|
|
< Free Open Study > |
|
3.4 Common Metacharacters and FeaturesThe following overview of current regex metacharacters covers common items and concepts. It doesn't discuss every issue, and no one tool includes everything presented here. In one respect, this is just a summary of much of what you've seen in the first two chapters, but in light of the wider, more complex world presented at the beginning of this chapter. During your first pass through this section, a light glance should allow you to continue on to the next chapters. You can come back here to pick up details as you need them. Some tools add a lot of new and rich functionality and some gratuitously change common notations to suit their whim or special needs. Although I'll sometimes comment about specific utilities, I won't address too many tool-specific concerns here. Rather, in this section I'll just try to cover some common metacharacters and their uses, and some concerns to be aware of. I encourage you to follow along with the manual of your favorite utility. The following is an outline of the constructs covered in this section, with pointers to the page where each sub-section starts:
3.4.1 Character RepresentationsThis group of metacharacters provides visually pleasing ways to match specific characters that are otherwise difficult to represent. 3.4.1.1 Character shorthandsMany utilities provide metacharacters to represent certain control characters that are sometimes machine-dependent, and which would otherwise be difficult to input or to visualize:
Table 3-6 lists a few common tools and some of the control shorthands they provide. As discussed earlier, some languages also provide many of the same shorthands for the string literals they support. Be sure to review that section (see Section 3.3) for some of the associated pitfalls. 3.4.1.2 These are machine dependent?As noted in the list, \n and \r are operating-system dependent in many tools,[10] so,
it's best to choose carefully when you use them. When you need, for example, "a newline" for whatever system your script will happen to run on, use \n. When
you need a character with a specific value, such as when writing code for a
defined protocol like HTTP, use \012 or whatever the standard calls for. (\012 is
an octal escape.) If you wish to match DOS line-ending characters, use
3.4.1.3 Octal escape\numImplementations supporting octal (base 8) escapes generally allow two- and threedigit
octal escapes to be used to indicate a byte or character with a particular
value. For example, Table 3-7 shows the octal escapes some tools support. Some implementations, as a special case, allow You might wonder what happens with out-of-range values like \565 (8-bit octal values range from \000 to \377). It seems that half the implementations leave it as a larger-than-byte value (which may match a Unicode character if Unicode is supported), while the other half strip it to a byte. In general, it's best to limit octal escapes to \377 and below. 3.4.1.4 Hex and Unicode escapes: \xnum, \x{num}, \unum, \Unum, ...Similar to octal escapes, many utilities allow a hexadecimal (base 16) value to be
entered using \x, \u, or sometimes \U. If allowed with \x, for example,
Besides the question of which escape is used, you must also know how many digits they recognize, and if braces may be (or must be) used around the digits. These are also indicated in Table 3-7. 3.4.1.5 Control characters: \ccharMany flavors offer the Details aren't uniform among systems that offer this construct. You'll always be safe using uppercase English letters as in the examples. With most implementations, you can use lowercase letters as well, but Sun's Java regex package, for example, does not support them. And what exactly happens with non-alphabetics is very flavor-dependent, so I recommend using only uppercase letters with \c. Related Note: GNU Emacs supports this functionality, but with the rather ungainly
metasequence
3.4.2 Character Classes and Class-Like ConstructsModern flavors provide a number of ways to specify a set of characters allowed at a particular point in the regex, but the simple character class is ubiquitous. 3.4.2.1 Normal classes: [a-z] and [^a-z]The basic concept of a character class has already been well covered, but let me
emphasize again that the metacharacter rules change depending on whether
you're in a character class or not. For example, With most systems, the order that characters are listed in a class makes no difference, and using ranges instead of listing characters is irrelevant to the execution speed (e.g., [0-9] should be no different from [9081726354]). However, some implementations don't completely optimize classes (Sun's Java regex package comes to mind), so it's usually best to use ranges, which tend to be faster, wherever possible. A character class is always a positive assertion. In other words, it must always
