8.4 Sun's Regex Package
Sun's regex package, java.util.regex, comes standard with Java as of Version
1.4. It provides powerful and innovative functionality with an uncluttered (if somewhat
simplistic) class interface to its "match state" object model discussed (see Section 8.2.1.2).
It has fairly good Unicode support, clear documentation, and good efficiency.
We've seen examples of java.util.regex in earlier chapters (see Section 2.3.7.1, Section 3.2.2, Section 3.2.3.1, Section 5.4.2.1,
Section 6.3.2). We'll see more later in this chapter when we look at its object model and
how to actually put it to use, but first, we'll take a look at the regex flavor it supports,
and the modifiers that influence that flavor.
8.4.1 Regex Flavor
java.util.regex is powered by a Traditional NFA, so the rich set of lessons from
Chapters 4, 5, and 6 apply. Table 8-2 below summarizes its metacharacters.
Certain aspects of the flavor are modified by a variety of match modes,
turned on via flags to the various functions and factories, or turned on and off via
 (?
mods-mods
) (?
mods-mods
) and
(?
mods-mods:···)
modifiers embedded within the regular expression itself. The modes are listed in Table 8-3 in Section 8.4.1.
and
(?
mods-mods:···)
modifiers embedded within the regular expression itself. The modes are listed in Table 8-3 in Section 8.4.1.
A regex flavor certainly can't be described with just a tidy little table, so here are
some notes to augment Table 8-2:
The table shows "raw" backslashes, not the doubled backslashes required
when regular expressions are provided as Java string literals. For example,
\n
in the table must be written as "\\n" as a Java string. See "Strings as Regular
Expressions" (see Section 3.3.1). With the Pattern.COMMENTS option (see Section 8.4.1), #···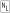 sequences are taken as comments. (Don't forget to add newlines to multiline string literals, as in the
sidebar in Section 8.4.4.2.) Unescaped ASCII whitespace is ignored. Note: unlike
most implementations that support this type of mode, comments and free
whitespace are recognized within character classes.
sequences are taken as comments. (Don't forget to add newlines to multiline string literals, as in the
sidebar in Section 8.4.4.2.) Unescaped ASCII whitespace is ignored. Note: unlike
most implementations that support this type of mode, comments and free
whitespace are recognized within character classes. Table 2. Overview of Sun's java.util.regex Flavor|
| |
|
|
Character Classes and Class-Like Constructs
|
| |
|
|
Anchors and other Zero-Width Tests
|
| |
|
|
Comments and Mode Modifiers
|
| |
|
|
Grouping, Capturing, Conditional, and Control
|
| |
|
|
(c) - may be used within a character class(See text for notes on many items) |
|
\b
is valid as a backspace only within a character class (outside, it matches a
word boundary).
\x## allows exactly two hexadecimal digits, e.g.,
\xFCber
matches '
über'.
\u#### allows exactly four hexadecimal digits, e.g.,
\u00FCber
matches '
über', and
\u20AC
matches '€'.
\0
octal
requires the leading zero, with one to three following octal digits.
\c
char
is case sensitive, blindly xoring the ordinal value of the following character with 64. This bizarre behavior means that, unlike any other regex flavor
I've ever seen, \cA and \ca are different. Use uppercase letters to get the traditional meaning of \x01. As it happens, \ca is the same as \x21, matching '!'. (The case sensitivity is scheduled to be fixed in Java 1.4.2.) Table 3. The java.util.regex Match and Regex Modes|
Compile-Time Option
|
(?mode)
|
Description
| |
Pattern.UNIX_LINES
|
d
| Changes how dot and
^
match (see Section 8.4.2) | |
Pattern.DOTALL
|
s
| Causes dot to match any character (see Section 3.3.3.2) | |
Pattern.MULTILINE
|
m
| Expands where
^
and
$
can match (see Section 8.4.2) | |
Pattern.COMMENTS
|
x
| Free-spacing and comment mode (see Section 2.3.6.2)
(Applies even inside character classes) | |
Pattern.CASE_INSENSITIVE
|
i
| Case-insensitive matching for ASCII characters | |
Pattern.UNICODE_CASE
|
u
| Case-insensitive matching for non-ASCII characters | |
Pattern.CANON_EQ
| | Unicode "canonical equivalence" match mode
(different encodings of the same
character match
as identical Section 3.3.2.2) |
\w
,
\d
, and
\s
(and their uppercase counterparts) match only ASCII characters,
and don't include the other alphanumerics, digits, or whitespace in Unicode.
