| Oracle® Database Utilities 10g Release 1 (10.1) Part Number B10825-01 |
|





|
View PDF |
| Oracle® Database Utilities 10g Release 1 (10.1) Part Number B10825-01 |
|
|
View PDF |
This chapter describes SQL*Loader's conventional and direct path load methods. The following topics are covered:
For an example of using the direct path load method, see Case Study 6: Loading Data Using the Direct Path Load Method. The other cases use the conventional path load method.
SQL*Loader provides two methods for loading data:
A conventional path load executes SQL INSERT statements to populate tables in an Oracle database. A direct path load eliminates much of the Oracle database overhead by formatting Oracle data blocks and writing the data blocks directly to the database files. A direct load does not compete with other users for database resources, so it can usually load data at near disk speed. Considerations inherent to direct path loads, such as restrictions, security, and backup implications, are discussed in this chapter.
The tables to be loaded must already exist in the database. SQL*Loader never creates tables. It loads existing tables that either already contain data or are empty.
The following privileges are required for a load:
You must have INSERT privileges on the table to be loaded.
You must have DELETE privileges on the table to be loaded, when using the REPLACE or TRUNCATE option to empty old data from the table before loading the new data in its place.
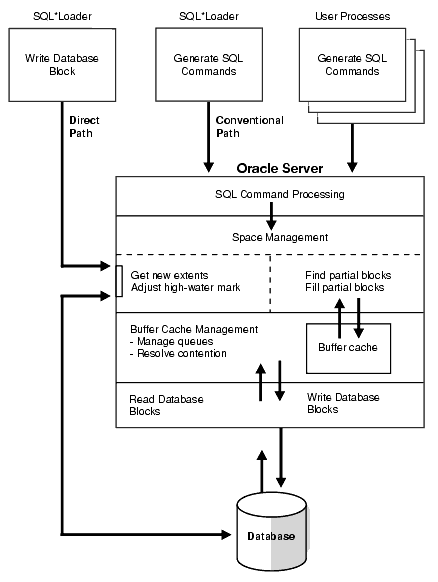
Figure 11-1 shows how conventional and direct path loads perform database writes.
Figure 11-1 Database Writes on SQL*Loader Direct Path and Conventional Path
In both conventional path and direct path, you can specify a text value for a ROWID column. (This is the same text you get when you perform a SELECT ROWID FROM table_name operation.) The character string interpretation of the ROWID is converted into the ROWID type for a column in a table.
Conventional path load (the default) uses the SQL INSERT statement and a bind array buffer to load data into database tables. This method is used by all Oracle tools and applications.
When SQL*Loader performs a conventional path load, it competes equally with all other processes for buffer resources. This can slow the load significantly. Extra overhead is added as SQL statements are generated, passed to Oracle, and executed.
The Oracle database looks for partially filled blocks and attempts to fill them on each insert. Although appropriate during normal use, this can slow bulk loads dramatically.
By definition, a conventional path load uses SQL INSERT statements. During a conventional path load of a single partition, SQL*Loader uses the partition-extended syntax of the INSERT statement, which has the following form:
INSERT INTO TABLE T PARTITION (P) VALUES ...
The SQL layer of the Oracle kernel determines if the row being inserted maps to the specified partition. If the row does not map to the partition, the row is rejected, and the SQL*Loader log file records an appropriate error message.
If load speed is most important to you, you should use direct path load because it is faster than conventional path load. However, certain restrictions on direct path loads may require you to use a conventional path load. You should use a conventional path load in the following situations:
When accessing an indexed table concurrently with the load, or when applying inserts or updates to a nonindexed table concurrently with the load
To use a direct path load (with the exception of parallel loads), SQL*Loader must have exclusive write access to the table and exclusive read/write access to any indexes.
When loading data into a clustered table
A direct path load does not support loading of clustered tables.
When loading a relatively small number of rows into a large indexed table
During a direct path load, the existing index is copied when it is merged with the new index keys. If the existing index is very large and the number of new keys is very small, then the index copy time can offset the time saved by a direct path load.
When loading a relatively small number of rows into a large table with referential and column-check integrity constraints
Because these constraints cannot be applied to rows loaded on the direct path, they are disabled for the duration of the load. Then they are applied to the whole table when the load completes. The costs could outweigh the savings for a very large table and a small number of new rows.
When loading records and you want to ensure that a record is rejected under any of the following circumstances:
If the record, upon insertion, causes an Oracle error
If the record is formatted incorrectly, so that SQL*Loader cannot find field boundaries
If the record violates a constraint or tries to make a unique index non-unique
Instead of filling a bind array buffer and passing it to the Oracle database with a SQL INSERT statement, a direct path load uses the direct path API to pass the data to be loaded to the load engine in the server. The load engine builds a column array structure from the data passed to it.
The direct path load engine uses the column array structure to format Oracle data blocks and build index keys. The newly formatted database blocks are written directly to the database (multiple blocks per I/O request using asynchronous writes if the host platform supports asynchronous I/O).
Internally, multiple buffers are used for the formatted blocks. While one buffer is being filled, one or more buffers are being written if asynchronous I/O is available on the host platform. Overlapping computation with I/O increases load performance.
During a direct path load, data conversion occurs on the client side rather than on the server side. This means that NLS parameters in the initialization parameter file (server-side language handle) will not be used. To override this behavior, you can specify a format mask in the SQL*Loader control file that is equivalent to the setting of the NLS parameter in the initialization parameter file, or set the appropriate environment variable. For example, to specify a date format for a field, you can either set the date format in the SQL*Loader control file as shown in Example 11-1 or set an NLS_DATE_FORMAT environment variable as shown in Example 11-2.