match a character to be successful. A negated class must still match a character,
but one not listed. It might be convenient to consider a negated character class to
be a "class to match characters not listed." (Be sure to see the warning about dot
and negated character classes, in the next section.) It used to be true that something
like Be sure to understand the underlying character set when using ranges. For example,
3.4.2.2 Almost any character: dotIn some tools, dot is a shorthand for a character class that can match any character, while in most others, it is a shorthand to match any character except a newline. It's a subtle difference that is important when working with tools that allow target text to contain multiple logical lines (or to span logical lines, such as in a text editor). Concerns about dot include:
3.4.2.3 Dot versus a negated character classWhen working with tools that allow multiline text to be searched, take care to
note that dot usually does not match a newline, while a negated class like 3.4.2.4 Class shorthands: \w, \d, \s, \W, \D, \SSupport for the following shorthands is quite common:
As described in Section 3.1.1.5, a POSIX locale could influence the meaning of these
shorthands (in particular, 3.4.2.5 Unicode properties, scripts, and blocks: \p{Prop}, \P{Prop}On its surface, Unicode is a mapping (see Section 3.3.2.2), but the Unicode Standard offers much more. It also defines qualities about each character, such as "this character is a lowercase letter," "this character is meant to be written right-to-left," "this character is a mark that's meant to be combined with another character," etc. Regular-expression support for these qualities varies, but many Unicode-enabled
programs support matching via at least some of them with The general properties are shown in Table 3-8. Each character (each code point actually, which includes those that have no characters defined) can be matched by just one general property. The general property names are one character ('L' for Letter, 'S' for symbol, etc.), but some systems support a more descriptive synonym ('Letter', 'Symbol', etc.) as well. Perl, for example, supports these.
With some systems, single-letter property names may be referenced without the
curly braces (e.g., using
Each one-letter general Unicode property can be further subdivided into a set of
two-letter sub-properties, as shown in Table 3-9. Additionally, some implementations
support a special composite sub-property, Also shown are the full-length synonyms (e.g., "Lowercase_Letter" instead of "Ll"), which may be supported by some implementations. The standard suggests that a variety of forms be accepted ('LowercaseLetter', 'LOWERCASE_LETTER', 'Lowercase•Letter', 'lowercase-letter', etc.), but I recommend, for consistency, always using the form shown in Table 3-9.
Scripts. Some systems have support for matching via a script (writing system)
name with Some scripts are language-based (such as Gujarati, Thai, Cherokee, ...). Some span multiple languages (e.g., Latin, Cyrillic), while some languages are composed of multiple scripts, such as Japanese, which uses characters from the Hiragana, Katakana, Han ("Chinese Characters"), and Latin scripts. See your system's documentation for the full list.
A script does not include all characters used by the particular writing system, but
rather, all characters used only (or predominantly) by that writing system. Common
characters, such as spacing and punctuation marks, are not included within
any script, but rather are included as part of the catch-all pseudo-script IsCommon,
matched by Blocks. Similar (but inferior) to scripts, blocks refer to ranges of code points on the Unicode character map. For example, the Tibetan block refers to the 256 code points from U+0F00 through U+0FFF. Characters in this block are matched with \p{InTibetan} in Perl and java.util.regex, and with \p{IsTibetan} in .NET. (More on this in a bit.) There are many blocks, including blocks for most systems of writing (Hebrew, Tamil, Basic_Latin, Hangul_Jamo, Cyrillic, Katakana, ...), and for special character types (Currency, Arrows, Box_Drawing, Dingbats, ...). Tibetan is one of the better examples of a block, since all characters in the block that are defined relate to the Tibetan language, and there are no Tibetan-specific characters outside the block. Block qualities, however, are inferior to script qualities for a number of reasons:
Support for block qualities is more common than for script qualities. There is ample room for getting the two confused because there is a lot of overlap in the naming (for example, Unicode provides for both a Tibetan script and a Tibetan block). Furthermore, as Table 3-10 shows, the nomenclature has not
yet been standardized. With Perl and java.util.regex, the Tibetan block is
Other properties/qualities. Not everything talked about so far is universally supported. Table 3-10 gives a few details about what's been covered so far. Additionally, Unicode defines many other qualities that might be accessible via the
3.4.2.6 Class set operations: [[a-z]&&[^aeiou]]Sun's Java regex package supports set operations within character classes. For example, you can match all non-vowel English letters with "[a-z] minus [aeiou]". The nomenclature for this may seem a bit odd a first it's written as [[a-z]&&[^aeiou]] , and read aloud as "this and not that." Before looking at that in more detail, let's look at the two basic class set operations, OR and AND. OR allows you to add characters to the class by including what looks like an embedded class within the class: [abcxyz] can also be written as [[abc][xyz]] , [abc[xyz]] , or [[abc]xyz] , among others. OR combines sets, creating a new set that is the sum of the argument sets. Conceptually, it's similar to the "bitwise or" operator that many languages have via a '|' or 'or' operator. In character classes, OR is mostly a notational convenience, although the ability to include negated classes can be useful in some situations. AND does a conceptual "bitwise AND" of two sets, keeping only those characters found in both sets. It is achieved by inserting the special class metasequence && between two sets of characters. For example, [\p{InThai}&&\P{Cn}] matches all assigned code points in the Thai block. It does this by taking the intersection between (i.e., keeping only characters in both) \p{InThai} and \P{Cn}. Remember, \P{···} with a capital 'P', matches everything not part of the quality, so \P{Cn} matches everything not unassigned, which in other words, means is assigned. (Had Sun supported the Assigned quality, I could have used \p{Assigned} instead of \P{Cn} in this example.) Be careful not to confuse OR and AND. How intuitive these names feel depends on your point of view. For example, [[this][that]] in normally read "accept characters that match [this] or[that]," yet it is equally true if read "the list of characters to allow is [this] and[that]." Two points of view for the same thing. AND is less confusing in that [\p{InThai}&&\P{Cn}] is normally read as "match only characters matchable by \p{InThai} and \P{Cn}," although it is sometimes read as "the list of allowed characters is the intersection of \p{InThai} and \P{Cn}." These differing points of view can make talking about this confusing: what I call OR and AND, some might choose to call AND and INTERSECTION. Class subtraction. Thinking further about the [\p{InThai}&&\P{Cn}] example, it's useful to realize that \P{Cn} is the same as [^\p{Cn}], so the whole thing can be rewritten as the somewhat more complex looking [\p{InThai}&&[^\p{Cn}]] . Furthermore, matching "assigned characters in the Thai block" is the same as "characters in the Thai block, minus unassigned characters." The double negative makes it a bit confusing, but it shows that [ \p{InThai} && [^\p{Cn} ]] means " \p{InThai} minus \p{Cn} ." This brings us back to the
Mimicking class set operations with lookaround. If your program doesn't
support class set operations, but does support lookaround (see Section 3.4.3.6), you can mimic
the set operations. With lookahead,
(?!\p{Cn})\p{InThai}
(?=\P{Cn})\p{InThai}
\p{InThai}(?<!\p{Cn})
\p{InThai}(?<=\P{Cn})
3.4.2.7 Unicode combining character sequence: \XPerl supports As discussed earlier (see Section 3.3.2.2), Unicode uses a system of base and combining characters
which, in combination, create what look like single, accented characters like
à ('a' U+0061 combined with the grave accent '`' U+0300). You can use more than
one combining character if that's what you need to create the final result. For
example, if for some reason you need 'ç If you wanted to match either "francais" or "français," it wouldn't be safe to just use
Besides the fact that 3.4.2.8 POSIX bracket-expression "character class": [[:alpha:]]What we normally call a character class, the POSIX standard calls a bracket expression. POSIX uses the term "character class" for a special feature used within a bracket expression[13] that we might consider to be the precursor to Unicode's character properties.