That is, \d is exactly the same as [0-9], \w is the same as [0-9a-zA-Z_],
and \s is the same as [• \t\n\f\r\x0B] (\x0B is the little-used ASCII VT
character). For full Unicode coverage, you can use Unicode properties (see Section 3.4.2.4): use \p{L} for \w, use \p{Nd} for \d, and use \p{Z} for \s. (Use the \P{···} version
of each for \W, \D, and \S.)
\p{···}
and
\P{···}
support most standard Unicode properties and blocks. Unicode scripts are not supported. Only the short property names like \p{Lu} are supportedlong names like \p{Lowercase_Letter} are not supported. (see the tables in Section 3.4.2.5 and Section 3.4.2.5.) One-letter property names may omit the
braces: \pL is the same as \p{L}. Note, however, that the special composite
property \p{L&} is not supported. Also, for some reason, \p{P} does not
match characters matched by \p{Pi} and \p{Pf}. \p{C} doesn't match characters matched by \p{Cn}.
\p{all} is supported, and is equivalent to (?s:.). \p{assigned} and \p{unassigned} are not supported: use \P{Cn} and \p{Cn} instead. This package understands Unicode blocks as of Unicode Version 3.1. Blocks
added to or modified in Unicode since Version 3.1 are not known (see Section 3.3.2.2). Block names require the 'In' prefix (see the table in Section 3.4.2.6), and only the raw form unadorned with spaces and underscores may be used. For example,
\p{In_Greek_Extended} and \p{In Greek Extended} are not allowed;
\p{InGreekExtended} is required.
$
and
\Z
actually match line terminators when they should only match at the
line terminators (for example, a pattern of "(.*$)" actually captures the line
terminator). This is scheduled to be fixed in Java 1.4.1.
\G
matches the location where the current match started, despite the documentation's claim that it matches at the ending location of the previous match
(see Section 3.4.3.3).
\G
is scheduled to be fixed (to agree with the documentation and
match at the end of the previous match) in Java 1.4.1. The
\b
and
\B
word boundary metacharacters' idea of a "word character" is
not the same as \w and \W's. The word boundaries understand the properties
of Unicode characters, while \w and \W match only ASCII characters. Lookahead constructs can employ arbitrary regular expressions, but lookbehind is restricted to subexpressions whose possible matches are finite in
length. This means, for example, that
?
is allowed within lookbehind, but
*
and
+
are not. See the description in Chapter 3, starting in Section 3.4.3.6. At least until Java 1.4.2 is released, character classes with many elements are
not optimized, and so are very slow; use ranges when possible (e.g., use [0-9A-F] instead of [0123456789ABCDEF] ), and if there are characters or ranges that are likely to match more often than others, put them earlier in the class's list.
8.4.2 Using java.util.regex
The mechanics of wielding regular expressions with java.util.regex are fairly
simple. Its object model is the "match state" model discussed in Section 8.2.1.2. The
functionality is provided with just three classes:
java.util.regex.Pattern
java.util.regex.Matcher
java.util.regex.PatternSyntaxException
Informally, I'll refer to the first two simply as "Pattern" and "Matcher". In short, the Pattern object is a compiled regular expression that can be applied to any
number of strings, and a Matcher object is an individual instance of that regex
being applied to a specific target string. The third class is the exception thrown
upon the attempted compilation of an ill-formed regular expression.