When loading a partitioned or subpartitioned table, SQL*Loader partitions the rows and maintains indexes (which can also be partitioned). Note that a direct path load of a partitioned or subpartitioned table can be quite resource-intensive for tables with many partitions or subpartitions.
|
Note: If you are performing a direct path load into multiple partitions and a space error occurs, the load is rolled back to the last commit point. If there was no commit point, then the entire load is rolled back. This ensures that no data encountered after the space error is written out to a different partition.You can use the |
When loading a single partition of a partitioned or subpartitioned table, SQL*Loader partitions the rows and rejects any rows that do not map to the partition or subpartition specified in the SQL*Loader control file. Local index partitions that correspond to the data partition or subpartition being loaded are maintained by SQL*Loader. Global indexes are not maintained on single partition or subpartition direct path loads. During a direct path load of a single partition, SQL*Loader uses the partition-extended syntax of the LOAD statement, which has either of the following forms:
LOAD INTO TABLE T PARTITION (P) VALUES ... LOAD INTO TABLE T SUBPARTITION (P) VALUES ...
While you are loading a partition of a partitioned or subpartitioned table, you are also allowed to perform DML operations on, and direct path loads of, other partitions in the table.
Although a direct path load minimizes database processing, several calls to the Oracle database are required at the beginning and end of the load to initialize and finish the load, respectively. Also, certain DML locks are required during load initialization and are released when the load completes. The following operations occur during the load: index keys are built and put into a sort, and space management routines are used to get new extents when needed and to adjust the upper boundary (high-water mark) for a data savepoint. See Using Data Saves to Protect Against Data Loss for information about adjusting the upper boundary.
A direct path load is faster than the conventional path for the following reasons:
Partial blocks are not used, so no reads are needed to find them, and fewer writes are performed.
SQL*Loader need not execute any SQL INSERT statements; therefore, the processing load on the Oracle database is reduced.
A direct path load calls on Oracle to lock tables and indexes at the start of the load and releases them when the load is finished. A conventional path load calls Oracle once for each array of rows to process a SQL INSERT statement.
A direct path load uses multiblock asynchronous I/O for writes to the database files.
During a direct path load, processes perform their own write I/O, instead of using Oracle's buffer cache. This minimizes contention with other Oracle users.
The sorted indexes option available during direct path loads enables you to presort data using high-performance sort routines that are native to your system or installation.
When a table to be loaded is empty, the presorting option eliminates the sort and merge phases of index-building. The index is filled in as data arrives.
Protection against instance failure does not require redo log file entries during direct path loads. Therefore, no time is required to log the load when:
The Oracle database has the SQL NOARCHIVELOG parameter enabled
The SQL*Loader UNRECOVERABLE clause is enabled
The object being loaded has the SQL NOLOGGING parameter set
The following conditions must be satisfied for you to use the direct path load method:
Tables are not clustered.
Tables to be loaded do not have any active transactions pending.
To check for this condition, use the Oracle Enterprise Manager command MONITOR TABLE to find the object ID for the tables you want to load. Then use the command MONITOR LOCK to see if there are any locks on the tables.
For versions of the database prior to Oracle9i, you can perform a SQL*Loader direct path load only when the client and server are the same version. This also means that you cannot perform a direct path load of Oracle9i data into a database of an earlier version. For example, you cannot use direct path load to load data from a release 9.0.1 database into a release 8.1.7 database.
Beginning with Oracle9i, you can perform a SQL*Loader direct path load when the client and server are different versions. However, both versions must be at least release 9.0.1 and the client version must be higher than the server version. For example, you can perform a direct path load from a release 9.0.1 database into a release 9.2 database. However, you cannot use direct path load to load data from a release 10.0.0 database into a release 9.2 database.
The following features are not available with direct path load:
Loading a parent table together with a child table
Loading BFILE columns
In addition to the previously listed restrictions, loading a single partition has the following restrictions:
The table that the partition is a member of cannot have any global indexes defined on it.
Enabled referential and check constraints on the table that the partition is a member of are not allowed.
Enabled triggers are not allowed.
If none of the previous restrictions apply, you should use a direct path load when:
You have a large amount of data to load quickly. A direct path load can quickly load and index large amounts of data. It can also load data into either an empty or nonempty table.
You want to load data in parallel for maximum performance. See Parallel Data Loading Models.
All integrity constraints are enforced during direct path loads, although not necessarily at the same time. NOT NULL constraints are enforced during the load. Records that fail these constraints are rejected.
UNIQUE constraints are enforced both during and after the load. A record that violates a UNIQUE constraint is not rejected (the record is not available in memory when the constraint violation is detected).
Integrity constraints that depend on other rows or tables, such as referential constraints, are disabled before the direct path load and must be reenabled afterwards. If REENABLE is specified, SQL*Loader can reenable them automatically at the end of the load. When the constraints are reenabled, the entire table is checked. Any rows that fail this check are reported in the specified error log. See Direct Loads, Integrity Constraints, and Triggers.
Default column specifications defined in the database are not available when you use direct path loading. Fields for which default values are desired must be specified with the DEFAULTIF clause. If a DEFAULTIF clause is not specified and the field is NULL, then a null value is inserted into the database.
This section explains how to use the SQL*Loader direct path load method.
To prepare the database for direct path loads, you must run the setup script, catldr.sql, to create the necessary views. You need only run this script once for each database you plan to do direct loads to. You can run this script during database installation if you know then that you will be doing direct loads.
To start SQL*Loader in direct path load mode, set the DIRECT parameter to true on the command line or in the parameter file, if used, in the format:
DIRECT=true
|
See Also:
|
You can improve performance of direct path loads by using temporary storage. After each block is formatted, the new index keys are put in a sort (temporary) segment. The old index and the new keys are merged at load finish time to create the new index. The old index, sort (temporary) segment, and new index segment all require storage until the merge is complete. Then the old index and temporary segment are removed.