A POSIX character class is one of several special metasequences for use within a
POSIX bracket expression. An example is [:lower:], which represents any lowercase
letter within the current locale (see Section 3.1.1.5). For English text, [:lower:] is comparable to a-z. Since this entire sequence is valid only within a bracket
expression, the full class comparable to The exact list of POSIX character classes is locale dependent, but the following are usually supported:
Systems that support Unicode properties (see Section 3.4.2.5) may or may not extend that Unicode support to these POSIX constructs. The Unicode property constructs are more powerful, so those should generally be used if available. 3.4.2.9 POSIX bracket-expression "collating sequences": [[.span-ll.]]A locale can have collating sequences to describe how certain characters or sets of characters should be ordered. For example, in Spanish, the two characters ll (as in tortilla) traditionally sort as if it were one logical character between l and m, and the German ß is a character that falls between s and t, but sorts as if it were the two characters ss. These rules might be manifested in collating sequences named, for example, span-ll and eszet. A collating sequence that maps multiple physical characters to a single logical
character, such as the span-ll example, is considered "one character" to a fully
compliant POSIX regex engine. This means that something like A collating sequence element is included within a bracket expression using a
[.···.] notation: 3.4.2.10 POSIX bracket-expression "character equivalents": [[=n=]]Some locales define character equivalents to indicate that certain characters should
be considered identical for sorting and such. For example, a locale might define an equivalence class 'n' as containing n and ñ, or perhaps one named 'a' as containing
a, à, and á. Using a notation similar to [:···:], but with '=' instead of a
colon, you can reference these equivalence classes within a bracket expression:
If a character equivalence with a single-letter name is used but not defined in the
locale, it defaults to the collating sequence of the same name. Locales normally
include normal characters as collating sequences [.a.], [.b.], [.c.], and so
onso in the absence of special equivalents, 3.4.2.11 Emacs syntax classesGNU Emacs doesn't support the traditional
Emacs is special because the choice of which characters fall into these classes can be modified on the fly, so, for example, the concept of which characters are word constituents can be changed depending upon the kind of text being edited. 3.4.3 Anchors and Other "Zero-Width Assertions"Anchors and other "zero-width assertions" don't match actual text, but rather positions in the text. 3.4.3.1 Start of line/string: ^, \ACaret When supported, 3.4.3.2 End of line/string: $, \Z, \zAs Table 3-11 below shows, the concept of "end of line" can be a bit
more complex than its start-of-line counterpart. Two other common meanings for A match mode (see Section 3.3.3.4) can change the meaning of When supported,
3.4.3.3 Start of match (or end of previous match): \G
If a match is not successful, the location at which Perl's
See the sidebar below for an example of these features in action.
Despite these convenient features, Perl's 3.4.3.4 End of previous match, or start of the current match?One detail that differs among implementations is whether
One side effect of the transmission having to step in this way is that the "end of
the previous match" then differs from "the start of the current match." When this
happens, the question becomes: which of the two locations does On the other hand, applying the same search-and-replace with some other tools
yields the original '!a!b!c!d!e!', showing that their You can't always rely on the documentation that comes with a tool to tell you
which is which, as I've found that both Microsoft's .NET and Sun's Java documentation
are incorrect. My testing has shown that java.util.regex and Ruby have
3.4.3.5 Word boundaries: \b, \B, \<, \>, ...Like line anchors, word-boundary anchors match a location in the string. There are two distinct approaches. One provides separate metasequences for start- and end-of- word boundaries (often \< and \>), while the other provides ones catch-all word boundary metasequence (often \b). Either generally provides a not-word-boundary metasequence as well (often \B). Table 3-12 shows a few examples. Tools that don't provide separate start- and end-of-word anchors, but do support lookaround, can mimic word-boundary anchors with the lookaround. In the table, I've filled in the otherwise empty spots that way, wherever practical. A word boundary is generally defined as a location where there is a "word character"
on one side, and not on the other. Each tool has its own idea of what constitutes
a "word character," as far as word boundaries go. It would make sense if the
word boundaries agree with \w, but that's not always the case. With Sun's Java
regex package, for example, \w applies only to ASCII and not the full Unicode that
Java supports, so in the table I've used lookaround with the Unicode letter property
\pL (which is a shorthand for Whatever the word boundaries consider to be "word characters," word boundary tests are always a simple test of adjoining characters. No regex engine actually does linguistic analysis to decide about words: all consider "NE14AD8" to be a word, but not "M.I.T."