Sun's documentation is sufficiently complete and clear that I refer you to it for the
complete list of all methods for these objects (if you don't have the documentation
locally, see regex.info for links). The rest of this section highlights just
the main points.
|
Traditionally, pre-Unicode regex flavors treat a newline specially with respect to
dot,
^
,
$
, and
\Z
. However, the Unicode standard suggests the larger set of "line
terminators" discussed in Chapter 3 (Section 3.3.2.2). Sun's package supports a subset of the these consisting of these five characters and one character sequence:
|
|
U
+000A
U
+000D
U
+000D
U
+000A
U
+0085
U
+2028
U
+2029
|
LF\n
CR\r
CR/LF\r\n
NEL
LS
PS
|
ASCII Line Feed
ASCII Carriage Return
ASCII Carriage Return / Line Feed
Unicode NEXT LINE
Unicode LINE SEPARATOR
Unicode PARAGRAPH SEPARATOR
|
This list is related to the dot,
^
,
$
, and
\Z
metacharacters, but the relationships
are neither constant (they change with modes), nor consistent (one would expect
^
and
$
to be treated similarly, but they are not).
Both the Pattern.UNIX_LINES and Pattern.DOTALL match modes (available
also via
(?d)
and
(?s)
) influence what dot matches.
^
can always match at the beginning of the string, but can match elsewhere
under the (?m) Pattern.MULTILINE mode. It also depends upon the
(?d)
Pattern.UNIX_LINES mode.
$
and
\Z
can always match at the end of the string, but they can also match just before certain string-ending line terminators. With the Pattern.MULTILINE
mode,
$
can match after certain embedded line terminators as well. With Java 1.4.0, Pattern.UNIX_LINES does not influence
$
and
\Z
in the same way (but it's slated to be fixed in 1.4.1 such that it does). The following table summarizes the relationships as of 1.4.0.
|
Default action, without modifiers
dot matches all but:
^ matches at beginning of line only
$
and
\Z
match before line-ending:
With Pattern.MULTILINE or (?m)
^ matches after any:
$
matches before any:
With Pattern.DOTALL or (?s)
dot matches any character |
|
|
|
|
|
|
does not apply if Pattern.UNIX_LINES or (?d) is in effect
Finally, note that there is a bug in Java 1.4.0 that is slated to be fixed in 1.4.1:
$
and
\Z
actually match the line terminators, when present, rather than
merely matching at line terminators.
|
Here's a complete example showing a simple match:
public class SimpleRegexTest {
public static void main(String[] args)
{
String sampleText = "this is the 1st test string";
String sampleRegex = "\\d+\\w+";
java.util.regex.Pattern p = java.util.regex.Pattern.compile(sampleRegex);
java.util.regex.Matcher m = p.matcher(sampleText);
if (m.find()) {
String matchedText = m.group();
int matchedFrom = m.start();
int matchedTo = m.end();
System.out.println("matched [" + matchedText + "] from " +
matchedFrom + " to " + matchedTo + ".");
} else {
System.out.println("didn't match");
}
}
}
This prints '
matched [1st] from 12 to 15.
'. As with all examples in this chapter,
names I've chosen are in italic. Notice the Matcher object, after having been
created by associating a Pattern object and a target string, is used to instigate the
actual match (with its m.find() method), and to query the results (with
m.group(), etc.).
The parts shown in bold can be omitted if
import java.util.regex.*;
or perhaps
import java.util.regex.Pattern;
import java.util.regex.Matcher;
are inserted at the head of the program, just as with the examples in Chapter 3
(see Section 3.2.2.1). Doing so makes the code more manageable, and is the standard approach.
The rest of this chapter assumes the import statement is always supplied. A more
involved example is shown in the sidebar in Section 8.4.4.3.