During a conventional path load, every time a row is inserted the index is updated. This method does not require temporary storage space, but it does add processing time.
To improve performance on systems with limited memory, use the SINGLEROW parameter. For more information, see SINGLEROW Option.
|
Note: If, during a direct load, you have specified that the data is to be presorted and the existing index is empty, a temporary segment is not required, and no merge occurs—the keys are put directly into the index. See Optimizing Performance of Direct Path Loads for more information. |
When multiple indexes are built, the temporary segments corresponding to each index exist simultaneously, in addition to the old indexes. The new keys are then merged with the old indexes, one index at a time. As each new index is created, the old index and the corresponding temporary segment are removed.
|
See Also: Oracle Database Administrator's Guide for information about how to estimate index size and set storage parameters |
To estimate the amount of temporary segment space needed for storing the new index keys (in bytes), use the following formula:
1.3 * key_storage
In this formula, key storage is defined as follows:
key_storage = (number_of_rows) *
( 10 + sum_of_column_sizes + number_of_columns )
The columns included in this formula are the columns in the index. There is one length byte per column, and 10 bytes per row are used for a ROWID and additional overhead.
The constant 1.3 reflects the average amount of extra space needed for sorting. This value is appropriate for most randomly ordered data. If the data arrives in exactly opposite order, twice the key-storage space is required for sorting, and the value of this constant would be 2.0. That is the worst case.
If the data is fully sorted, only enough space to store the index entries is required, and the value of this constant would be 1.0. See Presorting Data for Faster Indexing for more information.
SQL*Loader leaves indexes in an Index Unusable state when the data segment being loaded becomes more up-to-date than the index segments that index it.
Any SQL statement that tries to use an index that is in an Index Unusable state returns an error. The following conditions cause a direct path load to leave an index or a partition of a partitioned index in an Index Unusable state:
SQL*Loader runs out of space for the index and cannot update the index.
The data is not in the order specified by the SORTED INDEXES clause.
There is an instance failure, or the Oracle shadow process fails while building the index.
There are duplicate keys in a unique index.
Data savepoints are being used, and the load fails or is terminated by a keyboard interrupt after a data savepoint occurred.
To determine if an index is in an Index Unusable state, you can execute a simple query:
SELECT INDEX_NAME, STATUS FROM USER_INDEXES WHERE TABLE_NAME = 'tablename';
If you are not the owner of the table, then search ALL_INDEXES or DBA_INDEXES instead of USER_INDEXES.
To determine if an index partition is in an unusable state, you can execute the following query:
SELECT INDEX_NAME,
PARTITION_NAME,
STATUS FROM USER_IND_PARTITIONS
WHERE STATUS != 'VALID';
If you are not the owner of the table, then search ALL_IND_PARTITIONS and DBA_IND_PARTITIONS instead of USER_IND_PARTITIONS.
You can use data saves to protect against loss of data due to instance failure. All data loaded up to the last savepoint is protected against instance failure. To continue the load after an instance failure, determine how many rows from the input file were processed before the failure, then use the SKIP parameter to skip those processed rows.
If there are any indexes on the table, drop them before continuing the load, then re-create them after the load. See Data Recovery During Direct Path Loads for more information about media and instance recovery.
|
Note: Indexes are not protected by a data save, because SQL*Loader does not build indexes until after data loading completes. (The only time indexes are built during the load is when presorted data is loaded into an empty table, but these indexes are also unprotected.) |
The ROWS parameter determines when data saves occur during a direct path load. The value you specify for ROWS is the number of rows you want SQL*Loader to read from the input file before saving inserts in the database.
A data save is an expensive operation. The value for ROWS should be set high enough so that a data save occurs once every 15 minutes or longer. The intent is to provide an upper boundary (high-water mark) on the amount of work that is lost when an instance failure occurs during a long-running direct path load. Setting the value of ROWS to a small number adversely affects performance and data block space utilization.
In a conventional load, ROWS is the number of rows to read before a commit operation. A direct load data save is similar to a conventional load commit, but it is not identical.
The similarities are as follows:
A data save will make the rows visible to other users.
Rows cannot be rolled back after a data save.
The major difference is that in a direct path load data save, the indexes will be unusable (in Index Unusable state) until the load completes.
SQL*Loader provides full support for data recovery when using the direct path load method. There are two main types of recovery:
Media - recovery from the loss of a database file. You must be operating in ARCHIVELOG mode to recover after you lose a database file.
Instance - recovery from a system failure in which in-memory data was changed but lost due to the failure before it was written to disk. The Oracle database can always recover from instance failures, even when redo logs are not archived.
If redo log file archiving is enabled (you are operating in ARCHIVELOG mode), SQL*Loader logs loaded data when using the direct path, making media recovery possible. If redo log archiving is not enabled (you are operating in NOARCHIVELOG mode), then media recovery is not possible.
To recover a database file that was lost while it was being loaded, use the same method that you use to recover data loaded with the conventional path:
Restore the most recent backup of the affected database file.
Recover the tablespace using the RECOVER command.
|
See Also: Oracle Database Backup and Recovery Advanced User's Guide for more information about the RMANRECOVER command |
Because SQL*Loader writes directly to the database files, all rows inserted up to the last data save will automatically be present in the database files if the instance is restarted. Changes do not need to be recorded in the redo log file to make instance recovery possible.
If an instance failure occurs, the indexes being built may be left in an Index Unusable state. Indexes that are Unusable must be rebuilt before you can use the table or partition. See Indexes Left in an Unusable State for information about how to determine if an index has been left in Index Unusable state.
Data that is longer than SQL*Loader's maximum buffer size can be loaded on the direct path by using LOBs. You can improve performance when doing this by using a large STREAMSIZE value.
You could also load data that is longer than the maximum buffer size by using the PIECED parameter, as described in the next section, but Oracle highly recommends that you use LOBs instead.