3.4.3.6 Lookahead (?=···), (?!···); Lookbehind, (?<=···), (?<!···)Lookahead and lookbehind constructs (collectively, lookaround) are discussed with an extended example in the previous chapter's "Adding Commas to a Number with Lookaround" (see Section 2.3.5). One important issue not discussed there relates to what kind of expression can appear within either of the lookbehind constructs. Most implementations have restrictions about the length of text matchable within lookbehind (but not within lookahead, which is unrestricted). The most restrictive rule exists in Perl and Python, where the lookbehind can
match only fixed-length strings. For example, (?<!\w) and (?<!this|that) are
allowed, but (?<!books?) and (?<!^\w+:) are not, as they can match a variable
amount of text. In some cases, such as with (?<!books?), you can accomplish
the same thing by rewriting the expression, as with The next level of support allows alternatives of different lengths within the lookbehind, so (?<!books?) can be written as (?<!book|books). PCRE (and the pcre routines in PHP) allows this. The next level allows for regular expressions that match a variable amount of text, but only if it's of a finite length. This allows (?<!books?) directly, but still disallows (?<!^\w+:) since the \w+ is open-ended. Sun's Java regex package supports this level. When it comes down to it, these first three levels of support are really equivalent, since they can all be expressed, although perhaps somewhat clumsily, with the most restrictive fixed-length matching level of support. The intermediate levels are just "syntactic sugar" to allow you to express the same thing in a more pleasing way. The fourth level, however, allows the subexpression within lookbehind to match any amount of text, including the (?<!^\w+:) example. This level, supported by Microsoft's .NET languages, is truly superior to the others, but does carry a potentially huge efficiency penalty if used unwisely. (When faced with lookbehind that can match any amount of text, the engine is forced to check the lookbehind subexpression from the start of the string, which may mean a lot of wasted effort when requested from near the end of a long string.) 3.4.4 Comments and Mode ModifiersWith many flavors, the regex modes and match modes described earlier (see Section 3.3.3) can be modified within the regex (on the fly, so to speak) by the following constructs. 3.4.4.1 Mode modifier: (?modifier), such as (?i) or (?-i)Many flavors now allow some of the regex and match modes (see Section 3.3.3) to be set
within the regular expression itself. A common example is the special notation
This example works with most systems that support Actually, that last PHP example can be simplified a bit because with many implementations
(including PHP's), when The mode-modifier constructs support more than just 'i'. With most systems, you can use at least those shown in Table 3-13.
Some systems have additional letters for additional functions. Tcl has a number of different letters for turning its various modes on and off see its documentation for the complete list. 3.4.4.2 Mode-modified span: (?modifier:···), such as (?i:···)The example from the previous section can be made even simpler for systems that
support a mode-modified span. Using a syntax like When supported, this form generally works for all mode-modifier letters the system
supports. Tcl and Python are two examples that support the 3.4.4.3 Comments: (?#···) and #···Some flavors support comments via 3.4.4.4 Literal-text span: \Q···\EFirst introduced with Perl, the special sequence \Q···\E turns off all regex metacharacters between them, except for \E itself. (If the \E is omitted, they are turned off until the end of the regex.) It allows what would otherwise be taken as normal metacharacters to be treated as literal text. This is especially useful when including the contents of a variable while building a regular expression. For example, to respond to a web search, you might accept what the user types as $query, and search for it with m/$query/i. As it is, this would certainly have unexpected results if $query were to contain, say, 'C:\WINDOWS\', which results in a run-time error because the search term contains something that isn't a valid regular expression (the trailing lone backslash). To get around this, you could use m/\Q$query\E/i, which effectively turns 'C:\WINDOWS\' into 'C:\\WINDOWS\\', resulting in a search that finds 'C:\WINDOWS\' as the user expects. This kind of feature is less useful in systems with procedural and object-oriented handling (see Section 3.2.2), as they accept normal strings. While building the string to be used as a regular expression, it's fairly easy to call a function to make the value from the variable "safe" for use in a regular expression. In VB, for example, one would use the Regex.Escape method. Currently, the only regex engine I know of that fully supports 3.4.5 Grouping, Capturing, Conditionals, and Control3.4.5.1 Capturing/Grouping Parentheses: (···) and \1, \2, ...Common, unadorned parentheses generally perform two functions, grouping and