8.4.3 The Pattern.compile() Factory
A Pattern regular-expression object is created with Pattern.compile(···). The
first argument is a string to be interpreted as a regular expression (see Section 3.3.1). Optionally,
compile-time options shown in Table 8-3 in Section 8.4.1 can be provided as a second argument. Here's a snippet that creates a Pattern object from the string in
the variable sampleRegex, to be matched in a case-insensitive manner:
Pattern pat = Pattern.compile(sampleRegex,
Pattern.CASE_INSENSITIVE | Pattern.UNICODE_CASE);
A call to Pattern.compile(···) can throw two kinds of exceptions: an invalid regular
expression throws PatternSyntaxException, and an invalid option value
throws IllegalArgumentException.
8.4.3.1 Pattern's matcher(···) method
A Pattern object offers some convenience methods we'll look at shortly, but for
the most part, all the work is done through just one method: matcher(···). It
accepts a single argument: the string to search. It doesn't actually apply the regex,
but prepares the general Pattern object to be applied to a specific string. The
matcher(···) method returns a Matcher object.
8.4.4 The Matcher Object
Once you've associated a regular expression with a target string by creating a
Matcher object, you can instruct it to apply the regex in various ways, and query
the results of that application. For example, given a Matcher object m, the call
m.find() actually applies m's regex to its string, returning a Boolean indicating
whether a match is found. If a match is found, the call m.group() returns a string
representing the text actually matched.
The next sections list the various Matcher methods that actually apply a regex,
followed by those that query the results.
8.4.4.1 Applying the regex
Here are the main Matcher methods for actually applying its regex to its string:
-
find()
-
Applies the object's regex to the object's string, returning a Boolean indicating
whether a match is found. If called multiple times, the next match is returned
each time.
-
find(
offset
)
-
If find(···) is given an integer argument, the match attempt starts from the
given offset number of characters from the start of the string. It throws
IndexOutOfBoundsException if the offset is negative or beyond the end of
the string.
-
matches()
-
This method returns a Boolean indicating whether the object's regex exactly
matches the object's string. That is, the regex is wrapped with an implied
\A···\z
. is also available via String's matches() method. For example,"123".matches("\\d+") is true.
-
lookingAt()
-
Returns a Boolean indicating whether the object's regex matches the object's
string from its beginning. That is, the regex is applied with an implied leading
\A
. This is also available via String's matches() method. For example,
"Subject:•spam".lookingAt("^\\w+:") is true.
8.4.4.2 Querying the results
The following Matcher methods return information about a successful match.
They throw IllegalStateException if the object's regex hasn't yet been applied
to the object's string, or if the previous application was not successful. The methods
that accept a num argument (referring to a set of capturing parentheses)
throw IndexOutOfBoundsException when an invalid num is given.
-
group()
-
Returns the text matched by the previous regex application.
-
groupCount()
-
Returns the number of sets of capturing parentheses in the object's regex.
Numbers up to this value can be used in the group(
num
) method,
described next.
-
group(
num
)
-
Returns the text matched by the num
th set of capturing parentheses, or null if
that set didn't participate in the match. A num of zero indicates the entire
match, so group(0) is the same as group().
-
start(
num
)
-
Returns the offset, in characters, from the start of the string to the start of
where the num
th set of capturing parentheses matched. Returns -1 if the set
didn't participate in the match.
-
start()
-
The offset to the start of the match; this is the same as start(0).
-
end(
num
)
-
Returns the offset, in characters, from the start of the string to the end of
where the num
th set of capturing parentheses matched. Returns -1 if the set
didn't participate in the match.
-
end()
-
The offset to the end of the match; this is the same as end(0).
8.4.4.3 Reusing Matcher objects for efficiency
The whole point of having separate compile and apply steps is to increase efficiency, alleviating the need to recompile a regex with each use (see Section 6.4.3). Additional
efficiency can be gained by reusing Matcher objects when applying the same
regex to new text. This is done with the reset method, described next.
|
Here's the java.util.regex version of the CSV example from Chapter 6
(see Section 6.6.7.3). The regex has been updated to use possessive quantifiers (see Section 3.4.5.10)
for a bit of extra efficiency.