The PIECED parameter can be used to load data in sections, if the data is in the last column of the logical record.
Declaring a column as PIECED informs the direct path loader that a LONG field might be split across multiple physical records (pieces). In such cases, SQL*Loader processes each piece of the LONG field as it is found in the physical record. All the pieces are read before the record is processed. SQL*Loader makes no attempt to materialize the LONG field before storing it; however, all the pieces are read before the record is processed.
The following restrictions apply when you declare a column as PIECED:
This option is only valid on the direct path.
Only one field per table may be PIECED.
The PIECED field must be the last field in the logical record.
The PIECED field may not be used in any WHEN, NULLIF, or DEFAULTIF clauses.
The PIECED field's region in the logical record must not overlap with any other field's region.
The PIECED corresponding database column may not be part of the index.
It may not be possible to load a rejected record from the bad file if it contains a PIECED field.
For example, a PIECED field could span three records. SQL*Loader loads the piece from the first record and then reuses the buffer for the second buffer. After loading the second piece, the buffer is reused for the third record. If an error is then discovered, only the third record is placed in the bad file because the first two records no longer exist in the buffer. As a result, the record in the bad file would not be valid.
You can control the time and temporary storage used during direct path loads.
To minimize time:
Preallocate storage space
Presort the data
Perform infrequent data saves
Minimize use of the redo log
Specify the number of column array rows and the size of the stream buffer
Specify a date cache value
To minimize space:
When sorting data before the load, sort data on the index that requires the most temporary storage space
Avoid index maintenance during the load
SQL*Loader automatically adds extents to the table if necessary, but this process takes time. For faster loads into a new table, allocate the required extents when the table is created.
To calculate the space required by a table, see the information about managing database files in the Oracle Database Administrator's Guide. Then use the INITIAL or MINEXTENTS clause in the SQL CREATE TABLE statement to allocate the required space.
Another approach is to size extents large enough so that extent allocation is infrequent.
You can improve the performance of direct path loads by presorting your data on indexed columns. Presorting minimizes temporary storage requirements during the load. Presorting also enables you to take advantage of high-performance sorting routines that are optimized for your operating system or application.
If the data is presorted and the existing index is not empty, then presorting minimizes the amount of temporary segment space needed for the new keys. The sort routine appends each new key to the key list.
Instead of requiring extra space for sorting, only space for the keys is needed. To calculate the amount of storage needed, use a sort factor of 1.0 instead of 1.3. For more information about estimating storage requirements, see Temporary Segment Storage Requirements.
If presorting is specified and the existing index is empty, then maximum efficiency is achieved. The new keys are simply inserted into the index. Instead of having a temporary segment and new index existing simultaneously with the empty, old index, only the new index exists. So, temporary storage is not required, and time is saved.
The SORTED INDEXES clause identifies the indexes on which the data is presorted. This clause is allowed only for direct path loads. See Case Study 6: Loading Data Using the Direct Path Load Method for an example.
Generally, you specify only one index in the SORTED INDEXES clause, because data that is sorted for one index is not usually in the right order for another index. When the data is in the same order for multiple indexes, however, all indexes can be specified at once.
All indexes listed in the SORTED INDEXES clause must be created before you start the direct path load.
If you specify an index in the SORTED INDEXES clause, and the data is not sorted for that index, then the index is left in an Index Unusable state at the end of the load. The data is present, but any attempt to use the index results in an error. Any index that is left in an Index Unusable state must be rebuilt after the load.
If you specify a multiple-column index in the SORTED INDEXES clause, the data should be sorted so that it is ordered first on the first column in the index, next on the second column in the index, and so on.
For example, if the first column of the index is city, and the second column is last name; then the data should be ordered by name within each city, as in the following list:
Albuquerque Adams Albuquerque Hartstein Albuquerque Klein ... ... Boston Andrews Boston Bobrowski Boston Heigham ... ...
For the best overall performance of direct path loads, you should presort the data based on the index that requires the most temporary segment space. For example, if the primary key is one numeric column, and the secondary key consists of three text columns, then you can minimize both sort time and storage requirements by presorting on the secondary key.
To determine the index that requires the most storage space, use the following procedure:
For each index, add up the widths of all columns in that index.
For a single-table load, pick the index with the largest overall width.
For each table in a multiple-table load, identify the index with the largest overall width. If the same number of rows are to be loaded into each table, then again pick the index with the largest overall width. Usually, the same number of rows are loaded into each table.
If a different number of rows are to be loaded into the indexed tables in a multiple-table load, then multiply the width of each index identified in Step 3 by the number of rows that are to be loaded into that index, and pick the index with the largest result.
Frequent data saves resulting from a small ROWS value adversely affect the performance of a direct path load. A small ROWS value can also result in wasted data block space because the last data block is not written to after a save, even if the data block is not full.
Because direct path loads can be many times faster than conventional loads, the value of ROWS should be considerably higher for a direct load than it would be for a conventional load.
During a data save, loading stops until all of SQL*Loader's buffers are successfully written. You should select the largest value for ROWS that is consistent with safety. It is a good idea to determine the average time to load a row by loading a few thousand rows. Then you can use that value to select a good value for ROWS.
For example, if you can load 20,000 rows per minute, and you do not want to repeat more than 10 minutes of work after an interruption, then set ROWS to be 200,000 (20,000 rows/minute * 10 minutes).
One way to speed a direct load dramatically is to minimize use of the redo log. There are three ways to do this. You can disable archiving, you can specify that the load is unrecoverable, or you can set the SQL NOLOGGING parameter for the objects being loaded. This section discusses all methods.
If archiving is disabled, direct path loads do not generate full image redo. Use the SQL ARCHIVELOG and NOARCHIVELOG parameters to set the archiving mode. See the Oracle Database Administrator's Guide for more information about archiving.