capturing. Common parentheses are almost always of the form Capturing parentheses are numbered by counting their opening parentheses from
the left, as shown in figures in Section 2.2.2, Section 2.2.3, and Section 2.3.4. If backreferences are available,
the text matched via an enclosed subexpression can itself be matched later in
the same regular expression with One of the most common uses of parentheses is to pluck data from a string. The
text matched by a parenthesized subexpression (also called "the text matched by
the parentheses") is made available after the match in different ways by different
programs, such as Perl's $1, $2, etc. (A common mistake is to try to use the Table 3-14 below shows how a number of programs make the captured text available after a match. It shows how to access the text matched by the whole expression, and the text matched by a set of capturing parentheses.
3.4.5.2 Grouping-only parentheses: (?:···)Now supported by many common flavors, grouping-only parentheses Non-capturing parentheses are useful for a number of reasons. They can help make the use of a complex regex more clear in that the reader doesn't need to wonder if what's matched by what they group is accessed elsewhere by $1 or the like. They can also be more efficient if the regex engine doesn't need to keep track of the text matched for capturing purposes, it can work faster and use less memory. (Efficiency is covered in detail in Chapter 6.) Non-capturing parentheses are useful when building up a regex from parts. Recall the example from Section 2.3.6.7, where the variable $HostnameRegex holds a regex to match a hostname. Imagine now using that to pluck out the whitespace around a hostname, as in the Perl snippet m/(\s*)$HostnameRegex(\s*)/ . After this, you might expect $1 to hold any leading whitespace, and $2 to hold trailing whitespace, but that's not the case: the trailing whitespace is actually in $4 because the definition of $HostnameRegex uses two sets of capturing parentheses: $HostnameRegex = qr/[-a-z0-9]+(\.[-a-z0-9]+)*\.(com|edu|info)/i; Were those sets of parentheses non-capturing instead, $HostnameRegex could be used without generating this surprise: $HostnameRegex = qr/[-a-z0-9]+(?:\.[-a-z0-9]+)*\.(?:com|edu|info)/i; Another way to avoid the surprise, although not available in Perl, is to use named capture, discussed next. 3.4.5.3 Named capture: (?<Name>···)Python and .NET languages support captures to named locations. Python uses the
syntax
This "fills the names" Area, Exch, and Num with the components of a phone number. The program can then refer to each matched substring through its name, for example, RegexObj.Groups("Area") in VB.NET and most other .NET languages, RegexObj.Groups["Area"] in C#, and RegexObj.group("Area") in Python. The result is clearer code. Within the regular expression itself, the captured text is available via You can use the same name more than once within the same expression. For
example, to match an area code that looks like '(###)' as well as '###-', you might
use 3.4.5.4 Atomic grouping: (?>···)Atomic grouping, The regex This example gives no hint to the usefulness of atomic grouping, but atomic grouping has important uses. In particular, they can help make matching more efficient (see Section 4.5.6.1.1), and can be used to finely control what can and can't be matched (see Section 6.6.6.1). 3.4.5.5 Alternation: ···|···|···Alternation allows several subexpressions to be tested at a given point. Each
subexpression is called an alternative. The Alternation is a high-level construct (one that has very low precedence) in almost
all regex flavors. This means that Most flavors allow an empty alternative, like with
3.4.5.6 Conditional: (?if then |else)This construct allows you to express an if/then/else within a regex. The if part is a special kind of conditional expression discussed in a moment. Both the then and else parts are normal regex subexpressions. If the if part tests true, the then expression is attempted. Otherwise, the else part is attempted. (The else part my be omitted, and if so, the '|' before it may be omitted as well.) The kinds of if tests available are flavor-dependent, but most implementations allow at least special references to capturing subexpressions and lookaround. Using a special reference to capturing parentheses as the test. If the if part is a number in parentheses, it evaluates to "true" if that numbered set of capturing parentheses has participated in the match to this point. Here's an example that matches an <IMG> HTML tag, either alone, or surrounded by <A>···</A> link tags. It's shown in a free-spacing mode with comments, and the conditional construct (which in this example has no else part) is bold:
( <A\s+[^>]+> \s* )? # Match leading <A> tag, if there.