First, we set up Matcher objects that we'll use in the actual processing. The
'\n' at the end of each line is needed because we use
#···
comments, which
end at a newline.
//Prepare the regexes we'll use
Pattern pCSVmain = Pattern.compile(
" \\G(?:^|,) \n"+
" (?: \n"+
" # Either a double-quoted field... \n"+
" \" # field's opening quote \n"+
" ( (?> [^\"]*+ ) (?> \"\" [^\"]*+ )*+ ) \n"+
" \" # field's closing quote \n"+
" # ... or ... \n"+
" | \n"+
" # ... some non-quote/non-comma text ... \n"+
" ( [^\",]*+ ) \n"+
" ) \n",
Pattern.COMMENTS);
Pattern pCSVquote = Pattern.compile("\"\"");
// Now create Matcher objects, with dummy text, that we'll use later.
Matcher mCSVmain = pCSVmain.matcher("");
Matcher mCSVquote = pCSVquote.matcher("");
Then, to parse the string in csvText as CSV text, we use those Matcher
objects to actually apply the regex and use the results:
mCSVmain.reset(csvText); // Tie the target text to the mCSVmain object
while ( mCSVmain.find() )
{
String field; // We'll fill this in with $1 or $2 . . .
String first = mCSVmain.group(2);
if ( first != null )
field = first;
else {
// If $1, must replace paired double-quotes with one double quote
mCSVquote.reset(mCSVmain.group(1));
field = mCSVquote.replaceAll("\"");
}
// We can now work with field . . .
System.out.println("Field [" + field + "]");
}
This is more efficient than the similar version shown in Section 5.4.2.1 for two
reasons: the regex is more efficient (as per the Chapter 6 discussion), and
that one Matcher object is reused, rather than creating and disposing of new
ones each time (as per the discussion in Section 8.4.4.2).
|
-
reset(
text
)
-
This method reinitializes the Matcher object with the given String (or any
object that implements a CharSequence), such that the next regex operation
will start at the beginning of this text. This is more efficient than creating a
new Matcher object (see Section 8.4.4.2). You can omit the argument to keep the current text, but to reset the match state to the beginning.
Reusing the Matcher object saves the Java mechanics of disposing of the old
object and creating a new one, and requires only about one fourth the overhead
of creating a new Matcher object.
In practice, you usually need only one Matcher object per regex, at least if you
intend to apply the regex to only one string at a time, as is commonly the case.
The sidebar below shows this in action. Dummy strings are immediately
associated with each Pattern object to create the Matcher objects. It's okay
to start with a dummy string because the object's reset(···) method is called with
the real text to match against before the object is used further.
In fact, there's really no need to actually save the Pattern objects to variables,
since they're not used except to create the Matcher objects. The lines:
Pattern pCSVquote = Pattern.compile("\"\"");
Matcher mCSVquote = mCSVquote.matcher("");
can be replaced by
Matcher mCSVquote = Pattern.compile("\"\"").matcher("");
thus eliminating the pCSVquote variable altogether.
8.4.4.4 Simple search and replace
You can implement search-and-replace operations using just the methods mentioned
so far, but the Matcher object offers convenient methods to do simple
search-and-replace for you:
-
replaceAll(
replacement
)
-
The Matcher object is reset, and its regex is repeatedly applied to its string.
The return value is a copy of the object's string, with any matches replaced by
the replacement string.
This is also available via a String's replaceAll method:
string.replaceAll(regex, replacement);
is equivalent to:
Pattern.compile(regex).matcher(string).replaceAll(replacement)
-
replaceFirst(
replacement
)
-
The Matcher object is reset, and its regex is applied once to its string. The
return value is a copy of the object's string, with the first match (if any)
replaced by the replacement string.
This is also available via a String's replaceFirst method, as just described
with replaceAll.