To save time and space in the redo log file, use the SQL*Loader UNRECOVERABLE clause in the control file when you load data. An unrecoverable load does not record loaded data in the redo log file; instead, it generates invalidation redo.
The UNRECOVERABLE clause applies to all objects loaded during the load session (both data and index segments). Therefore, media recovery is disabled for the loaded table, although database changes by other users may continue to be logged.
|
Note: Because the data load is not logged, you may want to make a backup of the data after loading. |
If media recovery becomes necessary on data that was loaded with the UNRECOVERABLE clause, the data blocks that were loaded are marked as logically corrupted.
To recover the data, drop and re-create the data. It is a good idea to do backups immediately after the load to preserve the otherwise unrecoverable data.
By default, a direct path load is RECOVERABLE.
UNRECOVERABLE LOAD DATA INFILE 'sample.dat' INTO TABLE emp (ename VARCHAR2(10), empno NUMBER(4));
The number of column array rows determines the number of rows loaded before the stream buffer is built. The STREAMSIZE parameter specifies the size (in bytes) of the data stream sent from the client to the server.
Use the COLUMNARRAYROWS parameter to specify a value for the number of column array rows. Note that when VARRAYs are loaded using direct path, the COLUMNARRAYROWS parameter defaults to 100 to avoid client object cache thrashing.
Use the STREAMSIZE parameter to specify the size for direct path stream buffers.
The optimal values for these parameters vary, depending on the system, input datatypes, and Oracle column datatypes used. When you are using optimal values for your particular configuration, the elapsed time in the SQL*Loader log file should go down.
To see a list of default values for these and other parameters, invoke SQL*Loader without any parameters, as described in Invoking SQL*Loader.
|
Note: You should monitor process paging activity, because if paging becomes excessive, performance can be significantly degraded. You may need to lower the values forREADSIZE, STREAMSIZE, and COLUMNARRAYROWS to avoid excessive paging. |
It can be particularly useful to specify the number of column array rows and size of the steam buffer when you perform direct path loads on multiple-CPU systems. See Optimizing Direct Path Loads on Multiple-CPU Systems for more information.
If you are performing a direct path load in which the same date or timestamp values are loaded many times, a large percentage of total load time can end up being used for converting date and timestamp data. This is especially true if multiple date columns are being loaded. In such a case, it may be possible to improve performance by using the SQL*Loader date cache.
The date cache reduces the number of date conversions done when many duplicate values are present in the input data. It enables you to specify the number of unique dates anticipated during the load.
The date cache is enabled by default. To completely disable the date cache, set it to 0.
The default date cache size is 1000 elements. If the default is used and the number of unique input values loaded exceeds 1000, then the date cache is automatically disabled for that table. This prevents excessive and unnecessary lookup times that could affect performance. However, if instead of using the default, you specify a nonzero value for the date cache and it is exceeded, the date cache is not disabled. Instead, any input data that exceeded the maximum is explicitly converted using the appropriate conversion routines.
The date cache can be associated with only one table. No date cache sharing can take place across tables. A date cache is created for a table only if all of the following conditions are true:
The DATE_CACHE parameter is not set to 0.
One or more date values, timestamp values, or both are being loaded that require datatype conversion in order to be stored in the table.
The load is a direct path load.
Date cache statistics are written to the log file. You can use those statistics to improve direct path load performance as follows:
If the number of cache entries is less than the cache size and there are no cache misses, then the cache size could safely be set to a smaller value.
If the number of cache hits (entries for which there are duplicate values) is small and the number of cache misses is large, then the cache size should be increased. Be aware that if the cache size is increased too much, it may cause other problems, such as excessive paging or too much memory usage.
If most of the input date values are unique, the date cache will not enhance performance and therefore should not be used.
|
Note: Date cache statistics are not written to the SQL*Loader log file if the cache was active by default and disabled because the maximum was exceeded. |
If increasing the cache size does not improve performance, revert to the default behavior or set the cache size to 0. The overall performance improvement also depends on the datatypes of the other columns being loaded. Improvement will be greater for cases in which the total number of date columns loaded is large compared to other types of data loaded.
If you are performing direct path loads on a multiple-CPU system, SQL*Loader uses multithreading by default. A multiple-CPU system in this case is defined as a single system that has two or more CPUs.
Multithreaded loading means that, when possible, conversion of the column arrays to stream buffers and stream buffer loading are performed in parallel. This optimization works best when:
Column arrays are large enough to generate multiple direct path stream buffers for loads
Data conversions are required from input field datatypes to Oracle column datatypes
The conversions are performed in parallel with stream buffer loading.
The status of this process is recorded in the SQL*Loader log file, as shown in the following sample portion of a log:
Total stream buffers loaded by SQL*Loader main thread: 47 Total stream buffers loaded by SQL*Loader load thread: 180 Column array rows: 1000 Stream buffer bytes: 256000
In this example, the SQL*Loader load thread has offloaded the SQL*Loader main thread, allowing the main thread to build the next stream buffer while the load thread loads the current stream on the server.
The goal is to have the load thread perform as many stream buffer loads as possible. This can be accomplished by increasing the number of column array rows, decreasing the stream buffer size, or both. You can monitor the elapsed time in the SQL*Loader log file to determine whether your changes are having the desired effect. See Specifying the Number of Column Array Rows and Size of Stream Buffers for more information.
On single-CPU systems, optimization is turned off by default. When the server is on another system, performance may improve if you manually turn on multithreading.
To turn the multithreading option on or off, use the MULTITHREADING parameter at the SQL*Loader command line or specify it in your SQL*Loader control file.
|
See Also: Oracle Call Interface Programmer's Guide for more information about the concepts of direct path loading |
For both the conventional path and the direct path, SQL*Loader maintains all existing indexes for a table.
