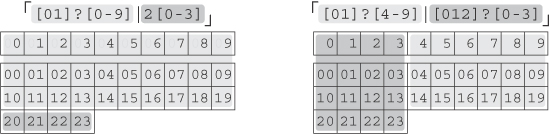
0?[0-9]|1[0-9]|2[0-3]![]() .
.
Actually, we can combine the first two alternatives, resulting in the shorter
[01]?[0-9]|2[0-3]![]() . You might need to think about it a bit to convince
yourself that they'll really match exactly the same text, but they do. The figure below might help, and it shows another approach as well. The shaded
groups represent numbers that can be matched by a single alternative.
. You might need to think about it a bit to convince
yourself that they'll really match exactly the same text, but they do. The figure below might help, and it shows another approach as well. The shaded
groups represent numbers that can be matched by a single alternative.
|
|
< Free Open Study > |
|