With any of these functions, the replacement string receives special parsing:
Instances of '$1', '$2', etc., within the replacement string are replaced by the
text matched by the associated set of capturing parentheses. ($0 is replaced by
the entire text matched.)
IllegalArgumentException is thrown if the character following the '$' is not
an ASCII digit. Only as many digits after the '$' as "make sense" are used. For example, if
there are three capturing parentheses, '$25' in the replacement string is interpr
eted as $2 followed by the character '5'. However, in the same situation, '$6'
in the replacement string throws IndexOutOfBoundsException. A backslash escapes the character that follows, so use '···\$···' in the replacement
string to include a dollar sign in it. By the same token, use '···\\···' to get
a backslash into the replacement value. (And if you're providing the replacement
string as a Java string literal, that means you need "···\\\\···" to get a
backslash into the replacement value.) Also, if there are, say, 12 sets of capturing
parentheses and you'd like to include the text matched by the first set, followed
by '2', you can use a replacement value of '···$1\2···'.
8.4.4.5 Advanced search and replace
Two additional methods provide raw access to Matcher's search-and-replace
mechanics. Together, they build a result in a StringBuffer that you provide. The
first is called after each match, to fill the result with the replacement string, as well
as the text between the matches. The second is called after all matches have been
found, to tack on the text remaining after the final match.
-
appendReplacement(
stringBuffer, replacement
)
-
Called immediately after a regex has been successfully applied (e.g., with
find), this method appends two strings to the given stringBuffer : first, it
copies in the text of the original target string prior to the match. Then it
appends the replacement string, as per the special processing described in the
previous section.
For example, let's say we've got a Matcher object m that associates the regex
\w+
with the string '-->one+test<--'. The first time through this while loop:
while (m.find())
m.appendReplacement(sb,"XXX")
the find matches the underlined portion of '
-->
one+test<--'. The call to
appendReplacement fills the stringBuffer
sb with the text before the match,'-->', then bypasses what matched, instead appending the replacement string, 'XXX', to sb.
The second time through the loop, find matches '-->one+test<--'. The call
to appendReplacement appends the text before the match, '+', then again
appends the replacement string, 'XXX'.
This leaves sb with '-->XXX+XXX', and the original target string within the m
object marked at '-->one+test <--'. <--'.
-
appendTail(
stringBuffer
)
-
Called after all matches have been found (or, at least, after the desired
matches have been found you can stop early if you like), this method
appends the remaining text. Continuing the previous example,
m.appendTail(sb)
appends '<--' to sb. This leaves it with '-->XXX+XXX<--', completing the
search and replace.
Here's an example showing how you might implement your own version of
replaceAll using these. (Not that you'd want to, but it's illustrative.)
public static String replaceAll(Matcher m,String replacement)
{
m.reset(); // Be sure to start with a fresh Matcher object
StringBuffer result = new StringBuffer(); // We'll build the updated copy here
while (m.find())
m.appendReplacement(result, replacement);
m.appendTail(result);
return result.toString(); //Convert to a String and return
}
Here's a slightly more involved snippet, which prints a version of the string in the
variable Metric, with Celsius temperatures converted to Fahrenheit:
// Build a matcher to find numbers followed by "C" within the variable "Metric"
Matcher m = Pattern.compile("(\\d+(?:\\.(\\d+))?)C\\b").matcher(metric);
StringBuffer result = new StringBuffer(); // We'll build the updated copy here
while (m.find()) {
float celsius = Float.parseFloat(m.group(1)); //Get the number, as a number
int fahrenheit = (int) (celsius * 9/5 + 32); //Convert to a Fahrenheit value
m.appendReplacement(result, fahrenheit + "F"); //Insert it
}
m.appendTail(result);
System.out.println(result.toString()); //Display the result
For example, if the variable Metric contains '
from 36.3C to 40.1C.
', it displays
'
from 97F to 104F.
'.