To avoid index maintenance, use one of the following methods:
Drop the indexes prior to the beginning of the load.
Mark selected indexes or index partitions as Index Unusable prior to the beginning of the load and use the SKIP_UNUSABLE_INDEXES parameter.
Use the SKIP_INDEX_MAINTENANCE parameter (direct path only, use with caution).
By avoiding index maintenance, you minimize the amount of space required during a direct path load, in the following ways:
You can build indexes one at a time, reducing the amount of sort (temporary) segment space that would otherwise be needed for each index.
Only one index segment exists when an index is built, instead of the three segments that temporarily exist when the new keys are merged into the old index to make the new index.
Avoiding index maintenance is quite reasonable when the number of rows to be loaded is large compared to the size of the table. But if relatively few rows are added to a large table, then the time required to resort the indexes may be excessive. In such cases, it is usually better to use the conventional path load method, or to use the SINGLEROW parameter of SQL*Loader. For more information, see SINGLEROW Option.
With the conventional path load method, arrays of rows are inserted with standard SQL INSERT statements—integrity constraints and insert triggers are automatically applied. But when you load data with the direct path, SQL*Loader disables some integrity constraints and all database triggers. This section discusses the implications of using direct path loads with respect to these features.
During a direct path load, some integrity constraints are automatically disabled. Others are not. For a description of the constraints, see the information about maintaining data integrity in the Oracle Database Application Developer's Guide - Fundamentals.
The constraints that remain in force are:
NOT NULL
UNIQUE
PRIMARY KEY (unique-constraints on not-null columns)
NOT NULL constraints are checked at column array build time. Any row that violates the NOT NULL constraint is rejected.
UNIQUE constraints are verified when indexes are rebuilt at the end of the load. The index will be left in an Index Unusable state if a violation of a UNIQUE constraint is detected. See Indexes Left in an Unusable State.
During a direct path load, the following constraints are automatically disabled by default:
CHECK constraints
Referential constraints (FOREIGN KEY)
You can override the automatic disabling of CHECK constraints by specifying the EVALUATE CHECK_CONSTRAINTS clause. SQL*Loader will then evaluate CHECK constraints during a direct path load. Any row that violates the CHECK constraint is rejected. The following example shows the use of the EVALUATE CHECK_CONSTRAINTS clause in a SQL*Loader control file:
LOAD DATA INFILE * APPEND INTO TABLE emp EVALUATE CHECK_CONSTRAINTS FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' (c1 CHAR(10) ,c2) BEGINDATA Jones,10 Smith,20 Brown,30 Taylor,40
When the load completes, the integrity constraints will be reenabled automatically if the REENABLE clause is specified. The syntax for the REENABLE clause is as follows:


The optional parameter DISABLED_CONSTRAINTS is provided for readability. If the EXCEPTIONS clause is included, the table must already exist, and you must be able to insert into it. This table contains the ROWIDs of all rows that violated one of the integrity constraints. It also contains the name of the constraint that was violated. See Oracle Database SQL Reference for instructions on how to create an exceptions table.
The SQL*Loader log file describes the constraints that were disabled, the ones that were reenabled, and what error, if any, prevented reenabling or validating of each constraint. It also contains the name of the exceptions table specified for each loaded table.
If the REENABLE clause is not used, then the constraints must be reenabled manually, at which time all rows in the table are verified. If the Oracle database finds any errors in the new data, error messages are produced. The names of violated constraints and the ROWIDs of the bad data are placed in an exceptions table, if one is specified.
If the REENABLE clause is used, SQL*Loader automatically reenables the constraint and then verifies all new rows. If no errors are found in the new data, SQL*Loader automatically marks the constraint as validated. If any errors are found in the new data, error messages are written to the log file and SQL*Loader marks the status of the constraint as ENABLE NOVALIDATE. The names of violated constraints and the ROWIDs of the bad data are placed in an exceptions table, if one is specified.
|
Note: Normally, when a table constraint is left in anENABLE NOVALIDATE state, new data can be inserted into the table but no new invalid data may be inserted. However, SQL*Loader direct path load does not enforce this rule. Thus, if subsequent direct path loads are performed with invalid data, the invalid data will be inserted but the same error reporting and exception table processing as described previously will take place. In this scenario the exception table may contain duplicate entries if it is not cleared out before each load. Duplicate entries can easily be filtered out by performing a query such as the following:
SELECT UNIQUE * FROM exceptions_table; |
|
Note: Because referential integrity must be reverified for the entire table, performance may be improved by using the conventional path, instead of the direct path, when a small number of rows are to be loaded into a very large table. |
Table insert triggers are also disabled when a direct path load begins. After the rows are loaded and indexes rebuilt, any triggers that were disabled are automatically reenabled. The log file lists all triggers that were disabled for the load. There should not be any errors reenabling triggers.
Unlike integrity constraints, insert triggers are not reapplied to the whole table when they are enabled. As a result, insert triggers do not fire for any rows loaded on the direct path. When using the direct path, the application must ensure that any behavior associated with insert triggers is carried out for the new rows.
Applications commonly use insert triggers to implement integrity constraints. Most of the triggers that these application insert are simple enough that they can be replaced with Oracle's automatic integrity constraints.
Sometimes an insert trigger cannot be replaced with Oracle's automatic integrity constraints. For example, if an integrity check is implemented with a table lookup in an insert trigger, then automatic check constraints cannot be used, because the automatic constraints can only reference constants and columns in the current row. This section describes two methods for duplicating the effects of such a trigger.
Before either method can be used, the table must be prepared. Use the following general guidelines to prepare the table:
Before the load, add a 1-byte or 1-character column to the table that marks rows as "old data" or "new data."
Let the value of null for this column signify "old data," because null columns do not take up space.