<IMG\s+[^>]+> # Match <IMG> tag.
(?(1)\s*</A>) # Match a closing </A>, if we'd matched an <A> before.
The (1) in Consider these two approaches to matching a word optionally wrapped in "<···>":
If named capture (see Section 3.4.5.3) is supported, you can generally use the name in parentheses instead of the number.
Using lookaround as the test. A full lookaround construct, such as Other tests for the conditional. Perl adds an interesting twist to this conditional construct by allowing arbitrary Perl code to be executed as the test. The return value of the code is the test's value, indicating whether the then or else part should be attempted. This is covered in Chapter 7, in Section 7.8. 3.4.5.7 Greedy quantifiers: *, +, ?, {num,num}The quantifiers (star, plus, question mark, and intervalsmetacharacters that affect
the quantity of what they govern) have already been discussed extensively. However,
note that in some tools, 3.4.5.8 Intervals{min,max} or \{min,max \}Intervals can be considered a "counting quantifier" because you specify exactly the
minimum number of matches you wish to require, and the maximum number of
matches you wish to allow. If only a single number is given (such as in One caution: don't think you can use something like
3.4.5.9 Lazy quantifiers: *?, +?, ??, {num,num}?Some tools offer the rather ungainly looking *?, +?, ??, and { min,max }?. These are the lazy versions of the quantifiers. (They are also called minimal matching, non-greedy, and ungreedy.) Quantifiers are normally "greedy," and try to match as much as possible. Conversely, these non-greedy versions match as little as possible, just the bare minimum needed to satisfy the match. The difference has farreaching implications, covered in detail in the next chapter (see Section 4.4.2). 3.4.5.10 Possessive quantifiers: *+, ++, ?+, {num,num}+Currently supported only by java.util.regex, but likely to gain popularity, possessive quantifiers are like normally greedy quantifiers, but once they match something, they never "give it up." Like the atomic grouping to which they're related, understanding possessive quantifiers is much easier once the underlying match process is understood (which is the subject of the next chapter). In one sense, possessive quantifiers are just syntactic sugar, as they can be mimicked
with atomic grouping. Something like | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
< Free Open Study > |
|
 \b
\b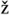 is the title case of the lowercase d
is the title case of the lowercase d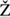 ).
).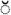 ', that would be 'c' followed by a combining
cedilla '¸' and a combining breve '
', that would be 'c' followed by a combining
cedilla '¸' and a combining breve ' abcde', but
doesn't actually match any text. In a global search-and-replace situation, where the
regex is applied repeatedly, picking up each time from where it left off, unless the
transmission does something special, the "where it left off" will always be the
same as where it started. To avoid an infinite loop, the transmission forcefully
bumps along to the next character when it recognizes this situation. You can see
this by applying s/x?/!/g to 'abcde', yielding '!a!b!c!d!e!'.
abcde', but
doesn't actually match any text. In a global search-and-replace situation, where the
regex is applied repeatedly, picking up each time from where it left off, unless the
transmission does something special, the "where it left off" will always be the
same as where it started. To avoid an infinite loop, the transmission forcefully
bumps along to the next character when it recognizes this situation. You can see
this by applying s/x?/!/g to 'abcde', yielding '!a!b!c!d!e!'.