8.4.5 Other Pattern Methods
In addition to the main compile(···) factories, the Pattern class contains some helper functions and methods that don't add new functionality, but make the current
functionality more easily accessible.
-
Pattern.matches(
pattern, text
)
-
This static function returns a Boolean indicating whether the string pattern can
match the CharSequence (e.g., String) text. Essentially, this is:
Pattern.compile(pattern).matcher(text).matches();
If you need to pass compile options, or need to gain access to more information
about the match than whether it was successful, you'll have to use the
methods described earlier.
8.4.5.1 Pattern's split method, with one argument
-
split(
text
)
-
This Pattern method accepts text (a CharSequence) and returns an array of
strings from text that are delimited by matches of the object's regex. This is
also available via a String's split method.
This trivial example
String[] result = Pattern.compile("\\.").split("209.204.146.22");
returns the array of four strings ('209', '204', '146', and '22') that are separated by
the three matches of
\.
in the text. This simple example splits on only a single literal
character, but you can split on an arbitrary regular expression. For example,
you might approximate splitting a string into "words" by splitting on non-alphanumerics:
String[] result = Pattern.compile("\\W+").split(Text);
When given a string like 'What's up, Doc' it returns the four strings ('What', 's',
'up', and 'Doc') delimited by the three matches of the regex. (If you had non-ASCII
text, you'd probably want to use
\P{L}+
, or perhaps
[^\p{L}\p{N}_]
, as the
regex, instead of
\W+
see Section 8.4.1.)
Empty elements with adjacent matches
If the object's regex can match at the beginning of the text, the first string returned
by split is an empty string (a valid string, but one that contains no characters).
Similarly, if the regex can match two or more times in a row, empty strings are
returned for the zero-length text "separated" by the adjacent matches. For
example,
String[] result = Pattern.compile("\\s*,\\s*").split(", one, two , ,, 3");
splits on a comma and any surrounding whitespace, returning an array of five
strings: an empty string, 'one', 'two', two empty strings, and '3'.
Finally, any empty strings that might appear at the end of the list are suppressed:
String[] result = Pattern.compile(":").split(":xx:");
This produces just two strings: an empty string and 'xx'. To keep trailing empty
elements, use the two-argument version of split(···), described next.
8.4.5.2 Pattern's split method, with two arguments
-
split(
text, limit
)
-
This version of split(···) provides some control over how many times the Pattern's regex is applied, and what is done with trailing empty elements.
The limit argument takes on different meanings depending on whether it's less
than zero, zero, or greater than zero.
Split with a limit less than zero
Any limit less than zero means to keep trailing empty elements in the array. Thus,
String[] result = Pattern.compile(":").split(":xx:", -1);
returns an array of three strings (an empty string, 'xx', and another empty string).
Split with a limit of zero
An explicit limit of zero is the same as if there were no limit given, i.e., trailing
empty elements are suppressed.
Split with a limit greater than zero
With a limit greater than zero, split(···) returns an array of at most limit
elements. This means that the regex is applied at most limit -1 times. (A limit of
three, for example, requests three strings separated by two matches.)
After having matched limit -1 times, no further matches are checked, and the entire
remainder of the string after the final match is returned as the last string in the
array. For example, if you had a string with
Friedl,Jeffrey,Eric Francis,America,Ohio,Rootstown
and wanted to isolate just the three name components, you'd split the string into
four parts (the three name components, and one final "everything else" string):
String[] NameInfo = Pattern.compile(",").split(Text, 4);
// NameInfo[0] is the family name
// NameInfo[1] is the given name
// NameInfo[2] is the middle name (or in my case, middle names)
// NameInfo[3] is everything else, which we don't need, so we'll just ignore it.
The reason to limit split in this way is for enhanced efficiency why bother
going through the work of finding the rest of the matches, creating new strings,
making a larger array, etc., when there's no intention to use the results of that
work? Supplying a limit allows just the required work to be done.
|