When loading, flag all loaded rows as "new data" with SQL*Loader's CONSTANT parameter.
After following this procedure, all newly loaded rows are identified, making it possible to operate on the new data without affecting the old rows.
Generally, you can use a database update trigger to duplicate the effects of an insert trigger. This method is the simplest. It can be used whenever the insert trigger does not raise any exceptions.
Create an update trigger that duplicates the effects of the insert trigger.
Copy the trigger. Change all occurrences of "new.column_name" to "old.column_name".
Replace the current update trigger, if it exists, with the new one.
Update the table, changing the "new data" flag to null, thereby firing the update trigger.
Restore the original update trigger, if there was one.
Depending on the behavior of the trigger, it may be necessary to have exclusive update access to the table during this operation, so that other users do not inadvertently apply the trigger to rows they modify.
If the insert trigger can raise an exception, then more work is required to duplicate its effects. Raising an exception would prevent the row from being inserted into the table. To duplicate that effect with an update trigger, it is necessary to mark the loaded row for deletion.
The "new data" column cannot be used as a delete flag, because an update trigger cannot modify the columns that caused it to fire. So another column must be added to the table. This column marks the row for deletion. A null value means the row is valid. Whenever the insert trigger would raise an exception, the update trigger can mark the row as invalid by setting a flag in the additional column.
In summary, when an insert trigger can raise an exception condition, its effects can be duplicated by an update trigger, provided:
Two columns (which are usually null) are added to the table
The table can be updated exclusively (if necessary)
The following procedure always works, but it is more complex to implement. It can be used when the insert trigger raises exceptions. It does not require a second additional column; and, because it does not replace the update trigger, it can be used without exclusive access to the table.
Do the following to create a stored procedure that duplicates the effects of the insert trigger:
Declare a cursor for the table, selecting all new rows.
Open the cursor and fetch rows, one at a time, in a processing loop.
Perform the operations contained in the insert trigger.
If the operations succeed, change the "new data" flag to null.
If the operations fail, change the "new data" flag to "bad data."
Execute the stored procedure using an administration tool such as SQL*Plus.
After running the procedure, check the table for any rows marked "bad data."
Update or remove the bad rows.
Reenable the insert trigger.
SQL*Loader needs to acquire several locks on the table to be loaded to disable triggers and constraints. If a competing process is enabling triggers or constraints at the same time that SQL*Loader is trying to disable them for that table, then SQL*Loader may not be able to acquire exclusive access to the table.
SQL*Loader attempts to handle this situation as gracefully as possible. It attempts to reenable disabled triggers and constraints before exiting. However, the same table-locking problem that made it impossible for SQL*Loader to continue may also have made it impossible for SQL*Loader to finish enabling triggers and constraints. In such cases, triggers and constraints will remain disabled until they are manually enabled.
Although such a situation is unlikely, it is possible. The best way to prevent it is to make sure that no applications are running that could enable triggers or constraints for the table while the direct load is in progress.
If a direct load is terminated due to failure to acquire the proper locks, carefully check the log. It will show every trigger and constraint that was disabled, and each attempt to reenable them. Any triggers or constraints that were not reenabled by SQL*Loader should be manually enabled with the ENABLE clause of the ALTER TABLE statement described inOracle Database SQL Reference.
If triggers or integrity constraints pose a problem, but you want faster loading, you should consider using concurrent conventional path loads. That is, use multiple load sessions executing concurrently on a multiple-CPU system. Split the input datafiles into separate files on logical record boundaries, and then load each such input datafile with a conventional path load session. The resulting load has the following attributes:
This section discusses three basic models of concurrency that you can use to minimize the elapsed time required for data loading:
Concurrent conventional path loads
Intersegment concurrency with the direct path load method
Intrasegment concurrency with the direct path load method
Using multiple conventional path load sessions executing concurrently is discussed in Increasing Performance with Concurrent Conventional Path Loads. You can use this technique to load the same or different objects concurrently with no restrictions.
Intersegment concurrency can be used for concurrent loading of different objects. You can apply this technique to concurrent direct path loading of different tables, or to concurrent direct path loading of different partitions of the same table.
When you direct path load a single partition, consider the following items:
Local indexes can be maintained by the load.
Global indexes cannot be maintained by the load.
Referential integrity and CHECK constraints must be disabled.
Triggers must be disabled.
The input data should be partitioned (otherwise many records will be rejected, which adversely affects performance).
SQL*Loader permits multiple, concurrent sessions to perform a direct path load into the same table, or into the same partition of a partitioned table. Multiple SQL*Loader sessions improve the performance of a direct path load given the available resources on your system.
This method of data loading is enabled by setting both the DIRECT and the PARALLEL parameters to true, and is often referred to as a parallel direct path load.
It is important to realize that parallelism is user managed. Setting the PARALLEL parameter to true only allows multiple concurrent direct path load sessions.
The following restrictions are enforced on parallel direct path loads:
Neither local or global indexes can be maintained by the load.
Referential integrity and CHECK constraints must be disabled.
Triggers must be disabled.
Rows can only be appended. REPLACE, TRUNCATE, and INSERT cannot be used (this is due to the individual loads not being coordinated). If you must truncate a table before a parallel load, you must do it manually.
If a parallel direct path load is being applied to a single partition, you should partition the data first (otherwise, the overhead of record rejection due to a partition mismatch slows down the load).
Each SQL*Loader session takes a different datafile as input. In all sessions executing a direct load on the same table, you must set PARALLEL to true. The syntax is:
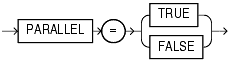
PARALLEL can be specified on the command line or in a parameter file. It can also be specified in the control file with the OPTIONS clause.
For example, to invoke three SQL*Loader direct path load sessions on the same table, you would execute the following commands at the operating system prompt:
sqlldr USERID=scott/tiger CONTROL=load1.ctl DIRECT=TRUE PARALLEL=true sqlldr USERID=scott/tiger CONTROL=load2.ctl DIRECT=TRUE PARALLEL=true sqlldr USERID=scott/tiger CONTROL=load3.ctl DIRECT=TRUE PARALLEL=true
The previous commands must be executed in separate sessions, or if permitted on your operating system, as separate background jobs. Note the use of multiple control files. This enables you to be flexible in specifying the files to use for the direct path load.
|
Note: Indexes are not maintained during a parallel load. Any indexes must be created or re-created manually after the load completes. You can use the parallel index creation or parallel index rebuild feature to speed the building of large indexes after a parallel load. |
When you perform a parallel load, SQL*Loader creates temporary segments for each concurrent session and then merges the segments upon completion. The segment created from the merge is then added to the existing segment in the database above the segment's high-water mark. The last extent used of each segment for each loader session is trimmed of any free space before being combined with the other extents of the SQL*Loader session.
When you perform parallel direct path loads, there are options available for specifying attributes of the temporary segment to be allocated by the loader. These options are specified with the FILE and STORAGE parameters. These parameters are valid only for parallel loads.
To allow for maximum I/O throughput, Oracle recommends that each concurrent direct path load session use files located on different disks. In the SQL*Loader control file, use the FILE parameter of the OPTIONS clause to specify the filename of any valid datafile in the tablespace of the object (table or partition) being loaded.
For example:
LOAD DATA INFILE 'load1.dat' INSERT INTO TABLE emp OPTIONS(FILE='/dat/data1.dat') (empno POSITION(01:04) INTEGER EXTERNAL NULLIF empno=BLANKS ...
You could also specify the FILE parameter on the command line of each concurrent SQL*Loader session, but then it would apply globally to all objects being loaded with that session.
The FILE parameter in the Oracle database has the following restrictions for parallel direct path loads:
For nonpartitioned tables: The specified file must be in the tablespace of the table being loaded.
For partitioned tables, single-partition load: The specified file must be in the tablespace of the partition being loaded.
For partitioned tables, full-table load: The specified file must be in the tablespace of all partitions being loaded; that is, all partitions must be in the same tablespace.
You can use the STORAGE parameter to specify the storage attributes of the temporary segments allocated for a parallel direct path load. If the STORAGE parameter is not used, the storage attributes of the segment containing the object (table, partition) being loaded are used. Also, when the STORAGE parameter is not specified, SQL*Loader uses a default of 2 KB for EXTENTS.
For example, the following OPTIONS clause could be used to specify STORAGE parameters:
OPTIONS (STORAGE=(INITIAL 100M NEXT 100M PCTINCREASE 0))
You can use the STORAGE parameter only in the SQL*Loader control file, and not on the command line. Use of the STORAGE parameter to specify anything other than PCTINCREASE of 0, and INITIAL or NEXT values is strongly discouraged and may be silently ignored.
Constraints and triggers must be enabled manually after all data loading is complete.
Because each SQL*Loader session can attempt to reenable constraints on a table after a direct path load, there is a danger that one session may attempt to reenable a constraint before another session is finished loading data. In this case, the first session to complete the load will be unable to enable the constraint because the remaining sessions possess share locks on the table.
Because there is a danger that some constraints might not be reenabled after a direct path load, you should check the status of the constraint after completing the load to ensure that it was enabled properly.
PRIMARY KEY and UNIQUE KEY constraints create indexes on a table when they are enabled, and subsequently can take a significantly long time to enable after a direct path loading session if the table is very large. You should consider enabling these constraints manually after a load (and not specifying the automatic enable feature). This enables you to manually create the required indexes in parallel to save time before enabling the constraint.
If you have control over the format of the data to be loaded, you can use the following hints to improve load performance:
Make logical record processing efficient.
Use one-to-one mapping of physical records to logical records (avoid using CONTINUEIF and CONCATENATE).
Make it easy for the software to identify physical record boundaries. Use the file processing option string "FIX nnn" or "VAR". If you use the default (stream mode) on most platforms (for example, UNIX and NT) the loader must scan each physical record for the record terminator (newline character).
Make field setting efficient. Field setting is the process of mapping fields in the datafile to their corresponding columns in the table being loaded. The mapping function is controlled by the description of the fields in the control file. Field setting (along with data conversion) is the biggest consumer of CPU cycles for most loads.
Avoid delimited fields; use positional fields. If you use delimited fields, the loader must scan the input data to find the delimiters. If you use positional fields, field setting becomes simple pointer arithmetic (very fast).
Do not trim whitespace if you do not need to (use PRESERVE BLANKS).
Make conversions efficient. SQL*Loader performs character set conversion and datatype conversion for you. Of course, the quickest conversion is no conversion.
Use single-byte character sets if you can.
Avoid character set conversions if you can. SQL*Loader supports four character sets:
Client character set (NLS_LANG of the client sqlldr process)
Datafile character set (usually the same as the client character set)
Database character set
Database national character set
Performance is optimized if all character sets are the same. For direct path loads, it is best if the datafile character set and the database character set are the same. If the character sets are the same, character set conversion buffers are not allocated.
Use direct path loads.
Use the SORTED INDEXES clause.
Avoid unnecessary NULLIF and DEFAULTIF clauses. Each clause must be evaluated on each column that has a clause associated with it for every row loaded.
Use parallel direct path loads and parallel index creation when you can.
Be aware of the effect on performance when you have large values for both the CONCATENATE clause and the COLUMNARRAYROWS clause. See Using CONCATENATE to Assemble Logical Records.
Additionally, the performance tips provided in Performance Hints When Using External Tables also apply to SQL*Loader.
|
 Copyright © 1996, 2003 Oracle Corporation All Rights Reserved. |
|

